基于光譜變換與SPA-SVR的玉米SPAD值高光譜估測
2021-10-15 07:19:38常慶瑞崔小濤張佑銘蔣丹垚落莉莉
東北農業大學學報 2021年8期
關鍵詞:模型
郭 松,常慶瑞,崔小濤,張佑銘,陳 倩,蔣丹垚,落莉莉
(西北農林科技大學資源環境學院,陜西 楊凌 712100)
葉綠素含量為植被生長和營養脅迫等研究常用指示量,可反映植被初級生產力和生長狀態[1-2]。分光光度法、熒光分析法等傳統葉綠素含量檢測方法不僅流程復雜、誤差大、耗時長,且對植被本身損害較大,不利于大樣本下葉綠素含量監測[3]。近年來,高光譜遙感技術以其數據蘊含較高維度信息的特點被應用到植被葉綠素含量估測研究中,為簡便迅速、大范圍測量植被葉綠素含量提供技術支持[4]。
目前,國內外在高光譜估算植被葉綠素方面開展大量研究,Bannari等使用Hyperion EO-1傳感器獲取地面和實驗室高光譜數據,構建多個光譜葉綠素植被指數反演冠層尺度上小麥葉綠素a含量,模型決定系數達0.69[5];Ali等發現基于高光譜反射率提取的紅邊位置(REP)可準確估計植被葉綠素含量,通過紅邊位置建立的模型決定系數為0.90~0.93[6];Yamashita等利用機器學習算法和綠茶葉綠素高光譜敏感波段建立可較好的葉綠素反演模型,預測偏差1.4~2.0[7];陳瀾等創建多個關中地區獼猴桃PCA-RF模型,決定系數最高達0.98[8];袁小康等對比不同灌溉條件下夏玉米高光譜特征變化,發現植被指數與葉綠素含量相關性較高,相關系數最小絕對值為0.812[9];陳春玲等為準確檢測玉米葉片葉綠素含量,采用蟻群算法優化BP神經網絡模型,結果表明,優化后神經網絡模型建模和驗證決定系數較未優化時分別提高0.073與0.078[10]。綜上,利用高光譜遙感技術檢測作物葉綠素含量的研究較成熟,但光譜變換可對光譜空間坐標作數學轉換,突出原有光譜特點,同時消除光譜噪聲[11],大部分研究依賴于作物原始光譜構建模型,較少探索光譜變換后的建模效果;連續投影算法為一種以矢量空間共線性最小為原則篩選變量的方法[12],目前大多基于主成分分析或偏最小二乘實現高光譜數據降維,而使用連續投影算法的報道較少。
本研究以陜西省關中地區玉米為研究對象,通過玉米原始光譜及其變換光譜,構建基于特征波段和植被指數的一元回歸模型、基于連續投影算法的多元線性回歸模型和支持向量回歸模型,探究玉米葉綠素含量最優估算模型,旨在為實時獲取關中地區玉米生長信息提供技術和理論支持。
1 材料與方法
1.1 研究區概況與實驗設計
研究區位于陜西省咸陽市乾縣齊南村(108°07′04″E,34°38′32″N)(見圖1),地處關中平原與渭北旱塬過渡地帶,地貌類型為黃土臺塬,平均海拔1 000 m;屬暖溫帶半干旱大陸性季風氣候,年均氣溫10.8℃,年均降水量560~600 mm,多集中在6~8月;試驗區內土壤類型為紅油土,持水保肥,適宜耕作;作物一年一熟,主要為小麥和玉米。試驗于2020年6月1日開展,供試作物為“陜單2001”玉米,共設30個小區和1個大田(空白對照),小區面積72 m2(9 m×8 m),大田面積286 m2(11 m×26 m),施用氮、磷、鉀3種肥料,每種肥料分5個施肥水平,共15個處理,每個處理重復兩次,其中氮肥處理純N施用量分別為:0、60、120、180、240 kg·hm-2;磷肥處理P2O5施用量分別為0、40、80、120、150 kg·hm-2;鉀肥處理K2O施用量分別為0、30、60、90、120 kg·hm-2。在播種前一次性施入所有肥料,不追肥,與當地田間管理一致。試驗樣品采集于玉米抽雄期,每個小區與大田設兩個采樣點,每個采樣點采集3片生長狀態良好的玉米冠層葉片,葉片裝入塑封袋并排盡空氣,迅速保置于冰袋恒溫箱,當天在室內測定葉片葉綠素含量與高光譜信息。
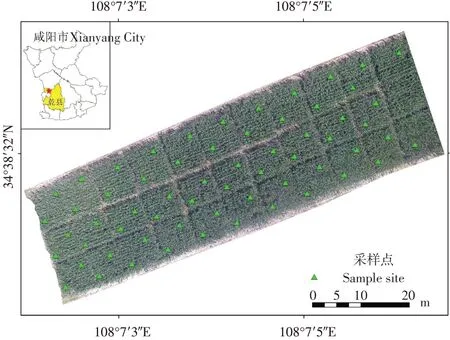
圖1 研究區玉米試驗田位置Fig.1 Location of maize test field in the study area
1.2 項目測定與方法
1.2.1 葉片SPAD值測定
玉米葉片葉綠素含量測定使用SPAD-502(柯尼卡美可達公司,日本)手持式葉綠素儀測定,用SPAD值表示[13]。測量時用紙巾輕輕擦凈葉片表面灰塵并按順序放置,在每片葉子尖、中、基3個部位分別測定4個SPAD值,測量時避開葉脈,每個樣點3片葉子共獲取36個SPAD值,取其平均值作為該樣點最終SPAD值。
1.2.2 葉片光譜反射率測定
采用SVC HR-1024i(Spectrum Vista公司,美國)便攜式地物光譜儀測定葉片光譜反射率。該儀器使用內置鎢燈作為光源,光譜范圍為350~2 500 nm,光譜分辨率在350~1 000、1 000~1 850、1 850~2 500 nm分別為3.5、9.5及6.5 nm。為確保數據科學可靠,自測量開始到結束,每0.5 h作一次白板校正。每片葉子在葉尖、葉中和葉基3個部位(與SPAD值測定位置相對應)分別測定兩條光譜曲線,每個樣點三3片葉子共獲取18條光譜曲線。
1.3 數據處理與分析
對抽雄期玉米各樣點SPAD值排序并按照3:1比例分層抽樣,得到建模樣本47個,預測樣本15個。健康植被光譜響應波段主要集中在可見光-近紅外[14],因此,將葉片光譜曲線重采樣至400~1 000 nm,光譜間隔1 nm;每個樣點獲取18條玉米葉片光譜曲線,取平均作為該樣點代表光譜曲線,通過Savitzky-Golay二階平滑以減小光譜獲取過程中產生的隨機噪聲;最后對代表光譜開展4種變換,分別為普通一階導數變換[15]、間隙一階導數變換[16]、連續統去除變換[17]和開平方根變換[18]。
1.4 模型建立
選取4種物理意義較為明確的植被指數(見表1)及各類型光譜特征波段(與SPAD值相關性最高波段)作為單因素模型建模參數,單因素模型包括指數、對數和冪函數回歸模型;通過連續投影算法(Successive projections algorithm,SPA)獲取各類型光譜多因素模型建模參數,分別建立基于SPA的多元線性回歸(Multiple linear regression,MLR)模型和支持向量回歸(Support vector regression,SVR)模型。比較各模型的反演精度,篩選出最佳反演模型。模型建立在MATLAB 2016a中實現。

表1 植被指數計算方式Table 1 Calculation method of vegetation index
采用決定系數(R2)、均方根誤差(RMSE)及平均相對誤差(MRE)3個指標評價模型精度,決定系數越接近1,均方根誤差和相對誤差越小,評價模型質量越優。RMSE與MRE使用公式如下。
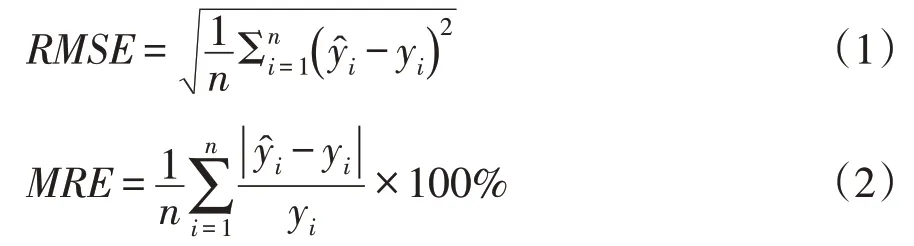
2 結果與分析
2.1 玉米葉片高光譜特征分析
選取樣本中SPAD最小值、最大值及中位數,分析不同SPAD值下玉米光譜變化特征,如圖2所示。
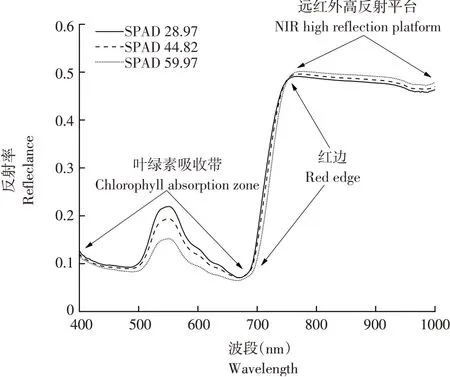
圖2 不同SPAD值玉米高光譜特征Fig.2 Hyperspectrum characteristics of maize with different SPAD values
不同SPAD值含量樣本光譜曲線變化趨勢一致,玉米葉綠素吸收藍光與紅光,反射綠光的特性,導致其在可見光波段400~520 nm及600~750 nm處分別形成兩個吸收谷,其最低反射率分別為0.09和0.07,在520~600 nm形成一個弱反射峰,最高反射率為0.22;在680~780 nm處由葉綠素紅光吸收過渡到葉片細胞結構對近紅外的強烈散射、反射,產生“紅邊”;進而在780~1 000 nm處形成近紅外高反射平臺,該平臺各波段反射率均在0.45以上。隨葉綠素含量增加,葉片對光的利用效率增加,在400~680 nm處反射率隨SPAD值上升而下降,“紅邊”向長波方向移動;同時葉綠素增加標志葉片成熟度越高、內部細胞結構越穩定,因此高反射平臺會隨SPAD值增加而上升。
2.2 不同類型光譜與SPAD值相關性分析
2.2.1 光譜反射率與SPAD值相關性
各類型光譜反射率與SPAD值相關性如圖3所示。由此可知,原始光譜與開平方根光譜相關性曲線變化趨勢一致,二者通過0.01相關性檢驗的敏感波段數量分別為298、303個,均集中分布在451~745 nm,相應特征波段位于709、708 nm,相關系數分別為-0.852和-0.853;普通一階導數與間隙一階導數相關性曲線走勢也同樣類似,二者敏感波段數量分別為335和358個,均集中在477~550、552~670、670~713及717~861 nm,特征波段各自位于756和764 nm,二者相關系數分別為0.906與0.907;450~758、765~810、842~896 nm為連續統去除光譜的敏感波段區域,其敏感波段數量達400個,特征波段在746 nm處,相關系數為-0.893。在與SPAD值相關性方面,各變換光譜敏感波段數量多于原始光譜,且不同變換光譜特征波段相關系數絕對值均大于原始光譜,說明光譜變換可有效消除噪聲,提高數據反演SPAD值潛力。
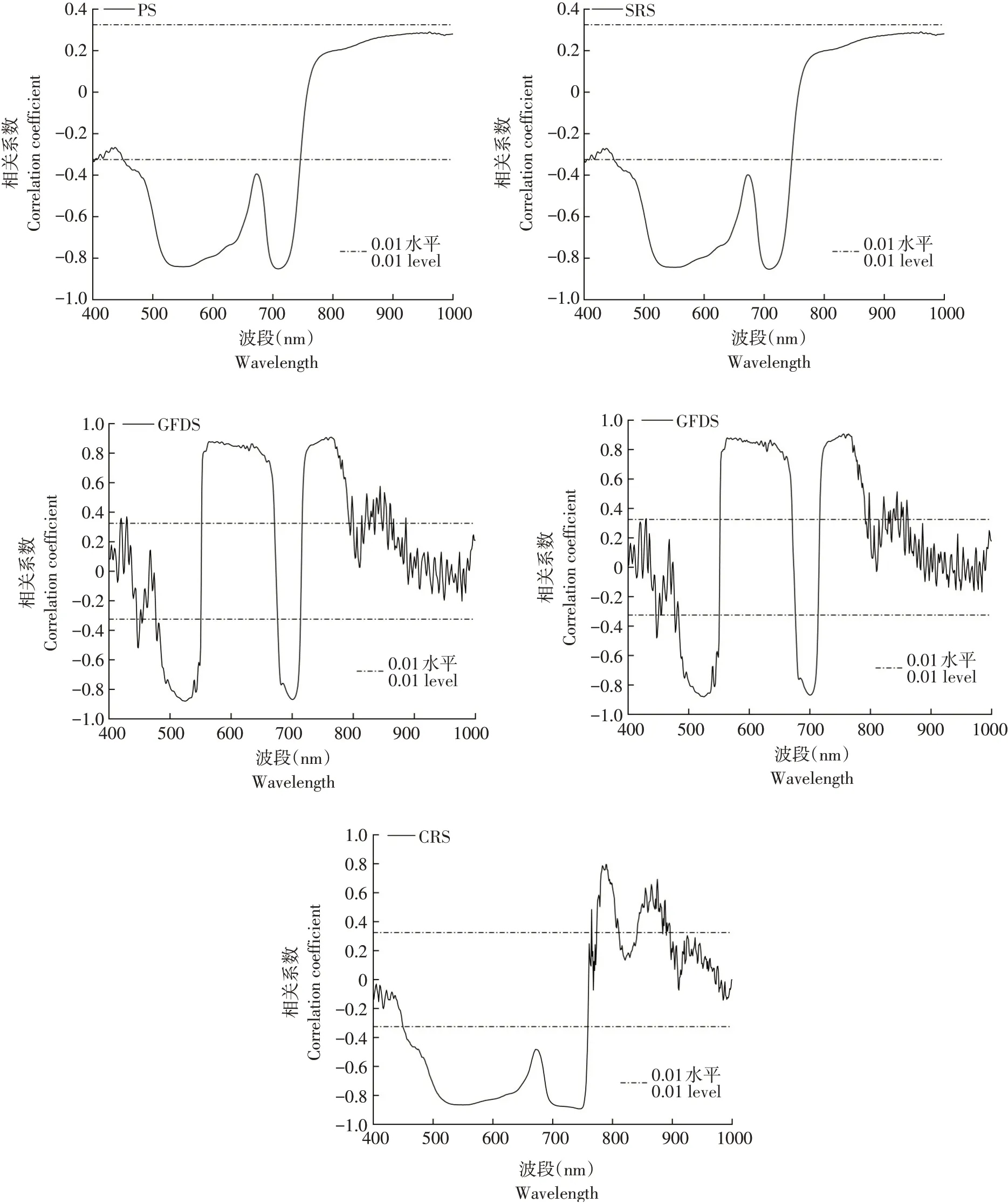
圖3 不同類型光譜反射率與SPAD值相關性Fig.3 Correlation between different types of spectrum reflectance and SPAD values
2.2.2植被指數與SPAD值相關性
根據表1構建不同類型光譜植被指數,分別計算其與SPAD值相關性(見表2),由此可知,同一植被指數在不同類型光譜中反演SPAD值潛力不同,其中mNDVI和RVI最穩定,相關系數變化范圍 分 別為0.777~0.883、0.863~0.874;而NDVI與MCARI在普通一階導數及間隙一階導數變化下相關性較差,相關系數絕對值最低分別為0.440和0.385。根據相關性高低確定PS、SRS和CRS 3種光譜類型最佳植被指數為NDVI,OFDS和GFDS兩種光譜類型最佳植被指數為mNDVI。
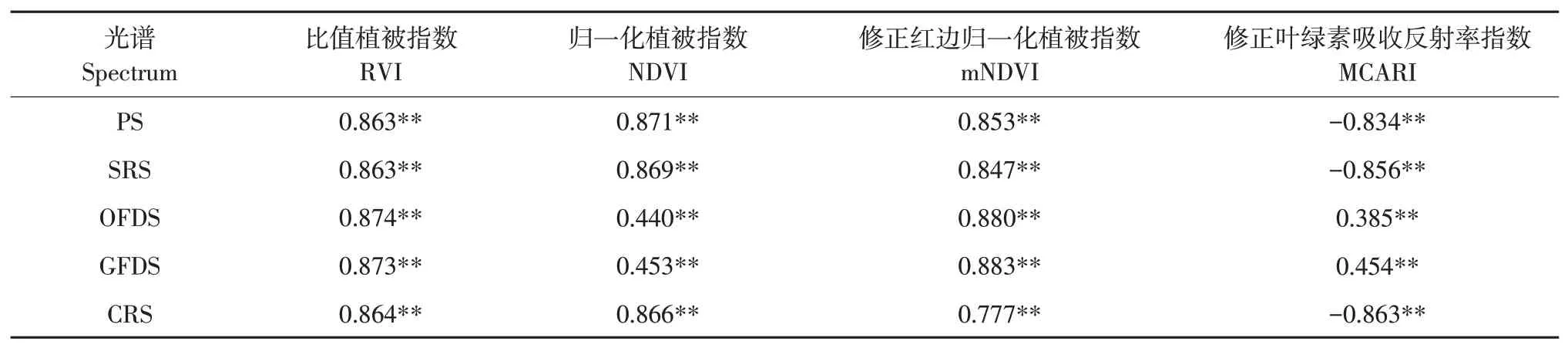
表2 不同類型光譜植被指數與SPAD值相關性Table 2 Correlation of vegetation index of different spectrum types
2.3 單因素模型構建及精度評價
選取不同類型光譜特征波段與最優植被指數分別構建單因素模型,建模結果見表3。
由表3可知,原始光譜與開平方根光譜兩種模型建模精度相當,但為二者基于特征波段的驗證精度不佳;連續統去除光譜、普通一階導數光譜和間隙一階導數光譜特征波段模型較相應植被指數模型,建模R2分別提高0.02、0.02、0.04,驗證R2則分別提高0.05、0.09與0.06,同時三者基于特征波段模型在建模精度與驗證精度方面,RMSE與MRE均處于較低水平。綜合看,基于一階導數特征波段模型為所有單因素模型中最優,其建模R2、RMSE和MRE分別為0.81、2.73和4.78%,驗證R2、RMSE和MRE分別為0.83、2.40和4.36%,在應用單因素模型反演玉米葉片SPAD值時,應優先考慮該模型;其次為間隙一階導數特征波段模型。
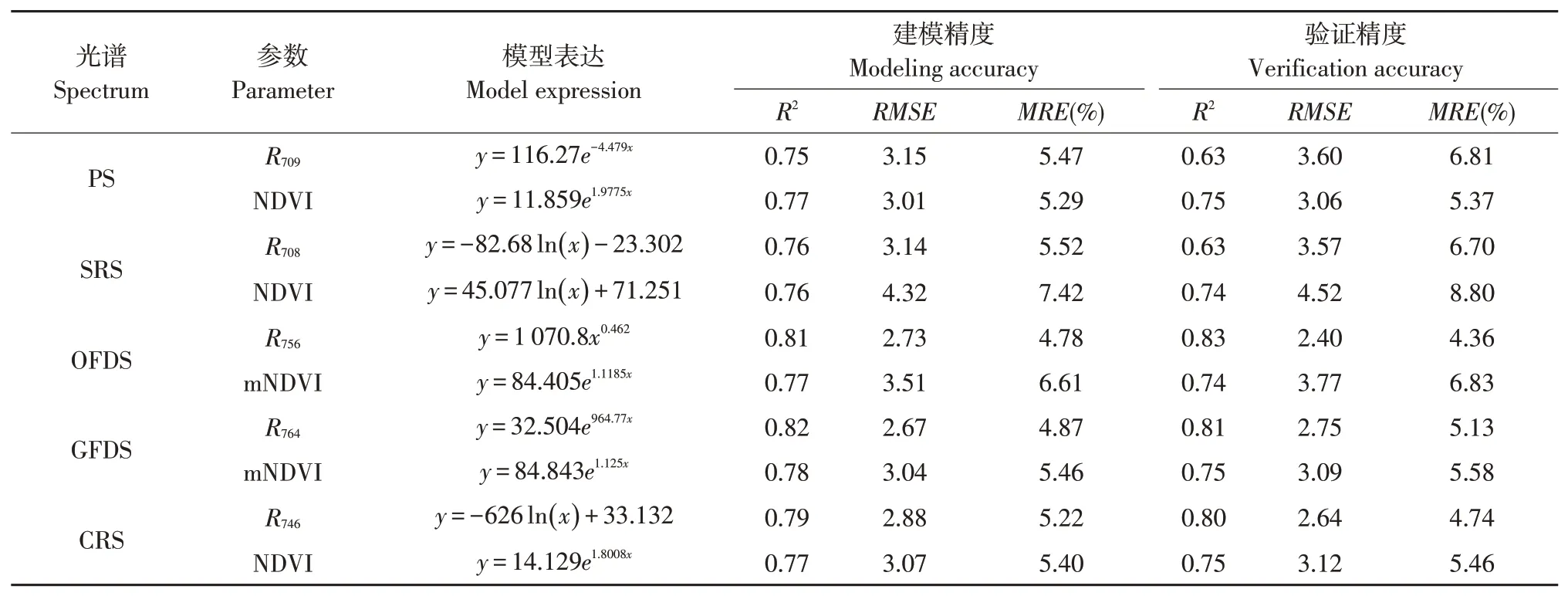
表3 不同光譜類型單因素模型Table 3 Single factor models of different spectrum types
2.4 多因素模型構建及精度評價
2.4.1 基于SPA算法的多元建模參數提取
通過相關性檢驗(0.01水平)的各類型光譜敏感波段作為SPA算法輸入量,SPAD值作為響應量,通過不斷調試,以RMSE最小為原則[23],進一步提取不同類型光譜多因素模型建模參數。結果見表4,SPA算法可大幅降低光譜維度,篩選出各類型光譜建模參數5~9個,且降維比均在97%以上;其中間隙一階導數光譜建模參數最多(9個),連續統去除光譜建模參數最少(5個)。
2.4.2 基于SPA-MLR的多因素模型建立及精度比較
利用表4中列出各類型光譜建模參數,建立多元線性回歸方程(見表5)。與單因素模型相比,各類型光譜建模R2與驗證R2分別提高0.03~0.09、0.01~0.16,同時具有較低RMSE與MRE,可見多元線性回歸模型精度整體上優于單因素模型;同時普通一階導數光譜與間隙一階導數光譜MLR模型建模精度與驗證精度均優于原始光譜,其中基于一階導數光譜的MLR模型為最優模型。

表4 不同類型光譜多元建模參數Table 4 Multivariate modeling parameters of different types of spectra

表5 不同光譜類型下多元線性回歸模型Table 5 Multiple linear regression models under different spectrum types
2.4.3 基于SPA-SVR的多因素模型建立及精度比較
支持向量回歸(SVR)為一種使用超平面定義高維空間邊界的非線性回歸方法,該方法僅依靠支持向量來決定超平面,無需全部數據,適宜處理非線性擬合問題[24]。因此,本文基于表4中各多元建模參數,利用SVR反演玉米葉片SPAD值,為避免自變量數值差異過大影響建模精度,建模前將所有自變量作歸一化處理。支持向量機類型選擇epsilon-SVR,使用RBF核函數,gamma參數設置為特征數倒數,ε采用默認值0.05,通過網格法確定懲罰系數C值,由于C值偏大會造成過擬合,偏小會造成欠擬合,故網格法尋優區間為[10-2,102]。
建模結果如表6所示,除開平方根光譜外,其余各模型建模精度均較高,相應建模與驗證R2在0.85、0.72以上,均方根誤差不超過2.57、3.25,平均相對誤差則在4.33%及6.39%以下。綜合建模及驗證精度看,基于普通一階導數光譜SVR模型具有極高決定系數,建模和驗證的決定系數均超過0.90,同時誤差RMSE、MRE均處于較低水平,為支持向量回歸模型中最優模型。
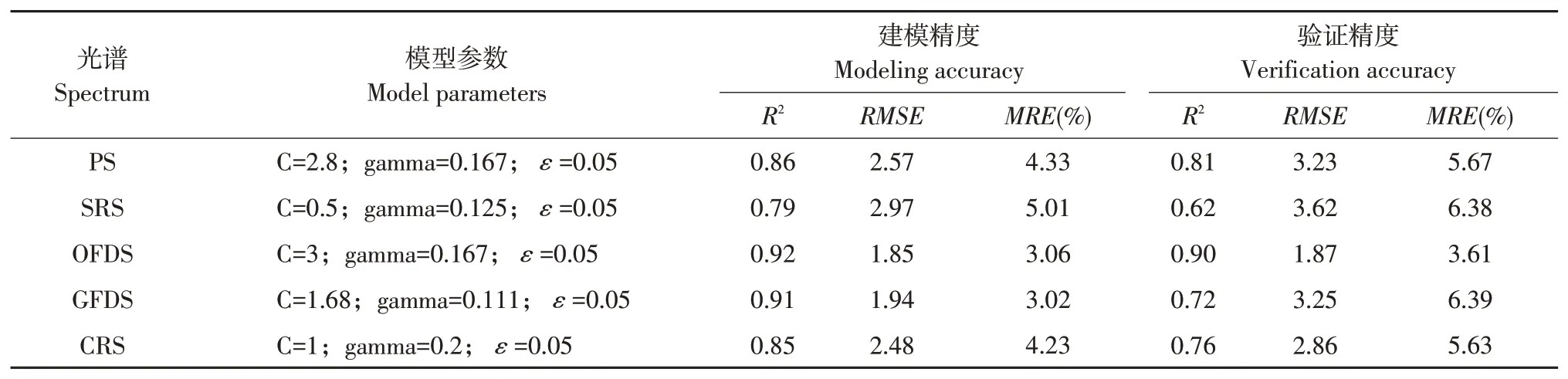
表6 不同光譜類型下支持向量回歸模型Table 6 Support vector regression models under different spectrum types
比較各類型光譜不同建模方法,多元線性回歸模型在建模效果與驗證效果方面均優于單因素模型,支持向量回歸模型建模精度優于單因素模型。但在連續統去除光譜、開平方根光譜及間隙一階導數光譜中,SVR模型建模精度較高,驗證精度低于單因素模型,說明支持向量回歸模型易出現過擬合現象。
分別選擇3種建模方法中最優模型,將相應預測值與實測值線性擬合(見圖4),其中虛線為1:1線,實線為擬合線,當擬合方程斜率越接近1,截距越接近0,說明模型質量越好。由此可見,在所有模型中,普通一階導數光譜支持向量回歸模型為最優模型,其建模R2與驗證R2高達0.92和0.90,相 應 建 模RMSE與MRE則 低 至1.85和3.06%,驗證RMSE與MRE為1.87和3.61%。
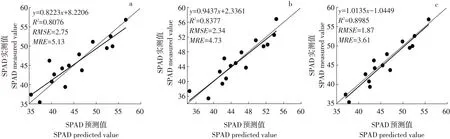
圖4 不同類型光譜最優模型實測值與預測值分布Fig.4 Distribution of measured and predicted values of different types of optimal spectrum models
3 討論
不同形式光譜變換在降低作物反射光譜背景噪聲同時可增強其固有波譜特征,提高光譜反演作物生理生化參數潛力[25]。本文所使用4種光譜變換均可提高SPAD與特征波段相關性,結果與林少喆等[26]研究結果一致。但光譜變換對選取的傳統植被指數敏感性兼具增強與減弱,原因在于傳統植被指數多為基于作物原始光譜構建,變換后光譜曲線特征與原始光譜相比已發生本質性變換,故其植被指數不完全優于原始光譜。因此對光譜變換后傳統植被指數公式改進為下一步研究重點。連續投影算法篩選出各類型光譜多元建模參數介于5~9個,與前人篩選波段數量不一致[11,23],可能是高光譜反演對象不一樣所致,未來研究可針對不同對象開展連續投影算法降維對比。
本文使用不同建模方法構建玉米SPAD值高光譜估算模型,各方法下最優模型建模精度由單因素向多因素、傳統回歸建模向機器學習模型遞增,各類變換光譜中,普通一階導數光譜建模效果最優,與Wang等研究結果一致[27]。單因素一元模型蘊含信息少、對SPAD值響應不全面,所以模型精度與多元模型相比較低;一階導數光譜放大原始光譜的“紅邊”,建模效果最優。SVR提供眾多核函數用以解決各種回歸問題,且模型復雜度僅依賴于支持向量個數,而非數據本身。但該方法對參數及核函數選擇比較敏感,易出現過擬合、收斂慢問題,所以在前人研究基礎上[28],本研究結合連續投影算法與網格法尋優構建的SVR模型為最佳模型。
抽雄期為玉米生長發育最快時期,該時期玉米長勢直接決定后期籽粒是否飽滿。利用本研究建立的模型與田間獲取的實測玉米葉片高光譜數據可反演玉米SPAD值,SPAD值高樣點,說明玉米長勢較好,無需追肥;SPAD值低樣點,說明玉米長勢較差,需追肥。但受氣候、玉米品種及儀器等不同條件影響,本研究僅可反映關中地區抽雄期玉米情況,其他生育期估算反演模型有待進一步研究;同時,未來玉米SPAD值高光譜估測研究應逐漸向衛星遙感方向靠攏,通過遙感影像數據將地面SPAD值由點擴展到面,從大區域尺度上監測玉米長勢狀況。
4 結論
本文以關中地區抽雄期玉米為研究對象,通過不同類型光譜構建基于特征波段與植被指數的單因素模型、基于連續投影的多元線性回歸模型和支持向量回歸模型,得出結論如下:
a.不同SPAD值玉米原始反射光譜曲線特征一致,隨SPAD值增加,可見光波段反射率降低,近紅外反射率上升,同時“紅邊”向長波方向偏移。
b.光譜變換不僅可增強特征波段與SPAD值相關性,還可增加敏感波段數量,提升建模質量;間隙一階導數光譜特征波段相關系數絕對值最大,連續統去除光譜敏感波段數量最多,二者相較原始光譜分別增加0.054和102個;普通一階導數光譜建模效果最佳,各類型模型建模與驗證精度皆優于原始光譜。
c.連續投影算法顯著降低數據維度,各類型光譜降維比均在97%以上。所有模型中,普通一階導數光譜下SPA與SVR結合的模型決定系數最高,擬合誤差最小,為最優玉米葉片SPAD值估算模型,其建模R2與驗證R2分別達0.92、0.90。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
