標簽擴展的協同過濾推薦算法 *
2021-10-26 02:12:30陳海龍閆五岳孫海嬌
計算機工程與科學 2021年10期
陳海龍,閆五岳,孫海嬌,程 苗
(哈爾濱理工大學計算機科學與技術學院,黑龍江 哈爾濱 150080)
1 引言
隨著互聯網技術的迅速發展,互聯網人口快速增長,隨之導致網上數據呈指數級增長態勢,從而導致了嚴重的信息過載。為了使用戶能夠快速準確地獲取自己感興趣的物品,推薦系統應運而生。推薦系統能夠分析系統中的用戶數據,根據用戶的喜好為用戶推薦商品或服務,能夠有效地解決信息過載帶來的問題。目前,成熟的推薦算法有很多,如基于內容的推薦[1]、協同過濾推薦[2]和基于關聯規則的推薦[3]等。
在有關的推薦算法中,協同過濾推薦算法應用最為廣泛。但是,協同過濾模型的一大問題是數據稀疏,該問題影響了推薦算法的推薦質量。為了緩解數據稀疏對推薦算法的影響,研究人員進行了許多嘗試。例如Cui等[4]為解決個性化興趣點POI(Point-Of-Interest)推薦數據稀疏問題,從多角度來擴展協同過濾模型。Guan[5]提出了一種三維協同過濾框架,通過使用用戶和項目的特征進行相似度計算來處理數據稀疏性問題。除此之外,為了實現推薦算法的高效性,將深度學習融入推薦算法成為了熱點。Mohammad等[6]在推薦系統框架下集成深度神經網絡和矩陣分解并使用顯示反饋進行協同過濾。Huang等[7]利用基于多注意深度神經網絡實現準確的組推薦,采用多注意網絡捕獲內部社交特征,采用神經注意機制來描述每個組和成員之間的偏好交互。另外,Huang等[8]還提出了一種基于多模式表示學習模型,通過項目的多峰特征和用戶的全局特征來計算用戶對項目的偏好。Fu等[9]提出了一種基于深度學習的智能推薦,通過學習用戶和項目的相應低維向量采用前饋神經網絡模擬用戶和物品之間的交互。Zhao等[10]提出了一種預測協同過濾方法,利用部分觀察到的用戶-項目矩陣和基于項目的輔助信息來產生推薦。
近年來,標簽[11]的應用越來越廣泛。標簽是一種無層次化結構的、用來描述信息的關鍵詞[12],它可以用來描述物品的語義。根據給物品標注標簽的人的不同,標簽應用一般分為2種:一種是專家給物品標注標簽,一種是普通用戶給物品標注標簽,也就是UGC(User Generated Content)。UGC的標簽系統可以用來表示用戶興趣和物品語義。社會化標簽[13]可以看作用戶與物品之間的紐帶,將原本不相關的項目聯系起來,既表達了用戶自身的興趣愛好,又反映了物品的主題。
基于標簽的推薦系統一般應用在音樂網站、視頻網站和電影書籍評論網站中,最具代表性的網站有Delicious、Last.fm和豆瓣等。標簽系統的最大優勢是可以發揮群體智能,獲取對物品內容信息比較準確的關鍵詞描述,而準確的內容信息是提升個性化推薦系統性能的重要資源[14]。
基于標簽的推薦算法通常使用用戶標注項目的頻率反映用戶的興趣,用戶使用標簽的次數越多,則代表該用戶越喜歡標簽代表的特定項目類別。Ignatov等[15]將標簽頻率分析應用于標簽推薦算法中,用來發現用戶的興趣。Gedikli等[16]認為應該在項目的上下文中考慮標簽偏好,并提出了一種在推薦過程中利用上下文的標簽偏好的推薦方案。但是以上研究沒有考慮到由于用戶標注標簽的隨意性導致的標簽信息稀疏問題。由于用戶個體不同,用戶對相同項目的理解不同,導致不同的用戶對相同的項目標記的標簽會有所不同,從而導致標簽信息的稀疏性。因此,僅通過用戶-標簽和項目-標簽的匹配程度來衡量用戶相似度和項目相似度是不準確的。趙宇峰等[17]通過標簽聚類降低標簽稀疏度,進而提高推薦精度。除此之外還存在以下現象:用戶給物品標注的標簽不同,但是在語義上可能相近。針對這種現象需要對標簽進行語義分析。在語義分析方面,可以利用基于WordNet詞典的方法。顏偉等[18]提出了一種基于WordNet的英語詞語相似度計算方法,從WordNet中提取同義詞并采取向量空間方法計算英語詞語的相似度。
在上述研究的基礎上,本文提出了一種標簽擴展的協同過濾推薦算法。本文通過擴展標簽來緩解標簽信息稀疏問題,提高算法推薦精度。利用標簽相似度進行標簽擴展,計算標簽相似度的方法有2種:一種是基于用戶標注標簽的行為進行計算,另一種是根據標簽的語義進行計算。現有的標簽擴展方法多數是根據標簽共現計算基于用戶行為的標簽相似度實現的,未充分考慮標簽的語義相似度。因此,本文從用戶行為和標簽語義2方面考慮,分別運用標簽共現和WordNet詞典計算標簽相似度。通過結合基于用戶行為的標簽相似度和基于標簽語義的標簽相似度,進一步提升標簽擴展的效果,進而提升推薦算法的性能。
2 算法設計
傳統基于標簽的推薦算法,利用標簽頻率反映用戶的興趣。但是,用戶標注標簽的隨意性,可能會導致出現以下2種情況:
(1)標簽t1被用于標注項目ij,標簽t2也被用于標注項目ij,相同的項目ij被用戶標注了不同的標簽t1和t2。
(2)用戶u1為項目ij標注了標簽t1,用戶u2為項目ij標注了標簽t2,用戶為項目ij標注了不同的標簽t1和t2,雖然標簽t1和t2不相同,但在語義層面表達了相近的意思。
上述問題導致了在利用標簽進行推薦時,與標簽相關的用戶-標簽和項目-標簽矩陣稀疏,從而導致推薦精度下降。
為了降低矩陣稀疏度,提高推薦算法的精度,本文提出了標簽擴展的思想。在進行標簽擴展時,需要先進行標簽相似度計算。在計算標簽相似度時,根據情況(1)和情況(2)的描述,本文從用戶行為和標簽語義2方面進行標簽相似度計算。
用戶為相同的項目標注了不同的標簽,根據用戶的行為,本文利用標簽共現的思想計算標簽相似度。利用標簽共現來表示標簽相似度的基本思想是:如果2個標簽在項目中同時出現的次數越多,則這2個標簽的相似度就越高。
用戶為項目標注了不同的標簽,但標簽在語義上相同,根據標簽語義,本文利用語義分析的思想計算標簽相似度。利用語義分析計算標簽相似度的基本思想是:判斷詞語之間的相似度。本文利用WordNet語義詞典在信息處理方面的優勢,將WordNet應用到標簽的語義分析中,用于計算標簽相似度。
綜上所述,本文提出了一種標簽擴展的協同過濾推薦算法。該算法的流程如下所示:
(1)根據數據集構建項目-標簽矩陣,并創建標簽集合。
(2)利用標簽共現信息,計算標簽共現矩陣,得到基于用戶行為的標簽相似度矩陣。
(3)根據標簽集合并利用WordNet語義詞典計算基于標簽語義的標簽相似度矩陣。
(4)結合基于用戶行為和標簽語義的標簽相似度矩陣,并利用標簽相似度矩陣進行標簽擴展,重構項目-標簽矩陣。
(5)利用重構后的項目-標簽矩陣計算項目相似度,并通過基于項目的協同過濾方法進行推薦。
2.1 基于標簽共現計算標簽相似度
本文所用的數據集示例如表1所示。正如前面提到的,用戶個體不同會導致不同用戶對相同項目標注的標簽不同,因此本文根據用戶標注標簽的行為,通過標簽共現思想來整合標簽之間的相似度。標簽共現就是指用2個標簽標注同一個項目,如標簽t1和t2共同標注了某一個項目,則稱標簽t1和t2共現。
不同用戶可能為相同項目標注不同的標簽。正如表1所示,用戶20對電影1 747所標注的標簽為politics和satire,而用戶49對電影1 747 所標記的標簽為Robert De Niro。
網站中的用戶組成了用戶集合U= {u1,…,um},網站中的商品組成了商品(項目)集合I={i1,…,in},用戶對商品標注的標簽組成了標簽集

Table 1 Data format
合T= {t1,…,tk}。根據以上信息構建標注矩陣K,K的大小為n*k,n為項目個數,k為標簽個數,矩陣中的元素kpj表示標簽tp標注商品ij的次數。根據矩陣K構建共現矩陣C,C的大小為k*k,k為標簽個數,矩陣中的元素cpq表示標簽tp與標簽tq標注同一個商品的頻率。本文通過余弦相似度來評估每2個標簽的共現分布,即:
(1)
其中,nti,ij表示標簽tp標注項目ij的數目,ntq,ij表示標簽tq標注項目ij的數目。N(tp)表示標簽tp標注的項目集合,N(tq)表示標簽tq標注的項目集合。N(tp)∩N(tq)表示標簽tp和標簽tq共同標注的項目集合。p(tp,tq)在[0,1],且p(tp,tq)越接近1,tp和tq越相似。
通過式(1)得到標簽共現矩陣,本文將標簽共現矩陣作為基于用戶行為的標簽相似度矩陣。基于用戶行為的標簽相似度矩陣C的表達形式如式(2)所示:
(2)
2.2 利用WordNet計算標簽相似度
由于用戶個體不同,導致用戶為項目標注的標簽可能不同,但某些標簽可能在語義上相近。本文利用WordNet語義詞典在信息處理方面的優勢,將WordNet應用到標簽的語義分析中,計算標簽的相似度。利用WordNet計算標簽t1和t2的相似度的過程如下所示:
(1)利用Stanford CoreNLP和Lemmatization對標簽進行預處理。
(2)利用WordNet分別生成(t1,t2)的同義詞集(s1,s2)。
(3)對每個同義詞集檢索注釋并利用文本預處理方法(拆分、刪除停用詞、詞性標注、詞形還原)為s1和s2提取注釋G1和G2。
(4)基于集合之間相同的詞匯數量越多,相似度越高的思想,根據s1和s2、G1和G2計算標簽t1和t2之間的語義相似度。
具體的流程如圖1所示。
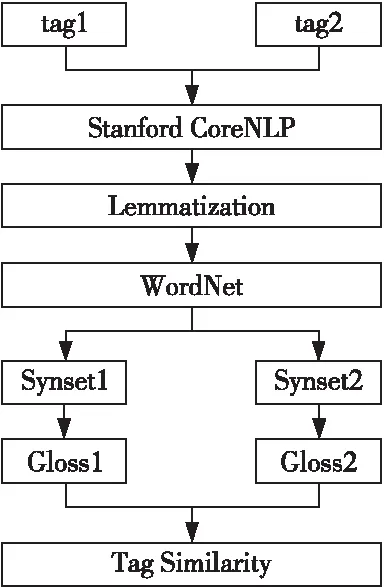
Figure 1 Calculation flow chart of tag similarity圖1 標簽相似度計算流程圖
利用s1和s2、G1和G2計算標簽相似度的公式如式(3)所示:
(3)
通過上述方法計算出2個標簽的語義相似度,得到基于語義的標簽相似度矩陣N。N的表示形式如式(4)所示:
(4)
2.3 合并標簽相似度矩陣
將得到的基于用戶行為的標簽相似度矩陣C和基于標簽語義的標簽相似度矩陣N進行合并,合并公式如式(5)所示:
sim(ti,tj)=α*p(ti,tj)+
(1-α)simT(ti,tj)
(5)
其中,系數α是用于調節的合并權重。經過式(5)得到合并后的標簽相似度矩陣M。M的表達形式如式(6)所示:
(6)
在得到標簽相似度矩陣M后,利用M進行標簽擴展。
2.4 標簽擴展
大多數使用標簽的推薦算法都會考慮到用戶-標簽和項目-標簽之間的關系。但是,由于用戶為項目標注標簽的隨意性,會導致標簽信息稀疏;由于標簽的多樣性,會導致標簽信息稀疏,因此,利用項目-標簽衡量項目相似度是不準確的。所以,本文提出了一種擴展標簽的方法,通過利用標簽相似度矩陣產生的標簽之間的關聯,評估用戶未使用的標簽的可能頻率來進行標簽擴展,從而降低標簽信息的稀疏度。
對于已經標注項目ij但沒有標注項目ii的標簽tz,根據標簽tz與標注到項目ii上的所有標簽共現分布,估計標簽tz標注到項目ii上的可能概率。概率估計公式如式(7)所示:
(7)

(8)
其中,Ni表示標注項目ii的標簽總數,nt,i表示標簽tt標注項目ii的次數。
通過上述方法,本文對項目-標簽矩陣進行了標簽擴展,重建了項目-標簽矩陣,降低了該矩陣的稀疏度。
2.5 計算項目相似度并推薦
在得到重建后的項目-標簽矩陣R后,利用余弦相似度計算項目之間的相似度得到項目相似度矩陣S。項目相似度的計算公式如式(9)所示:
(9)
其中,Ti,j表示在矩陣R中項目ii和項目ij共有的標簽集合。Ti表示標記項目ii的標簽集合,Tj表示標記項目ij的標簽集合。simiz表示標簽tz標記項目ii的概率,simjz表示標簽tz標記項目ij的概率。在得到項目相似度矩陣之后,利用基于項目的協同過濾算法為用戶生成推薦。
3 實驗
3.1 實驗數據集
實驗采用MovieLens數據集,該數據集含有電影的標簽數據。為了驗證本文算法的效率,在2個基準數據集上進行實驗。較小的數據集為ml-latest-small,該數據集由164 979部電影和671個用戶組成,含有1 296個標簽記錄。較大的數據集為ml-10M100K,該數據集由71 567個用戶和10 681部電影組成,含有95 580個標簽。本文按照8∶2的比例將數據集分成訓練集和測試集。
3.2 評價標準
準確率(Precision),其值表示的是在產生的推薦結果中,正確推薦給用戶的項目數在推薦給用戶的項目總數中的占比,如式(10)所示:
(10)
召回率(Recall),其值表示的是在產生的推薦結果中,正確推薦給用戶的項目數在用戶實際評價過的項目總數中的占比,如式(11)所示:
(11)
其中,R(u)是用戶u推薦的項目集合,T(u)是測試集中用戶u評分過的項目集合。
3.3 實驗結果及其分析
3.3.1α的選擇
在式(5)中系數α用于調節相似度權重,用來調節標簽相似度權重變化對于推薦算法的推薦準確率的影響,其取值在[0,1],每次增加0.1比較Precision的變化,實驗結果如圖2所示。
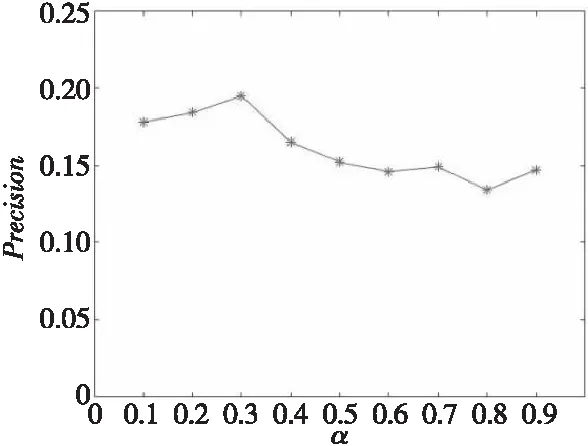
Figure 2 Effect of α on Precision圖2 α對準確率的影響
由圖2可知,當α的取值為0.3時,Precision值最大,推薦的準確率最高。本文實驗中,α取值為0.3。
3.3.2 算法性能比較
為了驗證標簽相似度的改變對于推薦算法的推薦精度的影響,本文將通過標簽共現進行標簽擴展的協同過濾CTCF(Collaborative Filtering of tag extension based on Tag Co-occurrence)和結合標簽共現與WordNet進行標簽擴展的協同過濾CWTCF(Collaborative Filtering of tag extension based on Tag Co-occurrence and WordNet)進行比較分析。實驗結果如圖3和圖4所示。
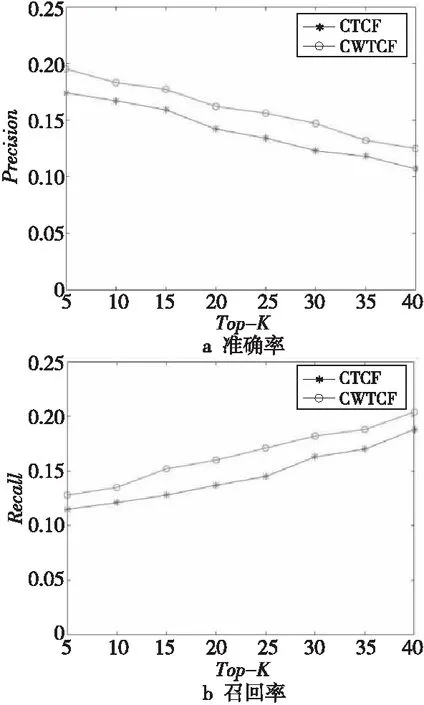
Figure 3 Performance of CTCF and CWTCF on ml-latest-small圖3 CTCF和CWTCF在ml-latest-small上的性能
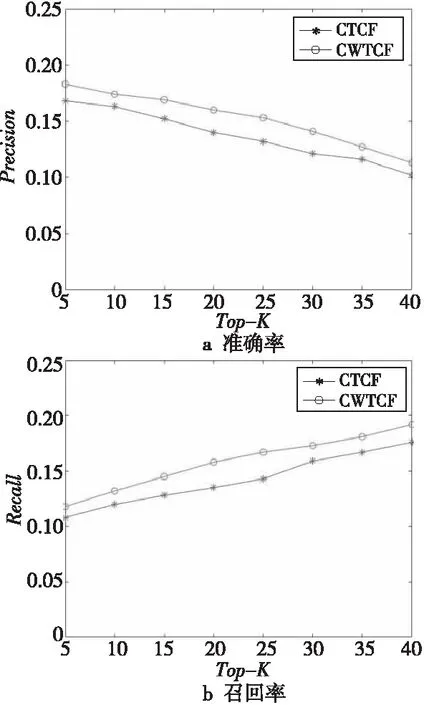
Figure 4 Performance of CTCF and CWTCF on ml-10M100K圖4 CTCF和CWTCF在ml-10M100K上的性能
由圖3和圖4可知,相較于只使用標簽共現進行標簽擴展的協同過濾或只使用WordNet進行標簽擴展的協同過濾而言,將標簽共現和WordNet進行結合再利用標簽擴展進行協同過濾的推薦算法的Precision有所提高。由此可知,在利用標簽相似度進行標簽擴展時,應從用戶行為和標簽語義這2方面考慮,本文通過標簽共現思想得到基于用戶行為的標簽相似度矩陣,通過標簽語義得到基于語義相似度的標簽相似度矩陣,將2個相似度矩陣進行融合,并在此基礎上進行標簽擴展,降低數據稀疏度,進行協同過濾,提高了推薦精度。
接著為了驗證本文提出算法的性能,本文選取3種算法與本文算法進行比較。
算法1:傳統的基于項目的協同過濾推薦ItemCF(Item Collaborative Filtering)算法。
算法2:Guan[5]提出的3DCF(3-Dimension Collaborative Filtering)算法,利用用戶和項目的特征進行相似度計算來處理數據稀疏問題。
算法3:Gedikli等[16]提出的Item-specific算法,在項目上下文中考慮標簽偏好對推薦的影響。
不同算法性能比較如表2~表5所示。
由表2~表5可知,相較于傳統的ItemCF算法,其他3種算法的性能更高,因為這3種算法都在ItemCF基礎上進行了一定程度的改進。另外,可以觀測到,Item-specific算法的性能比3DCF的更高,可能的原因是Item-specific算法將標簽應用到了以協同過濾為基礎的推薦算法之中,可以更好地反映用戶的興趣。除此之外,本文算法的性能相較于其他3種算法都高,相較于3DCF在降低數據稀疏度時僅僅考慮用戶和項目特征,本文在降低數據稀疏度時充分考慮了標簽數的作用,相較于Item-specific僅僅在項目上下文中考慮標簽偏好,本文算法利用標簽數據降低了數據稀疏度,綜上本文算法的性能更好,推薦精度更高。
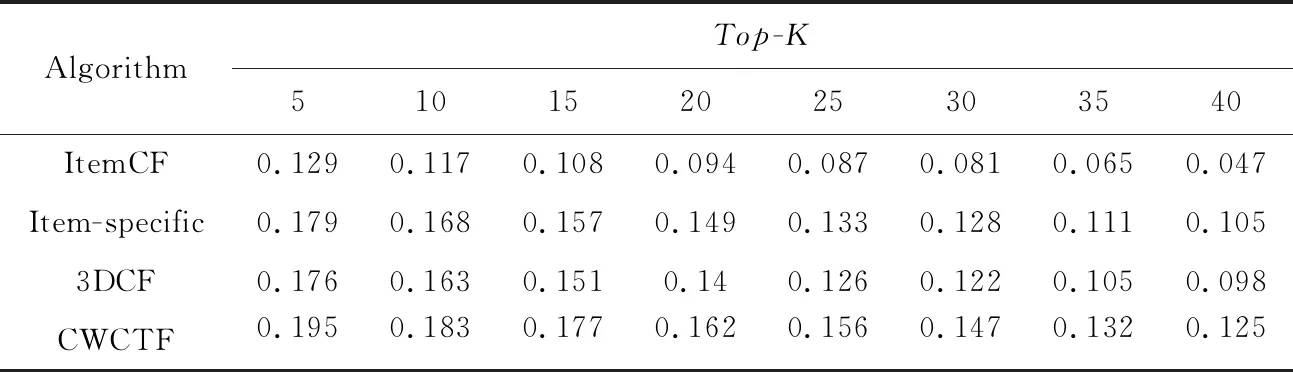
Table 2 Precision of four algorithms on ml-latest-small
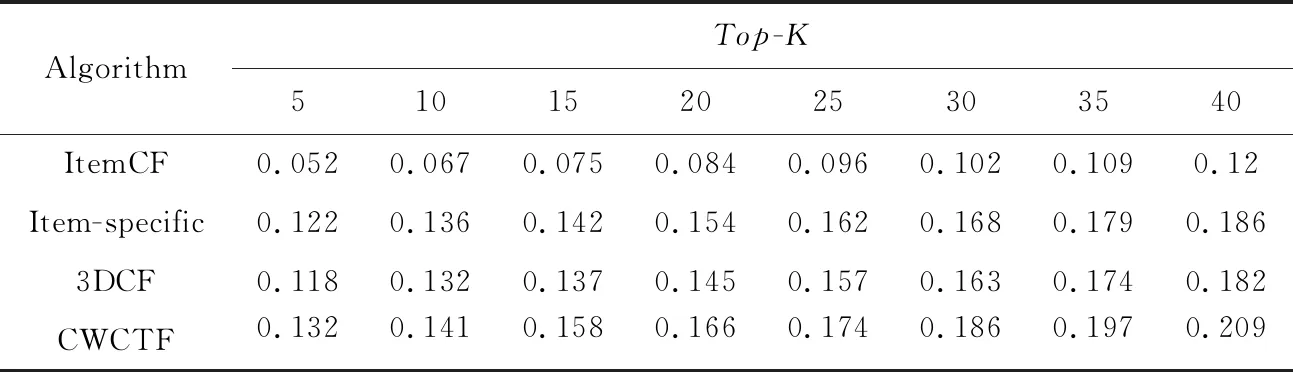
Table 3 Recall of four algorithms on ml-latest-small
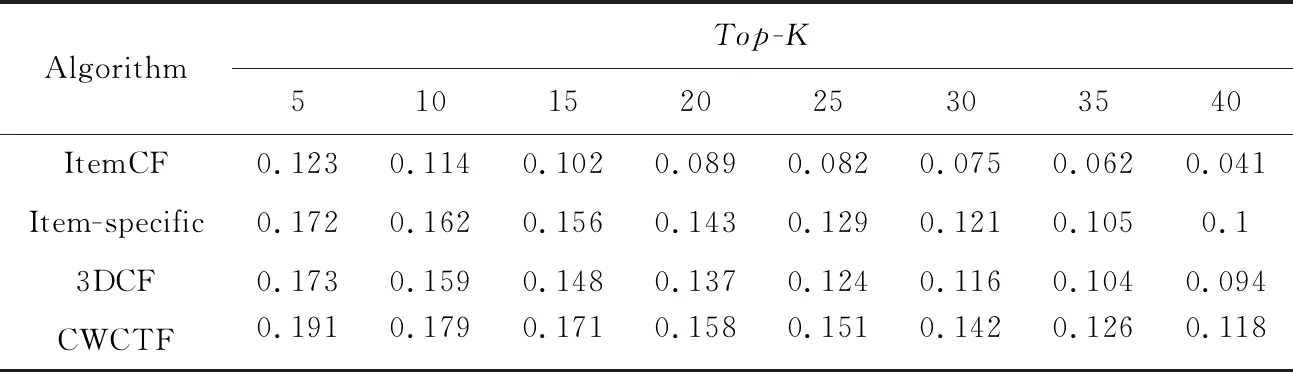
Table 4 Precision of four algorithms on ml-10M100K
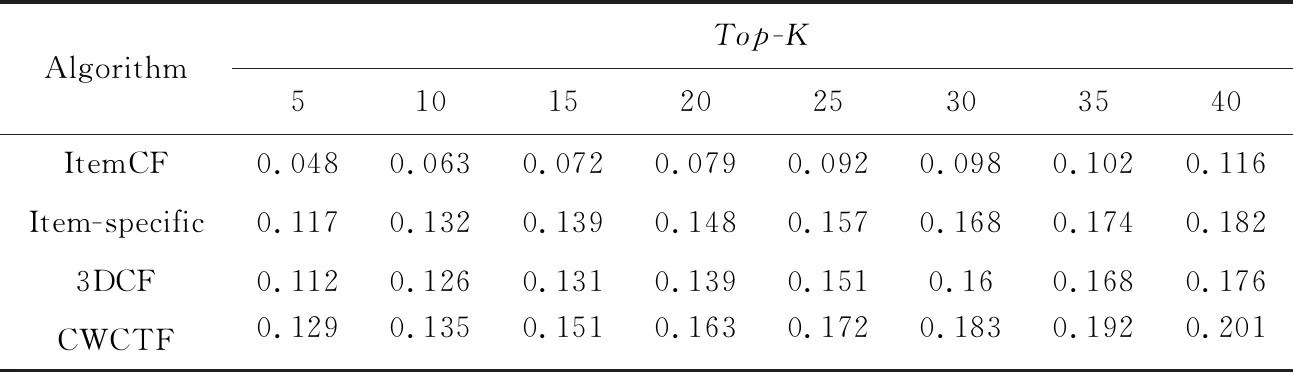
Table 5 Recall of four algorithms on ml-10M100K
4 結束語
大多數利用用戶、項目與標簽之間的關系進行推薦的算法,都會面臨著用戶個體不同導致的標簽信息稀疏問題,因此,本文進行標簽擴展,重構項目-標簽矩陣,進行協同推薦,在進行標簽擴展時從用戶行為和標簽語義2方面進行考慮。最終的實驗結果表明,本文提出的推薦算法相較于傳統的協同過濾算法的推薦效果更好。
猜你喜歡
中等數學(2022年2期)2022-06-05 07:10:50
小學生學習指導(低年級)(2020年6期)2020-07-25 02:31:36
開放教育研究(2020年2期)2020-03-31 01:54:14
小學生學習指導(低年級)(2018年9期)2018-09-26 05:59:44
瘋狂英語·新讀寫(2018年2期)2018-09-07 09:32:10
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
現代語文(2016年21期)2016-05-25 13:13:44
商用汽車(2016年4期)2016-05-09 01:23:12
大連民族大學學報(2015年2期)2015-02-27 08:28:11
