基于單“音頻像素”擾動(dòng)的說(shuō)話人識(shí)別隱蔽攻擊
2021-11-05 12:04:30沈軼杰李良澄劉子威劉天天
計(jì)算機(jī)研究與發(fā)展 2021年11期
沈軼杰 李良澄 劉子威 劉天天 羅 浩 沈 汀 林 峰,2 任 奎
1(浙江大學(xué)網(wǎng)絡(luò)空間安全研究中心 杭州 310027) 2(浙江省區(qū)塊鏈與網(wǎng)絡(luò)空間治理重點(diǎn)實(shí)驗(yàn)室(浙江大學(xué)) 杭州 310027) 3(浙江東安檢測(cè)技術(shù)有限公司 杭州 310063) (shenyijie@zju.edu.cn)
說(shuō)話人識(shí)別技術(shù)通過(guò)對(duì)說(shuō)話人聲紋的分析識(shí)別說(shuō)話人身份,是目前應(yīng)用廣泛的生物認(rèn)證技術(shù)之一.該技術(shù)已經(jīng)被廣泛應(yīng)用于個(gè)人安全和社會(huì)安全領(lǐng)域(如個(gè)人設(shè)備管理[1]、電子取證[2]以及電子監(jiān)控[3]等).然而,目前主流的說(shuō)話識(shí)別系統(tǒng)存在著重大安全隱患,即攻擊者可以通過(guò)來(lái)源于第三方的音頻(即非來(lái)源于受害者的音頻)獲取目標(biāo)系統(tǒng)(如安卓操作系統(tǒng)、支付寶、微信等)中受害者的權(quán)限,執(zhí)行查看隱私、交易支付、登入社交賬號(hào)等操作.這些操作會(huì)威脅受害者的隱私信息、經(jīng)濟(jì)利益甚至人身安全.
前人的工作提出了一系列基于機(jī)器學(xué)習(xí)的攻擊方案.這些攻擊運(yùn)用對(duì)抗學(xué)習(xí)的技術(shù),生成特殊的擾動(dòng)使第三方音頻偽裝成受害者的身份,實(shí)現(xiàn)入侵系統(tǒng)的目的.根據(jù)攻擊者對(duì)模型信息的獲取程度可以分為白盒攻擊[4-5]和黑盒攻擊[6-8].其中,白盒攻擊假設(shè)攻擊者需要獲取模型的完整參數(shù),而黑盒攻擊假設(shè)攻擊者不需要獲得模型的任何參數(shù).上述方案取得了一定的效果,但是也存在2點(diǎn)不足:1)白盒攻擊依賴于被攻擊模型的完整參數(shù),這一約束降低了攻擊的實(shí)用性.2)人工復(fù)查是目前檢測(cè)語(yǔ)音識(shí)別是否遭受攻擊的主要手段之一.因此,提升攻擊對(duì)于人耳的隱蔽性是提高攻擊實(shí)用性的重要環(huán)節(jié).由于增加擾動(dòng)會(huì)引入寬頻噪聲,這樣的噪聲根據(jù)人耳的“掩蔽效應(yīng)”[9]容易被人耳所察覺(jué).因此注入擾動(dòng)的時(shí)長(zhǎng)越長(zhǎng),攻擊被察覺(jué)的可能性越大.然而目前的攻擊方案需要向第三方音頻注入亞秒級(jí)甚至秒級(jí)的擾動(dòng),導(dǎo)致攻擊易被察覺(jué).存在這一不足是因?yàn)楝F(xiàn)有的白盒和黑盒攻擊方案都依賴于梯度信息,所以容易陷入局部最優(yōu)解,形成對(duì)于攻擊能力的限制,即攻擊者無(wú)法通過(guò)修改對(duì)攻擊成功增益最大的采樣點(diǎn)實(shí)現(xiàn)將第三方音頻偽裝成受害者的目的.
隨著深度學(xué)習(xí)的發(fā)展,基于深度學(xué)習(xí)的說(shuō)話人識(shí)別技術(shù)(如x-vector[10]和d-vector[11-12])由于其高精確以及高魯棒性成為了目前該領(lǐng)域的主流技術(shù).現(xiàn)有的工作[13-14]指出了深度學(xué)習(xí)技術(shù)在實(shí)現(xiàn)特征提取的過(guò)程中位于決策邊界附近的數(shù)據(jù)點(diǎn)對(duì)于特定方向的擾動(dòng)的敏感性.特別地,本文利用這一特性試圖實(shí)現(xiàn)一種針對(duì)說(shuō)話人識(shí)別的高隱蔽性擾動(dòng)攻擊.為了實(shí)現(xiàn)針對(duì)說(shuō)話人識(shí)別系統(tǒng)的攻擊并克服現(xiàn)有工作不足,本文攻擊方案需要滿足3個(gè)特性:
1) 黑盒攻擊.攻擊者不需要獲取任何說(shuō)話人識(shí)別系統(tǒng)中模型的參數(shù)信息,這一特性增強(qiáng)攻擊的實(shí)用性.
2) 有目標(biāo)的攻擊.攻擊能夠?qū)⒌谌揭纛l偽裝成目標(biāo)受害者,這一特性使攻擊具有有效性和針對(duì)性.
3) 單“音頻像素”擾動(dòng).單“音頻像素”指音頻中的單個(gè)獨(dú)立采樣點(diǎn),類比于圖像中的一個(gè)像素點(diǎn),是音頻采集過(guò)程中最小的記錄單位.在擾動(dòng)生成過(guò)程中能夠搜索對(duì)攻擊增益最高的“音頻像素”并進(jìn)行注入.這一特性強(qiáng)化攻擊的高效性和隱蔽性.
為了實(shí)現(xiàn)以上3個(gè)特性,圖1展示了我們針對(duì)說(shuō)話人識(shí)別基于單“音頻像素”擾動(dòng)的攻擊流程,下文簡(jiǎn)稱這種攻擊為基于單“音頻像素”擾動(dòng)的攻擊.攻擊者先在第三方音頻上搜索對(duì)攻擊增益最高的“音頻像素”,并通過(guò)向搜索到的“音頻像素”注入擾動(dòng)產(chǎn)生能夠偽裝成受害者身份的攻擊音頻,最后攻擊者使用該音頻實(shí)現(xiàn)攻擊.為了實(shí)現(xiàn)這套方案需要解決2個(gè)技術(shù)挑戰(zhàn):1)如何在黑盒條件下實(shí)現(xiàn)針對(duì)說(shuō)話人識(shí)別系統(tǒng)的攻擊?2)如何使得攻擊能夠搜索并修改對(duì)攻擊增益最高的“音頻像素”?
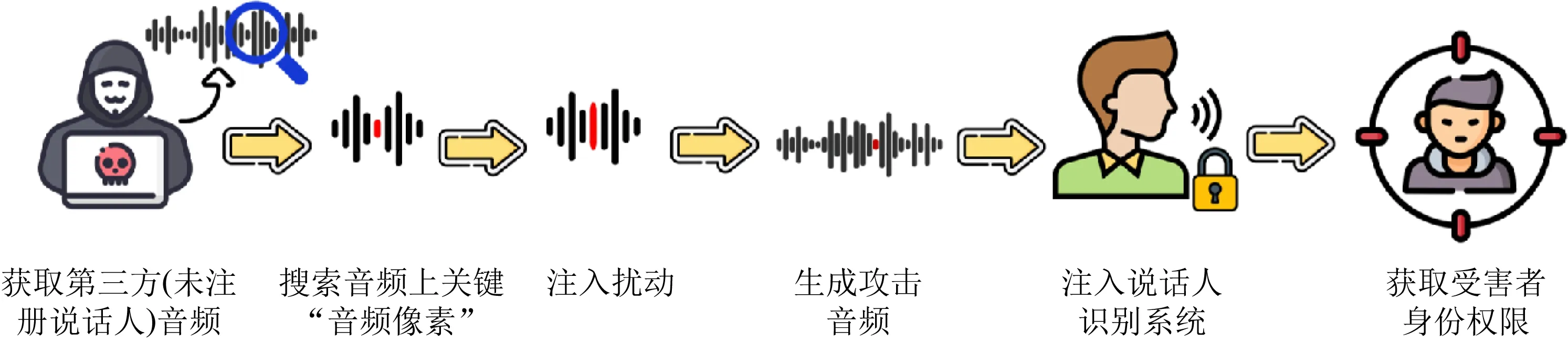
Fig.1 The workflow of the attack aiming the speaker verification system via one-“audio pixel” perturbation圖1 單“音頻像素”擾動(dòng)實(shí)現(xiàn)針對(duì)說(shuō)話人識(shí)別系統(tǒng)的攻擊流程
本文提出了一種基于差分進(jìn)化算法[15]的針對(duì)說(shuō)話人識(shí)別技術(shù)的攻擊方案,以下簡(jiǎn)稱基于單“音頻像素”擾動(dòng)的攻擊.首先,利用差分進(jìn)化算法的啟發(fā)式特性,實(shí)現(xiàn)不依賴于系統(tǒng)參數(shù)的攻擊.其次,提出基于音頻段-音頻點(diǎn)-擾動(dòng)值多元組的候選點(diǎn)構(gòu)造模式,結(jié)合差分進(jìn)化算法不依賴梯度的特點(diǎn),對(duì)候選點(diǎn)進(jìn)行迭代和優(yōu)化,實(shí)現(xiàn)搜索并修改對(duì)攻擊增益最高的“音頻像素”,生成能夠偽裝為受害者的攻擊音頻.我們?cè)贚ibriSpeech數(shù)據(jù)集[16]上測(cè)試了該方案,攻擊成功率達(dá)到了100%.另外,我們對(duì)影響基于單“音頻像素”擾動(dòng)的攻擊因素進(jìn)行了評(píng)估,為獲得高性能攻擊提供了指導(dǎo).除此之外,利用實(shí)驗(yàn)探究了不同平臺(tái)和跨數(shù)據(jù)集下攻擊的性能,說(shuō)明了攻擊不依賴于平臺(tái)和數(shù)據(jù)集.
本文的主要貢獻(xiàn)有3個(gè)方面:
1) 提出和探索了利用單“音頻像素”擾動(dòng)實(shí)現(xiàn)對(duì)于說(shuō)話人識(shí)別系統(tǒng)的隱蔽攻擊,攻擊注入擾動(dòng)的時(shí)長(zhǎng)僅為幾十微妙.
2) 設(shè)計(jì)了基于音頻段-音頻點(diǎn)-擾動(dòng)值多元組的候選點(diǎn)構(gòu)造模式,結(jié)合差分進(jìn)化算法,實(shí)現(xiàn)了在音頻上搜索對(duì)攻擊增益最高的“音頻像素”并注入有效的擾動(dòng).
3) 開展了廣泛的實(shí)驗(yàn),探究了不同條件對(duì)于攻擊的影響.同時(shí),通過(guò)實(shí)驗(yàn)說(shuō)明基于單“音頻像素”擾動(dòng)的攻擊隱蔽性優(yōu)于目前最先進(jìn)的攻擊工作.
1 背景及相關(guān)工作
1.1 說(shuō)話人識(shí)別系統(tǒng)
相比于其他生物認(rèn)證技術(shù),說(shuō)話人識(shí)別技術(shù)具有低成本、高精確度和非接觸的特點(diǎn).經(jīng)過(guò)數(shù)十年的發(fā)展,說(shuō)話人識(shí)別系統(tǒng)已經(jīng)具有大量的開源平臺(tái)(如Kaldi[17],MSR Identity Toolkit[18],ALIZE[19]和SIDEKIT[20])以及商業(yè)項(xiàng)目(Google home[21],Talentedsoft[22]).根據(jù)對(duì)于識(shí)別時(shí)語(yǔ)料內(nèi)容的約束,說(shuō)話人識(shí)別系統(tǒng)可以分為文本相關(guān)的[23-24]和文本無(wú)關(guān)的[25-26]兩類,前者要求用戶使用文本內(nèi)容一致的語(yǔ)料進(jìn)行注冊(cè)和識(shí)別,而后者沒(méi)有這一限制.顯然,文本無(wú)關(guān)的說(shuō)話人識(shí)別系統(tǒng)更加便利和實(shí)用,因此本文設(shè)計(jì)的攻擊針對(duì)文本無(wú)關(guān)的說(shuō)話人識(shí)別系統(tǒng)展開,即下文中的說(shuō)話人識(shí)別系統(tǒng)默認(rèn)為文本無(wú)關(guān)的說(shuō)話人識(shí)別系統(tǒng).說(shuō)話人識(shí)別系統(tǒng)由3個(gè)子模塊構(gòu)成,分別為音頻預(yù)處理模塊、特征提取模塊以及決策模塊.
1) 音頻預(yù)處理模塊.使用人聲提取算法如G.279[27]提取原音頻中的人聲部分從而消除環(huán)境噪聲對(duì)于識(shí)別結(jié)果的影響,接著通過(guò)梅爾頻率倒譜系數(shù)(Mel-frequency cepstral coefficients, MFCC)[28]等時(shí)頻分析方法,獲取音頻信號(hào)的時(shí)頻信息為進(jìn)一步的特征提取提供數(shù)據(jù).
2) 特征提取模塊.特征提取模塊通過(guò)特定的提取器,提取出與身份相關(guān)的特征為身份決策提供可靠的依據(jù).特征提取模塊是說(shuō)話人識(shí)別系統(tǒng)的核心模塊,也是目前說(shuō)話人識(shí)別技術(shù)的主要研究?jī)?nèi)容.目前的特征提取器大致可以分為基于概率分析的特征提取器和基于深度學(xué)習(xí)的特征提取器2類.
① 基于概率分析的特征提取器.基于概率分析的特征提取器使用概率模型提取語(yǔ)音中的特征.基于高斯混合-通用背景模型(Gaussian mixture model-universal background model, GMM-UBM)框架[29]的特征提取是其中最成熟的特征提取方式,它通過(guò)大量無(wú)關(guān)語(yǔ)料預(yù)先構(gòu)建通用的背景模型,實(shí)現(xiàn)不依賴用戶的說(shuō)話人特征提取.而基于概率分析的特征提取器中最先進(jìn)的是Dehak等人[30]提出的i-vector,它優(yōu)化GMM-UBM模型,基于i-vector因子分析技術(shù)將信道和說(shuō)話人作為一個(gè)整體分析,實(shí)現(xiàn)高性能的說(shuō)話人特征提取.
② 基于深度學(xué)習(xí)的特征提取器.基于深度學(xué)習(xí)的特征提取器使用深度神經(jīng)網(wǎng)絡(luò)提取描述對(duì)象身份的特征.按照優(yōu)化提取器性能的方法不同,主要可以分為2類:一類使用獨(dú)特的深度神經(jīng)網(wǎng)絡(luò)模型來(lái)實(shí)現(xiàn)高效的特征提取.比如,Google公司[31]提出的d-vector;Shi等人[32]提取的j-vector;Snyder等人[33]提出的x-vector.另一類使用獨(dú)特的損失函數(shù)來(lái)實(shí)現(xiàn)高效的特征提取.比如,rahman等人[34]和Wan等人[11]先后提出基于元組的端到端損失(tuple-based end-to-end, TE2E)和廣義端到端損失(generalized end-to-end, GE2E).
目前基于深度學(xué)習(xí)的特征提取器性能表現(xiàn)遠(yuǎn)高于基于統(tǒng)計(jì)分析的特征提取器,因此本文的工作針對(duì)基于深度學(xué)習(xí)的特征提取器展開.
3) 決策模塊.決策模塊可以使用余弦相似度[11]、K臨近算法[35]、支持向量機(jī)[36]和概率線性判別分析[37]等算法根據(jù)特征提取模塊提取的特征識(shí)別說(shuō)話人身份.在這一模塊根據(jù)目的的不同,說(shuō)話人識(shí)別可以細(xì)分為說(shuō)話人確認(rèn)和說(shuō)話人辨認(rèn)2類.由于在日常使用的支付、解鎖、登入社交帳號(hào)等操作中都以說(shuō)話人確認(rèn)為目的,因此本文圍繞以說(shuō)話人確認(rèn)為目的的說(shuō)話人識(shí)別展開.在發(fā)起一次識(shí)別后,將輸入語(yǔ)音x與受害者的記錄進(jìn)行比較.在比較過(guò)程中,識(shí)別系統(tǒng)通過(guò)函數(shù)f(·)計(jì)算x與受害人的相似度作為得分.當(dāng)?shù)梅指哂诜謹(jǐn)?shù)閾值θ時(shí),輸出受害者的身份信息;若得分低于θ時(shí),則輸出失敗的標(biāo)識(shí),具體公式為

(1)
1.2 對(duì)抗音頻攻擊
2013年Szegedy等人[38]在圖像領(lǐng)域提出對(duì)抗樣本的概念.隨著這一技術(shù)的應(yīng)用和發(fā)展,Cisse等人[39]將對(duì)抗概念應(yīng)用于語(yǔ)音識(shí)別領(lǐng)域,實(shí)現(xiàn)了對(duì)抗音頻攻擊.隨后,不同研究人員針對(duì)語(yǔ)音識(shí)別提出了成功率更高和隱蔽性更強(qiáng)的攻擊方案[40-42].緊接著,研究人員發(fā)現(xiàn)對(duì)抗音頻攻擊同樣可以用于攻擊說(shuō)話人識(shí)別.因此,隨后的工作[4-8]針對(duì)說(shuō)話人識(shí)別的對(duì)抗音頻攻擊進(jìn)行了探索.其中有基于白盒攻擊[4-5]的工作,通過(guò)對(duì)于說(shuō)話人識(shí)別模型參數(shù)的學(xué)習(xí),生成能夠偽裝成受害者的攻擊音頻.然而,白盒攻擊需要依賴于被攻擊模型的參數(shù),這些參數(shù)在實(shí)際場(chǎng)景中往往被第三方所保護(hù),攻擊者難以獲取,因此這類攻擊的實(shí)際應(yīng)用價(jià)值很低.Li等人[7]和Chen等人[6]的工作分別提出了針對(duì)說(shuō)話人識(shí)別系統(tǒng)的黑盒攻擊方案,解決了以往工作中對(duì)于被攻擊模型參數(shù)的依賴問(wèn)題.然而,這些工作中對(duì)于注入時(shí)長(zhǎng)沒(méi)有約束,攻擊時(shí)需要對(duì)于整段音頻進(jìn)行注入,引入長(zhǎng)時(shí)間的寬帶噪聲易于被察覺(jué).Li等人[8]為了降低長(zhǎng)時(shí)間噪聲的影響提出了一種亞秒級(jí)的注入攻擊,但是注入擾動(dòng)的時(shí)間仍然超過(guò)0.2 s,無(wú)法實(shí)現(xiàn)“音頻像素”級(jí)的注入攻擊.因此,已有工作在實(shí)現(xiàn)高隱蔽性對(duì)抗音頻攻擊的方面仍然存在不足.
相較于已有工作,基于單“音頻像素”擾動(dòng)的攻擊方案不依賴于梯度信息,利用差分進(jìn)化算法和獨(dú)特的候選點(diǎn)構(gòu)造模式,通過(guò)修改單個(gè)“音頻像素”實(shí)現(xiàn)有效的黑盒攻擊,大幅度地減小了注入時(shí)間,從而獲得更高的隱蔽性.
1.3 差分進(jìn)化算法
差分進(jìn)化算法(differential evolution, DE)[15]是一種基于種群的優(yōu)化算法,適合用來(lái)實(shí)現(xiàn)基于單“音頻像素”擾動(dòng)的攻擊,因?yàn)樵撍惴ň哂?個(gè)特性:
1) 全局最優(yōu)性.差分進(jìn)化算法在迭代過(guò)程中利用隨機(jī)性選擇的候選點(diǎn)進(jìn)行擇優(yōu)進(jìn)化.這使得差分進(jìn)化算法能夠在全局搜索解,避免陷入局部最優(yōu)解.
2) 可遷移性.差分進(jìn)化算法是一種不依賴于目標(biāo)模型的黑盒算法,因此對(duì)于攻擊的目標(biāo)系統(tǒng)有良好的可遷移性,即當(dāng)更換攻擊目標(biāo)系統(tǒng)時(shí)不需要對(duì)算法實(shí)現(xiàn)進(jìn)行重寫.
3) 可優(yōu)化性.本文中所使用的是標(biāo)準(zhǔn)的差分進(jìn)化算法.差分進(jìn)化算法發(fā)展至今已經(jīng)出現(xiàn)了多種變體以滿足不同的優(yōu)化需求,如使用模糊邏輯控制器加快收斂速度[43]和使用自適應(yīng)參數(shù)選擇優(yōu)化算法性能[44].
除了這3個(gè)算法理論的特性以外,差分進(jìn)化算法已經(jīng)在攻擊圖像識(shí)別領(lǐng)域上展現(xiàn)了優(yōu)異的性能.Su等人[13]利用差分進(jìn)化算法實(shí)現(xiàn)了一種基于單像素的攻擊方案,通過(guò)改變圖像中關(guān)鍵像素的像素值,實(shí)現(xiàn)干擾系統(tǒng)識(shí)別結(jié)果的目的.然而,由于圖像和音頻在表現(xiàn)形式和特征蘊(yùn)含方式上都有巨大的差異.因此我們?cè)O(shè)計(jì)了一套獨(dú)特的差分進(jìn)化算法構(gòu)造模式,輔助我們將差分進(jìn)化算法應(yīng)用于攻擊說(shuō)話人識(shí)別系統(tǒng),實(shí)現(xiàn)基于單“音頻像素”擾動(dòng)的攻擊方案,具體的方案會(huì)在第3節(jié)中詳細(xì)討論.
2 攻擊模型
在基于單“音頻像素”擾動(dòng)的攻擊中,攻擊者通過(guò)在第三方音頻上注入單“音頻像素”擾動(dòng),即改變第三方音頻中的一個(gè)采樣點(diǎn),將第三方音頻偽裝成受害者身份.為了使攻擊者具有足夠的能力和約束,我們對(duì)攻擊者有4方面假設(shè):
1) 攻擊者有足夠大的語(yǔ)料庫(kù)用于攻擊.目前,開源社區(qū)中包含大量語(yǔ)音開源數(shù)據(jù)庫(kù)(如VCTK[45],TIMIT[46],CMU_ARCTIC[47]等)以及網(wǎng)絡(luò)上存在大量音頻信息,因此攻擊者可以通過(guò)網(wǎng)絡(luò)獲取語(yǔ)料庫(kù)從而滿足這一假設(shè).
2) 攻擊者進(jìn)行黑盒攻擊,即攻擊者只能獲取說(shuō)話人識(shí)別系統(tǒng)反饋的評(píng)分?jǐn)?shù)值和最終給出的身份.這一假設(shè)符合目前主流說(shuō)話人識(shí)別系統(tǒng)給出識(shí)別結(jié)果的形式.
3) 說(shuō)話人識(shí)別系統(tǒng)提供用戶接口進(jìn)行查詢,例如Talentedsoft[22].攻擊者可以通過(guò)這些接口注入攻擊.同時(shí),它也符合已有工作對(duì)于注入擾動(dòng)攻擊的假設(shè)[6].
4) 受害者的語(yǔ)料數(shù)據(jù)不能被獲得,攻擊者無(wú)法使用偷錄等方式獲得被害者語(yǔ)料.受害者對(duì)于自身的保護(hù)可以滿足這一假設(shè).
相較于現(xiàn)有的攻擊方案,基于單“音頻像素”擾動(dòng)的攻擊在保證高性能的前提下,利用差分進(jìn)化算法,突破以往攻擊注入時(shí)間長(zhǎng)而易被發(fā)現(xiàn)的問(wèn)題,實(shí)現(xiàn)基于單“音頻像素”擾動(dòng)的隱蔽攻擊.
3 基于單“音頻像素”擾動(dòng)的攻擊設(shè)計(jì)
3.1 攻擊目標(biāo)
圖2為基于單“音頻像素”擾動(dòng)的攻擊目標(biāo).受害者的身份標(biāo)識(shí)為v,目標(biāo)說(shuō)話人識(shí)別的相似度比較為函數(shù)f(·),函數(shù)的輸入值為一段語(yǔ)音數(shù)據(jù),輸出值為輸入值和系統(tǒng)中受害者記錄的相似度,當(dāng)輸出值大于閾值θ時(shí),系統(tǒng)認(rèn)為輸入值來(lái)源于受害者.
基于單“音頻像素”擾動(dòng)的攻擊需要滿足3個(gè)目標(biāo):1)攻擊者能偽裝成受害者進(jìn)入系統(tǒng);2)攻擊者能夠修改的采樣點(diǎn)數(shù)量為1;3)生成的擾動(dòng)注入第三方音頻后,幅值絕對(duì)值不能超出音頻編碼允許的最大值.

Fig.2 The goal of the attack based on one-‘a(chǎn)udio pixel’ perturbation圖2 基于單“音頻像素”擾動(dòng)的攻擊目標(biāo)
在這3個(gè)目標(biāo)下,為了更好地建立攻擊的數(shù)學(xué)模型,我們對(duì)這3個(gè)目標(biāo)進(jìn)行了公式化的描述.假設(shè)一個(gè)n維向量x=(x1,x2,…,xn)表示第三方音頻,攻擊的目標(biāo)是生成一個(gè)n維擾動(dòng)p=(p1,p2,…,pn),使得系統(tǒng)識(shí)別x+p的結(jié)果是v,定義為
f(x+p)≥θ.
(2)
接著,為了實(shí)現(xiàn)通過(guò)單“音頻像素”擾動(dòng)的目標(biāo),我們進(jìn)一步地約束擾動(dòng)為
(3)
其中,k為算法搜索到的進(jìn)行攻擊的“音頻像素”位置的集合,當(dāng)基于單“音頻像素”擾動(dòng)實(shí)現(xiàn)攻擊時(shí),k中的元素?cái)?shù)量為1,Di為對(duì)應(yīng)位置i處需要引入擾動(dòng)的大小.在此基礎(chǔ)上,為了保證擾動(dòng)p注入第三方音頻x后的采樣點(diǎn)幅值的絕對(duì)值小于音頻幅值的絕對(duì)值上限l,我們需要擾動(dòng)滿足:
|xi+pi|≤l,i∈{1,2,…,n}.
(4)
攻擊可以被描述為在式(3)和式(4)約束下對(duì)式(2)的優(yōu)化問(wèn)題.
3.2 基于單“音頻像素”擾動(dòng)的攻擊概述

Fig.3 The workflow of the attack base on the one-‘a(chǎn)udio pixel’ perturbation圖3 基于單“音頻像素”擾動(dòng)的攻擊的工作流程圖
基于單“音頻像素”擾動(dòng)的攻擊的工作流程圖如圖3所示,可以分為2個(gè)子模塊:1)候選語(yǔ)料選擇;2)擾動(dòng)生成.其中擾動(dòng)生成包含候選點(diǎn)構(gòu)造、候選點(diǎn)的迭代優(yōu)化和最優(yōu)點(diǎn)測(cè)試攻擊3個(gè)步驟.當(dāng)攻擊者發(fā)起攻擊,候選語(yǔ)料選擇子模塊首先從語(yǔ)料庫(kù)中選擇最有可能實(shí)現(xiàn)攻擊的前50條語(yǔ)料送入擾動(dòng)生成子模塊,擾動(dòng)生成模塊對(duì)于當(dāng)前語(yǔ)料生成候選點(diǎn)集并開始迭代,當(dāng)其中任意一條語(yǔ)料被注入擾動(dòng)后可以偽裝成受害者身份進(jìn)入目標(biāo)系統(tǒng)時(shí),則認(rèn)為攻擊成功;否則,若50條語(yǔ)料全部進(jìn)行嘗試后,則認(rèn)為攻擊失敗.
3.3 候選語(yǔ)料選擇
攻擊者利用一個(gè)數(shù)量巨大的語(yǔ)料庫(kù)對(duì)目標(biāo)受害者進(jìn)行攻擊.然而,針對(duì)特定的受害者,并不是所有語(yǔ)料都能實(shí)現(xiàn)有效的攻擊,因此隨機(jī)選擇候選語(yǔ)料嘗試攻擊的方法將消耗大量無(wú)意義的時(shí)間.為了優(yōu)化攻擊的時(shí)間成本,我們利用深度神經(jīng)網(wǎng)絡(luò)中,位于決策邊界附近的數(shù)據(jù)對(duì)于擾動(dòng)的敏感度高的特性[14],對(duì)語(yǔ)料庫(kù)進(jìn)行篩選,通過(guò)說(shuō)話人識(shí)別系統(tǒng)對(duì)于語(yǔ)料庫(kù)中語(yǔ)料與受害者之間的相似度,把語(yǔ)料庫(kù)中的語(yǔ)料按相似度從高到低排序.最后,我們選擇相似度最高的前 50條語(yǔ)料作為攻擊的候選語(yǔ)料,以相似度從高到低的順序送入擾動(dòng)生成子模塊.
3.4 擾動(dòng)生成
擾動(dòng)生成子模塊采用差分進(jìn)化算法,利用我們提出的音頻段-音頻點(diǎn)-擾動(dòng)值多元組的候選點(diǎn)構(gòu)造模式,解決針對(duì)基于單“音頻像素”擾動(dòng)的攻擊差分進(jìn)化算法的候選點(diǎn)難以被描述的問(wèn)題,實(shí)現(xiàn)能夠有效攻擊目標(biāo)說(shuō)話人識(shí)別系統(tǒng)的擾動(dòng)的生成.
對(duì)于每一條語(yǔ)料,基于單“音頻像素”擾動(dòng)的生成的實(shí)現(xiàn)可以分為3個(gè)步驟:
1) 以特殊的構(gòu)造模式構(gòu)建候選點(diǎn),每個(gè)候選點(diǎn)是一個(gè)包含多個(gè)元素的元組.在初始化過(guò)程中,系統(tǒng)會(huì)根據(jù)攻擊者給出的參數(shù)隨機(jī)生成一個(gè)包含多個(gè)候選點(diǎn)的集合,稱為候選集.
2) 當(dāng)前候選集中的候選點(diǎn)稱為父代候選點(diǎn),對(duì)于每個(gè)父代候選點(diǎn),攻擊者先通過(guò)對(duì)于整體父代候選集中的最優(yōu)點(diǎn)bbest,即注入語(yǔ)料后生成的音頻與受害者相似度最高的候選點(diǎn),進(jìn)行變異得到一個(gè)子代候選點(diǎn),再將子代和父代候選點(diǎn)進(jìn)行交叉,獲得新的候選點(diǎn).最后,保留父代候選點(diǎn)和新的候選點(diǎn)之間對(duì)于攻擊表現(xiàn)更好的候選點(diǎn),完成一次變異—交叉—選擇的過(guò)程.對(duì)所有候選點(diǎn)完成一次變異—交叉—選擇后,則完成一次迭代.
3) 重復(fù)步驟2,每次迭代結(jié)束后,當(dāng)新一代的父代候選點(diǎn)集中的bbest注入語(yǔ)料后能夠以受害者的身份被系統(tǒng)所識(shí)別時(shí)則退出迭代,且返回候選點(diǎn)bbest.當(dāng)?shù)螖?shù)大于設(shè)定閾值后結(jié)束迭代,且返回攻擊失敗.
3.4.1 候選點(diǎn)構(gòu)造模式
候選點(diǎn)是為基于單“音頻像素”擾動(dòng)的攻擊提供優(yōu)化所需要的啟發(fā)信息的重要描述方法.我們結(jié)合音頻數(shù)據(jù)的時(shí)間維度特性提出了基于音頻段-音頻點(diǎn)-擾動(dòng)大小多元組的候選點(diǎn)構(gòu)造模式,實(shí)現(xiàn)候選點(diǎn)的構(gòu)造.為了使候選點(diǎn)構(gòu)造方法更具有普適性,我們介紹當(dāng)需注入擾動(dòng)點(diǎn)數(shù)量為n的情況下,擾動(dòng)點(diǎn)的構(gòu)造模式.構(gòu)造候選點(diǎn)b為
b={xb,x0,D0,x1,D1,…,xn-1,Dn-1},
(5)
其中,xb為候選點(diǎn)插入擾動(dòng)點(diǎn)時(shí)的基準(zhǔn)值,xi為第i個(gè)擾動(dòng)點(diǎn)的相對(duì)偏移,即xb+xi為實(shí)際擾動(dòng)在音頻中插入的絕對(duì)位置,Di為第i個(gè)擾動(dòng)點(diǎn)位置加入擾動(dòng)的大小.
同時(shí),假設(shè)采樣率為s,“音頻像素”分布時(shí)間的寬度為Δt,初始化時(shí)約束候選點(diǎn)b的不等式為
Max(b)≤sΔt,
(6)
其中,Max(b)是計(jì)算候選點(diǎn)中最大xi的函數(shù).初始化階段攻擊者總共生成140個(gè)候選點(diǎn).
3.4.2 候選點(diǎn)的迭代優(yōu)化
在初始化候選點(diǎn)后,我們需要對(duì)候選點(diǎn)進(jìn)行迭代優(yōu)化,從而獲得能夠?qū)崿F(xiàn)攻擊的候選點(diǎn).迭代優(yōu)化過(guò)程可以分為變異—交叉—選擇3個(gè)階段,是基于單“音頻像素”擾動(dòng)的攻擊的核心過(guò)程.變異階段使用已有候選點(diǎn)產(chǎn)生新的候選點(diǎn),實(shí)現(xiàn)候選集的擴(kuò)大;交叉階段使用對(duì)父代和子代的交叉重組,實(shí)現(xiàn)通過(guò)離散雜交增加子代隨機(jī)解的多樣性;選擇階段淘汰對(duì)于實(shí)現(xiàn)目標(biāo)能力較弱的候選點(diǎn),使得候選集整體朝著設(shè)定目標(biāo)不斷進(jìn)化.
1) 變異.我們采用的是best1bin策略進(jìn)行變異.變異階段通過(guò)父代候選點(diǎn)中的最優(yōu)點(diǎn)bbest生成新的子代候選點(diǎn).值得注意的是,變異—交叉—選擇的過(guò)程是針對(duì)一個(gè)父代候選點(diǎn)進(jìn)行的,但是在best1bin策略的變異中并不會(huì)使用該父代候選點(diǎn)的元素值.子代候選點(diǎn)生成:
(7)

2) 交叉.交叉階段首先需要定義交叉概率cr因子:
(8)

當(dāng)確定cr因子后,需要對(duì)父代候選點(diǎn)和子代候選點(diǎn)的每一個(gè)維度進(jìn)行交叉重組:
(9)

3) 選擇.在完成交叉以后,算法需要對(duì)父代候選點(diǎn)b和新生成的侯選點(diǎn)b″進(jìn)行選擇.選擇依據(jù)為將2個(gè)候選點(diǎn)分別注入語(yǔ)料后,比較與受害者的相似度,將相似度更高的候選點(diǎn)保留作為下一代的父代候選點(diǎn),并淘汰另一個(gè)候選點(diǎn).
3.4.3 迭代設(shè)置
在實(shí)驗(yàn)過(guò)程中,攻擊設(shè)定最大迭代次數(shù)為1 000次.同時(shí),為了提高攻擊效率,攻擊設(shè)定了一個(gè)附加約束:每100次迭代計(jì)算最優(yōu)候選點(diǎn)與受害者相似度的提升,當(dāng)提升小于等于0時(shí),則也提前終止迭代,并與達(dá)到最大迭代次數(shù)的情況一樣返回攻擊失敗的提示.
4 實(shí)驗(yàn)設(shè)置
4.1 數(shù)據(jù)集和攻擊環(huán)境
為了探究基于單“音頻像素”擾動(dòng)的攻擊性能,我們使用LibriSpeech[16]公開語(yǔ)音數(shù)據(jù)庫(kù)作為語(yǔ)料數(shù)據(jù)集.LibriSpeech是一個(gè)在語(yǔ)音識(shí)別領(lǐng)域被廣泛使用的語(yǔ)料庫(kù),包含有大約1 000 h的英語(yǔ)語(yǔ)音.每段語(yǔ)音經(jīng)過(guò)去除環(huán)境噪音處理,且分割為10s左右的語(yǔ)音片段.我們將數(shù)據(jù)庫(kù)分為3個(gè)部分,分別對(duì)說(shuō)話人識(shí)別系統(tǒng)進(jìn)行訓(xùn)練、注冊(cè)和攻擊.其中,訓(xùn)練集由train-clean-100數(shù)據(jù)包構(gòu)成,注冊(cè)集由train-clean-100數(shù)據(jù)包中隨機(jī)選擇的60個(gè)人構(gòu)成,攻擊集由test-clean數(shù)據(jù)包中隨機(jī)選擇的40個(gè)人構(gòu)成.
我們搭建了一個(gè)基于d-vector的說(shuō)話人身份認(rèn)證系統(tǒng)作為攻擊的目標(biāo)系統(tǒng).采用由百度提出的Deep Speaker[12]作為說(shuō)話人特制提取器,并將余弦相似性作為說(shuō)話人識(shí)別的決策模塊.我們?cè)谂鋫銾buntu 16.04和Intel?Xeon?CPU E5-2678 v3 2.50 GHz(12核)的服務(wù)器上進(jìn)行了實(shí)驗(yàn),這臺(tái)服務(wù)器還配有8塊NVIDIA GeForce GTX 1070(8 GB)的顯卡.
4.2 評(píng)價(jià)指標(biāo)
我們通過(guò)欺騙說(shuō)話人識(shí)別的成功率(success rate of spoofing speaker recognition,SRoSSR)來(lái)量化單“音頻像素”擾動(dòng)的攻擊的性能,下文簡(jiǎn)稱成功率,具體計(jì)算為:對(duì)于已注冊(cè)的說(shuō)話人,假如存在一個(gè)攻擊集中的音頻,在注入對(duì)抗擾動(dòng)后能使目標(biāo)聲紋識(shí)別系統(tǒng)判斷說(shuō)話人為該已注冊(cè)的說(shuō)話人,則認(rèn)為針對(duì)這一已注冊(cè)的說(shuō)話人的攻擊成功,我們對(duì)所有注冊(cè)集中說(shuō)話人進(jìn)行攻擊,成功率為被攻擊成功的說(shuō)話人占所有目標(biāo)說(shuō)話人的比例.定義為
(10)
其中,S是被攻擊成功的說(shuō)話人數(shù)量,T是所有目標(biāo)說(shuō)話人的數(shù)量.該評(píng)價(jià)方法也被應(yīng)用于Chen等人[48]的工作中,能夠有效評(píng)價(jià)針對(duì)說(shuō)話人識(shí)別系統(tǒng)的性能.
此外,為了評(píng)價(jià)說(shuō)話人識(shí)別系統(tǒng)的性能,我們使用錯(cuò)誤接受率(fake accept rate,FAR)、錯(cuò)誤拒絕率(fake reject rate,FRR)和精確度(accuracy,Acc).其定義分別為:
(11)
(12)
(13)
其中,TP是正確分類陽(yáng)性樣本的數(shù)量,TN是正確分類陰性樣本的數(shù)量,F(xiàn)P是錯(cuò)誤分類陽(yáng)性樣本的數(shù)量,F(xiàn)N是錯(cuò)誤分類陰性樣本的數(shù)量.在這3個(gè)指標(biāo)的基礎(chǔ)上,我們使用等錯(cuò)誤率(equal error rate,EER)對(duì)說(shuō)話人識(shí)別系統(tǒng)的整體性能進(jìn)行客觀的評(píng)價(jià).等錯(cuò)誤率定義為:當(dāng)錯(cuò)誤接受率和錯(cuò)誤拒絕率相等時(shí),錯(cuò)誤接受率和錯(cuò)誤拒絕率的值.
為了評(píng)估用戶調(diào)查中語(yǔ)音的隱蔽性,首先考慮定量的評(píng)價(jià)指標(biāo),正如引言中介紹的增加擾動(dòng)會(huì)引入寬頻噪聲,因此我們使用攻擊注入前后時(shí)頻譜的失真率作為評(píng)價(jià)隱蔽性的指標(biāo).其中,直方圖相似度被用于評(píng)價(jià)時(shí)頻譜的失真率,它是一種能夠評(píng)價(jià)時(shí)頻譜圖失真率的指標(biāo),直方圖相似度定義為[49]
(14)
其中,x和y分別為攻擊注入前后時(shí)頻譜,Hx和Hy分別為x和y歸一化直方圖的向量.此外,S(x,y)∈[-1,1],該值越小則失真率越大,反之失真率越小.除此之外,我們還設(shè)置評(píng)價(jià)指標(biāo)擾動(dòng)數(shù)據(jù)占比對(duì)于用戶調(diào)查結(jié)果進(jìn)行評(píng)價(jià),該數(shù)值越低則攻擊隱蔽性越高,定義為
(15)
其中,DR是擾動(dòng)數(shù)據(jù)占比,distorted_number是被認(rèn)為注入過(guò)擾動(dòng)的音頻數(shù)量,total_number是該類音頻的總量.
5 實(shí)驗(yàn)及評(píng)估
5.1 說(shuō)話人識(shí)別系統(tǒng)性能評(píng)估
我們首先評(píng)估搭建的說(shuō)話人識(shí)別系統(tǒng)在Libri-Speech數(shù)據(jù)集上的性能,該性能能夠證明第三方音頻被識(shí)別成受害者是由攻擊引起的,而不是因?yàn)橄到y(tǒng)本身的性能不佳導(dǎo)致的.
首先,我們使用4.1節(jié)中提到的訓(xùn)練集對(duì)Deep Speaker進(jìn)行訓(xùn)練,接著我們使用注冊(cè)集中每個(gè)人的一條語(yǔ)料進(jìn)行注冊(cè),最后使用每個(gè)人與注冊(cè)語(yǔ)料不同的一條語(yǔ)料進(jìn)行測(cè)試.在認(rèn)證階段,說(shuō)話人識(shí)別系統(tǒng)會(huì)計(jì)算輸入語(yǔ)料的特征和注冊(cè)人的特征之間的余弦相似度sim,設(shè)定閾值為θ,當(dāng)sim<θ時(shí),則認(rèn)為語(yǔ)料不屬于注冊(cè)人;否則,認(rèn)為語(yǔ)料屬于注冊(cè)人.由于余弦相似度的特性θ∈[-1,1].通過(guò)改變閾值θ,我們繪制了說(shuō)話人識(shí)別系統(tǒng)的接收者操作特征曲線,如圖4所示.圖4說(shuō)明說(shuō)話人識(shí)別系統(tǒng)的等錯(cuò)誤率為0.05(EER=0.05).此時(shí)設(shè)定的閾值θ=0.58,說(shuō)話人識(shí)別的精確度為98.5%.圖4說(shuō)明,我們攻擊的說(shuō)話人識(shí)別系統(tǒng)具有良好的性能,可以有效地識(shí)別說(shuō)話人的身份,用來(lái)評(píng)估我們攻擊的性能.

Fig.4 The receiver operating characteristic of the speaker recognition system圖4 說(shuō)話人識(shí)別系統(tǒng)的接收者操作特征曲線
5.2 攻擊性能和隱蔽性評(píng)估
在最優(yōu)情況下,攻擊者可以通過(guò)注入單“音頻像素”的擾動(dòng)來(lái)實(shí)現(xiàn)攻擊.我們使用4.1節(jié)攻擊集中的40個(gè)人,對(duì)已注冊(cè)的60個(gè)人進(jìn)行攻擊.攻擊的成功率能夠到達(dá)100%.這一結(jié)果說(shuō)明,基于單“音頻像素”擾動(dòng)的攻擊可以有效地攻擊說(shuō)話人識(shí)別系統(tǒng).我們還對(duì)基于單“音頻像素”擾動(dòng)的攻擊隱蔽性進(jìn)行了評(píng)估并與Chen等人[6]的工作FakeBob進(jìn)行了比較,F(xiàn)akeBob是目前攻擊說(shuō)話人識(shí)別的工作中最先進(jìn)的方法.結(jié)果顯示我們攻擊平均直方圖相似度S=0.99高于FakeBob的0.94,這一結(jié)果表明基于單“音頻像素”擾動(dòng)的攻擊在隱蔽性方面具有優(yōu)越性.除此之外,下文我們還對(duì)基于單“音頻像素”擾動(dòng)的攻擊的隱蔽性進(jìn)行了用戶調(diào)查進(jìn)一步說(shuō)明了這一優(yōu)越性.
5.3 不同攻擊集中人數(shù)的影響
攻擊集人數(shù)對(duì)于攻擊的性能也存在著影響,我們使用4.1節(jié)中的攻擊集進(jìn)行測(cè)試,把整個(gè)攻擊集的人數(shù)等分成了4組,每組10個(gè)人.隨機(jī)選擇其中的一組作為攻擊集,對(duì)所有注冊(cè)的說(shuō)話人進(jìn)行攻擊.接著,在攻擊集中加入一組人,重復(fù)上述步驟,直到攻擊集中人數(shù)到達(dá)40人.
圖5展示了測(cè)試結(jié)果,結(jié)果表明隨著攻擊集中人數(shù)的上升,攻擊的成功率也呈現(xiàn)上升趨勢(shì).當(dāng)人數(shù)到達(dá)40人時(shí),成功率到達(dá)了100%.這說(shuō)明攻擊者可以通過(guò)加攻擊集中人數(shù)來(lái)提高攻擊的性能,并且由于開源的音頻數(shù)據(jù)庫(kù)和其他音頻數(shù)據(jù)量十分巨大,攻擊者可以借助這些音頻數(shù)據(jù)實(shí)現(xiàn)高性能的攻擊.由于基于單“音頻像素”擾動(dòng)的攻擊在攻擊集中人數(shù)到達(dá)40時(shí)成功率已經(jīng)到達(dá)了100%,使得在40人的條件下探究5.4~5.6節(jié)的實(shí)驗(yàn)無(wú)法得出有意義的實(shí)驗(yàn)結(jié)論,因此在5.4~5.6節(jié)的實(shí)驗(yàn)中我們使用本節(jié)中劃分的30人作為攻擊集進(jìn)行攻擊,下文稱為30人攻擊集.攻擊的基準(zhǔn)成功率為91.7%.

Fig.5 Experiment of different numbers of individuals圖5 不同人數(shù)的實(shí)驗(yàn)
5.4 不同擾動(dòng)點(diǎn)分布時(shí)間寬度的影響
在實(shí)際攻擊中,通過(guò)改變少量“音頻像素”擾動(dòng)的攻擊只會(huì)產(chǎn)生短時(shí)的寬頻噪聲,同樣能夠保證攻擊的隱蔽性,因此值得深入探究.首先考慮“音頻像素”分布的時(shí)間寬度對(duì)于攻擊性能的影響.我們使用4.1節(jié)的注冊(cè)集進(jìn)行注冊(cè),并使用30人攻擊集進(jìn)行攻擊.在設(shè)置擾動(dòng)中改動(dòng)的“音頻像素”數(shù)量為3的條件下,探究“音頻像素”分布時(shí)間的寬度分別為1 ms,10 ms,100 ms,1 000 ms時(shí)攻擊的成功率.
圖6展示了4種不同的“音頻像素”分布時(shí)間的寬度下攻擊的成功率.如圖6所示,當(dāng)“音頻像素”分布時(shí)間的寬度從10 ms擴(kuò)大到100 ms時(shí),性能有小幅度提高,并在10 ms之前和100 ms之后保持穩(wěn)定狀態(tài).這一現(xiàn)象說(shuō)明“音頻像素”分布時(shí)間的寬度對(duì)于攻擊性能存在小幅度的影響,且當(dāng)“音頻像素”分布時(shí)間的寬度到達(dá)100 ms后性能達(dá)到最優(yōu)且趨于穩(wěn)定.

Fig.6 Experiment of different ranges of distribution of “audio pixel”圖6 不同“音頻像素”分布時(shí)間寬度的實(shí)驗(yàn)
5.5 不同數(shù)量的“音頻像素”的影響
我們探究了“音頻像素”數(shù)量對(duì)于攻擊成功率的影響.我們使用4.1節(jié)中的注冊(cè)集進(jìn)行注冊(cè),并使用30人攻擊集進(jìn)行攻擊.除此之外,我們固定“音頻像素”分布時(shí)間為100 ms.結(jié)果如圖7所示,結(jié)果說(shuō)明當(dāng)擾動(dòng)中修改的“音頻像素”數(shù)量上升時(shí),攻擊的成功率會(huì)增加,當(dāng)“音頻像素” 數(shù)量到達(dá)10時(shí),攻擊的成功率會(huì)到達(dá)96.8%并在隨后趨于穩(wěn)定,然而隨著“音頻像素”數(shù)量的增加,攻擊的隱蔽性會(huì)相對(duì)降低.這一現(xiàn)象說(shuō)明,“音頻像素”的數(shù)量和攻擊的成功率之間存在權(quán)衡的關(guān)系.當(dāng)“音頻像素”數(shù)量上升時(shí),攻擊的成功率會(huì)增高,而攻擊的隱蔽性則會(huì)相應(yīng)降低.值得注意的是,當(dāng)“音頻像素”數(shù)量到達(dá)10個(gè)時(shí),攻擊的成功率已經(jīng)超過(guò)了95%,但此時(shí)擾動(dòng)帶來(lái)噪聲的總時(shí)間也遠(yuǎn)低于已有工作匯報(bào)的結(jié)果[6].
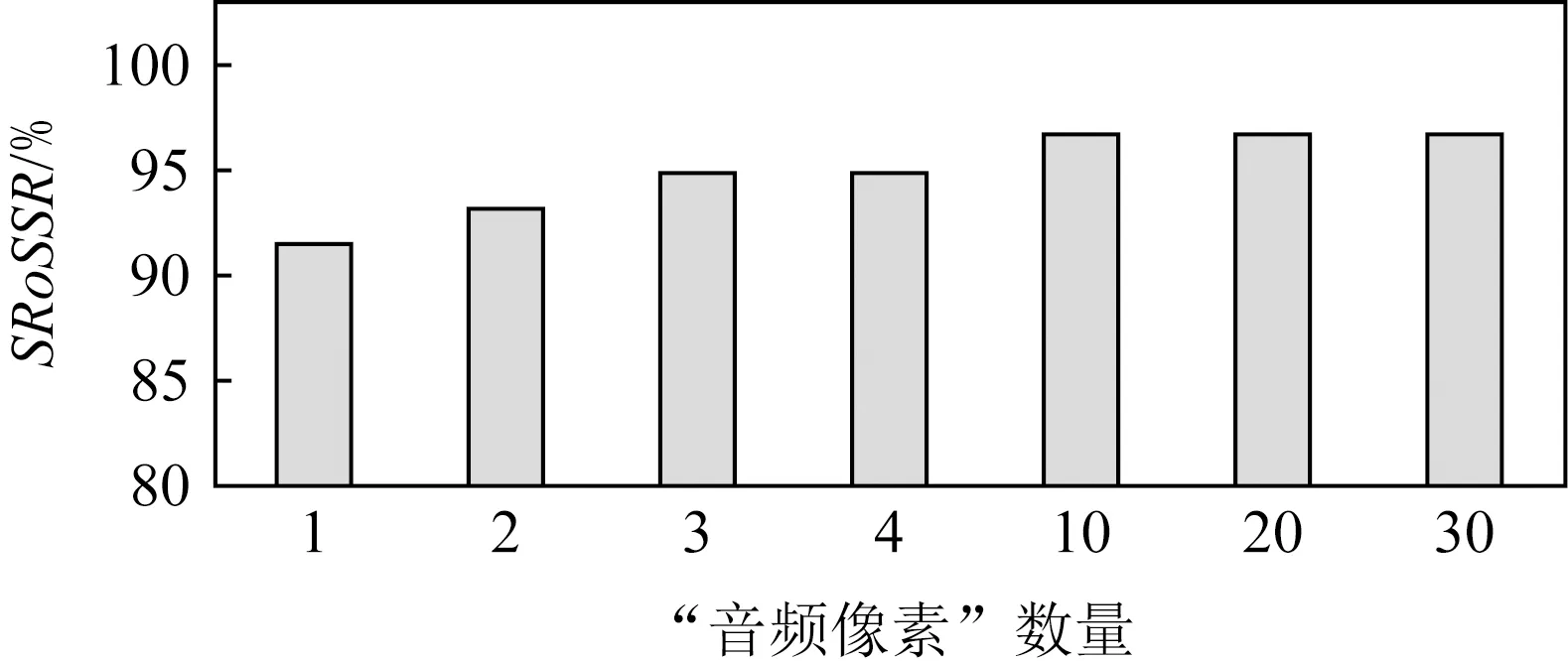
Fig.7 Experiment of different numbers of “audio pixel”圖7 不同“音頻像素”數(shù)量的實(shí)驗(yàn)
5.6 不同性別的影響
性別也是影響攻擊性能的關(guān)鍵性因素之一.為了探究性別對(duì)于攻擊性能的影響,我們從LibriSpeech數(shù)據(jù)集中隨機(jī)選擇20名女性和20名男性的語(yǔ)料組成攻擊集(與注冊(cè)的說(shuō)話人不重復(fù)),并從4.1節(jié)的注冊(cè)集中選取25名女性和25名男性進(jìn)行注冊(cè)并作為受害者.在攻擊過(guò)程中,我們使用攻擊者語(yǔ)料庫(kù)中的每一條語(yǔ)料嘗試攻擊所有注冊(cè)人,并記錄每一次攻擊的結(jié)果.最終,對(duì)所有攻擊成功的語(yǔ)料和受害者的性別配對(duì)關(guān)系進(jìn)行了分析.結(jié)果如表1所示,在所有成功的配對(duì)中同性別之間的攻擊數(shù)量占所有攻擊成功配對(duì)數(shù)的93%,同時(shí)跨性別的攻擊數(shù)量?jī)H占所有攻擊成功配對(duì)數(shù)的7%.這一結(jié)果表明,性別對(duì)于攻擊性能有較大的影響.這是因?yàn)榛趩巍耙纛l像素”擾動(dòng)的攻擊只改變音頻中的一個(gè)或幾個(gè)“音頻像素”,微小的改變無(wú)法改變男性和女性之間音調(diào)和音色的天然不同,使得跨性別的攻擊難以實(shí)現(xiàn).但是,因?yàn)楣粽呖梢垣@得大量的語(yǔ)料庫(kù)進(jìn)行嘗試,所以這并不會(huì)成為限制攻擊者攻擊能力的阻礙.

Table 1 Percentage of Successful Attacks That Were Intergender and Transgender
5.7 不同說(shuō)話人識(shí)別系統(tǒng)的影響
現(xiàn)實(shí)中存在不同的說(shuō)話人識(shí)別系統(tǒng),基于單“音頻像素”擾動(dòng)的攻擊能否在不同系統(tǒng)上都獲得良好的性能也是值得探究的問(wèn)題.為了探究這一問(wèn)題,我們使用GE2E[11]和x-vector[33]分別搭建了2個(gè)說(shuō)話人識(shí)別系統(tǒng),使用4.1節(jié)中的訓(xùn)練集對(duì)它們分別進(jìn)行了訓(xùn)練.與5.1節(jié)一樣我們使用注冊(cè)集中的一條語(yǔ)料注冊(cè),并使用一條語(yǔ)料進(jìn)行測(cè)試.最后得到2個(gè)說(shuō)話人識(shí)別系統(tǒng)的EER分別為0.05和0.06.在此基礎(chǔ)上,我們使用4.1節(jié)中的注冊(cè)集進(jìn)行注冊(cè),使用4.1節(jié)中的攻擊集進(jìn)行基于單“音頻像素”擾動(dòng)的攻擊,即攻擊中改變的“音頻像素”數(shù)量為1.結(jié)果如表2所示,在2個(gè)系統(tǒng)上的成功率分別為98.3%和95%.這一結(jié)果說(shuō)明基于單“音頻像素”擾動(dòng)的攻擊在不同說(shuō)話人識(shí)別系統(tǒng)上都能獲得良好的性能.

Table 2 SRoSSR on Different Speaker Recognition Platforms
5.8 跨數(shù)據(jù)集的攻擊性能
由于不同數(shù)據(jù)集采集的環(huán)境、說(shuō)話人習(xí)慣和采集設(shè)備不同.為了說(shuō)明跨數(shù)據(jù)集下基于單“音頻像素”擾動(dòng)的攻擊仍然有效,我們組織了下面的實(shí)驗(yàn):以4.1節(jié)中的注冊(cè)集進(jìn)行注冊(cè),并使用TIMIT數(shù)據(jù)集[46]和CMU_ARCTIC數(shù)據(jù)集[47]作為攻擊集進(jìn)行基于單“音頻像素”擾動(dòng)的攻擊,即攻擊中改變的“音頻像素”數(shù)量為1.結(jié)果表明,攻擊的成功率達(dá)到了98.3%.這一結(jié)果說(shuō)明在跨數(shù)據(jù)集的情況下,基于單“音頻像素”擾動(dòng)的攻擊仍然可以保持良好的性能.
5.9 用戶調(diào)查
為了體現(xiàn)出我們攻擊的隱蔽性,我們進(jìn)行了用戶調(diào)查并將基于單“音頻像素”擾動(dòng)的攻擊和Chen等人[6]的工作FakeBob進(jìn)行了比較.
1) 用戶調(diào)查的設(shè)置.為了保證志愿者不會(huì)被先驗(yàn)知識(shí)所影響,我們?cè)谶M(jìn)行用戶調(diào)查時(shí)從正常(無(wú)攻擊)的、FakeBob攻擊后的和我們攻擊后的語(yǔ)音數(shù)據(jù)庫(kù)中分別隨機(jī)選擇10條語(yǔ)音打亂后組成30條語(yǔ)音的測(cè)試集(1)用戶調(diào)查數(shù)據(jù):https://flin.group/attack_demo.我們總共招募了10位志愿者包括7名男性和3名女性,在測(cè)試之前我們會(huì)告知志愿者測(cè)試集中包含正常(無(wú)攻擊)的和攻擊后的語(yǔ)音.接著,在安靜的環(huán)境中,每位志愿者單獨(dú)試聽測(cè)試集中的所有語(yǔ)音,每條語(yǔ)音志愿者都可以重復(fù)試聽任意次數(shù),最后志愿者給出當(dāng)前語(yǔ)音是正常或是被攻擊的標(biāo)記.
2) 用戶調(diào)查結(jié)果和分析.經(jīng)過(guò)用戶調(diào)查中設(shè)置的實(shí)驗(yàn)后,我們統(tǒng)計(jì)了每種類型的擾動(dòng)數(shù)據(jù)占比.結(jié)果如表3所示,正常(無(wú)攻擊)的語(yǔ)音中的擾動(dòng)數(shù)據(jù)占比為11%;FakeBob攻擊后的語(yǔ)音中的擾動(dòng)數(shù)據(jù)占比為71%;我們攻擊后的語(yǔ)音中的擾動(dòng)數(shù)據(jù)占比為38%.從表3可知,在志愿者被告知聽到的語(yǔ)音中存在被攻擊的語(yǔ)音后,志愿者對(duì)于攻擊的警惕性增強(qiáng),因此即使是正常(無(wú)攻擊)的語(yǔ)音中也有11%的語(yǔ)音被志愿者認(rèn)為是攻擊后的語(yǔ)音.在這種情況下,基于單“音頻像素”擾動(dòng)的攻擊比目前最先進(jìn)的FakeBob擾動(dòng)數(shù)據(jù)占比低了33%,這說(shuō)明基于單“音頻像素”擾動(dòng)的攻擊的隱蔽性更高,更加不易被人所察覺(jué).

Table 3 The Distorted Rate in Different Attack Types
6 防御方法
由于我們提出的基于單“音頻像素”擾動(dòng)的攻擊的成功率高且隱蔽性強(qiáng),通過(guò)用戶調(diào)查可以說(shuō)明人工的審查很難檢測(cè)出攻擊;同時(shí),由Wang等人[50]提出的最先進(jìn)的針對(duì)單個(gè)元素?cái)_動(dòng)的攻擊的檢測(cè)方法和候選檢測(cè)方法的性能只能達(dá)到9.1%和30.1%.因此本文提出攻擊會(huì)對(duì)說(shuō)話人識(shí)別系統(tǒng)的安全造成顯著的危害.為了避免這一危害,我們?cè)诒竟?jié)討論了3種可行的防御方法.
1) 使用去噪器的防御方法.說(shuō)話人識(shí)別系統(tǒng)可以在預(yù)處理階段增加針對(duì)基于單“音頻像素”擾動(dòng)的攻擊的去噪器,由于注入單“音頻像素”的擾動(dòng),所以注入的擾動(dòng)幅值大,去噪器將局部變化認(rèn)為超過(guò)閾值的點(diǎn)去除,從而實(shí)現(xiàn)去除注入擾動(dòng)的目的.這一方法在Chen等人[51]的工作中已經(jīng)被證明能夠有效地抵抗單像素的攻擊,并在圖像領(lǐng)域取得了98.6%的防御成功率.
2) 使用重建算法的防御方法.由于聲音是連續(xù)的信號(hào),所以在音頻信號(hào)中時(shí)間相近的“音頻像素”存在一定相關(guān)性,通過(guò)這種相關(guān)性我們可以通過(guò)重建的方式將音頻進(jìn)行重建,重建后的音頻將不包含與周圍“音頻像素”不相關(guān)的擾動(dòng)點(diǎn).這種方法也被Liu等人[52]證明了防御針對(duì)基于單像素?cái)_動(dòng)攻擊的有效性.
3) 使用不同壓縮方式的防御方法.說(shuō)話人識(shí)別系統(tǒng)可以通過(guò)不同的壓縮方式將音頻進(jìn)行壓縮,實(shí)現(xiàn)對(duì)于單“音頻像素”擾動(dòng)的攻擊的防御.由于不同壓縮算法(如MP3[53])的特性在壓縮過(guò)程中會(huì)將原音頻中的“音頻像素”壓縮,所以擾動(dòng)點(diǎn)所在位置的信息會(huì)被去除,從而使得擾動(dòng)無(wú)法生效.
7 討 論
7.1 時(shí)頻信息層面的攻擊
在說(shuō)話人識(shí)別領(lǐng)域,由于時(shí)頻信息相較于時(shí)域信息帶有更多能夠描述說(shuō)話人特征的信息,因此對(duì)于時(shí)頻信息的分析是目前說(shuō)話人識(shí)別中主流的預(yù)處理方式.由于時(shí)頻信息相較于時(shí)域信息的粒度更細(xì),因此如果針對(duì)時(shí)頻信息(如MFCC等)進(jìn)行擾動(dòng)攻擊,實(shí)現(xiàn)的說(shuō)話人識(shí)別攻擊能夠獲得更高的性能和隱蔽性.由于說(shuō)話人識(shí)別系統(tǒng)接收的是時(shí)域的音頻信息并且目前的主流時(shí)頻分析方法(如MFCC等)是不可逆的,所以如何將攻擊后的時(shí)頻信息映射回時(shí)域是實(shí)現(xiàn)上述攻擊的一大挑戰(zhàn).我們?cè)O(shè)想使用自編碼器可以有效地解決這一問(wèn)題,已有工作[54]已經(jīng)證明自編碼器具有良好的降維能力,這一能力能夠有效地幫助完成高維的時(shí)頻信息映射到低維的時(shí)域信息的任務(wù),從而實(shí)現(xiàn)時(shí)頻信息層面的攻擊.
7.2 通過(guò)空氣傳播的擾動(dòng)注入方式
除了本文假設(shè)的攻擊者通過(guò)用戶接口注入擾動(dòng)的方式以外,通過(guò)音頻在空氣中傳播的擾動(dòng)注入方式也是常見(jiàn)的注入方式之一.聲波在空氣中傳播會(huì)引入音頻的失真(如衰減、環(huán)境噪聲和多徑效應(yīng))導(dǎo)致最終的結(jié)果無(wú)法達(dá)到預(yù)期.針對(duì)這一問(wèn)題,目前已有工作給出了一些解決方案,如在有先驗(yàn)知識(shí)的條件下整合房間脈沖響應(yīng)附加到擾動(dòng)上,使得生成的音頻能夠在空氣中傳播而不損失擾動(dòng)信息[55].除此之外,Li等人的工作[8]提出了通過(guò)在對(duì)抗學(xué)習(xí)過(guò)程加入符合環(huán)境失真條件的隨機(jī)擾動(dòng),使得生成的擾動(dòng)能夠穩(wěn)定地在空氣中傳播而避免失真帶來(lái)的性能損失.因此,在基于單“音頻像素”擾動(dòng)的攻擊中可以在擾動(dòng)生成子模塊將符合環(huán)境失真條件的隨機(jī)擾動(dòng)附加到擾動(dòng)之上,使得攻擊能夠生成不受空氣傳播中失真影響的單“音頻像素”擾動(dòng),實(shí)現(xiàn)通過(guò)空氣傳播的擾動(dòng)注入方式.
7.3 減少對(duì)于說(shuō)話人識(shí)別系統(tǒng)的訪問(wèn)
在攻擊過(guò)程中,對(duì)于說(shuō)話人識(shí)別系統(tǒng)的大量訪問(wèn)會(huì)降低攻擊的效率并且增加攻擊被管理人員發(fā)現(xiàn)的可能性.替代模型是解決這一問(wèn)題最先進(jìn)的方式.攻擊者通過(guò)對(duì)于目標(biāo)系統(tǒng)的少量訪問(wèn),可以在本地建立目標(biāo)說(shuō)話人識(shí)別系統(tǒng)的替代模型,從而大幅度減少對(duì)于目標(biāo)系統(tǒng)的訪問(wèn)次數(shù).Papernot 等人[56]最早在圖像對(duì)抗攻擊中應(yīng)用了這種方法并取得了良好的性能.Chen等人[48]將該方法應(yīng)用于攻擊說(shuō)話人識(shí)別系統(tǒng)中,在不降低攻擊性能的前提下,實(shí)現(xiàn)了對(duì)于訪問(wèn)次數(shù)的優(yōu)化,說(shuō)明了替代模型在攻擊說(shuō)話人識(shí)別領(lǐng)域中的可用性和高效性.因此,單“音頻像素”攻擊可以借助替代模型,從而實(shí)現(xiàn)減少對(duì)于說(shuō)話人識(shí)別系統(tǒng)的訪問(wèn)的目的.
8 總 結(jié)
本文提出了一種新穎的基于單“音頻像素”擾動(dòng)的說(shuō)話人識(shí)別隱蔽攻擊,獲得了相較以往攻擊更高的隱蔽性.利用差分進(jìn)化算法不依賴梯度的特性,克服了已有工作中存在局部最優(yōu)的問(wèn)題,提出了基于音頻段-音頻點(diǎn)-擾動(dòng)的構(gòu)造模式,解決了針對(duì)我們的攻擊差分進(jìn)化算法的候選點(diǎn)難以被描述的問(wèn)題,實(shí)現(xiàn)了具有高性能高隱蔽性的攻擊.這種攻擊在由百度提出的Deep Speaker上獲得了100%的成功率,同時(shí)攻擊對(duì)主流的說(shuō)話人識(shí)別都有良好的攻擊性能表現(xiàn).我們還探究了不同因素對(duì)于攻擊性能的影響,并且進(jìn)行了用戶調(diào)查說(shuō)明了攻擊的隱蔽性.最后,我們提出了幾種針對(duì)攻擊有效的防御手段,進(jìn)一步增強(qiáng)了說(shuō)話人識(shí)別的安全性.
作者貢獻(xiàn)聲明:沈軼杰提出基于單“音頻像素”擾動(dòng)的攻擊方案,設(shè)計(jì)總體實(shí)驗(yàn),優(yōu)化算法,整體文章撰寫;李良澄實(shí)現(xiàn)基于單“音頻像素”擾動(dòng)的攻擊,設(shè)計(jì)候選點(diǎn)構(gòu)造模式;劉子威搭建攻擊測(cè)試平臺(tái),收集實(shí)驗(yàn)所需數(shù)據(jù);劉天天嘗試迭代優(yōu)化中不同參數(shù)對(duì)于性能的影響;羅浩繪制文章內(nèi)圖片,對(duì)文章進(jìn)行修訂;沈汀在修改過(guò)程中,對(duì)于實(shí)驗(yàn)給出指導(dǎo)性建議,提出使用直方圖相似度對(duì)失真率進(jìn)行衡量,從而解決對(duì)于攻擊性能量化的目標(biāo),并對(duì)文章整體進(jìn)行了修訂;林峰指導(dǎo)實(shí)驗(yàn)的總體設(shè)計(jì)和文章寫作指導(dǎo);任奎指導(dǎo)文章寫作,對(duì)于克服文中挑戰(zhàn)給出方向性建議.
猜你喜歡
艦船科學(xué)技術(shù)(2022年15期)2022-09-14 09:21:50
公民與法治(2020年5期)2020-05-30 12:33:40
電子制作(2019年15期)2019-08-27 01:12:00
電子制作(2018年19期)2018-11-14 02:37:08
自動(dòng)化學(xué)報(bào)(2017年11期)2017-04-04 02:52:58
中國(guó)健康心理學(xué)雜志(2015年5期)2015-09-05 09:55:54
母子健康(2015年1期)2015-02-28 11:21:37
噪聲與振動(dòng)控制(2015年4期)2015-01-01 07:08:21
中國(guó)社會(huì)公共安全研究報(bào)告(2013年1期)2013-03-11 18:07:49
軸承(2010年2期)2010-07-28 02:26:12
