基于材料數值計算大數據的材料輻照機理發現
2021-11-22 02:00:44任帥陳丹丹儲根深白鶴李慧昭何遠杰胡長軍
大數據 2021年6期
任帥,陳丹丹,儲根深,白鶴,李慧昭,何遠杰,胡長軍
1.北京科技大學計算機與通信工程學院,北京 100083;2.智能超算融合應用技術教育部工程研究中心,北京 100083
1 引言
在材料輻照效應領域,高性能計算軟件在模擬過程中會實時產生數值計算數據。這些數值計算數據不僅數目巨大、關聯性強,而且不同計算尺度、不同服役環境下的數據之間是相互關聯的。同時,這些數據中蘊含著材料從微觀機理到宏觀性能的規律,具有量大、關聯復雜、類型豐富的典型大數據特征(如圖1所示),是具有寶貴價值的。除了具有典型大數據特征,這些數據還具有領域特殊性。從反應堆材料生命周期的角度來看,首先,數據類型豐富。從具體的設計、服役到壽命終止,都會產生大量的類型多樣的數據,這些數據是典型的大數據。其次,關聯復雜,反應堆材料的使用壽命與各個服役階段息息相關。優異的服役性能離不開精確的系統測試,離不開大量的工藝參數調控,更離不開合適的成分、結構設計,因此,各個階段之間的數據關聯關系極其復雜。最后,具有時序性。反應堆材料的服役周期長達幾十年,且隨著使用時間增長,材料性能在不同的時效作用下也會呈現不同的特點,數據版本多種多樣,使得反應堆材料輻照數據具有顯著的時序性特點。
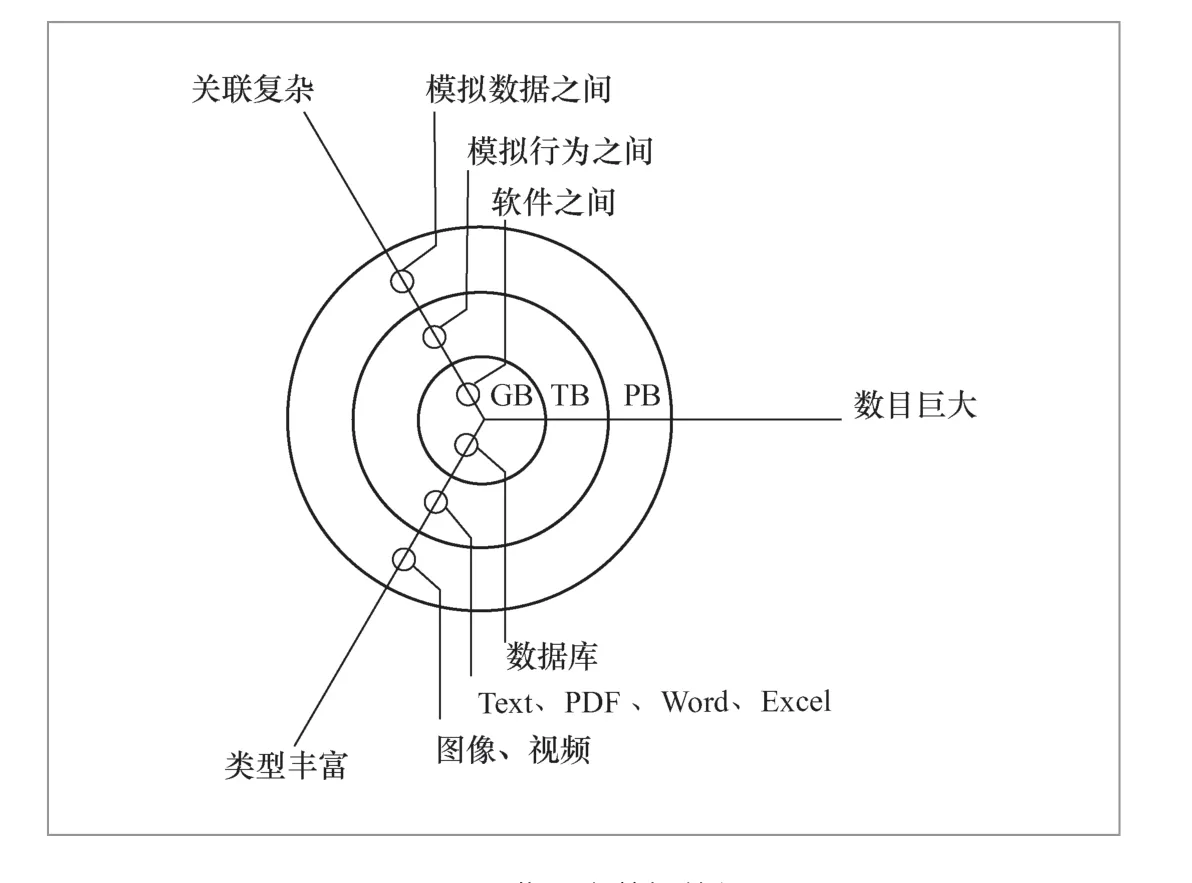
圖1 典型大數據特征
基于上述分析,筆者提出了材料數值計算大數據(big data of material simulation,MSBD)的概念,在超級計算機上已通過準確性驗證的材料數值建模和模擬軟件會產生大量的數值計算數據,這些數據具有數目巨大、關聯復雜、類型豐富等典型的大數據特征;同時這些數據具有類型豐富、時序性等領域特殊性。材料數值計算大數據是一類典型的工業大數據,對材料輻照效應的研究具有重要意義。依托現有的超算資源(如天河、神威、曙光等大型超級計算機),輔以專用數據庫實現,材料數值計算大數據不僅可以用于材料領域機器學習、知識發現和數據挖掘,也可以用于發展新的建模技術,例如用于材料計算模型的改進、材料多尺度模型耦合等。具體地講,材料數值計算大數據可用于以下幾個方面。例如,級聯碰撞后,材料內部原子離開原始晶格位置,聚集在一起形成不同形態的原子團簇微觀缺陷,這些缺陷在材料內部不容易滑移,因此容易引起材料硬化和脆化,從而影響反應堆壽命。這些團簇的尺寸只有幾納米,目前的實驗手段只能實現靜態的觀察,因此對于這些團簇的形成機理尚不清楚。聚類的方法通常用于數據模式識別,因此可通過基于聚類的方法對級聯碰撞特定時間步產生的材料數值計算大數據進行分析,挖掘級聯碰撞數據中不同類型的團簇,進而研究團簇類型和數量與實驗條件之間的關系,從而探究團簇類型和數量對材料性能的影響。又如,在新材料發現方面,基于物理模型的數值模擬計算被用于預測新材料已經有很多年的歷史,然而,這些模型在處理大規模、多維度問題時,往往需要占用大量的計算資源,且非常耗時。此外,隨著合金元素的增加,基于物理模型的勢函數建模越來越困難,通常來講,一種勢函數模型的構建時間需要2~3年。機器學習在處理多維問題上表現優異,基于機器學習方法和材料數值計算大數據對原子體系的模擬參數和勢能進行擬合,保留必要的物理參數,隱藏復雜的物理研究過程,從而改進現有建模技術。
2 材料數值計算大數據相關工作
近年來,大規模高性能材料數值計算模擬在材料研究中起著越來越重要的作用,是現今進行材料研究不可或缺的手段之一。尤其對于實驗條件復雜且實驗成本高昂的材料輻照效應研究而言,實驗前先通過材料模擬軟件對材料進行篩選,在大幅節省科研成本的同時,提高材料研究安全性[1-4]。高性能計算技術的發展使得材料輻照效應模擬無論在時間尺度還是空間尺度都取得了突破性進展[5]。隨著軟件尺度規模的擴大,產生的數據越來越多,材料數值計算大數據的高效存儲與分析成為材料數值計算研究的新焦點。
首先,在材料輻照效應模擬過程中,材料模擬軟件會產生海量的數值計算數據[6]。從不同模擬軟件的維度來看,分子動力學軟件用于原子尺度結構演化過程的模擬,一次大規模級聯碰撞模擬產生的原子尺度數據在1 GB以上,這些數據將被用于蒙特卡洛模擬軟件的短程演化;蒙特卡洛模擬軟件產生的原子結構數據將被傳遞給團簇動力學軟件,并由其對原子結構進行長程演化,一次大規模的輻照效應團簇動力學模擬產生的數據約100 GB,這些數據被用于位錯動力學等更大尺度的模擬。因此,材料數值計算大數據不僅數目巨大,而且各軟件產生的數據之間是彼此緊密關聯的。從單個軟件的模擬行為角度來看,不僅可以對不同類型的物理過程進行模擬,也可以針對同一類型的物理過程進行不同實驗條件下的模擬。例如,分子動力學軟件既可以進行晶內原子級聯碰撞的模擬,也可以進行晶界析出強化的模擬;既可以進行高能中子下的級聯碰撞模擬,也可以進行低能中子下的級聯碰撞模擬。蒙特卡洛模擬軟件既可以實現級聯碰撞的退火模擬,也可以對材料晶粒形核、長大過程進行模擬,還可以實現級聯碰撞的析出模擬等。從各軟件產生的材料數值計算大數據來看,數據類型更是極為復雜。每個軟件的每一次計算過程都會有不同的輸入數據、過程數據、結果數據、后處理數據等,不同軟件之間的這些數據還存在復雜的關聯關系。例如前面提到的,分子動力學軟件的模擬結果數據作為蒙特卡洛模擬軟件的輸入數據,蒙特卡洛模擬軟件的結果數據或者后處理數據則作為團簇動力學軟件的輸入數據,依此類推。綜上所述,材料輻照效應數值計算大數據具有顯著的數目巨大、關聯復雜的特點。
其次,這些數據對于材料輻照效應模擬的研究具有重要價值。這些數據蘊含了模擬材料輻照過程的物理模型信息、計算模型信息,合理收集這些數據并進行研究對于改進現有模型具有重要的研究價值。例如在材料輻照效應級聯碰撞模擬中,級聯碰撞結果數據通常為所有原子的坐標數據,與初始晶體的原子坐標數據(如獲取Frenkel缺陷對的數量)進行對比分析,可以對高能粒子輻照后的材料結構變化有初步的認識。如果進一步分析結果數據,還可以得到級聯碰撞后產生的團簇類型和數量信息,從而對原子尺度的輻照效應有一個更加清晰和直觀的認識。此外,模擬軟件計算結果往往存在不穩定性,這種不穩定性也是反映在結果數據中的。對多次模擬的結果數據進行統計分析,可以為改進模擬軟件的穩定性提供指導。除了結果數據具有很重要的研究價值,級聯碰撞過程數據同樣是值得研究的。過程數據反映了材料輻照效應模擬的整個演變過程,最直觀的用途是用于計算結束后模擬過程的可視化。由于數據量過大,還可以針對過程數據的可視化方法進行研究,例如對實時的可視化方法的研究等都離不開過程數據。除此之外,隨著機器學習和數據挖掘等方法近些年取得突破性發展,可以將這些方法用于材料數值計算大數據的研究中,例如,可以對輸入數據和結果數據之間的關聯關系進行挖掘。
近幾年已有一些基于材料數值計算大數據開展的研究工作被報道。例如,Bhardwaj U等人[7-9]使用聚類的方法開展了對分子力學(molecular dynamics,MD)級聯碰撞數據的分析研究。Podryabinkin E V等人[10]、Pilania G等人[11]通過機器學習對勢函數庫進行學習,開發用于勢函數計算的機器學習模型,在保證原有精度的基礎上將計算時間減少幾個數量級。Jia W L等人[12]把勢函數機器學習模型跟MD模擬軟件LAMMPS集成起來,擴大了原有的計算規模。Kawamura T等人[6]基于模擬的過程數據,開發了一種名為“In-Situ PBVR”的可視化軟件,首次實現了大規模核反應堆仿真的實時可視化。汪岸等人[13]針對數值核反應堆數據的特點進行了論述,提出了數值計算大數據在多個領域的應用需求。
然而,關于材料數值計算大數據研究價值的認識仍然處于起步階段。另外,由于這些數值計算數據數目巨大、關聯復雜,以及考慮到其所具有的領域價值等因素,材料數值計算大數據存儲還沒有一個很好的解決方案。這是因為材料數值計算大數據的存儲要考量軟件類型、模擬行為、數據類型等多個維度的因素,這些數據既有獨立性又有相似性,而且還需要研究人員對相關的材料領域具有專業的認識。例如,國際原子能機構(International Atomic Energy Agency,IAEA)給出了一種材料數值計算大數據的存儲方案,該方案被用于收集世界各地的MD數值計算大數據,受到研究人員的廣泛關注。然而,面向多尺度模擬軟件的統一數據存儲方案目前仍然是個空白。本文針對材料多尺度數值計算大數據的特點,設計了一種適用于材料多尺度數值計算大數據的存儲與管理框架,并基于該數據庫框架,結合機器學習等算法,實現了其在改進材料多尺度模擬中的應用。
3 材料數值計算大數據的特點
由前面給出的材料數值計算大數據定義可知,材料數值計算大數據具有數目巨大、類型豐富、領域特殊性等特點。為了進一步說明,以反應堆壓力容器Fe基材料多尺度模擬為例,對材料輻照效應模擬軟件MISA-MD和MISA-SCD的模擬結果進行了統計(見表1),軟件均已開源。其中,MISA-MD用來模擬Fe基材料在原子尺度受到中子轟擊后產生的原子級聯碰撞過程,MISA-SCD用于更高空間尺度的模擬,即級聯碰撞后產生的材料微觀缺陷的演化過程。基于這兩個軟件的數值計算數據,概括材料數值計算大數據的特點如下。
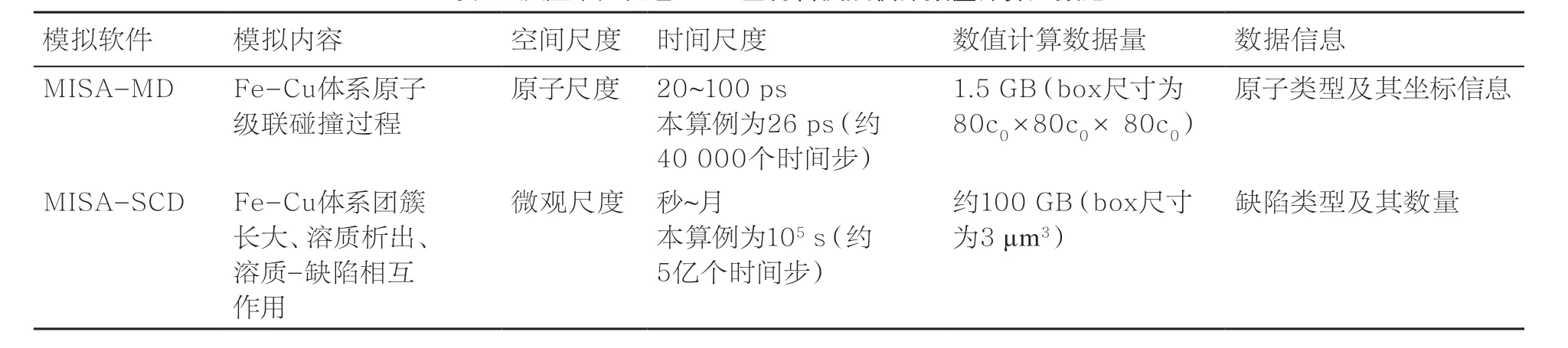
表1 反應堆壓力容器Fe基材料模擬軟件數值計算大數據
(1)數目巨大。材料輻照效應模擬軟件在模擬過程中會產生大量的數據,僅完成一次物理過程模擬的數據量就達到MB、GB甚至TB。本算例中MISA-MD選取的模擬時間為26 ps,約40000個時間步,box尺寸為80c0×80c0×80c0,其中c0為晶格常數。完成一次級聯碰撞演化過程模擬產生的數據量約1.5 GB。MISA-SCD選取的模擬時間為105s,約5億個時間步,box尺寸為3 μm3,完成一次團簇演化過程模擬產生的數據量約為100 GB。對于如此龐大的數據量,如果沒有一個合理的數據存儲體系,這些數據將很難被高效地存儲和分析。
(2)關聯性強。本例中MISA-MD與MISA-SCD的材料模擬過程是緊密關聯的,兩者分別被用來模擬不同尺度的缺陷演化。MISA-MD只能模擬原子尺度的級聯碰撞現象,要想進一步模擬后續缺陷演化現象,目前常采用的辦法是材料多尺度模擬,即將原子尺度的級聯碰撞數據傳遞給MISA-SCD軟件并作為初始輸入,然后才能進行更高尺度的模擬。因此,在材料多尺度模擬過程中,不同尺度軟件產生的數據是緊密關聯的。
(3)蘊含價值。材料數值計算大數據蘊含著材料演化過程的物理、化學信息,而非毫無意義的數據。MISA-MD產生的數值計算大數據包含了級聯碰撞后的原子種類和坐標,通過聚類等方法對這些數據進行識別,將相似的結構歸為一類,可以獲得級聯碰撞后的團簇種類和數量。而這些團簇的種類和數量可以作為初始輸入傳遞給MISA-SCD進行后續演化模擬。此外,由于隨機數的存在,材料輻照效應模擬往往具有一定的隨機性。通過對同一實驗條件下的模擬結果進行多次統計,獲得模擬次數與缺陷數量的關系,可以對MISA-MD的結果穩定性進行評估。獲得穩定的模擬結果是材料多尺度軟件間實現正確耦合的前提。
(4)類型豐富。根據物理過程、尺度的不同,材料可以有很多種類型。首先,同一尺度的軟件可以用來模擬不同的物理過程,從而得到不同的材料數值計算大數據。例如,MISA-MD可以被用來模擬不同合金原子級聯碰撞過程,也可以被用來模擬合金原子在晶界偏聚對晶界強化、脆化的作用,還可以被用來模擬液態合金系統在凝固過程中的空位形成特性等。其次,不同尺度軟件模擬得到的數值計算大數據也不同。例如MISA-MD得到的是原子類型及其坐標信息,而MISA-SCD得到的是原子團簇類型及其數量信息。數據類型不同給數據存儲方式的選擇帶來了挑戰。
(5)領域特殊性。由于空間尺度和時間尺度跨度很大,材料從原子尺度到宏觀性能預測的模擬過程并不是一個軟件能實現的。通常采用材料多尺度模擬的方法,使用不同的軟件來模擬不同尺度的材料演化過程,然后將這些多尺度軟件從低尺度到高尺度耦合起來,實現從原子尺度到微觀再到介觀甚至宏觀的模擬。除此之外,材料從設計到投入使用要經歷成分設計、微觀組織調控、工業測試、服役等多道工序,這決定了全周期的材料數值計算大數據具有時序性。因此,材料數值計算大數據具有多尺度、時序性等材料領域特殊性。
除上述特點,材料數值計算大數據還具有數值計算所帶來的不同于傳統大數據和實驗數據的特點。首先,材料數值計算大數據以數值類數據為主;其次,由于浮點運算的存在,材料數值計算大數據并非完全的精確數據;最后,并行執行的非確定性、隨機的非確定性以及離散的非確定性導致材料數值計算大數據中帶有非確定性的數據。這些特點為材料數值計算大數據的研究、管理和分析帶來了傳統大數據不曾面臨的挑戰。
4 材料數值計算大數據存儲體系
為了有效收集、利用材料輻照效應模擬過程中產生的數值計算大數據,需要解決材料數值計算大數據的采集、存儲與管理、處理與分析以及隱私和安全等大數據技術問題。本文提出了一種適用于材料數值計算的數值計算大數據存儲體系(numerical calculation data storage architecture,NDSA)。該體系涵蓋包含不同尺度軟件的數值計算大數據,主要有MD、KMC(kinetic Monte Carlo)、SCD等主要數據庫。這里所用的軟件為北京科技大學與中國原子能科學研究院聯合自主研發的材料輻照效應多尺度模擬軟件,包括分子動力學軟件MISA-MD、動力學蒙特卡洛模擬軟件MISA-AKMC、隨機團簇動力學軟件MISA-SCD。目前這幾款軟件均已實現開源。
在數據庫組織上,按照不同尺度的模擬軟件進行組織。每個模擬尺度的數值計算大數據庫中還包含程序模擬的多個生命周期的數據,如軟件輸入參數集合、模擬結果、模擬分析結果等。通過這樣的兩層組織,形成了多尺度模擬軟件的大數據體系,形成了雙重維度(材料多尺度模擬維度和數值計算生命周期維度)的數據關聯存儲。由于在模擬中,有時候參數(如合金的比例)是不定的,且隨著模擬的增加,數據也會大量增加,數據庫需具備高擴展性。此外,材料數值計算大數據的結構大多不固定。MongoDB框架可以為Web應用提供可擴展的高性能數據存儲,其文檔類似于JSON對象,在使用時也更加靈活。對于模擬的結果數據文件,由于其數量很大,如果存放在數據庫中,可能會導致數據庫冗雜和效率降低,因此,這些文件采用文件存儲服務進行管理。文件存儲采用分布式對象存儲MinIO技術方案,該技術方案具有可靠性(糾刪碼機制自動容錯)、高可用性(在一半節點宕機時仍可保證服務可用)、可擴展性強(由于分布式特點,大數據量下可擴展至多個節點)等優點,比文件系統更可靠,便于文件的管理與遷移。使用對象存儲技術為數值計算大數據管理帶來很大的便捷性,在獲取一個文件時不需要提供文件在文件系統中的具體位置,而是通過請求對象存儲服務獲得一個統一資源定位符(uniform resorce locator,URL)。其多節點的特性使得數據的安全與訪問速度得到保障,扁平結構便于快速地獲取數據。其彈性擴容特性使得在后期對其進行擴容變得更方便。MinIO方案專為性能和S3 API設計,非常適用于對安全性有嚴格要求的大型私有云環境。下面以MD為例,對材料數值計算大數據存儲與管理技術進行介紹。
MD數據庫共包括5個集合,即輸入參數集合simulation、結果數據集合output_file、一次模擬后處理的集合analysis、多次模擬后處理的集合multi analysis和MD作業運行的集合job。各集合之間的關聯關系如圖2所示。output_file集合及analysis集合分別見表2和表3。
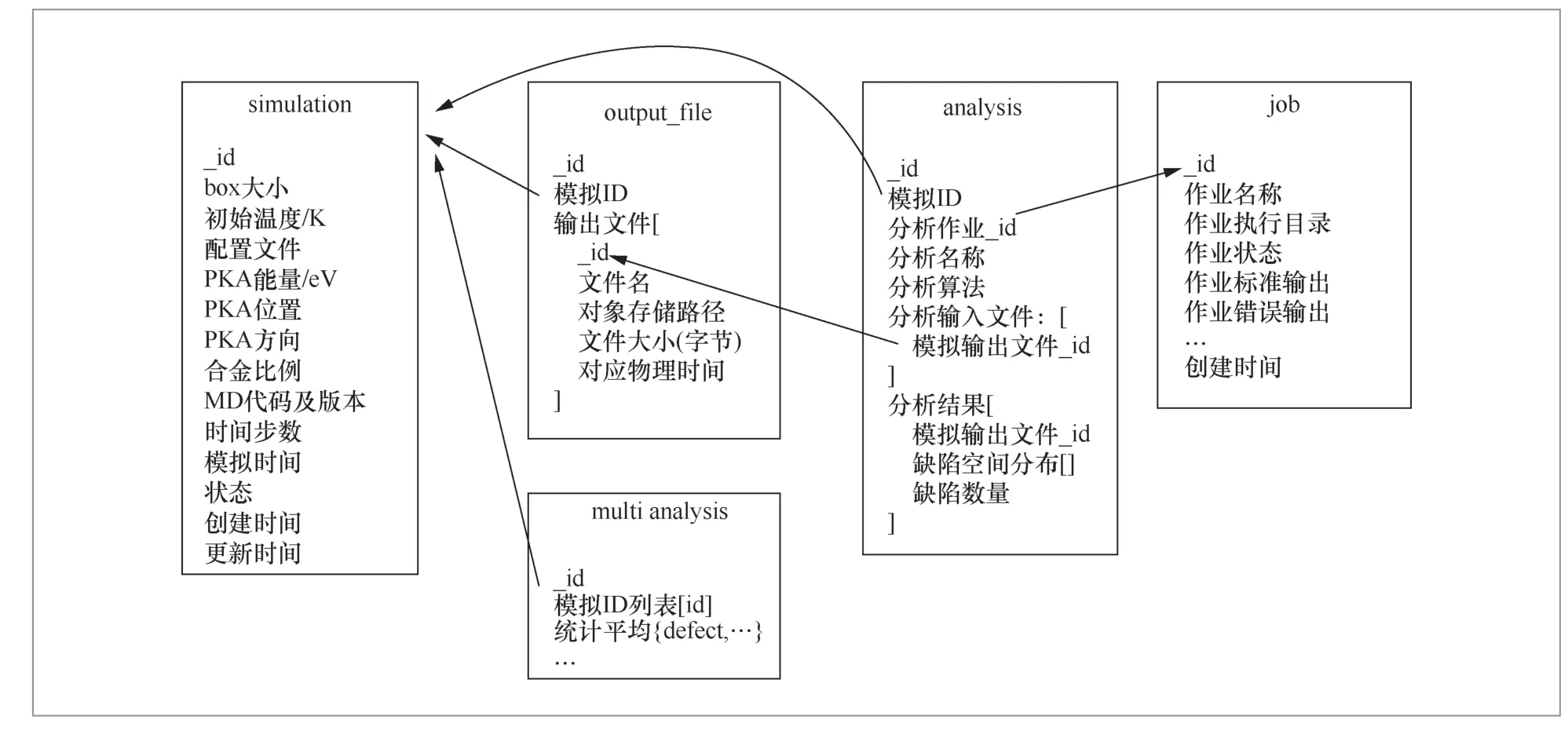
圖2 MD數值計算大數據存儲結構設計

表2 output_file集合

表3 analysis集合
采用以上數據存儲與管理技術,可以將不同尺度的數值計算大數據存入數據庫,形成完整的材料輻照效應多尺度數值計算大數據庫。該數據庫具有高擴展性。數據庫中保存的各尺度軟件的參數、結果、后處理等數據,可用于機器學習及多尺度模型改進等后續相關研究。
以一次analysis集合為例,向analysis集合插入一條“結果后處理分析”文檔的語法如下:


5 基于多尺度數值計算大數據的挖掘分析
為了更好地理解材料數值計算大數據的價值,本節以典型核反應堆壓力容器材料Fe-1.5%wtCu合金的兩個分子動力學模擬實例加以說明。本實例所用的軟件為材料輻照效應分子動力學模擬軟件MISA-MD,該軟件能夠模擬的粒子數規模達到4×1012,為目前國內外能夠模擬的第二大規模的分子動力學軟件[14-15]。在“天河二號”的英特爾平臺上,與LAMMPS軟件包相比,MISA-MD的內存占用僅為前者的40%[5]。目前該款軟件已經完成開源。
5.1 基于XGBoost算法的Frenkel缺陷對數預測
在對相同宏觀參數下的原子體系進行多次MD級聯碰撞模擬時,首先需通過隨機數種子對所有粒子的速度大小和方向進行初始化,根據麥克斯韋速度分布定律可知,對于同一宏觀條件的粒子體系,各個粒子的狀態是時刻變化的。因此,每一次模擬需使用不同的隨機數種子,使得該宏觀參數下體系的多種粒子微觀狀態可以得到充分考慮。在所有宏觀參數一致的情況下,級聯碰撞模擬得到的Frenkel缺陷的數目并非完全相同,而是在一定范圍內波動。過去的做法通常需要多次執行同一宏觀條件下的模擬然后取平均,例如,對于1000×1000×1000的box,使用32個節點,共512個核,每次模擬程序都需要運行2~5 h,且獲得模擬結果后,還需要使用最短距離標記法獲取缺陷的信息,整個流程不僅耗費超算計算資源,而且時間跨度也長。本文基于MD數值計算大數據中的Frenkel缺陷提出一種更高效的Frenkel缺陷對計算方法。
本文采用機器學習中的集成學習來實現上述功能,集成學習通過構建結合多個學習器來完成學習任務,最后的結果由多個學習器共同決定。本文選取的算法是XGBoost[16],它將許多樹模型集成在一起,由這些樹模型共同決定結果。
首先使用XGBoost訓練所有MISAMD模擬的數據,使用訓練完的模型對未知的模擬進行缺陷對數預測。每次模擬中的box大小、晶格常數以及合金比例都為固定值,而在這些模擬之間,只有能量、入射角度、隨機數、時間步長這些參數是不同的,因此將這些參數組合成特征向量,以[能量,x,y,z, 隨機數, 時間步長]的形式。基于上述方法,對多組數據進行預測,并將其與真實值進行比較,缺陷對預測值與真實值對比見表4。由表4可知,預測值與真實值很接近,這驗證了該方法的有效性。
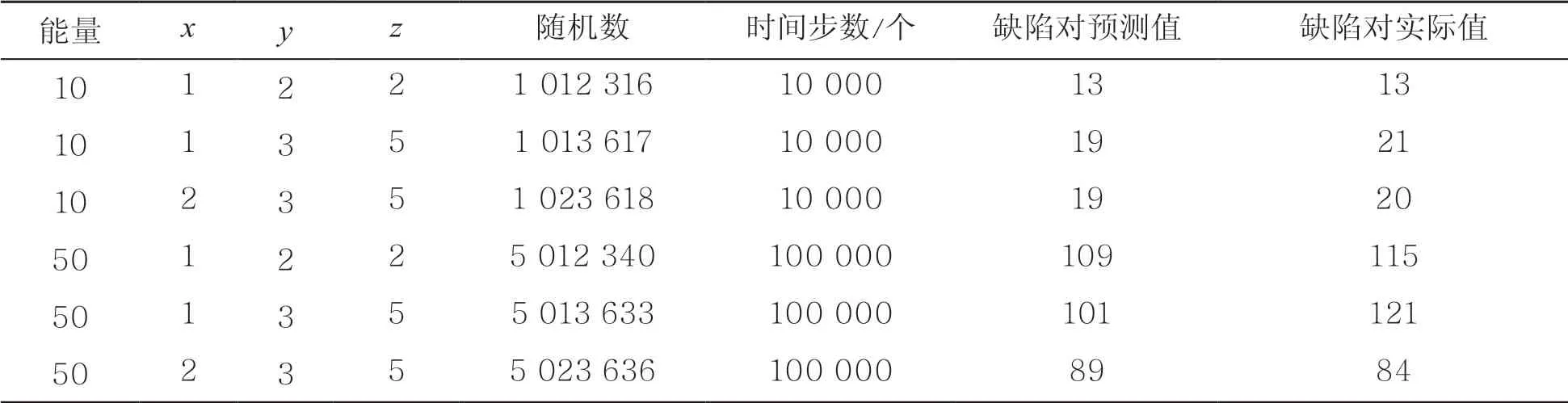
表4 缺陷對預測值與真實值
5.2 基于并查集算法的級聯碰撞團簇劃分方法
級聯碰撞模擬后,由于能量粒子的撞擊,材料原子離開原本的晶格位置,從而發生移位,而后進一步演化發生聚集或湮滅,形成原子或空位團簇。團簇過多或過大會使得材料力學性能產生降級,從而威脅反應堆設施的安全,例如形成空洞。基于MD數值計算大數據庫中的.dump數據,采用并查集算法,可以實現對團簇的有效劃分。
數據集采用的晶體結構均為體心立方晶體(BCC),元素都是鐵(Fe)元素,晶格常數為2.85532,box大小均為[80, 80, 80],它的含義是x、y、z方向上都是80倍的晶格常數,即80個晶格點。實驗環境在600 K的溫度下,根據入射中子能量的不同,時間步數有10000個和100000個兩種,總的時間步數有41000個和131000個兩種。MISA-MD運行時,每隔1000個時間步輸出一個結果,這里選取最后一個時間步的結果。每個時間步的結果數據都是.dump坐標數據,里面包含1024000個原子坐標。
在上述實驗環境下,數據涵蓋不同能量、不同角度,且每種能量每種角度都進行了多次模擬。數據包括從10 keV、30 keV、50 keV 3種不同的能量,角度分為122、135、235這3個方向,每種都進行了50次模擬,最終有450次模擬數據。
常規做法是將每個缺陷看成一個單缺陷的團簇,然后遍歷其他所有缺陷,將指定距離內的缺陷加入該團簇,進行缺陷的合并。這看起來并不復雜,但是當數據量大時,若采用常規方法來解決,往往時間復雜度過大,因為它需要反復查找一個缺陷所在的團簇,導致不能很好地解決該問題。因此在這里采用并查集算法來解決。并查集 采用一種樹形數據結構來處理這種不相交集合的問題。并查集算法有兩種操作:合并(把兩個不相交的集合合并為一個集合)、查詢(查詢兩個元素是否在同一個集合)。將所有元素合并完之后,森林中有幾棵樹,就有幾種集合。因為并查集的數據結構為樹形,所以樹的高度越高,時間復雜度也越高。這里選取的是優化的并查集算法。
如偽代碼1所示,首先設置一個大小與缺陷總數相同的根節點數組root,它的含義為該缺陷所屬團簇的編號,初始時,每個缺陷被視為單獨的一個團簇,因此初始數組的值為自身編號。再設置一個大小與缺陷總數相同的數組height,它表示以當前節點為根節點的樹的高度,因為初始時每個缺陷都是一個團簇,也就是一棵樹,所以初始時樹的高度都為1。接下來計算任意兩個缺陷之間的距離,在計算的過程中需要判斷這兩種缺陷的類型。如果這兩個缺陷都是間隙原子或者一個是間隙原子、一個是空位,且它們的距離在一倍晶格常數(第二近鄰)內,就認為它們屬于同一個團簇;如果兩個缺陷都是空位,且它們的距離在倍晶格常數(第三近鄰)內,就認為它們屬于一個團簇。如圖 3所示,此時缺陷2和缺陷9在距離閾值內,第一步先查找兩個缺陷的根節點,在查找的過程中,將向上經過的所有缺陷的根節點都設為最上層那個缺陷,也就是都直接接到根節點上,這被稱為路徑壓縮,可以減少樹的高度,使得以后向上查找根節點時速度更快。獲取根節點后,根據height數組判斷兩個根節點的樹的高度,將高度小的樹接到高度大的樹上,如果樹高一樣,則任意將一棵樹接到另一棵樹上作為孩子節點。遍歷根節點數組,若根節點相同的缺陷為一棵樹上的,則將根節點相同的缺陷劃分到一個團簇中,從而獲取缺陷可以劃分的所有團簇。將獲得的所有團簇信息(包括團簇中缺陷坐標、缺陷對數、缺陷類型(間隙或者空位)等)存儲到團簇數據庫中,最初獲得了4483個團簇。
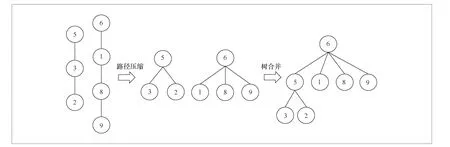
圖3 并查集算例演示
偽代碼1 使用優化的并查集劃分團簇


5.3 基于聚類算法的KMC長程演化類環狀原子簇發現
通過對數值計算大數據庫中的MISAKMC長程演化團簇數據進行分析,發現了材料輻照效應中的類環狀團簇。選取的特征向量為缺陷團簇中各缺陷與幾何中心的距離,以及每兩個缺陷與幾何中心形成的夾角。考慮到幾何形狀經旋轉、放大及縮小后,形狀仍然是相同的,這里每隔5°形成一維數據,共36維數據;對于距離,每次將所有距離除以當前團簇的最大值,進行歸一化處理,每隔0.025形成一維數據,共40維數據,因此特征向量包含76維數據,如圖4所示。選取HDBSCAN(hierarchical density-based spatial clustering of applications with noise)聚類算法對團簇進行識別。它是一種基于密度聚類的無監督的聚類算法,不需要已經標記的數據,也無須事先知道要劃分的類別數。它可以對不同密度的團簇進行聚類,可以忽略噪聲,且效率較高。團簇聚類的結果如圖5所示。從圖5可以看到,將所有的缺陷團簇分為幾種不同的類別,每種顏色代表一種類別,每種類別的團簇的幾何形狀相同或相近。基于該方法,筆者在KMC長程演化數據中發現了一些類環狀的團簇,如圖6所示,這一發現驗證了之前報道的材料輻照實驗中缺陷團簇的出現[17-18]。
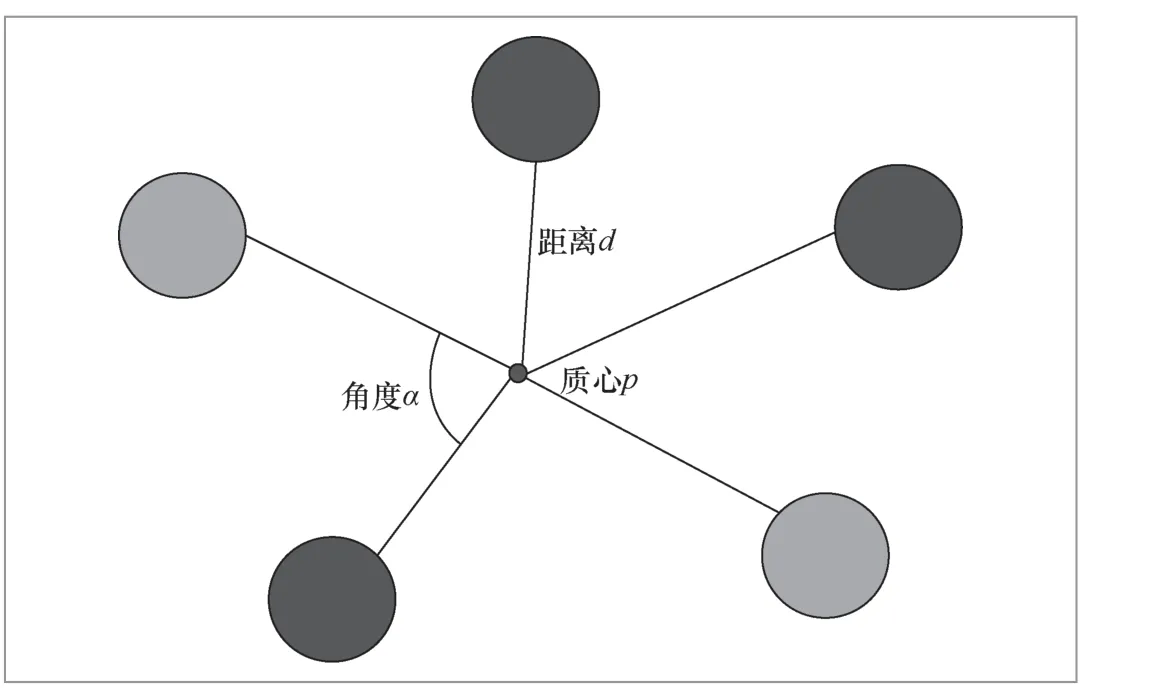
圖4 團簇特征提取方法
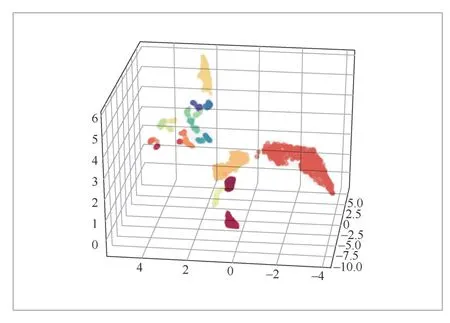
圖5 團簇識別結果
圖6 KMC長程演化產生的類環狀團簇識別結果
5.4 基于神經網絡的勢函數模型AIPM
勢函數計算是材料多尺度模擬關鍵的一環,MD和KMC中粒子速度、位置的更新,以及SCD中多元組分材料參數的計算,均離不開勢函數模型。過去常用的勢函數模型通常包含兩種,一種基于第一性原理,另一種基于經驗函數。前者往往計算復雜,且對于多元組分而言,第一性原理勢函數的構建過程非常復雜;后者雖然在效率上有所提高,但精度往往不夠,而對多元合金組分的經驗勢函數構建過程則更加困難。
針對上述問題,基于第一性原理數值計算大數據,提出了一種基于機器學習的方法對原子體系模擬參數及勢能之間進行擬合的勢函數模型AIPM(artificial intelligence based potential model)。這里選取Fe-Cu二元合金體系,基于原子坐標進行機器學習模型的特征提取,如圖7所示。首先按照最近鄰法對原子鄰域進行劃分,并以該原子為中心,建立局域坐標系,第一近鄰和第二近鄰分別設置為x、y坐標,二者的向量積作為z坐標,于是可以得到每個原子的坐標,將這些坐標作為神經網絡的輸入。這里選取3層神經網絡的結構,如圖8所示,每層的節點數依次為15、10、6,擬合得到體系內一個原子的勢能,然后針對其他原子采用相同的方案進行擬合,最后將所有的原子的勢能求和,即可得到總的原子體系的勢能。將這一勢能與數據庫中給定的經典勢能——EAM勢能進行比較,以驗證模型的精度。采用AIPM模型對1000個粒子大小的Fe-Cu原子體系勢能進行計算,驗證了AIPM的可靠性。Fe-Cu原子體系神經網絡計算結果見表5。
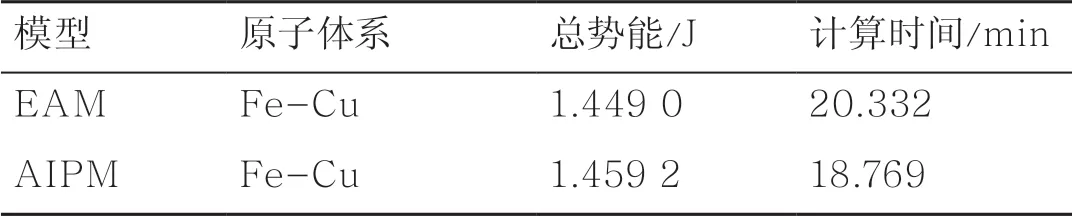
表5 Fe-Cu原子體系神經網絡計算結果
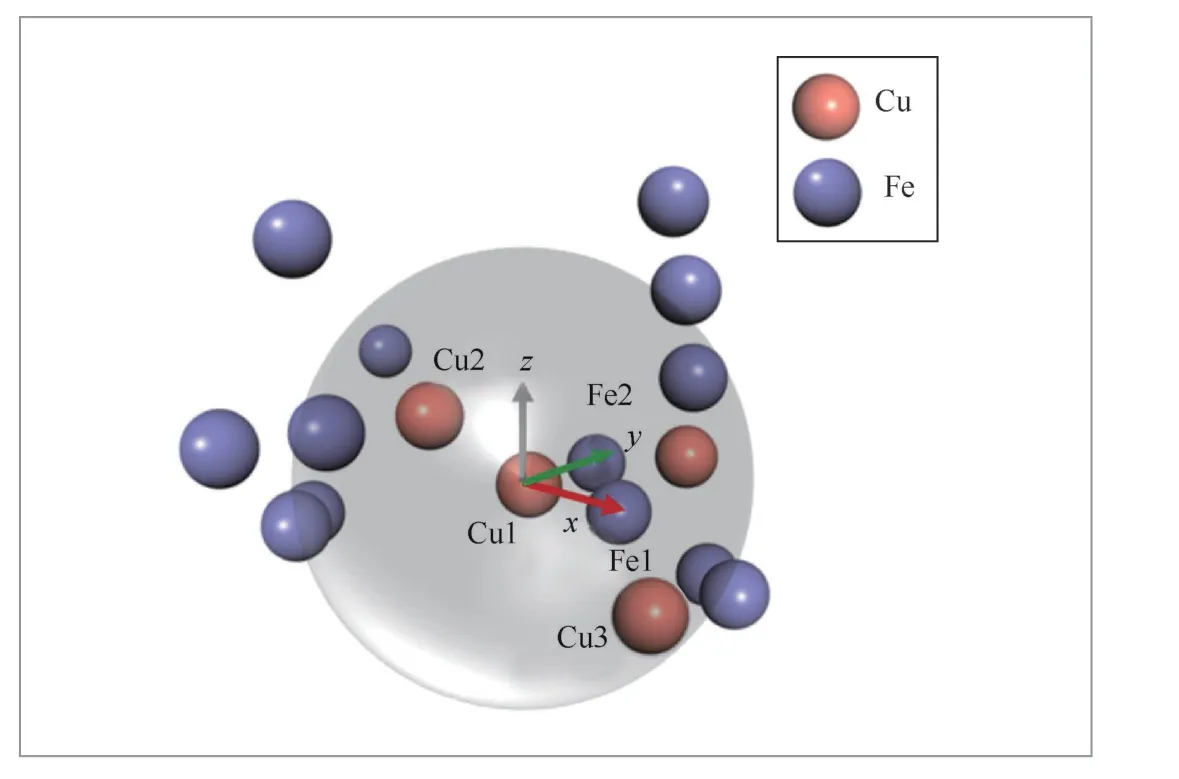
圖7 局域坐標系的建立方法
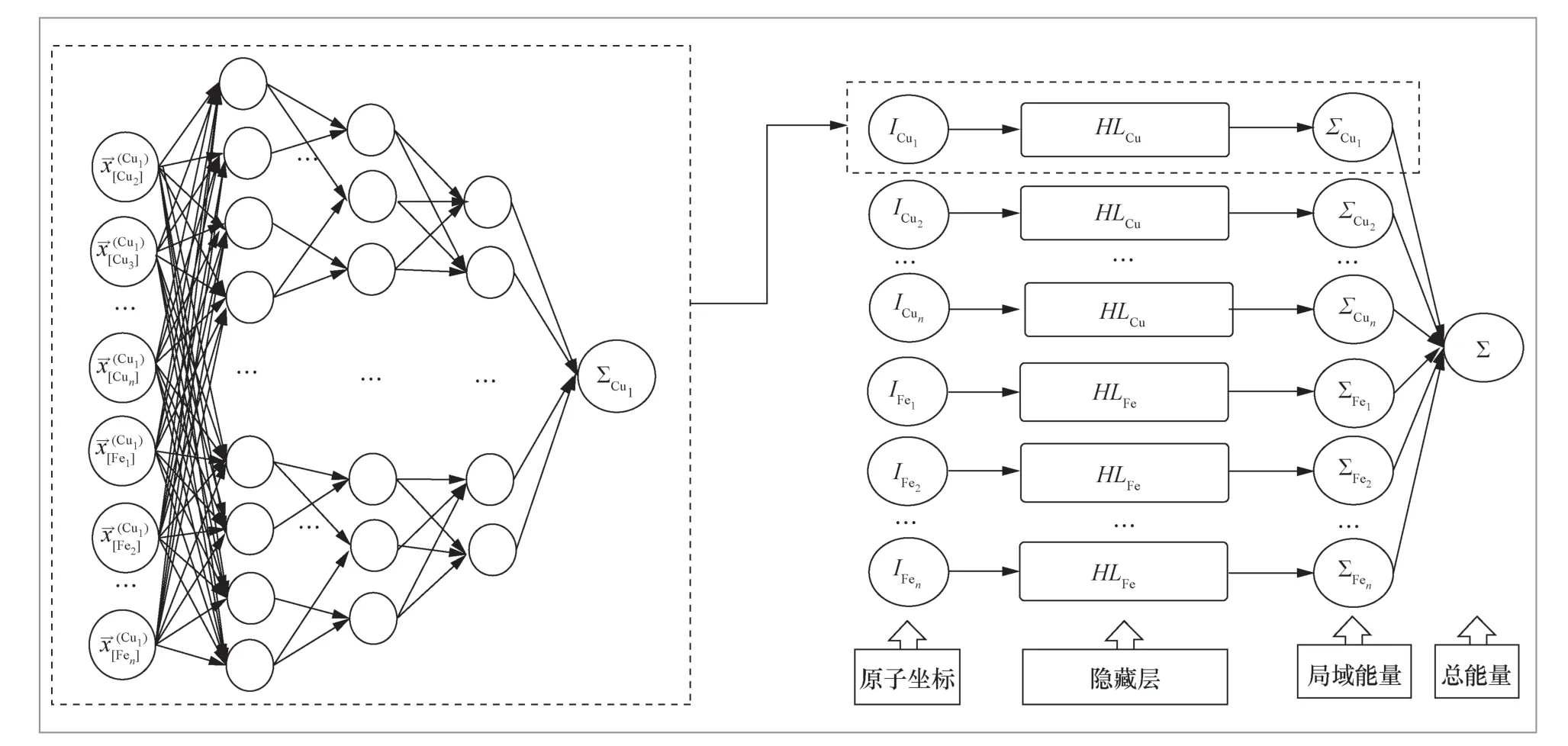
圖8 Fe-Cu原子體系神經網絡構建過程
6 結束語
本文首次提出了材料數值計算大數據的概念,闡述了材料數值計算大數據的特點及研究意義,提出了一種適用于材料數值計算的數值計算大數據存儲體系,并基于該數據體系,在Frenkel缺陷對計算、MD中的缺陷團簇劃分、類環狀團簇發現以及勢函數模型構建等多個方面取得了進展。盡管數值計算大數據很早就出現在研究工作中,但系統性的研究仍處于起步階段。隨著數值計算的規模越來越大以及技術上的瓶頸越來越多,數值計算大數據的研究在材料多尺度模擬研究中起到了越來越重要的作用,其價值有待進一步挖掘,尤其在改進物理模型和軟件耦合方面,數值計算大數據將成為突破多尺度模擬難點和挑戰的重要途徑和手段。
