基于數據挖掘的實踐及應用
2021-10-30 02:35:52雷湘琦
科學與生活 2021年19期
關鍵詞:數據挖掘
雷湘琦
摘要:過去數十年中,數據挖掘得到廣泛的應用,作用的領域包括人工智能、統計學、數據庫等等。于當下的學生來說,數據挖掘是一門經久不衰的學科,而對于從事數據挖掘的工作者來說,更是深刻地體會到了數據挖掘強有力的發展前景。對數據挖掘這個領域應用最多的就是算法,掌握算法的意義就抓住了數據挖掘的核心。如今,雖然數據挖掘技術的應用相當廣泛,但是就算法而言其本質并未發生改變。現今運用的都是一些比較經典的算法,如傳統的決策樹算法等,同時這些算法也是學習數據挖掘算法的根基。文中主要列舉相關算法并應用相應的實例加以佐證,指出其中的不足和需要改進的地方。
關鍵詞:數據挖掘;決策樹;鳶尾花數據
引言
決策樹(Decision Tree)是在已知各種情況發生概率的基礎上,通過構成決策樹來求取凈現值的期望值大于等于零的概率,評價項目風險,判斷其可行性的決策分析方法,是直觀運用概率分析的一種圖解法。由于這種決策分支畫成圖形很像一棵樹的枝干,故稱決策樹。決策樹模式呈樹形結構,其中每個內部節點表示一個屬性上的測試,每個分支代表一個測試輸出,每個葉節點代表一個類別。學習時利用訓練數據,根據損失函數最小化的原則建立決策樹模型;預測時,對新的數據,利用決策樹模型進行分類。在機器學習中,決策樹是一個預測模型,它代表的是對象屬性與對象值之間的一種映射關系決策樹是一種基本的分類與回歸方法,本文應用的是用于分類的決策樹。
1 基本原理
決策樹學習通常包括三個步驟:特征選擇,決策樹的生成和決策樹的剪枝。
1.1 特征選擇
特征選擇在于選取對訓練數據具有分類能力的特征,這樣可以提高決策樹學習的效率。通常特征選擇的準則是信息增益(或信息增益比、基尼指數等),每次計算每個特征的信息增益,并比較它們的大小,選擇信息增益最大(信息增益比最大、基尼指數最小)的特征。
下面重點介紹一下本文特征選擇的準則:信息增益。首先定義信息論中廣泛使用的一個度量標準——熵(Entropy),它是表示隨機變量不確定性的度量。熵越大,隨機變量的不確定性就越大。而信息增益(Informational Entropy)表示得知某一特征后使得信息的不確定性減少的程度。簡單的說,一個屬性的信息增益就是由于使用這個屬性分割樣例而導致的期望熵降低。信息增益、信息增益比和基尼指數的具體定義如下:信息增益:特征A對訓練數據集D的信息增益,定義為集合D的經驗熵與特征A給定條件下D的經驗條件熵之差,即信息增益比:特征A對訓練數據集D的信息增益比定義為其信息增益與訓練數據集D關于特征A的值的熵之比,即其中n是特征A取值的個數。
1.2 決策樹的生成
? 從根結點開始,對結點計算所有可能的特征的信息增益,選擇信息增益最大的特征作為結點的特征,由該特征的不同取值建立子結點,再對子結點遞歸地調用以上方法,構建決策樹;直到所有特征的信息增均很小或沒有特征可以選擇為止,最后得到一個決策樹。決策樹需要有停止條件來終止其生長的過程。一般來說最低的條件是:當該節點下面的所有記錄都屬于同一類,或者當所有的記錄屬性都具有相同的值時。這兩種條件是停止決策樹的必要條件,也是最低的條件。在實際運用中一般希望決策樹提前停止生長,限定葉節點包含的最低數據量,以防止由于過度生長造成的過擬合問題。
1.3 決策樹的剪枝
? 決策樹生成算法遞歸地產生決策樹,直到不能繼續下去為止。這樣產生的樹往往對訓練數據的分類很準確,但對未知的測試數據的分類卻沒有那么準確,即出現過擬合現象。解決這個問題的辦法是考慮決策樹的復雜度,對已生成的決策樹進行簡化,這個過程稱為剪枝。
本文將應用鳶尾花數據進行決策樹分析。
2 決策樹的剪枝
Iris 鳶尾花數據集是一個經典數據集。數據集內包含 3 類共 150 條記錄,每類各 50 個數據,每條記錄都有 4 項特征:花萼長度、花萼寬度、花瓣長度、花瓣寬度,可以通過這4個特征預測鳶尾花卉屬于(Iris-setosa,Iris-versicolour,Iris-virginica)中的哪一品種。
2.1 利用Decision Tree分類器對Iris data進行分類
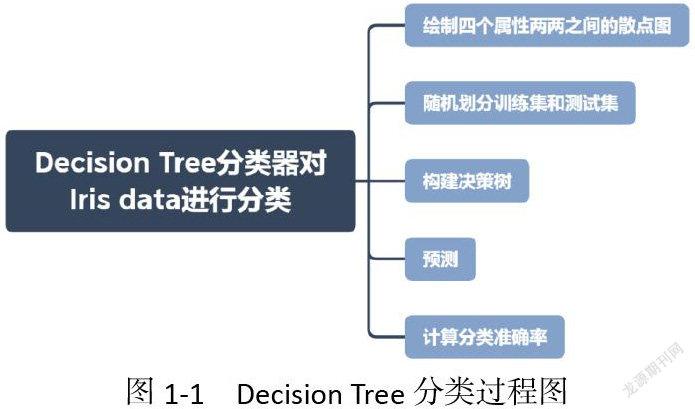
2.1.1 Decision Tree分類過程
如圖1-1。
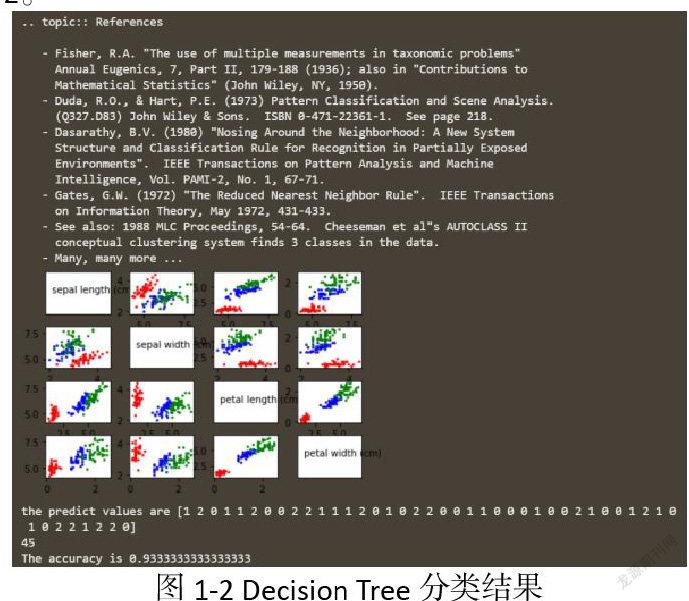
2.1.2 Decision Tree分類結果
如圖1-2。
3 結束語
經上述分析,決策樹分類算法與統計方法和神經網絡分類算法相比較具備以下優點:首先,通過決策樹分類算法進行分類,出現的分類規則相對較容易理解,并且在決策樹中由于每一個分支都對應不同的分類規則,所以在最終進行分類的過程中,能夠說出一個更加便于了解的規則集。其次,在使用決策樹分類算法對數據挖掘中的數據進行相應的分類過程中,與其他分類方法相比,速率更快,效率更高。最后,決策樹分類算法還具有較高的準確度,從而確保在分類的過程中能夠提高工作效率和工作質量。決策樹分類算法與其他分類算法相比,雖然具備很多優點,但是也存在一定的缺點,其缺點主要體現在以下幾個方面:首先,在進行決策樹的構造過程中,由于需要對數據集進行多次的排序和掃描,因此導致在實際工作過程中工作量相對較大,從而可能會使分類算法出現較低能效的問題。
參考文獻:
[1]程一芳.數據挖掘中的數據分類算法綜述[J].數字通信世界,2021(02):136-137+140.
[2]韓成成,增思濤,林強,曹永春,滿正行.基于決策樹的流數據分類算法綜述[J].西北民族大學學報(自然科學版),2020,41(02):20-30.
[3]姚奇峰,楊連賀.數據挖掘經典分類聚類算法的研究綜述[J].現代信息科技,2019,3(24):86-88.
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
西安工程大學學報(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
電子設計工程(2014年18期)2014-02-27 12:00:12
