一類基于梯度下降的高效分布式計算方法的應用研究
2021-10-20 03:26:40鄒智康羅元
應用數學 2021年4期
關鍵詞:方法
鄒智康,羅元
(武漢大學數學與統計學院,湖北武漢430072)
1.引言
隨著移動互聯網技術的迅速發展,數據信息安全問題逐漸為人們所重視.現實生活中,數據的存儲方式往往是分散的,由于數據傳輸成本以及機器存儲的限制,互聯網,金融,電子商務等行業會按區域分散設置服務器收集和存儲數據.如何實現數據在不出本地機的前提下完成聯合建模是當下亟待解決的技術性難題.而分布式計算是解決此問題的有效途徑之一,并且由于其高可靠,可容錯和易擴展的天然優勢,結合大數據時代背景,在高維回歸問題中極具應用前景.
至今為止,衍生出了許多分布式計算方法.比如說,文[1-2]通過平均不同本地計算機上的結果來估計實際參數.Jordan等[3]開發了一種通信有效的替代似然函數方法,即CLS(Communication-efficient Surrogate Likelihood).CLS可用于低維模型參數估計,高維正則估計和貝葉斯推斷.WANG等[4]通過在不同的本地機上使用梯度信息解決?1正則化M估計問題并提高了計算效率.
另一方面,高維稀疏條件下的特征篩選和參數估計一直是統計相關學科關注的熱點之一.其中,懲罰方法扮演著重要的角色.Tibshirani[5]提出了?1正則化方法,即Lasso(The Least Absolute Shrinkage and Selectionator operator)方法.然而Lasso方法通常會過度壓縮較大的系數,從而導致估計有偏差,因此統計學家考慮使用非凸懲罰,比如,FAN和LI[6]提出的SCAD(The Smoothly Clipped Absolute Deviation)方法以及ZHANG[7]提出的MCP(The Minimax Concave Penalty)方法都是解決此類問題的代表性成果.但是,在解超高維問題,尤其當維度p是樣本n的指數級時,即p=O(exp(n)),正則化方法存在不穩定不收斂等問題.為此,HUANG[8]提出了交替選擇支撐集并在支撐集上估計參數的SDAR方法來解決?0懲罰問題.SDAR方法是基于?0正則化最小二乘問題的KKT條件所提出來的,具有收斂快,精度高的優點,且可以估計出真實的支撐集并得到參數的Oracle估計.本文在SDAR算法的基礎上,提出了一種分布式的SDAR方法,簡記為GDSDAR.在GDSDAR算法中,我們利用梯度下降法來解決SDAR算法中一系列的最小二乘問題,其中梯度信息的傳遞保證了在聯合建模過程中原始數據的私密性,同時滿足高維稀疏計算以及數據安全的要求.
2.問題簡介





3.實驗結果與分析


由表3.1結果分析可知,其他參數保持不變,隨著樣本總量N的增加,三種算法的相對誤差(RE)值的變化沒有統一趨勢,但在每種情形下,GDSDAR算法的精準度都是最優的.對于正確指標覆蓋率ICR,LASSO與其他兩種方法相比,覆蓋率最小,SCAD方法在樣本量偏低時表現最好,而當樣本總量N增加到一定程度后,GDSDAR方法的ICR指標最優.此外,從計算時間的角度分析,三種算法運行所需的平均時長會隨著樣本總量N的增加而延長.但是在每一種情況下,GDSDAR算法的平均時長最短且波動幅度與另外兩種算法相近.綜上所述,GDSDAR算法在每種情形下都有著最好的精準度和最高的計算效率,且當樣本總量偏大時,正確指標覆蓋率表現更優.
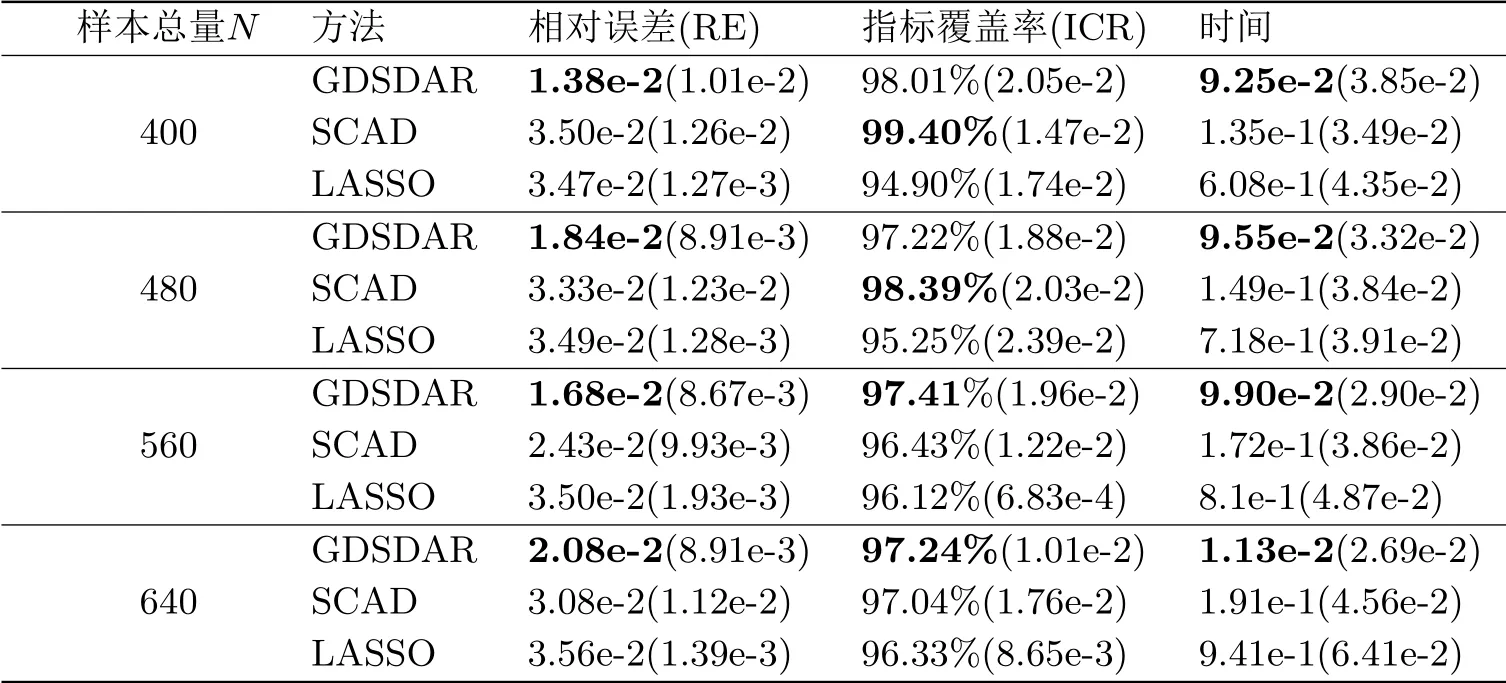
表3.1 不同樣本總量N下三種算法的比較
根據表3.2中的數據分析可知,在其他參數保持不變情況下,隨著稀疏度s的不斷增大,三種方法中只有GDSDAR結果的RE值在不斷下降,始終保持著最高的精準度,而另外兩種方法的RE值則不斷增加,與GDSDAR的精度差距逐漸拉大,說明我們的方法對中等稀疏問題仍然有效.至于正確指標覆蓋率,GDSDAR和SCAD方法隨著s值的增加,ICR指標都穩步提升,一度達到99%的準確率,LASSO方法的ICR指標在大幅降低,從一開始的96.72%陡降至62.67%,說明LASSO方法不適用于中等稀疏問題.綜上所述,在保證較高指標覆蓋率的前提下,GDSDAR擁有更高的精準度,且在稀疏度K較大時,表現更好.
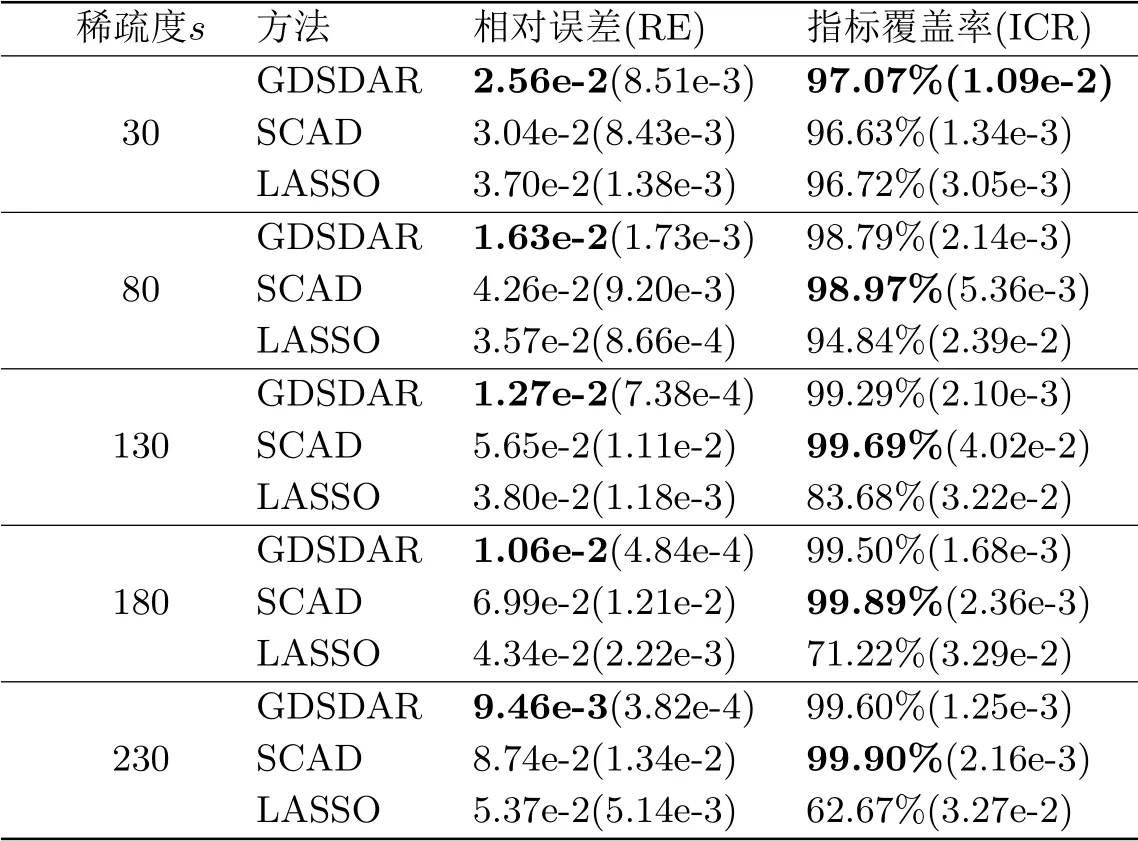
表3.2 不同稀疏度s下三種算法結果比較
分析表3.3數據可知,其他參數保持不變,當數據相關性ρ變高時,GDSDAR、LASSO結果的相對誤差都在不斷降低,而SCAD結果的相對誤差則在不斷增大,從總體上看,GDSDAR算法的RE值最小,精準度最高.對于正確指標覆蓋率,GDSDAR、SCAD兩種方法在相關性變高時,ICR指標逐漸增大,而LASSO方法表現呈下滑趨勢.相比而言,GDSDAR在低相關性條件下更有優勢,SCAD在高相關性條件下會略勝一籌.綜上所述,GDSDAR算法在相關性變動的情況下,精準度都有良好的保證,且正確指標覆蓋率較高.
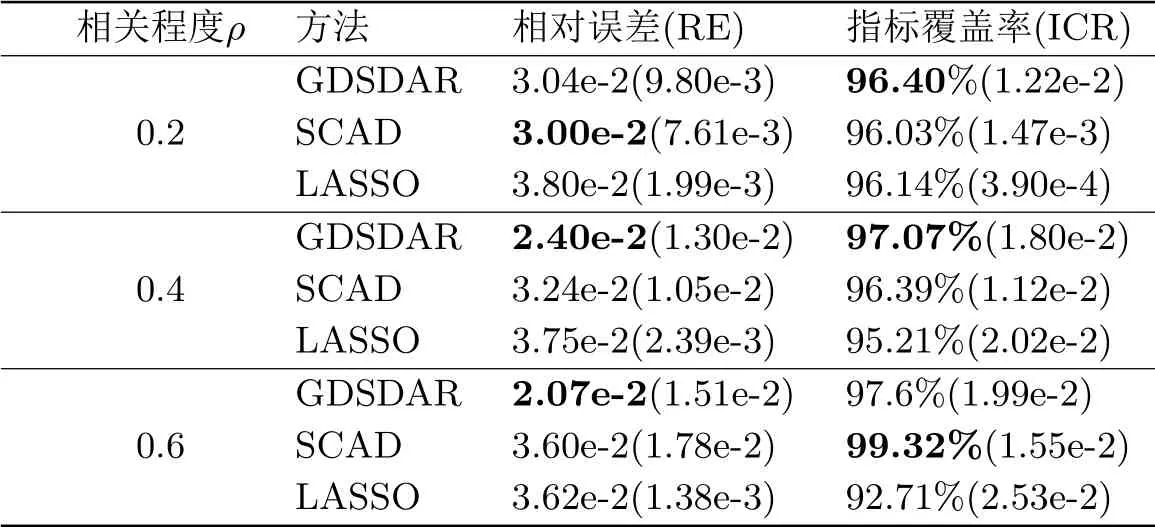
表3.3 不同相關程度ρ下三種算法結果比較
4.結語
本文提出了一種求解分布式情形下高維稀疏參數估計的算法GDSDAR.創新點主要體現在兩個方面.一方面,GDSDAR方法可以解決分散存儲數據的聯合建模問題,在運算過程中,發生信息交互的僅僅是梯度向量而非數據本身,所以能夠保證本地數據的私密性,考慮到當今社會對于信息安全的重視程度,這一特性使得GDSDAR算法擁有廣泛的應用前景.另一方面,在高維稀疏的假定下,GDSDAR算法通過對?0約束最小化KKT條件的改進,交替選擇支撐集的方式并在支撐集上估計參數.實驗表明,相較于經典的?1正則化方法,GDSDAR無論在精準度或是指標正確覆蓋率兩方面都有著優異的表現,穩定性也十分出色.
除了上述的創新點,GDSDAR算法仍然存在一些后續的問題.例如在每次運行算法前,我們需要依據經驗事先確定模型大小,然后據此得到相應的模型.在接下來的研究中,我們考慮運用交叉驗證或者統計學中的HBIC指標輔助判斷合適的模型大小,這種改進將會使GDSDAR算法更適用于真實數據的建模計算.
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
意林原創版(2016年10期)2016-11-25 10:28:30
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12

- 應用數學的其它文章
- Global Boundedness and Asymptotic Behavior in a Chemotaxis Model with Indirect Signal Absorption and Generalized Logistic Source
- 通脹風險和最低保障約束下基于二次效用函數的DC型養老金最優投資策略
- 三維不可壓磁微極流的投影統計解及其退化正則性
- Dynamic Feedback Stabilization for Timoshenko Beam with Locally Input Controls and Input Distributed Delay
- 一類奇異拋物方程淬火解的數值分析
- Convergence Rate Analysis of a Class of Derivative-Free Projection Methods for Convex Constrained Monotone Nonlinear Equations