移動機器人中視覺里程計技術綜述
2021-11-18 02:18:22馬科偉張鍥石康宇航任子良
計算機工程 2021年11期
馬科偉,張鍥石,康宇航,任子良,程 俊
(1.中國科學院深圳先進技術研究院,廣東 深圳 518055;2.中國科學院大學 深圳先進技術學院,北京 101408)
0 概述
視覺里程計(Visual Odometry,VO)[1]主要用于移動機器人和智能車輛的自主導航任務,尤其是在未知環境下的目標檢測和自身定位中發揮著重要作用。VO 的主要工作原理是在剛體運動過程中,利用攝像頭對周圍環境采集圖像數據,以連續圖像序列作為輸入信號,通過計算自身的位姿變化以得到運動估計。
早期的里程計技術多為機械式原理,如我國古代的記里鼓車利用齒輪傳動機構實現路程計量,而近代出現的電子式里程計則利用電子傳感器代替早期的機械部件,從而降低成本、提升可靠性并獲取更加準確的里程信息和速度信息。VO 相關研究起 源于20世紀80年代,最早是由MATTHIES 等[2]設計一套包括特征提取、特征匹配、運動估計等模塊的理論框架,并一直沿用至今。2004 年,VO 這一概念被DAVID 等[1]正式提出,同年,VO 被NASA 用于火星探測器,自此,VO 被大眾熟知并逐漸引起關注。近年來,VO 的相關研究成果已廣泛應用于無人駕駛、VR、AR、移動機器人等新興技術領域。隨著人工智能技術的發展,很多基于深度學習的VO方法不斷被提出,并在某些性能表現上優于傳統方法。
在實際應用中,通常采用實時定位與地圖構建(Simultaneous Localization and Mapping,SLAM)[3-4]技術來實現移動機器人的自主建圖與導航等需求。SLAM是一種無需外界信號源就能在陌生環境中實現獨立自主定位的技術,通過搭載特定的傳感器來捕獲環境信息,通常包括搭載激光雷達的SLAM 系統和搭載相機的SLAM 系統。其中,搭載相機的SLAM 系統被稱為視覺SLAM(Visual SLAM,VSLAM)[5]。VSLAM 注重全局軌跡和地圖的一致性,其最終目的是獲得一個全局且一致性的機器人運動路徑估計,整個系統通常包括傳感器數據、前端、后端、回環檢測、建圖等5個部分。而VO 的研究主要集中在如何根據相鄰幀圖像定量估算幀間相機的運動,其僅關注局部運動,工作方式是一個位姿接一個位姿地增量式重構地圖,且只優化前面若干個路徑位姿,因此,VO 通常作為VSLAM 的前端來使用。
為了使得VO 方法可以更好地應用于實際場景,研究人員進行了大量的研究,研究方法主要分為2 類:一類是基于傳統幾何方法,另一類是基于深度學習方法。本文對VO 方法的發展歷程進行概述,分別介紹基于傳統幾何和基于深度學習的VO 系統,在對VO 進行數學表述的基礎上匯總各類方法,并深入探討直接法和間接法2 類方法。同時歸納目前VO系統研究中常用的公共數據集,并對部分VO 系統進行評價測試,最后對VO 領域的未來發展方向進行展望。
1 傳統VO 方法
1.1 VO 的數學表述
VO 系統首先通過傳感器采集視覺信息,在獲取信息的過程中主要用到透視投影技術,透視投影的原理是將三維世界投影到二維平面,相機模型即基于透視投影,其幾何關系如圖1 所示。其中:C-xyz為相機坐標系;O-uv為二維投影成像平面;C點為攝像機的光心;C、O之間的距離為相機的焦距。考慮一個空間點P(X,Y,Z)經過投影映射到二維平面的p(u,v)點。
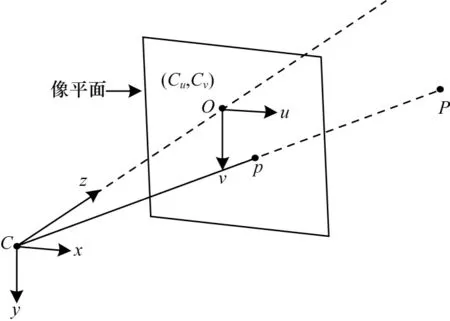
圖1 相機幾何模型Fig.1 Camera geometry model
從三維空間投影到二維平面的透視投影方程可以表示為:
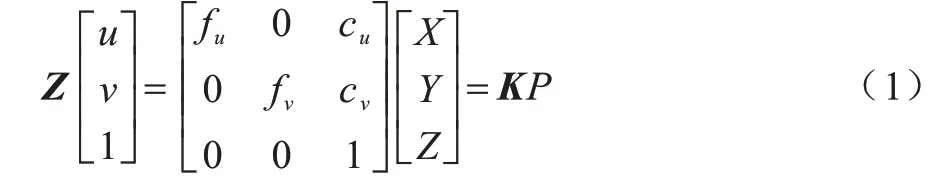
其中:fu、fv是u、v方向上的焦距;cu、cv為二維投影平面的像素從原點處向u、v方向的平移量。fu、fv、cu、cv都屬于相機的內部參數,由它們共同組成式(1)中的矩陣,稱為相機的內參數矩陣K,相機的內參在出廠后是固定的,不受外界環境影響。
相機在環境中以固定頻率采集運動圖像,假設在k時刻采集到的圖像為Ik,則在一段時間內采集到的圖像序列可以表示為I0:n={I0,I1,…,In},在k-1 時刻至k時刻,相機的坐標變換矩陣T可表示為:

其中:R為旋轉矩陣,t為平移向量,它們又稱為相機的外參數,均隨著相機的運動而發生改變,由它們組成的矩陣T稱為變換矩陣(外參數矩陣),其代表著相機軌跡,同時也是VO 中的待估計目標。設相機位姿集C0:n={C0,C1,…,Cn},通過圖像序列可以計算出一系列連續的變換矩陣Tk(k=1,2,…,n),就可以通過初始位姿C0得到相機的后續運動軌跡Cn=Cn-1×Tn=C0×T1×…×Tn。由于VO 是增量式重建軌跡,因此計算出的軌跡不可避免地會有誤差積累,為了減少這種誤差,通常使用捆綁調整優化(Bundle Adjustment,BA),通過迭代優化前m幀的重投影誤差使得誤差累計最小。
1.2 傳統VO 方法分類
傳統VO 方法是基于模型的系統,按照主流傳感器類型可以分為單目(Monocular)、雙目(Stereo)、深度相機(RGB-D)三大類,而按照對圖像的處理方法可以分為特征點法和直接法兩大類。
1.2.1 按傳感器類型的分類
只使用一個攝像頭的VO 系統稱為單目VO 系統,單目相機具有結構簡單、成本低的特點,受到眾多研究人員的關注,常用的單目VO 系統有PTAM[6]、SVO[7]、DSO[8]等。但是,單目相機在采集數據時往往會丟失一個重要場景維度,即深度。為解決該問題,需要平移單目相機后才能估計深度信息,但通過這一過程仍然無法獲得真實距離。
為得到更加準確的深度信息,研究人員嘗試使用雙目相機和深度相機,這兩類相機可以測量物體與相機的距離,從而解決單目相機無法測量距離的缺點。在取得距離之后,場景的三維結構就可以通過圖像恢復出來,也消除了尺度的不確定性。雙目相機由2 個單目相機組成,常用的雙目VO 系統有ORB-SLAM[9]、RTAB-MAP[10]。但是,雙目相機的視差計算往往非常消耗資源,這也是雙目相機存在的主要問題之一。深度相機主要利用紅外結構光或者ToF(Time-of-Flight)原理,通過向目標物體發射光并接收返回的光來測出距離,與雙目相機測距原理不同,深度相機是通過物理測量手段獲取距離參數,相比于雙目相機可節省計算資源,常用的深度VO系統有DVO[11]、RGB-D-SLAM-V2[12]等,但是深度相機存在易受光照影響、無法測量投射材質等不足,且主要用于室內測量,目前難以在室外廣泛應用。
1.2.2 按圖像處理方法的分類
根據是否直接對圖像進行特征提取,傳統VO 方法可分為特征點法和直接法兩大類。
特征點法首先從圖像中選取比較有代表性的點,且這些點在相機視角發生少量改變后依然保持不變,即在各幀圖像中盡可能找到相同位置的點,然后基于這些點計算位姿。早期提取的特征以灰度值的形式存在,但灰度值易受光照、形變、材質等影響,在不同圖像中變化較大,魯棒性較差。為了克服這一問題,研究人員設計出更加穩定的圖像特征,如SIFT[13]、SURF[14]、ORB[15]等,這些特征相對于早期的特征具有更穩定高效的優勢,因此,基于這些特征描述子衍生出了很多算法,如MonoSLAM[16]、PTAM[6]、ORB-SLAM[9]等。楊冬冬等[17]基于SIFT特征提出一種基于局部和全局優化的雙目VO,在滿足實時性的基礎上能夠提高精度。但是,通常特征點法中的關鍵點提取和描述子計算過程都非常耗時,且只使用了圖像的少量信息,如遇到某些特征缺失的場景,就難以找到足夠多的匹配點來估計相機運動。
特征點法需要消耗大量的資源來計算特征點,直接法則不需要知道點與點之間的對應關系,其只提取關鍵點,跳過描述子計算,直接根據像素灰度信息來計算相機的運動。常用的基于直接法的VO 系統有DTAM[18]、DSO[8]、DVO[11]等。
由于基于特征點法的VO 系統在SLAM 中更適合回環檢測與重定位,因此當前主流的VO 方案更多基于特征點法。常用的基于傳統方法的VO 系統性能對比結果如表1 所示。
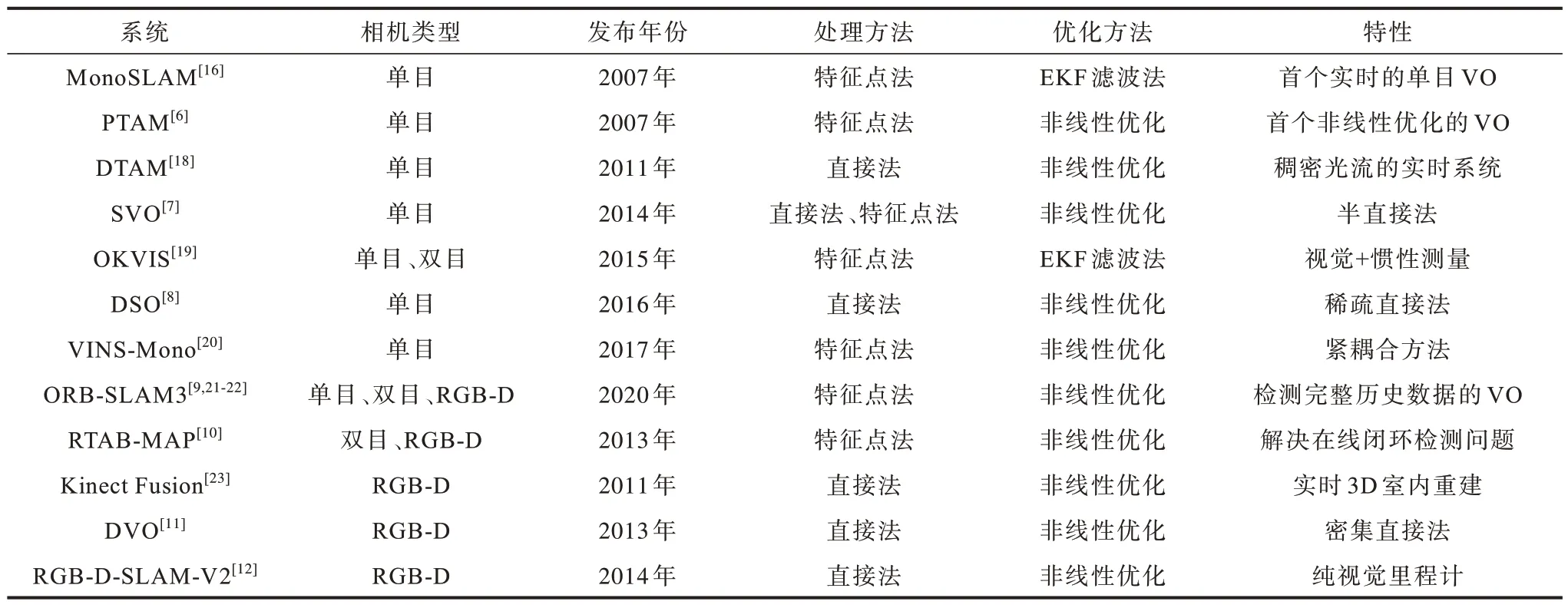
表1 基于傳統方法的VO 系統性能對比結果Table 1 Performance comparison results of VO systems based on traditional methods
1.3 特征點法
基于特征點法的VO 系統主要包含特征模塊和位姿估計兩大部分。其中:特征模塊主要包含特征檢測、特征匹配、特征誤匹配處理;位姿估計通常分為2D-2D、3D-3D、3D-2D。
1.3.1 特征模塊
特征模塊各部分具體如下:
1)特征檢測。特征點由關鍵點和描述子2 個部分組成。關鍵點是指特征點在圖像中的位置,其具有尺度、方向等信息,在關鍵點周圍的區域生成一個標示性的向量來表示這個區域的特征,這個向量被稱為描述子,其作用是將自己與其他區域分開,通常作為匹配過程的基礎。
在特征點檢測中,角點檢測是最早被提出的特征點檢測方案之一,角點及其特征在視角發生較大變化時依然能夠穩定存在,并且與鄰域相差較大。Moravec 角點檢測算法[24]以像素點為中心,檢測該點與周圍一定范圍內信息的相似性,不相似則該點會被認為是角點,但該方法具有對噪聲和邊緣敏感的缺點,而且不具備旋轉不變性。Harris 算法[25]在Moravec 算法的基礎上使用泰勒展開式,覆蓋了所有方向的檢測,克服了Moravec 只檢測45°倍角的缺點,不僅對噪聲不敏感,而且在不同光照條件下均具有很好的穩定性,但該方法不適用于對尺度變化要求較高的場景。Shi-Tomasi 算法[26]進一步優化了Harris 算法,提高了角點的穩定性。從本質上講,Moravec 算法[24]、Harris 算法[25]、Shi-Tomasi 算法[26]都是基于梯度的檢測算法。ROSTEN 等[27]于2006 年提出了FAST 算法,該算法將FAST 角點定義為:若某像素與周圍鄰域內足夠多的像素點差異較大,則該點可能是角點,其具有計算速度快、效率高的特點,在實時場景中可以被廣泛應用。
LOWE 等[13]于1999年提出了尺度不變特征變換(Scale-Invariant Feature Transform,SIFT)算法,并在2004 年對其進行改進。SIFT 特征是圖像的局部特征,其描述符具有尺度不變性,能夠適應旋轉、尺度縮放、亮度等變化,具有很強的穩定性和抗干擾性,但隨之帶來的是極大的計算量,因此,無法實時計算SIFT 特征。BAY 等[14]于2006 年提出了加速穩健特征(Speeded Up Robust Features,SURF)算法,該算法基于SIFT,但改變了其原有的特征點檢測方式,并將描述子從128 維降為64 維,解決了SIFT 特征計算量大的問題,提升了算法的執行效率。隨后,BRIEF 算法[28]的提出大幅簡化了描述子的計算過程,其利用局部圖像鄰域內隨機點對的灰度值來建立特征,生成二值特征描述子,使得特征提取的過程大幅加速,算法實時性較好,但其缺點是不支持大角度的旋轉。ETHAN 等[15]于2011年提出了ORB(Oriented FAST and Rotated BRIEF)算法,該算法在特征提取部分用改進的FAST 算法,特征描述部分基于BRIEF 算法進行改進,解決了其原先不適應大旋轉角的問題,因此,ORB 算法不僅具備FAST 和BRIEF 速度快的特點,還具有較好的尺度和旋轉角度不變性。
2)特征匹配。在檢測出了特征點之后,就可以通過匹配算法將圖像之間的特征點一一對應起來,這個過程稱為特征匹配。特征匹配是VO 中極為關鍵的一步,它解決了VO 中的數據關聯問題,即確定當前看到的路標與之前看到的路標之間的對應關系。通常最簡單的特征匹配方法是暴力匹配(Brute-Force Matcher),由于描述子距離代表了2 個特征點之間的相似程度,該算法中將每一個特征點與其他待匹配的特征點進行描述子距離計算,然后在其中尋找最合適的特征點作為匹配點。在實際應用中,也會用到不同的距離度量范數,其中,歐氏距離適合浮點類型描述子,而對于二進制描述子,通常使用漢明距離。暴力匹配算法在特征點數量很多時會出現計算量很大的問題,難以滿足實時性需求,因此,研究人員引入近似最鄰近(Approximate Nearest Neighbor,ANN)搜索,其適用于匹配點數量極多的情況,在保證匹配精度的情況下大幅提升了匹配速度。MUJA等[29]提出快速近似最鄰近(Fast Library for Approximate Nearest Neighbors,FLANN)算法,該算法依據KD 樹實現,從已知數據集中的分布特點和其要求的空間資源消耗來給出合理的搜索參數,FLANN 要求的特征空間通常是n維實數向量空間Rn,其依據歐氏距離尋找實例點附近最近的點作為關鍵點。
3)特征誤匹配處理。在實際特征匹配過程中,會遇到誤匹配的情況,即將非對應的特征點作為匹配點。誤匹配通常分為2 種情況進行處理:
(1)對于幾何約束是參數化的情況,隨機抽樣一致(RANSAC)算法[30]是當前使用最廣泛的誤匹配點剔除算法,其具有隨機性和假設性,可以從一組包含離群數據的數據集中通過迭代方式估算出數學模型參數,但該算法是一種不確定的算法,因此,為了提高結果的精確性,只能提高迭代次數。RANSAC 算法具有結構簡單、魯棒性強的特點。
(2)對于幾何約束是非參數化的情況,適合應用向量場一致(Vector Field Consensus,VFC)算法[31]進行處理。該算法的原理是利用向量場的光滑先驗,將外點從樣本中區分出來,其具有魯棒性強和匹配率高的特性,對于誤匹配率較高的圖像效果尤為顯著。
1.3.2 位姿估計
位姿估計即計算2 幀圖像之間的運動估計,用數學模型表達可以理解為變換矩陣T的計算。在實際運用中,根據特征點類型的不同,位姿估計通常分為2D-2D、3D-3D、3D-2D 這3 類計算方法,具體如下:
1)2D-2D(對極幾何)。在單目相機中,通常采集到的信息是以二維圖像形式存在,在進行2 幀之間運動估計時,由于圖像上的二維點沒有做三維測量,因此需要用到對極幾何(Epipolar Geometry)。對極幾何描述了同一場景在2 幅圖像之間的視覺幾何關系,其模型如圖2 所示。
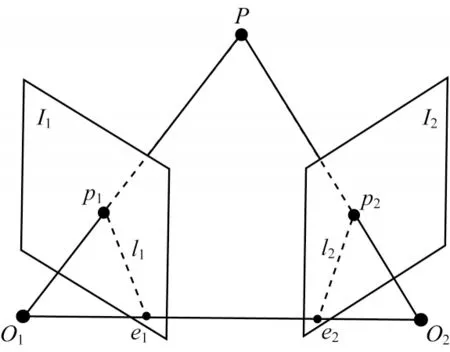
圖2 對極幾何約束模型Fig.2 Epipolar geometry constraint model
在對極幾何約束模型中,I1和I2代表相鄰圖像幀,O1、O2是相機中心,設p1、p2分別為I1和I2中已匹配成功的特征點,連線O1p1和O2p2在三維空間中相交于P點,O1O2的連線與I1、I2相交于極點e1、e2,p1e1、p2e2被稱為極線。根據代數幾何關系,可以得到特征點之間滿足以下約束關系:

其中:F是基礎矩陣;p1、p2為特征點在圖像中的像素位置。通過式(3)可以得出基礎矩陣F,基礎矩陣F與本質矩陣E存在如下關系:

其中:K為相機的內參矩陣。從式(4)可以得出本質矩陣E,而E=t^R,根據式(5)可求得R和t,即求出了變化矩陣T。

其中:x1、x2為特征點的歸一化坐標。
在等式E=t^R中,由于R和t各有3 個自由度,故t^R共有6 個自由度。本質矩陣是由等式為零的對極約束定義的,因此,E在不同尺度下是等價的,即E實際上有5 個自由度,這表明至少需要通過5 對點才能求解相機的運動[32-34]。除此之外,還有6 點算法[34]、8 點算法[35-36],6 點算法相比于5 點解決方案更加簡單,可以更加穩健地估計本質矩陣,且在平面場景中不會失效;8 點算法是從8 個或更多匹配點中通過對匹配點的坐標進行歸一化處理來計算基本矩陣,具有簡單易實現的優點。在特殊情況下,當相機只做平面運動時,運動模型就會降為3 個自由度,這種情況下僅需要2 對點就能計算出相機的運動參數[37]。
2)3D-3D(ICP)。3D-3D 是針對立體視覺,從三維圖像信息中計算位姿估計。假設有一組已經匹配成功的3D 特征點(已經對2 個RGB-D 圖像進行了特征匹配):P={p1,p2,…,pn},P'={p'1,p'2,…,p'n},通過對應的特征點求其歐式變換的R和t時,通常用迭代最近點(Iterative Closest Point,ICP)算法[38]求解,而ICP 的求解方式分為2 種,即利用線性代數的求解和利用非線性優化的求解。2 種求解方式具體如下:
(1)在線性代數求解方法中,以奇異值分解(Singular Value Decomposition,SVD)法為代表。根據對匹配點的定義,設第i對點的誤差項為:

然后構建最小二乘問題,求出使得誤差平方和達到最小的R和t:
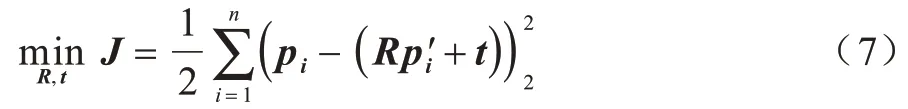
(2)在非線性優化求解方法中,通常使用迭代的方式求最優解。該類方法至少需要3 對非共線的三維點,且與3D-2D 的非線性解法類似,用李代數ξ表示相機位姿,如式(8)所示,通過多次迭代就可找到合適的ξ。
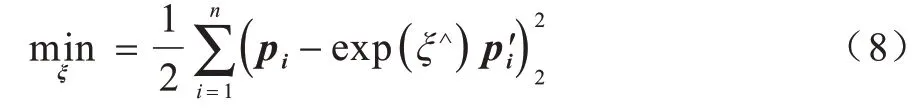
3)3D-2D(PnP)。在求解從三維空間點到二維平面點對的運動估計時,通常使用n點透視投影(Perspective-n-Point,PnP)方法,該方法不需要對極約束,且在匹配點對很少的情況下仍可獲得較好的運動估計。
求解PnP 問題有很多方法,包括P3P[39]、直接線性變換、非線性優化等。其中:P3P 方法主要使用3 對匹配點和1 對驗證點來估計變換矩陣;直接線性變換則要求最少有6 對匹配點才可實現對變換矩陣T的線性求解,當匹配點大于6 對時,還可以使用SVD 方法對超定方程求最小二乘解;非線性優化法則將PnP 問題構建成一個定義在李代數上的非線性最小二乘問題并進行求解。二維點坐標與空間點坐標的投影關系是求解PnP 問題的關鍵,其計算過程如下:

其中:P為空間坐標;u為投影的像素坐標。由于相機位姿未知,并且觀測點存在噪聲,故式(9)方程存在誤差,因此需要構建一個最小二乘問題,使得誤差最小,然后找出最合適的相機位姿:
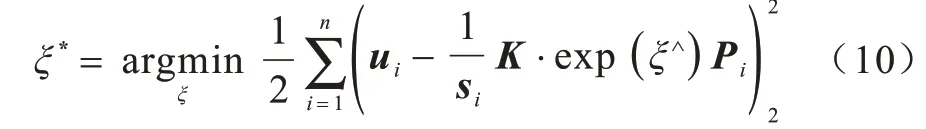
式(10)的誤差項是三維空間點根據當前估計投影到二維空間的坐標與觀測到的二維真實坐標之間的誤差,即PnP 問題可以看作一個最小化重投影誤差的問題。
1.4 直接法
在特征點法中,假設特征點是固定在三維空間中不動的點,通過最小化誤差來優化相機運動,而在這個過程中,需要精準地知道2 個對應的特征點在相機坐標系下的坐標,這也是進行特征匹配的原因,但由此帶來了巨大的計算量。而在直接法中,并不需要知道點與點之間的對應關系,在圖像有像素梯度的情況下,僅利用圖像的像素灰度信息,通過最小化光度誤差來計算運動變化,該方法不要求圖像中有特征點,避免了特征點的提取和匹配,同時能夠充分地使用圖像信息,尤其是在特征缺失的場景中,直接法的效果優于特征點法。
相比于只可以構建稀疏地圖的特征點法,直接法還可以構建稠密地圖。通常根據像素的使用數量將直接法分為稀疏、稠密、半稠密3 種方法。當P點來自于稀疏特征點時,稱之為稀疏直接法,經典的稀疏法有SVO 算法[7];當P點來自部分像素時,稱之為半稠密直接法,如LSD-SLAM 算法[40];當P點來自于所有像素時,稱之為稠密直接法。
直接法是基于灰度不變假設而提出的方法,但是實際情況并不如此,比如相機的自動曝光可能會改變灰度差異,使算法失效。此外,直接法只適用于運動變化很小的情況,很難對較大變化的運動進行位姿估計,并且其在閉環檢測過程中存在的累計漂移問題一直沒有得到很好地解決[8]。
1.5 直接法與特征點法的對比
目前,基于特征點法的VO 系統依舊占領主流地位,但是在某些特定的場景中,使用直接法效果優于特征點法,如在特征點稀少且有像素梯度時更適合直接法。表2 所示為直接法和特征點法的性能對比結果。
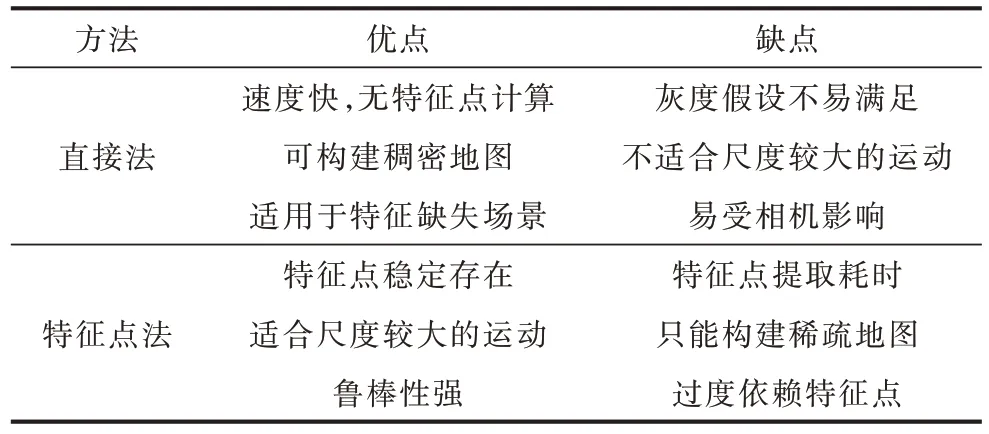
表2 直接法與特征點法性能對比結果Table 2 Performance comparison results of direct method and feature point method
1.6 傳統方法的不足
特征點法和直接法這2 種VO 方法已發展多年,但仍面臨以下問題:
1)人工設計的特征會丟失圖像中大部分信息,在某種程度上會導致VO 效率低下。
2)特征提取計算復雜耗時。
3)在相機運動幅度較大時,特征跟蹤容易丟失。
4)對于動態場景處理仍不理想,如視覺畫面中有行人持續走動的情況。
5)對光照敏感,在光照條件惡劣的條件下魯棒性差。
6)在圖像特征不明顯的情況下會導致精確度降低,并隨之引發誤差累積。
2 基于深度學習的VO 方法
2.1 方法介紹
近年來,深度學習的發展極大促進了計算機視覺的相關科學研究,提高了視覺相關任務的準確率、魯棒性以及執行效率。不同于傳統VO 系統通過嚴格幾何理論方法來實現的方式,基于深度學習的VO則通過尋找數據規律與目標任務之間的函數關系來完成同樣的工作。基于深度學習的VO 主要分為有監督、無監督、半監督3 種學習方法,其中具有代表性的VO方案有DeepVO[41]、GeoNet[42]、CNN-SLAM[43]等。
2008 年,ROBERTS 等[44]首次嘗試將機器學習的方法用于VO 系統,通過使用K-鄰近(K-Nearest Neighbor,KNN)算法學習從稀疏光流到平臺速度和旋轉速率的映射,雖然在當時無法像傳統幾何方法那樣準確地進行運動估計,但該方法可以在沒有相機校準或場景結構模型的情況下,驗證相機和環境的屬性與運動估計之間映射的可能性。
基于特征點法和基于深度學習的VO 方法在理論框架上具有一定程度的一致性。其中多數方法都更傾向于使用基于卷積神經網絡(Convolutional Neural Networks,CNN)的特征提取網絡,相比傳統方法其穩定性和匹配準確率更高。2015 年,KONDA 等[45]提出一種端到端的深度卷積神經網絡模型來進行位姿估計,雖然在當時其性能與傳統方法無法相提并論,但該模型進一步驗證了基于深度學習的VO 具有相當的潛力和可行性。2016 年,COSTANTE 等[46]提出一種名為P-CNN VO 的VO 系統,該系統在模糊、亮度對比異常的情況下具有較強的魯棒性。2017 年,MULLER 等[47]提出了Flowdometry 系統,該系統將原始光流直接作為預測網絡的輸入,再通過全連接層計算出位姿估計,其達到了同時期同類方法中的最佳性能。2018 年,LIN 等[48]提出一種基于循環卷積神經網絡(Recurrent Convolutional Neural Network,RCNN)的全局位姿估計網絡模型,該模型主要解決VO 的遠距離漂移問題。同年,JIAO 等[49]提出一種端到端的雙向循環卷積神經網絡的單目VO 系統Magic VO,該系統基于CNN 和雙向LSTM(Bi-SLTM),用于解決單目視覺測距問題。2018 年,YU等[50]提出DS-SLAM 系統,該系統將語義分割網絡與運動一致性檢查方法相結合,減少了動態目標的影響,從而大幅提高了在動態環境中的定位精度。2019 年,ALMALIOGLU 等[51]提出了基于生成式對抗網絡(Generative Adversarial Network,GAN)的模型來學習圖像特征,通過無監督學習得到一個名為GANVO 的單目VO 系統,該模型相比于監督學習不需要大量的標定數據,且相比于當時大多數的傳統方法具有更好的性能。PANG 等[52]提出一種名為CLOCs(Camera-LiDAR Object Candidates)的多模態學習網絡,該網絡對圖像數據集和雷達數據集進行雙模態學習,相比于單模態的純視覺學習,其在精度和魯棒性上都有了顯著提升,并且在KITTI 數據集中達到了較好效果。2020 年,YANG 等[53]提出了D3VO,該系統設計一個自監督單目深度估計網絡,提高了前端追蹤和后端非線性優化的性能,在單目VO 中,其測試結果相對傳統sota 方法得到顯著提升。表3 所示為部分基于深度學習的VO 系統的性能對比結果。
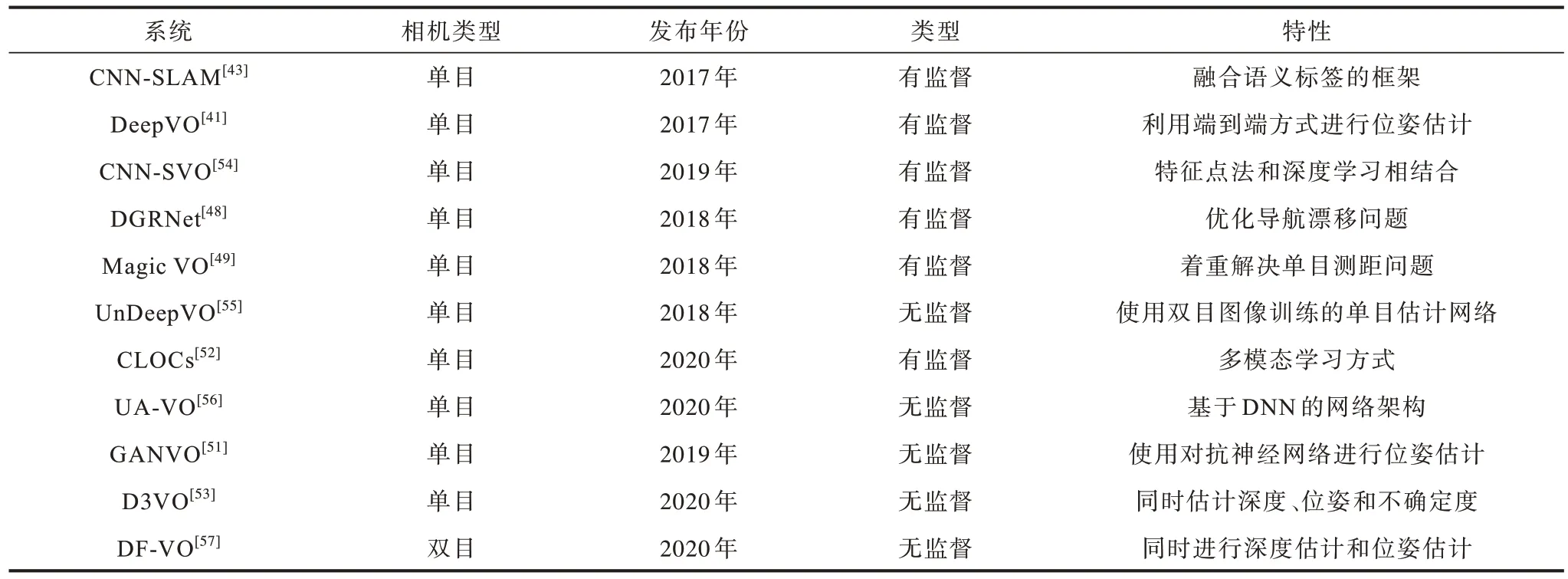
表3 基于深度學習的VO 系統性能對比結果Table 3 Performance comparison results of VO systems based on deep learning
2.2 基于深度學習的VO 方法優點
基于深度學習的VO 相比于傳統VO 的性能優勢主要體現在以下5 個方面:
1)基于深度學習的VO 系統具有很強的泛化能力,可以在光線復雜的環境中工作。
2)對于動態場景的識別更加有效。
3)采用數據驅動的模型,更符合人類與環境的交互方式。
4)深度學習的方法可以更好地和其他傳感器數據融合。
5)端到端的系統省去了中間的復雜流程,直接輸出結果。
2.3 基于深度學習的VO 方法缺點
雖然基于深度學習的VO 在一定程度上展現出性能優勢,但其依舊存在以下發展瓶頸:
1)模型訓練時間長,且需要大量的計算資源。
2)網絡層數多的模型容易出現梯度消失問題,使得梯度無法從輸出層傳到輸入層,進而導致訓練難度增大。
3)深度學習是典型的黑箱算法,沒有理論依據,不像傳統方法那樣每個環節都有很強的解釋性,其通過數據驅動的方式去學習,模型復雜,通常包含上億個參數,若應用結果出現問題很難確定是哪個參數的原因,從而無法針對性地解決問題。
4)大部分模型依賴于大規模帶有標簽的訓練數據,人工標注數據將消耗大量精力,并且實際場景更具復雜性,不可能收集到所有的標簽信息。
5)對數據集要求較高,即使在某個數據集上取得了優秀的結果,換個場景可能導致精準度降低,只有當數據集足夠大時,才可能展現出較強的適應性,因此,數據集的大小對于深度學習是一個非常重要的因素。
3 數據集
在測試VO 系統性能時,通常通過公共數據集來對比不同方法的性能,當前在VO 領域比較流行的公共數據集包括KITTI[58]、TUM RGB-D[59]、EuRoC[60]等。表4 所示為不同數據集之間的特性對比結果。
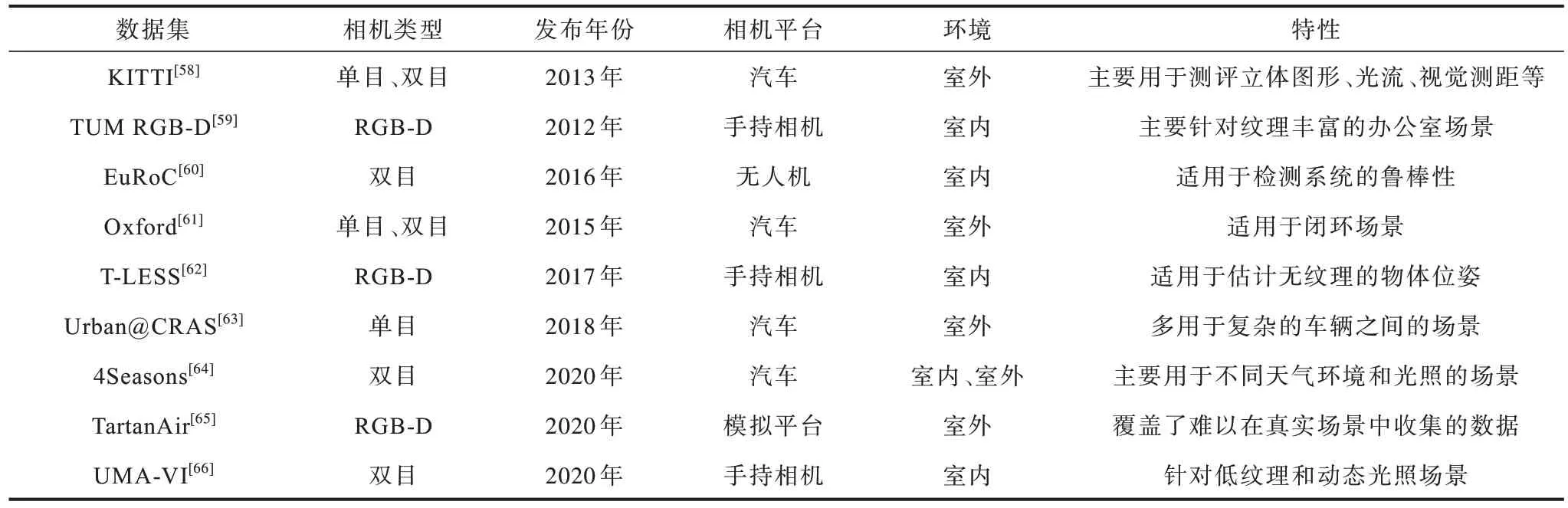
表4 部分VO 數據集對比結果Table 4 Comparison results of some VO datasets
KITTI[58]由卡爾斯魯厄理工學院和豐田美國技術研究院共同創辦,是目前國際上最大的自動駕駛場景下的計算機視覺算法評測數據集,其包含市區、鄉村、高速公路等不同場景以及在不同車速和光照條件下的數據,主要面向室外,多用于評測立體圖像、光流、視覺里程計、3D 物體檢測、3D 跟蹤等計算機視覺技術在車載環境下的性能。表5 所示為5 種典型VO 系統在KITTI 上的測試結果。
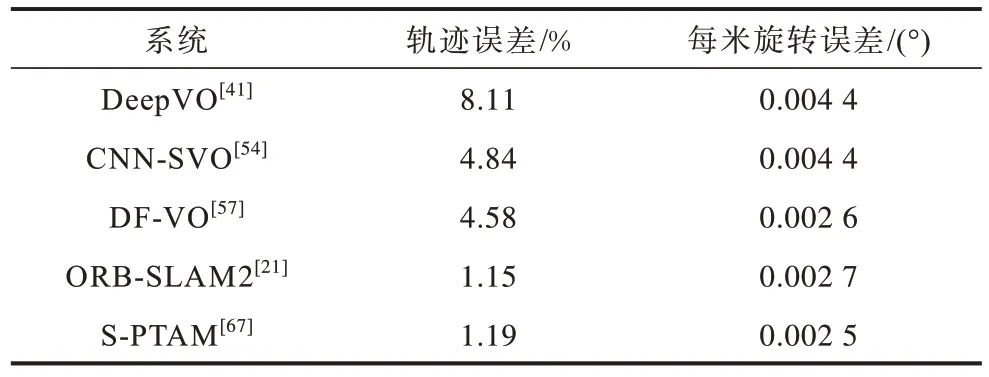
表5 5 種VO 系統在KITTI 數據集上的性能測試結果Table 5 Performance test results of five VO systems on KITTI dataset
TUM RGB-D[59]是由德國慕尼黑工業大學Computer Vision Lab 發布的針對深度相機的數據集,是業界很有名的RGB-D 數據集,該數據集主要針對紋理豐富的室內場景,數據類型多樣,包括幀數大小、相機運動快慢、場景結構以及不同的紋理類型。
EuRoC[60]是由蘇黎世聯邦理工學院發布的一個專門針對室內場景的數據集,其通過小型無人機+雙目相機+IMU 的形式采集數據,該無人機運動比較劇烈,適宜于檢測系統的魯棒性。
4 VO 領域未來的研究方向
VO 技術已經發展多年,在很多方面都取得了重大進展,但目前仍舊有一些問題等待解決,本文在總結現有方案的基礎上提出以下2 個值得探索的研究方向:
1)提高VO 在動態場景下的魯棒性。動態場景中存在著不確定因素,如在分辨動態物體時還要處理被遮蓋的靜態場景,而且許多VO 方法只能容忍在小尺度動態場景內發生的部分異常事件,在大尺度動態場景中并不能達到很好的效果。為了實現場景由小范圍固定環境到大范圍復雜動態環境的擴展,保證VO 在動態場景中具有良好的環境適應能力,需要快速有效地處理動態場景,這也是VO 未來的研究熱點。
2)探索基于深度學習的多模態融合VO 框架。機器人在移動過程中會面臨諸多場景變化,如天氣季節、光照角度、動態遮擋等,純視覺的單模態系統易受噪聲影響,從而降低軌跡估計的精確度。多模態融合的系統常使用多種傳感器來補償位姿估計,從而降低場景變化時所帶來的噪聲影響。如使用IMU 提高高速運動下的定位效果,使用LiDAR 提高不良照明條件下的魯棒性。同時,深度學習模型能充分利用不同類型傳感器的信息,提高對各類信息的利用率。因此,基于深度學習的多傳感器融合VO框架是一個值得探索的課題。
5 結束語
VO 方法在移動機器人領域應用越來越廣泛,本文分別介紹基于傳統幾何和基于深度學習的2 類VO 方法,并對比分析各類經典方法的性能特點,總結當前在VO 領域常用的公共數據集。分析結果表明,在VO 領域,以特征點法為代表的傳統幾何方法依舊是當前較為可靠的解決方案,同時基于深度學習的VO 也在不斷地展現出新的成果,雖然后者在VO 的部分環節表現出比傳統方法效果更好的特點,但其整體性能和傳統幾何方法相比還有差距,依舊存在較大的發展空間。實際應用場景復雜多樣,下一步將針對弱紋理環境中的特征提取問題進行研究,引入線特征策略來提高特征提取的精確度,同時嘗試使用深度學習方法優化前期的圖像數據,從而提高圖像質量。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
