數(shù)字經(jīng)濟的靶向路徑模型建立方法
2021-10-16 03:38:56潘思葳
中國新技術(shù)新產(chǎn)品 2021年14期
潘思葳
(哥倫比亞大學(xué),美國 紐約 10027)
0 引言
數(shù)字經(jīng)濟的核心為運用數(shù)字化的生產(chǎn)要素,通過現(xiàn)代信息網(wǎng)絡(luò)對經(jīng)濟結(jié)構(gòu)進行優(yōu)化[1]。基于數(shù)字經(jīng)濟的不斷發(fā)展,為驅(qū)動全球經(jīng)濟技術(shù)變革提供堅實的力量。杭州G20峰會明確指出:數(shù)字經(jīng)濟的重要功能就是促進中國經(jīng)濟高質(zhì)量發(fā)展。數(shù)字經(jīng)濟為全球經(jīng)濟的發(fā)展帶來了全新的機遇與挑戰(zhàn),能夠通過數(shù)據(jù)優(yōu)勢與傳統(tǒng)產(chǎn)業(yè)相結(jié)合,為產(chǎn)業(yè)業(yè)態(tài)創(chuàng)新提供源動力。數(shù)字經(jīng)濟的發(fā)展是我國經(jīng)濟在全球范圍內(nèi)快速增長的先決條件,因此,必須重視并充分發(fā)揮數(shù)字經(jīng)濟的能動力[2]。數(shù)字經(jīng)濟的靶向路徑是依賴數(shù)字技術(shù)的創(chuàng)新,通過數(shù)據(jù)要素精準(zhǔn)地滿足經(jīng)濟發(fā)展的需求。作為數(shù)字經(jīng)濟中的重要內(nèi)容,我國建立數(shù)字經(jīng)濟靶向路徑模型的方法層出不窮,但由于其在建立過程中缺少對數(shù)字經(jīng)濟的定量分析,導(dǎo)致數(shù)字經(jīng)濟的靶向路徑模型數(shù)字化密度指數(shù)低[3];因此,對數(shù)字經(jīng)濟的靶向路徑模型建立方法的相關(guān)研究成為學(xué)術(shù)界研究的熱門話題。該文基于此提出數(shù)字經(jīng)濟的靶向路徑模型建立方法研究,致力于提高靶向路徑模型的數(shù)字化密度指數(shù)。
1 數(shù)字經(jīng)濟的靶向路徑模型建立方法
在建立數(shù)字經(jīng)濟的靶向路徑模型的過程中,需要對數(shù)字經(jīng)濟的靶向路徑進行相關(guān)整理與收集,通過標(biāo)簽化的方式對數(shù)字經(jīng)濟的靶向路徑的相關(guān)數(shù)據(jù)進行預(yù)處理,具體方法包括刪除數(shù)字經(jīng)濟的靶向路徑冗余特征、填補數(shù)字經(jīng)濟的靶向路徑空值和噪聲點以及數(shù)字經(jīng)濟的靶向路徑特征降維。在該基礎(chǔ)上,通過模型訓(xùn)練的方式,調(diào)整數(shù)字經(jīng)濟的靶向路徑模型參數(shù),進而建立數(shù)字經(jīng)濟的靶向路徑模型[4]。該文設(shè)計的數(shù)字經(jīng)濟的靶向路徑模型建立方法整體流程如圖1 所示。
圖1 中6 步主要流程的具體研究內(nèi)容,如下文所述。
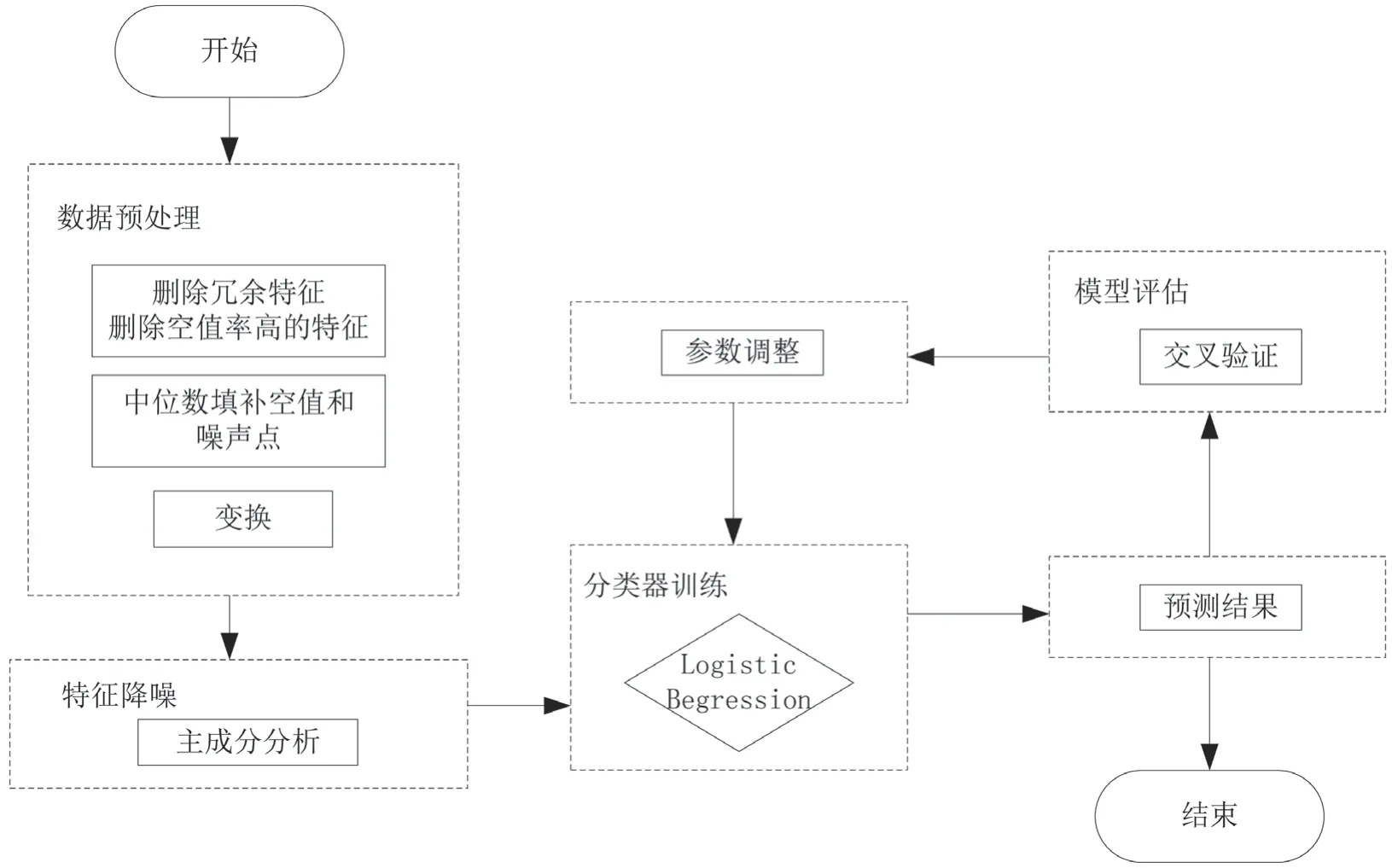
圖1 數(shù)字經(jīng)濟的靶向路徑模型建立方法流程
1.1 數(shù)字經(jīng)濟的靶向路徑數(shù)據(jù)挖掘
在建立數(shù)字經(jīng)濟的靶向路徑模型前,必須明確數(shù)字經(jīng)濟的靶向路徑模型的建立需求,預(yù)先選擇目標(biāo)數(shù)據(jù)[5]。根據(jù)數(shù)字經(jīng)濟靶向路徑數(shù)據(jù)的范圍,基于數(shù)據(jù)挖掘算法運用K-means 聚類分析數(shù)字經(jīng)濟靶向路徑數(shù)據(jù),以此實現(xiàn)對數(shù)據(jù)的挖掘,并對挖掘結(jié)果進行分析。數(shù)字經(jīng)濟的靶向路徑數(shù)據(jù)挖掘流程如圖2 所示。
圖2 數(shù)字經(jīng)濟的靶向路徑數(shù)據(jù)挖掘流程
首先,從不同的數(shù)字經(jīng)濟信息中任意抽取K個中心點,選擇初始簇的中心點;在提取數(shù)字經(jīng)濟的靶向路徑信息之前,先對其進行預(yù)處理,得到較為純凈的數(shù)字經(jīng)濟信息。其次,將各個不同的數(shù)字經(jīng)濟信息數(shù)據(jù)點配置到離該數(shù)據(jù)點最近的中心點,即分樣本簇點。最后,將多個不同的樣本數(shù)據(jù)簇的點劃分到距離其比較近的中心所表示的樣本簇中,即將與初始簇的中心點比較近的中心點劃分為一類。在該步驟中,引入距離公式得到公式(1)。

式中:d(x,y)為歐幾里得距離;n為數(shù)字經(jīng)濟信息的維度;i為數(shù)字經(jīng)濟的靶向路徑條數(shù),i為實數(shù);x、y分別為異種數(shù)字經(jīng)濟信息。
通過公式(1),以初始簇的中心點距離為指標(biāo),挖掘數(shù)字經(jīng)濟的靶向路徑數(shù)據(jù),總結(jié)出數(shù)字經(jīng)濟的靶向路徑數(shù)據(jù)中潛在的隱藏信息,完成對數(shù)字經(jīng)濟的靶向路徑數(shù)據(jù)的挖掘。
1.2 刪除數(shù)字經(jīng)濟的靶向路徑冗余特征
以上述通過數(shù)字經(jīng)濟的靶向路徑數(shù)據(jù)挖掘得到的接近真實的數(shù)字經(jīng)濟的靶向路徑聚類中心為依據(jù),考慮到數(shù)字經(jīng)濟的靶向路徑中存在的冗余特征會對模型建立造成干擾[6];因此,需要對數(shù)字經(jīng)濟的靶向路徑數(shù)據(jù)進行加工,其目的是刪除數(shù)字經(jīng)濟的靶向路徑冗余特征。在設(shè)計相關(guān)算法前需要提取數(shù)字經(jīng)濟的靶向路徑的冗余特征,以實現(xiàn)對數(shù)字經(jīng)濟的靶向路徑的有效識別。在提取冗余特征的過程中,根據(jù)數(shù)據(jù)特點,從不同維度對靶向路徑數(shù)據(jù)進行分類處理,根據(jù)不同類別數(shù)據(jù)的相關(guān)性對其進行權(quán)值賦值。在完成對靶向路徑數(shù)據(jù)迭代權(quán)值與訓(xùn)練樣本的定義后,分析其中高權(quán)重信息與低權(quán)值信息,去除低貢獻的低權(quán)值信息,保留高權(quán)值信息,并將其作為靶向路徑數(shù)據(jù)的冗余特征。反復(fù)迭代,構(gòu)建靶向路徑數(shù)據(jù)特征信息的集合。
在構(gòu)建特征信息集合的基礎(chǔ)上,以維護靶向路徑數(shù)據(jù)分類現(xiàn)狀為目標(biāo)進行特征權(quán)值迭代。假設(shè)不同冗余特征之間均存在一定間隔,將存在無效信息的特定面作為靶向路徑數(shù)據(jù)可以識別的最大距離。確定存在冗余特征的靶向路徑數(shù)據(jù)間隔,如公式(2)所示。
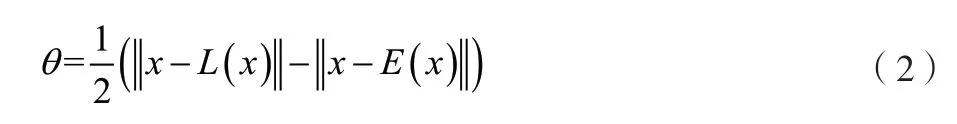
式中:θ為靶向路徑數(shù)據(jù)間隔;x為靶向路徑數(shù)據(jù);E(x)為距離靶向路徑數(shù)據(jù)x最近的同類冗余特征點;L(x)為與靶向路徑數(shù)據(jù)x屬于非同一類型的同類冗余特征點。
根據(jù)公式(2)獲取靶向路徑數(shù)據(jù)的具體冗余點,該過程為使用m×n表示多維度圖像矩陣。假設(shè)靶向路徑數(shù)據(jù)中存在n個冗余特征,將定義的n值存入數(shù)據(jù)庫;將待執(zhí)行訓(xùn)練的圖像中第i個冗余特征樣本置于靶向路徑數(shù)據(jù)第N列中,假設(shè)靶向路徑數(shù)據(jù)每行或每列的初始化特征權(quán)值表示為0,即Wj=0,則冗余特征樣本的數(shù)據(jù)集合可表示為j=1,2,3,…,N。
同時,假設(shè)在存在冗余特征的靶向路徑數(shù)據(jù)中,訓(xùn)練樣本的總個數(shù)為n,則需要在1~n對i值進行反復(fù)賦值。迭代權(quán)值的計算過程如公式(3)所示。
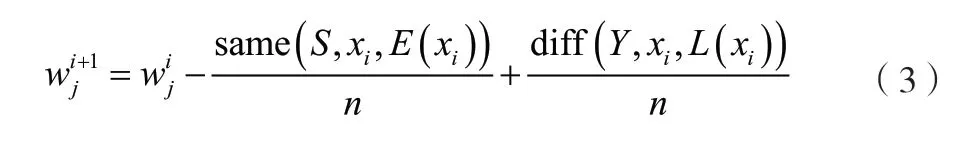
式中:為靶向路徑數(shù)據(jù)的初始化權(quán)值;xi為數(shù)字經(jīng)濟靶向路徑中的某一條數(shù)字經(jīng)濟信息;S為對靶向路徑數(shù)據(jù)抽樣過程中與xi同類的冗余樣本;Y為不同類的冗余樣本;E(xi)為與xi距離最近的坐標(biāo)點;L(xi)為與xi屬于不同類的最近坐標(biāo)點。
根據(jù)公式(3),在對存在冗余特征的靶向路徑數(shù)據(jù)進行刪除時,冗余特征樣本分別以同類數(shù)據(jù)與非同類數(shù)據(jù)的方式來表達,因此可認(rèn)為權(quán)值較大的特征數(shù)據(jù)集合之間冗余特征相似度較高;反之相似度較小。因此,要刪除數(shù)字經(jīng)濟的靶向路徑冗余特征。
1.3 填補數(shù)字經(jīng)濟的靶向路徑空值和噪聲點
刪除數(shù)字經(jīng)濟的靶向路徑冗余特征后,為保證數(shù)字經(jīng)濟的靶向路徑模型建立的數(shù)字化覆蓋程度,需要采用中位數(shù)填補數(shù)字經(jīng)濟的靶向路徑空值和噪聲點[7]。完成上述步驟后,選擇數(shù)字經(jīng)濟的靶向路徑最大的壓縮特征值作為類標(biāo)簽,標(biāo)記為偽標(biāo)記數(shù)據(jù),設(shè)U類的偽標(biāo)記數(shù)據(jù)個數(shù)是US,則U類偽標(biāo)記的小波變換計算公式,如公式(4)所示。

式中:L為帶標(biāo)簽的數(shù)字經(jīng)濟的靶向路徑壓縮數(shù)據(jù)的個數(shù);Lc為靶向路徑壓縮數(shù)據(jù)的最大個數(shù);x為靶向路徑數(shù)據(jù);R為同類偽標(biāo)記數(shù)據(jù);F為同類帶標(biāo)簽數(shù)字經(jīng)濟的靶向路徑壓縮數(shù)據(jù)平均相似度;i為數(shù)據(jù)次數(shù)。
結(jié)合公式(4),如果加入的偽標(biāo)記數(shù)據(jù)能夠滿足一定數(shù)字經(jīng)濟的靶向路徑壓縮條件,則可以通過空值和噪聲點補償所需要滿足的條件,如公式(5)所示。

式中:m為自適應(yīng)壓縮噪聲補償數(shù)據(jù)個數(shù);β為分類器錯誤率上限;θ為分類器噪聲率上限;R為同類偽標(biāo)記數(shù)據(jù);F為同類帶標(biāo)簽數(shù)字經(jīng)濟的靶向路徑壓縮數(shù)據(jù)平均相似度;σ為當(dāng)次迭代中偽標(biāo)記數(shù)據(jù)的數(shù)量。
得出數(shù)字經(jīng)濟的靶向路徑空值和噪聲點補償函數(shù)后,需要重構(gòu)經(jīng)過壓縮處理的數(shù)字經(jīng)濟的靶向路徑數(shù)據(jù)[8]。在建立的模型中填補數(shù)字經(jīng)濟的靶向路徑空值和噪聲點的優(yōu)勢在于能夠?qū)⑿〔ㄗ儞Q的模糊隸屬函數(shù)代入壓縮噪聲補償中,減少傳統(tǒng)模型建立方法中根據(jù)平均值進行壓縮處理容易丟失細節(jié)的問題,得到最終數(shù)字經(jīng)濟的靶向路徑數(shù)據(jù)編碼,從根本上降低數(shù)字經(jīng)濟的靶向路徑數(shù)據(jù)壓縮比,從而保證數(shù)字經(jīng)濟的靶向路徑數(shù)據(jù)的數(shù)字化覆蓋程度。
1.4 數(shù)字經(jīng)濟的靶向路徑特征降維
在填補數(shù)字經(jīng)濟的靶向路徑空值和噪聲點的基礎(chǔ)上,基于主成分分析(PCA)的方式對數(shù)字經(jīng)濟的靶向路徑特征進行降維處理,其目的在于減少所考慮的隨機變量的數(shù)量。首先,構(gòu)建數(shù)字經(jīng)濟的靶向路徑特征數(shù)學(xué)表達式,設(shè)其目標(biāo)函數(shù)為C,則有公式(6)。

式中:a為針對數(shù)字經(jīng)濟的靶向路徑的影響因素個數(shù),a為實數(shù);bn為該因素在數(shù)字經(jīng)濟的靶向路徑特征權(quán)重中的占比;Cn為最大特征值;n為次數(shù),取值為1~n。
在得出數(shù)字經(jīng)濟的靶向路徑數(shù)學(xué)表達式后,采用基于多元線性回歸的TensorFlow 命名機制修正多重共線性,先將上面的多元線性回歸表達式轉(zhuǎn)換成對數(shù)表達式,則有公式(7)。
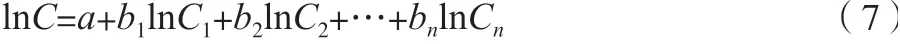
通過公式(7)改變表達式的自變量形式。其基本原理是以相關(guān)聯(lián)的自變量為基礎(chǔ)建立函數(shù)模型,從而達到降維的目的。假設(shè)最終維度降為N個,將上述80%的樣本數(shù)字經(jīng)濟的靶向路徑數(shù)據(jù)代入修正后的數(shù)字經(jīng)濟的靶向路徑特征表達式,回歸計算分析無關(guān)聯(lián)獨立影響因素的強度系數(shù)Ci(i=1~n),則有公式(8)。

通過公式(8),得出矩陣的無關(guān)聯(lián)獨立影響因素的強度系數(shù),將其作為數(shù)字經(jīng)濟的靶向路徑特征降維結(jié)果。
1.5 調(diào)整數(shù)字經(jīng)濟的靶向路徑模型參數(shù)
通過上述操作,完成對數(shù)字經(jīng)濟的靶向路徑數(shù)據(jù)的預(yù)處理。在該基礎(chǔ)上,調(diào)整數(shù)字經(jīng)濟的靶向路徑模型參數(shù),該參數(shù)分別為數(shù)字經(jīng)濟的靶向路徑常數(shù)誤差平方和以及極大似然估計值。在選取數(shù)字經(jīng)濟的靶向路徑模型指標(biāo)的基礎(chǔ)上,為了對常數(shù)誤差平方和、極大似然估計值2 個指標(biāo)進行精準(zhǔn)計算,該文采用最小二乘法,以誤差平方求和的方式計算數(shù)字經(jīng)濟的靶向路徑常數(shù)誤差平方和[9]。設(shè)數(shù)字經(jīng)濟的靶向路徑常數(shù)誤差平方和的計算表達式為E,如公式(9)所示。
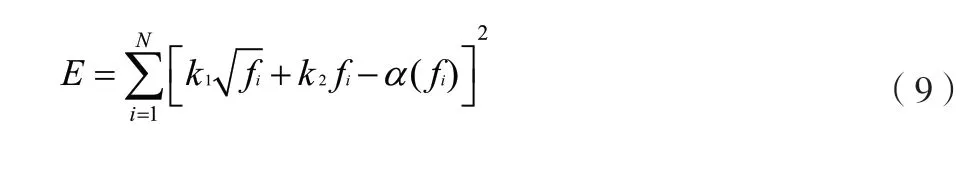
式中:N為數(shù)字經(jīng)濟的靶向路徑概率分布;k1為數(shù)字經(jīng)濟的靶向路徑數(shù)據(jù)高頻特征;fi為數(shù)字經(jīng)濟的靶向路徑數(shù)據(jù)更新頻率;k2為數(shù)字經(jīng)濟的靶向路徑數(shù)據(jù)低頻特征;α為網(wǎng)絡(luò)內(nèi)傳輸信號強度。
通過公式(9)可以計算出數(shù)字經(jīng)濟的靶向路徑數(shù)據(jù)常數(shù)誤差平方和。完成上述步驟后,根據(jù)最小二乘法中的二次函數(shù),求導(dǎo)計算數(shù)字經(jīng)濟的靶向路徑數(shù)據(jù)常數(shù)誤差平方和,如公式(10)所示。

式中:fi為數(shù)字經(jīng)濟的靶向路徑數(shù)據(jù)更新頻率;k1為數(shù)字經(jīng)濟的靶向路徑數(shù)據(jù)高頻特征;k2為數(shù)字經(jīng)濟的靶向路徑數(shù)據(jù)低頻特征。
基于最小二乘法對常數(shù)的相位常數(shù)進行計算,利用二次函數(shù)來擬合解空間,在函數(shù)中求極大似然估計值,優(yōu)化常數(shù)參數(shù)精度。在計算過程中,目標(biāo)函數(shù)與約束方程的關(guān)鍵參數(shù)均采用復(fù)雜的二次方程式進行擬合。設(shè)該目標(biāo)函數(shù)的表達式為z,則有公式(11)。

式中:γ為數(shù)字經(jīng)濟的靶向路徑正交特征;Y為數(shù)據(jù)量綱。
通過公式(11)計算出數(shù)字經(jīng)濟的靶向路徑極大似然估計值。根據(jù)計算得出的結(jié)果,調(diào)整數(shù)字經(jīng)濟的靶向路徑模型參數(shù)。
1.6 實現(xiàn)數(shù)字經(jīng)濟的靶向路徑模型建立
以上文計算調(diào)整后的數(shù)字經(jīng)濟的靶向路徑模型參數(shù)為依據(jù),通過上述公式建立數(shù)字經(jīng)濟的靶向路徑模型,得到目標(biāo)函數(shù)和約束函數(shù)的回歸方程,確定數(shù)字經(jīng)濟的靶向路徑參數(shù)中自變量和因變量之間的函數(shù)關(guān)系F(X),如公式(12)所示。

式中:β為數(shù)字經(jīng)濟的靶向路徑數(shù)據(jù)高頻時校正因子。
通過公式(12)計算出數(shù)字經(jīng)濟的靶向路徑模型,以此實現(xiàn)對數(shù)字經(jīng)濟的靶向路徑模型的設(shè)計。
2 實例分析
2.1 實驗準(zhǔn)備
為驗證所建立模型的科學(xué)性與準(zhǔn)確性,選擇某行業(yè)數(shù)字經(jīng)濟指數(shù)作為實驗對象進行實例分析。實例分析內(nèi)容為測試數(shù)字經(jīng)濟的靶向路徑模型建立方法的適用性。該實驗選用的測試工具為Loadrunner,忽略其他會對模型運行產(chǎn)生影響的外界因素。首先,使用該文的方法建立數(shù)字經(jīng)濟的靶向路徑模型,使用MATLAB 軟件測得該行業(yè)的數(shù)字經(jīng)濟數(shù)字化密度指數(shù),定義該組為實驗組。同時采用傳統(tǒng)的方法,建立數(shù)字經(jīng)濟的靶向路徑模型,同樣使用MATLAB 軟件測得該行業(yè)的數(shù)字經(jīng)濟數(shù)字化密度指數(shù),作為對照組。為了在同一環(huán)境下完成對比驗證,將多種變量參數(shù)設(shè)定為完全一致,避免其他因素對實驗結(jié)果的影響。共開展10 次實驗,將計算所得的數(shù)字化密度指數(shù)計入數(shù)據(jù)記錄表。數(shù)字化密度指數(shù)越高表示該模型性能越好,能夠為數(shù)字經(jīng)濟的靶向路徑選擇策提供真實的數(shù)據(jù)。
2.2 實驗結(jié)果分析與結(jié)論
記錄并整理計算結(jié)果,某行業(yè)的數(shù)字經(jīng)濟數(shù)字化密度指數(shù)對比結(jié)果見表1。
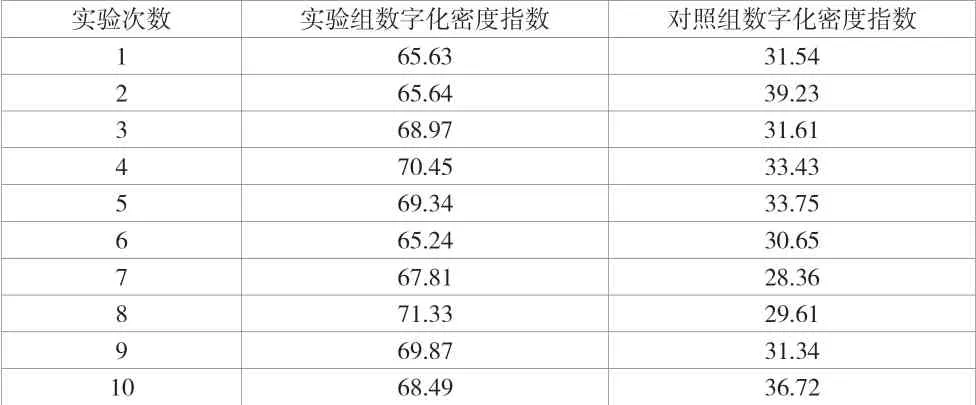
表1 數(shù)字化密度指數(shù)對比表
通過表1 可知,采用該文提出的設(shè)計方法建立的數(shù)字經(jīng)濟的靶向路徑模型數(shù)字化密度指數(shù)明顯高于對照組,證明設(shè)計模型更具實際應(yīng)用價值,值得被大力推廣。
3 結(jié)語
該文對數(shù)字經(jīng)濟的靶向路徑模型建立方法進行了研究,在完成對該文研究成果的分析后可知,數(shù)字經(jīng)濟的靶向路徑模型是一種較為復(fù)雜的模型結(jié)構(gòu),因此,需要采取數(shù)據(jù)預(yù)處理的方式提高建立模型的精度,并且在建立過程中,應(yīng)注意外界因素對數(shù)字經(jīng)濟的靶向路徑數(shù)據(jù)的干擾,避免模型因操作不當(dāng)而出現(xiàn)與實際不匹配的問題。在未來的研究中,可以以數(shù)字經(jīng)濟的靶向路徑發(fā)展為主要研究方向,結(jié)合當(dāng)下的國家政策,指明數(shù)字經(jīng)濟的靶向路徑主流方向。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
今日農(nóng)業(yè)(2022年14期)2022-09-15 01:44:56
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
民生周刊(2020年13期)2020-07-04 02:49:22
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
華人時刊(2018年23期)2018-03-21 06:26:00
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
