水環境模型與大數據技術融合研究
2021-11-22 02:01:04馬金鋒饒凱鋒李若男張京鄭華
大數據 2021年6期
馬金鋒,饒凱鋒,李若男,2,張京,鄭華,2
1.中國科學院生態環境研究中心城市與區域生態國家重點實驗室,北京 100085;2.中國科學院大學,北京 100049
1 引言
模型是集成和綜合不同觀測數據、理解復雜的交互作用和測試假設,以及模擬歷史、預測未來系統發展軌跡和決策如何應對未來趨勢的重要工具[1]。根據產生的來源,模型大體可被分為數據驅動和模型驅動兩類,數據驅動模型(機理模型)基于關聯關系構建,模型驅動模型(機理模型)基于因果關系構建。數據驅動模型是大數據價值體現鏈條中的重要環節,大數據的核心價值在于尋求或構建合適的模型,利用模型表達事物內在變化規律的過程。在大數據的原生定義中,基于事物之間的關聯關系尋求和構建模型,模型構建的成敗十分依賴數據的數量和質量。此外,由于數據驅動模型是基于關聯關系構建的,其模擬結果無法給予合理解釋,導致其認可度不高,因此數據驅動模型通常也被稱為“黑箱模型”[2]。目前在水環境領域中,由于可用數據數量少、數據質量低等原因,基于大數據技術成功構建的數據驅動模型案例并不多,總體上處于探索和發展階段。相比數據驅動模型,水環境領域中的機理模型相對成熟和完善,得到廣泛的推廣和應用。然而,在大數據環境下,如何從新的視角審視已成熟的機理模型,探索其在大數據技術背景下的價值發揮是一個值得探討的熱點問題。
顧名思義,機理模型從因果關系出發尋找規律,是真實水環境系統的抽象和概化。水環境機理模型是對水體中污染物隨空間和時間遷移的轉化規律的描述,是一個描述物質在水環境中的混合、遷移過程的數學方程,即描述水體中污染物與時間、空間的定量關系[3]。基于微分方程的水環境機理模型在過去的數十年間取得了極大發展,已經成為水資源及環境管理決策的有力工具。相對于數據驅動模型而言,機理模型除了具備模擬結果可解釋、廣泛認同和成熟應用的特點,還可以通過開源或者商業的方式獲取,即模型的可獲得性,這是機理模型區別于數據驅動模型的一個明顯特點。數據驅動模型需要耗費大量計算資源來訓練和構建,其核心在于如何創建模型;機理模型經過幾十年的發展,已相對成熟和完善,其核心在于如何應用模型。相對于數據驅動模型而言,機理模型的可獲得性、模擬結果的可解釋性、科學界廣泛的認同和實際中已有的成熟應用等特點共同決定了深度挖掘機理模型的應用潛力和充分發揮其應用價值是未來研究的重點方向。
在實際應用過程中,機理模型普遍面臨大規模情景運算、模擬結果海量存儲和高效分析的難題,這極大地限制了模型的推廣和應用,因此,迫切需要探索新的技術和方法來解決這些難題。大數據技術在解決上述難題方面具有潛在優勢,研究水環境模型融合大數據技術能否解決和如何解決上述難題是目前面臨的一個挑戰。本文以水環境模型為例,分析了該模型在實際應用中面臨的瓶頸;針對這些瓶頸,分別從規模計算、規模存儲和應用分析3個角度,提出了大數據技術與機理模型融合的技術思路,闡述了水環境模型與大數據技術融合的實現流程,以SWAT(soil and water assessment tool)模型率定為應用案例證明了框架的可行性;最后討論了水環境模型在大數據背景下未來的研究方向。
2 水環境模型應用過程中面臨的瓶頸
眾所周知,基礎數據難以獲取以及模型率定、模型驗證和場景分析中的高負荷計算是限制模型成功應用的主要瓶頸,如圖1所示。水環境模型構建要求有足夠的基礎數據用于建模、校準和驗證。基礎數據(如地形、風速、外部污染負荷、流入、流出和開邊界條件等)主要作為模型輸入,也可為校準模型參數提供依據,評估模型是否能充分描述水體特點。模型需要的數據應盡量準確,數據的局限性會限制模型的應用,數據的質量和數量在很大程度上決定了模型應用的質量。實際上,能夠獲取的數據往往很少,精準的長期監測是解決數據匱乏的主要途徑。此外,理論和經驗方法也經常用于彌補數據的欠缺[4]。

圖1 水環境模型應用過程中面臨的瓶頸及潛在解決方案
模型的核心價值在于對現實世界歷史的重現、對未來的預測和對未來優化決策的響應。模型的率定反映了對歷史的還原能力。由于水環境數值模型是對真實水環境系統的抽象和概化,模型的參數、輸入數據和模型結構均存在不確定性。為了更加客觀地反映自然水體中的一系列生化、生物反應過程,基于機理的數值模型在開發過程中不可避免地會引入大量參數。受監測資料和對復雜生態過程認知的限制,模型參數的率定往往存在較大困難,使得模型率定成為一個長期的研究方向[5-6]。與此同時,大量的應用不斷促進水環境模型的發展,模型變得日益復雜,需要考慮和包含更多的反應過程,增大了模型率定的難度。模型率定是一個嚴重依賴高性能計算的迭代過程,不同參數組合需要執行不同的獨立計算。為了對所有參數組合場景進行統一分析處理,需要對所有獨立計算的結果進行統一存儲和分析。參數率定、模型驗證以及情景分析等都依賴于大規模計算的支持[7]。在目前的實際應用過程中,由于計算規模大,單機多處理器模式和集群并行系統[8]并不能滿足上述需求,因此需要探索新的應用模式。大數據技術在支撐規模運算、海量存儲和高效分析方面具有顯著優勢,有望解決上述模型應用中面臨的困境。
3 水環境模型與大數據技術融合框架
水環境模型與大數據技術融合體現在分布式計算、存儲和分析3個方面,如圖2所示。針對分布式計算,機理模型與大數據融合體現在模型如何適應分布式并行計算以實現高性能計算。谷歌公司在2004年公開的MapReduce分布式并行計算技術是新型分布式計算技術的代表。典型的MapReduce系統由廉價的通用服務器構成,通過添加服務器節點可線性擴展系統的總處理能力,在成本和可擴展性上都有巨大的優勢。造成大數據挖掘革命的技術之一是Hadoop平臺上的MapReduce編程模型,其用于在對硬件要求不太高的通用硬件計算機上構建大型集群,從而運行應用程序[9]。除了MapReduce,還有其他分布式計算框架,比如內存迭代計算框架Spark和流式計算框架Storm等。MapReduce屬于離線式批量計算框架,鑒于數值模型具有CPU密集型計算的特點,該模型適合采用MapReduce框架。對于計算結果的交互式查詢分析,則適合采用Spark框架[8]。大數據計算框架與機理模型融合的核心在于將批量模型算例文件分發到計算節點,模型計算程序定位算例文件所在節點,啟動計算程序執行計算。

圖2 水環境模型與大數據技術融合框架
針對模型模擬結果海量存儲,機理模型與大數據融合體現在模型結果(包括原始結果和解析結果)如何實現高效持久化存儲。在存儲方面,2006年谷歌提出的文件系統GFS以及隨后的Hadoop分布式文件系統(Hadoop distributed file system,HDFS)奠定了大數據存儲技術的基礎。與傳統存儲系統相比,GFS和HDFS將計算和存儲節點在物理上結合在一起,從而避免在數據密集計算中易形成的I/O吞吐量的制約。同時這類分布式存儲系統的文件系統也采用了分布式架構,可以達到較高的并發訪問能力。GFS和HDFS屬于底層的文件存儲模式,為了支持非結構化數據存儲,BigTable和HBase誕生了。其中,HBase是一個針對結構化數據的可伸縮、高可靠、高性能、分布式和面向列的動態模式數據庫。和傳統關系數據庫不同,HBase采用BigTable的數據模型,即增強的稀疏排序映射表(key/value),其中,鍵由行關鍵字、列關鍵字和時間戳構成。HBase提供了對大規模數據的隨機、實時讀寫訪問,同時可以使用MapReduce來處理其保存的數據,它將數據存儲和并行計算完美地結合在一起[10]。也就是說,HDFS為HBase提供了高可靠性的底層存儲支持,MapReduce為HBase提供了高性能的計算能力。除了HBase,還有其他存儲框架,比如ElasticSearch、Cassandra、Redis、MongDB等。MapReduce和HBase都是Hadoop生態系統的核心組件,各組件間密切結合的設計原理的一大優點是能夠構建出無縫整合的不同處理模型的應用[11]。鑒于此,適合采用HBase存儲模擬結果解析后的結構化數據(記錄集)和非結構化數據(圖片集)。大數據存儲框架與機理模型融合的核心在于將分布于各個計算節點的模型計算原始結果文件和解析后的數據記錄并發寫入持久化存儲設備。
針對模型模擬結果挖掘分析,機理模型與大數據融合體現在對模型結果的快速提取及挖掘分析。在數據分析方面,首先要求數據處理速度足夠快,速度快意味著可以滿足交互式查詢的需求;其次,要求剝離對集群本身的關注,不需要關注如何在分布式系統上編程,也不需要過多關注網絡通信和程序容錯性,只需要專注于滿足不同應用場景下的需求;最后,要求支持通用的交互式查詢、機器學習、圖計算等不同運算,且能通過一個統一的框架支持這些計算,從而簡單、低耗地把各種處理流程整合在一起,這樣的組合在實際的數據分析過程中很有意義,減輕了對各種分析平臺分別管理的負擔。Spark是滿足上述需求的一個快速大數據分析框架。Spark于2009年誕生于加州大學伯克利分校RAD實驗室,其一開始就是為交互式查詢和迭代算法設計的,同時支持內存式存儲和高效的容錯機制。Spark支持在內存中進行計算,因而具有快速的處理速度,支持交互式查詢。Spark包含多個緊密集成的組件,比如Core(任務調度、內存管理、錯誤恢復、存儲交互)、SQL(操作結構化數據)、Streaming(實時計算)、MLib(機器學習算法庫)、GraphX(圖計算庫)等,各組件間密切結合,支持各種各樣的應用需求。和HBase一樣,Spark也是Hadoop生態系統中的核心組件之一。鑒于此,適合采用Spark框架對模擬結果進行進一步分析,典型應用功能包括交互式查詢、模型參數敏感性分析、模型率定、模型驗證、模型預測和應用決策。大數據分析框架與機理模型融合的核心在于快速提取分布于多個存儲節點上的模擬結果,組織成物理上分散、邏輯上統一的結構化數據格式,依托已有算法庫進行數據分析。
4 水環境模型與大數據技術融合的技術思路
下面分別從水環境模型的規模計算、規模存儲和應用分析角度,闡述實現融合框架的技術思路,具體如圖3所示。

圖3 水環境模型與大數據技術融合的技術思路
4.1 水環境模型的規模計算
參考文獻[9]最早采用Hadoop1.0開展水環境模型和大數據計算框架融合的研究,通過將SWAT模型率定和不確定性分析中的規模運算分解到map和reduce過程,為解決水文建模中的計算需求問題提供了一種有效方法。受此啟發,參考文獻[8]等提出一種僅使用map過程的改進方法,基于Hadoop2.0實現水動力水質模型Delft3D的集群運算架構。該架構不使用shuffle過程,提高了計算運行效率,為解決水環境模擬規模計算問題提供了新的視角。上述兩者指明了在統一平臺內耦合數值模型和計算框架的方法,即MapReduce模式下,模型作為第三方可執行程序被批量調用,map負責分布式計算,reduce負責匯總結果。
水環境模型具有其內在特點:一方面,包括流域分布式水文模型SWAT和三維水動力水質模型Delft3D在內的水環境數值模擬模型等,通常屬于CPU密集型計算,運行時間范圍為幾分鐘到幾小時,甚至到幾天。這和MapReduce的設計目標相符[12];另一方面,成熟的機理模型通常基于服務于科學計算的FORTRAN語言編寫,大數據計算框架往往基于Java語言編寫,兩套語言混合編程需要付出極大的開發成本,在實踐中應該發揮各自語言的特色,控制或降低融合成本。綜上所述,機理模型與大數據計算框架融合的思路是將機理模型作為獨立的第三方可執行程序被計算框架調用,所有計算任務之間相互獨立,不發生交互。
從實現角度,為了提高模型計算速度,通常需要保障獨立的計算核和足夠的內存。不論是Hadoop1.x中的JobTracker還是Hadoop2.x中的MRAppMaster都有整體計算資源的管理機制,都可根據應用需求動態調配內存和計算核。目前,YARN被證明是一個有效的資源管理工具,而且和MapReduce一樣同屬Hadoop生態圈,這方便了模型計算資源的調配。完成資源調配后,進入模型運行環節,這是模型和計算框架融合的核心,此環節主要包括模型啟動、狀態追蹤以及管理交互(暫停、繼續、中止和重啟等)。典型的Hadoop集群通常運行在Linux操作系統下,因此,模型引擎首先需要在Linux操作系統下編譯才能被使用;其次,模型在運行之前,需在集群中能夠被獲取;最后,在本地節點中模型被調用進而觸發執行過程。
本質上,模型作為第三方程序,通常不能將執行狀況告知節點,因此需要構建一套反饋機制以發送狀態給用戶。詳細的狀態信息應該包括兩部分,即模型自身運行狀態和任務運行狀態,用戶獲取到這些信息后會決定是否干預運行狀態。
綜上所述,模型和大數據計算框架融合的核心在于發揮計算框架的優勢,為模型的規模計算提供一種理想的方法。在具體的融合過程中,首先,依賴計算框架的資源調配機制,確保滿足模型對計算資源的需求;其次,依賴計算框架的編程模型,確保批量計算數據被分發,計算程序在分布式節點上可獲取、可調用和狀態可追蹤。
4.2 水環境模型模擬結果規模存儲
數據的持久化是一個非常重要的過程,存儲結構的設計決定了后續數據處理和分析的效率。當模型計算完成時,模擬結果存儲過程隨之啟動。為了實現高效持久化,結果文件一般以二進制格式存儲。不同的模型有不同的存儲格式,比如Delft3D的NEFIS格式、MIKE的dfs2格式等,因此需要不同的解析方法,以便提取重點關注的信息并將其寫入存儲介質。一般來說,模型說明文檔提供了相應的文件結構。根據此結構,可以設計合適的存儲結構。文件和數據庫是兩種比較常見的存儲模式。由于計算會耗費大量時間,原始結果文件顯得彌足珍貴,采用分布式文件存儲系統來存儲原始結果文件成為一種合理選擇。HDFS內置的可擴展、冗余、容錯機制確保了原始數據的可靠性和高可用性,使其成為一種較佳的選擇。其他選擇還有使用同樣廣泛的FastDFS,具體采用哪種存儲系統,需要結合計算框架和分析框架,從能否無縫結合的角度進行綜合考慮。
通常情況下,原始結果文件不能被直接使用,實際應用中需要借助專業的后處理工具。結構化的表結構是廣泛應用的一種形式。因此,通常需要將原始結果集進行解析和提取,形成結構化數據集。根據水環境管理領域特點,這種結構化數據集是一種典型的時間序列數據集。因此,在存儲階段,除了需要關注規模化的并行寫入,還要兼顧數據本身的時間序列特點。分布式列式數據庫在海量數據并行寫入方面具有優勢,但是考慮到數據本身的時間特性,時間序列數據庫是一個合適的選擇,而且其存儲框架和計算框架還能屬于同一個生態系統。不幸的是,在Hadoop生態系統中,在存儲方面除了擴展HBase的OpenTSDB,沒有單獨提供時間序列數據庫。即使OpenTSDB提供對時間序列存儲的支持,通過對HBase的存儲模式和行鍵同時進行優化設計,也能夠獲得優于OpenTSDB的讀寫性能。此外,其他選擇還有InfluxDB、RRDtool、Graphite和ElasticSearch等數據庫。因此,對于模擬結果存儲,有很多的選擇。盡管如此,不論采用何種數據庫,都需要慎重考慮存儲結構設計和主鍵設計,二者共同決定了后文中應用分析的效率。
綜上所述,模型和大數據存儲框架融合的核心在于選擇合適的模型計算結果持久化框架。在具體融合過程中,持久化存儲需要兼顧原始結果和解析記錄兩種不同格式。首先,需要判斷位于多個計算節點上的計算程序是否運行結束;其次,節點上的計算完成后,在本地節點上連接并寫入存儲框架,實現多節點并發存儲。
4.3 水環境模型模擬結果應用分析
模型結果分析依賴兩部分:結果集的獲取、基于數據之上的算法以及交互模式。在上述模型與存儲融合中,數據以分布式文件和數據庫的形式存儲,推薦采用的數據庫分別是HDFS和HBase。對于HDFS,Hadoop提供了客戶端FileSystem對象,該對象提供了類似操作本地文件的方法,可以將整個HDFS視作一塊大硬盤來處理。借助FileSystem,可以將HDFS中存儲的原始結果文件和解析后制圖渲染出的批量制圖文件下載到本地,其中,批量制圖文件可以直接使用,原始文件則需要進一步讀取和深入分析處理。對于分布式文件的處理,MapReduce通常被認為是一個最佳選擇。MapReduce擅長批量的順序處理,但是不支持隨機查詢。為此,需要一種支持隨機查詢的框架。對于HBase中存儲的記錄集,采用主流的Spark計算框架進行分析成為適宜的選擇。利用其內置的HBase-Spark接口,可以在HBase中進行交互式數據檢索,并將檢索結果轉化為易于操作的DataFrame格式。DataFrame派生于彈性分布式數據集(resilient distributed dataset,RDD),RDD是Spark SQL模塊中最核心的編程抽象,可以被理解為以列的形式組織的分布式數據集合,它類似于關系型數據庫中的表,但在底層實現優化并提供了一些抽象的操作來支持SQL。與此同時,Spark內部支持隨機查詢,這也為HDFS原始文件處理提供了支撐[13]。
RDD結構充分凸顯了分布式數據處理的優勢。RDD是邏輯集中的實體,在集群中的多臺機器上進行了數據分區。通過對多臺機器上不同RDD分區的控制,可以減少機器之間的數據重排。RDD是Spark的核心數據結構,具有豐富的算子以支持復雜分析,使用Spark集群的計算資源。在不影響HBase集群穩定性的情況下,可以通過并發分析的方式提高Spark的性能。RDD支持兩種操作,轉換操作用于將一個RDD轉換生成另一個RDD,行動操作則觸發Spark提交作業,并將數據輸出到Spark系統。基于RDD構成了Spark的四大組件,SQL用于處理結構化數據,Streaming用于處理流數據,MLlib用于機器學習,GraphX用于圖計算。因此,Spark提供了用于大規模數據處理的統一分析引擎,原始的結果文件和HBase中的解析結果集可以轉換為Spark的RDD,充分利用Spark生態系統實現算法高效處理分析。
交互和可視化在知識發現中非常重要。Spark生態系統中提供Shell和Submit兩種客戶端來支持交互,但是缺乏支持可視化分析的組件。對此,Hadoop生態系統中的Zeppelin組件同時被賦予交互和可視化能力,Zeppelin是一個可以進行大數據可視化分析的交互式開發系統,可以承擔數據接入、數據發現、數據分析、數據可視化、數據協作等任務。Zeppelin前端提供豐富的可視化圖形庫,后端支持HBase、Flink等大數據系統,并支持Spark、Python、Java數據庫連接(Java database connectivity,JDBC)、Markdown、Shell等常用解釋器,這使得開發者和研究者可以方便地在Zeppelin環境中進行數據分析。Zeppelin原生支持Spark解釋器,使得其成為一個合適的數據分析及可視化工具。
綜上所述,模型和大數據分析框架融合的核心在于選擇合適的交互式分析框架,該框架支持數據快速獲取、高效組織、交互式和可視化分析。具體融合流程分為3步:首先,借助交互式可視化工具,探索隱藏在數據中的規律,形成專業應用功能;其次,梳理上述交互式探索的流程,采用程序語言將處理流程封裝為算法軟件包;最后將算法軟件包集成到分布式計算框架中,用于服務具體業務的應用需求。
5 水環境模型與大數據技術融合案例
為了證實機理模型與大數據技術融合的可行性,以江西省梅江流域SWAT模型率定為例,描述水環境機理模型與大數據技術融合的具體實現流程。限于篇幅,本文僅給出融合過程中關鍵技術的實現流程。具體SWAT空間建模細節可參考參考文獻[14]。
5.1 SWAT模型空間建模
SWAT是一種半分布式模型,已被廣泛用于水文和環境建模。SWAT已開放源代碼軟件,其中的許多數據庫、文檔和出版物可供公眾使用,因此備受關注。此外,SWAT還提供了幾種軟件產品(如ArcSWAT、QSWAT),可以提供友好的用戶界面,并以直觀、信息豐富的地圖形式顯示結果。如圖4所示, SWAT的輸入數據包括數字高程模型(digital elevation model,DEM)、河道、土地利用和土壤數據。

圖4 SWAT模型空間建模流程
構建SWAT模型的流程如下:
● 將河道的線狀幾何信息加載到DEM;
● 對DEM進行預處理,并指定最小子流域面積;
● 核對并編輯河道上的點狀要素,選擇和定義流域出水口;
● 完成流域劃分;
● 根據土地利用、土壤數據和坡度數據對研究區域進行分類,以確定每個子匯水區的水文響應單元(hydrological response unit,HRU);
● 將所有天氣數據作為時間序列表輸入模型;
● 基于坡度、土地利用、土壤數據和天氣條件估算模型參數;
● 對SWAT模型進行校準和驗證,在模型運行過程中,最好設置一個預熱期以避免初始化錯誤。
5.2 SWAT模型與大數據技術框架融合
與傳統并行計算模式不同,基于大數據技術中的分布式并行計算框架實現的集群運算模式屬于多算例多任務分解模式,即每一個算例對應一個SWAT模型運行,這種模式適合大批量模型計算。通過位 置感知將計算移動到數據所在的存儲位置是一個重大的進步[15],即通過“數據本地化”可減少數據遷移,從而節約網絡帶寬,獲得高效的計算性能。分布式存儲將SWAT模擬結果分散存儲到多個節點,并且同一份數據在不同節點上保存多個副本,兼顧實現數據本地化和冗余備份,保障了數據的安全性。分布式計算則通過位置感知將SWAT模型的可執行程序分發到案例配置文件所在位置,達到“計算本地化優化”的目標。
SWAT模型在Hadoop平臺下的集群運算模式如圖5所示。配置文件的分布式存儲冗余備份機制縮短了計算程序的尋址感知時間。SWAT模型的分布式計算包括位置感知、本地化計算和計算結果存儲3個過程。分布式分發機制可以快速定位配置文件所在的計算節點,自動下載SWAT模型執行文件到計算節點,并創建運行空間,啟動模型讀取配置文件,執行模型本地化計算,最后將SWAT模擬結果寫入分布式存儲。

圖5 SWAT模型在Hadoop平臺下的集群運算模式
5.3 案例研究:SWAT模型自動率定
本案例采用貝葉斯優化(Bayesian optimization,BO)算法對SWAT模型進行參數估值,其率定流程如圖6所示。復雜水質模型包含大量參數,但通常只有少數參數會影響模型的輸出[16]。鑒于對不重要或者不敏感的參數進行估值會導致模型的過度參數化,從而大大降低參數估值的效率[17-18],在進行參數估值之前需要進行敏感參數選擇。本案例采用Morris敏感性分析方法,對選擇的重要參數進行敏感性排序,并篩選出敏感參數;然后,采用貝葉斯優化算法對篩選出的參數進行估值;最后,通過分析參數估值方法的優化效率和水質模型的擬合效果,對方法的適用性進行評估。

圖6 SWAT模型自動率定流程
Morris敏感性分析法是由Morris于1991年提出,后經過改進的一種全局敏感性分析方法[19]。該方法適用于分析參數眾多且運算量較大的模型,被廣泛應用于因子固定(factor fixing)和敏感性分析中。該方法的優點是以較低的計算成本獲得模型參數的敏感性相對大小,并對模型參數的敏感性大小進行排序[20]。基于高斯過程的貝葉斯優化算法具有收斂速度快、優化迭代次數少的特點,適用于解決評估代價高昂的環境模型的自動參數率定問題。納什效率系數(Nash-Sutcliffe efficiency coefficient,NSE)被當作目標函數進行水文參數敏感性及收斂性分析,從而定性分析度量方式的影響。NSE是最常用的模型評價指標之一[21-22],表示模型擬合方差占總方差的百分比[23]。
5.4 結果
SWAT模型參數選擇及其范圍是根據以往的研究確定的,選用參考文獻[24]中推薦的27個參數,經Morris采樣后產生24000組參數組合。進行圖6中的批量計算后,返回同等數量的NSE結果。將24000組參數集-NSE結果數據輸入Morris算法,得到敏感指數并排序。選擇敏感指數大于0.08的8個參數作為率定參數。各參數名稱、最大/最小值及參數意義見表1。值得注意的是,CH_K2和CH_N2屬于可測量參數,由于在本例中并沒有測定,因此仍然將其作為率定參數。
本案例中的大數據集群軟硬件信息詳見參考文獻[8]中的表1,貝葉斯優化算法的應用流程為:初始化參數空間,進行拉丁超立方抽樣,據此創建批量模型場景文件;將場景文件分發到大數據集群,集群在文件所在節點執行模型計算,返回NSE目標函數值;根據NSE目標函數值判斷是否達到率定要求,當未滿足率定要求時,選擇下一組參數繼續進行迭代計算,反之終止集群運算,返回率定結果。詳細操作流程可參考參考文獻[25]。

表1 SWAT模型中識別的敏感性參數
考慮到貝葉斯優化算法本質上屬于概率優化,因此本案例采用20次重復測試以檢驗優化結果的合理性。結合大數據集群硬件性能指標(56個算例并發計算),在單次優化過程中設置560(56×10)次迭代計算。圖7(a)顯示了某次迭代過程中,NSE隨著迭代次數的增加而緩慢增長的趨勢。結果表明,NSE總體上保持逐步上升趨勢。圖7(a)也有助于幫助理解貝葉斯優化過程,即如何推薦下一組參數集取決于開發和探索之間的權衡,NSE逐步上升過程中存在的波動變化證明了這一點。
為了進一步證明貝葉斯優化算法在SWAT參數率定中的優勢,本案例使用隨機搜索(random search,RO)算法進行對比。從圖7(b)可以看出,當BO和RS達到同一較高NSE取值時(以0.87為例),BO迭代次數(121)略小于RS(130),說明BO率定效率高于RS。而在給定迭代次數下(以220為例),BO優化獲得的NSE(0.89)大于RS(0.88),說明BO率定效果優于RS。上述結果表明,從SWAT參數率定和優化的效果和效率角度來看,貝葉斯優化算法優于隨機搜索算法。此外,依托大數據技術框架,可以融合多種優化算法,建立水環境模擬優化框架,從而為水環境模型深度應用和價值發揮提供理想環境。
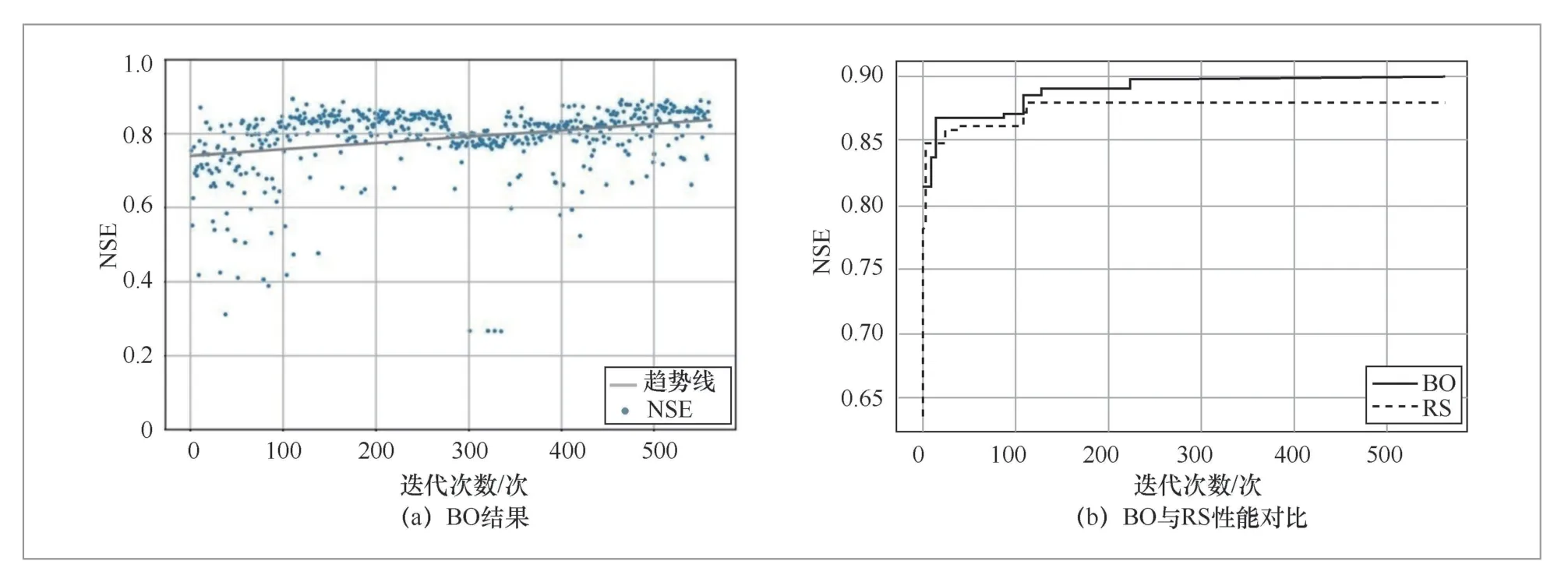
圖7 案例率定效果驗證一
為了檢驗本案例的率定效果,對徑流模擬值(Sim)與實測值(Obs)進行對比,如圖8(a)所示。BO的NSE最大值為0.89,說明率定后的模型較好地捕捉了月徑流變化,可以用于案例月徑流模擬。對貝葉斯優化過程中產生的20×560個徑流模擬結果值進行概率統計,獲得徑流模擬結果的概率直方圖,如圖8(b)所示。從圖8(b)可以看出,在率定過程中,徑流模擬值近似呈正態分布狀收斂,概率分布中極大值處的徑流量趨近于觀測值,說明率定過程中的參數不確定性可以傳到模擬結果中,從而導致模擬結果的不確定性。因此,在實際應用中,模擬結果分布呈現出的收斂趨勢比取某個特定值更具有參考價值,同時也反映了開展模型不確定性研究的重要性,本案例中提出的模型與大數據技術融合策略可以為開展模型不確定性研究提供一種新思路。

圖8 案例率定效果驗證二
6 結束語
限制水環境模型成功應用的主要瓶頸是基礎數據難以獲取以及模型率定、模型驗證及場景分析中的高負荷計算。基礎數據獲取依賴于精準的長期監測和對監測信息的高效提取,也可采用理論和經驗相結合的方法彌補數據的欠缺。大數據存儲技術的可擴展、冗余、容錯機制確保了原始數據的可靠性和高可用性,使其成為一種合適的持久化選擇,為多源異構基礎數據的持久化存儲提供了解決方案。作為典型的計算密集型復雜系統模型,水環境模型通常需要大量計算時間,尤其在面向自動率定、驗證及場景分析等批量計算需求時,通常無法承受大量的迭代計算。在單個模型計算非常耗時的情況下,批量計算是被禁止的。雖然現有并行計算體系很好地解決了數值模型的高性能計算問題,但是在計算結果的規模存儲,尤其規模分析上性能表現一般。這和現有并行計算體系的設計目標有關,它注重計算的高效性,而未考慮其他需求(如存儲和分析需求)。因此,水環境模型的高質量應用迫切需要一個緊密銜接計算、存儲和分析全鏈條的技術支撐體系。大數據技術體系成為潛在的理想選擇。大數據技術內置了分布式計算、存儲和分析框架體系,自然成為一種解決水環境模型規模計算問題的潛在理想方案。
在本研究中,以SWAT模型參數自動率定為例,驗證了方案的可行性。首先,通過將模型配置文件分布式分發到各個計算節點;接著,水環境模型計算程序會自動定位到配置文件所在位置;然后,在計算節點啟動計算的過程中,在SWAT模型計算完成后,開始解析計算結果,并將原始結果文件和解析結果記錄存入大數據庫;最后,利用內存網格技術高效地提取和分析模擬結果。上述所有環節緊密銜接了計算、存儲和分析技術鏈條,應用案例證明了水環境模型與大數據技術融合的可行性,二者的融合為深入挖掘水環境模型的應用潛力和充分發揮其應用價值提供了新的視角。
水環境模型和大數據技術融合的核心是模型分布式計算,即模型作為獨立的第三方可執行程序被計算框架調用,比較適合模型參數率定及情景分析等批量計算的應用場景。受益于大數據分布式計算橫向擴展的特點,計算效率通常和計算節點個數呈線性增長關系,這極大提高了模型的計算效率。即便如此,作為計算密集型復雜模型,水環境模型計算仍然非常耗時。相反,近似物理模型的統計“代理模型”可以提供對物理系統的高效仿真。代理模型系統以統計模型的形式映射輸入變量和輸出變量,該統計模型通過使用物理模型生成的一組數據進行訓練和驗證。代理模型在水文學領域已被廣泛研究[26],近似算法(如kriging[27]、人工神經網絡[28]、徑向基函數[29]、多項式回歸[30]、支持向量機[31]、稀疏網格插值法[32]和隨機森林技術[33])已被應用于各種地球系統和水文系統。在最新研究中,復雜水動力水質模型EFDC(environmental fluid dynamics code)被長短期記憶(long short-term memory,LSTM)代理反映了這一趨勢[34]。可以預見,水環境模擬與大數據技術融合有以下兩個發展趨勢。
(1)以大數據技術為轉化載體,水環境模型將以統計模型形式從物理模型轉化為代理模型,這將極大地改變現有水環境模型的應用模式。與物理模型相比,代理模型兼具較高的模擬精度和極高的計算效率,使之成為物理模型的理想替代,這勢必會推動模型參數敏感性分析、參數率定及情景分析等應用研究。
(2)水環境模擬優化框架成為未來的發展趨勢。該框架以完整的分布式計算、存儲和分析鏈為技術支撐,以物理模型或代理模型為核心,結合單目標或多目標優化算法,解決優化調控類科學決策問題。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年12期)2021-08-24 03:30:40
中老年保健(2021年11期)2021-08-22 03:15:44
中國傳媒大學學報(自然科學版)(2021年1期)2021-06-09 08:43:00
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
現代出版(2020年3期)2020-06-20 07:10:34
中國生殖健康(2020年6期)2020-02-01 06:28:50
中國生殖健康(2019年11期)2019-01-07 01:28:02
電子制作(2018年18期)2018-11-14 01:48:24
