基于YOLOv4-tiny改進的輕量級口罩檢測算法
2021-11-12 00:47:16王建立
液晶與顯示 2021年11期
朱 杰,王建立,王 斌
(1. 中國科學院 長春光學精密機械與物理研究所,吉林 長春 130033;2. 中國科學院大學,北京 100049)
1 引 言
新冠病毒席卷全球的當下,在機場、車站等公共場所佩戴口罩可以有效降低病毒的傳播概率,防止疫情的擴散。目前國內外的公共場所對人流的口罩佩戴情況的監測手段主要以人工監督為主,廣播呼吁為輔,這種手段效率低下的同時也浪費了大量公共資源。而近幾年人工智能技術日新月異,尤其是目標檢測領域大量優秀算法的涌現,例如YOLO[1-5]系列為代表的單階段算法以及RCNN[6-8]系列為代表的兩階段算法,讓我們可以通過計算機搭配監控攝像頭就能實現人流口罩佩戴情況的自動化監測。
目前,專門應用于口罩檢測的數據集和算法都相對較少。Cabani等人[9]提出了一個包含13萬張圖像的大規模口罩檢測數據集,但是該數據集的圖像目標和人物背景都相對單一,對現實場景的覆蓋面嚴重不足。Wang等人[10]提出了一個口罩人臉數據集 (Real-World Masked Face Dataset,RMFD),不過該數據集的場景覆蓋面依舊不充分,更重要的是公開的數據標注并不完善,難以直接應用于口罩檢測任務。牛作東等人[11]在人臉檢測算法RetinaFace中引入注意力進行機制優化,然后應用于口罩檢測任務,取得了不錯的平均精度均值 (mean Average Precision,mAP),但是算法的每秒傳輸幀數 (Frames Per Second,FPS)相對較低,很難滿足口罩檢測任務的實時性要求。王藝皓等人[12]在YOLOv3[3]算法中引入空間金字塔結構改進后用于口罩檢測任務,實現了mAP和FPS指標的小幅提升,不過算法數據集的背景相對單一,難以擴展到復雜的多場景口罩檢測任務中去,而且實時檢測速度依舊不理想。
YOLOv4-tiny由Wang等人于2020年6月發布,在COCO[13]數據集上以443 FPS(on GeForce RTX 2080Ti)的實時檢測速度實現了42.0%的檢測精度[5]。本文對YOLOv4-tiny進行改進和優化,以應用于復雜場景下的口罩檢測任務。保持YOLOv4-tiny的骨干網絡不變,在其后引入空間金字塔池化[14](Spatial Pyramid Pooling,SPP)模塊,對輸入特征層進行多尺度池化并融合,同時大幅增強網絡的感受野。利用路徑聚合網絡[15](Path Aggregation Network,PAN)取代YOLOv4-tiny的特征金字塔網絡[16](Feature Pyramid Networks,FPN),分兩條路徑將輸入特征層上采樣和下采樣而來的信息相互融合,以增強特征層對目標的表達能力。使用標簽平滑[17](Label smoothing)策略優化了網絡損失函數,結合Mosaic數據增強[4]和學習率余弦衰退思路,提高了模型的訓練效率。實驗結果表明,本文算法在普通性能的硬件(GeForce GTX 1050Ti)上達到了76.8 FPS的實時檢測速度,在口罩目標和人臉目標上的檢測精度分別達到了94.7%和85.7%,相比YOLOv4-tiny分別提高了4.3%和7.1%,滿足了多種復雜場景下口罩檢測任務的檢測精度與實時性要求。
2 YOLOv4-tiny算法原理
YOLOv4-tiny[5]由YOLOv4[4]進行尺度縮放而來。相比于YOLOv4,YOLOv4-tiny犧牲了一定的檢測精度,但是它的參數量不到前者的10%,推理速度則是前者的6~8倍。
2.1 YOLOv4-tiny的骨干網絡

圖1 YOLOv4-tiny網絡結構Fig.1 YOLOv4-tiny network structure
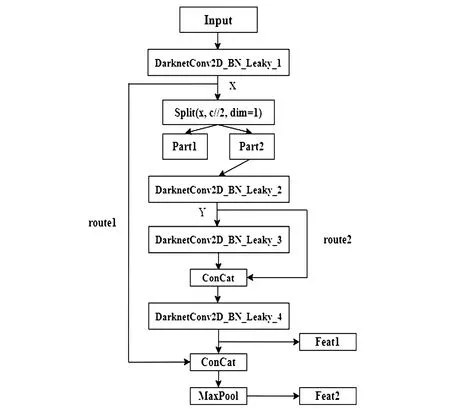
圖2 Resblock_body結構Fig.2 Resblock_body structure
如圖1所示,骨干網絡CSPDarknet53-tiny主要由DarknetConv2D_BN_Leaky模塊和Resblock_body模塊堆疊而成。DarknetConv2D_BN_Leaky模塊結合了二維卷積層、歸一化處理層和激活函數Leaky ReLU。Resblock_body模塊引入了如圖2所示的CSPNet結構[18]:模塊主干部分依舊是殘差塊的常規堆疊,但在分支部分引入了一條大跨度的殘差邊,該殘差邊經少量卷積處理之后直接連接到模塊的最后,與主干部分的輸出在通道維度進行堆疊,最后經2×2的最大池化層處理得到模塊的輸出。CSPNet結構在減少10%~30%的網絡參數量的同時,能夠保證模型準確率基本不變或者稍有提高。圖2中的Feat1和Feat2為Resblock_body模塊輸出的初始特征層。骨干網絡CSPDarknet53-tiny中的前兩個Resblock_body模塊輸出的初始特征層Feat1會被直接丟棄,Feat2則作為后一個Resblock_body模塊的輸入。對于第三個Resblock_body模塊的輸出Feat1和Feat2:Feat1直接作為特征增強網絡FPN的第一個輸入,Feat2經DarknetConv2D_BN_Leaky模塊處理后作為FPN的第二個輸入。第三個Resblock_body模塊的輸出Feat1和Feat2的尺寸分別是(256,38,38)和(512,19,19),其中,第一維的256或512代表的是特征層的通道數,后面兩個維度38×38或19×19代表的是特征層的高和寬。
2.2 YOLOv4-tiny的特征增強網絡
如圖1所示,YOLOv4-tiny使用FPN作為特征增強網絡。FPN的兩個輸入Feat1和Feat2的尺寸分別為(256,38,38)和(512,19,19)。FPN分兩個步驟構建特征金字塔:
1. Feat2經1×1卷積(Conv)處理之后得到FPN的第一個輸出P1(256,19,19);
2. P1再經1×1的卷積處理和上采樣處理之后與Feat1在通道維度進行堆疊,得到FPN的第二個輸出P2(384,38,38)。
最后,FPN模塊的兩個輸出P1和P2再經少量卷積處理即可得到用于邊界框預測的兩個預測特征層Yolo Head1(21,38,38)和Yolo Head2(21,19,19)。YOLOv4-tiny的FPN模塊構造非常簡單,甚至過于簡單,特征層的融合僅僅體現在單一的上采樣之后的特征層堆疊,這為YOLOv4-tiny帶來了非常優秀的實時檢測速度(COCO:443 FPS on RTX 2080Ti),但也為YOLOv4-tiny帶來了網絡整體感受野過弱、特征融合不充分以及對骨干網絡提取到的特征信息利用率過低等缺點,使其難以適應復雜場景下包含小目標或者遮擋目標的檢測任務。
3 改進的YOLOv4-tiny算法
本文對YOLOv4-tiny進行了一系列改進:在骨干網絡之后引入了SPP模塊,利用PAN結構代替FPN作為特征增強網絡,使用標簽平滑策略對網絡損失函數進行了優化,并結合Mosaic數據增強和學習率余弦衰退策略進行模型訓練。
3.1 空間金字塔池化
一般來說,可以使用剪裁或扭曲等方法改變輸入圖像的尺寸以滿足卷積神經網絡中分類器層(全連接層)的固定尺寸輸入要求,但是這也會帶來剪裁區域未覆蓋完整目標或者圖像畸變等問題。為了應對上述問題,He等人[14]提出了空間金字塔池化(SPP)網絡,可以對多尺度提取的特征層進行池化和融合,并得到固定尺寸的輸出。本文在YOLOv4-tiny的骨干網絡之后引入SPP模塊以實現從細粒度到粗粒度的多尺度特征融合,增強特征層對目標的表達能力。本文改進后的算法網絡結構如圖3所示,可以看到,骨干網絡CSPDarknet53-tiny的第二個輸出特征層會先經SPP模塊處理后再輸入改進的特征增強網絡PAN。
如圖3所示,SPP模塊處理步驟為:首先,輸入特征層經過3次卷積處理(卷積核大小分別為1×1、3×3和1×1)后通道數由512降至256;然后,使用3個池化層(核大小分別為3×3、7×7和11×11)進行最大池化處理,每個池化層的輸出通道數均為256;再將上一步的輸入與3個池化層處理后的輸出在通道維度進行堆疊,通道數變為1 024;最后,經過又一次3次卷積處理,SPP模塊輸出的通道數由1 024恢復至256。SPP模塊在對輸入特征層進行多尺度池化并融合的同時,也大幅增強了網絡的感受野,對輸入特征層的信息提取更為充分。

圖3 改進的YOLOv4-tiny網絡結構Fig.3 Improved YOLOv4-tiny network structure
3.2 特征增強網絡PAN
如圖1所示,CSPDarknet53-tiny的兩個輸出特征層在轉化為預測特征層YOLO Head之前,會先經過FPN結構進行特征信息的融合。FPN結構對語義信息更豐富的高層次特征層進行上采樣之后,與細節信息更為豐富的低層次特征層在通道維度進行堆疊,以達成特征融合的目的。但是YOLOv4-tiny的FPN結構過于“簡陋”,導致網絡整體感受野過弱,對細節信息的利用率過低,在面對復雜場景下的小目標或遮擋目標時的表現并不理想。
為了應對上述問題,本文算法使用路徑聚合網絡(PAN)作為特征增強網絡。如圖3所示,相比FPN,PAN的特征反復提取、相互融合的策略更加復雜,包含了自下而上和自上而下兩條特征融合的路徑。可以看到,PAN一樣有兩個輸入特征層,F1來自骨干網絡CSPDarknet53-tiny的第三個Resblock_body模塊,F2則來自SPP模塊。在自下而上的融合路徑里,輸入F2經1*1的卷積處理和上采樣處理之后,與同樣經過卷積處理的輸入F1在通道維度進行堆疊,特征層的通道數由128上升至256;該特征層經過3次卷積處理(卷積核大小分別為1×1、3×3和1×1)之后,得到PAN的第一個輸出。類似地,在自上而下的路徑里,第一條路徑的輸出在經過下采樣完成高和寬的壓縮之后與輸入F2在通道維度進行堆疊,再經過3次卷積處理之后得到PAN的第二個輸出。預測特征層YOLO Head由一個卷積核大小為3×3的DarknetConv2D_BN_Leaky模塊和一個卷積核大小為1×1的普通二維卷積層相連而成,其輸出數據主要用于先驗框的參數調整。PAN的特征融合策略里,來自不同尺度的特征相互融合、反復增強,充分利用骨干網絡提取到的細節信息,大幅提升了預測特征層對目標的表達能力。
3.3 算法的損失函數
目標檢測的損失函數一般包括3個部分,邊界框定位損失Lloc、預測類別損失Lcls和置信度損失Lconf。整體的網絡損失L的計算公式如下:
L=Lloc+Lcls+Lconf,
(1)
邊界框定位損失Lloc用于衡量預測框與真實框的位置(包括高、寬和中心坐標等)誤差,交并比(Intersection over Union,IoU)是目前最常用的評估指標,計算公式如下:
(2)
其中,B=(x,y,w,h)表示預測框的位置,Bgt=(xgt,ygt,wgt,hgt)表示真實框的位置。但是IoU損失僅在兩邊界框之間有重疊部分時生效,而對于非重疊的情形,IoU損失不會提供任何可供傳遞的梯度。Zheng等人[19]提出了Complete IoU(CIoU)損失函數,綜合考慮邊界框之間的重疊面積、中心點距離以及長寬比等幾何因素,使邊界框的回歸相比IoU更加穩定。本文算法將CIoU引入邊框回歸的損失函數Lloc,計算公式如下:
(3)
其中,ρ2(B,Bgt)表示預測框和真實框的中心點之間的歐氏距離,d表示包含預測框和真實框的最小閉包區域的對角線距離,α是權重參數,v是衡量長寬比一致性的參數,α和v的計算公式如下:
(4)
(5)
則邊界框定位損失函數Lloc為:
(6)
預測類別損失Lcls用于衡量預測框與真實框的類別誤差,采用交叉熵損失函數進行衡量:
(7)

(8)
其中,δ為標簽平滑超參數,取0.05。
置信度損失Lconf同樣采用交叉熵損失函數進行衡量,計算公式如下:
(9)

4 實驗結果與分析
4.1 數據集
目前專門應用于口罩檢測的公開數據集相對較少。本文從CMFD[9]和RMFD[10]中分別選取了3 800和4 200張圖像,并結合互聯網圖像爬取,建立了包含13 324張多場景圖像及標注的口罩檢測數據集。考慮到口罩目標的特殊性,數據集中還特意加入了約250張佩戴面巾、頭巾等遮擋物或者手部捂臉的圖像,以增強模型的泛化能力與實用性。模型訓練之前,隨機選取20%的數據(2 665張圖像)作為測試集;訓練過程中,以9∶1的比例劃分訓練集與驗證集,并采用隨機的剪裁、圖像翻轉、色域變換和Mosaic等數據增強方式增加訓練樣本的多樣性,提高模型的魯棒性。如圖4(d)所示,Mosaic拼接方式隨機選取4張圖片進行拼接,然后輸入網絡進行訓練,可以有效豐富檢測目標的背景。
4.2 評價指標
本文采用平均精度均值(mAP)和每秒傳輸幀數(FPS)分別作為算法檢測精度和檢測速度的評價指標。
在口罩檢測任務中,mAP即為口罩目標和人臉目標的平均精度(AP)的均值,如式(10)所示:
(10)
其中,N為類別數,i表示某一類別。某一類別i的AP計算公式如下:

(11)
其中,P(R)是精確率(Precision,P)與召回率(Recall,R)之間的映射關系,常用P-R曲線表示,曲線下方的區域面積即為該類別AP值。精確率和召回率的計算方式如下:
(12)
(13)
其中,TP表示檢測類別與真實標簽均為i的樣本數量,FP表示檢測類別為i與真實標簽不為i的樣本數量,FN表示檢測類別不為i但真實標簽為i的樣本數量。


圖4 數據增強示例Fig.4 Examples of data augmentation
FPS指的是網絡模型每秒能夠檢測的圖像幀數,常用于衡量模型的推理速度。FPS的計算過程主要考慮了模型前向計算、閾值篩選和非極大值抑制幾個步驟。
4.3 實驗設置
本文算法在基于Python 3.7的Ubuntu 18.04環境下使用PyTorch1.7.0框架實現,在桌面工作站(AMD Ryzen 3600x CPU @ 3.60 GHz,GeForce RTX 2080Ti)上進行訓練,并在個人電腦(Intel Core i5-8300H CPU @ 2.30 GHz,GeForce GTX 1050Ti)上進行測試。訓練時,使用COCO數據集上預訓練的YOLOv4-tiny模型對骨干網絡的參數進行初始化,以獲得更好的模型初始性能。網絡輸入尺寸為608×608,優化器選擇Adam,訓練過程分兩個階段:第一階段凍結骨干網絡,訓練剩余網絡參數,初始學習率為1e-3,批量大小為128,學習率調整策略為余弦衰退策略CosineAnnealingLR(T_max=5, eta_min=1e-5),其中T_max表示余弦函數的周期,eta_min表示學習率的最小值,訓練50輪次;第二階段解凍骨干網絡,訓練所有網絡參數,初始學習率為1e-4,批量大小為32,學習率調整策略與第一階段一致,訓練100輪次。
4.4 結果分析
本文算法和YOLOv4-tiny(在相同環境下以相同方式訓練)對口罩目標和人臉目標檢測結果的P-R曲線如圖5所示。可以看到,不管是對口罩目標還是人臉目標,本文算法的檢測性能均優于YOLOv4-tiny(P-R曲線越靠右,代表檢測效果越好)。
圖6則列出了YOLOv4-tiny和本文算法的檢測結果對比,可以看到,YOLOv4-tiny對于小目標或者遮擋目標存在一定的漏檢或錯檢情況,尤其是對遮擋目標,YOLOv4-tiny的適應性明顯較弱,而本文算法不管是檢測準確率還是檢測結果的置信度都明顯高于YOLOv4-tiny。

(a) 口罩檢測P-R曲線(a) P-R curves of mask detection

(b) 人臉檢測P-R曲線(b) P-R curves of face detection圖5 YOLOv4-tiny和本文算法的P-R曲線對比Fig.5 Comparison of P-R curves between YOLOv4-tiny and the proposed algorithm

(a) YOLOv4-tiny 算法1(a) YOLOv4-tiny algorithm 1

(b) 本文算法1(b) Proposed algorithm in this paper 1

(c) YOLOv4-tiny算法2(c) YOLOv4-tiny algorithm 2

(d) 本文算法2(d) Proposed algorithm in this paper 2

(e) 本文算法3(e) YOLOv4-tiny algorithm 3

(f) 本文算法3(f) Proposed algorithm in this paper 3
表1列出了本文算法和包括YOLOv4-tiny在內的其他幾種主流目標檢測算法的mAP和FPS指標對比。對于口罩目標和人臉目標,本文算法的檢測AP值分別達到了94.7%和85.7%,相比YOLOv4-tiny分別提高了4.3%和7.1%,具備更高的檢測精度。在檢測速度上,由于本文算法引入了SPP模塊并且使用了更復雜的特征融合策略PAN,增加了網絡的參數量,所以檢測速度略低于YOLOv4-tiny,不過仍然取得了76.8 FPS的實時檢測速度(on GeForce GTX 1050Ti)。相比YOLOv3-tiny,本文算法的mAP則有著11.5%的大幅提升,不管是口罩目標還是人臉目標,本文算法的檢測性能都明顯更優。至于其他非輕量級的單階段目標檢測算法,例如YOLOv3、YOLOv4和SSD[20],YOLOv3和YOLOv4的檢測精度與本文算法相當或稍有提升,SSD(輸入尺寸為512×512)的檢測精度低于本文算法,不過三者的檢測速度均低于18 FPS,不到本文算法的25%,難以滿足口罩檢測任務的實時性要求。而兩階段目標檢測算法的檢測速度則更低:FasterR-CNN[8](以VGG16[21]為骨干網絡)的檢測速度不到5 FPS,檢測精度也低于本文算法4.7%。綜上所述,本文算法以76.8 FPS的實時檢測速度取得了90.2%的平均檢測精度,很好地滿足了口罩檢測任務的精度與實時性要求。

表1 不同檢測算法性能比較Tab.1 Performance comparison of different detection algorithms
4.5 消融實驗
為了研究各個模塊或者訓練策略對模型帶來的影響,設計了如下幾組消融實驗,實驗設置如表2所示。實驗中骨干網絡均為CSPDartnet53-tiny,表中的“√”代表包含該結構或者使用該策略,“×”代表未包含該結構或未使用該策略。可以看到,第1組實驗設置代表了YOLOv4-tiny,mAP值為84.5%;第2組實驗在第1組實驗的基礎上引入了SPP模塊,增強了網絡的感受野,提取多尺度特征并進行融合,對輸入特征層的信息利用更充分,mAP相比第1組實驗提高了2.2%;第3組實驗使用PAN模塊代替第1組(YOLOv4-tiny)中的FPN模塊作為特征增強網絡,分兩條路徑將不同尺度的特征層相互融合、反復增強,mAP相比第1組實驗提高了2.6%;第4組實驗在第3組實驗的基礎上結合了SPP模塊和PAN模塊,mAP相比第3組實驗提高了2.4%,相比第1組實驗提高了5.0%;第5組實驗在第4組實驗的基礎上使用了標簽平滑策略對網絡損失函數進行優化,該策略同樣提高了模型的檢測精度,mAP相比第4組實驗提高了0.7%,相比第1組實驗提高了5.7%。綜上所述,本文算法對YOLOv4-tiny的改進和優化具備合理性和有效性,在口罩檢測任務中提升了原算法的檢測性能。

表2 消融實驗結果比較Tab.2 Comparison of ablation experiment results
5 結 論
為了在公共場所高效監測人流的口罩佩戴情況,本文提出了一種基于YOLOv4-tiny改進的輕量級口罩檢測算法。通過SPP模塊和PAN模塊的引入,以及標簽平滑和Mosaic數據增強等策略的應用,提高了算法在復雜場景下對小目標和遮擋目標的適應能力,在口罩目標和人臉目標上的檢測精度分別達到了94.7%和85.7%,相比YOLOv4-tiny分別提高了4.3%和7.1%,實時檢測速度達到了76.8 FPS(on GeForce GTX 1050Ti),滿足了多種復雜場景下口罩檢測任務的檢測精度與實時性要求。本文算法對人臉目標的檢測精度(85.7%)低于口罩目標的檢測精度(94.7%),主要原因是人臉目標檢測面臨的場景更為復雜多變,需要提取更多的細節信息,而YOLOv4-tiny作為通用目標檢測算法,它的骨干網絡對復雜場景下的人臉目標的適應能力略顯不足,在未來的研究中可以引入注意力機制或者結合專門的人臉檢測算法進行針對性優化。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
