基于3D 卷積神經網絡的動態手勢識別模型
2021-11-18 02:19:24徐訪,黃俊,陳權
計算機工程 2021年11期
徐 訪,黃 俊,陳 權
(重慶郵電大學通信與信息工程學院,重慶 400065)
0 概述
人機交互系統是人與機器之間交流與信息傳遞的橋梁[1]。傳統的人機交互需借助鼠標、觸摸屏、相機等可輸入設備進行,傳遞的信息形式也由早期的編碼字符等發展成圖像、視頻的形式。隨著科技的發展以及人們對智能設備日益增多的應用需求,目前,通過機器識別出肢體動作已成為熱門研究方向之一[2]。
手勢識別方法主要分為基于數據手套及基于視頻數據2 種方法。GRIMES 等[3]于1983 年發明了數據手套,里面的傳感設備將手部運動姿態等物理信息轉化為供計算機使用的數字信息并進行手勢識別。然而數據手套價格昂貴且過度依賴輔助設備,用戶體驗度不佳,難以推廣。在基于視覺數據的方法中,用戶無需佩戴數據手套等設備,僅配備攝像頭就可以實現手勢的識別,且識別的精度及速度均在可接受范圍內。
傳統的基于視覺的動態手勢識別常見模型有隱馬爾科夫模型(HMM)[4]和動態時間規整(DTW)模型[5]。文獻[6]提出一種融合手勢全局運動和手指局部運動的手勢識別模型,根據關節坐標和距離函數提取關鍵幀,利用支持向量機實現動態手勢識別及分類,該模型使用的手勢數據集存在局限性且沒有考慮手勢旋轉的情況;WANG 等[7]提出建立手勢三維軌跡特征向量和手形特征,再將識別結果進行融合的識別模型。雖然該模型能夠提升準確率,但軌跡特征獲取步驟多,處理復雜。整體來說,傳統模型往往需要人工提取特征,少量特征的表征能力相對不足,而對復雜特征進行人工提取操作又十分困難,因此造成基于傳統手勢識別模型和評價指標效果不佳的局面。
近年來,深度學習在目標識別、分類任務等領域被廣泛使用。傳統的2D 卷積網絡對圖像具有很強的特征提取能力,但是不能很好地捕捉圖像間的時序關系,因此在對視頻連續幀的處理上極易丟失目標信息。YU 等[8]提出了3D 卷積網絡(3DCNN)并用于人體行為識別,該網絡克服了傳統2DCNN 在視頻處理上的不足。TRAN 等[9]在3D 卷積神經網絡基礎上提出三維CNN 模型并取得較好的性能,該研究主要提出了一種從視頻片段中提取時空特征的結構。文獻[10]利用多向3D 卷積神經網絡做特征融合并進行手勢識別,為了避免手勢視頻中冗余數據對網絡準確率的影響,利用光流法對視頻進行關鍵幀提取,雖然該模型得到的實驗結果好于均勻采樣法,但該模型需要計算每幀的光流,在實際使用或是長視頻上計算消耗較大,可調參數的范圍有限。
為了從圖像中提取更完整的特征并進行識別和分類,卷積網絡的層數需越來越多。文獻[11-12]將ResC3D 應用于手勢識別任務中并取得了較好效果,這也證明了網絡層次越深,模型的學習能力將會越強。Dense-TCNs 模型[13]將DenseNets 網絡[14]和增強時間卷積網絡(TCNs)應用于手勢識別中并引入時域注意力機制,獲得了較高的準確率,但在噪聲大的數據上模型正確率較低。除了使用RGB 信息外,基于深度圖像的動態手勢識別技術也被廣泛研究[15]。對于視頻序列中的時間信息,常使用LSTM 網絡。文獻[16]使用CNN 網絡和LSTM 網絡相結合的方式進行動態手勢的識別,其中CNN 網絡提取空間特征而LSTM 網絡提取時域特征,這為后續將空間域和時間域分開處理提供了經驗。文獻[17]改進原有的CNN 架構,提出一種具有連續時間分類的R3DCNN 網絡進行手勢識別,該方法雖然對序列信息處理較好,但該方法的模型構造以及預訓練復雜,對于復雜環境不具有魯棒性。而KF+FF 模型[18]首先計算出每一幀的圖像熵,再對熵值做密度聚類計算從而選取關鍵幀,雖然能夠減少原始幀中的冗余信息,但僅針對野外場景,且魯棒性也有待提高。SIMONYAN 等[19]提出一種時空雙流卷積網絡,并分別從RGB 圖像和疊加光流圖像中提取輸入視頻的時間特征和空間特征,最后進行特征融合以實現手勢分類。
在實際應用中,由于動作執行者的個人習慣、反應速度等不同,導致采集到的視頻長度不同,又由于視頻中不含有手勢標志幀,因此識別困難。本文提出一種具有分級網絡結構的動態手勢模型,利用檢測器和分類器分步驟完成識別任務,同時利用卷積核拆分法加快模型的訓練和測試速度。
1 卷積神經網絡
1.1 三維卷積神經網絡
卷積神經網絡結構通常由卷積層、激活函數層、池化層和全連接層組成。而在實際的應用中會根據應用場景的不同對神經網絡的網絡層數和結構做出相應的調整。傳統的2D 卷積神經網絡無法處理或需要與其他網絡組合視頻數據中連續幀的動作,因此本文使用3D 卷積神經網絡對相鄰幀時間維度信息進行處理,3D 卷積過程表示為:
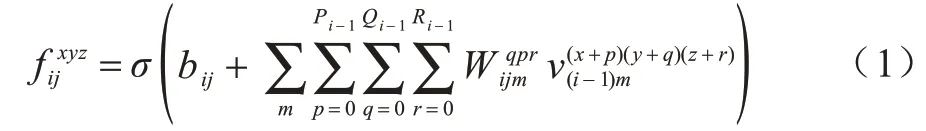
1.2 深度殘差網絡
深度卷積神經網絡的深度對最終的分類結果和識別準確率的影響較大,以往的設計思路是把網絡設計的越深越好,然而實際卻并非如此。實驗結果表明,20層以上的深度網絡,繼續增加網絡的層數,分類的精度反而會降低,50 層網絡的測試誤差率約為20 層網絡的1 倍[20]。主要原因是隨著深度的增加梯度消失現象愈發明顯,網絡效果也隨之下降。HE 等[21]提出深度殘差網絡,在網絡中引入恒等映射的設計,緩解了由于神經網絡深度增加帶來梯度消失和網絡退化的問題。圖1(a)為普通模型使用的堆疊連接方式,其中殘差網絡使用的是用捷徑連接(shortcut connections)方式構建的網絡,如圖1(b)所示。
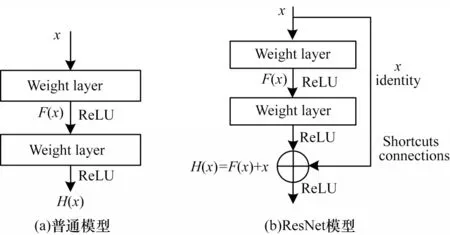
圖1 模型連接方式Fig.1 Model connection method
普通的深層神經網絡輸出結果為:

殘差網絡使用捷徑連接,把輸入x直接傳到輸出端,使得輸出的結果變為:

從式(2)和式(3)可知,普通的深層神經網絡輸出結果需要調整內部參數才能實現恒等映射F(x)=x,而殘差神經網絡的殘差單元在學習一個殘差F(x)=H(x)-x,當F(x)=0 后就可實現恒等映射。在增加模型的訓練速度和效果的同時,網絡的深度也大幅增加。
2 本文動態手勢識別方法
2.1 整體框架
單個完整的動態手勢動作可分為手勢開始、高潮和結束3 個部分,如圖2 所示。

圖2 完整手勢組成Fig.2 Complete gesture composition
針對在不帶有標志幀的手勢視頻上進行動態手勢識別準確率受影響的問題,本文利用傳統模型中分步驟完成任務的思路,將整個模型分為2級。第1級為手勢檢測器網絡模型,第2 級網絡為手勢分類器網絡模型。手勢檢測器模型首先進行實時檢測并判斷輸入視頻中是否包含手勢;之后將手勢檢測的結果保存在緩存隊列中,對緩存結果進行濾波操作;然后判斷是否啟動下一級分類器網絡。一旦第2 級網絡啟動,則能夠保證輸入到第2 級網絡的視頻段為手勢高潮部分,從而保證第2 級網絡提取圖像信息的有用性,避免不帶標志幀視頻中手勢開始和結束部分的冗余數據對手勢分類準確率造成影響。本文所提模型的整體框架如圖3 所示。
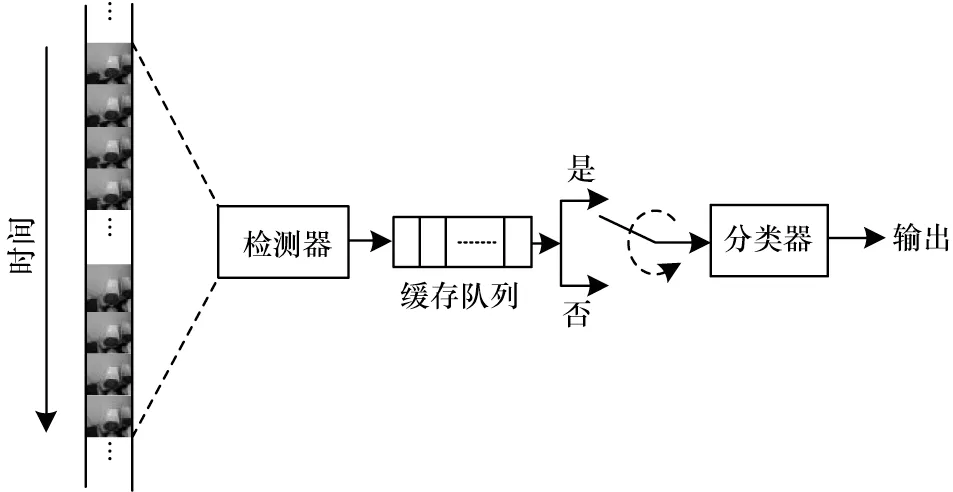
圖3 本文動態手勢識別模型整體框架Fig.3 Overall framework of dynamic gesture recognition model in this paper
2.2 卷積核拆分
由于3D 卷積核有3 個維度的信息,與傳統的2D卷積核相比,3D 卷積神經網絡的參數增加,這導致模型訓練時間變長、訓練速度變慢。本文受Inception-v3 模 型[22]中 將3×3 卷積核 分解為3×1 和1×3 這2 種卷積核從而加快模型訓練速度的啟發,將3D 卷積核拆分成如圖4 所示2 種卷積核的形式。圖4 中的t代表卷積核的時間維度,而w和h分別代表卷積核的寬度和高度。將尺寸為t×h×w的3D 卷積核拆分為1×h×w卷積核和t×1×1 卷積核形式,這兩種卷積核分別對輸入的視頻流進行操作,其中1×h×w卷積核對視頻流中的每幀圖像進行二維特征提取,而t×1×1 卷積核對視頻流進行深度卷積,提取相鄰運動幀之間的信息。

圖4 3D 卷積核拆分示意圖Fig.4 3D convolution kernel split diagram
本文改進網絡使用的基本結構如圖5 所示。輸入的視頻數據被分成2 部處理,對其中的左半部分提取空間域特征,對右半部分提取運行特征。原始輸入經過1×1×1 卷積核進行卷積操作后,可以使相加運算的特征圖個數相等。三維殘差網絡中基礎塊原有的3×3×3 卷積核參數個數為27 個,本文將卷積核進行拆分改進后的參數個數為2×(1×3×3+3×1×1)=24 個,卷積核的參數數量下降了11.11%。因此,改進后的3D 卷積核參數及整個網絡的參數將會減少,網絡訓練和測試的速度得以加快。
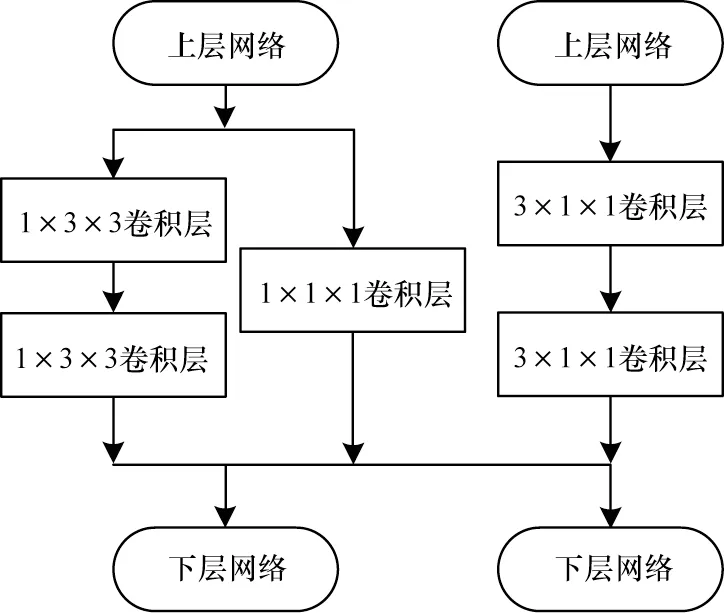
圖5 網絡基本結構Fig.5 Basic network structure
2.3 檢測器網絡結構設計
檢測器網絡需從手勢開始到結束保持工作狀態。與常見的18 層、34 層或更深的殘差網絡不同,本文所提檢測器網絡處在整個網絡的第1 級,故需要輕量級的檢測器模型從而保證較高的識別速度及準確率。因此,本文在深度殘差結構上改進以滿足對檢測器性能的要求,整個檢測器的層數為10,網絡結構如圖6 所示。

圖6 檢測器網絡結構Fig.6 Detector network structure
檢測器網絡的輸入由連續的N幀圖像組成,每一幀圖像的高度和寬度均為112 像素。公共卷積層Conv 的卷積核尺寸為3×7×7。為保留時間維度上的信息,本文只在空間維度上進行2×2 的下采樣,第一個池化層使用步長為2 的最大池化,其余卷積層Layer1、Layer2、Layer3、Layer4 的模塊個數均為1。F為進行卷積操作后的特征通道數,通道數分別為16、32、64、128 個,網絡在經過所有卷積層、平均池化層和全連接層后,被送入Softmax 分類器中進行有無手勢的判斷。
本文在單次卷積操作之后均加入批量歸一化,使得每層神經網絡在訓練過程中的平均值保持為0,方差保持為1,這樣有利于提高網絡的收斂速度,也可避免手勢離開相機視野等情況造成檢測器網絡誤判,從而降低整個分級網絡的整體性能。本文使用緩沖隊列保存檢測器網絡的原始結果,將檢測器網絡中本次檢測結果和前3 次結果進行中值濾波處理,從而獲得檢測器網絡的最終決策結果,并根據該結果判斷是否開啟下一級分類網絡。
2.4 分類器網絡結構設計
目前在圖像或視頻分類領域有諸多性能優異的模型,比如LeNet5、AlexNet、ResNet 等網絡模型。本文的分類器網絡在ResNeXt 模型上進行改進,ResNeXt 網絡將 原來基 礎模塊中的2 個3×3×3 卷 積核,先用1×1×1 卷積降維,然后用3×3×3 進行卷積,最后再用1×1×1 升維,以保證模型的精度,同時又減少了整體的參數數量。在此基礎上,本文將ResNeXt網絡基礎塊中的3×3×3 卷積核進一步拆分,以降低網絡的參數,從而加速網絡訓練和測試。
本文中分類器網絡的結構模型和檢測器網絡大致相同,但是卷積層Layer1、Layer2、Layer3、Layer4的塊個數Block_Num 分別為3、24、36、3。每個卷積層對應的輸出特征通道數F分別為:256、512、1 024、2 048。最后經過2 層全連接層送入到Softmax 分類器中進行手勢的分類。分類器網絡模型的參數如表1 所示。
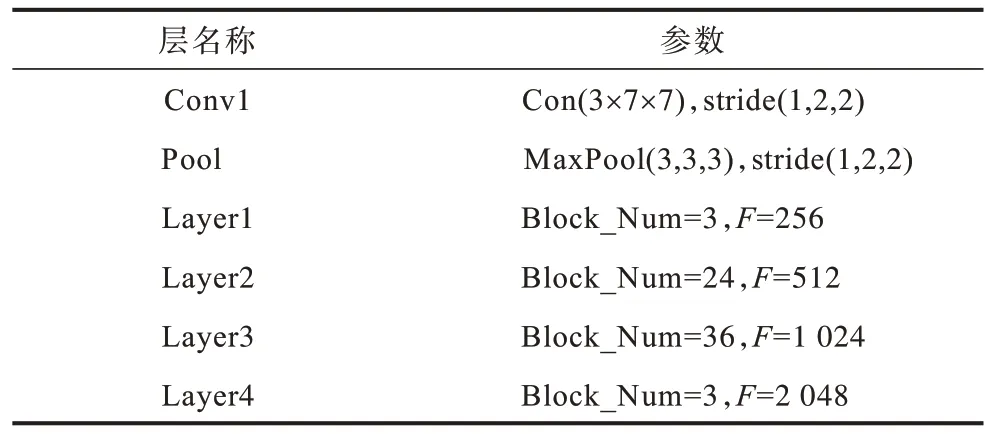
表1 分類器網絡參數設置Table 1 Classifier network parameter settings
3 實驗結果與分析
3.1 數據集
本文模型先在Jester 數據集[23]上進行預訓練,然后遷移到文獻[24]制作的EgoGesture 數據集上進行微調操作,最后與文獻中所述的VGG 網絡和C3D 網絡進行對比。EgoGesture 數據集包含83 類來自50 個不同 主體的2 081 個RGB-D 視 頻、24 161 個 手勢樣本和2 953 224 幀圖像。手勢的平均持續時間為38 幀。數據集按3∶1∶1 比例分為1 239 個訓練集視頻、411 個驗證集視頻和431 個測試集視頻,分別具有14 416、4 768 和4 977 個手勢樣本。單個手勢視頻帶有手勢起始幀和手勢結束幀標注。為得到不帶標志幀的數據集,人為地將原有的開始和結束標志幀去除,從而得到帶標注幀和不帶標注幀的2 個EgoGesture 數據集。
3.2 實驗環境
本文實驗采用的硬件環境為NVIDIA GeForce GTX 1080Ti 11 GB 顯 卡、Intel i7-8700K 6 核CPU、16 GB DDR4 內存;軟件平臺為Ubuntu18.04 操作系統,Python 3.6.10 版;PyTorch 為1.3.1;CUDA10.1.105版;cuDNN7.6.4。
3.3 模型參數
在檢測器模型和分類模型的訓練和測試時每個圖像的尺寸被隨機剪裁為112 像素×112 像素,并在整個手勢視頻的輸入中進行連續幀采樣,同時將整個訓練集圖像進行歸一化操作。由于3D 卷積神經網絡需要大量的訓練數據,為了避免過擬合,將模型訓練中的損失函數定為交叉熵,并采用隨機梯度下降(Stochastic Gradient Descent,SGD)算法進行參數優化。由于SGD 每次更新并不全會按照正確的方向進行,常存在波動的情況,使得收斂速度變慢。因此,將學習速率設置為0.01,每經過10 次迭代,學習率減小為原來的1/10。為選取最佳的L2 正則化參數λ,本文選取常用的λ參數0.1、0.01、0.001、0.000 1,分別對不同的參數進行5 折交叉驗證。將訓練集和驗證集中的40 個subjects 劃分為5 個子集,每個子集包含8 個subjects。其中分組1 的訓練集為子集1~子集4,驗證集為子集5;分組2 的訓練集為子集1~子集3和子集5,驗證集為子集4;依次至分組5 訓練集為子集2~子集5,驗證集為子集1。對不同λ參數和每個分組在驗證集上得到的結果如表2 所示。
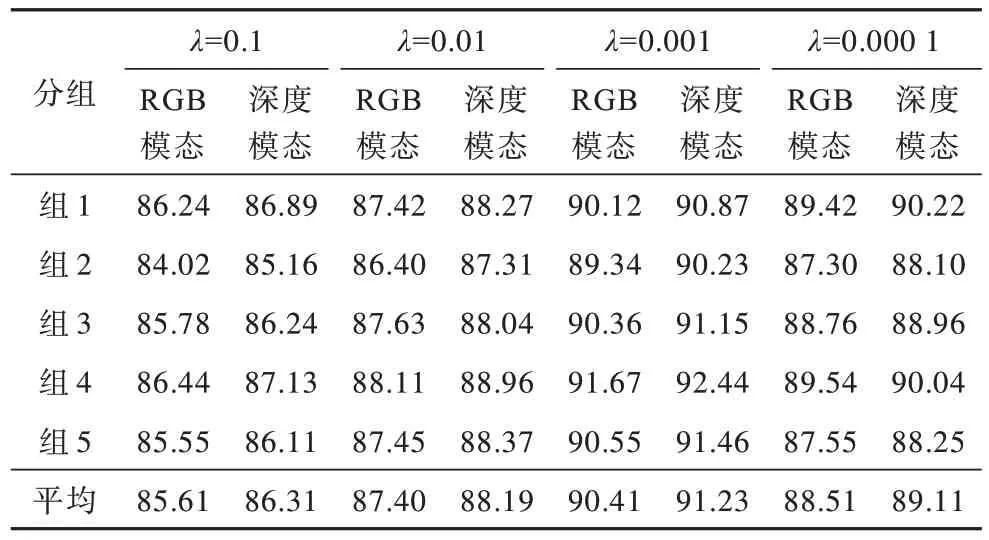
表2 不同λ 下的實驗準確率Table 2 Experimental accuracy rate of different λ %
從表2 可知,不同的λ參數在驗證集上得到的平均準確率存在較大區別。平均準確率隨著λ參數的減小呈現先升后減的變化趨勢。本文中選取λ=0.001 可以使在驗證集上的平均準確率最大。
3.4 卷積特征圖
對空間數據流卷積后的特征圖進行可視化,視頻幀原圖如圖7 所示。對于前面的卷積層來說,學習的是圖像的淺層特征,越往后的卷積層學習到的特征越高級。本文選取分類器第1 層的空間域卷積核進行特征可視化,此層存在256 個特征圖,本文選取了其中64 個進行可視化。分析可視化特征圖可知,空間卷積核能夠有效提取視頻幀的不同特征,如圖8 所示。

圖7 視頻幀原圖Fig.7 Original image of video frame

圖8 卷積特征Fig.8 Convolution feature
3.5 檢測器性能驗證
本文數據集手勢平均持續時間為38 幀,因此本文在測試時選取最大輸入幀數為32。表3 為檢測器模型在不同條件下的性能表。從表3 可以看出,本文設計的檢測器在手勢的檢測上準確率達到99.61%。實驗結果表明,隨著輸入幀數的增大,檢測器模型的準確率有所提升但幅度有限,且上升幅度呈減小趨勢,這與本文所選取數據集的平均手勢持續時間有關。從表3 中還可得知,在深度圖像模態下,模型識別準確率均比RGB 模態下的要高,這是由于深度圖像能夠有效去除背景環境中光照、顏色等噪音干擾,使模型能更順利地獲取區別特征。
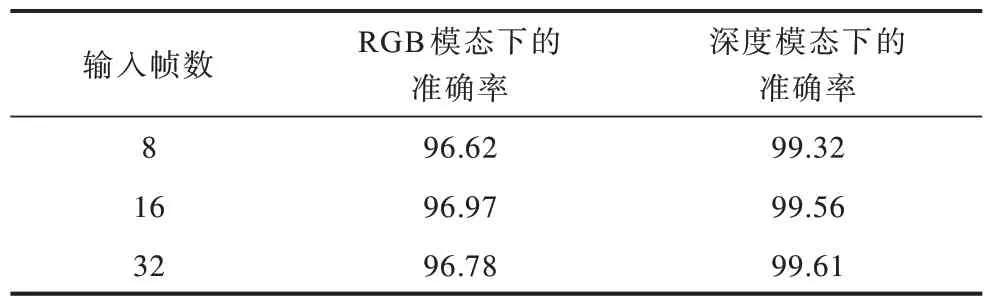
表3 本文檢測器模型在不同條件下的性能Table 3 Performance of the detector model in this paper under different conditions %
3.6 標志幀對分類器模型的影響
由于本文第1 級和第2 級網絡分別處理不同階段手勢,因此本文分類器模型不依賴于第1 級網絡,可以單獨進行手勢的分類操作。針對有無標志幀手勢視頻對識別準確率造成影響的問題,本文將所設計的分類器模型與其他現有的分類模型在2 個EgoGesture 數據集上進行對比實驗,實驗結果如表4所示。
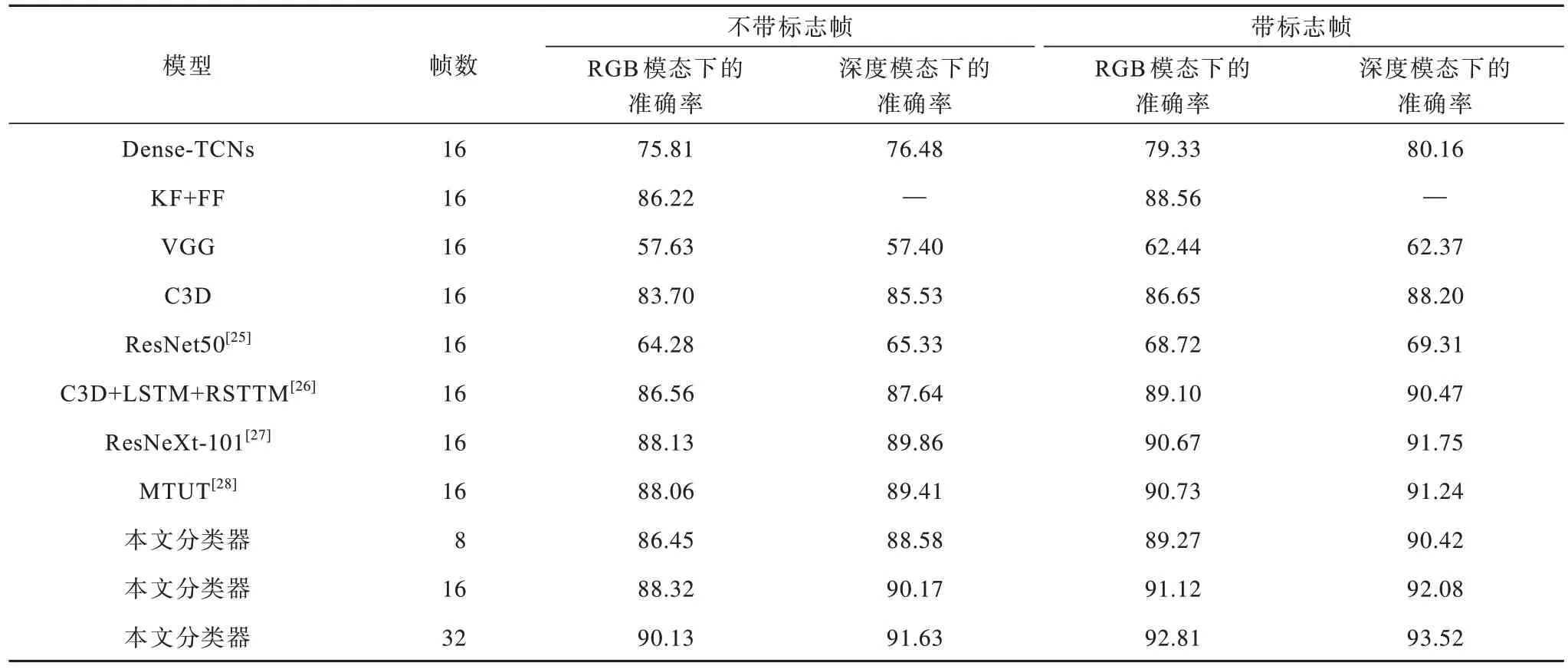
表4 標志幀對不同分類器模型的影響Table 4 Affected flag frame of different classifier models %
從表4 可以看出,Dense-TCNs 模型利用DenseNet 和TCNs 網絡分別提取空域特征和時域特征,相對于經典模型的準確率有所提升。KF+FF 模型通過使用關鍵幀提取和特征融合方法提高了在RGB 模態上的準確率。VGG 模型和C3D 模型均屬于經典模型,但二維VGG 和ResNet-50 模型無法處理時間域信息,導致其準確率遠低于C3D 模型。C3D+LSTM+RSTTM 模型能夠處理序列信息,這使得識別準確率大幅提高。3D 形式的ResNeXt101 模型利用深度殘差網絡的性能優勢,在帶標志幀的數據集上的準確率達到90.67%和91.75%。MTUT 則將多模態網絡信息嵌入到單模態網絡,從而使單模態網絡達到較高的準確率。此外,對于含有標注手勢起始幀和手勢結束幀的輸入視頻流,模型的識別準確率高于不帶有標注幀的,這是因為帶有標志幀的視頻流中已去除了非手勢高潮部分的同時,去除了手勢開始或結束階段中冗余數據和其他干擾,使最終的識別準確率得以提高。這表明對于不帶有標志幀的視頻數據,視頻中的非核心部分將對最終的識別準確率造成較大影響。由于深度模態輸入去除了背景中的干擾信息,因此識別準確率高于在RGB 模態下的準確率。本文設計的分類器隨著輸入的幀數的增加,識別準確率增加的幅度在逐漸減小,這與本文選取數據集的平均手勢持續時間有關。由此可知,單純增加輸入幀數對提升準確率作用不大。
3.7 本文模型性能驗證
從表3 可以看出,檢測器的輸入幀數對檢測器最終識別準確率的影響不明顯。因此本文在整體性能測試時,選取檢測器輸入幀數為8,在不帶有手勢起始和結束標志幀的數據集上對本文所提模型的整體性能測試結果如圖9(a)、圖9(b)所示。從圖9(a)可以看出,在RGB 模態下由于模型使用了預訓練加速,準確率在早期上升較快,但在經歷30 個周期后準確率趨于穩定,不同輸入幀數的準確率高達92.67%。而在圖9(b)所示的深度模態下,在經歷25 個周期后,模型的準確率趨于穩定,準確率高達93.35%。表5 所示為對本文所提模型整體測試的準確率結果。

表5 本文所提模型準確率Table 5 Accuracy rate of the method proposed in this article
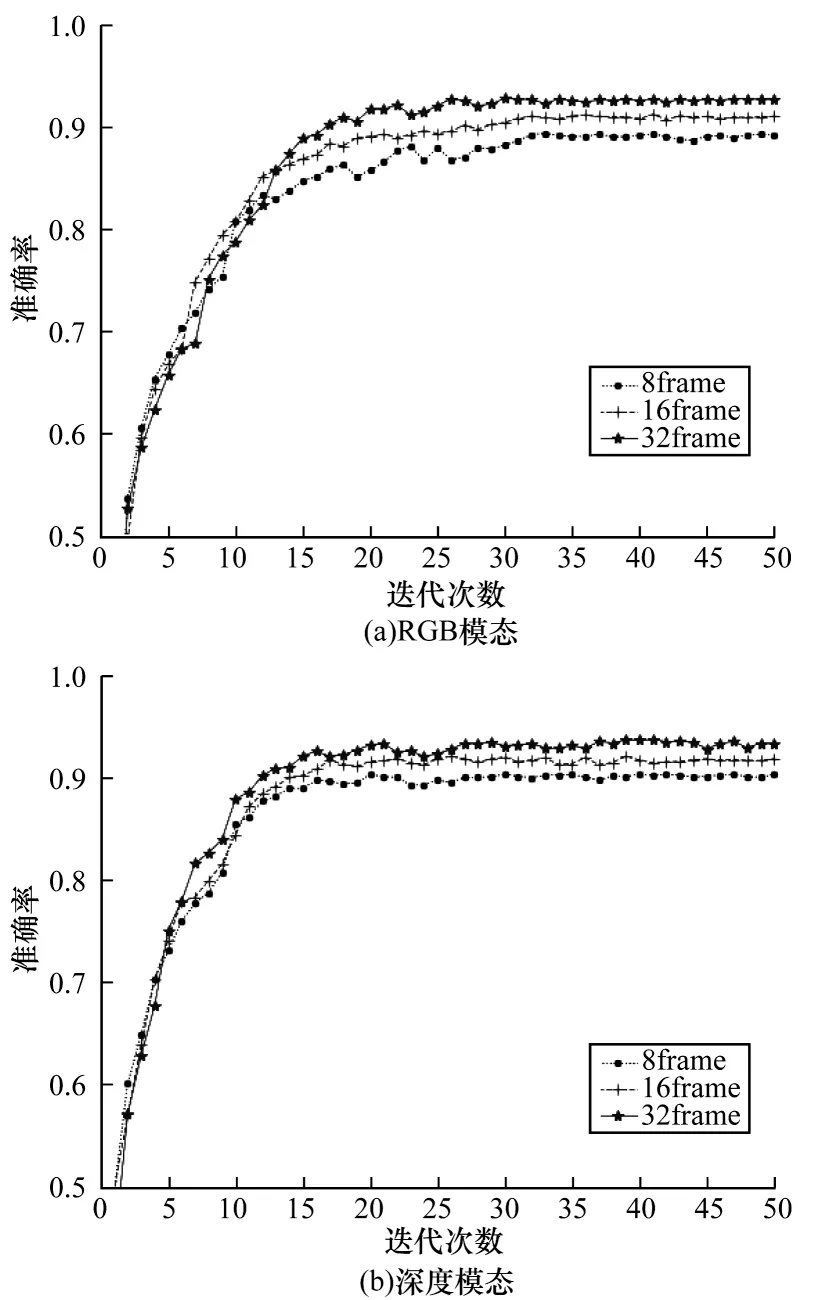
圖9 不同條件下模型準確率變化Fig.9 Model accuracy rate change under different conditions
結合表4 和表5 可知,與只使用分類器相比,本文提出使用分級網絡的模型在不帶有標志幀的數據集上識別準確率有較高的提升。此外,由于檢測器對手勢起始階段的檢測仍存在偏差,因此本文模型在識別準確率上要略低于帶標志幀的輸入視頻準確率,但兩者差距較小,可以證明本文提出分級網絡模型的有效性。
3.8 不同模型對比
本文選取檢測器網絡的輸入幀數為8,將本文所提模型和現有的模型在不帶標志幀的數據集EgoGesture 上,以固定輸入16 幀的條件進行了對比實驗,結果如表6 所示。實驗結果表明,本文所提模型在不帶有標志幀的EgoGesture 數據集上優于現有模型。

表6 不同模型準確率對比Table 6 Accuracy comparison of different model
Dense-TCNs 模型由于提取短時時空特征時依賴DenseNets 網絡的正確率,導致準確率較低。KF+FF模型雖然在野外場景下的小型數據集上取得了極高的準確率,但由于魯棒性較差,導致該模型在本文數據集包含的6 個室內外場景上準確率為86.22%,與本文所提方法相差4.74 個百分點。VGG 模型由于使用了對時間域信息缺乏處理能力的2D 卷積神經網絡,導致準確率低于60%。C3D 模型利用3D 卷積對時空域良好的學習能力提高了準確率,在RGB 模態和深度模態下的準確率分別達到了83.70% 和85.53%,但與本文模型相比仍有差距,分別下降了7.26、6.29 個百分 點。ResNet50+HandPoseNet 模 型從姿態提取網絡中獲得手勢的坐標信息并進行特征融合,大大提升了識別準確率;C3D+LSTM+RSTTM模型采取C3D 網絡結合LSTM、遞歸時空變換模塊RSTTM 的方法,利用遞歸時空變換模塊能夠將特征圖轉換為更易分類的規范圖特點提升了準確率,使該模型和本文模型的差距均縮小至4 個百分點左右。ResNeXt-101 模型由于深度殘差網絡良好的性能,在RGB 模態和深度模態下的準確率分別高達87.92%和89.86%。MUTU 模型則利用多模態網絡信息并將多模態信息嵌入到單模態網絡,提升了單模態網絡的準確率,但和本文相比還存在一定差距。
本文提出一種具有分級結構的識別模型,將手勢檢測網絡為第1 級,手勢分類網絡為第2 級。第1 級網絡作為下級網絡的啟動開關,保證了輸入到第2 級網絡視頻流中圖像信息的有用性和提取網絡的完整性。在不帶標志幀的EgoGesture 數據集上,與其他模型相比準確率達到最高水平,說明本文所提模型在不帶標志幀的動態手勢識別方面具有一定的優越性。
3.9 耗時性分析
本文所提模型將識別任務分成2 個階段,且采取三維卷積神經網絡參數較多,可能對模型的整體耗時產生影響。此外,由于本文檢測器使用ResNet網絡,而分類器模型主要在深度殘差網絡上進行改進,因此本文選取了ResNeXt101 模型進行耗時性分析。在相同的超參數設置情況下,對模型的訓練時間(epochs=10)以及對識別速率進行驗證,實驗結果如表7 所示。

表7 與ResNeXt101 模型的對比Table 7 Comparison with ResNeXt101 network
通過對比訓練時間可知,本文提出對3D 卷積核進行拆分的模型相對原有的ResNeXt101 模型減少了6.18%的訓練時間,但本文的分級網絡模型使網絡整體的訓練時間增加了1.93%,增加的部分時間主要由第1 級檢測器網絡對手勢檢測引起的。雖然本文所提模型在識別的速度上略有下降,但是仍可滿足實時性的要求。
4 結束語
在不帶有標志幀的手勢視頻上進行動態手勢識別會導致準確率下降。針對該問題,本文提出一種使用分級網絡完成識別任務的手勢識別模型。通過拆分3D卷積核避免3D卷積核參數過多和模型訓練時間過長。實驗結果表明,本文模型能有效縮短模型訓練時間,識別速度滿足實時性要求,且準確率優于Dense-TCNs、KF+FF、VGG 等模型。由于單一的RGB 數據或深度數據使模型對手勢的認識仍存在一定偏差,因此,下一步將對模型進行特征融合以提高識別率和泛化能力,此外,還將擴展其在連續動態手勢識別場景下的應用范圍。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
