基于可變形卷積的改進YOLO 目標檢測算法
2021-10-15 10:08:42黃鳳琪馮國富
計算機工程 2021年10期
黃鳳琪,陳 明,馮國富
(上海海洋大學 信息學院,上海 201306)
0 概述
目標檢測需判斷圖像中目標的類別及不同目標的邊界框位置,是計算機視覺里的主要任務,被廣泛應用于視頻監(jiān)控[1-2]、行人檢測[3-4]等領域。傳統(tǒng)的目標檢測方法依賴人工選擇的特征進行計算,如HOG[5]、SIFT[6]、Haar[7]等,但計算復雜,運算速度慢,且對目標形變和背景復雜變化的圖像檢測魯棒性較差。而深度神經(jīng)網(wǎng)絡依賴其強大的特征提取和特征表示功能,被廣泛應用于目標檢測任務。
目前主流的目標檢測算法有以YOLO[8-10]系列算法、SSD[11-12]系列算法為代表的單階段算法和以R-CNN[13-14]系列算法為代表的兩階段算法。單階段算法將目標檢測過程看作回歸問題來處理,使用一個統(tǒng)一的深度神經(jīng)網(wǎng)絡進行特征提取和目標分類及邊界框回歸,實現(xiàn)了端到端的推理,具有較快的檢測速度,但檢測精度沒有兩階段算法高;而兩階段目標檢測算法先使用區(qū)域建議網(wǎng)絡(Region Proposal Network,RPN)提取出感興趣區(qū)域,即含有目標的區(qū)域,再用深度神經(jīng)網(wǎng)絡對感興趣區(qū)域進行分類及邊界框回歸,具有更高的檢測精度,但其檢測速度太慢,達不到實時的要求。
目前對目標檢測算法的改進方法主要包括:使用更復雜更深層的骨干網(wǎng)絡,以提取更有效的特征;融合多尺度特征,使淺層特征傳遞到深層,從而提高定位精度;加入新型網(wǎng)絡模塊,以增強網(wǎng)絡的特征提取能力等。FU 等[12]提出在SSD 檢測框架的基礎上,采用更深的ResNet-101 網(wǎng)絡來進行特征提取,并且采用了反卷積層,引入額外的大量語義信息,改進了SSD算法對于小物體的檢測能力,但使用更深的基礎網(wǎng)絡和反卷積層,增加了大量的計算,使得檢測速度大幅降低,無法滿足實時的要求。JIANG 等[15]通過在SSD網(wǎng)絡中引入空洞卷積,擴大特征點的感受野,優(yōu)化網(wǎng)絡的特征提取能力,從而提高了網(wǎng)絡的檢測精度,但增加了模型的復雜度,導致檢測速度的降低。XU等[16]提出在YOLO 算法中引入注意力機制和改進的特征融合方法,以提高網(wǎng)絡的定位精度,形成了Attention-YOLO 算法,但檢測速度較慢。
以上研究從不同角度提升了目標檢測算法的性能。但單純地使用反卷積或空洞卷積等操作,擴大了特征點的感受野,可能增加背景區(qū)域?qū)μ卣鼽c信息的影響,導致目標定位不準或把背景誤檢為目標。對不同尺寸和形狀的目標自適應地提取感受野,可以有效地避免這個問題。DAI 等[17-18]提出了可變形卷積(Deformable Convolution),通過在常規(guī)卷積操作上增加平行網(wǎng)絡預測常規(guī)卷積采樣點的偏移,使得每個采樣點都具有一定的偏移量,可以學習到自適應的感受野,從而提高網(wǎng)絡對不同尺寸和形狀的物體進行特征提取的能力。
本文在YOLO 算法的基礎上,提出基于可變形卷積的改進dcn-YOLO 算法。通過構(gòu)建殘差可變形卷積模塊res-dcn,并將其嵌入YOLO 特征提取頭模塊和替換YOLO 特征提取層,形成兩種改進的dcn-YOLO 模型,使網(wǎng)絡能夠自適應地學習不同尺寸和形變目標的特征,提高目標檢測的精度。
1 YOLO 算法
YOLO 是一個端到端的深度神經(jīng)網(wǎng)絡模型,其網(wǎng)絡結(jié)構(gòu)如圖1 所示,主要由Darknet53 主干網(wǎng)絡、3 個FPN[20]多尺度特征提取頭加上3 個YOLO 多尺度檢測層組成,其中所有卷積模塊都由卷積層、Batch Normalization(BN)層和leaky 激活層組成。Residual為殘差模塊,將上一模塊的輸入累加到當前層,以實現(xiàn)淺層特征向深層的傳遞,提高定位精度。整個特征提取網(wǎng)絡由常規(guī)卷積層組成,使用3×3 的卷積核進行特征提取,采用1×1 的卷積核進行通道數(shù)壓縮,動用步長為2 的卷積層來減小特征圖分辨率,替代池化操作。
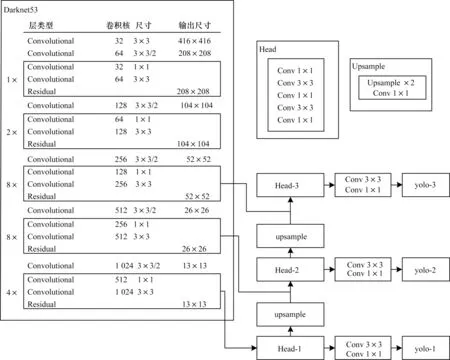
圖1 YOLO 網(wǎng)絡結(jié)構(gòu)Fig.1 Network structure of YOLO
YOLO 的核心思想是利用整個圖像作為網(wǎng)絡的輸入,將其分成S×S個網(wǎng)格,如果某個目標的中心落在這個網(wǎng)格中,則該網(wǎng)格就負責檢測這個目標,如圖2所示。每個網(wǎng)格檢測B個目標,每個目標需要預測邊界框坐標(x,y,w,h),其中(x,y)為目標邊界框中心坐標,(w,h)為邊界框的寬和高;一個置信度得分(該位置有目標的置信度)和C個類別得分(該目標屬于某類的概率),所以YOLO 檢測層輸出張量大小是S×S×B×(4+1+C)。以輸入圖像尺寸為416 像素×416 像素和VOC 數(shù)據(jù)集為例,3個多尺度YOLO檢測層尺寸分為13×13×75,26×26×75,52×52×75,分別負責對大、中、小型目標進行檢測,提高了YOLO 的檢測性能。

圖2 YOLO 的檢測過程Fig.2 Detection process of YOLO
雖然YOLO 使用了FPN 結(jié)構(gòu)進行多尺度檢測,有效提高了對目標的檢測能力,但同一特征圖上的特征點具有相同的感受野,對形變較大的目標提取的特征容易受到背景區(qū)域的干擾,導致檢測邊界框定位不準,同時背景干擾也會導致小目標檢測精度不高。
2 改進的dcn-YOLO 模型
卷積網(wǎng)絡對大尺寸多形變目標的建模存在固有的缺陷,這是因為卷積網(wǎng)絡只對輸入特征圖的固定位置進行采樣[21]。例如,在同一層特征圖中,所有的特征點的感受野是一樣的,但由于不同位置可能對應著不同尺度或變形的物體,因此能夠?qū)Τ叨然蛘吒惺芤按笮∵M行自適應學習精確定位的目標。
可變形卷積可以提高模型對形變目標的建模能力,使用平行卷積層學習offset 偏移,使得卷積核在輸入特征圖上的采樣點發(fā)生偏移,可集中于人們感興趣的區(qū)域或者目標。即對卷積核中每個采樣點的位置都增加了偏移量,可以實現(xiàn)在當前位置附近隨意采樣而不局限于常規(guī)卷積的規(guī)則采樣點。如圖3所示為常規(guī)卷積的采樣點和可變形卷積采樣點的對比。圖4 所示為可變形卷積的計算流程,使用卷積層對輸入特征圖計算偏移量,偏移量和輸出特征圖有相同的分辨率,輸出通道數(shù)為3N(N為卷積核采樣點個數(shù)),其中2N為預測的x、y方向偏移量,因為不同采樣點對特征有不同的貢獻,所以還要預測N個采樣點的權(quán)重。
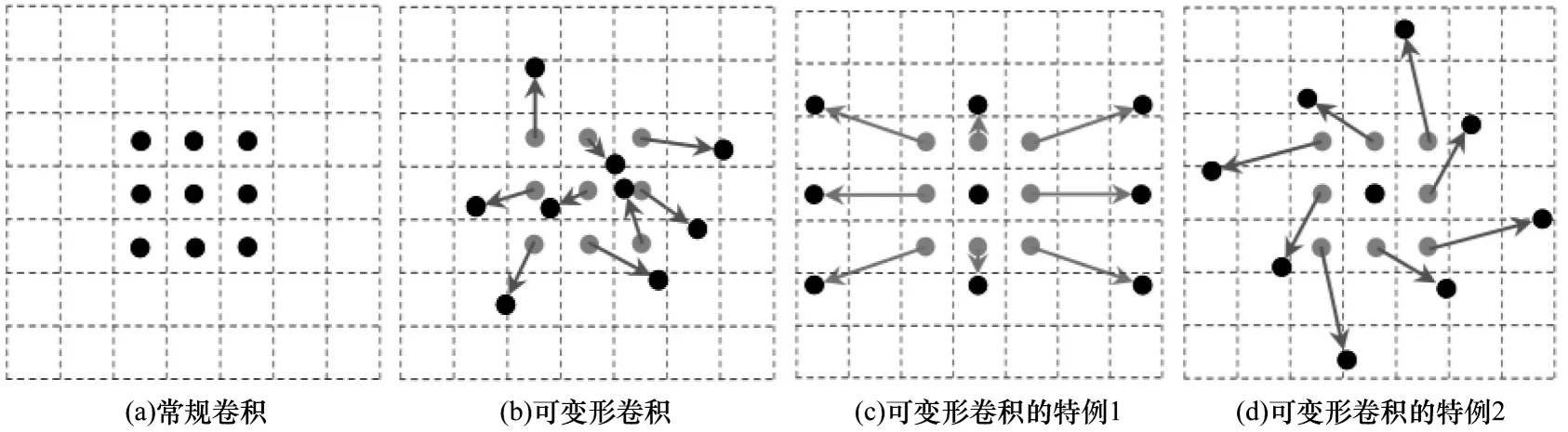
圖3 常規(guī)3×3 卷積和可變形卷積采樣點對比Fig.3 Comparison of sampling points between conventional 3×3 convolution and deformable convolution
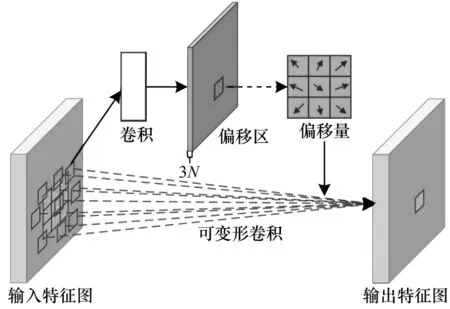
圖4 可變形卷積的計算流程Fig.4 Computational procedure of deformable convolution
常規(guī)的卷積操作主要分為2 步:1)在輸入的特征圖上使用規(guī)則網(wǎng)格R進行采樣;2)使用卷積核w對采樣點進行加權(quán)運算。R定義了感受野的大小和擴張,如式(1)所示定義了一個大小為3×3、擴張率為1 的卷積核。

對于在輸出的特征圖上的每個位置p0,通過式(2)計算輸出值y(p0):
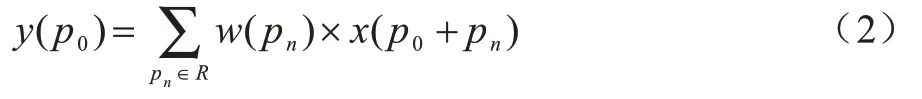
其中:pn是對R中所列位置的枚舉。
在可變形卷積的操作中,通過對規(guī)則網(wǎng)格R增加一個偏移量{Δpn|n=1,2,…,N},N=|R|進行擴張,同時對每個采樣點預測一個權(quán)重Δmn。那么同樣的位置p0的值y(p0)變?yōu)槿缡剑?)所示:
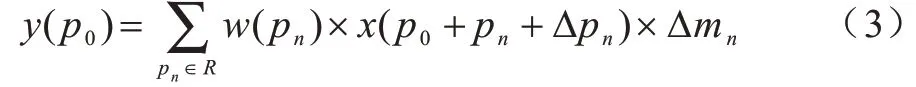
由于偏移量Δpn通常是小數(shù),因此需要通過雙線性插值法計算x的值,如式(4)~式(6)所示:
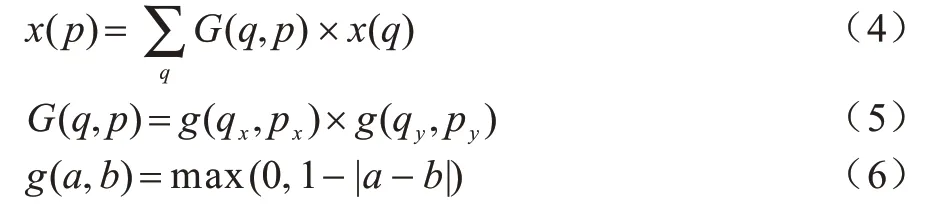
圖5 所示為常規(guī)卷積和可變形卷積的特征點感受野之間的對比。2 個特征點(分別在大羊和小羊身上)代表不同尺度和形狀的目標。對比可知,通過兩層卷積運算,常規(guī)卷積的特征點都具有固定尺寸的感受野,而可變形卷積可自適應的學習感受野的采樣位置更符合物體本身的形狀和尺寸,更有利于特征提取。
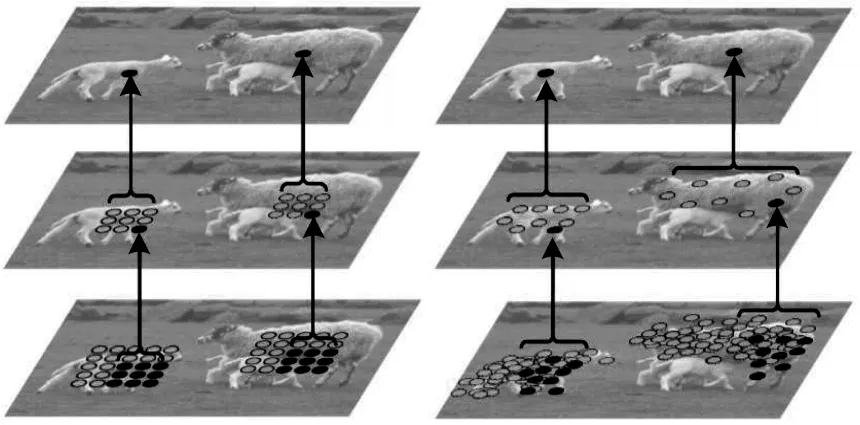
圖5 常規(guī)卷積和可變形卷積的特征點感受野對比Fig.5 Comparison of receptive fields between conventional convolution and deformable convolution
本文基于可變形卷積構(gòu)建res-dcn 模塊,在常規(guī)的卷積網(wǎng)絡中,首先使用3×3 的卷積進行特征提取,然后使用1×1 的卷積進行特征壓縮。對于可變形卷積來說,使用1×1 的可變形卷積對采樣點計算偏移容易導致采樣不穩(wěn)定,因此,本文的res-dcn 模塊連續(xù)使用3 個3×3 的可變形卷積進行特征提取。最后再將輸出和輸入按通道數(shù)進行拼接,以保留多層次的語義信息。如圖6 所示,Deform able conv 是由1 個可變形卷積、1 個BN 層和1 個leaky 激活層組成。其中,concat 為按通道數(shù)拼接。
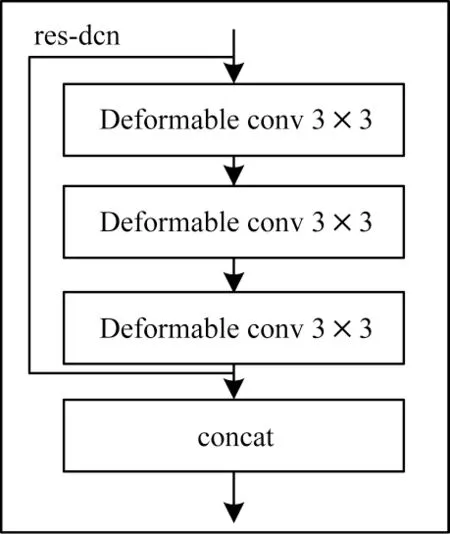
圖6 res-dcn 模塊結(jié)構(gòu)Fig.6 Module structure of res-dcn
本文設計了2 種改進的dcn-YOLO 模型,第1 種是在第1 個YOLO 特征提取頭部嵌入res-dcn 模塊,第2 種是將YOLO 網(wǎng)絡中3 個特征提取頭的卷積模塊替換為res-dcn,以實現(xiàn)對各個尺度都能更好的自適應提取特征。如圖7 所示,該設計參考了YOLO-spp[22]的網(wǎng)絡結(jié)構(gòu)。YOLO-spp 將YOLO 網(wǎng)絡中的Head-1 特征提取頭替換為YOLO-spp Head-1,使用1×1,5×5,9×9,13×13 的最大池化層,提取不同尺寸感受野的特征,再將特征按通道數(shù)進行拼接以融合多尺度的特征,提高了YOLO 的檢測性能。由此可知,YOLO 網(wǎng)絡中Head 特征提取頭模塊具有豐富的語義信息。
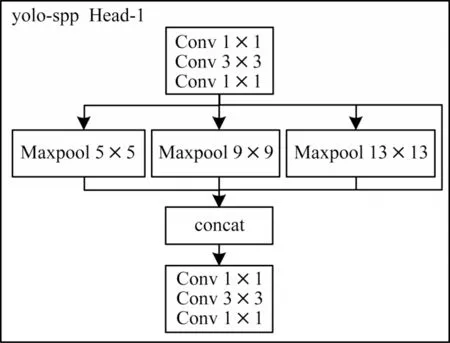
圖7 YOLO-spp Head-1 模塊結(jié)構(gòu)Fig.7 Module structure of YOLO-spp Head-1
本文先將dcn-YOLO1 模型在Head-1 的第2 卷積層后使用1×1 的常規(guī)卷積壓縮特征通道數(shù)到512以減少計算量;然后將res-dcn 模塊嵌入該卷積層后進行特征提取,3 個可變形卷積通道數(shù)均為512,網(wǎng)絡中其他結(jié)構(gòu)和YOLO 保持一致;而dcn-YOLO2 則將res-dcn 模塊替換YOLO 中所有Head 特征提取頭的第2、3、4 卷積層,以實現(xiàn)對大、中、小目標分別自適應提取特征。每個res-dcn 模塊中可變形卷積的通道數(shù)分別為512、256、128,網(wǎng)絡中其他結(jié)構(gòu)和YOLO保持一致,如圖8 和圖9 所示。

圖8 dcn-YOLO1 Head-1 模塊結(jié)構(gòu)Fig.8 Module structure of dcn-YOLO1 Head-1

圖9 dcn-YOLO2 Head 模塊結(jié)構(gòu)Fig.9 Module structure of dcn-YOLO2 Head
3 實驗結(jié)果與分析
本文所用到的實驗平臺是Intel酷睿i79700KCPU,64 GB 內(nèi)存,NVIDIARTX2080Ti11GBGPU,軟件環(huán)境是ubuntu18.04,pytorch1.3,cuda10.0,cudnn7.5。本文實驗使用pascalvoc2007 和voc2012 公開數(shù)據(jù)集,共有20 類目標;使用voc2007trainval和voc2012trainval作為訓練集,共有16 551 張圖像;使用voc2007test作為測試集,共有4 952 張圖像;使用平均精度(mAP)和檢測速度(FPS)來檢驗模型的有效性。
3.1 錨盒計算
YOLO 使用錨盒作為先驗框輔助預測目標邊界,尺寸合適的錨盒可以使目標檢測精度提高。為了獲得平均交并比(avg-iou)更大的錨盒,本文使用k-means++算法進行錨盒計算,使用(1-iou)作為聚類距離。算法流程如下:
算法1k-means++聚類錨盒算法
輸入訓練集所有目標的寬高集合S,聚類中心數(shù)K
輸出K組錨盒
步驟1從S中隨機取一個值作為初始聚類中心C1
步驟2計算S中所有樣本與已有聚類中心的最小iou 距離d(x),概率計算公式如式(7)所示,并選取下一個聚類中心Ci。

步驟3重復步驟2 直到找到K個聚類中心。
步驟4對數(shù)據(jù)集中的每個樣本xi,計算其到K個聚類中心的iou 距離,并將其劃分為距離最小的聚類中心所對應的類別。
步驟5根據(jù)劃分結(jié)果重新計算K個聚類中心,計算式如式(8)所示:

步驟6重復步驟4 和步驟5,直到聚類中心位置不再變化,輸出最終的聚類中心。
經(jīng)過聚類,得到了9 組錨盒{(28,55),(65,80),(66,179),(145,114),(116,273),(187,196),(334,200),(215,333),(362,360)},avg-iou 值為68.26%,比YOLO 默認的錨盒提高了4.10%。
3.2 網(wǎng)絡訓練
為了進行充分的對比實驗,分別對YOLO 模型、計算新錨盒后的YOLO 模型、YOLO-spp 模型和本文提出的dcn-YOLO1、dcn-YOLO2 模型進行訓練,并將YOLO 網(wǎng)絡中所有常規(guī)卷積層簡單替換為可變形卷積,形成all-dcn-YOLO 模型,以對比可變形卷積的特征提取能力。設置訓練迭代50 200 輪次,批量大小為8,動量為0.9,衰減系數(shù)為0.000 5,學習率更新策略見表1。使用隨機水平翻轉(zhuǎn)、裁剪、調(diào)整曝光飽和度等數(shù)據(jù)增強操作。每迭代10 輪次后,隨機調(diào)整輸入圖像尺寸(從320 像素×320 像素到608 像素×608 像素,以32 的倍數(shù)變化)。
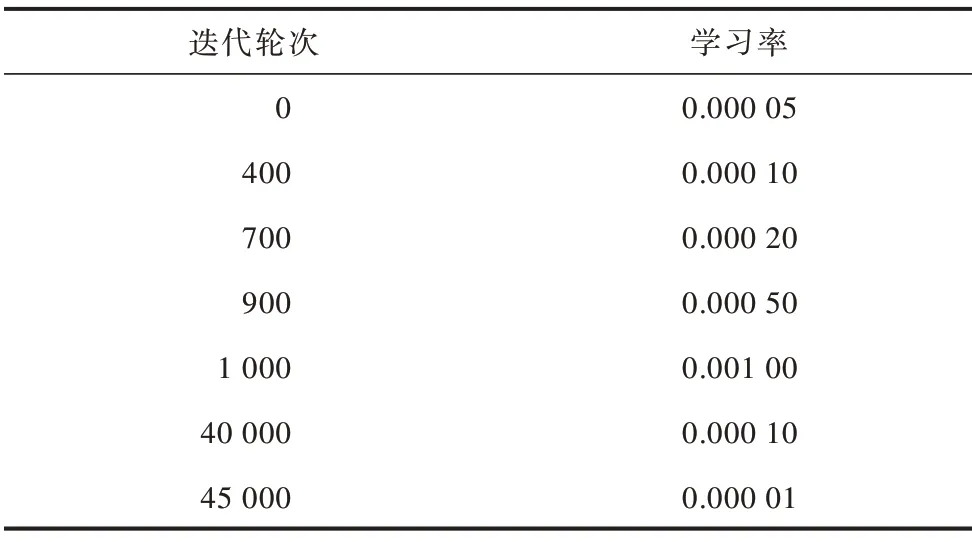
表1 學習率更新策略Table 1 Learning rate update strategy
3.3 縱向?qū)Ρ葘嶒?/h3>
訓練完成后,使用voc2007test 數(shù)據(jù)集進行對比測試,將輸入的圖像尺寸縮放為416 像素×416 像素,對比結(jié)果見表2。
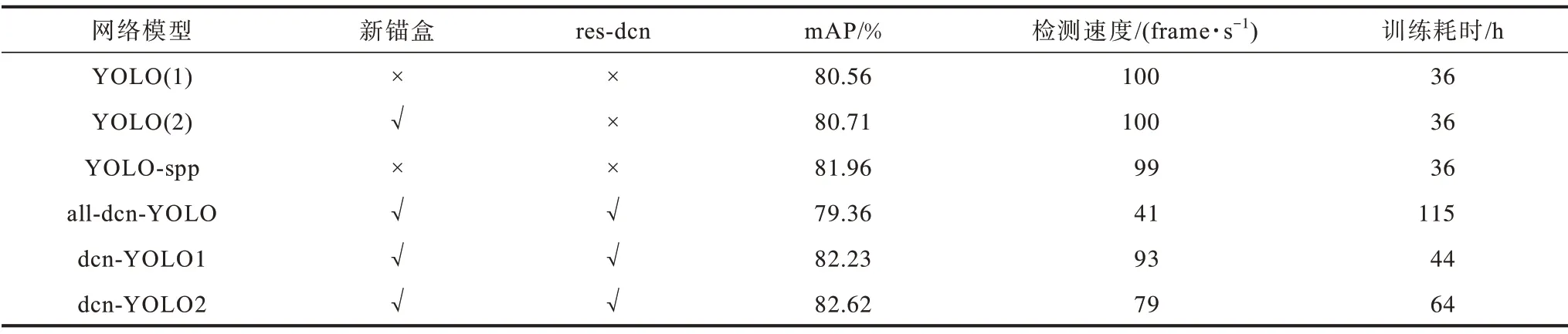
表2 各YOLO 模型縱向?qū)Ρ葘嶒濼able 2 Longitudinal contrast experiment of YOLO models
從表2 可以看出,使用k-means++聚類的錨盒獲得了更高的avg-iou,mAP 有略微提升。dcn-YOLO1和dcn-YOLO2 的mAP 相比原始YOLO 算法分別提高了1.67、2.06 個百分點,這是因為本文添加的resdcn 模塊可以對不同尺寸和形狀的目標自適應提取有效特征。雖然dcn-YOLO1 和dcn-YOLO2 的FPS有一定降低,但仍然能達到實時的效果。此外也可以看出簡單地將所有常規(guī)卷積替換為可變形卷積,并不能提高模型的檢測效果。相反,由于dcn 需要使用一個額外的卷積操作預測采樣點的偏移量,在前向計算和反向傳播的過程中,與標準卷積相比都增加了計算量,因此訓練時間和檢測時間大大增加,而檢測精度卻沒有提升。這也證明了本文提出的resdcn 模型有效性,即在損失少量計算速度的前提下,有效地提高了檢測精度。
表3 列出了各個模型對不同類別的mAP 值,其中加粗部分為各對比模型中獲得較高mAP 的項。從表3 可以看出,本文提出的模型與原YOLO 模型相比,18 種類別的目標檢測精度均有一定提高,尤其是bird 和pottedplant 等小目標分別比YOLO 高出了4.59、3.70 個百分點。同時,對boat 和cow 等尺寸和形狀變化較大的目標,精度分別提高了4.16、3.16 個百分點。雖然有些類別對YOLO-spp 有更高的精度,但提出的模型只略低一點。總體來看,本文提出的算法仍然達到了最高的mAP。
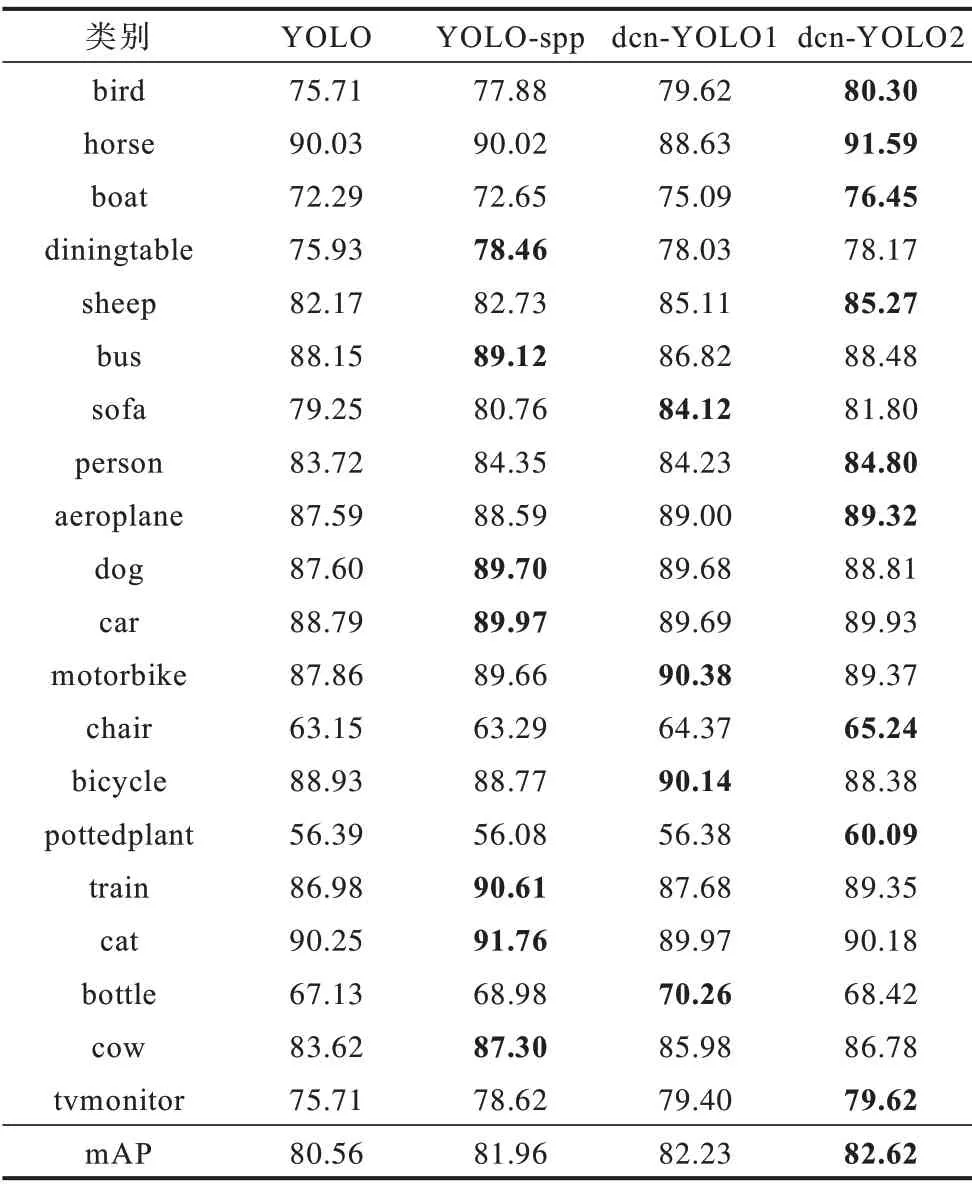
表3 各模型對不同類別的AP 對比Table 3 Comparison of AP of different models for different categories %
圖10 所示為YOLO 和dcn-YOLO 的檢測效果,在第1 行中,dcn-YOLO 預測出了bird 更精確的邊界框。由于翅膀所占的像素較少,特征不明顯,YOLO提取了更多的背景干擾特征,導致定位精度不高。而dcn-YOLO 可以自適應地提取到鳥翅膀的特征,所以定位效果更好。在第2 行中,YOLO 將2 個靠近的船只檢測為了1 只船,而dcn-YOLO 很好地區(qū)分出了2 只船;在第3 行中,dcn-YOLO 準確地檢測出了左上角遠處模糊的車輛,也得益于其良好的特征提取能力;第4 行中由于小目標特征不明顯,YOLO 漏檢了很多的小船只,而與之相比,dcn-YOLO 檢測出了更多的目標,取得了更好的檢測效果。

圖10 YOLO 和dcn-YOLO 的檢測效果對比Fig.10 Comparison of detection effect between YOLO and dcn-YOLO
3.4 橫向?qū)Ρ葘嶒?/h3>
將提出的模型和目前性能優(yōu)異的目標檢測算法進行了對比,結(jié)果見表4。可以看到dcn-YOLO與YOLO-spp 和Attention-YOLO 相比,mAP 分別高出了0.64、0.70 個百分點,而且檢測速度遠遠超過了Attention-YOLO;與單階段目標檢測算法SSD 和DSSD 相 比,dcn-YOLO 算法的mAP 分別高出了5.20、4.00 個百分點,且檢測速度遠遠超過DSSD,達到實時效果;與兩階段檢測算法FasterR-CNN 和R-FCN 相 比,dcn-YOLO 算法的mAP 分別高出了9.40、2.10 個百分點。
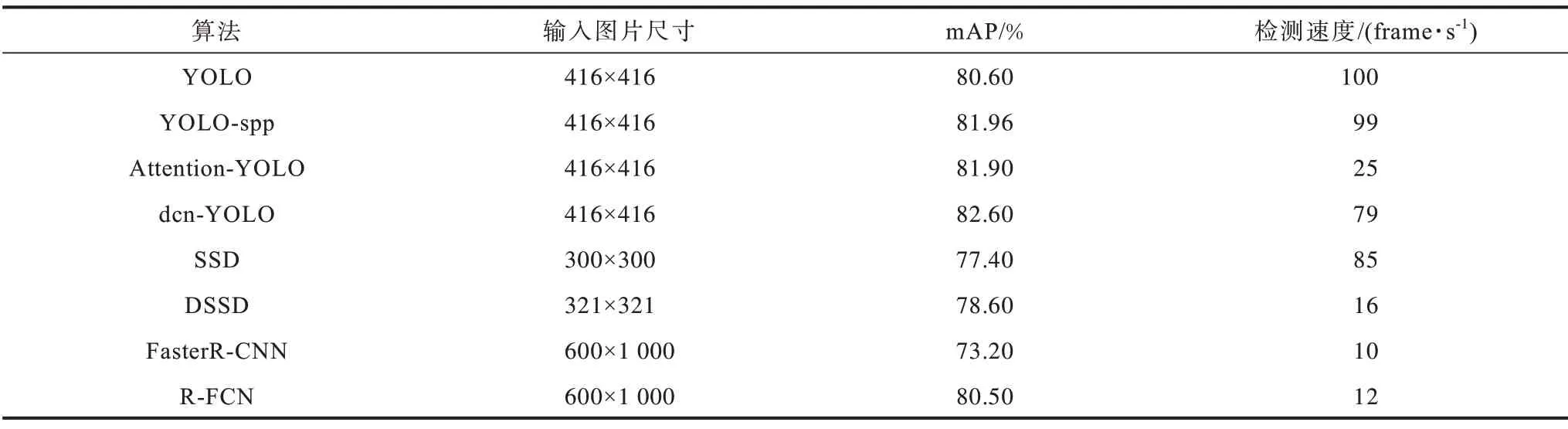
表4 dcn-YOLO 與其他目標檢測算法性能對比Table 4 Performance comparison between dcn-YOLO and other object detection algorithms
4 結(jié)束語
為提高YOLO 算法的檢測精度,本文基于可變形卷積構(gòu)建res-dcn 模塊,使用k-means++聚類出符合數(shù)據(jù)集尺寸的錨盒,將res-dcn模塊分別嵌入和替換YOLO特征提取頭,最終得到改進的dcn-YOLO模型。在VOC數(shù)據(jù)集上的實驗結(jié)果表明,該模型相比原YOLO 算法以及其他主流的目標檢測算法,都獲得了更好的效果,證明了本文提出模型的有效性。但由于可變形卷積需要更多的計算量,導致模型的運算速度有一定下降,下一步將構(gòu)建更好的模型,以保證在不降低網(wǎng)絡計算速度的前提下,達到更高的檢測精度。
猜你喜歡
中華詩詞(2020年1期)2020-09-21 09:24:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
小學生作文(中高年級適用)(2018年5期)2018-06-11 01:22:56
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中學生數(shù)理化·七年級數(shù)學人教版(2017年11期)2017-04-23 07:18:00
中國生物醫(yī)學工程學報(2017年6期)2017-02-10 05:11:45
數(shù)學大王·中高年級(2016年12期)2016-12-26 21:37:36
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
