基于LSTM和功率信息的大型工件加工過程監控
2021-10-26 13:15:24念志偉林正英朱圣杰
機械制造與自動化 2021年5期
關鍵詞:模型
念志偉,林正英,朱圣杰
(福州大學 機械工程及自動化學院,福建 福州 350108)
0 引言
大型工件,特別是結構復雜的加工件,加工時間長,生產組織難度大。對于大型工件而言,監控加工過程,掌握加工進度信息,既能夠確保加工任務的完成,提高加工效率,又能夠根據生產進度的情況來進行調度優化。
機床加工的過程中能量的消耗會反映出機床的加工情況,大型工件的實時加工過程對應著機床加工功率數據的實時變化。一些學者針對工件加工過程中能耗變化的狀況展開研究。WANG Q L等對連續功率信號進行重復分析并在加工過程中進行能效的多狀態建模,實現加工過程異常的檢測[1]。CAI Y等提出了一種連續小波變換和快速獨立分量分析相結合的方法,提取銑削過程中能效狀態的特征[2]。單東日等系統分析了柔性作業車間的工件加工過程中各階段的機床能耗與時間特性,通過遺傳算法和功率信息建立工件批量加工調度模型[3]。賀曉輝等通過分析工件加工過程功率變化特征,提出一種結合工件加工功率信息特征分析及支持向量機分類的工件在線識別和統計方法[4]。顧文斌等設計了一種以嵌入式技術為基礎的數控機床能耗監控系統,可實時采集和監控機床加工過程中的能耗狀態[5]。
目前大多數文獻能耗與加工過程的研究,部分是針對工件加工過程中總體能耗數據的特征進行分析,部分是針對能耗監控方法研究,但是未考慮工件加工過程中的功率變化。為此,針對現有研究的不足和問題,本文針對大型工件加工過程中的功率變化進行分析,實現對加工過程的監控。
1 大型工件加工進度狀態信息采集方法
1.1 工件加工過程功率狀態曲線的分析
劉飛等[6]對功率曲線進行分析后得出結論,工件的每一個加工過程,都有著一個確定的功率狀態曲線與其相對應;反之,功率狀態曲線上的每一點,對應著工件某一時刻的加工進度狀態信息。以實際銑削過程為例,圖1所示為機床銑削鋁合金過程中的功率數據曲線。根據功率數據曲線與實際加工過程的工步變化,可將數據分成空載進刀、銑刀接觸、銑削表面、銑刀離開以及空載運行五個部分。
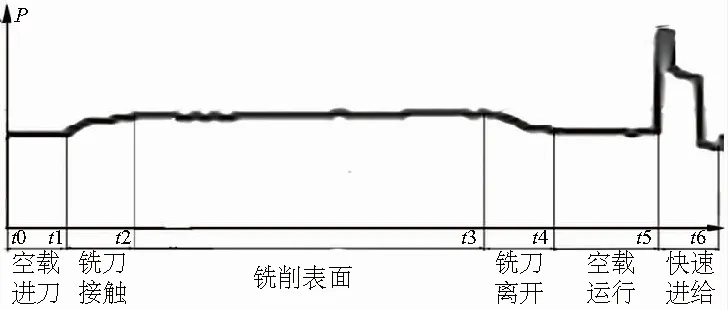
圖1 銑削鋁合金的功率數據曲線
以加工工件前事先獲取的功率數據作為訓練數據,建立工件工步識別模型,然后根據加工過程中實時采集的功率數據,將其輸入模型從而得出實時工步結果,監控工件加工過程。
1.2 長短時記憶神經網絡
長短時記憶(LSTM)神經網絡設計的初衷是為了解決神經網絡的長期依賴問題,避免像循環神經網絡RNN在處理長序列數據上會產生梯度消失的情況[7]。LSTM主要由遺忘門ft、輸入門it、記憶單元C以及輸出門Ot組成,單元結構如圖2所示[8]。
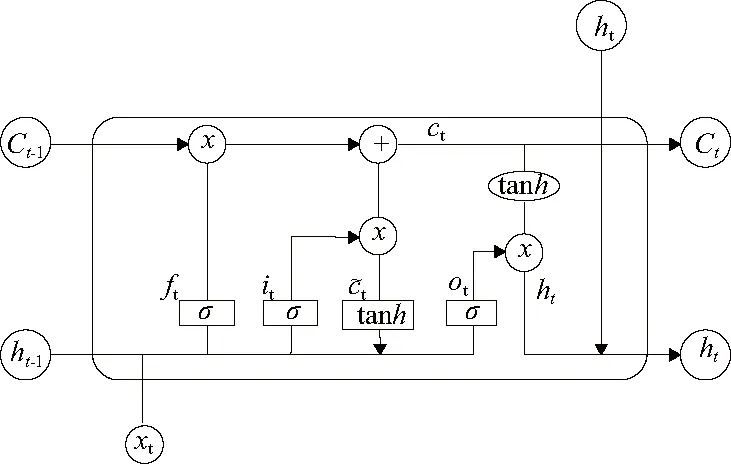
圖2 LSTM的細胞結構
LSTM的關鍵就是記憶單元,在單元上方從左至右貫穿單元,它能夠將上一個單元的信息傳輸到下一個單元。
LSTM的單元更新主要由3個門控制,其中控制神經單元決定其需要遺忘哪些信息,遺忘門為
ft=σ(Wf·[ht-1,xt]+bf)
(1)
負責更新細胞狀態的輸入門為
it=σ(Wi·[ht-1,xt]+bi)
(2)
(3)
決定當前時刻細胞輸出的輸出門為
Ot=σ(Wxo·Xt+Who·ht-1+bo)
(4)
ht=Ot·tanh(Ct)
(5)
LSTM的細胞狀態為
(6)
2 基于LSTM的大型工件工步識別模型
2.1 數據預處理
數據之間的差異性會對模型的學習能力產生負面影響。由于模型的數據來源是采集大型工件加工過程中的功率數據,功率數據的大小隨著工件加工工步的變化而變化,不同工步之間數值差距可能過大。因此為了保證模型的參數能夠穩定收斂,需對數據進行歸一化處理。
另外為了使功率數據能夠符合LSTM框架中的輸入層和輸出層要求,需要將輸入的加工工件的功率數據轉化為可監督數據,將功率數據打上標簽,以便進行分類識別。
2.2 模型構建
由于僅使用單變量功率數據實現大型工件工步識別,其數據的特征有限,因此本文所構建的LSTM網絡只有三層,第一層為輸入層,第二層為LSTM層,第三層為Dense層。模型損失函數選用交叉熵損失函數(binary_crossentropy),優化選取基于梯度下降的ADAM算法。
在構建LSTM神經網絡的過程中,隱藏神經元數目、初始學習率大小以及輸入量長度等重要參數會直接影響到模型識別效果,必須對模型中的這些參數進行優選,提高模型識別的精度。這里采用大型工件工步判斷的準確率(accuracy)作為檢驗識別模型效果的指標:
(7)
其中TR為工步判斷正確的數量。
網格搜索法(grid search method,GSM)是一種比較常用的優化算法,通過指定超參數,對訓練集進行窮舉訓練,最后選出最優模型的超參數。采用網格搜索法對輸入量長度、隱藏神經元數目和初始學習率大小進行參數優化,根據3個參數訓練不同模型,再通過模型的準確率得分確定最優的參數。
模型主要流程圖如圖3所示。

圖3 模型流程圖
3 某大型工件模擬驗證
3.1 模擬實例
以主軸箱加工為例,對加工工步功率進行模擬驗證,工件結構圖如圖4所示。
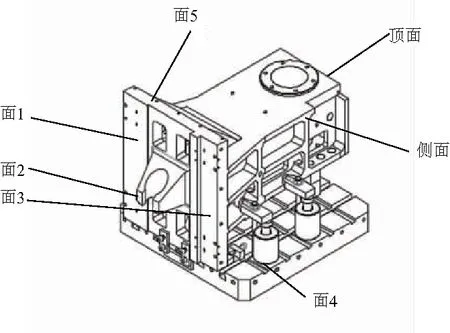
圖4 主軸箱結構圖
根據工件的加工工藝流程,以其中一道工序為例,該道工序的工藝規劃如表1所示。表中,轉速單位為r/min;尺寸單位為mm。
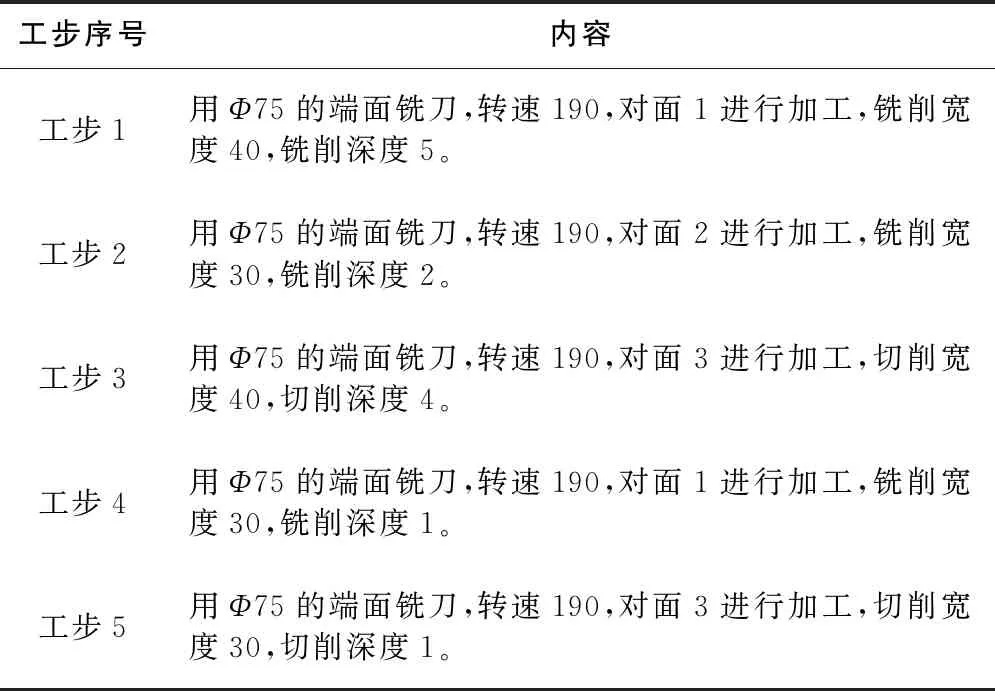
表1主軸箱加工的某道工序工步
當材料為灰鑄鐵時,銑削功率、銑削力的經驗公式[9]如下:
(8)
(9)
其中:Pc為銑削功率;Fc為銑刀切削力;ap為切削深度;ae為加工表面寬度;fz為每齒進給量;d0為銑刀直徑;Z為銑刀齒數;n為銑刀轉速。
根據公式建立加工工件功率數據集,模擬大型工件加工的參考功率曲線如圖5所示。

圖5 參考功率曲線
因為功率數據是由加工工件時以10s為一次采集頻率,相鄰數據的時間點接近,所以設定窗口長度的取值范圍取[30,40,50],隱藏層神經元個數的取值為[50,100,150,200],初始學習率設置[0.001,0.01,0.1]。
取網格搜索法對于超參數的模型得分,記錄了不同參數條件下的結果。表2-表4列出了輸入時間窗長度為30、40、50的得分數。

表2 窗口長度為30的參數尋優
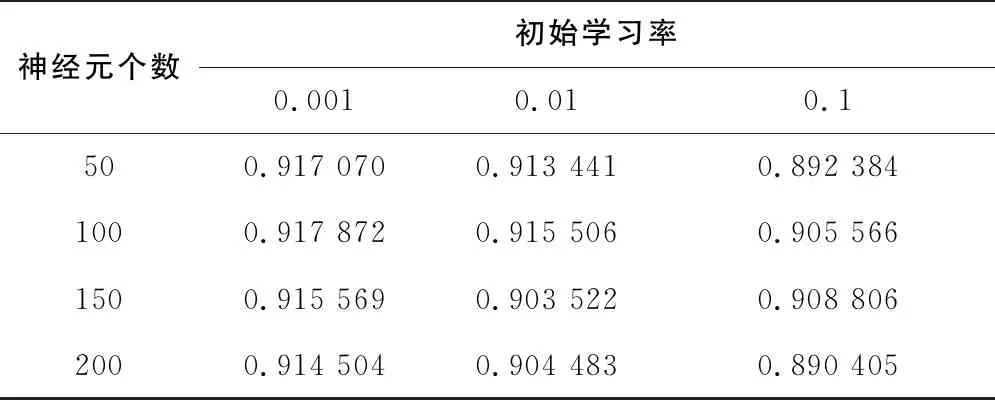
表3 窗口長度為40的參數尋優
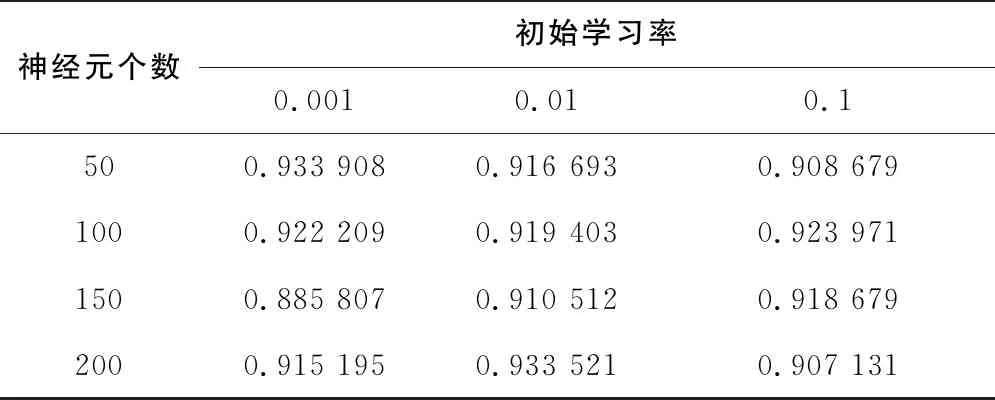
表4 窗口長度為50的參數尋優
從表2-表4可以看出,使用網格搜索法對于超參數進行遍歷,得到窗口長度為50,學習率為0.001,隱藏神經元數量為50的情況下網格搜索法的分類得分最高,模型的精度更好。
3.2 實驗與結果
為了體現本模型在數據集上的表現,實驗中,在相同數據集的情況下分別采用了LSTM、SVM和KNN 3種不同的方法對數據集進行分類,并計算準確率(表5)。

表5 不同方法的準確率
由表5可知,LSTM神經網絡的準確率遠高于另外兩種方法,這是因為對于加工過程可能會出現功率相近的情況,SVM和KNN無法識別工步的區別,因此LSTM更有優勢。
依照網格搜索法選取的超參數建立工步識別模型。工步識別的模型結果如圖6-圖7所示。圖6是模型在訓練集上的預測準確率(accuracy)的變化情況,圖7是模型在訓練集上的損失率(loss)變化情況。

圖6 準確率變化圖
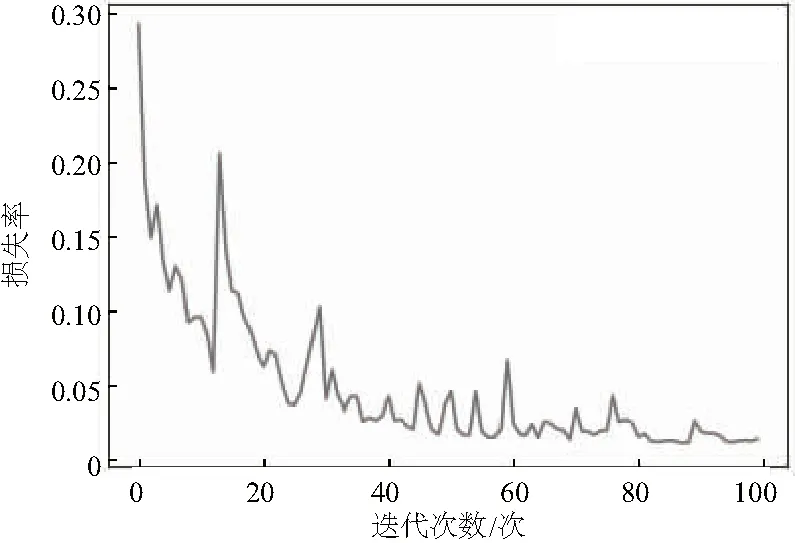
圖7 損失率變化圖
LSTM模型在訓練集上的準確率達到0.988 4,損失率為0.014 8。
將訓練好的模型用在測試集上測試,準確率達到99.13%,損失率為0.013 6。模型在測試集上的表現優秀,分類結果與實際工步結果相差小,能夠起到監控大型工件加工過程的作用。
4 結語
本文根據機床加工大型工件時功率數據具有的非線性和非平穩性的特征,提出了基于網格搜索法優化的LSTM大型工件工步識別模型,通過識別工件工步實現監控大型工件加工過程。通過對于大型工件的模擬實驗,證實了模型的有效性,同時通過功率信息數據監控大型工件加工過程,為工廠在調度、加工管理方面的優化提供了一定的參考。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
