基于改進核極限學習機和集成學習理論的目標機動軌跡預測*
2021-10-10 04:15:52寇英信奚之飛李戰武楊愛武
國防科技大學學報 2021年5期
關鍵詞:模型
寇英信,奚之飛,徐 安,李戰武,楊愛武
(空軍工程大學 航空工程學院, 陜西 西安 710038)
軌跡預測是根據目標的歷史運動軌跡,學習和推理其包含的內在信息,進而對目標未來的運動趨勢做出合理推測的過程。在空戰對抗過程中,對敵方目標的未來運動軌跡做出合理的預測具有重要意義。現代空戰獲取勝利的關鍵在于先于敵方形成觀察—判斷—決策—行動(Observation Orientation Decision Action, OODA)循環,從而達到先發制人的目的[1]。而實現這一切的基礎是能夠對目標機動軌跡進行精確預測,因此探索一種能夠對目標機動軌跡實現準確預測的理論方法具有重要意義。
近幾年,對于目標機動軌跡預測方法的研究方向主要分為兩種。
一種是參數法,主要包括卡爾曼濾波、α/β濾波以及線性回歸等傳統預測方法。例如文獻[2]針對目標運動模式不斷變化、機動幅度較大的情況,提出一種基于多項式卡爾曼濾波的運動軌跡預測算法;文獻[3]針對目標歷史位置信息存在缺失的情況,提出一種融合系統噪聲估計的改進卡爾曼濾波算法;文獻[4]針對傳統軌跡預測算法存在預測精度低以及算法實時性差的不足,提出一種基于卡爾曼濾波的動態軌跡預測算法;文獻[5]針對精確目標運動模型存在高度非線性、數據處理難度大以及預測精度低等問題,提出一種改進的交互式多模型軌跡預測算法。上述預測方法都只適用于目標運動特性相對簡單的軌跡預測問題,但是在實際空戰中,目標的運動往往是高度復雜的時序動態變化過程,目標的運動受到多種因素的影響,傳統的預測算法無法充分學習目標的機動特性;同時,為了更加準確地描述目標的運動,在建模時一般模型的復雜度較高,導致預測算法的實時性和適應性較差,從而無法滿足空戰對抗的需求。
另一種是以神經網絡為核心的非參數預測算法,主要基于目標歷史運動數據對目標未來機動軌跡進行預測。例如:文獻[6]基于廣義回歸神經網絡(Generalized Regression Neural Network, GRNN)良好的非線性映射能力、高度的容錯性以及魯棒性,提出一種基于GRNN的高超聲速飛行器軌跡預測方法;文獻[7-8]針對逆傳播(Back Propagation,BP)神經網絡存在對初值敏感且全局搜索能力較差的不足,分別提出一種基于遺傳算法和粒子群算法優化的BP神經網絡軌跡預測模型。非參數法不需要建立準確的目標運動模型,也能實現對目標機動軌跡的精確預測,但是這些方法需要通過煩瑣冗長的迭代訓練才能達到精確預測的目的,并且神經網絡在訓練的過程中容易陷入局部最優解,因此在實際預測中很難達到最佳的預測效果。
無論是參數法還是非參數法,應用到目標機動軌跡預測中,在實時性、精確性和模型復雜性等方面都存在一定的不足。總體而言,參數方法的特點是預測性能與模型精度成正相關,主要存在模型學習能力不足、難以處理模型內在不確定性及目標運動數據突變影響預測精度等缺點。非參數方法則基于數據挖掘和神經網絡[9]等方法根據目標歷史機動軌跡數據學習數據變化的內在規律,建立輸入輸出映射關系。其缺點是預測精度對歷史數據的數量和質量依賴程度高,且模型參數確定難度較大。受空戰對抗以及空戰環境等不確定因素影響,實際目標機動軌跡數據具有較強的非線性、時變性和易受隨機噪聲影響等特征。現有目標機動軌跡預測建模方法存在模型參數確定困難、預測精度不高和泛化能力較差等不足,難以滿足復雜空戰環境下的目標機動軌跡預測的要求。此外,采用單一預測模型對目標機動軌跡進行預測時往往采用給定的全部訓練樣本進行全局建模,導致需要建立具有復雜結構的全局模型對大量樣本支撐的復雜假設空間進行全局逼近[10],從而進一步增加預測模型的優化難度。另外,全局預測模型容易出現對樣本數據局部信息利用不充分的情況,導致難以完整描述訓練樣本支持的假設空間,進而影響目標機動軌跡的預測精度。
為了克服參量法和非參量法以及單一全局建模存在的不足,本文提出一種基于改進的(Kernel Extreme Learning Machine, KELM)和集成學習理論的目標機動軌跡預測模型。以AdaBoost.RT算法為集成框架,KELM神經網絡為弱預測器,通過不斷訓練得到強預測器。為了進一步提高模型的預測性能,一方面針對KELM神經網絡的預測性能容易受到懲罰系數和核參數的影響的問題,利用改進的蝙蝠算法對這兩個參數進行尋優,確定最佳的模型參數;另一方面,考慮到AdaBoost.RT算法存在對閾值敏感的不足,提出一種自適應閾值的AdaBoost.RT算法。
1 核極限學習機
極限學習機(Extreme Learning Machine,ELM)是一種新型性能優良的單隱含層前向神經網絡。與傳統的神經網絡相比,ELM神經網絡只需要一步即可確定網絡的輸出權值,極大地提高了網絡的泛化能力和學習效率,具有良好的非線性擬合能力,算法的計算復雜度和搜索空間也大大減小[11]。ELM神經網絡的結構如圖1所示。
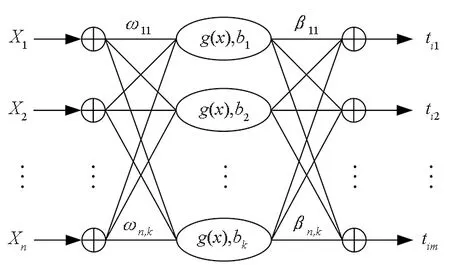
圖1 ELM神經網絡結構Fig.1 Structure of ELM neural network

(1)
式中,ωi為第i個隱含層節點與輸入層節點之間的權值向量;bi為ELM的第i個隱含層節點的閾值;βi為隱含層節點與輸出層之間的權值;yj為ELM的輸出值;gi(ωi·xj+bi)為第i個隱含層節點的激活函數。

(2)
上述的N個方程可以表述為:
Hβ=T
(3)
H(ω1,…,ωK,b1,…,bK,x1,…,xN)=
(4)
式中:H為ELM神經網絡的隱含層輸出矩陣;T為樣本真實值構成的矩陣。
通過求解Hβ=T的最小二乘解,即可得到最優的權值β*使得實際值與預測值之間的誤差趨近于零。根據求解廣義逆的相關理論,最優權值可解算為:
β*=H?T
(5)
式中,H?為ELM隱含層輸出矩陣的Moore-Penrose廣義逆。其值可以通過正交投影法或者采用奇異值分解(Singular Value Decomposition,SVD)等方法解算得到[12]。
在對ELM網絡進行訓練時,如果ELM神經網絡的隱含層節點數與樣本數相等,ELM能夠零誤差擬合所有訓練樣本。由于在實際應用中需要考慮算法的實時性,故隱含層的節點數通常取值小于訓練樣本數目,訓練樣本可能存在復共線性問題[13],從而導致ELM神經網絡的穩定性和泛化能力都不太理想。
為了進一步增強ELM算法的泛化能力和穩定性,Huang等[14-15]通過對比分析ELM和支持向量機(Support Vector Machines, SVM)的機理,提出將核函數引入ELM,構造KELM[16]。
1)基于Mercer′s條件定義核矩陣:
(6)
式(6)用核矩陣Ω來代替ELM中的隨機矩陣HHT,利用核函數將ELM網絡的所有輸入樣本從低維度空間映射到高維度隱含層特征空間。在核函數的參數設定之后,核矩陣的映射是定量。h(x)為ELM網絡隱含層節點的輸出函數;核函數K(μ,v)主要采用徑向基函數(Radial Basis Function,RBF)核函數、線性核函數和多項式核函數等,通常設定為RBF核函數。
K(μ,v)=exp[-(μ-v2/σ)]
(7)
2)將參數I/C增加到單位對角矩陣HHT中的主對角線元素上,使得單位對角矩陣的特征根不為零,再基于此確定權值向量β*。這樣的處理使得ELM具有更好的穩定性和泛化能力。此時的ELM神經網絡的輸出權值可描述為:
β*=HT(I/C+HHT)-1T
(8)
式中:I為對角矩陣;C為懲罰系數,主要用作平衡結構風險和經驗風險之間的比例;HHT是通過核函數將輸入樣本進行映射得到的。
由以上公式可以得到KELM的輸出為:
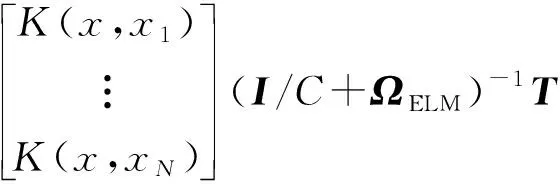
(9)
式中,KELM模型的輸出權值可以描述為:
β=(I/C+ΩELM)-1T
(10)
2 改進的集成學習算法
基于單一的KELM神經網絡對目標機動軌跡進行預測時,由于KELM神經網絡的預測性能容易受到懲罰系數和核參數的影響,為了提高目標機動軌跡預測的精度,引入集成學習理論,以改進的AdaBoost.RT算法為集成框架,將KELM神經網絡作為弱預測器,提出一種基于KELM-AdaBoost.RT算法的目標機動軌跡預測模型。基本思想是預先設定一個閾值φ,利用樣本數據對KELM神經網絡進行訓練,然后根據KELM神經網絡的預測結果來更新訓練樣本的權值,保持各個弱預測器KELM的訓練樣本不變,基于新的權重對弱預測器繼續進行訓練,以此不斷循環,訓練M輪得到M個弱預測器,給每一個弱預測器的輸出賦一個權值,將所有弱預測器的輸出加權得到最終預測結果。KELM-AdaBoost.RT集成學習算法流程如圖2所示。
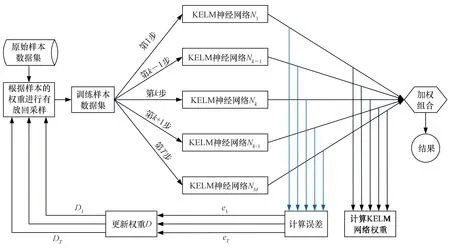
圖2 KELM-AdaBoost.RT集成學習算法流程Fig.2 Flow chart of KELM-AdaBoost.RT integrated learning algorithm
由于AdaBoost.RT算法的性能受閾值的影響較大,數值過大過小都會影響算法的性能,因此閾值的確定難度較大。此外,在樣本權重進行更新時,預測精度較低的樣本在下一輪迭代中的權重保持不變,導致樣本之間的區分度不大。針對AdaBoost.RT算法存在的不足,提出兩點改進策略:引入自適應閾值和增加預測誤差大的樣本權重。改進的KELM-AdaBoost.RT算法實施過程描述如下。
步驟1:確定樣本數據和初始化KELM網絡。
步驟2:初始化訓練樣本的權值Dj(i)=1/N(i=1 , 2 ,… ,N),設定算法的初始閾值φj和初始預測誤差ej。
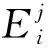
(11)
(12)
其中:hj(xi)為訓練樣本i第j次迭代計算的預測值;ti為真實值。
步驟4:更新預測誤差閾值。根據KELM預測誤差自適應調整閾值。基于KELM神經網絡的訓練誤差的閾值自適應調整策略為:
(13)
步驟5:更新訓練樣本權值。計算第j+1輪算法訓練樣本的權值,其更新公式為:
(14)
其中,Bj為歸一化因子。
步驟6:重復上述步驟T輪,得到T個弱預測器KELM,每一個弱預測器的輸出可以表示為ft(x)(t=1 , 2 ,…,T),加權得到強預測器輸出:
(15)
3 改進的蝙蝠算法
由于KELM的性能與懲罰系數和核參數的選擇密切相關,為了提高KELM的預測性能,引入改進的蝙蝠算法(Improved Bat-inspired Algorithm,IBA)對KELM的懲罰系數和核參數進行優化。蝙蝠算法(Bat-inspired Algorithm, BA)相對于經典的粒子群算法引入了局部搜索,具有更好的搜索能力,有助于算法跳出局部最優,因此相對于傳統的智能算法具有更好的優化能力。
蝙蝠算法是一種新的元啟發式智能優化算法,相較于粒子群算法和遺傳算法[17]具有明顯的優勢。與粒子群算法相似,BA隨機初始化種群,蝙蝠個體進行如下位置和速度更新:
fi=fmin+(fmax-fmin)β,β∈[0,1]
(16)
(17)
(18)
BA的獨特之處在于其結合了局部搜索。在進行局部搜索時,蝙蝠個體將在最優個體附近采取隨機搜索的方式進行局部尋優,具體可以表示[18]為:
Xnew=Xold+εAt
(19)
式中,ε為取值在0和1之間的隨機數;At為當前所有蝙蝠群體的平均響度。
隨著算法進化程度的增加,蝙蝠個體的響度Ai和強度ri也在不斷變化,變化過程可以表述[19]為:
(20)
(21)
其中,α和γ是常量。
每一次迭代計算之后都需要找到最佳位置X*,直到滿足算法的結束條件,輸出全局最優位置。
蝙蝠算法與粒子群算法、遺傳算法等群智能算法相比具有更好的優化性能,但是在收斂精度和收斂速度上還存在著不足。因此,為了提高蝙蝠算法的優化性能,避免算法陷入局部最優解,提高算法的收斂速度和精度,本文借鑒粒子群算法尋優過程[20]。借鑒粒子群算法的粒子位置更新策略,以提高算法的局部搜索能力和優化精度[21],對蝙蝠局部搜索策略做出以下改變:
(22)
式中,β和ρ為取值在0和1之間的隨機數。
為了使算法的局部搜索能力和全局搜索能力達到平衡,將脈沖速率變化率α改進為動態變化的參數,借鑒模擬退火算法中冷卻進程表中的冷卻因素,對其進行如下改進[22]:
(23)
4 基于改進的蝙蝠算法優化的KELM-AdaBoost.RT目標機動軌跡預測模型
針對目標機動軌跡預測問題,將改進的AdaBoost.RT算法與經過改進蝙蝠算法優化的KELM神經網絡相結合,提出一種基于改進蝙蝠算法優化的KELM-AdaBoost.RT目標機動軌跡預測模型,流程如圖3所示,具體實施步驟如下所示。
步驟1:輸入訓練樣本數據,初始化蝙蝠算法以及AdaBoost.RT算法的參數。
步驟2:采用改進的蝙蝠算法優化KELM神經網絡的參數。
步驟3:利用改進的蝙蝠算法優化的KELM神經網絡進行訓練,生成弱預測器,用訓練好的弱預測器對所有訓練樣本進行預測并計算預測誤差。基于弱預測器的預測誤差對樣本權值和算法閾值進行調整,直至滿足算法終止條件,得到基于若干個KELM弱預測器構成的強預測器。
步驟4:利用訓練好的強預測器對目標未來機動軌跡進行預測,輸出預測結果。
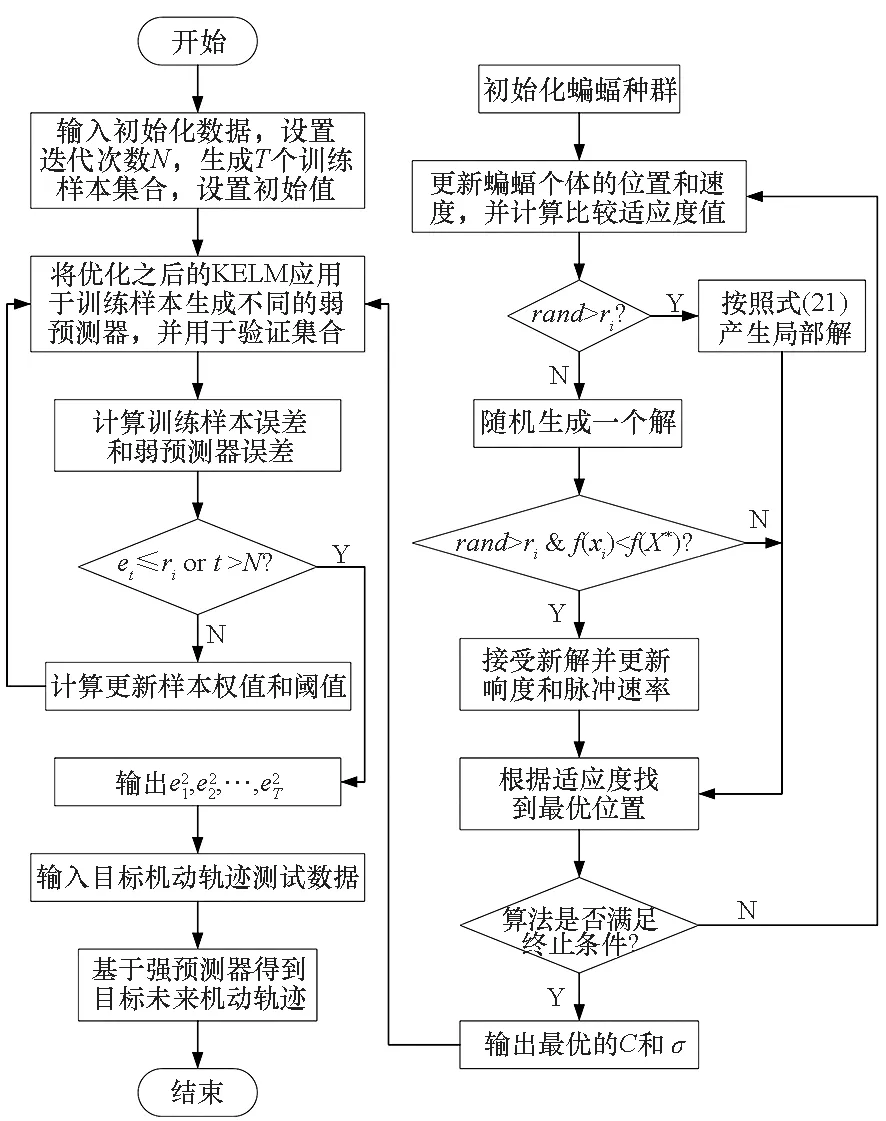
圖3 目標機動軌跡預測流程Fig.3 Flow diagram of the target maneuver trajectory forecasting
5 仿真分析
5.1 數據預處理
利用從空戰對抗訓練系統(Air Combat Maneuvering Instrument,ACMI)中提出的時間連續的4 000組飛行軌跡數據,數據之間的間隔為0.25 s,每一個數據組包括目標的三維坐標。以對目標軌跡x坐標進行預測為例,假設利用目標n個歷史軌跡數據,預測第n+1時刻的目標軌跡x坐標。輸入與輸出之間的函數關系可表達為:
x1+n=f(Xn)
(24)
式中:x1+n為第n+1時刻模型的輸出;Xn為第n+1時刻模型的輸入。對于預測模型的輸入數據,可以通過采用C-C法對歷史目標機動軌跡x坐標時間序列進行相空間重構得到,可表示為:
(25)
式中:τ為時間延遲;m為嵌入維數。
5.2 實驗設置
將目標機動三維坐標分離單獨進行預測,以x坐標為例,采用C-C法[23]確定時間延遲和嵌入維數,以確定的嵌入維數作為KELM神經網絡的輸入節點數。由于本文對目標機動軌跡進行單步預測,故輸出節點數為1。
各個算法的參數設置如下:KELM神經網絡的核函數采用RBF核函數,懲罰參數C和核參數σ通過改進的IBA算法尋優得到;IBA的最大循環次數為200,種群規模為50,蝙蝠的最大和最小頻率為2和0,初始化響度為1,脈沖速率為0.5;KELM弱預測器數目為20,閾值初始化為0.2。
將改進前后的BA性能進行了對比,證明了IBA的優越性;在此基礎上構建ELM和KELM預測模型,結合AdaBoost.RT算法,分別建立基于ELM-AdaBoost.RT和KELM-AdaBoost.RT的預測模型,同時還構建基于BP和SVM的目標機動軌跡預測模型,仿真對比這六種預測模型性能優劣。
5.3 算法的優化性能對比
5.3.1 算法收斂準則
蝙蝠優化算法的收斂準則是基于整個群體收斂的,以最優群體為搜索目標,但是最終需要的是解空間中的一個最優個體,并不要求整個群體最優。為此基于算法中最優個體保存策略,可以觀察到種群最優個體的進化情況。如果最優個體經過若干次進化沒有被更新,或者變化的幅度較小,則可以認為算法已經收斂。可以將算法的收斂判斷依據表示為:
(26)

如果蝙蝠個體的全局最優位置的適應度值連續ξ次變化滿足式(26),則認為算法已經收斂。
5.3.2 算法性能評價指標
為了更加客觀準確地評價改進前后蝙蝠算法的性能差異,選取四個評價指標對算法性能進行評價[24]。
1)收斂率(Converge Ratio,CR):算法成功收斂次數與算法執行總次數的比值,反映算法的可收斂性。
2)平均迭代次數(Average Iteration Times,AIT):對算法進行多次仿真實驗,得到算法成功收斂時的平均迭代次數,反映算法的收斂速度。
3)平均迭代運行時間 (Average Iteration Running Time,AIRT):算法運行最大迭代次數所需的平均中央處理器(Central Processing Unit,CPU)時間,反映算法的實時性。
4)迭代次數標準偏差(Iteration Times Standard Deviation,ITSD):算法成功收斂時迭代次數的標準偏差,反映算法的收斂穩定性。
5.3.3 仿真實驗與結果分析
在對目標機動軌跡的三維坐標分別建立模型進行預測時,采用IBA對KELM神經網絡進行優化。為了對比改進前后的蝙蝠算法性能變化,分別采用改進前后的蝙蝠對KELM神經網絡進行30次優化仿真,算法性能對比見表1。
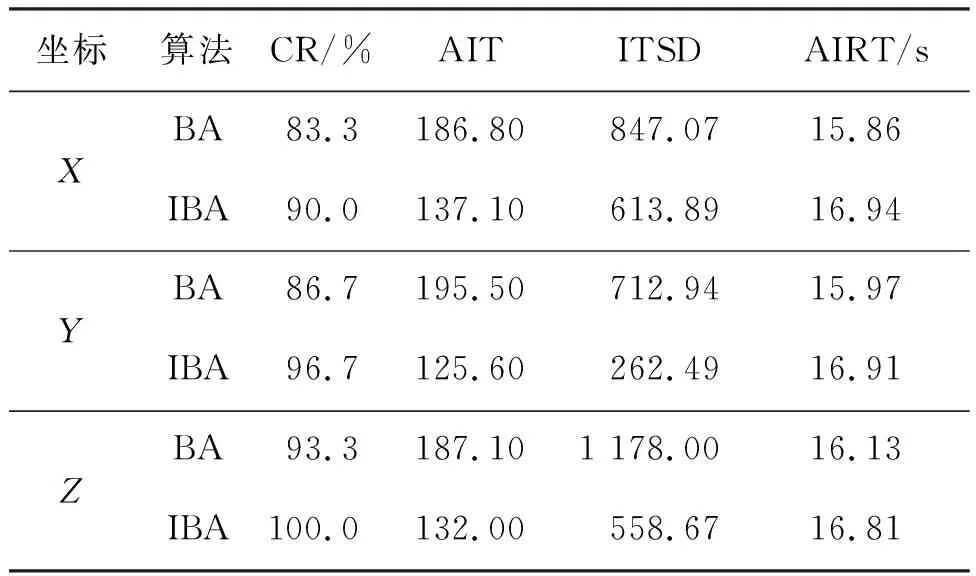
表1 算法性能對比
評價指標CR體現了算法的收斂性,CR越大,這說明算法的收斂性越好,通過表1中CR的數值可以看出,改進策略能有效提高蝙蝠算法的收斂性;評價指標AIT體現了算法的收斂速度,AIT越小,則算法的收斂速度越快,通過表中的AIT數值可知,改進之后的蝙蝠算法收斂速度明顯加快;評價指標ITSD反映了算法性能的穩定性,通過表中數值可知,改進之后的蝙蝠算法優化同一個問題的性能更加穩定;評價指標AIRT反映了算法的實時性,通過表1可以看出,改進之后的算法實時性有一定程度的降低,這是由于改進之后的算法的復雜度變高了,從而影響了算法的實時性。
通過圖4中算法的平均適應度下降曲線對算法的收斂過程做進一步分析。在圖4(a)中,BA和IBA的適應度函數值達到穩定時的迭代次數分別是87,72;在圖4(b)中,BA和IBA的適應度函數值達到穩定時的迭代次數分別是96,82;在圖4(c)中,BA和IBA的適應度函數值達到穩定時的迭代次數分別是113,68。這說明IBA收斂速度更快。通過圖4可以看出,IBA對KELM進行優化時的最終收斂數值都小于BA,這說明IBA具有更佳的收斂精度,適用于優化KELM算法參數。
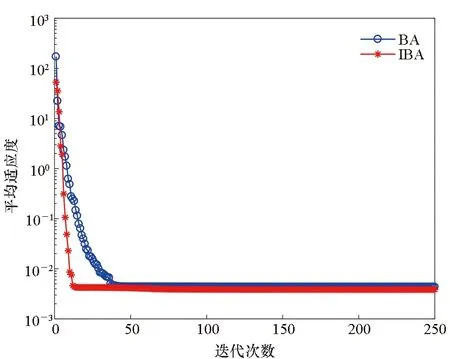
(a) X坐標下平均收斂曲線對比(a) Comparison of average convergence curve in X coordinate
5.4 預測模型仿真對比分析
利用ACMI記錄的目標機動軌跡歷史數據對KELM神經網絡進行訓練,使其具備預測目標未來機動軌跡的能力。不僅KELM神經網絡的參數會對其學習和預測能力造成影響,KELM神經網絡的訓練樣本規模也會對其性能造成影響。因此,在確定KELM輸入輸出結構以及網絡參數的基礎上,研究和分析樣本大小對預測誤差的影響尤為重要。
為了更加客觀地評價本文預測模型的有效性,從ACMI系統中提取兩組數據作為預測模型訓練和測試的樣本數據,樣本設置見表2。
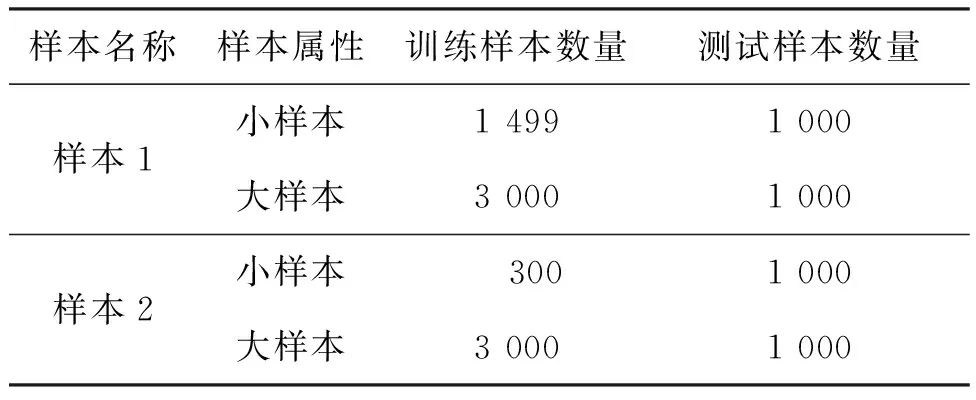
表2 仿真樣本設置
表2中大樣本的訓練數據包含了小樣本的訓練數據。根據六個預測模型的預測結果,繪制BP,ELM,KELM,ELM-AdaBoost.RT,KELM-AdaBoost.RT和SVM模型基于不同規模樣本數據的預測結果對比圖。仿真分為兩個部分:第一個部分采用樣本1中的大小樣本,樣本1中的大小樣本的數量差異不大,通過該樣本對比說明訓練樣本的變化是否會對模型的預測結果造成影響;第二個部分采用樣本2進行仿真實驗,樣本2的大小樣本的訓練數據存在量級差異,通過該樣本對比說明樣本的量級差異將會對模型的預測結果產生一定的影響。
為了進一步檢測目標機動軌跡預測模型的預測效果,用平均絕對誤差(Mean Absolute Error, MAE)、均方誤差(Mean Square Error, MSE)、歸一化均方誤差(Normalized Mean Square Error, NMSE)以及相關系數(Correlation coefficient, Cor)等指標對模型預測性能進行評價,定義如下所示:
(27)
(28)
(29)
(30)
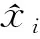
5.4.1 樣本數量差異仿真
圖5~7為目標預測結果對比情況。通過圖5~7中的BP、SVM、ELM以及KELM模型的預測結果以及誤差對比可以看出,四種預測模型的預測值與目標機動軌跡的實際值的變化大體上保持一致,這說明四種基本模型可以對目標機動軌跡進行有效預測。但是從整體上可以看出,基本的KELM模型預測結果相較于其他模型更加接近真實值。
通過圖5~7中的ELM、ELM-AdaBoost.RT、KELM以及KELM-AdaBoost.RT模型的預測結果以及誤差對比可以看出,結合了AdaBoost.RT算法的ELM和KELM模型的預測結果相較于基本的ELM和KELM模型而言誤差更小,且在目標機動軌跡波動時也能對其進行很好的預測,這些都說明AdaBoost.RT算法能夠有效提高弱預測器的預測性能,并且具有更好的泛化性能。
通過圖5~7中的圖(a)和圖(b)對比可以看出,訓練樣本較小差異將會對模型預測結果造成影響,同時也可以看出本文預測模型可以處理樣本較少的情況。通過曲線對比可以初步看出,訓練樣本規模較大時,模型的預測結果更加精確,并且在數據波動時的預測效果也表現得更好一些。
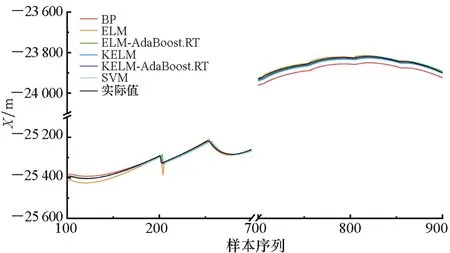
(a) 樣本量為2 499(a) Sample size was 2 499

(a) 樣本量為2 499(a) Sample size was 2 499
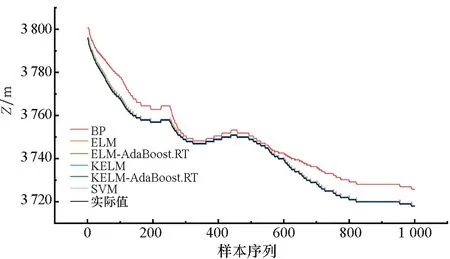
(a) 樣本量為2 499(a) Sample size was 2 499
為了進一步說明本文預測算法的預測效果,表3~5定量比較了BP,ELM,KELM,ELM-AdaBoost.RT,ELM-AdaBoost.RT和SVM模型基于不同規模樣本數據的預測性能。
通過表3~5數據可以發現,與小樣本的預測結果相比,較大的樣本量將導致神經網絡在預測過程中生成的MAE、MSE和NMSE略有減小,同時相關系數Cor也略有增加,這說明預測結果與真實值之間的接近程度高,可以很好地反映真實數據的情況。通過數據分析可知,MAE、MSE、NMSE算法性能評價指標與樣本量的大小呈負相關,樣本容量越大,評價指標的數值越小;而相關系數Cor與樣本量成正相關,這些都可以說明樣本的大小將會對預測性能產生一定的影響。從算法預測機理上對上述現象進行分析可知,較大的樣本量可以更好地訓練預測模型,使得模型可以更好地學習和了解目標歷史機動軌跡的內在規律,從而可以實現對目標未來機動軌跡更精確的預測。因此,樣本量越大,訓練之后的預測模型中包含的目標運動的歷史信息就越多,誤差也就越小。
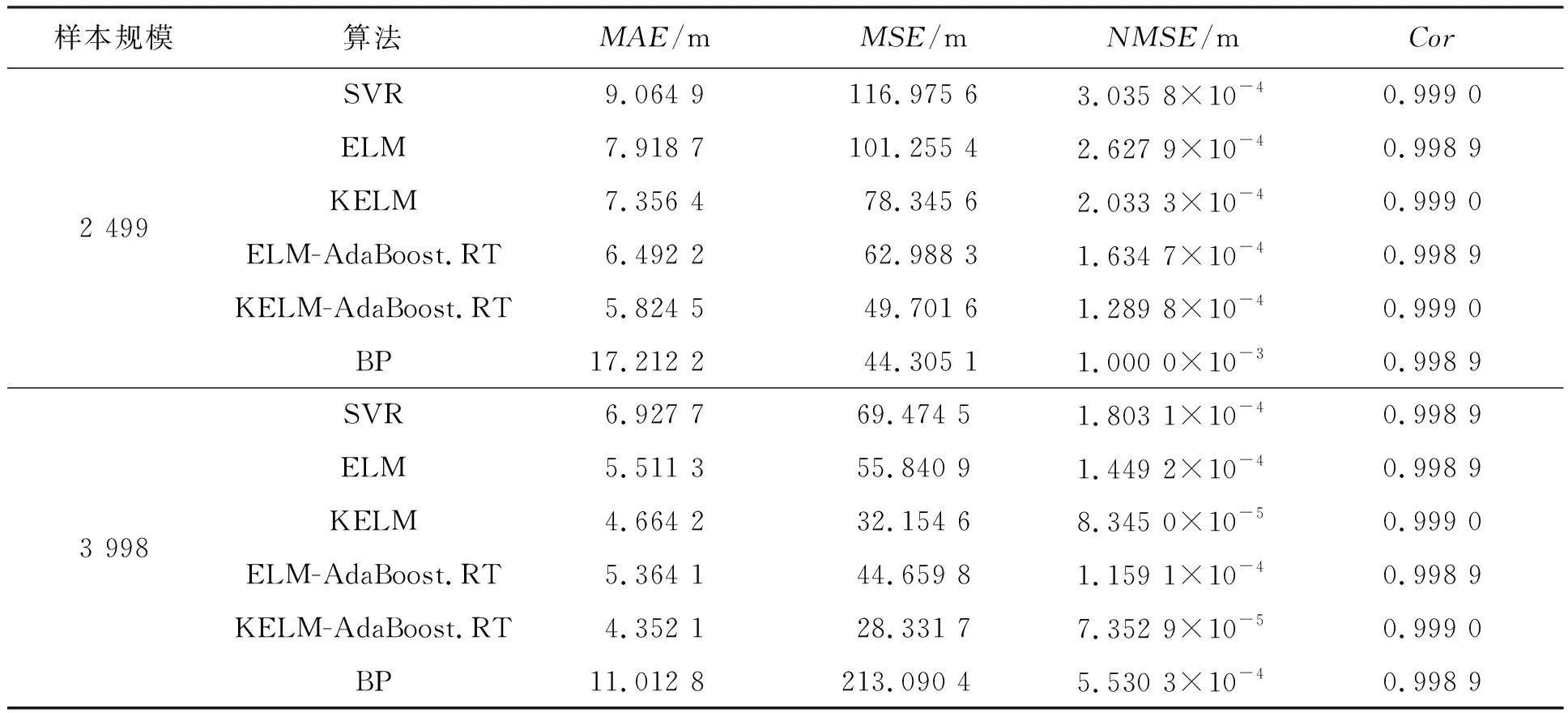
表3 不同預測模型對目標X坐標預測性能對比

表4 不同預測模型對目標Y坐標預測性能對比

表5 不同預測模型對目標Z坐標預測性能對比
通過表3~5可以看出,結合了AdaBoos.RT算法的ELM和KELM模型的預測性能相較于基本的ELM和KELM模型而言更優,這些都充分說明AdaBoos.RT算法能夠有效提高弱預測器的預測性能。
5.4.2 樣本量級差異仿真
為了進一步說明訓練樣本的規模差異將對模型的預測結果造成一定程度的影響,利用樣本2進行仿真驗證。在進行仿真實驗時,將大小樣本的規模設置為300和3 000,從而體現大小樣本之間的量級差異對模型預測結果的影響。基于大小樣本采用六種預測模型的預測結果對比如圖8~10所示。
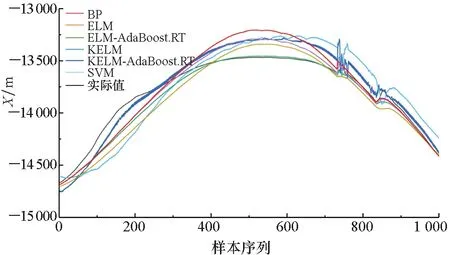
(a) 樣本量為300(a) Sample size was 300
通過圖8~10的對比結果,結合5.4.1節中的仿真結果可以看出,不論是樣本規模存在量級差異,還是僅僅存在一定的數量差異,都會對模型的預測結果產生一定的影響。通過模型的預測性能的對比分析,可以進一步分析樣本規模的量級差異對模型預測效果的影響程度。表6~8給出了六種預測模型基于不同規模樣本的預測性能。
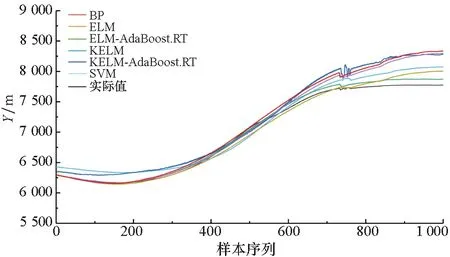
(a) 樣本量為300(a) Sample size was 300
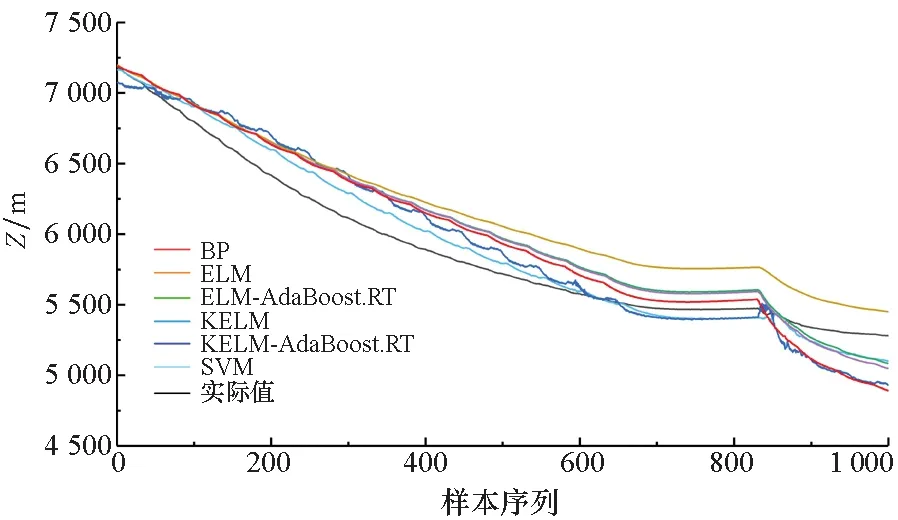
(a) 樣本量為300(a) Sample size was 300
通過對比表3~5與表6~8中對應預測模型的性能指標,可以看出,樣本規模差異越大,模型的預測性能差異也越明顯。通過對比指標數據可以看出,樣本的規模的不同導致了部分算法的MSE和NMSE指標出現量級差異,這都充分說明了訓練樣本的規模將會對模型的預測性能造成較大的影響。同時,也可以看出本文預測模型可以處理樣本的較少的情況,模型的泛化能力較強。本質上,樣本的大小反映了模型可以學習的歷史信息的多少,歷史信息越多,模型的預測結構越完整,泛化能力越強,從而模型的預測性能也越好。
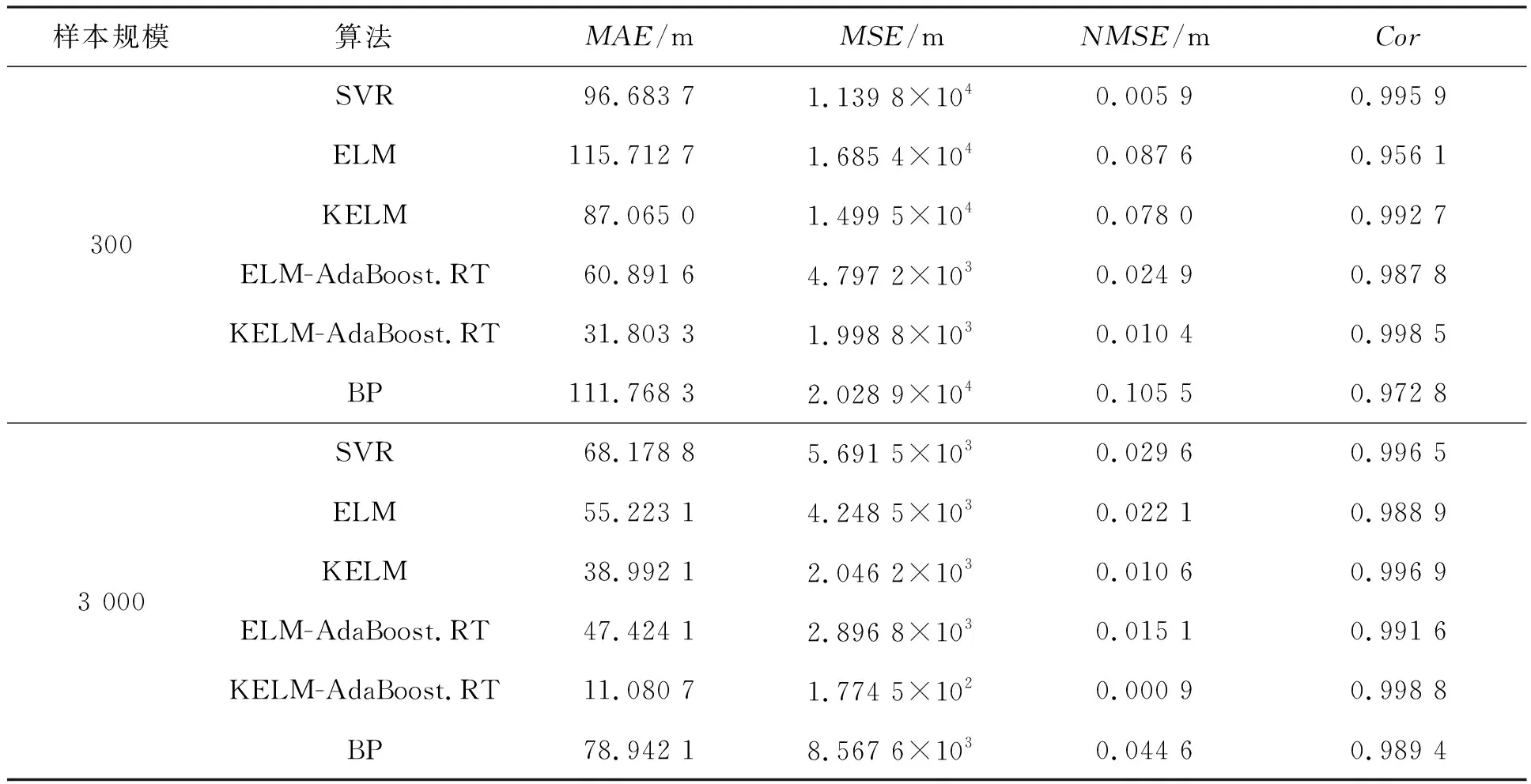
表6 不同預測模型對目標X坐標預測性能對比
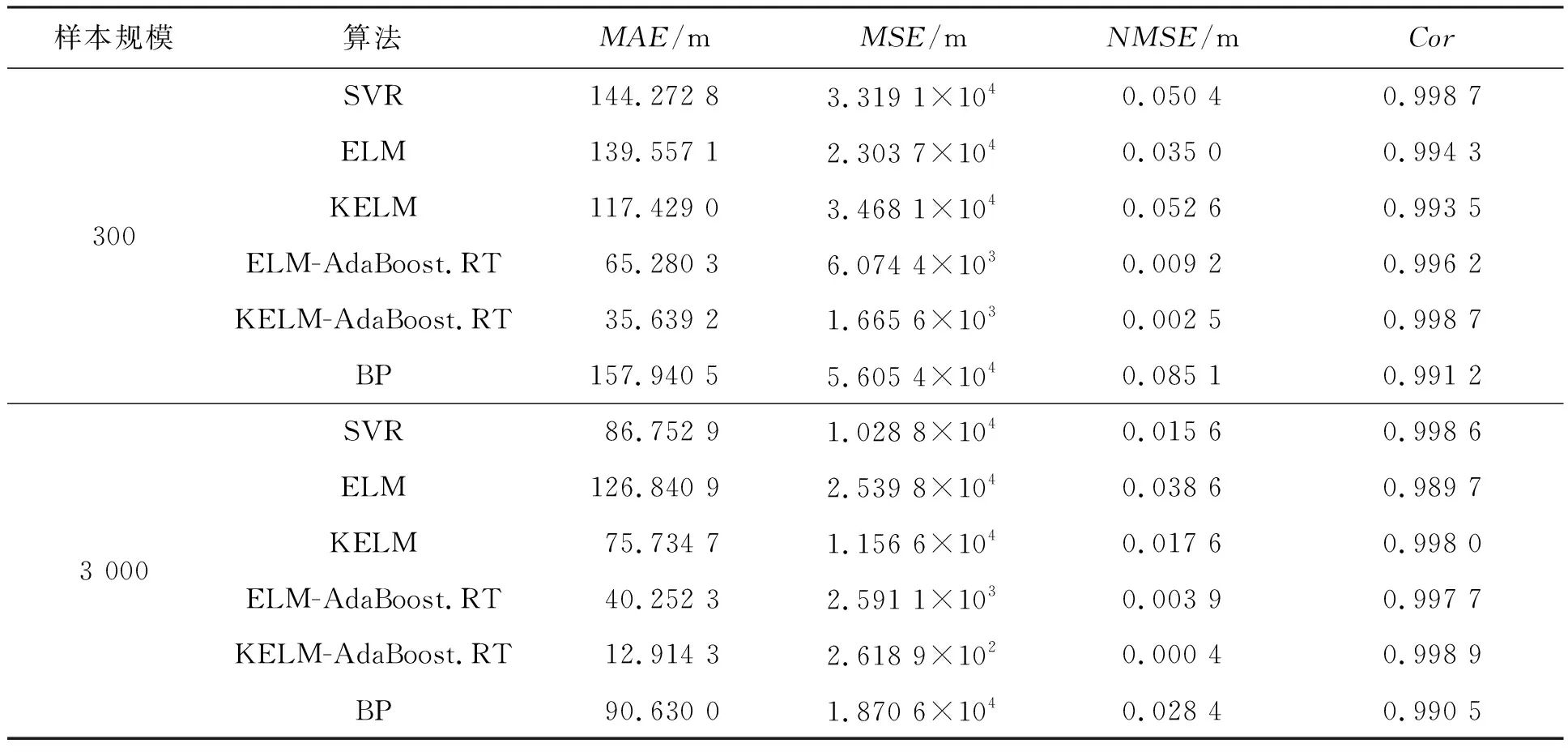
表7 不同預測模型對目標Y坐標預測性能對比

表8 不同預測模型對目標Z坐標預測性能對比
6 結論
針對目標機動軌跡預測問題,借鑒集成學習理論,將集成學習理論與KELM神經網絡相結合,構造一種基于KELM的強預測器模型。基于ACMI記錄的目標歷史機動軌跡數據,對模型進行訓練學習,進而將其應用于目標機動軌跡預測。基于理論分析和仿真驗證,可以得到以下結論:
1)從算法性能指標對比結果來看,KELM-AdaBoost.RT模型以及ELM-AdaBoost.RT模型的預測結果相較于KELM預測模型和ELM預測模型好。這些說明基礎學習理論可以有效提高弱預測器KELM的預測精度。
2)通過仿真充分驗證了訓練模型的樣本大小將會對預測模型的性能產生較大的影響,訓練樣本越大,模型的預測性能越好。
3)多組仿真實驗驗證了基于改進KELM和集成學習理論的預測模型具有良好的泛化性能和預測性能,因此本文算法不僅可以應用于目標機動軌跡預測,還可以應用于其他空戰問題研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
