基于問句感知圖卷積的教育知識庫問答方法
2021-10-12 08:49:52藺奇卡張玲玲趙天哲
計算機與生活 2021年10期
藺奇卡,張玲玲+,劉 均,趙天哲
1.西安交通大學 計算機科學與技術學院,西安 710049
2.陜西省天地網技術重點實驗室,西安 710049
近年來,隨著互聯網技術的蓬勃發展,各種在線教育平臺層出不窮,造成了海量教育資源以及教學數據的不斷積累[1]。知識庫(或知識圖譜)以RDF 三元組的形式存儲大量實體及它們之間豐富的語義關系,這為教育領域的海量信息提供了良好的組織方式,因而受到越來越多的關注。具體而言,教育知識庫可將分散、無序的教育數據聚合為結構化的,易于檢索、修改和保存的知識形式,進而降低用戶的使用成本并快速實現認知升級[2]。例如清華大學Yu等人[3]提出了大規模在線課程(massive open online course,MOOC)知識庫MOOCCube,其包含概念、課程、教師和學生行為等實體及其交互信息,用以支持多種不同場景的教學研究需求。Xu 和Guo[4]提出適用于K12教育的知識點知識庫,其中節點主要包含知識點、學校和教師等,實驗表明使用該知識庫能有效提升教育資源推薦的準確性。Lin 等人[5]使用大學教師在科研和教學活動中產生的交互數據構建了大學教師知識庫,包含教師、研究方向、科研成果和社會兼職等,進而為教師評估提供定性和定量的數據支持。
同時,教育知識庫的出現為教育領域的智能問答提供了基礎,它能為學習者提供良好的交互體驗和精準智能的答疑輔導服務,是在線教育領域亟待解決的關鍵問題之一[2]。目前,對于教育知識庫問答的研究還相對薄弱,不能滿足當前教育平臺發展的需求[6]。相比于開放領域的知識庫問答,教育領域知識庫中包含的關系較少。例如基于MOOCCube 的MOOC Q&A[3]中僅包含10 種關系類型,而基于開放知識庫Freebase[7]的WebQuestionsSP[8]數據集包含513 種關系。這種差異導致教育領域的問答模型需要有效獲取實體針對于問句獨特而有價值的表示方式,然而開放域的經典問答方法(例如GRAFT-Net[9]、PullNet[10]、MHGRN[11]和EmbedKGQA[12])在進行實體表示時,很少考慮問句的影響。基于此,本文提出基于問句感知圖卷積網絡(graph convolutional network,GCN)的教育知識庫問答方法。針對特定問句,該方法首先將其分解為問句描述信息和查詢實體集,并分別進行表示;之后,通過查詢實體集構建答案候選子圖,并通過雙注意力圖卷積網絡進行處理,注意力的計算分別來自問句描述信息和查詢實體集;最后,基于這些表示,進行候選實體打分并預測答案。
本文的主要貢獻包括:(1)提出一種基于聯合嵌入的教育知識庫問答框架,該框架獨立地建模問句中的描述信息和查詢實體以及候選實體子圖,之后融合這些信息并通過前饋神經網絡預測得分;(2)針對當前問答方法在候選實體建模時單一、難以捕獲特定于問句信息的缺陷,提出問句感知的雙注意力圖卷積神經網絡;(3)在現實的教育知識庫問答數據集上的實驗結果表明,本文模型的性能優于基準模型。
1 相關工作
目前知識庫問答方法主要分為兩類:語義解析方法和聯合嵌入方法。語義解析方法首先解析自然語言問句,將其轉換成邏輯表達式,并通過匹配知識庫生成查詢語句,最終執行查詢得到答案。例如Reddy 等人[13]提出基于語義圖的語義解析方法,該方法分析問句,構建由節點(實體、變量或者類型)、邊(關系)和操作符構成的語義圖,將其視為知識庫的子圖以實現問句映射,然后通過特定的圖匹配方法獲取答案。類似地,Yih 等人[14]通過引入查詢圖提出了基于知識庫的問答語義解析框架,其中語義解析被簡化為查詢圖的分階段搜索生成過程,最終通過查詢圖的實體鏈接和卷積神經網絡預測答案。整體來說,該類方法雖然取得了一定的效果,且易于理解,但它們通常包含多個模塊及多個步驟,在訓練時容易造成誤差積累,導致性能較差。
基于以上缺陷,一些基于聯合嵌入的問答方法被提出,這類方法使用表示學習的思想將問題和候選答案嵌入到統一的向量空間中,之后在該空間中進行距離計算以得到答案。例如Dong 等人[15]提出的MCCNNs(multi-column convolutional neural networks)使用多列圖卷積網絡處理問句得到其表示向量,同時將候選答案的相關特征(類別、上下文和路徑)映射到對應的問句空間中,最后通過向量內積計算距離以預測答案。Sun 等人[10]使用聯合嵌入的思想將外部文本融入知識庫中以實現更全面的問答。通過迭代地擴充問題子圖(節點為實體、實體對及文檔),并使用卷積網絡進行聯合嵌入,模型能夠有效解決多跳知識庫問答問題。Saxena 等人[12]利用知識庫嵌入的思想進行實體、關系及問句的嵌入,其中問句可以理解為知識庫上的單跳或者多跳關系,進而將它們都嵌入在同一向量空間中,最后使同經典的知識庫嵌入方法(如ComplEx[16])進行得分計算。
基于聯合嵌入的方法能夠有效挖掘問句和知識庫的深度特征,進而取得良好的預測性能。但是目前的相關方法在進行實體表示時僅僅利用知識庫中的結構信息,并未考慮問句信息的影響,導致建模不充分。基于此,本文提出問句感知的圖卷積網絡進行實體建模,在圖卷積的信息傳遞時,模型會綜合考慮問句描述和相關查詢實體的影響。
2 基于問句感知圖卷積的問答模型
為了讓圖卷積網絡能夠學習到針對問句的特定實體表示,本文引入問句感知的注意力來分別建模問句描述信息和相應查詢實體,整體模型架構如圖1所示。形式化地,針對待回答的問題q,其蘊含待查詢實體集合EH,例如圖1 問句所對應的查詢實體集合包含[李華]和[張濤]。使用該集合為種子列表,從知識庫中獲取h階鄰近子圖Gq,其節點集合為Eq,h的取值需保證問題q對應的答案集合ET是Eq的子集。為了解決該類教育知識庫問答問題,本文采用問題建模、子圖建模和答案預測三階段的計算方式。本章將從以下三方面進行詳細介紹:基于Transformer和知識庫嵌入的問句建模、基于問句感知圖卷積的子圖建模和答案預測與損失函數。
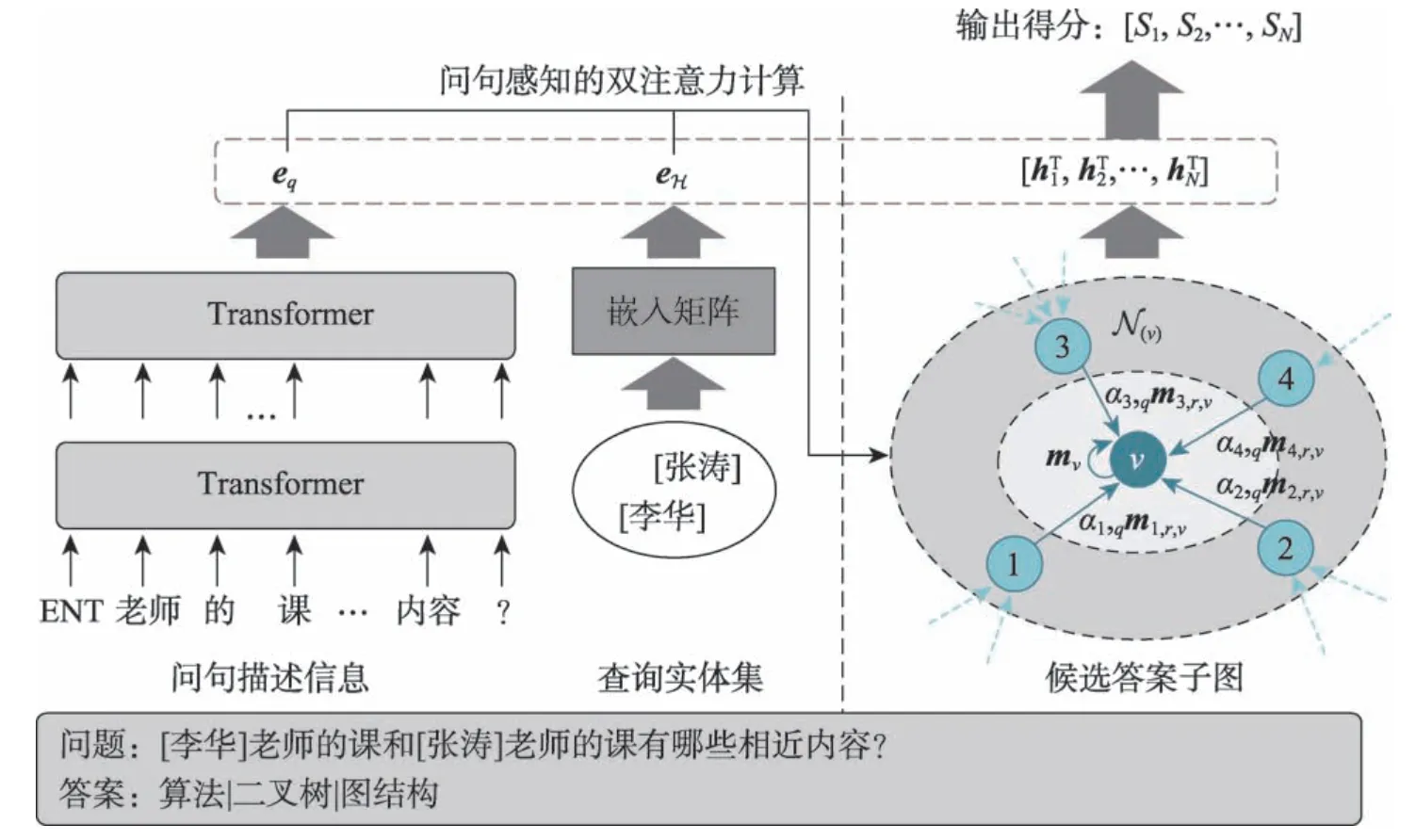
Fig.1 Overall architecture of proposed model圖1 模型框架示意圖
2.1 基于Transformer 和知識庫嵌入的問句建模
本文采用將問句描述與其待查詢實體分離的處理方式進行問句建模。具體地,問句描述能夠捕獲與實體無關的、更本質的意圖,而待查詢實體能夠根據原知識庫的結構信息進行建模,兩者在預測答案時采用信息融合中“late-fusion”的策略,實現完備的語義補充。針對問句,本文首先將其中的實體轉換為特殊符號“ENT”,之后使用中文分詞工具“結巴”進行分詞處理,得到問句的序列化表示形式q=[w1,w2,…,wn-1,wn],其中n表示句子長度,wi表示第i個詞。之后使用帶有多頭注意力的Transformer[17]進行建模,計算得到問句表示eq:
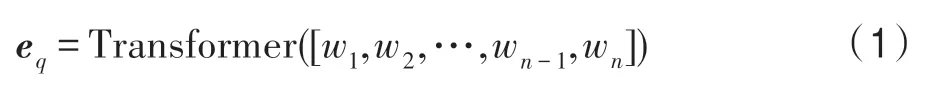
為了有效獲取待查詢實體在原知識庫中的結構信息,模型使用知識庫嵌入技術進行初始化向量表示,得到實體表示矩陣E(其中Ei表示實體i的嵌入向量)。本文默認采用DistMult[18]方法進行嵌入,嵌入方法對模型結果的影響見3.4.3 小節。基于此,查詢實體集合EH的表示eH可以通過實體嵌入向量均值的方式析出:

2.2 基于問句感知圖卷積的子圖建模
圖卷積神經網絡[19]由于其強大的圖結構建模能力而逐漸引起廣泛關注,它一般遵循迭代消息傳遞的模式來捕獲節點鄰域的結構化信息,其第k+1 層的表示通常基于第k層的表示進行圖卷積操作(消息傳遞機制)得到:
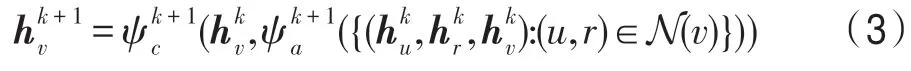
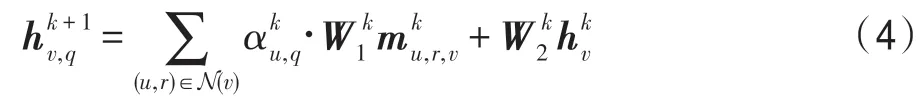

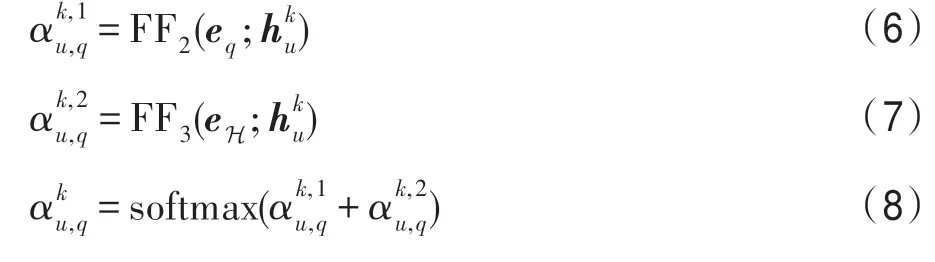
FF 表示前饋神經網絡層,符號“;”表示向量之間的拼接操作。通過式(6)和(7)的計算,圖卷積在信息傳遞時會綜合考慮問句描述信息和相應的查詢實體,因此與問句相關的信息會被增強而無關的信息會被削弱,進而模型能夠更好地建模實體表示并預測答案。在圖卷積網絡的最后一層,記錄子圖Gq中的節點表示用于最終答案預測。
2.3 答案預測與損失函數
基于前文中對問句和查詢子圖的建模,本文將問句表示、查詢實體表示和候選節點的表示進行拼接,并使用前饋神經網絡與sigmoid 函數計算得分:
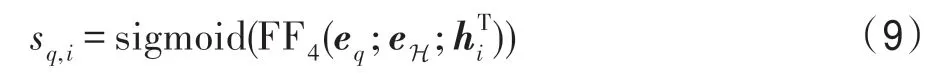
在答案預測時,根據以上計算選擇子圖中得分最高的實體作為答案。模型最后通過二分類交叉熵定義模型的整體損失函數:
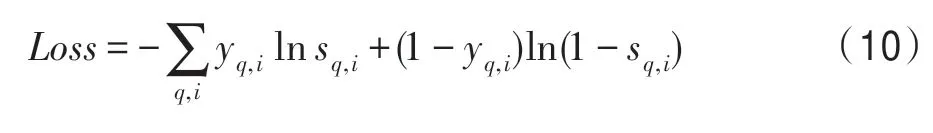
3 實驗結果和分析
3.1 實驗數據集
實驗數據集使用清華大學構建的大規模在線教育知識庫MOOCCube[3],并使用其中的MOOC Q&A數據集進行教育知識庫的問答實驗。該知識庫包含706 門真實在線課程、700 個概念和4 723 個用戶等7類實體,以及概念-領域、課程-視頻和概念先后修順序等10 類關系,總共構成52 195 個三元組。知識庫詳細統計信息如表1 所示。MOOC Q&A 中包含兩類問題:單跳(one-hop)和多跳(multi-hop)。單跳問題只涉及知識庫中的一個頭實體和一個關系,而多跳問題可能包含多個實體,且要回答這類問題需要對知識庫中的多個事實進行推理。單跳和多跳問題的數量分別為5 504、13 637,在進行實驗時,它們都按照80%、10%和10%的比例進行訓練集、驗證集和測試集的劃分。
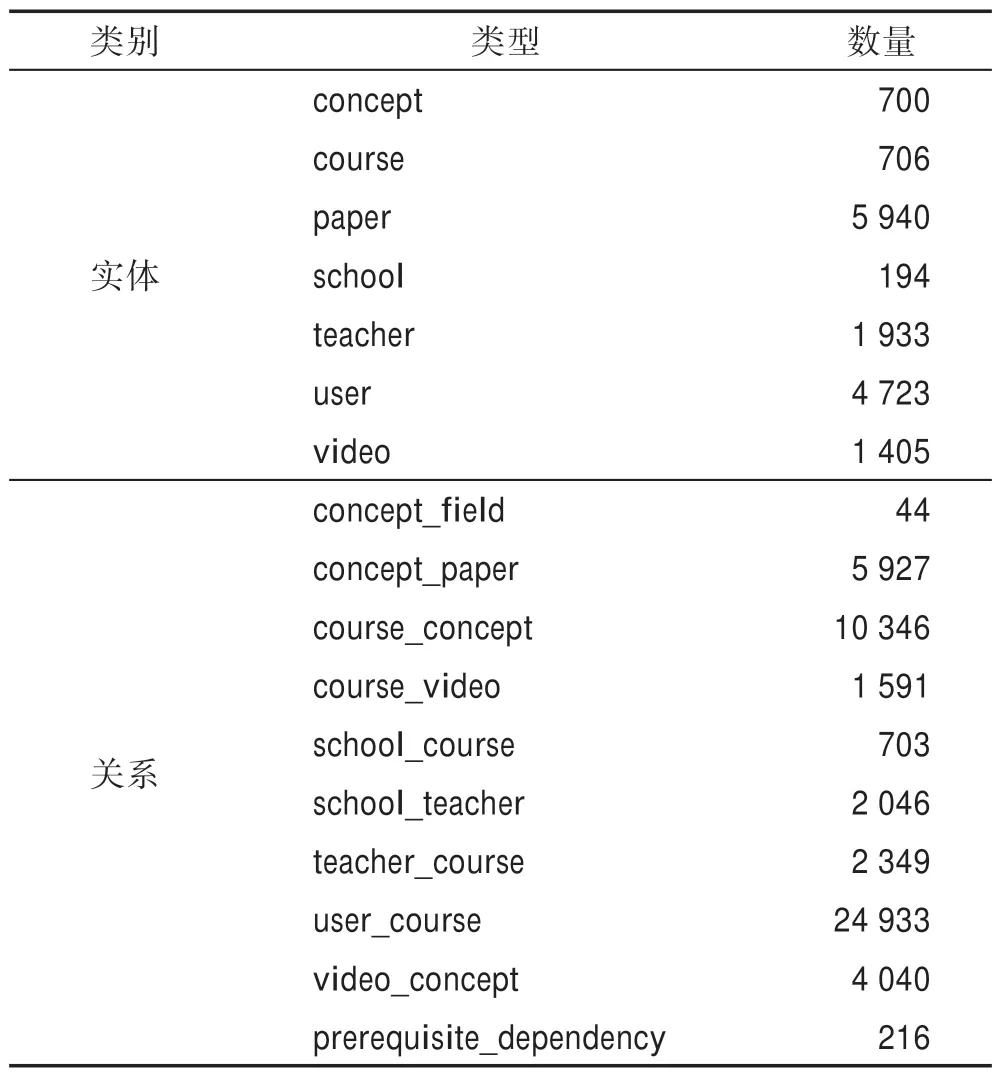
Table 1 Statistics of entities and relations in knowledge base of MOOC Q&A表1 MOOC Q&A 知識庫中實體和關系的統計
3.2 實驗參數設置
在進行實驗時,本文使用“結巴”分詞工具進行問句的分詞處理,并使用DistMult方法進行知識庫中實體的嵌入,默認嵌入維度為200。針對單跳和多跳問題,鄰近子圖Gq抽取時階數h分別設置為1 和2,類似地,圖卷積網絡的層數也相應設置為1 和2。詞語嵌入維度、Transformer 隱藏層維度和圖卷積網絡的維度都被默認設置為200,且每個前饋網絡層都采用ReLU 函數激活,并增加丟棄率為0.1 的Dropout 層以增強模型的泛化性能。在進行訓練時,本文使用學習率為0.002 的Adam 算法[20]進行優化,并將最大迭代次數設置為30。
3.3 對比模型與評價指標
為了驗證本文模型的有效性,實驗對比了當前最優模型EmbedKGQA[12]。該模型將問句視為知識庫中關系的單跳或多跳推理過程,進而將知識庫問答問題類比為鏈接預測任務,并通過鏈接預測的得分函數計算候選實體的得分。實驗中分別使用TransE[21]、DistMult[18]、ComplEx[16]和RotatE[22]作為得分函數進行答案預測。
本文選取預測準確率(accuracy,ACC)和平均倒數排名(mean reciprocal rank,MRR)作為性能評價指標。準確率ACC 衡量預測得分最高的實體是否出現在實際答案列表中,MRR 表示答案集中的實體在預測列表中平均倒數排名,它們的計算方式如下:
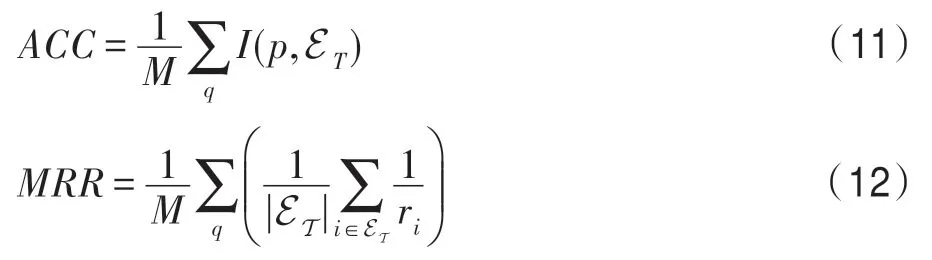
其中,M表示問句數量;ET為問題q的實際答案集合;p為模型預測得分最高的實體;函數I表示元素是否在集合中,其值域為{0,1};ri表示實體i在預測答案列表中的排名。
3.4 實驗結果與分析
3.4.1 實驗結果對比
本文模型與EmbedKGQA 方法在MOOC Q&A數據集上的性能對比如表2 所示。整體上,可以看出提出的模型在單跳和多跳問答的指標上都取得了優秀的性能。除了多跳的MRR 略小于(0.009)得分函數為ComplEx 的EmbedKGQA,其他指標都優于對比模型,其中相比使用TransE 的提升最大,4 個指標分別提升了0.129、0.120、0.241 和0.210。類似地,對比使用ComplEx 的最優EmbedKGQA,單跳的ACC、MRR 和多跳的ACC 也分別取得了0.011、0.008 和0.004 的提升。這顯示出本文模型的有效性。
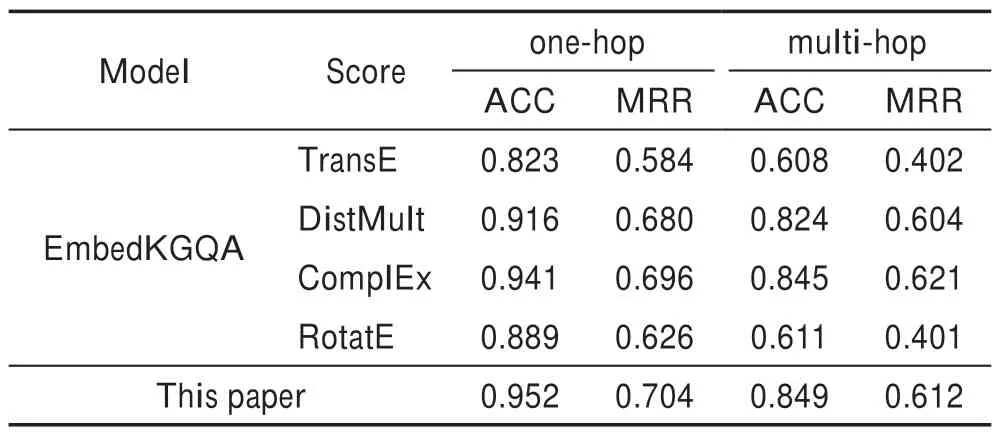
Table 2 Comparison of experimental performance表2 實驗性能對比
3.4.2 消融實驗
為了驗證本文提出的問句感知的雙注意力機制對于答案預測的真實作用,本文開展了注意力消融實驗。實驗結果如表3 所示,表中“注意力1”和“注意力2”分別指式(6)、(7)計算的關于問句描述信息和相應查詢實體的注意力。由表3 可知,消融某個或全部注意力得分都會降低實驗性能,說明每個注意力對于實驗性能的提升都具有積極作用。同時注意力2 的影響略高于注意力1,這從側面說明在進行圖卷積的候選答案建模時,模型會更注重考慮其與查詢實體之間的關聯。
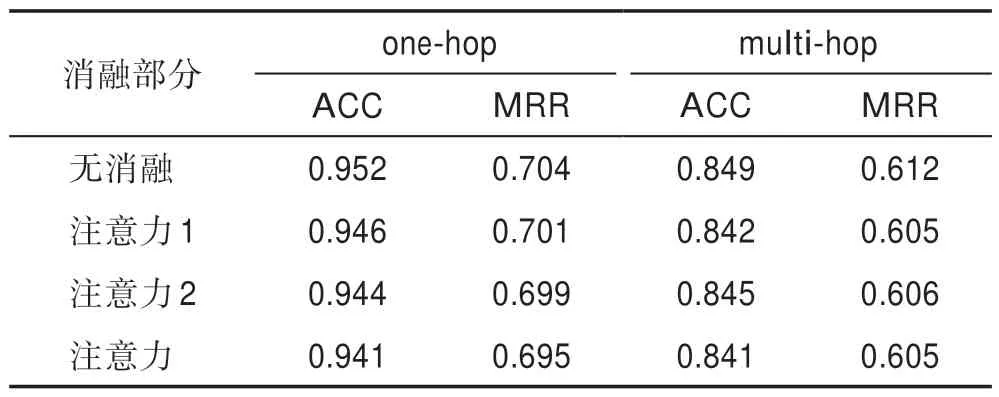
Table 3 Results of ablation experiments表3 消融實驗結果
3.4.3 特征初始化的影響
為了探究知識庫中實體的初始嵌入矩陣對于問答性能的影響,本文使用不同的初始化嵌入方法進行實驗。圖2 展示了使用TransE、DistMult、ComplEx和RotatE 時模型的性能對比。由此可知,初始化嵌入方法對模型整體的影響較小,模型在每種嵌入方法上都能取得良好的性能。
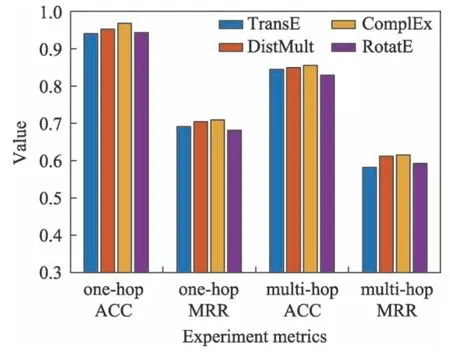
Fig.2 Impact of initialization embedding method on Q&A performance圖2 初始化嵌入方法對問答性能的影響
3.4.4 特征維度的影響
為了探究嵌入維度對實驗性能的影響,本文在區間[100,500]上以100 為步長進行了分組實驗。在實驗時,詞語嵌入維度、Transformer 隱藏層維度和圖卷積網絡的維度都被統一設置,實驗結果如圖3 所示。可以看出,當嵌入維度小于200 時,嵌入維度的增加會略微提升模型性能;當維度大于200 時,其對于模型的影響較小,模型的性能趨于穩定。
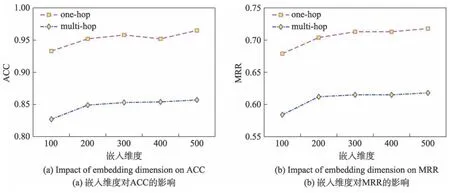
Fig.3 Impact of embedding dimension on performance圖3 嵌入維度對性能的影響
4 結束語
由于開放領域的知識庫與教育領域存在差異,且相關方法都相對獨立地進行候選實體建模,缺乏與問句的交互,基于此本文提出了基于問句感知圖卷積網絡,分別使用問句中的相關描述信息和查詢實體集計算圖卷積信息傳遞時的注意力得分,進而能夠學習到特定于問句的實體表示。實驗結果表明了該方法的有效性,且消融實驗證明了提出的兩個注意力對于預測性能都具有積極作用。
本文在進行問句建模時,使用了簡單的Transformer 進行處理,且并未考慮候選答案實體對其表示的影響。在以后的工作中,將考慮使用大規模預訓練語言模型進行更高效的問句建模,并考慮多種信息(如查詢實體和候選答案實體)之間的有效融合方式。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
