基于多變量小樣本的滲流代理模型及產量預測方法1)
2021-11-10 03:45:24程林松張向陽時俊杰
力學學報 2021年8期
曹 沖 程林松 張向陽 賈 品 時俊杰
(中國石油大學(北京)石油工程學院,北京 102249)
引言
地下流體在多孔介質中的流動往往涉及多尺度、多變量、多物理場的耦合.現有的產量預測方法包括經驗曲線法[1-3]、(半)解析方法[4-6]及數值模擬法[7-11].因為模型的假設條件及方程的局限性,無法真實準確地刻畫實際油藏生產過程,從而造成了產量預測結果不確定性.盡管低滲,特低滲及非常規油氣資源的開發已成為當前研究熱點問題,人們對地下復雜的油氣滲流機理的認識仍不完善[12-15],這也限制了這些傳統方法的適用性.此外,綜合考慮多種力學問題的耦合滲流問題存在機理表征困難,模型求解難度大,計算不收斂等問題.因此,實際油田中的多變量,多尺度和非線性數據給傳統產量預測模型帶來了巨大的挑戰[16-18].
近年來,人工智能技術,大數據分析方法由于其強大的學習及預測能力在工業界得到了廣泛應用.同時,油田中存在的地質?油藏?流體?工藝數據給數據建模技術應用在石油行業提供了可能性.吳新根等[19]應用BP 神經網絡預測羅馬什金油田年產量,與Weng 旋回模型預測結果相比,人工神經網絡是一種可行的石油產量外推預測方法.李留仁等[20]采用3 層BP 神經網絡預測了12 個月的月產油量,預測月產油量誤差在10%以內.邢明海等[21]以多層前饋神經網絡和函數連接神經網絡為基礎,研究了5 種不同的組合方式下的油田總產量.Chithra 等[22]利用高階神經網絡模型預測10 個月的累積產量,誤差在5%以內.高階神經網絡包含傳統神經網絡的線性相關項(突觸操作)及神經輸入與突觸權重的高階相關項(n階相關項).馬林茂等[23]利用遺傳算法優化BP 神經網絡連接權值和閾值,并將該算法用于預測大慶油田BED 試驗區高含水階段的油田產量預測.李彥尊等[24]基于靜態地質,油藏及工程參數,利用人工神經網絡方法預測頁巖油氣的投產5年內的產量.神經網絡強大的預測能力往往依賴于大量樣本數據庫,對于小樣本數據(數據量小于1000)的訓練,容易出現明顯的過擬合現象.而實際油田開發過程中由于區塊限制,記錄不全,操作不當等因素難以獲取較為準確的大量樣本數據.近年來,眾多學者探索了機器學習算法在產量預測中的應用,并取得了一定的效果.Bhattacharya 等[25]和Wang 等[26]等綜合多類型油藏數據,建立機器學習模型,預測頁巖氣單井日產量.宋宣毅等[27]利用隨機森林方法確定了影響產能的主控因素.Xue 等[28]以頁巖氣藏的多段壓裂水平井為例,綜合影響頁巖氣產量的9 個主控參數及生產動態中的最大產氣量數據,對比多目標隨機森林回歸和多輸出回歸鏈算法對日產氣量進行預測.
針對地下流體在多孔介質中的滲流機理復雜,滲流模型求解難度大,產量預測結果不確定性強等問題,本文以特低滲透油藏開發過程中搜集到的小樣本數據為例(樣本量 <1000),探究一種適用于預測產量的數據代理模型,它可以省去復雜物理建模過程,簡化模型求解問題,兼顧計算效率與預測精度.此外,給出了數據代理模型預測產量的詳細流程,并對比分析三種代理模型在產量預測中應用效果.最后,針對小樣本多變量產量預測問題,給出能有效提高模型預測效果的針對性建議,為滲流代理模型在石油行業的應用提供了理論指導.
1 數據建模預測產量流程
滲流代理模型能否準確預測油氣產量往往取決于可靠的油田數據.而真實的油田數據資料往往存在數據跳躍,數據缺失等問題.因此,數據預處理,作為建立代理模型的第一步,能將原始油田數據進行加工、降噪、歸一化等一系列處理形成產量預測數據庫.為了保證計算精度的前提下盡可能節省代理模型的計算時間,模型的超參數優化在數據建模中也至關重要.最后,經過訓練后的最優代理模型能用于油氣產量預測.本文將數據建模技術預測油氣產量的一般流程劃分為數據采集,數據預處理,代理模型建立與優化三個部分,如圖1 所示.

圖1 數據建模技術預測油氣產量的一般流程Fig.1 A general flow of data modeling techniques for predicting oil and gas production
1.1 數據采集
為了獲得準確可靠的產量預測結果,應盡可能廣泛地收集影響油氣產量的油田數據.本文結合地質背景,在充分理解油藏開發規律和生產工藝的基礎上,將影響產量預測的實際油田數據歸為以下八類(如圖2 所示).針對產量預測這類回歸問題,類別數據需通過獨熱編碼技術,圖像數據通過卷積神經網絡轉化后便于代理提取和學習.

圖2 油田數據庫的建立Fig.2 Establishment of oilfield database
1.2 數據預處理
為了使機器學習算法具有更好的預測能力,需要有足夠數量和質量的訓練數據.實際油田數據存在著記錄不完整、數據噪聲大等問題.這些實際數據在輸入機器學習模型進行訓練之前需要進行預處理.本文將數據預處理的過程分為四個部分:數據清理、數據標準化、相關性分析和數據集劈分.數據清理是數據預處理的第一步,其中包括刪除或填充丟失的記錄和異常值,對分類數據進行編碼和對數據集進行平滑處理等.此外,對輸入數據進行標準化是獲得可靠的訓練模型所必不可少的步驟,它可以消除不同維度的變量之間的差異.在訓練滲流代理模型之前,通過均值和方差對數據進行歸一化.特征工程是構建滲流代理模型的基礎,應基于影響石油生產的理論知識和現場專業知識進行初步提取.此外,低相關性的變量會降低模型的準確性,而高相關性的變量會大大降低模型的復雜度并提高預測準確率.因此,變量間的相關性分析和重要性排序對油氣產量預測具有重要意義,可用于主成分分析,灰色關聯分析,隨機森林進行分析.數據劈分是防止模型過擬合并提高模型泛化能力的方法之一.通過從產量預測模型數據集中隨機抽取訓練數據,然后將訓練,測試和驗證數據集通過交叉驗證進行劃分,交叉驗證可用于評估和預測油井的性能.
1.3 代理模型建立與優化
建立數據庫后,將訓練數據輸入到數據驅動的模型中進行訓練,通過優化算法對超參數進行優化.當訓練誤差達到期望值或沒有減少時,可以通過驗證集驗證訓練模型.最后,通過隨機選擇測試數據對模型進行盲測.在本文中,均方誤差(mean square error)Ems和準確率R2被用來評估代理模型,其具體表達式如下

式中,yi表示實際值,yi表示模型預測值,n為樣本量 ,y表示實際值yi平均.
2 理論基礎
2.1 隨機森林(random forest)
決策樹(decision tree)通過拆分預測變量并遞歸劃分數據集來描述因變量與一個或多個自變量之間的關系[29].在決策樹的每個分支上,觀察數據通過自變量的閾值分配給左右路徑.在回歸樹中,通過最小化誤差指標劈分數據集并在葉子節點上獲得預測值.基于CART 樹和裝袋法的隨機森林,通過聚集大量決策樹來近似表征任意復雜的非線性曲面,這使得它成為一個強大的預測工具[30-31],能用于解決復雜的非線性回歸和分類問題.它能從訓練數據集中獲得預定數量的小樣本用于并行估計,通過簡單的參數優化,便可獲得較高的預測精度.如圖3 所示,通過分割每個節點并隨機選擇給定節點的子集來構建隨機森林模型進行訓練,并且未經過剪枝的樹在每個節點處隨機增長.這種隨機化特征使得模型能夠避免過擬合問題.最終預測值是RF 算法中每個決策樹的平均值.此外,隨機森林方法也可以對變量的重要性進行排序,便于抽提產量主控因素,有助于分析油田生產動態分析.
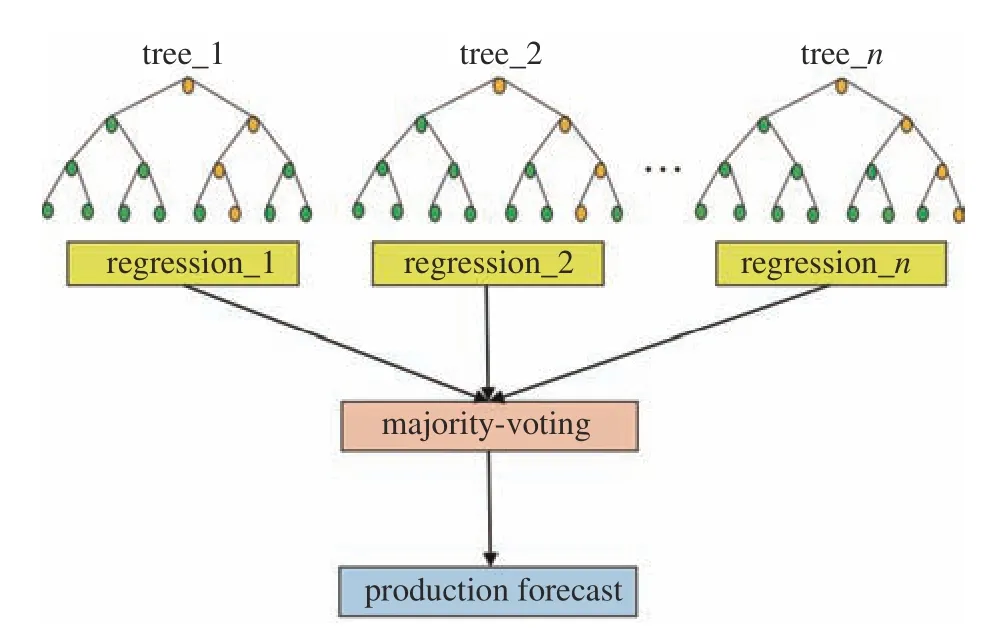
圖3 隨機森林預測產量示意圖Fig.3 Schematic diagram of random forest forecast oil production
2.2 極限梯度提升樹(extreme gradient boosting)
梯度提升樹(gradient boosting decision tree,GBDT)通過多輪迭代,每輪迭代產生一個弱學習器(CART 回歸樹),每個學習器通過降低上一輪的殘差進行訓練[32-33].最終的預測結果通過將每輪訓練得到的弱學習器進行加權求和得到,這種通過集合多個弱學習器形成一個強化模型的集成學習方法能大大減少模型的訓練時間,同時可以有效避免過擬合問題.近年來,由陳天奇等[34-35]提出的極限梯度爬升算法(extreme gradient boosting,XGBoost)對GBDT進行了優化,進一步提升了算法的計算速度和預測性能,成為了當前數據挖掘算法中的熱點.其主要優點如下[36-37].
(1)目標函數優化利用了損失函數關于待求函數的二階導數,加快優化進程,增加模型準確性.
(2)支持并行化,對于某個節點,節點內選擇最佳分裂點,候選分裂點計算增益用多線程并行.訓練速度快.
(3)通過引入正則化項,增加模型的泛化能力,能有效防止過擬合問題.
2.3 人工神經網絡
人工神經網絡 (artificial neural network),作為功能強大的機器學習算法,可以充分挖掘隱藏在數據背后的非線性關系.多個相互連接的并行神經元組成的人工神經網絡系統一般包括輸入層,隱藏層和輸出層.僅包含輸入和輸出層的神經網絡也稱為單層感知器,通常用于解決線性問題.多層感知器可能包含多個隱藏層,用來探索因變量和自變量之間復雜非線性關系[38-39].神經元之間的連接可以用等式(3)表示,當輸入信號通過時,神經元根據其權重交換消息.每個神經元的輸入信息通過線性加權組合在一起,通過不斷調整權重和偏差以使輸出與輸入變量相關.最后,通過激活函數獲得計算結果的輸出

式中yi是神經元i的輸出;f(·)是激活函數,可用于控制神經元的狀態(興奮或抑制);wij是后一層的神經元j和當前層的神經元i之間的連接權重;xj表示上一層神經元j的輸出值;bi是神經元i的偏差.
神經網絡的訓練過程包括兩個階段:信號的前饋傳輸和誤差的反向傳播[40-41].在第一階段,信號從輸入層傳遞到隱藏層或輸出層.在第二階段,將從預測值和實際值計算出的誤差信號傳播回輸入層,并更新輸入層中神經元之間的連接權重和偏差.最后,需要一個具有濾波器功能的傳遞函數來激活該單元并產生輸出.人工神經網絡中的常用激活函數包括Sigmoid 函數,tanh 函數和ReLU 函數.為了節省模型優化時間,本文采用文獻報道中普遍適用的ReLU函數作為產量預測的激活函數[42-44].
3 實例分析
3.1 產量預測數據庫建立
本文以國內某特低滲透油田為例,盡可能地搜集了該油田242 口壓裂水平井的6 個月累積產油量及影響產量的地質?油藏?工藝變量,主要包括孔隙度(φ),滲透率(K),含水飽和度(Sw),泥質含量(Sh),電阻率(R),射孔厚度(hperf),有效厚度(h),井底流壓(pwf),生產壓差(ΔP),油藏位置(邊部),入地總液量(Vfrac)及六個月的平均產量(Q6?m).為了準確評估壓后效果及訓練模型,選取6 個月平均月產量作為預測指標,通過函數插值填補缺失值、降噪、類別數據獨熱編碼等技術手段對數據進行預處理,獲得了12 個變量的統計分析結果,主要包括均值(mean),標準差(std),最小值(min),第一四分位數(25%),中位數(50%),第三四分位數(75%),最大值(max),具體結果如表1 所示.

表1 產量數據庫統計分析Table 1 Statistical analysis of oilfield database
針對油田所搜集到的242 口壓裂水平井數據的產量預測問題,本文的工作流程如下.
(1)首先通過填補缺失值,類別數據(如油藏位置)進行獨熱編碼進行數據預處理;
(2)為了獲得較為可靠的預測結果,在數據預處理的基礎上先對數化處理再進行數據標準化,獲得符合高斯分布特征的無量綱數據,形成產量預測數據庫;
(3)為了對比驗證三種代理模型的預測效果,利用隨機劈分方法將數據切分為訓練集和測試集;
(4)經過模型訓練后的數據,為了減少模型訓練過程中預測結果的差異性,采用十折交叉驗證方法評估三種代理模型(隨機森林、XGBoost、人工神經網絡)的預測效果.
(5)為了評估小樣本數據下數據預處理對模型預測效果的影響,考慮經過數據對數化處理和不經過對數化處理兩種條件下評估代理模型的預測效果.
數據預處理是獲得準確可靠的預測結果的關鍵,針對本案例中偏度較大的變量,本文采用對數函數進行轉化,利用核密度估計方法獲取轉換前后的概率密度分布

式中,f為概率密度函數,K(·)為核函數(非負、積分為1,符合概率密度性質,并且均值為0),h>0 為一個平滑參數,稱作帶寬.結果表明,對數化處理后的數據更加服從高斯分布(見圖4,圖5 所示).

圖4 轉換前數據分布(以孔隙度為例)Fig.4 Data distribution before transformation(taking porosity as an example)

圖5 轉換后數據分布(以孔隙度為例)Fig.5 Data distribution after transformation (taking porosity as an example)
為了消除不同變量之間的量綱影響,采用基于原始數據的均值和標準差進行數據標準化處理,其表達為

式中,x表示原始數據,μ表示數據的均值,σ表示數據的標準差,x*為標準化后的數據.
經過預處理的數據可輸入到機器學習算法中進行訓練,為了評估模型效果并對比分析隨機森林、XGBoost、人工神經網絡之間的差異,本文采用隨機劈分方法將產量預測數據庫劃分為訓練集(70% 數據集)和測試集(30% 數據集),通過十折交叉驗證的均方誤差和準確率來評估模型的預測效果.
3.2 模型結構
正如前文所述,本文采用適用于小樣本的集成學習模型(隨機森林及XGBoost)進行訓練,并與人工神經網絡模型進行對比.為了獲取高效準確的優化模型,通過十折交叉驗證對滲流代理模型進行超參數優化,優化后的模型結構如表2 所示.

表2 模型參數優化結果Table 2 Model parameter optimization results
4 結果與討論
4.1 產量主控因素排序
產量主控因素分析及排序是油井性能評估的一個重要步驟,本文基于數據建模技術及前文建立的產量模型數據庫,采用皮爾遜相關系數分析各個變量對6 個月累積產油量的影響.皮爾遜相關系數能定量分析不同自變量與因變量之間的相關程度并排序,其值越接近1,相關性越強;其值越接近0,相關性越弱.皮爾遜相關系數的表達式為

式中, ρX,Y表示變量X,Y之間的相關系數;c ov(X,Y),σX, σY分別表示協方差、變量X的標準差、變量Y的標準差;μX, μY分別表示變量X、變量Y的均值.通過數據建模分析得到的皮爾遜相關系數矩陣如圖6 所示.從圖中可以看到,該特低滲透油藏,影響6 個月累積產油量前四個因素分別為入地液量,儲層厚度,生產壓差,油藏有無邊水.

圖6 產量影響因素分析Fig.6 Analysis of factors affecting oil production
4.2 數據標準化對預測效果影響
此外,為了說明數據預處理步驟在數據驅動預測產量過程中的重要性,本文對比了三種滲流代理模型在經過數據預處理(標準化)和不經過數據標準化的兩種場景下的預測效果,如圖7~圖9 所示.
從圖7~圖9 可以看出,未經過標準化的數據直接輸入到模型中會產量較大誤差,嚴重影響模型預測效果.對比三種滲流代理模型來看,數據標準化對神經網絡模型影響最大;而對于集成學習模型,未進行標準化也能取得一定的效果.因此,利用滲流代理模型進行回歸預測時,數據標準化是模型取得較高準確率的關鍵,尤其是對于神經網絡,未經數據標準化的數據會模型會嚴重影響產量預測效果.

圖7 隨機森林模型標準化對比Fig.7 Standardization comparison of random forest models

圖8 XGBoost 模型標準化對比Fig.8 Standardization comparison of XGBoost models
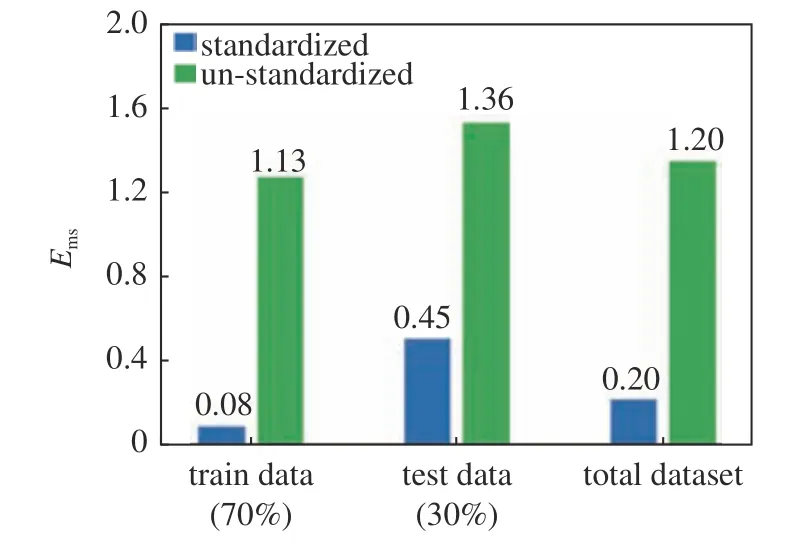
圖9 人工神經網絡模型標準化對比Fig.9 Standardization comparison of artificial neural network models
4.3 三種滲流代理模型對比
將隨機劈分的產量預測數據庫分別輸入到優化的隨機森林、XGBoost 回歸樹及人工神經網絡模型中,通過指數化及反歸一化可以得到產量模型的預測結果.所得訓練集,測試集及整個數據集的均方誤差及準確率結果如表3 所示.為了更加直觀對比三種機器學習算法的預測性能,繪制了目標值與模型值的交會圖如圖10~圖12 所示.

圖10 隨機森林目標值與預測值交會圖Fig.10 Cross plot of target and predicted values of random forest

圖11 XGBoost 目標值與預測值交會圖Fig.11 Cross plot of target and predicted values of XGBoost
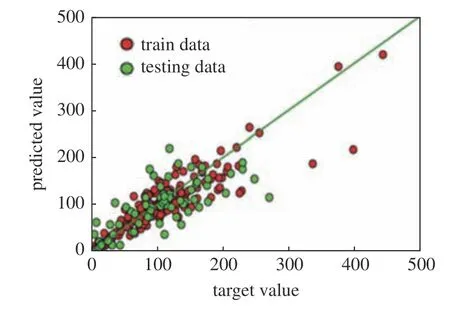
圖12 人工神經網絡目標值與預測值交會圖Fig.12 Cross plot of target and predicted values of artificial neural networks
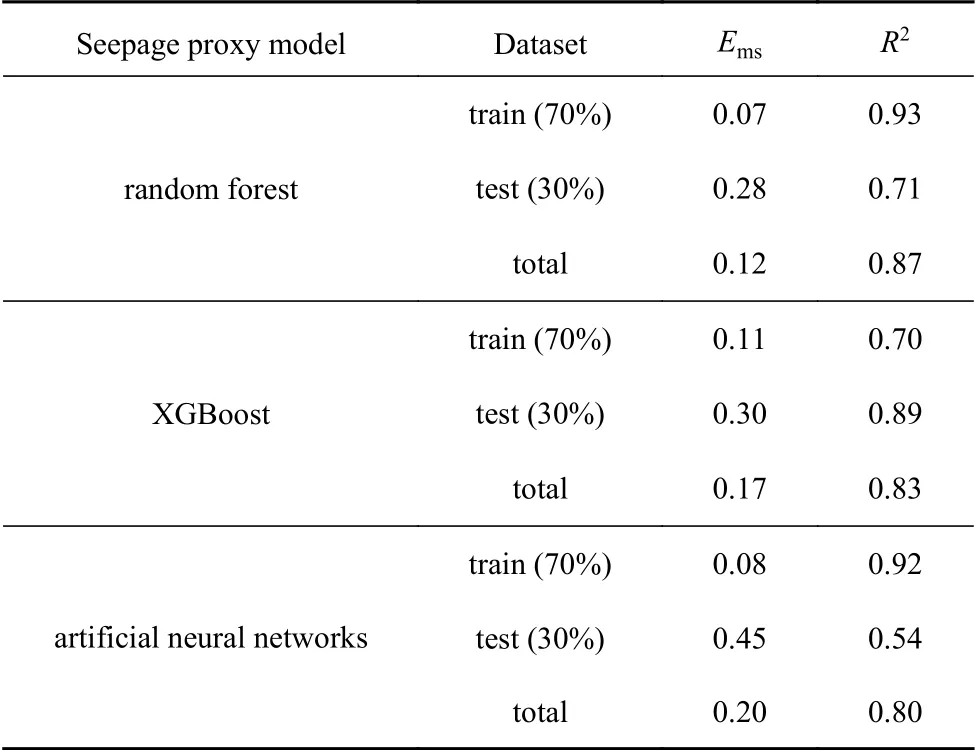
表3 滲流代理模型結果對比Table 3 Comparison of results of seepage proxy model
結合兩種模型評估指標(均方誤差,Ems、準確率,R2)來看,總體而言三種滲流代理模型均能取得較好的預測效果(R2>0.8,Ems<0.2),這說明滲流代理模型能被用來挖掘多變量油田數據之間復雜非線性關系.從測試集的均方誤差結果可以看出,人工神經網絡針對小樣本數據的預測的過擬合現象十分嚴重(Ems= 0.45,R2= 0.54),不太適合小樣本數據的預測,而隨機森林算法和極限梯度提升數的預測效果明顯優于神經網絡,進一步說明集成學習算法在處理小樣本數據時表現出來的優越性,對比隨機森林和極限梯度提升樹來看,隨機森林在測試集上略低于極限梯度提升樹,而在總體預測結果來看,隨機森林算法仍具有明顯的優勢,因此,隨機森林算法能較好地用于小樣本多變量的油田數據分析.
5 結論
本文針對地下多孔介質滲流過程中存在的非線性、多尺度、多物理場等耦合滲流機理難以準確刻畫與表征,考慮多機理耦合的滲流模型求解難度大,計算效率低等滲流力學發展面臨的瓶頸問題,探索了一種利用大數據分析方法建立滲流代理模型預測石油產量的方法與流程,所得結論如下.
(1)本文建立的三種滲流代理模型不需要建立復雜的物理模型及假設便能挖掘油田數據之間復雜的非線性關系,高效準確地預測產量,兼顧計算效率的同時能實現產量的準確預測.
(2)滲流代理模型預測石油產量包括油田數據收集、數據清洗(缺失值填充、數據標準化與對數化等)、產量預測數據庫建立、代理模型優化、產量預測等步驟.針對油田開發過程中的多變量小樣本問題,在模型開始訓練前,數據對數化及歸一化處理能明顯提升模型的預測效果.
(3)代理模型能快速分析多變量之間的相關性,抽提影響產量的主控因素.相比于神經網絡模型,隨機森林具有更好的泛化性能,能更好地適用于小樣本多變量的產量預測問題.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
礦山安全信息(2022年40期)2022-04-07 02:16:52
今日農業(2021年14期)2021-11-25 23:57:29
石油與天然氣地質(2021年1期)2021-02-22 14:14:44
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
今日農業(2020年20期)2020-11-26 06:09:10
數學物理學報(2020年2期)2020-06-02 11:29:24
中國果業信息(2019年10期)2019-11-13 01:21:34
聚氯乙烯(2018年9期)2018-02-18 01:11:34
光學精密工程(2016年6期)2016-11-07 09:07:19
