基于模型壓縮YOLOv4的彈載圖像艦船目標實時檢測
2021-10-15 01:33:40王曙光楊傳棟
兵器裝備工程學報 2021年9期
雷 鳴,王曙光,凌 沖,楊傳棟,秦 杰
(陸軍炮兵防空兵學院 高過載彈藥制導控制與信息感知實驗室, 合肥 230031)
1 引言
如何將性能優越的目標檢測算法移植到彈載平臺,實現圖像制導彈藥的自尋的打擊,并且滿足準確率、功耗和實時性要求是圖像制導彈藥的重要發展趨勢。彈載平臺是指通過艦炮、榴彈炮、迫擊炮和火箭炮等發射的精確制導彈藥上搭載的嵌入式平臺。彈載平臺是一個高速旋轉且不斷前進的平臺,會造成圖像抖動、旋轉、失焦和尺度變化較大等問題,不僅對目標檢測算法的實時性和精度有著較高要求,而且需要算法有較好的尺度適應性和魯棒性。彈載圖像目標檢測技術指的是利用彈載攝像機獲取的圖像進行逐幀(場)分析計算,獲得目標的位置、大小和類別信息的技術,是智能彈藥發展的關鍵技術之一。傳統彈載圖像目標檢測算法主要有模板匹配法、特征統計法、圖像分割法等。雖然傳統目標檢測算法在硬件平臺上實際應用成熟,但是人工設計算法來提取特征對研究者經驗要求較高,在光照、尺度和背景變化的情況下魯棒性不足。近年來,基于深度學習的目標檢測技術得到廣泛應用,省去了人工提取特征的步驟,是一種更為高效的方法。
值得注意的是,深度學習算法在彈載平臺上的移植要考慮運算資源占用的問題。目前,深度學習目標檢測算法YOLOv4(You Only Look Once v4)[1]集成多種先進算法策略,在MS COCO數據集的實時檢測速度約為65 FPS,平均精度均值為43.5%,相比上一代YOLOv3算法分別提高12%和10%。雖然YOLOv4算法在PC端利用GPU加速,可以做到實時高精度檢測,但是其權重文件達到了244 MB,在運算資源有限且條件復雜的彈載平臺上,檢測啟動慢、預存開銷大且運算成本高,必須針對特定打擊目標進行神經網絡模型的針對性訓練,并且對模型進行輕量化處理,在精度下降不大的情況下提高檢測速度,以更好地適應彈載平臺硬件的特殊需求。
2 YOLOv4目標檢測算法
為實現效果最佳的實時高精度檢測,本文選取一階段深度學習目標檢測算法YOLOv4作為基礎網絡。YOLOv4算法首先將輸入圖像分割成K×K的柵格網格,然后每個網格負責檢測中心坐標位于網格內的目標,同時網格內會預測邊框的位置坐標和邊框的置信度,最后對預測邊框進行篩選時使用非極大值抑制算法選出最優邊框[2]。YOLOv4算法檢測網絡是由改進的輸入端、基于CSP Darknet53的特征提取網絡、SPP(Spatial Pyramid Pooling)附加模塊、PANet(Path Aggregation Network)特征融合模塊以及基于錨框機制的YOLOv3預測模塊組成的體系結構。本算法網絡結構如圖1所示。
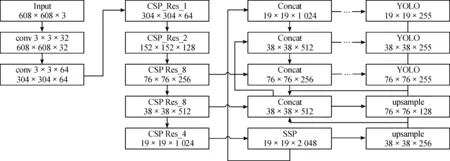
圖1 YOLOv4網絡結構框圖
Darknet53特征提取網絡分為5個大殘差塊,其中包含的小殘差單元的個數分別為1、2、8、8、4。CSP Darknet53是在Darknet53的每個大殘差分塊上加上CSP(Cross Stage Partial)模塊[3],CSP模塊將上一層的特征映射劃分為兩部分,然后通過跨階段層次結構將它們合并,608×608的特征圖經過5個CSP模塊后輸出19×19的特征圖。CSP模塊可以增強神經網絡的學習能力,能夠在保證網絡結構輕量化的同時減少內存成本、降低運算瓶頸和維持準確性。CSP殘差塊網絡結構如圖2所示。

圖2 CSP殘差塊網絡結構框圖
其中,BN[4]指的是批量歸一化(Batch Normalization),起著優化訓練的作用,可緩解訓練時的梯度消失與梯度爆炸問題,批量是指訓練模型設置的圖片數量。YOLO系列網絡模型都引用了BN層,在每個卷積層后面添加,防止了過擬合且降低了模型向前推理速度。BN計算過程為
(1)
式中:γ為縮放參數;μ為均值;σ2為方差;β為偏置量;ω為權值參數;xconv為通道特征圖卷積計算值。
卷積層和BN層合并后,權值參數變為:
(2)
偏置量變為:
(3)
最終,合并后的BN計算公式為:
(4)
卷積層和BN層的合并可以減少運算成本,有利于提升模型速度與模型泛化能力。輸入圖片經過卷積層得到特征圖,接著經過BN層的歸一化處理后由激活函數激活。其中,γ和β是用來縮放和偏置的2個參數,通過神經網絡訓練迭代得到,體現每層網絡的特征分布。本文剪枝過程基于BN層γ縮放參數實現[5],不需額外引入其他參數,可大幅減小模型參數和計算資源占用量,從而提升神經網絡模型的推理速度。
3 模型壓縮策略
神經網絡模型中有大量冗余參數,其存在對目標檢測結果無影響,這是因為神經網絡模型在訓練過程中需要保有一個大參數量來尋找最優解[6]。這些大部分無用的參數在訓練結束后還是保留在了權重文件中,使得權重文件過大。本文模型壓縮策略通俗來講就是在原始參數范圍內找到對檢測效果影響最大的計算路徑,剪枝掉冗余的通道和層,這樣神經網絡模型的精度不會降低且占用儲存空間大幅減少。模型剪枝的策略有細粒度剪枝[7]和粗粒度剪枝[8]兩種類型,分別對應權重剪枝和通道剪枝。細粒度剪枝在目標類別數量多的情況下效果較好,本文研究的是針對艦船目標檢測的模型剪枝,檢測目標類別較少。粗粒度剪枝具有原理簡單、計算開銷小、硬件依賴小和可行性高等特點,針對特定數據集的剪枝效果較好,所以本文采用粗粒度的通道剪枝對神經網絡模型進行壓縮。
本文模型壓縮的策略是:首先,在PC端使用YOLOv4訓練艦船目標數據集,獲取權重文件為后續工作做準備;其次,對神經網絡模型進行稀疏訓練;再次,對神經網絡中冗余的通道或層進行剪枝,壓縮神經網絡模型的深度和寬度;最后,對剪枝后的模型進行微調來回升精度。
3.1 稀疏訓練
縮放參數γ決定著BN層特征圖通道的重要性,代表著每一通道的權重。假設輸入通道i對應的γi值接近0,那么式(1)分子部分隨著γi的減小而減小從而接近常數0,導致此通道卷積計算值對后續計算不產生影響[9]。通常來講,訓練后的神經網絡中BN權重一般呈正態分布,等于或者接近0的參數較少。顯然,如果想要完成冗余參數的剪枝,那么就要在神經網絡訓練時減小縮放參數γ值,這種方法叫做稀疏訓練。引入稀疏規則算子L1范數(Lasso Regularization)進行正則化,計算過程為
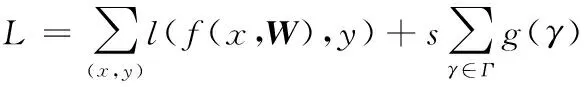
(5)
式中,前項對應于卷積神經網絡的正常訓練損失,其中(x,y)表示訓練的輸入和目標邊框,W表示可訓練的權重,后項中的g(γ)是對縮放因子的稀疏性懲罰,s是用于平衡損失和稀疏性懲罰的超參數,引入L1范數g(γ)=|γ|,對于非平滑L1懲罰項,采用次梯度作為優化方法。 另一種選擇是用平滑L1罰分代替L1罰分[10],以避免在非平滑點使用次梯度。
超參數s根據數據集大小、平均精確率mAP(mean Average Precision)和BN權重分布進行調整,稀疏訓練中s越大稀疏就越快,但mAP下降的也越快。學習率調整更大,稀疏會加快,但是小的學習率有助于后期mAP的回升。通過調整學習率μ和s來保持mAP下降較少而同時實現模型的高稀疏度。
稀疏訓練整個訓練過程保持恒定的s,這樣可以保持均勻的壓縮力度從而獲得較高的壓縮度,但是此方法對精度的折損較大,且最優s值的調參過程時間成本較大。如果在訓練進行一半的階段把s值衰減100倍,有助于精度的回升,減少了尋找最優s值的時間成本,但是會犧牲一部分壓縮度。
3.2 模型剪枝
模型剪枝屬于模型壓縮的范疇,實際應用成熟。通道剪枝即有選擇地剪枝刪除某個卷積核對應通道。層剪枝即有選擇地直接刪除某個卷積層。
剪枝效果取決于稀疏訓練的效果[11],BN權重稀疏度越高,粗粒度剪枝后模型壓縮度越大。通道剪枝后可以進行層剪枝,進一步提升壓縮度。本文通道剪枝利用全局閾值篩選出各卷積層的掩膜,然后和與之相連的直接連接層(shortcut)取并集進行剪枝,此方法考慮了每一個相關卷積層,并且限制了每一卷積層的保留通道。層剪枝的原理與通道剪枝的原理相似,本文通過對每一個直接連接層前的殘差塊進行打分,排列各層γ值分數,對最小得分的層進行剪枝來壓縮骨干網絡。為保證神經網絡模型的完整性,對直接連接層做處理時同時剪掉其之前的2個卷積層。
3.3 知識蒸餾
2015年Hinton團隊首次提出知識蒸餾(Knowledge of distillation,KD) 的思想[12]。針對剪枝導致的精度下降問題,本文對剪枝后的神經網絡模型進行微調以回升精度。剪枝后的小模型與原始模型在結構上相似,可采用知識蒸餾的策略進行微調。知識蒸餾是基于TS(teacher-student) 框架的模型壓縮策略,指一個參數量大的復雜神經網絡模型(teacher)學習到的特征表征能力傳遞給一個參數量小的簡單神經網絡模型(student),從而獲得一個速度快、參數少且學習能力強的模型。具體算法流程如圖3所示。
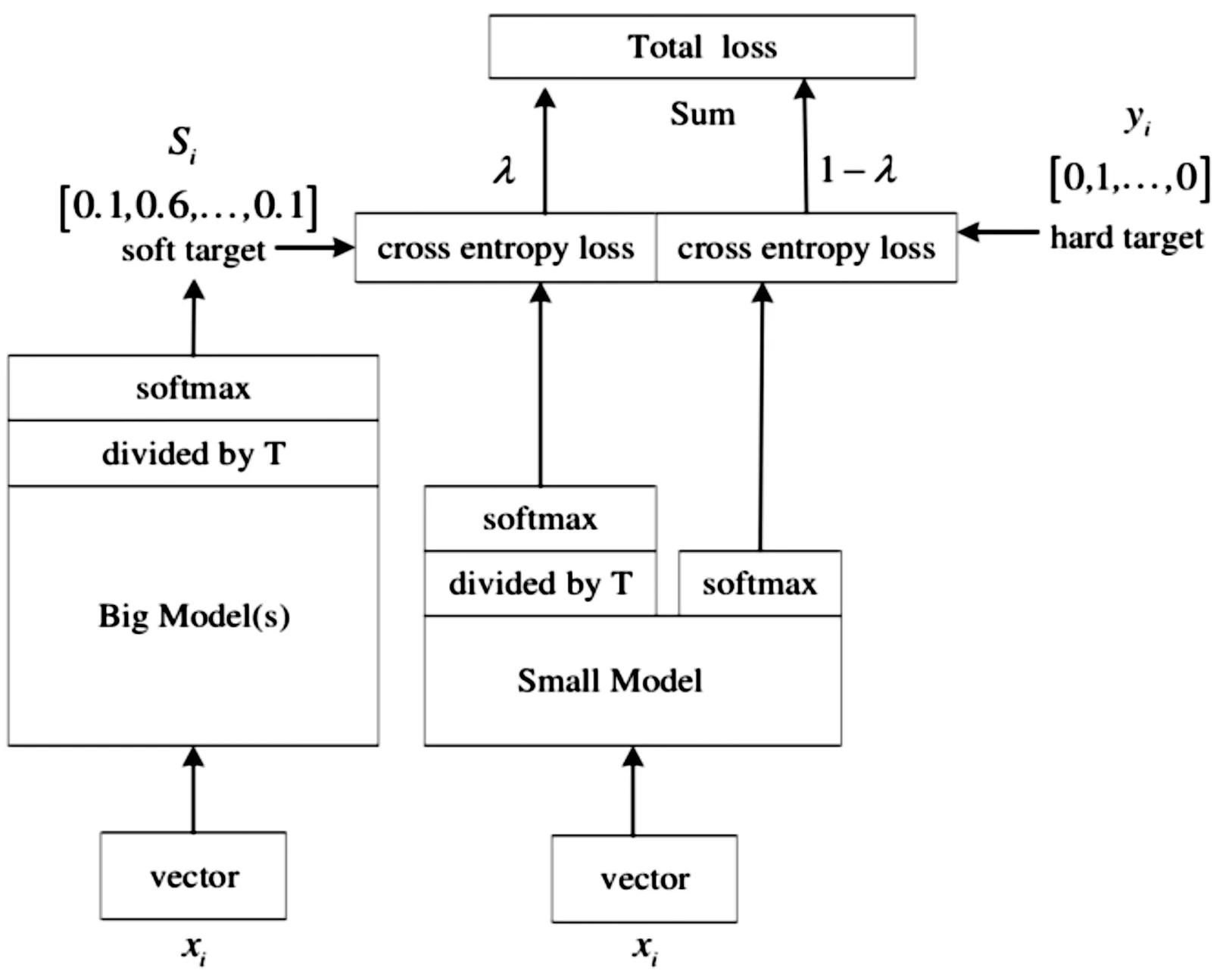
圖3 知識蒸餾流程框圖
利用標注目標邊框的數據集訓練大模型,即基礎訓練模型,設定一個蒸餾溫度值(Temperature,T),然后用基礎訓練模型的預測輸出值除于T,再進行soft max回歸[13],由此獲得介于0~1的軟目標(soft target)預測概率值。然后將基礎訓練模型的特征表征能力傳遞給小模型,這一階段分為兩部分進行,一是一部分小模型預測輸出除以T然后進行softmax回歸,二是剩余部分小模型預測輸出直接進行softmax回歸。硬目標(hard target)指的是真實目標,0表示無真實目標,1表示有真實目標。參數λ是權重參數,用于調節基礎訓練模型與小模型之間交叉熵損失函數的權重,作為小模型訓練的損失函數之一。
4 實驗結果與分析
本研究實驗環境為Microsoft Windows 10專業版(64位) 操作系統,英特爾Intel(R) Core(TM) i5-8300H @ 2.30GHz(2304 MHz) CPU,HP 84DB主板,8.00 GB(2667 MHz) 內存,NVIDIA GeForce GTX 1060(6144MB) 顯卡,CUDA版本10.1.168,cudnn版本7.6.4,OpenCV版本3.4.1,Visual Studio版本2015。基于pytorch框架實現模型壓縮算法。
本研究采用A7200CG30彩色面陣工業相機拍攝水面上的艦船模型,模擬彈載攝像機獲取圖像時的光照條件、下滑角與尺度變化,同時考慮到了實際情況中目標出視場或處于視場邊緣對目標檢測效果的影響,拍攝了部分處于圖像邊緣的艦船目標圖像,充分保證艦船目標數據的真實性與多樣性。獲取圖片3 548張,隨機選取2 838張圖片作為訓練集,選取355張圖片作為驗證集,選取剩余355張圖片作為測試集,使用Yolo-mark工具進行目標邊框標注。在訓練過程引入馬賽克(Mosaic)數據增強方法,把4張具有不同語義信息的輸入圖像通過隨機裁剪、隨機排列、隨機縮放的方式拼接成一張圖像,然后通過批量歸一化的操作從每層的拼接圖像中獲取激活統計信息。如此可以使檢測器檢測超出常規語境的目標,進一步豐富了數據集,同時可以減少對微型批量(mini-batch)大小的依賴從而增強模型的魯棒性,訓練過程可視化如圖4所示。

圖4 Mosaic數據增強訓練過程可視化圖形
首先進行模型的基礎訓練,調整學習率等參數獲得效果最佳的模型作為稀疏訓練的預訓練模型。設置稀疏訓練超參數s,經過反復測試,通過可視化工具查看BN層中γ稀疏的稀疏情況,調整超參數s與學習率。根據先驗知識,超參數s值設置區間為10-3~10-5,根據數據集、學習率、BN分布和mAP調整,學習率越小越有助于稀疏訓練后期精度提升,s值越大γ系數的壓縮越快,同時精度也下降越快。經過循環測試,最終設定s為10-4,在訓練中段s衰減之前可以達到較高壓縮度的同時,在s衰減之后恢復精度能力較好。稀疏訓練前后γ系數的壓縮程度如圖5和圖6所示,可以看到γ系數大部分都被壓縮至接近0,γ系數接近0的通道影響作用極小,可以進行通道剪枝。
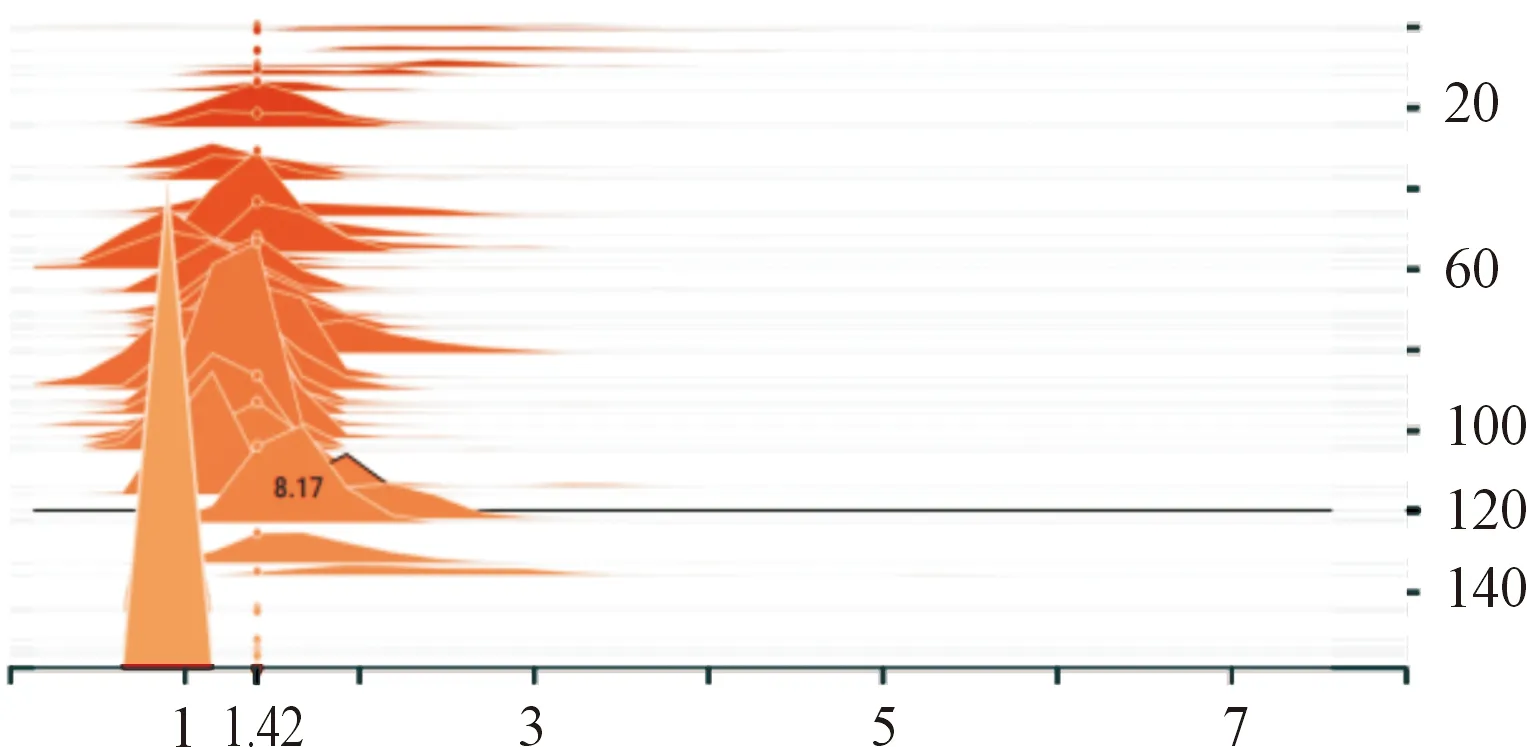
圖5 稀疏訓練前的γ系數分布圖形
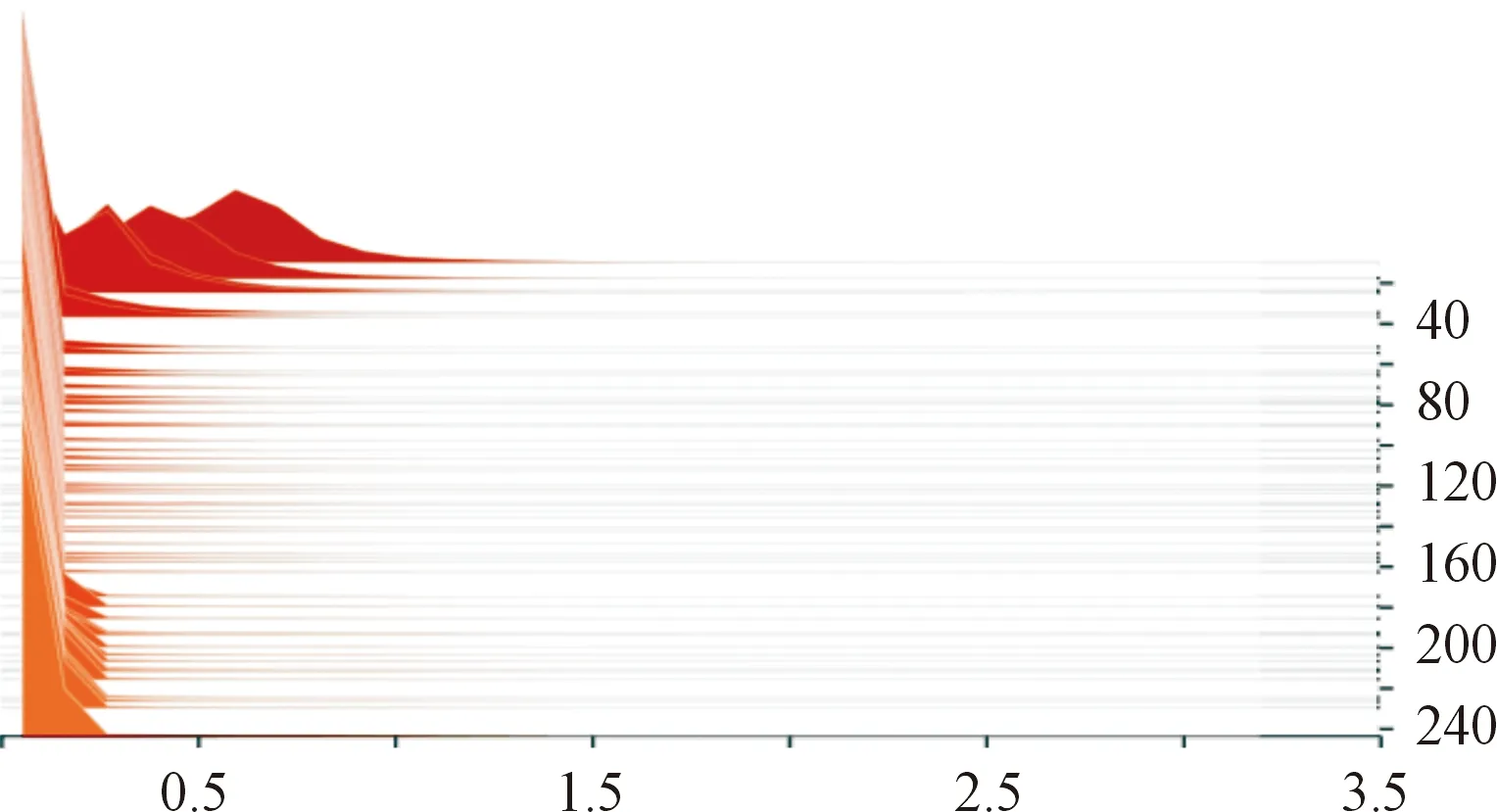
圖6 稀疏訓練后的γ系數分布圖形
稀疏訓練過程可視化如圖7所示,可見稀疏訓練在較小影響精度的情況下完成了γ系數壓縮的任務,符合剪枝條件。稀疏訓練前后各評價指標對比如表1所示。
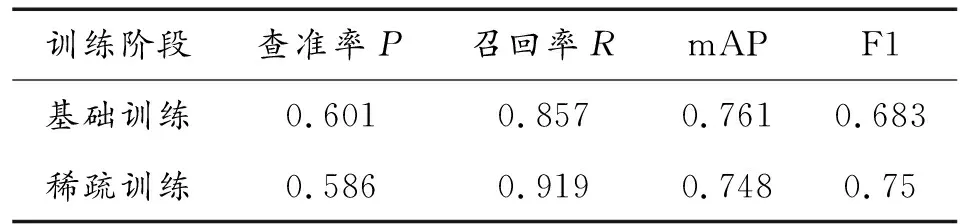
表1 稀疏訓練前后各評價指標
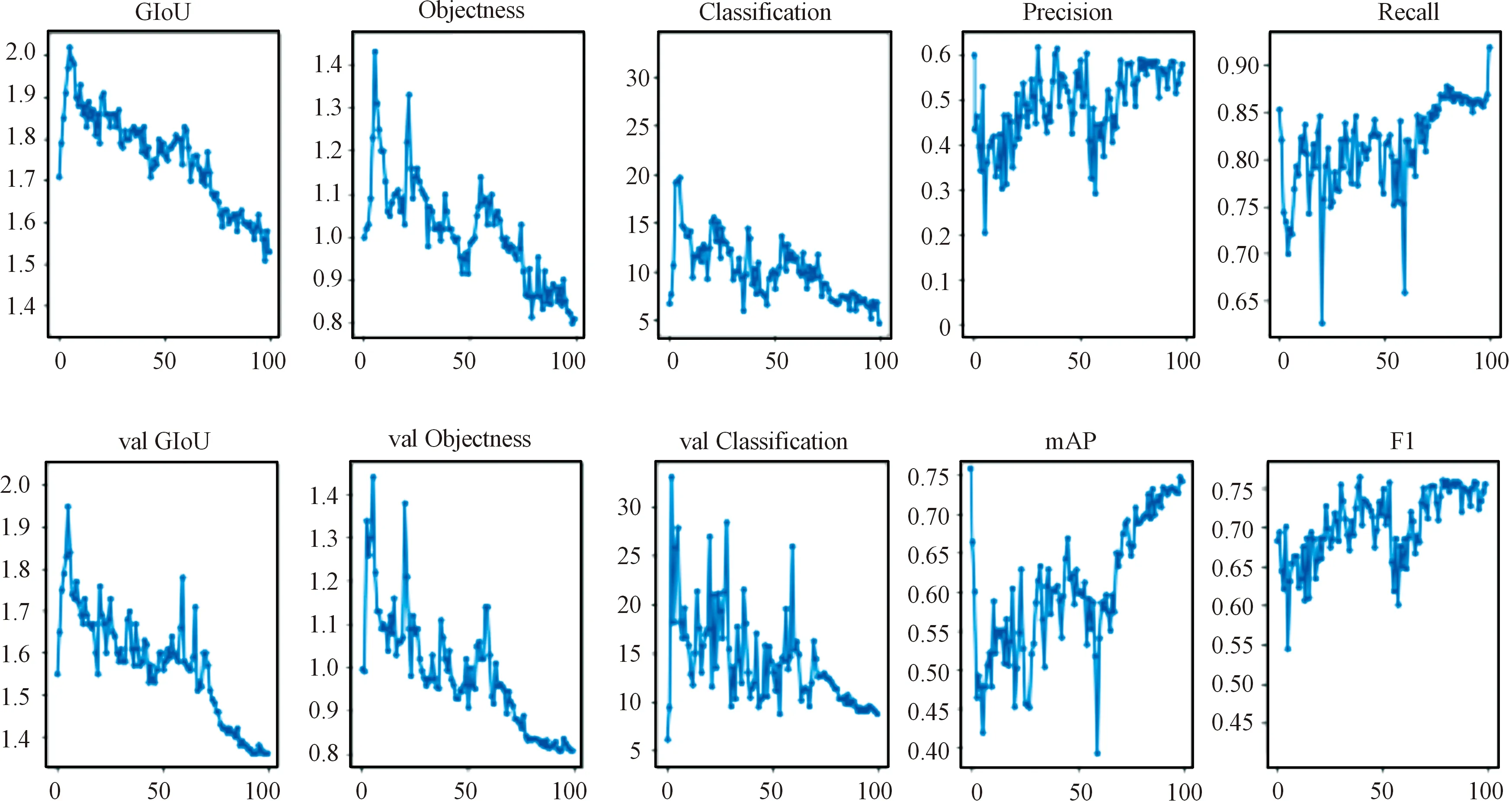
圖7 稀疏訓練各評價指標曲線
YOLOv4神經網絡原始模型有161層,其中有104 個BN層,通道數量為32 256個,包含63 943 071個參數,權重文件大小為244 MB。可見參數量與體積巨大,不適合在彈載平臺部署,所以對其進行剪枝處理。
全局通道剪枝0.85,層保留0.01,剪枝后的神經網絡模型參數為7 033 738,被壓縮了89%,通道數為11 153,被壓縮了65.4%,模型大小為25.7 MB,被壓縮了89.5%。mAP為0.698,可以繼續對冗余的卷積層進行剪枝。
YOLOv4中有23個直接連接層,對于艦船數據集這種各類別特征較為相似的簡單數據集,可以在剪枝大量直接連接層的同時精度衰減較少,本研究剪枝了16個直接連接層和其前面的兩個卷積層,共48層,層剪枝后BN層數為56層,減少了46.2%,總層數為113層模型大小19.9 MB,mAP為0.621。
為了恢復精度,使用知識蒸餾的思想對剪枝后模型進行微調。設置原始模型為老師模型,剪枝后模型為學生模型,使簡單模型可以學習到復雜模型的特征表征能力,進而回升精度。
各模型效果如表2所示,A代表YOLOv4原始模型,B代表通道剪枝后模型,C代表層剪枝后模型,D代表知識蒸餾微調后的模型。
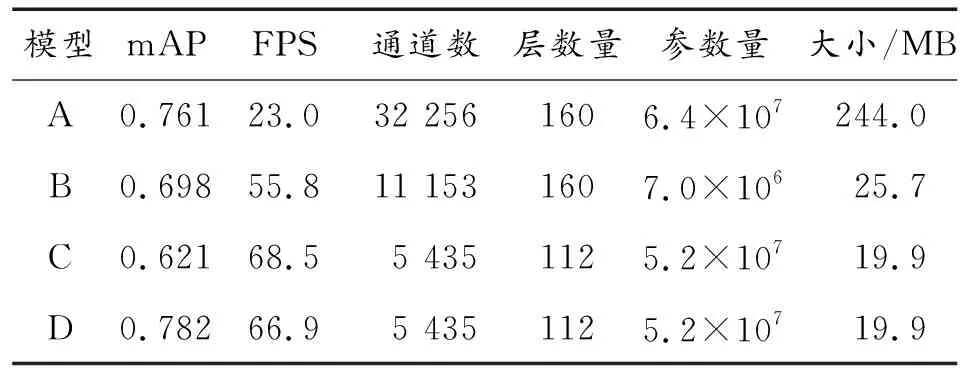
表2 各模型評價指標
對艦船目標檢測效果如圖8所示。

圖8 艦船目標檢測效果圖形
最終微調后的神經網絡模型相較于原始模型精度稍有提升,這是因為稀疏訓練和知識蒸餾訓練也相當于進行了L1正則化,推理速度提升了2倍,通道數縮減為原始模型的16.8%,剪枝了46.2%的層,參數量規模下降91.9%,模型大小為原始模型的8%。
5 結論
1) 提出了一種可以完成實時高精度檢測的輕量級艦船目標深度學習檢測模型,對硬件設備要求更小,充分利用運算資源,為深度學習算法的彈載平臺移植提供了一個可行預研方案。
2) 此模型主要針對水面環境的艦船類目標檢測,對其他戰場環境下的目標檢測能力有待考證,接下來需進一步在彈載平臺上進行驗證。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
