元數據評估模型及質量提升對策
2021-11-05 18:58:09蒲飛涂旭東陳苗趙正輝
中國新通信 2021年18期
蒲飛 涂旭東 陳苗 趙正輝
【摘要】? ? 跟隨教育信息化的飛速發展,高校信息化系統迅速擴張,產生了海量教育大數據。許多高職院校都建立了校級的數據中心,高質量的元數據是數據中心的最基本部分。元數據質量直接決定著大數據分析結果的準確性,但由于數據來源的多樣化和復雜化,導致數據形式、格式不一,元數據的質量難以保證;導致難以支撐高校教學、科研和管理模式改革。本文以數據質量的判定模型為標準,對重慶醫藥高等專科學校元數據來源進行分析,并針對性提出提高數據質量的解決方法策略,為其他高職院校數據質量分析提供借鑒。
【關鍵詞】? ? 元數據? ? 數據質量? ? 判定模型? ? 對策
一、元數據質量是智慧校園建設的基礎
隨著教育信息化的來的深入發展,各高校紛紛開始啟動大數據戰略,并建立數據中心,來深度推進學校信息化的建設和發展。當前各高校正在從數字化校園的建設逐步邁向智慧校園的建設,這樣就使得數據中心的數據變得更為海量化、復雜化、多樣化和快速化。另一方面,數據中心元數據的質量直接決定著大數據分析的結果,數據中心元數據的質量如果得不到一定程度的保證,后續的大數據分析將會建立在這些不可靠的數據之上。因此學校數據中心的元數據質量是決定學校能否從數字化數園順利過渡到智慧校園的關鍵。但學校元數據的質量到底如何,又該如何進行評價,下面通過元數據質量評估的模型,以重慶醫藥高等專科學校元數據為例來進行探討提升數據質量的方法。
二、數據質量的判定模型
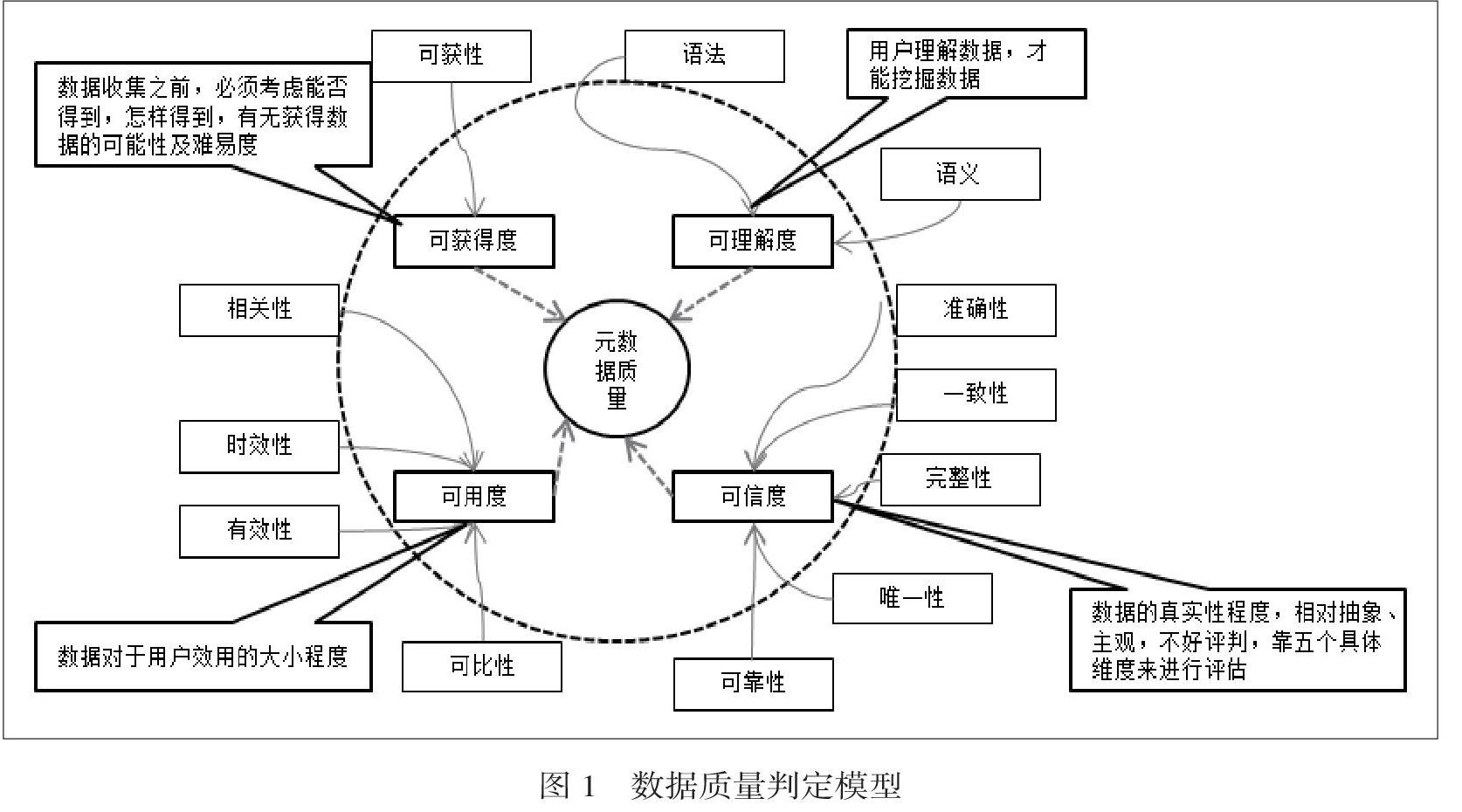
通常對數據質量的理解就是存儲于計算機及網絡系統中的數據質量的好壞和優劣[3]。如何來判斷數據中心數據質量的好壞和優劣,當前并沒有一個很好的標準。我們在對學校數據質量的判定中,主要是按照元數據四個不同的維度對質量進行評估:如下圖1。
2.1數據質量模型評估標準四個方面的關系
從圖1中可以看出,評估標準的四個方面中,可獲得度是解決能否從系統中獲取數據的問題,包括通過一定的數據轉換模型來獲得的數據[3]。數據的可獲得度是數據可理解度的基礎,它與數據可理解度一起,構成了挖掘數據的基本條件。只有獲取了數據,并且對數據的語法、語義理解之后,用戶才能進行數據挖掘。但當用戶獲取并理解了數據之后,隨之而來的一個問題是:數據是否可信。假設數據的可信度很高,那么接下來的問題是:數據是否有用。因此可以說數據質量評估的四個方面:可獲得度,可理解度,可信度,可用度,是一種遞進深入的關系。元數據質量的是否優劣,須依次回答四個問題[5]:一從哪里獲取數據;二是否明白和理解已獲取的數據;三數據有多少是可信的;四可信的的數據中有哪些數據對分析和挖掘有用。經過上述四個流程篩選之后,元數據質量就會得到保證,接下來就可放心地對數據進行預處理,然后就可以根據創立相應的算法,使用相應的模型進行數據分析了。
2.2數據質量12個影響因子的相互關系
影響數據質量的因素,既可按照評估標準分成4個大的方面,又可根據每個具體的評估標準拆分成12個最終影響因子(如圖1)。即數據質量的優劣其實是根據這12個因子來評判的,當然這12個因子在對數據質量判定上的作用各有側重,并不是都完全相同的。有些因子,如準確性、可靠性等之類的,對數據質量的判定作用幾乎是一票否決,而有些因子如相關性、可比性等之類的,對數據質量的判定作用相對而言要弱一些。這些影響因子既在評估標準每個方面的內部之間相互關聯、相互影響,同時又能影響其他評估標準下的影響因子。
比如數據的準確性較差,那么數據的可靠性、有效性就不會太高;如果數據同時能夠做到準確、一致、有時效,那么數據的可靠性就比較高。因此12個影響因子缺一不可、相輔相成構成了對數據質量優劣的評判。
2.3數據質量研究判斷的難題
從上述12個數據質量的影響因子中可以看出,這些影響因子對數據質量的評判更多的是一種定性的判斷。相對于數據分析而言,數據質量的評判需要給出定量的結果。假設抽樣數據的準確性不是100%,而是準確性為90%,一致性為91%、完整性為92%。按工程上的準確率計算方法,根據這三個因子相乘計算得出的數據質量優劣率為90%*91%*92%*100%=75%,如果再有其它的幾項因子相乘,那么數據質量的優劣率將會變得更低。除非保證數據質量影響因子的參數值都為100%,否則數據質量優劣率都將會低于100%,也就是說數據都將是不完全可信的,但是12個數據質量影響因子同時定性為100%,這在現實中不太可能。在實際中,總是希望數據質量越高越好,這只是一種定性的說法,能不能對數據質量建立一種更為精確的定量分析方式,使得數據質量根據各項指標的參數值進行綜合評判,當數據質量的各項影響因子達到某些閾值的時候,數據才是可靠和可性的,才會在數據分析中具有研究的價值,但是實際的情況是閾值的確定,這是數據質量評估要深入研究的一個課題[5]。
三、重慶醫藥高等專科學校元數據質量現狀
在高職院校的各項信息數據中,高校普遍存在數據質量不高的事實,而且當前越來越多的高校也已經意識到因數據質量不高而可能產生的各類問題。為了摸清我校數據質量的狀況,學校信息圖書中心聯合其它相關職能部門,對本校數字化校園內的,一段時間內和一定范圍內的數據作了一次數據質量抽樣的摸底調查分析。由于數字化校園數據類型多樣、龐大,因此有必要在作摸底調查之前,對每種類型的數據作一個從數據選擇到分析方法的大致規劃。將結構化類型數據采取數值量化、將非結構化數據中不易量化的數據劃分為優、良、一般、劣四個等級[4-5],確保本次抽樣數據質量分析接近本校的實際情況。
3.1個人手工輸入方式數據
在整個系統中涉及數據手工輸入的操作者主要有學生、普通教師、系統平臺管理員類, 它們一方面由于對系統各個子平臺使用不熟悉,對某些填寫內容理解不透徹[3];另一個方面是由于計算機技能欠缺, 培訓機會不多和責任心不強,在錄入數據時可能會誤填、漏填或誤添某項數據;又加上系統中的某些數據定義不明確、概念混淆,系統在開發時控制和校驗不嚴,造成數據的缺項和漏項,導致系統中數據質量問題很多,從而影響數據的準確性。
3.2外部系統來源的結構化數據
從外部系統導入到學校系統的結構化數據,主要存在不同系統之間數據編碼沖突的問題,這是因為大多數系統之間沒有統一的技術和數據標準,數據不能自動導入,缺乏有效的關聯和共享[5]。
不同數據源的相同數據編碼不一致,常見的有兩種情形,一種為屬性編碼的不一致。以學校招生管理系統中學生的性別為例,外部系統數據源編碼為“男=1,女=2”,而在學校系統數據源中編碼為“女=1,男=2”,這樣就造成了數據導入的出錯,影響數據的準確性。另一種為字符編碼的不一致,常見的中文字符編碼有GBK編碼和UTF-8編碼,一種字符編碼的數據在導入到另一種字符編碼的數據時容易出現亂碼,因此在導入外部系統來源的結構化數據之前有必要做好屬性編碼和字符編碼的轉換。
另一方面,在高校當前的各個應用環境中,不同系統之間存在大量的業務數據依賴,比如教務系統中學生的基本信息數據,可能是從招生管理系統或者迎新管理系統中導入,來自迎新管理系統的數據,因為某些學生未來入學和各管理員沒有在系統中對學生的信息進行及時核對,導致學生的數據變得不準確,因此在從其它系統導入數據之前,有必要對相關數據進行核對,以保證數據的準確性和完整性。
3.3外部來源的非結構化數據
非結構化數據一般是指無法用固定結構來邏輯表達實現的數據,包括辦公文檔、文本、圖片、XML、HTML、各類報表、圖像和音視頻等等,相比結構化數據而言,這類數據特別是音視頻文件沒有統一的格式,關鍵詞不統一。這類非結構化數據的內容大多數不易改動,質量的決定主要是清晰度,但是一般而言在存儲時候,都會作一次篩選,因此數據質量較高。
3.4應用系統自動生成的結構化數據
應用系統自動生成的結構化數據,如門禁系統數據和一卡通系統數據,相比外部導入的結構化數據而言,數據的準確性,完整性的都很好,數據質量相對較高,這主要是因為系統自動生成的數據格式固定,不會出現手工輸入數據存在的各種問題。因此從這上面可以看出,如果要想數據質量高,盡量應使用系統自動產生的規范線上數據。
3.5應用系統自動生成的非結構化數據
由于是應用系統自動生成的非結構化數據,數據的準確率相對也是很高。
四、提高元數據質量的措施
4.1組建專業的管理人員隊伍
高校數字化校園系統對學校來說是及其重要的部分,不可能讓每一個人都對系統進行增刪改,必須賦予一部分特定的人員較高或最高的權限,來對系統進行管理和獨立操作。另一方面,高校數字化校園系統對數據的處理要求很高,這主要是因為業務中對數據的提取,加載,轉換和處理比較頻繁[5],這必須要求要有一定計算機水平的管理人員來維護數據的一致性與完整性,在數據錄入時控制數據的來龍去脈,對輸入的數據,要進行完整性約束。 我校在意識到此問題之后,是在每一個部門設一個部門數據管理員,并且定期組織數據管理技能培訓。
4.2建立嚴格的審核機制
正確地輸入數據是系統進行有效數據分析的前提和保證,錯誤的數據只會讓系統輸出不正確或無用的結果,從而導致后續數據的處理和分析失去意義,因此有必要要求各平臺和各系統管理員對手工輸入的數據進行嚴格的審查和核對;另一方面要求信息系統也具有一定的自動審核機制,比如自動清除字符之間的空格,判斷必填項是否為空等等,真正實現從源頭上控制數據的質量,從而降低數據出錯的概率,為后續數據的導出或分析奠定堅實的基礎。
4.3建立統一的數據標準
業務數據的標準化包括統一的數據字符編碼標準和統一的屬性編碼標準,統一的屬性編碼標準是指屬性的值有多個字段,給每個字段進行統一的編碼,比如“民族”這個屬性,對漢族進行編碼為1,壯族編碼為2等等。目前中華人民共和國教育行業標準中的《高等學校管理信息標準》以及數據標準化的思想尚未得到全面應用[3],但是很有必要在全國進行推廣。我校通過此數據治理也建設了一套適用于本校的數據標準,主要原則是“有國標用國標,有省標用省標,無標就自建校標”的方法。
4.4建立可靠的數據質量評估和監督機制。
數據質量的持續改進和提高,需要相應的數據管理部門來評估和監督,需要相關部門負責對數據質量標準進行定義和控制,包括抽查等,目的是為了當有數據質量問題時,及時告知各業務部門,找出導致問題的源頭數據,并監督相關業務部門改進,這些在保證數據質量繼續改進的同時,又避免了較大數據事件的出現。
五、結束語
隨著各高校的數字化校園建設正逐步邁向智慧校園建設,用戶對各個系統的功能要求也越來越高。一方面,要求系統提供更多更強的功能,從原來功能的“單一化“發展為現在功能的“多樣化”,從原來數據的簡單獲取,發展為現在數據的綜合分析,再到數據為決策者提供決策支持;另一方面,信息化建設的重心正在發生轉變,之前主要是以關注各個應用系統的功能要滿足各個業務部門工作為主,現在逐漸過度到了以關注用戶包括各職能部門管理者的決策分析使用需求為主。
并要求系統能提供定制化和個性化的集成服務。因此高校的信息化建設要真正實現精準化服務,真正滿足用戶對系統和數據日益增長的需求,就必須進一步提高各系統數據的質量,為智慧校園打下堅實的數據基礎。
參? 考? 文? 獻
[1]賈宏.高校機構資源庫元數據質量控制研究.南陽師范學院學報,2017(16):65-67.
[2] 郭曉明,高校信息化環境中數據質量問題探析.中國教育信息化,2016(15):59-62.
[3] 宓詠.智慧時代數據服務的發展與思考[J].中國教育網絡,2015(8):23-26.
[4] 郭曉明,張巍.高校信息化建設中公共數據平臺的探討[J].中國教育信息化,2015(19):69-72.
[5]楊勤.高校統計數據質量問題若干問題[J].現代經濟信息.2016(1).
蒲飛(1970.05),男,本科,高級工程師,研究方向:系統規劃與管理、數據管理、治理。
通訊作者: 陳苗(1990.07),女,研究生,講師,研究方向:計算機系統結構、移動計算。
猜你喜歡
中學生數理化·七年級數學人教版(2021年11期)2021-12-06 05:38:46
江蘇安全生產(2020年3期)2020-04-21 05:44:14
云南教育·中學教師(2019年6期)2019-08-13 07:03:28
活力(2019年22期)2019-03-16 12:47:28
基層中醫藥(2018年11期)2019-01-31 05:26:52
現代情報(2016年11期)2016-12-21 23:41:05
科學與財富(2016年26期)2016-12-01 21:50:16
中國市場(2016年40期)2016-11-28 04:58:19
時代金融(2016年27期)2016-11-25 19:02:25
科學與財富(2016年15期)2016-11-24 13:18:39
