微信惡意賬號檢測研究
2021-11-05 12:08:32殷其雷李浩然苗園莉
計算機研究與發展 2021年11期
楊 征 殷其雷 李浩然 苗園莉 元 東 王 騫 沈 超 李 琦
1(清華大學網絡科學與網絡空間研究院 北京 100084)2(武漢大學國家網絡安全學院 武漢 430072)3(西安交通大學網絡空間安全學院 西安 710049)(yz17@mails.tsinghua.edu.cn)
隨著移動互聯網的發展,移動社交網絡迅速地成為了主流的社交平臺,在人們的生活和工作中占據了重要的地位.除了傳統的對話交流,移動社交網絡平臺還為用戶提供了更加多樣化的服務,例如閱讀、購物等.眾多的用戶共同編織了一張復雜的社交網絡,他們的一舉一動都在影響著這個網絡的發展.與此同時,一些不法分子也在社交網絡上活躍著,他們使用批量注冊的賬號,在社交平臺上進行各種惡意活動,例如賭博、刷閱讀量、引導用戶流等,以此牟取不法利益.
為了防止惡意賬號危害社交網絡生態環境,許多惡意賬號檢測模型被提出.例如基于用戶發送的內容(如文字、圖片、鏈接等)、用戶行為(如點贊、上傳、關注等),來訓練檢測模型[1-6];或者根據用戶間的社交關系(如好友、關注、訂閱等)構建圖模型,來挖掘惡意團體[7-10].然而,無論是用戶發送的內容、用戶的行為,還是用戶間的社交關系,都需要一定的時間來收集和積累.在這段期間里,惡意賬號已經可以開展大量的惡意活動,對正常用戶造成影響.另一方面,當今黑色產業鏈已大規模地采用自動化賬戶注冊技術來批量獲取社交網絡賬號,以確保其惡意活動可持續、影響范圍廣且獲得的不法利益高.本文首先具體介紹了現有惡意賬號檢測工作并分析了它們的優缺點.為克服它們的局限性,更加快速而有效地應對此類黑產威脅,減少惡意賬號造成的危害,并盡早檢測出此類由黑產鏈批量注冊的惡意賬號,本文提出了基于社交網絡賬號注冊屬性的惡意賬號檢測方法.本文工作旨在僅基于賬號注冊屬性實現對惡意賬號的有效檢測,在注冊階段即遏止惡意賬號的進一步活動.
微信是現今中國最大的移動互聯網社交網絡平臺,每天的賬號注冊量可達百萬級別.在與微信平臺所有方——騰訊公司——達成深度合作的基礎上,本文對其提供的2017年部分微信注冊賬號數據進行了深入統計分析,發現在某些時段上惡意賬號占全部新注冊賬號的比例可高達50%,但由于涉及商業隱私,我們無法給出具體的數值.此外,還發現惡意賬號會使用某些相同的注冊屬性,如某個惡意團體注冊的賬號具有相同的IP前綴和手機號碼前綴.這是由于惡意團體注冊賬號時受時間、人力、設備等資源所限,使用機器批量注冊造成的.此外,惡意賬號的某些注冊屬性會存在異常,如注冊國家與用戶填寫的國家不一致、注冊IP所在省份與手機號所在省份不一致等.這可能是因為這些屬性是黑色產業鏈的批量注冊工具隨機生成的,未考慮正常賬號屬性間的內在聯系.針對惡意賬號具有的相似性特征和異常特征,本文使用了帶權重的無向非連通圖的賬號聚類算法,用圖中的點代表賬號,邊代表賬號間的相似關系,圖中的連通分量便能體現賬號間的群組關系,從而能夠快速地將大量注冊賬號聚集成若干個群組.注意到每一個連通分量都是一張有權重的無向連通子圖,本文提出了基于帶權重的無向連通圖的惡意檢測算法,為每個賬號計算出惡意分數來衡量其惡意程度.惡意分數高的賬號將最終被判定為惡意賬號.
本文的貢獻主要有3個方面:
1) 系統分析了近年來社交網絡惡意賬號檢測的研究工作,包括基于賬號屬性特征的檢測模型與基于賬號間關系的檢測模型;
2) 對微信賬號的注冊數據進行大規模地統計分析,系統總結了惡意賬號具有相似與異常的注冊屬性模式;
3) 設計了一種基于注冊屬性的無監督惡意賬號檢測方法,可在賬號注冊階段實現對大規模惡意賬號的快速有效檢測,且該方法無需提供標簽數據作為訓練集.
1 社交網絡惡意賬號檢測工作
目前已經有很多在社交網絡上檢測惡意賬號的工作.這些工作主要可以分為兩大類模型:1)基于賬號屬性特征的檢測模型;2)基于賬號間關系的檢測模型.
基于賬號屬性特征的檢測模型通常將檢測惡意賬號視為一個機器學習領域的二分類問題[1-6,11-18].根據每個賬號的自身屬性如發布的內容(如微博、Twitter中的URL等)、操作行為(如點擊流、關注、訂閱等)、注冊信息(如IP地址、User Agent等)來提取相關特征,然后使用提取的特征和有標簽的數據來訓練有監督的機器學習模型.如Almaatouq等人通過分析Twitter用戶的行為、消息內容以及用戶的個人畫像信息,提取特征區分正常賬號和不同類型的惡意賬號[1];Egele等人基于用戶行為建立用戶畫像,通過用戶行為發生突變的異常現象,結合惡意賬號活動具有相似性的特點進行檢測[2];Freeman等人利用賬號登錄的數據,從概率統計分析的角度檢測用戶是否為惡意賬號[3];Badri等人通過用戶的點贊行為提取特征區分惡意賬號[4];Wang等人通過對用戶點擊行為數據劃分會話,在此基礎上進行會話和點擊行為流2個層面的特征提取[5];Thomas等人基于賬號注冊時的昵稱、郵箱名等信息提取惡意注冊模式,并結合用戶注冊的行為流、用戶代理等信息檢測惡意賬號[18].
然而真實社交網絡的用戶數量是巨大的.以微信為例,每天新注冊的用戶數量在百萬級,且給如此多的數據標注標簽是不現實的.這導致基于賬號自身屬性和有監督機器學習算法的檢測模型難以在大規模的社交網絡中進行實際使用.另一方面,使用有監督方法檢測惡意賬號的方法魯棒性難以得到保障,一旦檢測使用的模型或特征提取的方式不慎泄露,惡意用戶可以有針對性地修改自己的行為模式和個人信息,使得模型分類效率大幅下降從而逃避檢測.而本文提出的檢測模型是無監督的,不依賴標簽,使得我們的檢測模型更有實用價值.
基于賬號間關系的檢測模型通常使用圖模型來刻畫賬號間關系,故可被稱為基于圖拓撲的檢測模型.其通常以用戶為點,用戶之間的關系為邊建圖,利用圖的拓撲結構發現惡意賬號[7-10,19-39].常見的用戶間的關系有:好友關系、關注與被關注、訂閱與被訂閱、相同或相似的行為、使用相同的設備或資源等.比如Jiang等人根據分析賬號在社交網絡上的行為來建立一張賬號行為關系圖,通過圖拓撲分析賬號的同步性和異常性,進而發現惡意賬號[7];或者利用圖的信息傳播特點挖掘惡意賬號,例如通過受害賬號及其社交關系拓撲找出惡意賬號[8],通過部分賬號標簽和賬號間社交關系構成的社交網絡圖推導其他賬號的標簽[9],或計算信任關系在圖中的傳播從而發現信任度低的團體[10].
然而,這些已有的基于圖拓撲的社交網絡惡意賬號檢測方法都依賴用戶在社交網絡上產生足夠的行為或建立足夠多的社交關系.這就意味著只有當惡意賬號在社交網絡上活躍了一段時間,比如幾天、幾周甚至幾個月等,這些圖模型檢測方法才能夠將它們檢測出來.而本文提出的檢測模型,是利用用戶的注冊信息來進行惡意賬號檢測的,檢測的時間點是賬號注冊當天,從而極大壓縮惡意賬號在社交網絡上的存活時間.
Thomas等人的工作與本文方法在檢測算法設計上較為相似,不過他們檢測惡意賬號時使用了較多只適用于Twitter網站的數據與特征,如注冊流、User Agents、表單提交時間等[18],且運用了各賬號在網頁上的具體操作與交互數據.而我們的工作僅使用了更加通用且僅提取自賬號注冊階段的特征,如IP地址、手機號等,從而可僅基于賬號注冊信息進行有效快速的判斷.Yuan等人提出了Ianus方法同樣可在注冊階段檢測惡意賬號,但是該方法需要賬號的標簽數據來進行訓練和調整[40].而本文方法不依賴標簽數據,只通過對比和度量各賬號間注冊屬性相似性,即可構建賬號相似連通圖并挖掘由疑似惡意賬號所組成的連通分量,屬于無監督類方法,故適用性更佳.如表1所示,我們詳細地列出了各檢測方法所運用的信息與本文方法的差異.

Table 1 Comparison of Sybil Detection Methods on Social Network

續表1
2 惡意注冊賬號分析
微信作為中國最大的移動互聯網社交網絡,現已具有10億的月活用戶(1)http://www.xinhuanet.com/2018-03/05/c_1122488991.htm,背后則是每天百萬級別的用戶注冊量.為了盡早檢測出批量注冊的惡意賬號并防止惡意賬號作惡,本文通過分析微信的賬號注冊數據,挖掘惡意賬號的模式與特點,并設計和提出相應的檢測算法.本文工作雖基于微信賬號注冊數據,但本文所分析和總結出的在線社交網絡惡意賬號在注冊階段所表現出的重要特性,包括惡意賬號間的相似特征及與正常用戶不同的異常特征,均源自于黑色產業鏈所運用的自動化批量賬號技術,與正常用戶的人工注冊存在本質不同.故本文所分析的惡意賬號注冊特性在其他在線社交網絡平臺上同樣適用.據此,本文研究方法通用性好,可進一步運用于其他社交網絡場景中的惡意賬號檢測任務中.
2.1 注冊數據
賬號注冊數據主要包括一系列注冊屬性,比如注冊IP地址、昵稱、手機號碼、WiFi MAC、注冊設備ID、微信客戶端版本號、注冊設備類型、注冊時間、注冊國家等.為了保護用戶隱私,WiFi MAC、注冊設備ID等在收集前已經被哈希加密(經哈希處理后,理論上用戶和屬性值信息仍然能保持一一對應關系,不會對后續分析造成干擾);注冊國家、微信客戶端版本號等均用代號表示.據抽樣觀察時間跨度達3個月的微信注冊賬號數據發現,正常賬號和惡意賬號的比例及各項特征的分布較為穩定.本文進一步對按不同時間跨度劃分的注冊數據做了驗證,結果表明按天劃分的數據集的統計結果更具有區分度與代表性.據此,本節將對某一天的微信注冊數據進行細致的統計分析.
2.2 注冊屬性分析
受制于有限的時間資源與設備資源,同時為最大化攻擊效率及不法獲益,黑色產業鏈通常會運用自動化賬戶注冊技術等批量獲取賬號,進而導致在多注冊屬性上呈現出相似性,且與正常注冊賬號表現相異.
2.2.1 IP地址
本文首先對賬號注冊時使用的IP地址前綴進行了統計,統計時采用的前綴長度是24.結果顯示,在正常賬號中,IP地址前綴相同的賬號數一般小于50;而在惡意賬號中,IP地址前綴相同的賬號數超過了50的情況較多.該現象表明惡意賬號比正常賬號更傾向使用相同的IP前綴進行注冊.
2.2.2 手機號碼
注冊微信賬號需提供手機號碼.惡意用戶為持續注冊賬號,需要從通信運營商批量獲取手機號.需要注意的是,手機號碼的末4位是用戶的個人編號,而除去末4位后的手機號碼前綴,則包含有該號碼的服務提供商和區域信息.經統計除去末4位后的手機號碼的前綴發現:所有惡意賬號中所使用的手機號碼前綴總量較少,單個號碼前綴被復用10次以上較為常見;所有正常賬號中所使用的手機號碼前綴總量與正常賬號總量接近,單個號碼前綴復用3次以下的情形較為常見.這表明惡意賬號更傾向使用相同的手機號碼前綴進行注冊.
2.2.3 WiFi MAC
當前手機接入網絡主要通過2種方式:蜂窩網絡或WiFi.WiFi MAC是指當移動設備通過WiFi接入網絡時,WiFi網關的MAC地址.如果注冊時使用的是蜂窩網絡,則賬號的WiFi MAC屬性為空.本文經統計分析發現,惡意賬號更傾向于使用相同的WiFi MAC進行注冊.
2.2.4 設備ID
經統計每個設備ID所關聯的注冊賬號數量,本文發現共用同一臺設備的惡意賬號數量遠遠多于正常賬號.此現象表明惡意賬號更傾向于使用相同的設備進行批量注冊.
2.2.5 昵稱模式
本文對正常與惡意賬號所使用的昵稱進行了以字符粒度的統計分析,發現正常賬號昵稱通常由中文與個性化字符所組成,而惡意賬號昵稱往往包含有特殊字符,如冒號、分號等,且惡意賬號間往往會共用相同的特殊昵稱模式.
2.2.6 客戶端版本與操作系統類型
通過對用戶注冊賬號時所使用的微信客戶端版本號和手機操作系統類型的分析,本文發現使用老舊客戶端或操作系統注冊的賬號集合中,惡意賬號所占比例極大.具體地,數據集中有約2 000個賬號是基于一個老舊的安卓系統注冊的,其中惡意賬號占比96.5%.此外,在iOS 8(一個老舊的iOS操作系統)系統下注冊的所有賬號中,99%的注冊賬號是惡意的.此現象背后的原因是黑產出于成本、穩定性等考慮而更傾向于使用老舊的設備與自動化注冊腳本.
2.2.7 地理位置
經映射,一個公網IP地址可以對應到一個地理位置(國家、省、市),手機號碼同理.通過對比注冊賬號時用戶的IP地址對應的地理位置與手機號碼對應的地理位置,本文發現65%的惡意賬號表現出了地理位置不一致的現象,而正常賬號的兩地理位置均基本一致.該現象一個可能的原因是,黑產從業者用于注冊賬號的手機號碼可能是從當地的通信運營商處獲得的,而用于注冊賬號的設備可能是遠程設備或云服務;另一個可能的原因則是黑產使用的手機號碼是從外地購買得到的[42],設備則是本地的.因此,惡意賬號注冊時更容易出現不一致地理位置的現象.
2.2.8 IP-WiFi多對多
本文對正常賬號和惡意賬號在注冊時所使用的IP和WiFi MAC兩個屬性的對應關系進行了統計分析,發現惡意賬號中的單一WiFi MAC可能對應著多個IP,同時這些IP又可能對應著多個WiFi MAC.而在正常賬號中,此類型的IP與WiFi MAC數量稀少.該現象背后的原因是,惡意賬號很可能是使用虛擬設備注冊的,因而IP與WiFi MAC之間存在著多對多映射關系.其恰好展現了該類注冊賬號的虛假性.
2.2.9 注冊時間
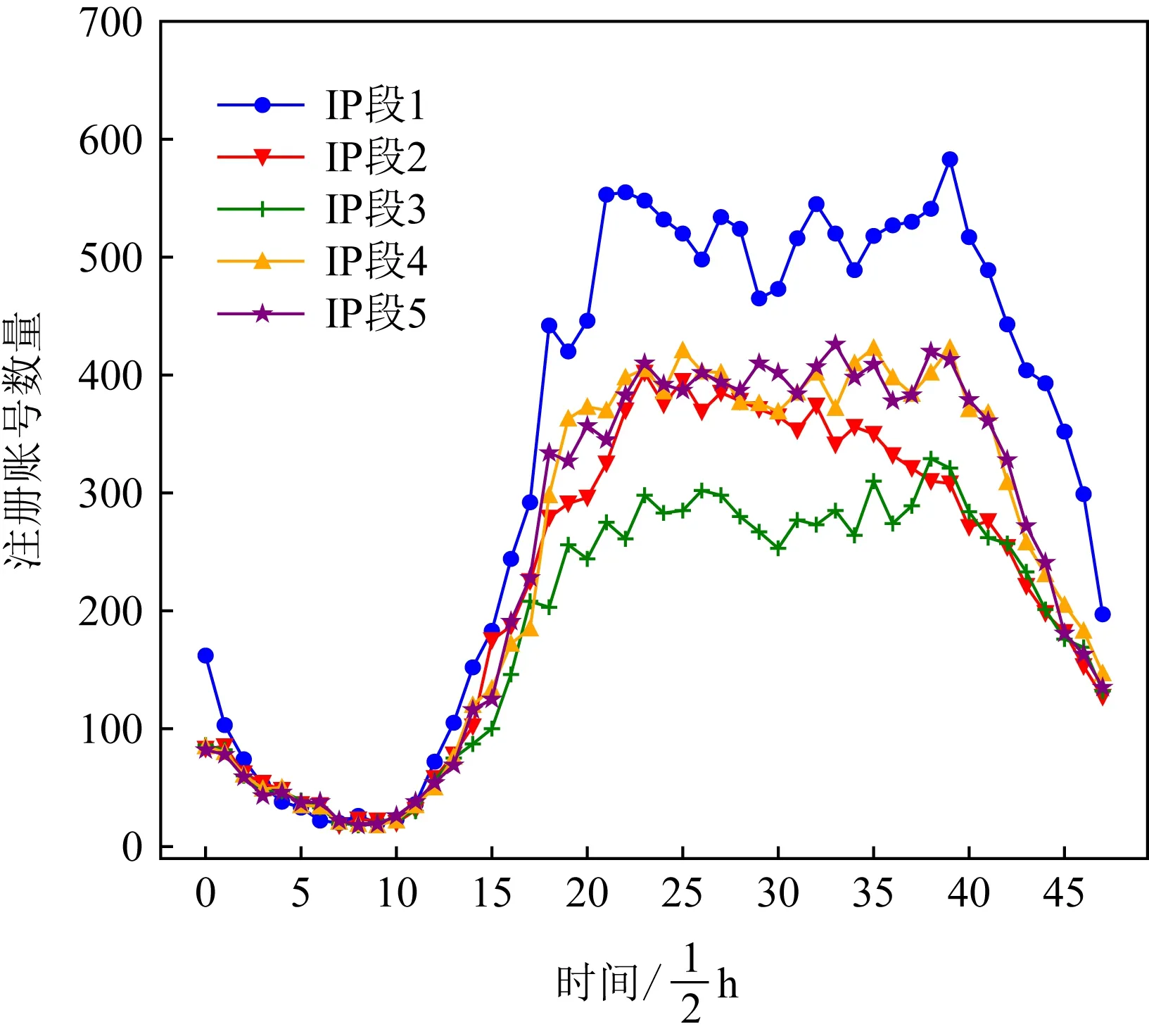
Fig.1 Distribution of normal account registrations圖1 正常賬號注冊分布
本文于圖1與圖2中展示了不同賬號的注冊時間分布.其中圖1是對正常賬號統計的結果,圖2是對惡意賬號統計的結果.圖1和圖2中不同的折線表示不同的IP段.比較發現,正常賬號的注冊時間分布比較一致,且在半夜僅有很少注冊量,與大多數人的生活作息相符.惡意賬號的注冊時間則分布混亂,不僅均勻分布在24 h里,還在某些較短時間內較為密集,與正常賬號差異明顯.
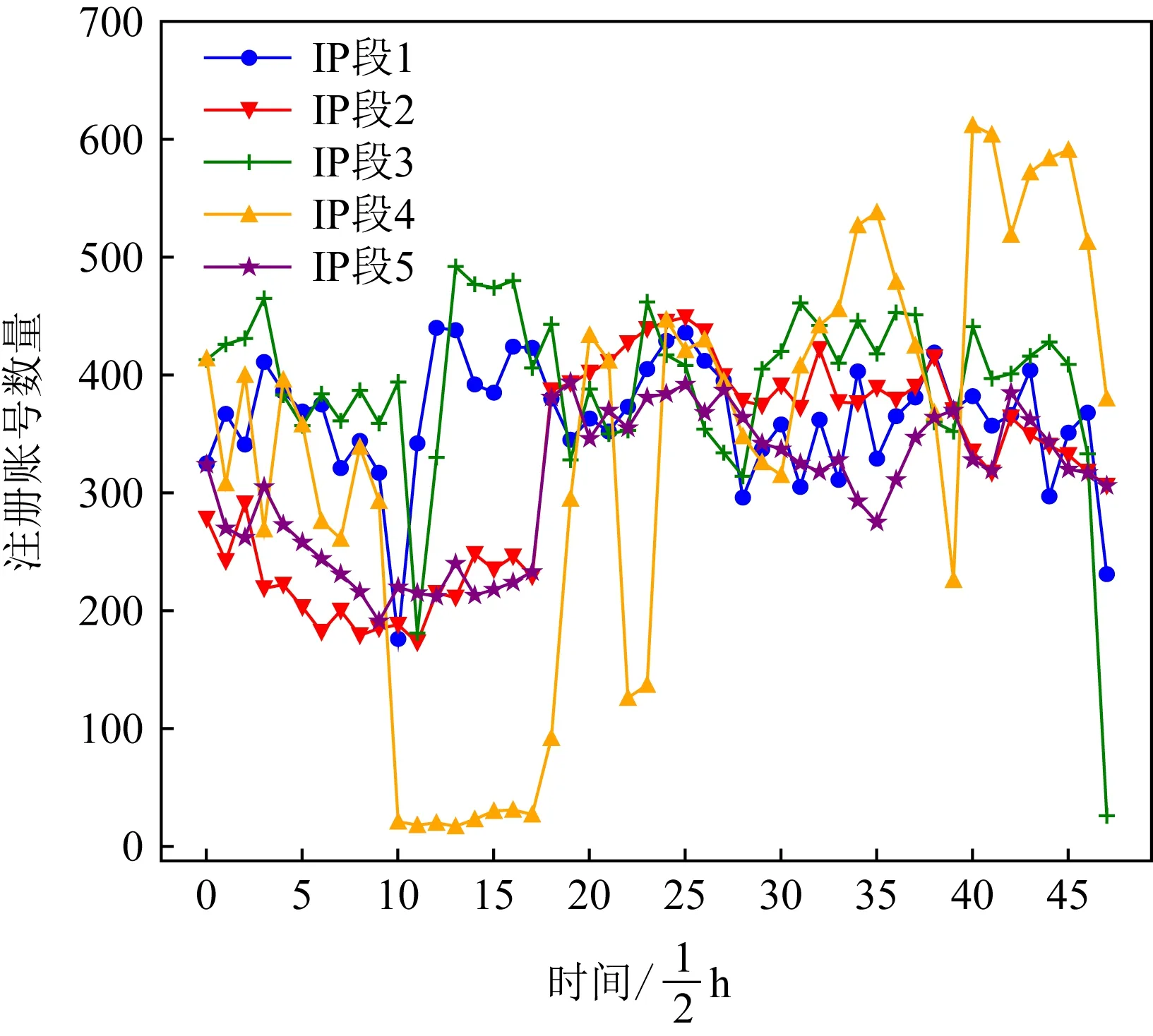
Fig.2 Distribution of malicious account registrations圖2 惡意賬號注冊分布
3 基于注冊屬性的惡意賬號檢測
根據第2節對賬號注冊數據的深入統計分析,本文發現惡意賬號容易使用某些相同的注冊屬性,并會在一些屬性上與正常注冊賬戶表現相異.這是因為受制于有限的各項資源,惡意團伙一般使用批量注冊的方法降低成本,包括使用同一批設備、IP注冊、在相同時間注冊等.基于這些特性,本文提出了一種基于注冊屬性的惡意賬號檢測方法,其主要運用了無監督圖聚類技術.方法具體由5個步驟組成:1)賬號注冊特征提取.2)特征權重配置.3)賬號相似度計算.4)賬號相似圖構建.5)基于圖聚類的惡意賬號群體挖掘.
在整體上,該方法首先提取各用戶賬號的注冊特征數據.隨后,方法基于預配置的權重策略,計算不同賬號間的注冊屬性相似度以構建各注冊賬號的連通圖,并最終通過圖聚類方法,挖掘連通圖中的特定群體來有效識別惡意賬號.方法整體流程如圖3所示:
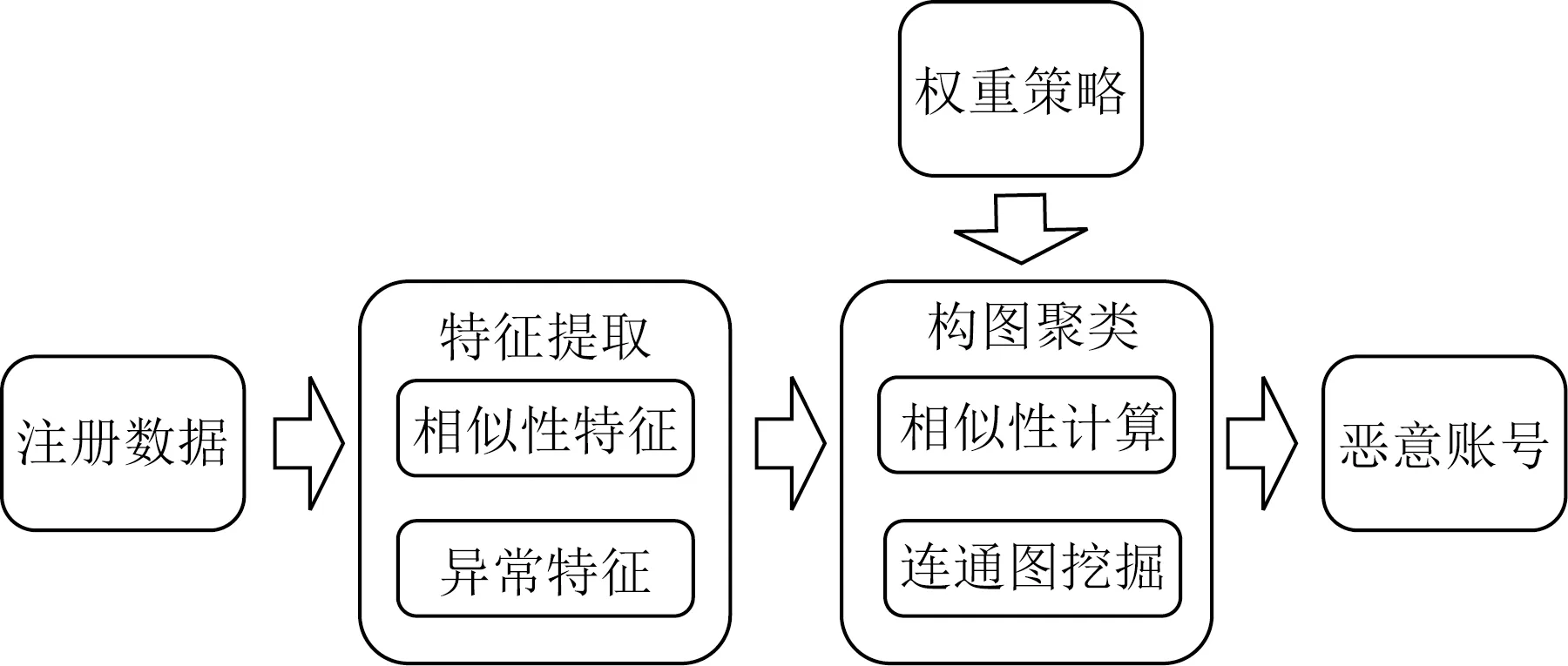
Fig.3 Overview of our registration pattern based wechat sybils detection method圖3 基于注冊屬性的微信惡意賬號檢測方法流程圖
3.1 注冊特征提取
根據數據分析階段的發現,本文首先對各用戶賬號提取多種注冊屬性,并基于注冊屬性進一步獲取它們的相似性及異常特征.方法所提取的注冊屬性及各屬性可獲取的特征如表2所示:
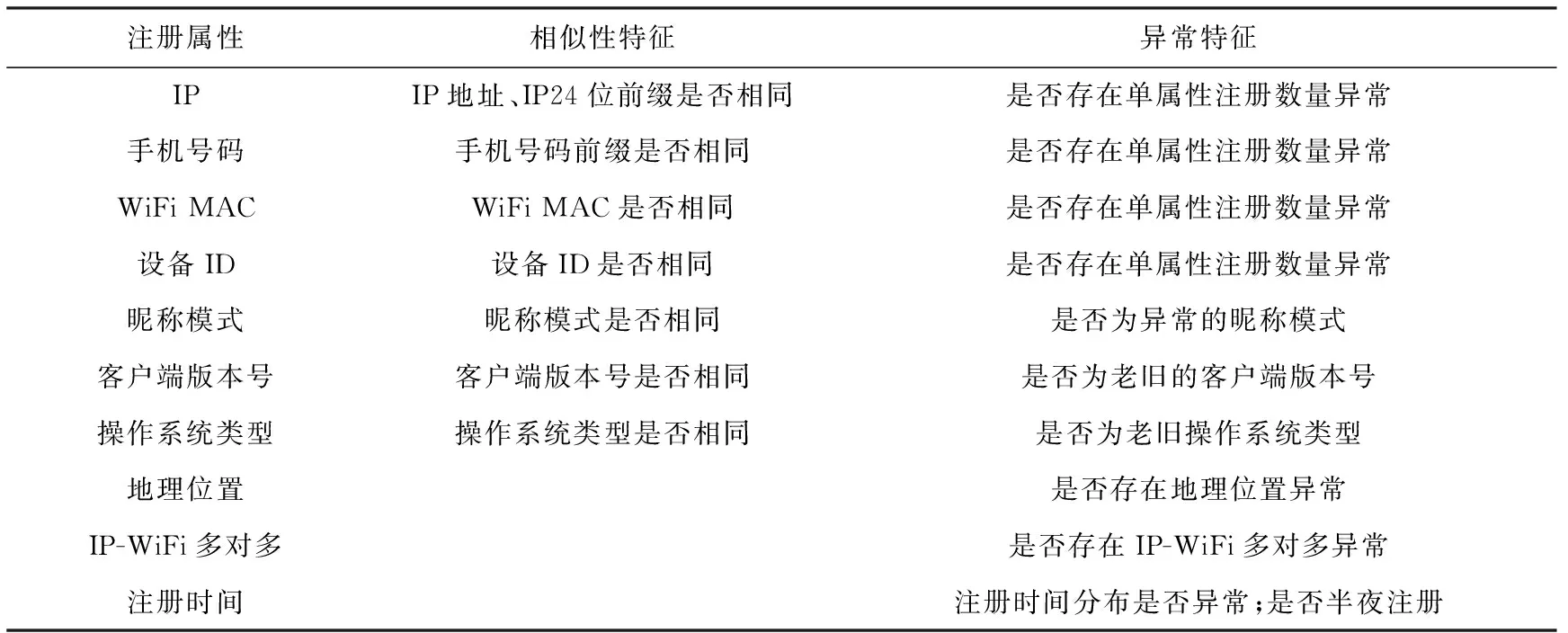
Table 2 Registration Patterns and Features Extracted by Our Method
3.1.1 昵稱模式
不同于其他可直接提取的注冊屬性,本文基于特定的昵稱模式及提取方法來更針對性處理各賬號的注冊昵稱.根據字符特征,昵稱可分為中文、英文、混合字符3種類型.從中文昵稱中,可以提取出傳統中文姓名和隨機中文字符串2種昵稱模式;從英文昵稱中,可以提取出拼音和隨機英文字符串2種昵稱模式;對于混合字符昵稱,將其抽象化后得到的符號串作為其昵稱模式.具體針對不同類型的昵稱,本文采用這3種昵稱模式提取方法:
1) 中文昵稱.本文將中文昵稱分為傳統中文姓名和隨機中文字符串.①傳統中文姓名.使用結巴分詞工具(2)Jieba. https://github.com/fxsjy/jieba對中文昵稱進行分詞,然后在百家姓的基礎上進行一次過濾,再根據詞性分析以及字符串長度過濾,2次過濾后得到的所有中文昵稱的昵稱模式就是傳統中文姓名.②隨機中文字符串.使用正常的中文文章集作為語料庫訓練n-gram模型(3)Wikipedia contributors. N-gram. Wikipedia, The Free Encyclopedia. April 11, 2018. https://en.wikipedia.org/w/index.php?title=N-gram&oldid=835900923. Accessed June 29, 2018.如果一個字符串是中文常用語,將其輸入到訓練好的n-gram模型中,模型會輸出一個較高的概率值,表明模型認為該字符串出現在語料庫中的可能性較高;反之則是低概率值,表明該字符串出現在語料庫中的可能性低,即是隨機的中文字符串.為了確定模型閾值,本文從昵稱數據集中抽取少量已知是隨機中文字符串的昵稱(本文抽取了1 000個昵稱),將其輸入n-gram模型計算概率值,并根據這些隨機中文昵稱的概率值的分布來啟發式地設置了閾值.如果輸入字符串的概率值低于該閾值,則認為輸入昵稱為隨機中文字符串昵稱.
2) 英文昵稱.本文將英文昵稱分為拼音和隨機英文字符串2種模式.如同提取中文昵稱模式時所述的方法,本文分別使用對應的語料庫來訓練正常拼音或英文字符串的n-gram模型.根據隨機抽取的拼音昵稱或隨機英文字符串昵稱的概率值,啟發式地設置了閾值使得模型能檢測出拼音昵稱或隨機英文字符串昵稱.
3)混合字符.混合字符一般具有較為明顯的模式,比如中英混合、夾雜特殊符號(比如分號、@)等.本文采用了Thomas等人[18]所提出的方法,以將昵稱抽象化成統一類型的符號串.具體地,本文首先設計一類字符映射規則,將昵稱中不同類型的字符映射到不同的符號上.比如中文字符用C表示,大寫字母字符用U表示,小寫字母字符用L表示,數字字符用D表示,其余字符保留原始字符.在該映射規則下,“張三123”將被映射為“CCLLL”.映射后得到的符號串,就是昵稱的模式,即符號串“CCLLL”就是昵稱“張三123”的昵稱模式.
3.1.2 相似性特征
基于各賬號的注冊屬性,本文提取8個相似性特征來判斷2個賬號是否在某些角度表現出相似性:
1) IP前綴相同.如果2個賬號的24位IP前綴相同,則2個賬號具有該特征.
2) IP相同.如果2個賬號的IP地址完全相同,則2個賬號具有該特征.
3) 手機號碼前綴相同.如果2個賬號的手機號碼前綴相同,則2個賬號具有該特征.
4) WiFi MAC相同.如果2個賬號的WiFi MAC相同,則2個賬號具有該特征.
5) 設備ID相同.如果2個賬號的設備ID相同,則2個賬號具有該特征.
6) 客戶端版本號相同.如果2個賬號的微信客戶端版本號相同,則2個賬號具有該特征.
7) 設備操作系統類型相同.如果2個賬號的注冊設備系統類型相同,則2個賬號具有該特征.
8) 昵稱模式相同.若2個賬號具有相同的昵稱模式,如均為中文名字昵稱、拼音昵稱或兩者昵稱抽象模式之間的編輯距離與其長度平均值的比例小于一定閾值(基于本文對注冊賬號昵稱數據的統計分析,將該閾值設為0.3),則認為2個賬號具有該特征.
3.1.3 異常特征
本文提取的異常特征則包含9個部分:
1) 老舊客戶端版本號.本文根據當前已發布的最新微信版本,來確定老舊的或者罕見的微信客戶端版本號.若2個賬號客戶端均老舊,則認為它們具有該特征.
2) 老舊設備系統類型.本文根據各個手機操作系統的更新歷史,來確定老舊的或者罕見的設備系統類型.若2個賬號操作系統均老舊,則認為它們具有該特征.
3) 單屬性注冊數量.本文同樣通過統計分析數據來制定判斷單個相同屬性下注冊賬號數量是否超過閾值及是否可認定為異常.具體地,若同一個IP地址下注冊的賬號超過40個,或同一個WiFi MAC/設備ID下注冊的賬號超過25個,或同一個手機號前綴下超過30個,則認定這個IP地址、WiFi MAC、設備ID或者手機號前綴是異常的;若2個賬號均具有單屬性注冊數量異常,則認為它們存在對應特征.
4) 地理位置異常.若2個賬號手機號碼前綴相同,但IP不同,則本文認定它們為異常.若IP相同,但手機號碼前綴不同,則同樣認定2個賬號是異常的;若2個賬號均具有該異常屬性,則認為它們具有地理位置異常特征.
5) IP-WiFi多對多異常.倘若IP與WiFi存在多對多關系,即一個WiFi MAC對應多個IP.同時,被對應的IP也對應著多個WiFi MAC,則本文認為這樣的IP和WiFi MAC是異常的;若2個賬號均具有IP-WiFi多對多異常現象,則認為它們存在IP-WiFi多對多異常特征.
6) 時間分布異常.本文將一個IP段下的賬號注冊時間分布與正常賬號的注冊時間分布進行對比,如果KL距離大于設定閾值,那么認定該IP段是異常的.本文同樣基于數據分析的結果啟發式地調整該閾值,最終使用默認值1.0作為KL距離的閾值;若2個賬號均具有時間分布異常屬性,則認為它們存在時間分布異常特征.
7) 昵稱模式異常.若2個賬號的昵稱模式均為隨機中文字符串或者隨機英文字符串,則本文認為2個賬號在該特征上異常.
8) 注冊國家異常.若用戶填寫的注冊國家和其真實注冊的國家不一致,則該賬號在注冊國家上是異常的;若2個賬號均存在該現象,則認為它們存在注冊國家異常特征.
9) 注冊時間異常.如果2個賬號均在半夜進行注冊(本文使用的是在凌晨2:00—5:00),則本文認為該2個賬號存在注冊時間異常特征.
3.2 構圖聚類
本文提出了一種基于構圖聚類的惡意注冊賬號檢測方法.該方法基于各賬號注冊屬性及提取的相似性和異常特征,視各賬號為圖中頂點,計算節點間相似性并建立邊,從而構建一張賬號間的相似性圖.隨后,通過進行圖聚類和計算不同賬號的惡意分數,從而準確識別圖中的惡意賬號.
3.2.1 特征權重分配
考慮到不同的特征在決策賬號間相似性時作用可能存在不同,本文首先為每個特征賦予一定的初始權值,其由對數據中相似惡意賬號的統計分析結果來進行啟發式地確定.本文將特征的重要性分為4個等級,從低到高依次設為0.5,1.0,1.5,2.0.例如版本號相似、操作系統相似等惡意賬號間常見的特征,本文為它們配置最低初始權重.例如WiFi MAC相似、IP相似等包含地理位置等信息的特征,本文為它們配置最高初始權重.
在初始權重的基礎上,本文進一步通過多輪實驗迭代的方式進行權重調整,以期更好地表現出微信數據中惡意注冊賬號的特點.本文通過在3.1.2節和3.1.3節所述分析數據上的構圖聚類檢測結果,且在每輪迭代時只改變一個特征的權重等級,進而對比上一輪實驗和本次實驗結果的優劣,最終只記錄能提升性能的權重特征改變.如此對全部特征權重進行逐個調整,并最終形成如表3所示的特征權重表,以用于對測試數據的實際檢測中.
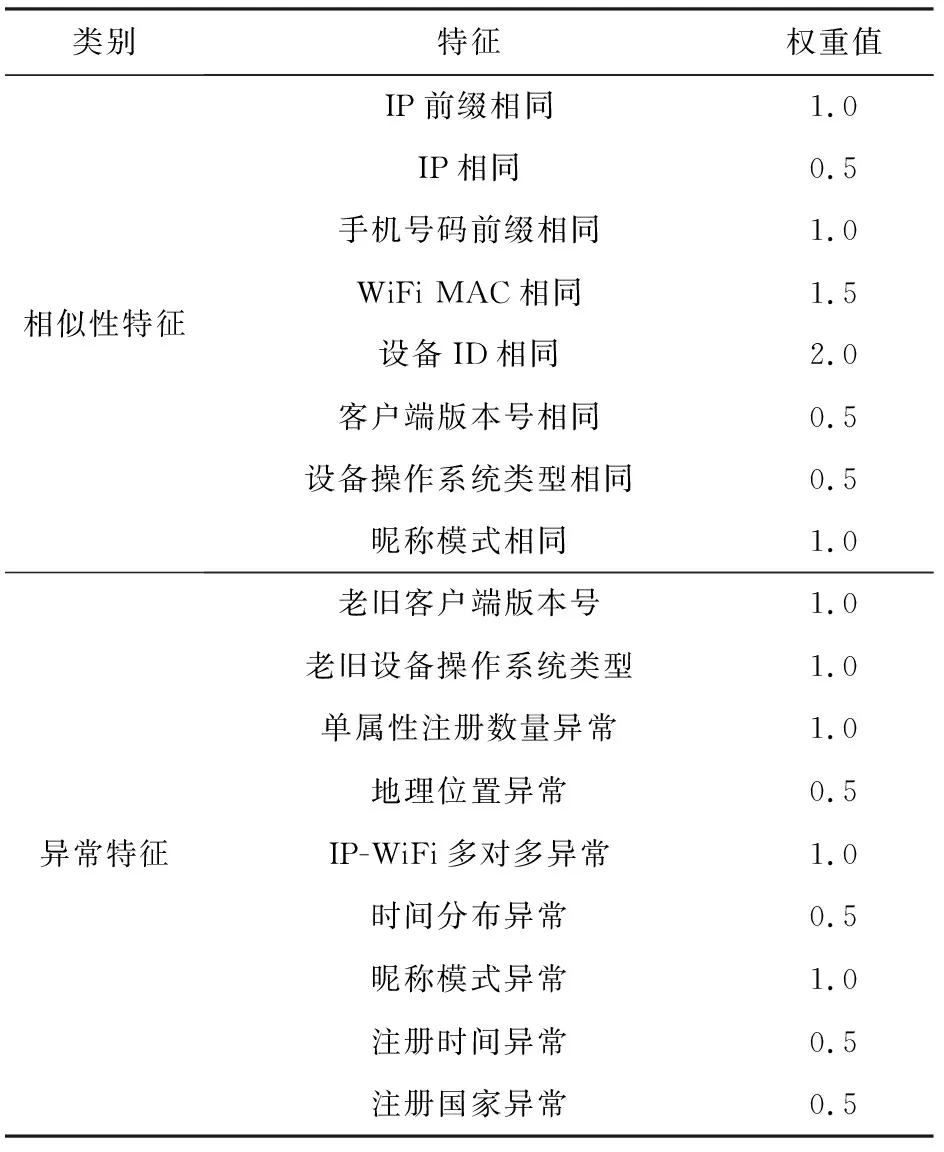
Table 3 Weights of Our Features
3.2.2 邊的權重計算與連通圖建立
基于3.1.2節、3.1.3節和3.2.1節所述的特征與特征權重,本文首先給出賬號間注冊相似性(Similarity)的定義:
定義1.賬號相似性Similarity.設C1與C2為全體賬號集合C中任意2個賬號,CF1與CF2分別為C1與C2對應的注冊屬性,Feat(x,y)為基于2個賬號各自注冊屬性進行3.1.2和3.1.3節所述賬號間特征提取函數,f則為3.2.1節所述特征權重向量,則C1與C2間的賬號相似性Similarity的計算方式為
Similarity(C1,C2)=f·Feat(CF1,CF2),
(1)
其中“·”為內積運算符.
基于賬號間注冊相似性的定義,本文進一步給出賬號相似連通圖的定義:
定義2.賬號相似連通圖G.設賬號相似連通圖G=(V,E),其中V為各注冊賬號所組成的頂點集合.對于?V1,V2∈V, 若Similarity(V1,V2)>Threshold, 則E中存在且唯一存在一條邊e=(V1,V2).另設權重W(e)=Similarity(V1,V2).
對于決定是否在2個頂點間建邊的相似度閾值Threshold,本文同樣通過實驗迭代的方式進行設置.本文最終所使用的相似度閾值為3.5.
3.2.3 連通圖聚類
基于批量注冊的惡意賬號具備較強相似性這一特性,本文通過采用圖聚類的方式從相似連通圖中挖掘出由相似頂點組成的簇.具體地,本文采用典型圖聚類方法:對建立好的賬號間相似關系圖(非連通無向圖)進行遍歷,獲取圖中所有連通分量.每個連通分量都是相似連通圖的一個極大連通子圖,從連通分量中的任一頂點出發,能且只能訪問到該連通分量中所有的頂點.將同一個連通分量內的所有注冊賬號歸為一個賬號簇,其中所有賬號間表現出較強的相似性.
然而,特定部分正常賬號可能與惡意賬號存在較為相似的屬性,進而被關聯至特定賬號簇中.故本文將對各賬號簇進行更細致的分析,從而準確地檢測出簇中的惡意賬號.
3.2.4 惡意分數計算
為了避免將特定正常賬號誤判為惡意賬號,本文基于連通分量中各頂點的邊權重來進行更細致的判斷.其依據是相較惡意注冊賬號本身,特定正常賬號與惡意賬號間存在邊(相似)的可能性更少,故它們的邊數與權重更少.據此,本文計算每個賬號的惡意分數Malicious Score來判斷.
定義3.賬號惡意分數Malicious Score.給定賬號連通圖G=(V,E), 對于?v∈V,設以其作為頂點的邊集合為Edge(v), 則定義v的Malicious Score的計算方式為
(2)
對于每個挖掘出的連通分量中的每個賬號頂點,本文計算其所連接邊權重和的tanh值,以表示該賬號的惡意分數.惡意分數越高,則代表該賬號與其他賬號的相似性越大,亦代表該賬號為惡意的可能性越大.計算出各賬號的惡意分數后即可通過閾值對比來最終判斷各賬號是否為惡意.該閾值采用了與特征權重相同的方式,在分析數據上進行配置和調整,并最終用于測試數據的檢測中,該閾值最終設為0.75.
4 性能評價
我們使用Scala編程語言實現了基于本文方法的原型系統,并基于Spark框架實現百萬級別注冊賬號的快速準確檢測能力.該系統已在微信應用平臺進行了部署和較長時期應用.
4.1 實驗數據集
本文實驗使用的數據為微信應用2017年10月某一周的用戶賬號注冊日志.數據總計有1 040萬條注冊記錄,其中惡意賬號數量為500萬.平均每一天約有150萬的注冊賬號,其中惡意賬號占比最高為50%左右.
1) 數據集劃分.一周的總數據集按天被分成7份.本文使用第1天的分析數據確定了表3所示的各特征權重、相似度閾值(值為3.5)和惡意分數閾值(值為0.75).這些權重和閾值是通過啟發式的方法,根據模型在分析數據上的實驗結果不斷地調整而確定的.測試時,分別取第1天、前3天、前5天、前7天的數據用于驗證和對比模型的檢測效果.
2) 數據集標簽.為了驗證模型的檢測效果,騰訊公司提供了數據集所有數據的標簽.標簽來源于其他根據注冊后用戶的行為來檢測的相關模型、其他用戶的舉報以及微信安全團隊的抽樣審計.
3) 實驗環境.本文系統構建于騰訊公司Spark計算平臺之上.Spark是業內常用的大規模數據計算引擎.在實驗中,本文系統共使用了30個Executor,每個Executor配置了16核CPU和10 GB內存.
4) 用戶隱私保護.本文工作是與微信安全團隊的合作項目,已簽署了微信的相關保密協議.實驗使用的數據源于用戶注冊賬號時收集的相關信息.所有收集的數據都已在微信的隱私保護協議中聲明,用戶在注冊賬號前必須閱讀且同意該協議才可以注冊賬號.在收集數據時,微信會對敏感數據先脫敏再收集.如用戶手機的號碼僅保留號碼前綴,對WiFi MAC和設備ID進行哈希計算等.
4.2 系統實現
在通過Spark平臺實現基于本文方法的原型系統時,考慮到日均150萬的新增注冊賬號數量,直接基于任意一對賬號的注冊屬性獲取二者之間的相似性與異常特征,進而計算二者相似度,最終構建賬號相似度連通圖這樣的實現方法計算開銷將是巨大而不可接受的.據此,本文采用了如下工程方式來有效加速賬號間相似度計算,從而使本文原型系統能滿足微信應用日均百萬級的新注冊賬號檢測需求:
在讀入當日新賬號的每個注冊屬性時,就對所有賬號按相同的單個屬性值進行劃分,即在各注冊屬性上將全體賬號劃分為多個集合,每個集合包含一定數量的賬號.由于本文設計的相似性和異常特征均提取自含有相同屬性值的賬號對,故只需對各集合內部的賬號對進行特征提取與相似度計算,進而遍歷當前注冊屬性的所有集合及其他所有注冊屬性的賬號劃分集合,即可完成所有可能存在相似性的賬號對的計算,而無需窮舉全體賬號內的任意賬號對.
此外,該實現方法的本質是基于相同注冊屬性先選出在特定特征的部分賬號對(可能存在邊),忽略其余明確不存在特定特征的賬號對(肯定不存在邊),進而再基于挑選出的賬號對進行相似度計算(確定是否建邊).據此,此種方法下賬號連通圖中的邊與原始方法下連通圖中的邊將不會存在差異,對連通分量的挖掘與惡意賬號檢測結果同樣不會受到任何影響.
4.3 準確率和召回率
若對惡意賬號的檢測結果中存在較多的誤報,則容易造成大量正常用戶被誤封,將嚴重影響微信應用的用戶體驗和正常運行.據此,為確保檢測出惡意賬號的準確性,本文選擇了較高的相似度閾值,以在可接受的召回率前提下使檢測結果盡可能準確.如圖4所示,本文方法檢測結果的準確率為96%左右,召回率為50%~60%,隨著數據量從百萬級增長到千萬級,本文的算法仍然保持相對穩定的性能.圖5則展示了各測試數據集下,本文方法的日平均檢測結果,每天平均可準確檢測出40萬至50萬的惡意注冊賬號.

Fig.4 Precision and recall of our method on the dataset collected in Oct. 2017圖4 基于2017年10月數據集的準確率和召回率
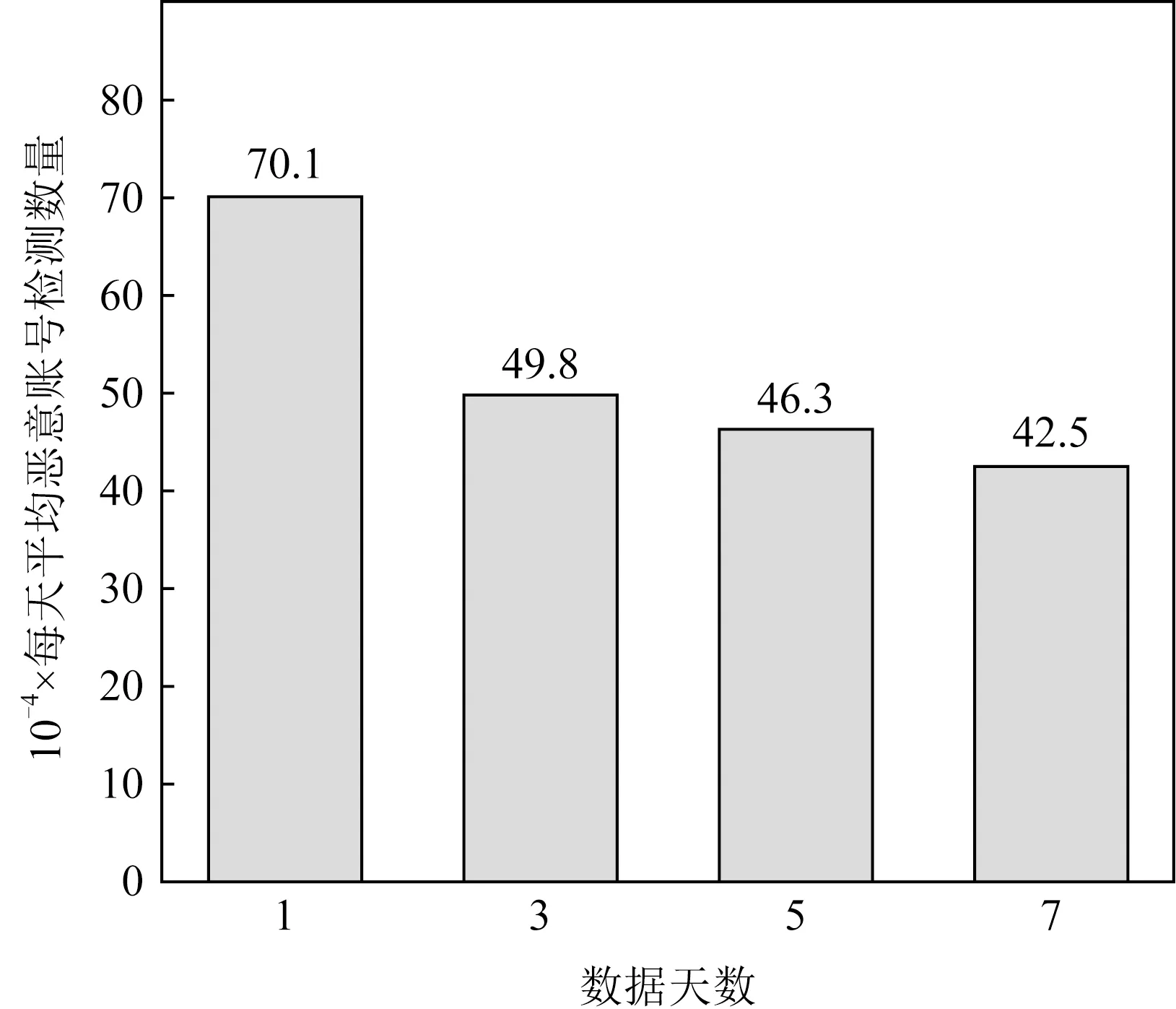
Fig.5 Average number of detected sybils per day圖5 每天平均的惡意賬號檢測數量
4.4 時效性
為了驗證模型是否能在一段時間之后的數據集上仍保持較好的效果,本文又獲取了微信應用2017年11月某一周連續5天的用戶賬號注冊日志.數據總計有690萬條注冊記錄,其中惡意賬號數量為294萬.使用與4.2節中同樣的參數和閾值,模型對每天注冊賬號檢測的準確率和召回率如圖6所示.對比4.3節的模型檢測結果,可以看到在新數據集上模型有92%左右的準確率和70%左右的召回率,依然保持著穩定的檢測效果.由此可見,本文方法及選定閾值并不局限于特定時期的數據,具有良好的時效性.

Fig.6 Precision and recall of our method on the dataset collected in Nov. 2017圖6 基于2017年11月數據集的準確率和召回率
4.5 特征重要性
根據第2節的注冊數據分析結果,在直觀上我們可以提出更加樸素的檢測方法:即僅基于IP地址或手機號等注冊屬性來進行檢測,而不再需要3.1節所設計的相似性特征和異常特征.為了驗證本文設計的相似性特征和異常特征的重要性,本文進行了一個對比實驗.以本文提出的微信惡意賬號檢測模型為基準線,分別與僅用IP地址、僅用手機號前綴和僅用設備ID三種不同檢測模型進行對比.本文僅選用IP地址、手機號和設備ID這3個屬性的原因是它們對惡意和正常賬號的區分度遠優于其他屬性(如昵稱等).以僅用IP地址的檢測模型為例,根據分析數據中同一惡意IP地址下注冊的賬號數與同一正常IP地址下注冊的賬號數,選擇一個合適的閾值(本文使用了500),如果測試數據中一個IP地址下注冊的賬號數超過該閾值,則此IP地址下的所有賬號都是惡意賬號,反之此IP地址下的所有賬號都是正常賬號.在僅用手機號前綴的檢測模型中,本文使用的閾值是9;在僅用設備ID的檢測模型中,本文使用的閾值是2.這些閾值是根據各模型的檢測結果啟發地調整得到的,使得各模型能夠取得最優的檢測結果.需要注意的是,因為是僅用單個屬性來檢測,所以閾值與3.1.3節單屬性注冊異常中的閾值不一樣.對比實驗的結果如圖7所示.
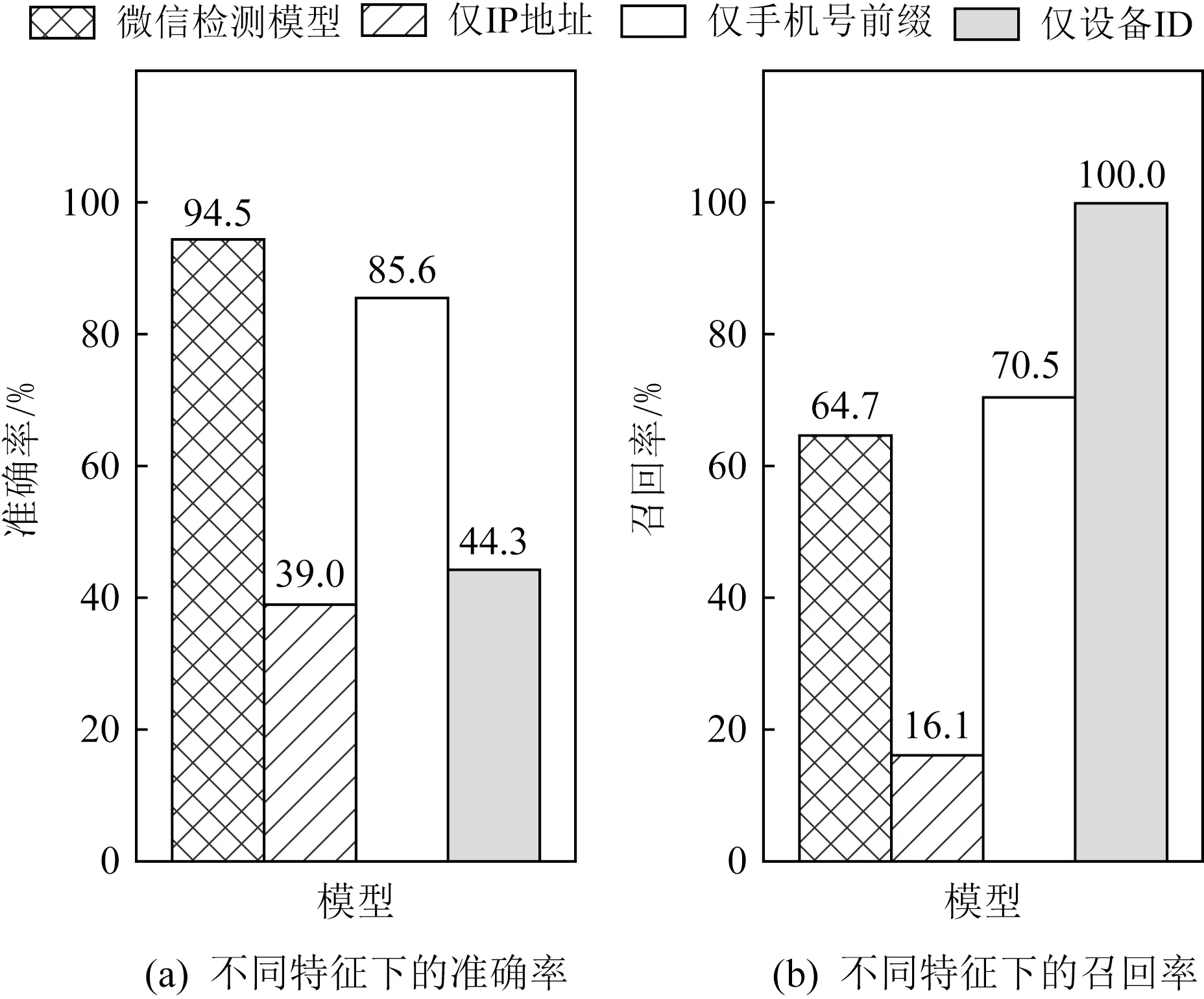
Fig.7 Precision and recall of our method under different feature sets圖7 不同特征下的準確率與召回率實驗結果
從圖7中可以看到,相比于本文提出的微信惡意賬號檢測模型,僅用單個屬性的樸素模型在準確率上有明顯的差距.這就意味著,在實際使用場景中,這些模型會造成大量用戶的賬號被誤封,極大影響用戶體驗.這個對比實驗表明,本文提取的相似性或異常特征是重要的,可以保證模型對惡意賬號覆蓋率和提高檢測結果的準確率.
4.6 可拓展性
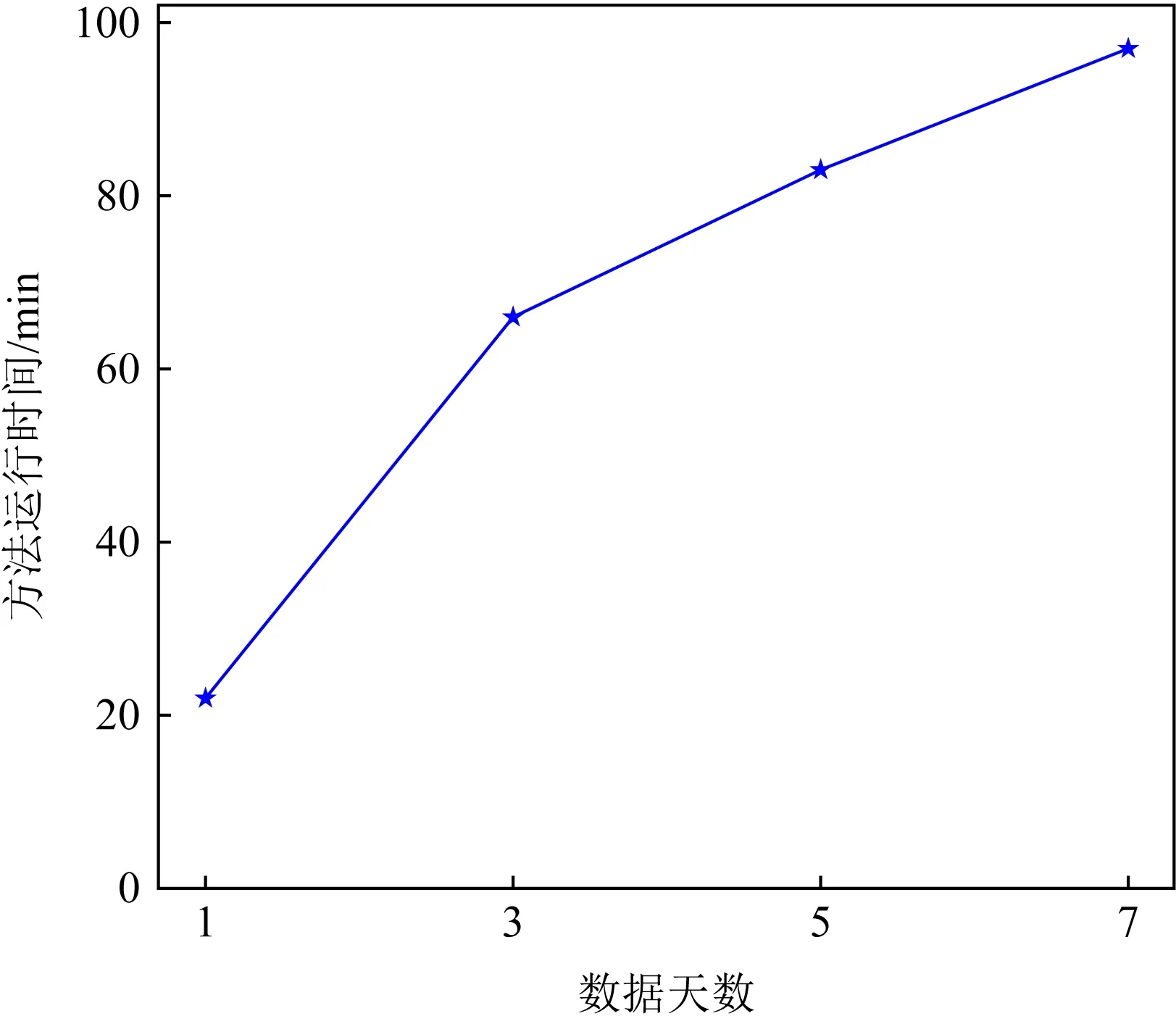
Fig.8 Running time of our method on different test data圖8 不同測試數據下方法的運行時間
基于實際場景測試,本文所實現原型系統檢測百萬級別的數據需耗時約20 min,檢測千萬級別的數據則需耗時約100 min,具體如圖8所示.可以看出,本文所實現原型系統對于千萬級的數據仍然有較快的檢測速度,并且檢測結果的準確率穩定在96%左右.由此可見,本文方法及原型系統可拓展性良好.
4.7 系統部署
本文提出的無監督惡意注冊檢測模型及原型系統已被微信安全團隊部署,用于對惡意注冊賬號的日常檢測.具體地,檢測模型會于每天24時,基于賬號注冊日志對當天的所有注冊賬號進行線下檢測.由于模型存在著少量的誤報進而導致誤封號,而這些被誤封號的用戶可以通過微信內置的解封申訴渠道進行解封.由此產生的誤封記錄將被維護人員分析,用于進一步地提升模型的檢測效果.據近期統計,本文系統每日依然可檢測出40萬左右的惡意賬號,根據用戶的申訴反饋和維護人員的抽樣分析,檢測準確率在90%~95%.需要注意的是,微信公司每日新增注冊用戶數量在百萬級,故無法知悉其中全部惡意賬號數目并計算本文系統實際部署階段的漏報率或召回率.
異常檢測系統在實際部署中同樣需要考慮先進攻擊者進行針對性逃避的可能.對于目前比較先進的黑產攻擊者,他們的主要表現是注冊成功后各類攻擊行為更加復雜隱蔽.而本文方法瞄準的是其注冊階段,即在其發動攻擊之前進行有效防范.本文方法所使用的注冊屬性在新用戶注冊賬號時必須提交,且會由于自動注冊工具的使用而表現出聚集性.典型的黑產攻擊者均無法回避這2個特性.因此,本文方法能有效防范真實網絡中大部分典型的黑產攻擊者威脅.
5 總 結
本文首先系統介紹并分析了現有社交網絡惡意賬號檢測方法的原理及優缺點.隨后,通過全面地對社交網絡賬號的注冊屬性進行統計分析,對比正常和惡意賬號在不同注冊屬性上的分布差異,本文設計了相似性特征和異常特征用于比較不同注冊賬號間的相似性,進而構建賬號相似連通圖,并通過連通圖算法挖掘并檢測惡意注冊賬號.本文方法具備不依賴帶標簽訓練集、檢測性能好且穩定、處理速度快等優點,并已在微信運營平臺得到了實際部署和長期應用,有力打擊了在線社交網絡黑產鏈,保障廣大用戶安全使用微信應用.
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國信息化周報(2016年47期)2017-03-25 17:33:41
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
中國信息化周報(2015年27期)2015-08-12 22:09:31
中國信息化周報(2015年28期)2015-08-06 22:08:50
中國信息化周報(2015年13期)2015-06-01 21:47:12
