基于Petri網的并發事件流程模型修復分析 *
2021-10-26 01:17:24楊慧慧方賢文邵叱風
計算機工程與科學 2021年10期
楊慧慧,方賢文,邵叱風
(安徽理工大學數學與大數據學院,安徽 淮南 232001)
1 引言
流程挖掘是工作流建模中最有用的工具,它可以從事件日志中獲取客觀的、有價值的信息,建立流程模型[1]。流程挖掘主要包括3種類型:流程發現、一致性檢查和流程增強。但是,通過流程發現得到的模型有時會出現與原始模型沒有任何相似之處的情況,這樣會丟失原始模型的使用價值,因此為了避免這種損失,許多學者對模型修復的研究越來越關注。
模型修復與流程挖掘的3大類型是不同的。流程發現主要是從工作流日志中發現并提取流程模型,允許用戶構建表示記錄在日志中的流程行為的流程模型[2]。例如,文獻[3]探討了一類基于業務流程執行事件的在線流的流程發現。還有一些研究側重于評估所發現的流程模型,文獻[4]提出了一種新的方法來評估人為產生的負面事件的流程模型,這種方法允許為發現的流程模型定義行為度量。對于一致性檢查,其目的是評估記錄在事件日志中的流程模型和事件數據是否一致[5]。文獻[6]利用用于交互式流程發現的底層技術提出了一個框架(及其應用)來快速計算一致性,以便增量地更新一致性結果。對于流程增強,文獻[7]提供了流程增強的概述,描述了流程增強在各種工業中的應用以及在選擇增強方法時考慮增強流程的目標和約束的重要性,相關的增強方法有分解模型修復[8]、使用角色信息來增強業務流程模型[9]等。而模型修復主要針對事件日志與原始模型不符合的部分進行修復,最大程度地與原始模型保持相似。文獻[10,11]均研究了修復流程模型的問題,后者提出通過事件日志的觸發序列,可以從刪除行為、添加行為和更改行為3個方面對流程模型進行修復,修復后的流程模型均可以重放日志,并且與原始模型盡可能相似。因此,模型修復的方法既保留了原始模型的價值,又順應了現實的流程執行,具有一定的研究價值。
本文余下部分的結構為:第2節介紹與本文相關的基本概念;第3節提出新的修復方法來解決本文所針對的問題;第4節用實例分析本文所提方法的可行性;第5節總結全文并對未來工作做出展望。
2 基本概念
定義1(Petri網)[12]滿足下列條件的三元組N=(P,T,F)稱作一個Petri網:
(1)P∪T≠?;
(2)P∩T=?;
(3)F?(P×T)∪(T×P);
(4)dom(F)∪cod(F)=P∪T。
其中,P和T是2個不相交的集合,它們是Petri網N的基本元素集,P中的元素稱為P-元或庫所,也稱為位置,T中的元素稱為T-元或變遷,F是Petri網N的流關系。dom(F)={x∈P∪T|?y∈P∪T:(x,y)∈F},cod(F)={x∈P∪T|?y∈P∪T:(y,x)∈F}。dom(F)表示F的定義域,Petri網N的流關系中2個相鄰節點x與y之間為因果關系,dom(F)為所有滿足條件的x的集合;而cod(F)表示F的值域,是2個相鄰節點x與y之間滿足cod(F)的條件的所有x的集合。
定義2(跡,事件日志)[13]設Φ是一組活動名稱的集合,Φ*是活動發生序列的一個集合,若α∈Φ*是一個活動序列,則稱α是一條跡。若L∈B(Φ*)是跡的有限非空的多重集,則稱L是一個事件日志。
定義3(對齊)[13]設N=(P,T,F,α,m0,mf)是一個Petri網,其m0為初始標識,mf為終止標識。設α=a1a2…aθ是一條跡,其中θ表示活動序列中觸發的活動事件的個數,α到Petri網流程模型N之間的對齊γ=(a1,t1)(a2,t2)…(az,tz)(其中(az,tz)表示對齊中第z組移動對)是滿足下列條件的移動序列:
(1)對齊γ的第1行(a1,a2,…,az)是事件日志中的一條跡;
(2)對齊γ的第2行(t1,t2,…,tz)是Petri網流程模型N中的一組變遷發生序列;
(3)對于所有的i=1,2,…,z,如果ti≠?,α(ti)≠τ,且ai≠?,那么α(ti)=ai。
這里的移動對滿足以下條件:
(1)如果ai=?∧ti≠?,則稱為模型移動;
(2)如果ai≠?∧ti=?,則稱為日志移動;
(3)如果ai≠?∧ti≠?,則稱為同步移動。
定義4(狀態集)[14]設Ns=(S,SI,SF,Φ,T)是一個Petri網流程模型N的一個狀態集,其中:
(1)S是模型中的狀態,SI?S是初始狀態,SF?S是終止狀態;
(2)Φ是一組活動集;
(3)T?S×Φ×S。
例如,若(s1,act,s2)∈T,則說明狀態s1通過變遷act可以轉變為狀態s2。
3 基于并發事件的模型修復
3.1 最優對齊以及問題的提出
對于給定的跡和Petri網流程模型N,可能會存在多個不同的對齊,為了方便比較不同對齊與流程模型之間偏差的大小,本文分別賦予同步移動、日志移動和模型移動的成本函數值為0,1,1,特別地,(?,τ)的成本函數值為0。因此,一個跡對齊γ的成本c(γ)為γ中所有移動的成本函數值的和。c(γ)越小則偏差越小,因此本文將考慮最優對齊。
定義5(最優對齊)[15]給定一條跡α和Petri網流程模型N,對于α和N之間所有的對齊χ,?γ∈χ,對?γ′∈χ,都有c(γ)≤c(γ′),則稱γ是α和N之間的最優對齊。
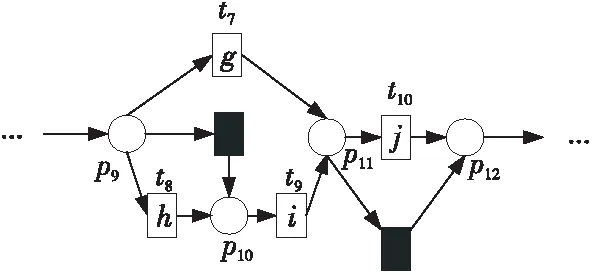
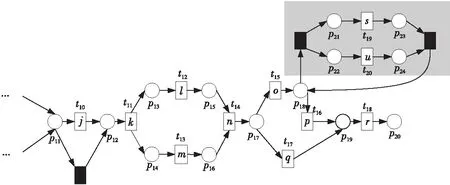
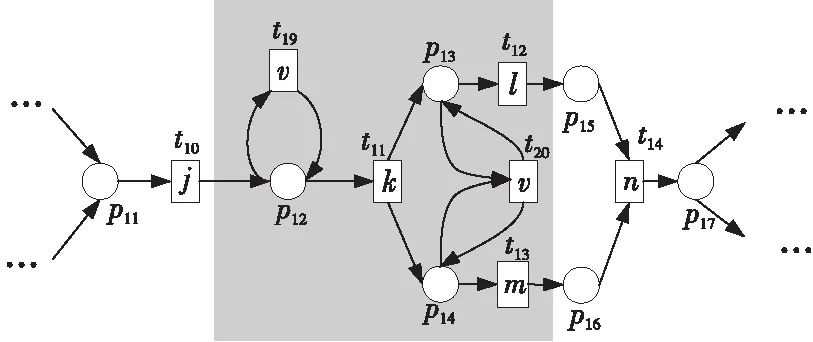
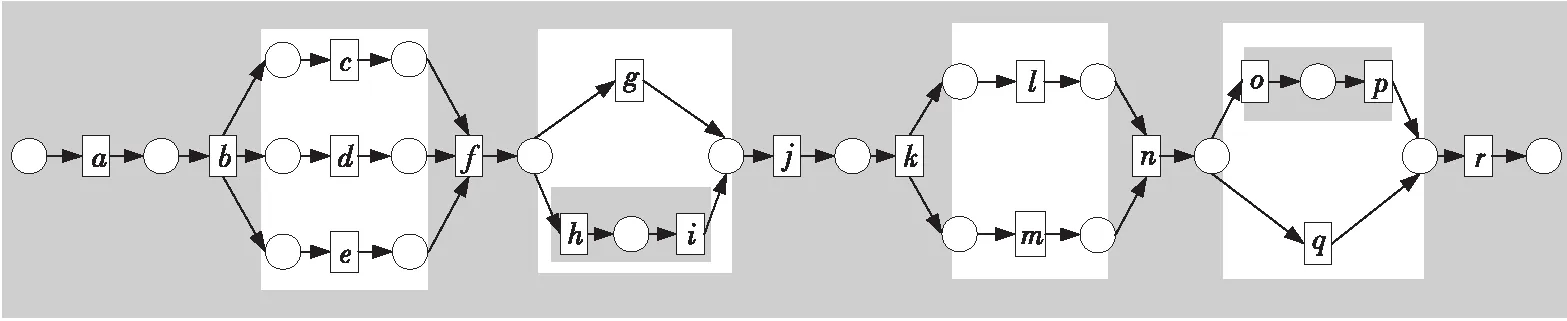
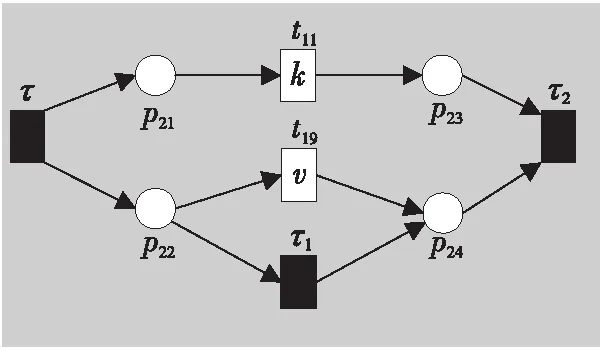
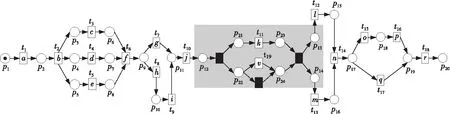
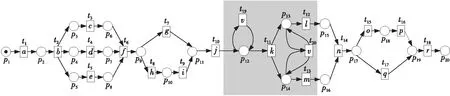
例如,考慮本文第4節給出的跡α1,可以看出α1與事故保險理賠流程模型N之間存在3種不同的對齊,即γ(α 1)、γ′(α 1)和γ″(α 1),如式(1)所示,由于2=c(γ(α 1)) 本文第4節給出了3個事件日志,共有12條跡,其中α1,α6,α7,α11,α12這5條跡與事故保險理賠流程模型存在偏差,但是觀察發現這5條跡在現實生活中皆是合理的。交通事故涉及到的糾紛比較復雜,若當事人直接選擇走司法程序則會出現α1的情形,由司法程序進行裁決,并對相關損失作出估價;通常需要走司法程序的時候都會開具相關證明,在辦理理賠手續的過程需要用到這些證明,即α6和α7;當事故較小時也可以不進行現場勘查,若在允許理賠情況下,當事人對理賠金額存在異議,則保險公司便不執行匯款,等待異議解除后確定了最終金額再進行匯款,即α11和α12。然而這幾條合理有效的跡并不能完全在流程模型N中重放,說明理賠系統目前不夠完善,應該進一步修復模型,使得模型能更好地反映出各個事件日志。 目前,已有的經典修復方法允許簡單的插入和跳過活動,在γ(α1)中有2個模型移動,即(?,h),(?,j)。活動事件h和j不能在跡中觀察到但在模型中卻存在,這種情況下允許插入隱變遷跳過相應行為活動來進行模型修復,如圖1所示。 Figure 1 Model repair diagram of the insertion of implicit transitions圖1 插入隱變遷的模型修復圖 圖1中變量與本文第4節一致,其中p9~p12表示庫所的序號,t7~t10表示變遷的序號,g表示輕微事故,損失較小,h表示重大事故,損失較大,i表示進入司法程序,j表示事故現場勘查檢驗。對于跡α11和α12與流程模型N之間的最優對齊γ(α11)和γ(α12)如式(2)所示,都包含了2個連續的日志移動(s,?)和(u,?),只是順序不同,對于這種情況,可以根據文獻[13]中基于子流程的修復算法進行模型修復,如圖2所示。 γ(α1):=abedcf?i?kmlnqrabedcfhijkmlnqrt1t2t5t4t3t6t8t9t10t11t13t12t14t17t18, γ'(α1):=abedcfi??kmlnqrabedcf?gjkmlnqrt1t2t5t4t3t6t7t10t11t13t12t14t17t18, γ″(α1):=abedcfi???kmlnqrabedcf?hijkmlnqrt1t2t5t4t3t6t8t9t10t11t13t12t14t17t18 (1) γ(α12):=abdcefhijkmlnousprabdcefhijkmlno??prt1t2t4t3t5t6t8t9t10t11t13t12t14t15t16t18, (2) Figure 2 Model repair partial display diagram based on subprocess圖2 基于子流程的模型修復部分顯示圖 圖2中變量與本文第4節一致,其中p11~p24表示庫所的序號,t10~t20表示變遷的序號。根據上述模型修復方法,修復日志移動需要插入相應的活動,那么就有可能發生具有相同行為的同一個活動在模型中不同位置重復出現,分別多次構成自循環的情況,增加了很多不必要的循環行為。例如,式(3)所示的最優對齊γ(α6)和γ(α7)中都含有日志移動(v,?),顯然,若在模型中插入2次相同的活動v會構成兩個自循環結構,如圖3所示,模型允許出現活動v多次循環的行為:(…,j,v,v,k,l,m,n,…),(…,j,v,v,v,k,l,m,n,…),(…,j,v,k,v,v,l,m,n,…),(…,j,k,v,v,v,l,m,n,…),…,而日志中并未出現任何循環行為。 Figure 3 Schematic diagram of unnecessary cyclic behavior圖3 不必要的循環行為示意圖 因此,本文針對類似于γ(α6)和γ(α7)包含的這類對齊提出一種新的修復方法,即先將相關活動的所有流關系斷開,然后重新構造一個并發結構的子流程,最后將重構的子流程連接到流程模型中以達到修復效果。 這種修復方法適合修復并發事件,因此本文研究的并發事件符合下列2個條件: (1)w(w≥2)個對齊中皆含有相同活動事件的日志移動,且原流程模型中不包含此活動事件。 (2)若將此日志移動的活動事件與相鄰同步移動的活動事件視為一組并發事件ξ2,且ξ2↑∈βi-1,ξ2∈βi,ξ2↓∈βi+1,其中βi-1,βi,βi+1分別屬于塊結構工作流網[16]中的一個結構,則有βi-1,βi,βi+1為順序關系,且在w(w≥2)個對齊中均成立。其中,ξ2↑和ξ2↓分別表示對應跡中ξ2的前一個活動事件和后一個活動事件。 為了篩選符合條件的并發事件,需要考慮流程模型的順序結構,因此用塊結構工作流網[16]來展示更為直觀,如圖5所示。下面將給出詳細的篩選算法。 算法1篩選符合條件的并發事件 輸入:所有最優對齊γ,流程模型N。 輸出:所有符合條件的并發事件ξ。 步驟2將η1中的對齊進行分組,包含相同日志移動的對齊分為一組,然后將單獨成組的對齊刪除,設分組完成后形成λ組,即G1,G2,…,Gλ(λ≥1)。 γ(α6):=abdcefhijkvlmnoprabdcefhijk?lmnoprt1t2t4t3t5t6t8t9t10t11t12t13t14t15t16t18, γ(α7):=abdecfhijvklmnoprabdecfhij?klmnoprt1t2t4t5t3t6t8t9t10t11t12t13t14t15t16t18 (3) 步驟3采用流程樹語言對流程模型進行描述,列出構成順序結構的各個分支β1,…,βk*,然后執行步驟4對G1,G2,…,Gλ(λ≥1)分別進行組內篩選。 步驟4觀察組內各個對齊,保留日志移動(包含連續日志移動)前后均為同步移動的對齊,其余情況的對齊刪除。若|Gi|<2,則刪除第i組,否則執行步驟5。 步驟5在Gi中的各個對齊內,設日志移動的活動事件為α,若均滿足α↑∈βi,α↓∈βi+1,1≤i≤k-1,則刪除Gi,然后對剩余各組執行步驟6。 步驟6在各組中分別對目標日志移動中的活動事件δ進行分析,若將δ與相鄰活動事件a視為一組并發事件ξj=[δ,a],a∈βi并且在組內各個對齊中均滿足ξj↑∈βi-1,ξj∈βi,ξj↓∈βi+1,2≤i≤k-1,則保留符合條件的并發事件ξj,否則刪除此組對齊。 步驟7得到各組中保留的符合條件的并發事件ξ1,ξ2,…,輸出所有符合條件的并發事件ξ={ξ1,ξ2,…},算法結束。 找到符合條件的并發事件后,便可以對模型進行修復,重構一個并發結構的子流程,然后將其連接到模型中,使得事件日志與流程模型偏差為零,保證了流程模型能夠更好地反映出實際事件日志的情況。具體步驟如算法2所示。 算法2重構子流程模型修復 輸入:一組并發事件ξj=〈a1,a2,…,a*〉,流程模型N,含有ξj的一組對齊γ(α)。 輸出:含有重構子流程的修復模型N′。 步驟4添加一個隱變遷τ,使得τ∈·s′,其中s′={s′i*∈·ti*|i*=1,2,…,n*}; 步驟6將U連接到模型中,滿足p′∈·U,pn∈U·,即p′為τ的輸入庫所,p″為τ′的輸出庫所; 步驟7得到一個含有重構子流程的修復模型N′,算法結束。 本節以事故保險理賠流程模型為例,使用本文提出的新方法對原始模型進行修復,使得修復后的模型能夠完全重放事件日志,并且盡可能減少不必要的行為發生。最后與目前經典的插入與跳過活動的修復方法進行對比,以驗證本文所提方法的可行性。 近年來,隨著人們生活水平顯著提高,交通事故的保險理賠也越來越受到重視。正常情況下,事故發生之后,第一時間先報案,然后打電話通知保險公司,繼而保險公司會進行以下正常的理賠程序:a報案受理;b查詢保單信息;c填寫出險報案表;d報案登記;e人員調度;f理賠初審;g輕微事故;損失較小;h重大事故;損失較大;i進入司法程序;j事故現場勘查檢驗;k定損估價;v開具證明;l填寫索賠相關材料;m提交相關證明,n理賠復核;o理賠;s暫時不支付;u等待最終確認金額;p匯款;q拒賠;r結案歸檔。由于事故發生類型錯綜復雜,事故保險理賠系統難免會出現不符合現實案例的情況,因此進一步完善保險理賠系統是有必要的。本文從保險公司理賠系統中隨機調取了部分事件日志,經刪除噪聲處理后得到如式(3)所示的事件日志: L1={α1=〈a,b,e,d,c,f,i,k,m,l,n,q,r〉23,α2=〈a,b,d,e,c,f,h,i,j,k,l,m,n,q,r〉316,α3=〈a,b,d,c,e,f,g,j,k,l,m,n,o,p,r〉2952,α4=〈a,b,e,c,d,f,g,j,k,m,l,n,o,p,r〉2710}, L2={α5=〈a,b,c,d,e,f,h,i,j,k,l,m,n,o,p,r〉2108,α6=〈a,b,c,e,d,f,h,i,j,k,v,l,m,n,o,p,r〉18,α7=〈a,b,d,e,c,f,h,i,j,v,k,m,l,n,o,p,r〉31}, L3={α8=〈a,b,e,d,c,f,g,j,k,l,m,n,q,r〉1791,α9=〈a,b,e,d,c,f,h,i,j,k,m,l,n,q,r〉536,α10=〈a,b,c,e,d,f,h,i,j,k,m,l,n,q,r〉824,α11=〈a,b,c,d,e,f,g,k,l,m,n,o,s,u,p,r〉29,α12=〈a,b,d,c,e,f,h,i,j,k,m,l,n,o,u,s,p,r〉16} (4) 其中,L1,L2,L3表示3個不同的事件日志,αφ(φ=1,2,…,12)表示12條不同的跡,每條跡中后面的數字上標表示這條跡在事件日志中出現的次數。根據這些事件日志,本文構建了基于Petri網的事故保險理賠流程模型N,如圖4所示,該流程模型符合一般的理賠程序。根據Petri網定義可知,圖4顯然滿足條件(1)~條件(3),對于條件(4),已知對于x∈P∪T,記·x={y|y∈P∪T∧(y,x)∈F},x·={y|y∈P∪T∧(x,y)∈F},稱·x為x的前集,x·為x的后集,因此,圖4中所有變遷與庫所中,dom(F)表示相鄰2節點x和y滿足(x,y)∈F的·y的集合,cod(F) 表示相鄰2節點x和y滿足(y,x)∈F的y·的集合,即dom(F)={p1,p2,…,p18,p19,t1,t2,…,t17,t18},cod(F)={p2,p3,…,p19,p20,t1,t2,…,t17,t18},滿足條件(4),因此,圖4是合理的Petri網模型。 通過比對給定的事件日志與流程模型可以發現,事件日志中大多數的跡都可以在流程模型中重放,但α1,α6,α7,α11,α12并不能與流程模型完全擬合,對于α1,α11,α12,前文已經進行了詳細分析,本節主要針對α6,α7這類行為,對事件日志L2使用本文提出的新方法對原始模型進行修復。 首先用流程樹語言描述流程模型的結構,并用矩形區域將流程樹節點表示出來,如圖5所示,可以清楚地看到流程模型中的各個結構,即順序結構、選擇結構和并發結構。 →(a,b,∧(c,d,e),f,×(g,→(h,i)),j,k,∧(l,m),n,×(→(o,p),q),r) Figure 4 Process model N of accident insurance claim based on Petri net圖4 基于Petri網的事故保險理賠流程模型N Figure 5 Block structure diagram of Petri net model N圖5 Petri網模型N的塊結構示意圖 然后根據算法1篩選符合條件的并發事件,具體的篩選過程如表1所示。通過表1可以看出[k,v]是一組符合條件的并發事件,找到并發事件后根據算法2對模型進行修復。首先斷開活動k的所有流關系,然后與活動v重構為一個并發結構 Table 1 Main processes and results of filtering concurrent events 最后將U連接到模型中,滿足·U={p12},U·={p13,p14},即得到修復后的模型N′,如圖7所示。 顯然,相較于原始模型,含有重構子流程的修復模型N′可以完全重放事件日志L2。不難發現,在實際生活中,當發生重大事故采取司法程序處理時,都會收到開具的相關證明,以便在理賠手續中提供合法憑證。若使用現有的修復方法,例如,使用目前經典的插入與跳過活動的修復方法所得到的修復模型N1(如圖8所示),可以看出修復模型N1中包含自循環結構,允許無限多的循環行為,因此圖8過度概括了日志中出現的行為,導致模型表達不精確。相反,使用本文所提方法修復的模型N′,結構相對比較簡單,不包含循環結構,不會多次出現循環活動v的行為,如圖7灰色部分所示,只涵蓋3種執行順序:〈k,v〉,〈v,k〉,〈k〉,與L2中的情況完全吻合。 Figure 6 Subprocess U of the refactoring圖6 重構的子流程U Figure 7 Repair model N′ containning the refactored subprocess圖7 含有重構子流程的修復模型N′ Figure 8 Repair model N1 with existing methods圖8 現有方法的修復模型N1 最后,為了對比N1與N′這2個修復模型的精確性,本文根據文獻[14]給出適合度fitness和精度precision的相關公式,如式(5)所示: (5) fitness(L2,N1)=1-0=1 fitness(L2,N′)=1-0=1 對于2個模型的精度,根據精度計算公式可得: 顯然,0.84<0.97,在適合度都為1的情況下,本文方法修復后的模型精度更高一些。因此,通過上述對比可知,本文提出的方法具有合理性和可行性。 本文在已有研究的基礎上,基于事件日志與流程模型之間的最優對齊,提出了一種重構子流程的修復方法。首先根據最優對齊,利用相關算法篩選符合條件的并發事件,并將其重構為一個并發結構的子流程,之后將子流程連接到原模型中完成修復。最后本文通過事故保險理賠系統的一個實例驗證了該方法的合理性。 由于本文提出的種方法對于含有復雜結構的流程模型并不能很好地適用,因此,在未來的研究中,我們希望可以進一步拓展,尋找一種在復雜結構的情況下也能普遍適用的修復方法,并盡可能提高相應的適合度以及精度。3.2 重構子流程修復模型




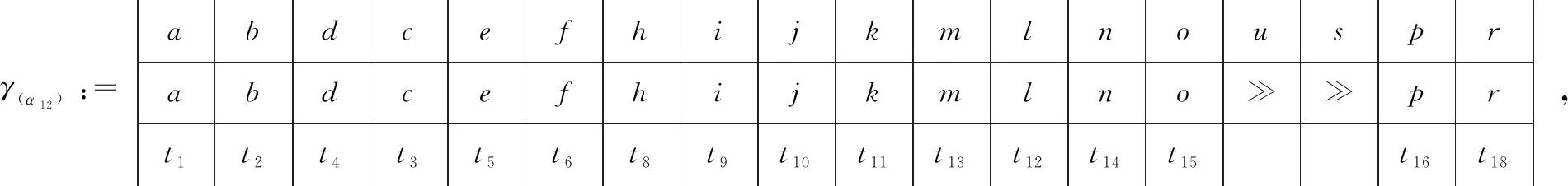
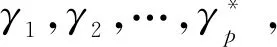


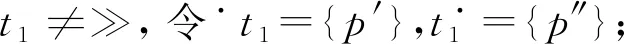
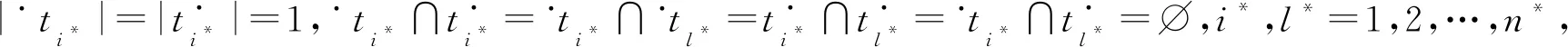
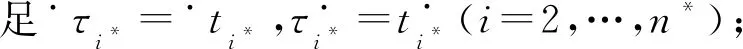
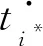
4 實例分析



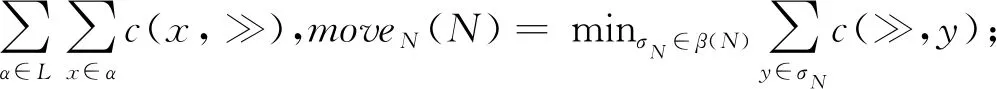
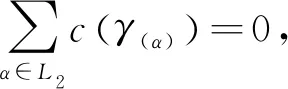
5 結束語
猜你喜歡
少先隊活動(2022年5期)2022-06-06 03:45:04
家庭科學·新健康(2022年3期)2022-05-10 00:32:13
中老年保健(2021年2期)2021-08-22 07:31:10
哲學評論(2021年2期)2021-08-22 01:53:34
中華詩詞(2019年7期)2019-11-25 01:43:04
海峽姐妹(2018年3期)2018-05-09 08:20:40
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
