一種基于動態分幀和掩蔽閾值分析的語音隱藏方法
2021-10-15 01:33:30張林科楊百龍
兵器裝備工程學報 2021年9期
康 凱,張林科,楊百龍
(火箭軍工程大學, 西安 710025)
1 引言
語音信號傳輸的應用廣泛,以語音信號為載體實現隱蔽通信具有不易被察覺的特點,在信息安全傳輸領域具有重要應用價值[1-2]。基于掩蔽閾值分析的隱藏算法能夠跟隨語音載體非平穩特征自適應調整嵌入位置和強度,在滿足信息嵌入后信噪比要求的前提下,能夠使信號在聽覺意義上失真降為最小,具有較好的不可感知性。文獻[3]通過小波包分解和離散余弦變換(discrete cosine transform,DCT)估算掩蔽閾值,自適應選取信息嵌入位置和嵌入強度,與人耳頻域掩蔽特性關聯較好,但臨界頻帶劃分不夠準確,掩蔽閾值計算復雜,信息提取時的嵌入強度盲檢測存在較大誤差,算法自身不穩定;文獻[4]采用DCT變換計算掩蔽閾值,確定嵌入強度,設置能量補償點,從而實現了信息隱藏前后能量的一致,算法穩定且魯棒性強,但臨界帶劃分和掩蔽閾值計算不夠準確,固定分幀與載體非平穩特征關聯不好,不可感知性較弱;文獻[5]在離散小波變換(discrete wavelet transform,DWT)域計算掩蔽閾值,基于先前的載密數據計算當前的嵌入強度,嵌入強度盲檢測準確,魯棒性強,但嵌入強度計算復雜,掩蔽閾值計算不夠準確,與載體特征關聯性有待提升。
本文提出一種采用動態分幀和基于掩蔽閾值分析的自適應嵌入方法。仿真實驗及性能分析表明:本文方法在保證隱藏容量達到一定要求的同時,具有運算量小、魯棒性較強、不可感知性較好的特點,可以穩定可靠地應用于以語音為載體的隱蔽通信系統中。
2 基本原理
人耳存在掩蔽效應,充分利用這一聽覺感知特性,可以使嵌入信息不可感知[6-8]。本文方法基于心理聲學模型Ⅱ,采用DWT和DCT變換精確計算掩蔽閾值,自適應確定嵌入強度。由于魯棒性與量化索引調制(quantization index modulation,QIM)嵌入強度大小直接相關[9-10],本文采用動態分幀,將信息隱藏在載體語音能零比較大幀的低頻段,在保證不可感知性前提下最大限度提高嵌入強度,并有效保證魯棒性。盲提取要求穩定可靠實現嵌入強度盲檢測,本文采用能量補償方法,使信息嵌入前后各臨界頻帶能量保持不變,消除信息嵌入過程對嵌入強度盲檢測的影響。
2.1 動態分幀與快速重定位
由人耳掩蔽特性和魯棒性要求可知,能零比較大的低頻段更適于隱藏信息。然而語音信號是非平穩隨機信號,固定分幀嵌入信息的方法與語音信號的非平穩隨機特性關聯不好[11-12],本文采用動態分幀選取合適的信息嵌入幀。
語音信號能零比能夠檢測語音端點,區分有聲段和無聲段,但對數據平移不敏感,提取端難以再次準確定位隱藏信息[12]。本文根據載體音頻能量比分布情況,將載體音頻區分為能零比較大的數據隱藏段(有聲段)和能零比較小的非隱藏段(無聲段),秘密信息隱藏在載體音頻能零比較大的位置。圖1為動態分幀結構示意圖,數據隱藏段由起始幀、信息嵌入幀和結束幀構成。其中,對有聲段語音做小波變換后,采用QIM法在小波系數中插入m序列標識起始幀。結束幀通過對3層尺度系數進行能零比檢測來確定,用于標識當前數據隱藏段的終端,并做容錯處理防止誤檢測。在起始幀和結束幀之間的信息嵌入,以1幀為單位進行逐幀嵌入秘密信息。
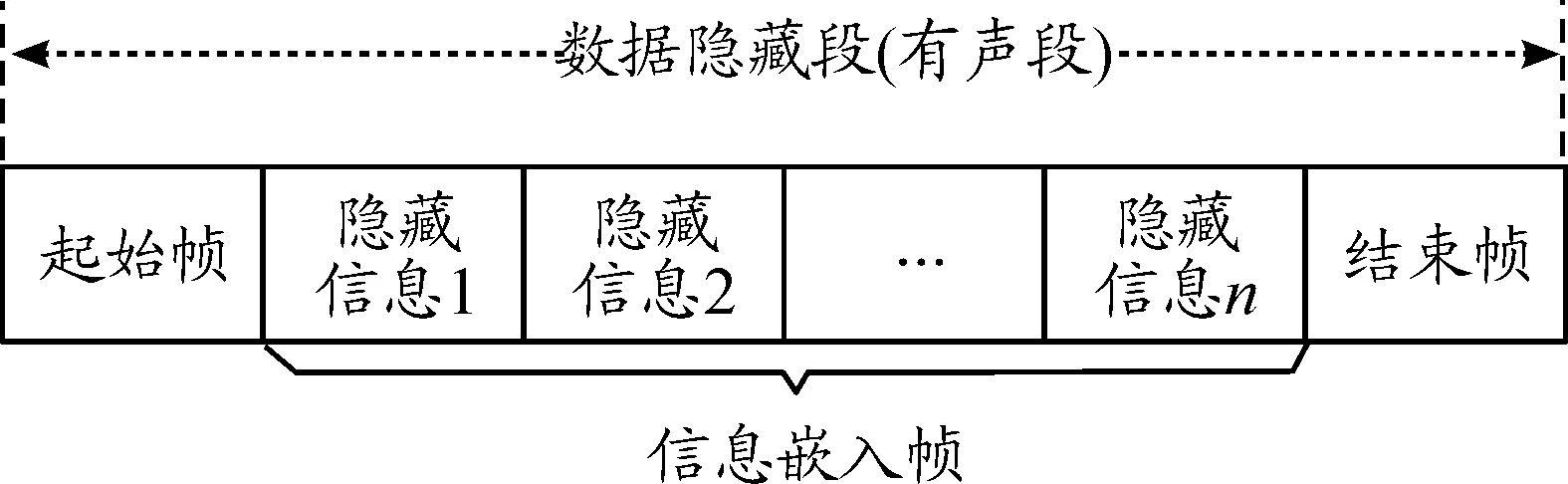
圖1 動態分幀結構示意圖Fig.1 The dynamic framing structure
提取端利用小波變換的時頻局部特性,在小波域快速搜索匹配m序列實現精準重定位。Haar小波變換[13]3層系數只與原信號8個樣點有關,當原信號平移8個樣點時,3層系數產生1個樣點的平移。在3層小波系數中搜索同步碼時,可利用這種特殊的平移性,只全部計算前8次逐點平移的小波系數,后續小波系數可依次通過對應的前8次小波系數向左平移1位,再計算最后8個樣點對應的小波系數做為最后1位而得到,這樣可以極大提高搜索效率。
m序列自相關函數為
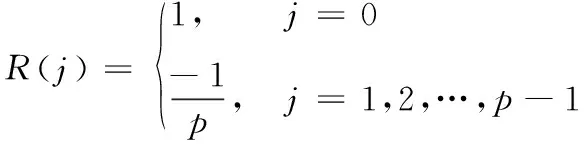
(1)
式(1)中,p為m序列的周期。設嵌入的m序列為m(i),由QIM法檢測到的m序列為m′(i),對m(i)和m′(i)做自相關檢測,如果有
(2)
就認為檢測到同步碼。其中,z是一個適當的閾值參數,z的取值因根據信道質量、同步碼嵌入強度確定。仿真實驗表明,門限值一般取z/p=0.9比較合適。取值太高,誤碼會導致漏檢測。取值太低,小波三層系數的穩定性會導致誤檢測,誤同步。
2.2 基于心理聲學模型Ⅱ的掩蔽閾值分析
基于心理聲學模型Ⅱ計算掩蔽閾值更為精確,當信息嵌入引入噪聲能量譜密度低于掩蔽閾值一定值時,就能保證隱藏信息不被感知。語音信號能量集中在低頻段,為提高算法魯棒性,本文只將信息隱藏在載體語音的低頻段,采用DWT和DCT變換在載體低頻段劃分臨界頻帶[14-15],計算各臨界頻帶的掩蔽閾值。
2.2.1臨界頻帶劃分
人耳聽覺范圍為0.020~22.05 kHz,根據聽覺特性可以劃分為25個臨界頻帶,臨界頻帶序號稱為臨界頻帶域或Bark域,表1給出前9個臨界頻帶頻率。
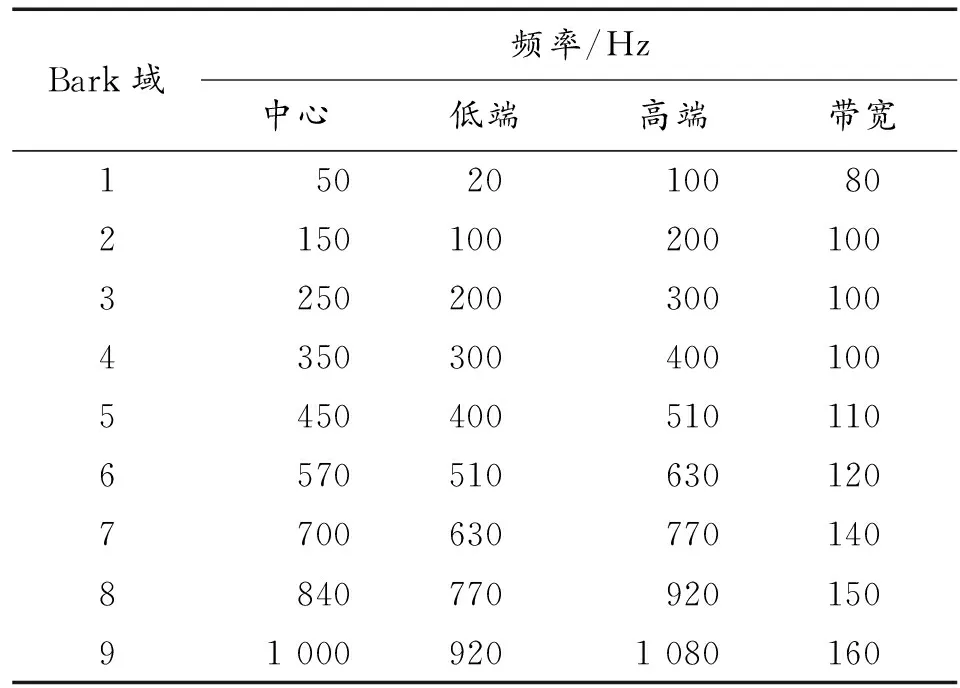
表1 前9個臨界頻帶頻率
對于采樣率fs=8 kHz的語音信號,能量主要集中在低頻段,且人耳對低頻信號不敏感,因此只選取1~9臨界頻帶隱藏信息,忽略其他臨界頻帶[9]。動態分幀時幀長為L,每幀信號先做3層哈爾(Haar)小波變換,3層尺度系數c3(i)和3層小波系數d3(i)對應頻帶為0~500 Hz和500~1 000 Hz;再分別對c3(i)和d3(i)做DCT變化,各得到L/8個DCT系數Xc(k)和Xd(k),用DCT系數等間隔平分低頻帶寬,其頻率分辨率均為fs/2L(Hz);再將Xc(k)和Xd(k)所代表的頻點對應劃分到各Bark域,實現臨界頻帶劃分。本文取L=504,則頻率分辨率約為7.94 Hz,對照表1中各臨界頻帶的上下邊界,可得各臨界頻帶包含的DCT系數范圍和數量如表2所示。
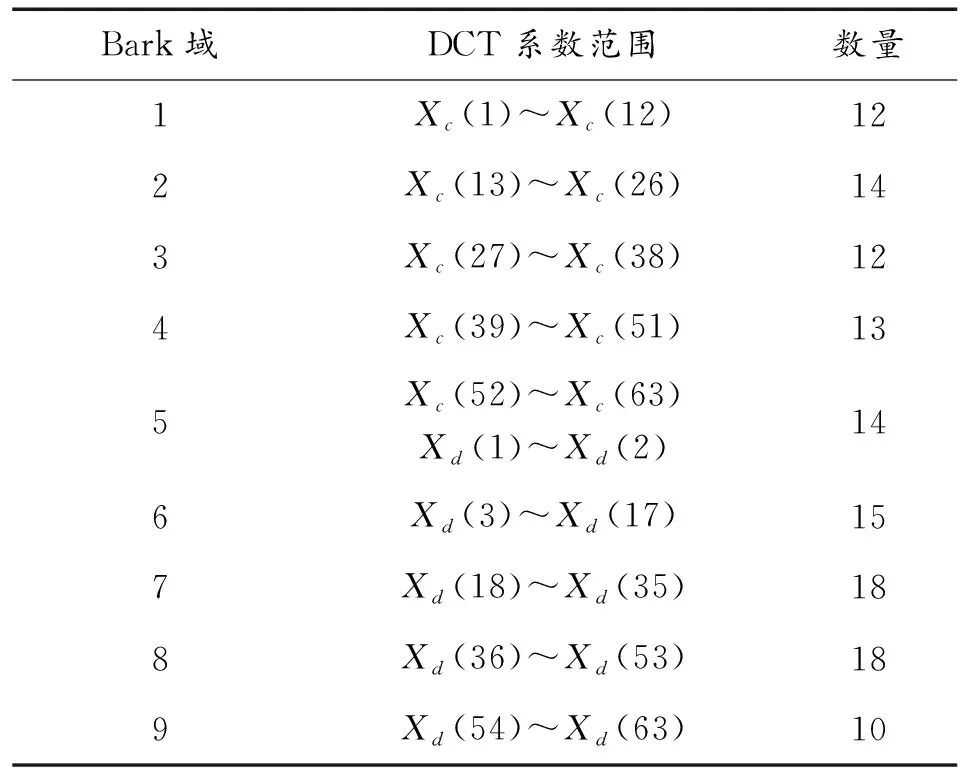
表2 各臨界頻帶包含的DCT系數范圍和數量
2.2.2掩蔽閾值計算
本文基于心理聲學模型Ⅱ計算掩蔽閾值,計算方法如下:
步驟1:當前幀內所有臨界頻帶對第j個臨界頻帶疊加產生的掩蔽效應由各臨界頻帶能量與掩蔽擴展函數卷積進行定量估算。
① 計算各臨界頻帶能量Bj。設Xj(i)為Xc(k)和Xd(k)映射到第j個臨界頻帶的系數,則第j個臨界頻帶的能量譜密度為:
(3)
第j個臨界頻帶的能量為
(4)
式中,jl和jh分別為第j個臨界頻帶內最低頻點和最高頻點對應的DCT系數。
② 計算掩蔽擴展函數[5]值SFj(dB)。
(5)
③ 計算擴展后的掩蔽閾值Cj。
(6)
式(6)中,*表示做卷積運算。
步驟2:掩蔽閾值的大小與音頻信號的譜平坦度和音調特性有關,純音掩蔽噪聲和噪聲掩蔽純音的掩蔽閾值不同。實際信號往往既不是純音也不是噪音,因此采用音調系數對掩蔽閾值進行修正,通過估算第j個臨界頻帶的譜平坦度和音調系數對掩蔽閾值進行定量修正。
① 計算臨界頻帶的譜平坦度SFM(dB):
SFM=10lg(G/A)
(7)
式(7)中,G為臨界頻帶能量譜密度的幾何平均值,A為臨界頻帶能量譜密度的算數平均值。
② 計算音調系數α。
α=min(SFM/-60,1)
(8)
式中,當音頻信號為純音時α=1,當音頻信號為白噪聲時α=0,而實際音頻信號的音調系數往往介于[0,1]之間。
③ 計算掩蔽閾值Tzj(dB)。
由音調系數得到第j個臨界頻帶掩蔽閾值修正值[1,5]為
Oj=α(14.5+j)+(1-α)5.5
(9)
修正后的臨界頻帶j的掩蔽閾值為
Tj=10lgCj-Oj/10
(10)
考慮估算得到的掩蔽閾值修正值Tj不應小于該臨界頻帶的絕對掩蔽閾值Tq(f),臨界頻帶j的最終掩蔽閾值為:
Tzj=max(Tj,Tq(f))
(11)
式中,絕對掩蔽閾值Tq(f)(dBSPL)取值如下[5]:
(12)
由于Tj表示能量值,而Tq(f)表示聲強級,二者單位不統一,因此不能直接比較二者大小。由聲強級和絕對掩蔽閾值定義可知,當確定0 dB聲強級對應的絕對能量譜密度值后,就可以確定各頻點處的絕對能量譜密度值。本文設定DCT域0 dB聲強級對應的絕對能量譜密度值為S,為便于運算,取各臨界頻帶中點處絕對掩蔽閾值為該臨界頻帶絕對掩蔽閾值Tq(j),將前9個Bark域中心頻率代入計算得Tq(j),對應的絕對能量譜密度值為S(j)。如表3所示,其中S值通過實驗設定,最終與仿值歸一化數值實現統一。
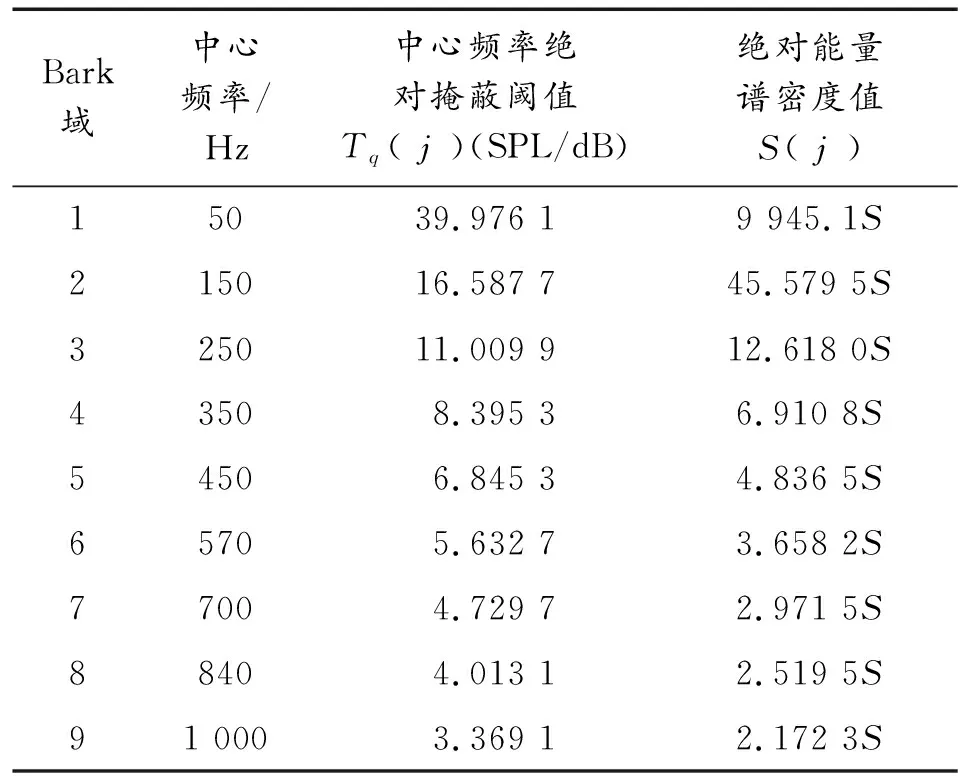
表3 絕對掩蔽閾值
臨界頻帶j的最終掩蔽閾值為
Tz(j)=max[Tj,lj×Tq(j)]=max[Tj,lj×S(j)]
(13)
式(13)中,lj為第j個臨界頻帶DCT系數數量。
2.3 能量補償
由掩蔽閾值的計算過程可知,擴展后的掩蔽閾值Cj和譜平坦度SFM都與載體信號能量譜密度相關,而信息嵌入勢必影響載體信號的能量譜密度,這會導致提取端掩蔽閾值與發送端掩蔽閾值產生偏差,進而導致盲檢測嵌入強度產生誤差,盲提取誤碼率增大。
為提高盲提取的準確性和算法穩定性,本文采用能量補償法,基本原理為:將各臨界頻帶DCT系數分為2組,設為g1和g2。g1用于隱藏信息,g2用于能量補償,通過調整g1組嵌入算法和g2組DCT系數大小,使得各臨界帶信息嵌入前后能量不變,即:
(14)
式中,Xj(i)′為Xj(i)嵌入和調整后的數值。
令
(15)
則有
(16)
為便于計算,對g2組補償系數做等比例縮放,則有
(17)
由上式可知,應有k≥0且k盡量接近1。為達到這一目的,首先應合理劃分g1和g2組DCT系數數量,本文方法中當臨界帶DCT系數少于15個時,g2組選取2個DCT系數;否則,g2組選取3個DCT系數。其次,由k的表達式可知,應使g1組嵌入前后能量差最小,g2組能量和不能過小,以防止調整方位過大。為使能量差最小,量化過程應盡量滿足:
(18)
為實現上述目的,本文在QIM法嵌入信息過程中采取以下措施:
① 當0≤k≤2時,不做處理;
② 當k>2時,表明嵌入后系數平方和過小,將嵌入后變小的系數逐個增大一個嵌入強度Δj,直至0≤k≤2;
③ 當k<2時,表明嵌入后系數平方和過大,將嵌入后變大的系數逐個減小一個嵌入強度值Δj直到剛好k>0為止。
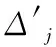
本文方法中對g2組系數做如下處理:
(19)
能量補償能夠消除信息嵌入對各臨界頻帶能量Bj、算數平均值A的影響,但不能消除對幾何均值G帶來的影響,導致音調系數α在信息嵌入前后發生變動。但本文方法經過能零比檢測處理,信息嵌入段載體信號譜平坦度變化不是十分劇烈,仿真實驗也表明,掩蔽閾值修正值大體范圍為[5,12],因此,本文將Oj設定為8 dB。
2.4 嵌入強度選取
本文信息嵌入采用QIM調制的方法,量化步長的選取關系方法的不可感知性和魯棒性,根據文獻[3]的結論和實驗測試,如果信息嵌入后的音頻噪聲掩蔽比NMR≤-5 dB,信息隱藏后具有較好的不可感知性。設QIM嵌入法量化步長或嵌入強度為Δj,則g1組單點信息嵌入引起的最大量化誤差為Δj/2,進過能量補償調整后,單點最大量化誤差為Δj;g1組系數幅值越大,調整比例k越趨近于1;對于調整過的g2組系數,k值極少大于2,一般在[0,2]之間,因此可取g2組系數單點最大量化誤差亦為Δj。單點最大噪聲能量為
(20)
又有
NMR(j)=En-Tz(j)/lj
(21)
當量化噪聲不可感知時,有
10lgNMR(j)≤-5
(22)
則當前幀第j個臨界頻帶的嵌入強度
(23)
2.5 量化索引調制
設待隱藏的二進制信息為x(i),采用QIM法嵌入信息的公式為
①x(i)=1時,
Xj1(i)′=
(24)
②x(i)=0時,
Xj1(i)′=
(25)
式中,Xj1(i)、Xj1(i)′為嵌入前后的DCT系數,Δj為當前幀第j個臨界頻帶的嵌入強度,?·」表示向下取整。
設盲提取的二進制信息為x′(i),采用QIM法盲提取隱藏信息的公式為
(26)
式中,Xj1(i)″為提取端當前幀各臨界頻帶g1組DCT系數,Δj″為盲檢測得到的各臨界帶的嵌入強度。
由QIM法嵌入公式可知,信息嵌入前后各DCT系數量化誤差最大值為Δj/2。由于能量補償算法對部分嵌入后的DCT系數進行了調整,導致部分DCT系數信息嵌入前后量化誤差最大值為Δj,但調整幅度均為+Δj或-Δj,且調整前后DCT系數正負值不發生變化,故不會對提取過程造成任何影響。由QIM法提取公式可知,提取時的噪聲容限為±Δj″/4,只要最終檢測誤差不超過噪聲容限,就可以正確的恢復出隱藏信息,否則就可能產生誤碼;提取過程中的Δj″為盲檢測得到,提取過程不需要原始載體,故能夠實現盲提取。
3 信息嵌入提取過程
3.1 信息自適應嵌入
為了保證魯棒性,本文所提方法在DCT域基于QIM在載體語音的低頻段進行信息的嵌入和提取過程。在嵌入端,利用能零比檢測和m序列自相關性,動態選取和標記適于信息隱藏的語音段,進而結合DWT和DCT準確劃分臨界頻帶并基于心理聲學模型Ⅱ計算掩蔽閾值,實現嵌入強度的自適應調整。自適應嵌入流程如圖2所示。
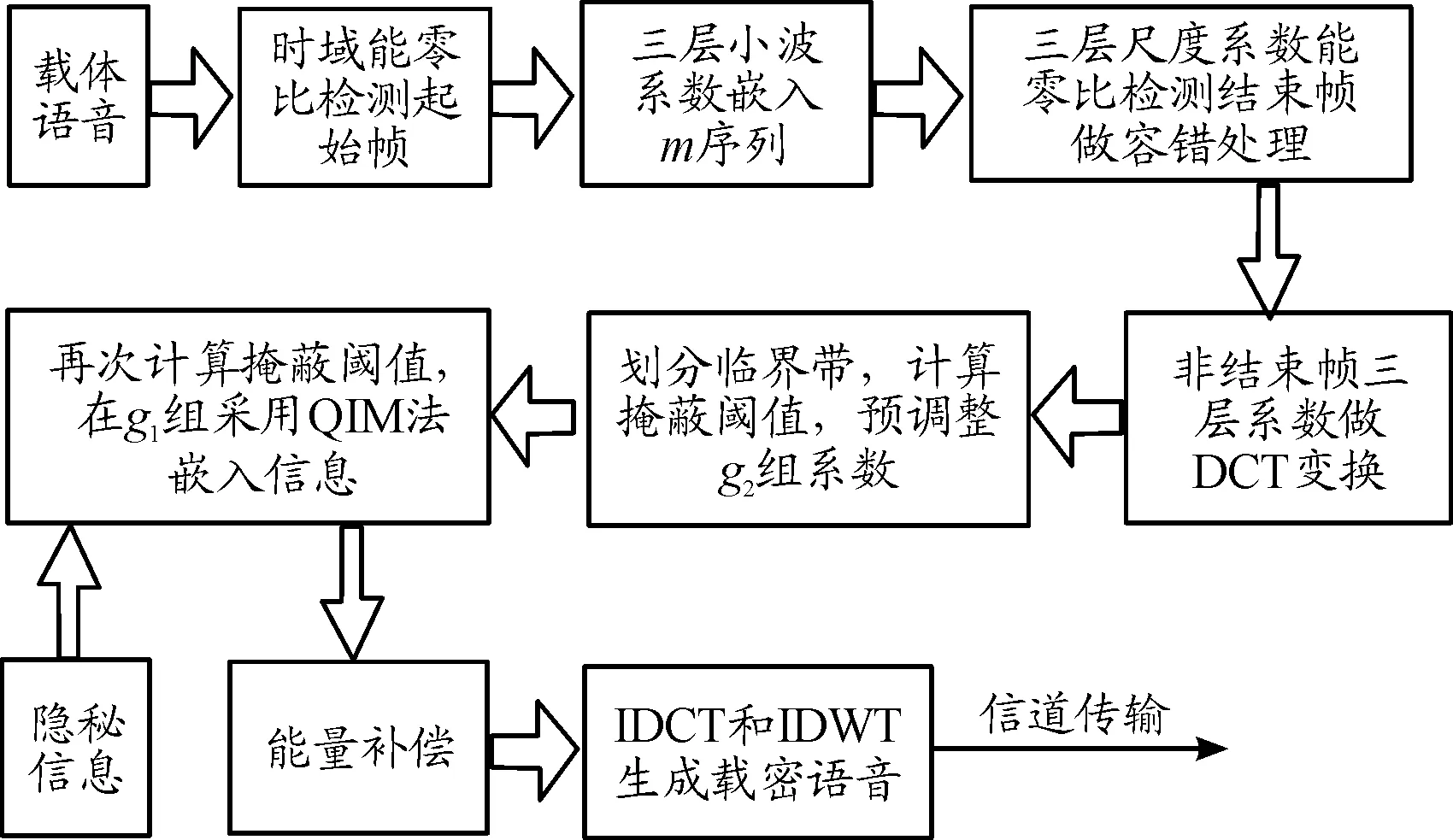
圖2 自適應嵌入流程框圖Fig.2 The adaptive embedding flow chart
具體步驟為:
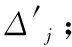
③ 再次計算掩蔽閾值和嵌入強度Δj;
④ 采用QIM法在各臨界帶g1組系數中依次嵌入隱藏信息;
⑤ 計算各臨界帶k(j)值,依據k(j)值調整g1組相應系數量化誤差;
⑥ 根據k(j)縮放g2組系數,使信息嵌入前后各臨界帶能量不變,實現能量補償目的;
⑦ 經過IDCT、IDWT得到信息隱藏后數據,對應替換原數據,實現信息隱藏。
3.2 信息盲提取
在提取端,利用小波變換的時頻局部特性,在小波域采用容錯處理的方法實現快速準確重定位,并在各臨界帶采用能量補償方法消除嵌入信息對嵌入強度盲檢測準確度的影響,進而采用QIM方法提取信息。盲提取流程如圖3所示。
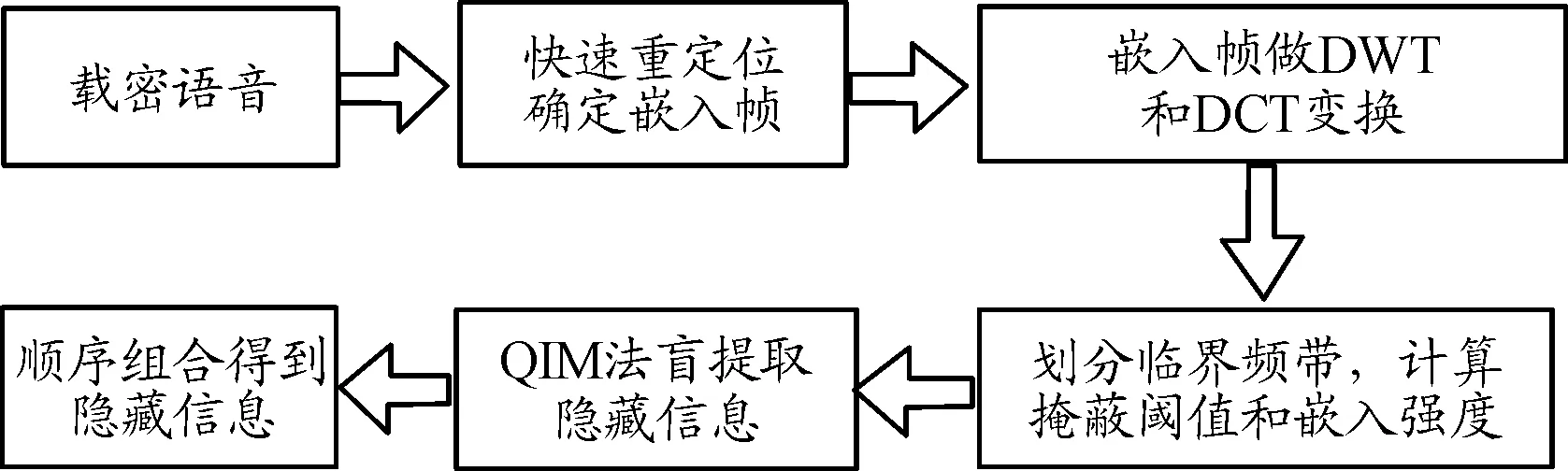
圖3 盲提取流程框圖Fig.3 The blind extraction flow chart
具體步驟為:
① 利用小波變換時頻局部特性和m序列自相關檢測實現快速重定位;
② 對嵌入幀做DWT和DCT變換;
③ 按照發送端方法劃分臨界頻帶,計算掩蔽閾值,確定嵌入強度Δj″;
④ 從各臨界帶g1組采用QIM法順序盲提取隱藏信息;
⑤ 順序組合得到所有隱藏信息,實現信息盲提取。
4 仿真實驗及性能分析
本文基于心理聲學模型Ⅱ分析掩蔽閾值,通過動態分幀、精確劃分臨界頻帶、計算掩蔽閾值,充分利用人耳掩蔽效應,自適應調整嵌入位置和嵌入強度。下面對該方法的不可感知性、隱藏容量、抗干擾能力和復雜度進行測試分析。性能測試載體語音采用采集的3段8 kHz采樣率、16位采樣精度、時長5 s(40 000點)單聲道語音信號(樣本一為女聲、樣本二為男中音、樣本三為男低音),隱藏信息為任意的一段隨機二進制序列,同步幀和嵌入幀幀長均為504點,m序列周期p=63,0 dB聲強級對應的絕對能量譜密度值S=3×10-6。
4.1 不可感知性分析
采用平均意見得分(average opinion score,MOS)和信噪比(signal to noise ratio,SNR)對不可感知性進行綜合表征和評判。鑒于自適應方法的不可感知性不隨載體音頻改變而改變,測試對載體音頻的影響不做考慮。
表4給出了測試樣本的MOS和SNR值。由于嵌入信息是偽隨機序列,SNR值存在小幅波動,表4中的數值為10次測量平均值。
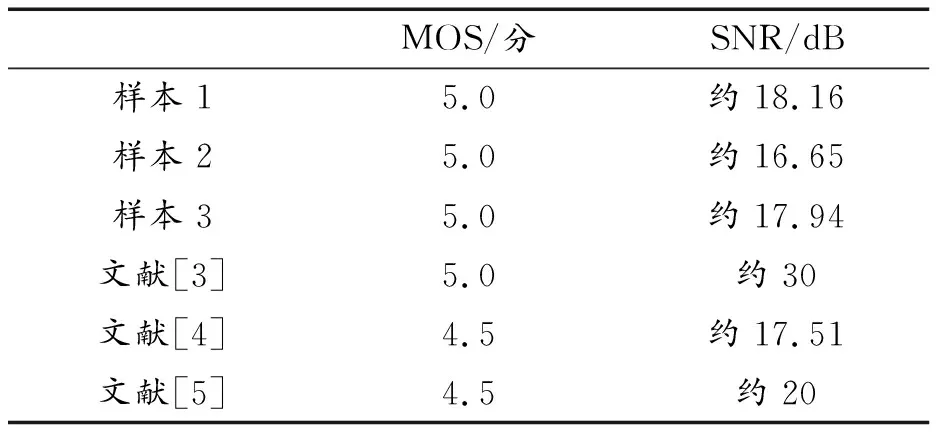
表4 不可感知性測試
對表4數據進行分析可知:
① 本文方法。在保證MOS值足夠大的前提下,即使SNR值較小(時域差值大,0.1量級),不可感知性依然較好;SNR值小意味著嵌入強度大,有利于算法提高魯棒性;算法MOS值不隨載體音頻不同而變化,自適應特性良好;
② 文獻[3]方法。為了提高信噪比,選取嵌入系數時選取了較小的嵌入強度(時域差值0.01量級),降低了嵌入容量,進而降低了魯棒性,且小波包變換與臨界帶對應不是很準,不可感知性與本文方法相當;
③ 文獻[4-5]方法。由于掩蔽閾值計算不夠準確,在同樣低信噪比的情況下不可感知性低于本文方法。
樣本一信息嵌入前后時域如圖4所示。
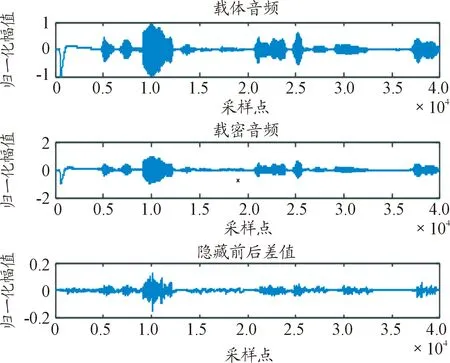
圖4 樣本一信息嵌入前后的時域Fig.4 The time-domain comparison before and after information embedding in sample 1
4.2 隱藏容量分析
語音信號是典型的非平穩隨機信號,且不同于連續音頻信號,有聲段無聲段特征區分明顯,固定隱藏容量顯然不能適應其特點,隱藏容量自適應調整具有更高應用價值。本文方法采取動態分幀選取嵌入位置,隱藏容量受載體語音自身能零比特征影響。表5給出測試樣本的嵌入容量,分析可知:
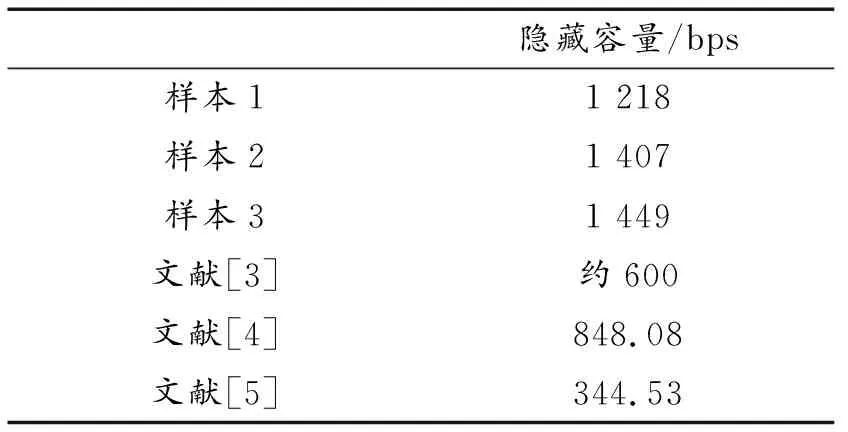
表5 隱藏容量測試表Table 5 The hiding capacity experiments
① 文獻[3]自適應選取嵌入系數,嵌入容量動態變化;
② 文獻[4-5]采用固定分幀和固定嵌入位置的方法,嵌入容量不隨載體變化;
③ 本文方法隱藏容量與載體能零比分布情況相關,在不同測試樣本下的隱藏容量不同,但都明顯大于文獻[3-5]之值。
4.3 抗干擾能力分析
不同于音頻水印,音頻信息隱藏受到的干擾主要為采樣精度和計算精度引入的噪聲和信道傳輸過程中誤碼導致的噪聲,本文采用高斯白噪聲模擬干擾,采用誤比特率(bit error rate,BER)衡量抗擾能力。設置式(2)中z/p=0.9時實驗數據統計性能表現較好。表6給出該條件下測試樣本在不同干擾強度及不進行能量補償時的BER值。
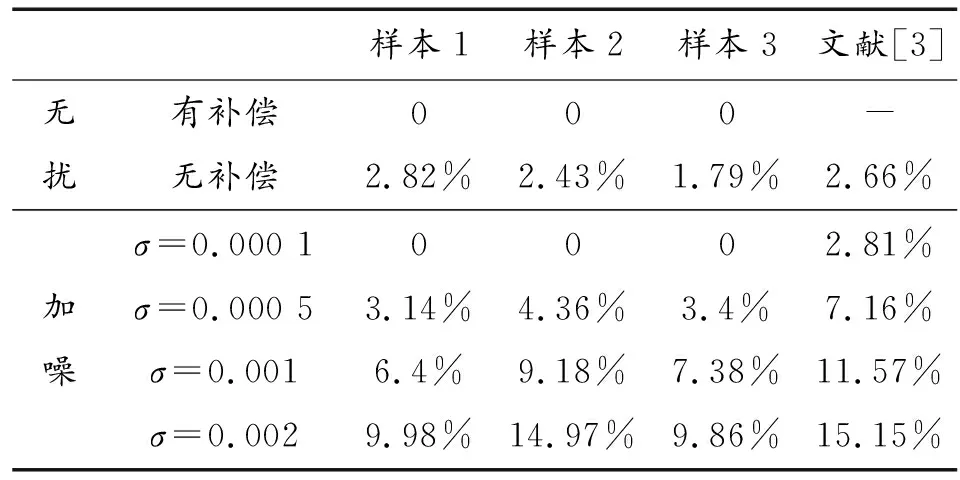
表6 抗干擾能力測試表
對表6數據進行分析可知:
① 無干擾情況下本文方法BER值始終為0、無干擾不進行能量補償時BER值不為0,本文采用能量補償確實提高了算法自身穩定性;
② 本文方法在受擾情況下BER值變化平緩,不存在明顯的邊界現象,說明本文方法有助于改善魯棒性;
③ 文獻[3]算法沒有考慮信息隱藏對載體音頻的影響,算法自身不穩定,且為了單純提高信噪比而選取了較小嵌入強度,導致抗擾能力弱于本文方法;
此外,文獻[4-5]采用了矢量量化方法,以降低隱藏容量換取強魯棒性,屬于強魯棒性水印算法。在確定了具體的信息隱藏方法后,抗擾能力往往直接受嵌入強度影響,適當降低不可感知性要求,提高絕對掩蔽閾值參考值S,可以明顯改善低干擾情況下的BER值。
4.4 計算復雜度分析
一個長度為N的離散數列的小波變換,使用Mallat算法的計算復雜度為O(N);完全小波包分解的計算復雜度與DCT變換的計算復雜度相當,均為O(NlogN);部分小波包分解的計算復雜度介于O(N)和O(NlogN)之間。
為保證頻譜分析具有足夠的分辨率,幀長N必須具有足夠的長度。文獻[3]采用部分小波包分解;文獻[4]直接采用DCT變換;本文方法在動態分幀的基礎上先進行3層DWT變化,使數列長度變為N/8后,再進行DCT變換。從變換過程計算量分析,文獻[3]<本文方法<文獻[4]算法,但當N值較小時,DCT變換和部分小波包分解運算量差別不大。因此本文方法具有和文獻[4]相同的頻率分辨率,優于文獻[3]的頻率分辨率;本文方法計算復雜度與文獻[3]相當,優于文獻[4]算法。
5 結論
本文方法在計算復雜度未有明顯提升的情況下,掩蔽閾值計算準確,在較低的信噪比下具有較高的MOS值,不可感知性好,且不可感知性不受載體音頻影響;充分利用了人耳掩蔽特性,隱藏容量較大;在信息嵌入端,采用動態分幀和自適應嵌入,提高了嵌入強度的統計平均值,在保證一定不感知性的前提下有利于抗干擾性能的提升;在信息提取端,容錯處理和能量補償措施有助于實現穩定的盲提取,保證了方法的穩定性。
猜你喜歡
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中華手工(2017年2期)2017-06-06 23:00:31
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
祝您健康(1987年2期)1987-12-30 09:52:28
