一種融合極限學習機和改進煙花算法的混合式目標跟蹤技術*
2021-10-09 08:33:32景雪寧
計算機與數字工程 2021年4期
景 平 董 娜 景雪寧
(蘭州理工大學 蘭州 730050)
1 引言
運動目標跟蹤是計算機視覺領域內的一個重要的研究內容,它在交通監控、視頻交互、行為分析等一些領域有著廣泛的應用。目標跟蹤技術主要由三個部分組成:1)目標的特征提取,如何從目標的圖片信息中提取出能夠顯著性表達目標特點的信息特征;2)外觀模型,外觀模型的作用是在當前幀中判決候選圖像區域是被跟蹤目標的可能性;3)目標運動位置預測,其通過描述幀與幀目標運動狀態之間的關系,預測出下一幀的目標所處位置的可能區域[1]。
起初人們采用全局直方圖來表示目標特征信息,利用直方圖之間的巴氏距離來判斷圖像塊的匹配關系,但是用直方圖來表示圖像特征只能描述特征元素在整幅圖像特征中所占的比例關系,忽略了特征元素所處的空間位置,因此該特征模型不能完整反映目標的信息。為了應對上述問題,學者們在構建外觀模型時加入了分塊-聯合機制[2~3]。在應對復雜背景下的目標跟蹤問題,人們又利用判別分類法去描述目標外觀,例如Helmut在文獻[4]中提到的Boosting算法,該算法基本思想為:針對同一個訓練集訓練不同的分類器(弱分類器),然后把這些弱分類器集合起來,構成一個更強的最終分類器(強分類器),但是采用該分類器處理跟蹤問題時運行幀率不能滿足實時性需求。為了解決計算復雜度大的問題,Zhang在文獻[5]中提出了快速壓縮跟蹤算法。該算法是通過對圖像信息降維處理方式來提取目標特征信息,進而實現高效的跟蹤,但是經過這樣處理會使得所構建的外觀模型不能精確地描述目標細節信息,容易在處理背景雜波干擾的跟蹤問題就會出現錯誤匹配現象。隨后,有學者[6]將稀疏矩陣模型用在跟蹤領域,該模型利用目標模板和瑣碎模板來構建目標外觀模型,與此同時還有人提出多實例學習算法[7]和TLD算法[8],這些算法相較于之前有著很大的進步,但還需進一步的完善和改進。最近神經網絡[9~11]在跟蹤領域引來廣泛的關注,該方法借鑒人類視覺神經的層級結構作為訓練模型,通過一層層的組合優化來反映圖像的分布特征,然而該方式用于處理數據信息需要消耗大量的時間資源,不能滿足跟蹤的實時性要求。文獻[12~15]應用到極限學習機算法來處理視頻的跟蹤問題,該算法是Huang在文獻[16]中提出的一種前饋神經網絡算法,由于其隱層參數是隨機給定,隱藏層到輸出層的權值通過最小二乘法求解得到,因此該方法有較高的計算效率。在線極端學習機是一種基于極端學習機的增量學習方法,它不需將所有計數據代入計算,只需在原有數據的基礎上增量學習當前幀的數據,因此在線更新過程沒有太大的計算負擔。
關于目標位置預測,滑動窗口算法[17]采用的是窮盡式搜索方法,它需用不同尺寸的窗口多次遍歷整個圖像區域,采用該方式進行搜索定位會搜集到大量含有背景雜波的候選目標樣本,這將會大大增加檢測失敗的概率。Meanshift算法[18~20]是通過概率密度的梯度爬升尋求局部最優的方式來實現目標位置的預測,然而其在目標的搜索定位過程容易陷入局部最優,導致目標位置預測失敗。為了應對復雜環境下的目標跟蹤問題,后來人們將卡爾曼濾波算法[21~22]應用于目標位置預測,卡爾曼濾波算法是kalman于1960年提出,其通過已有物體位置的觀察序列(可能有偏差)預測出物體的位置的坐標及速度。因為卡爾曼濾波算法較適合帶有高斯噪聲的線性系統,所以,該算法對于復雜環境下的非線性系統的搜索定位問題不能很好的解決。為了應對該問題,后面人們將粒子濾波算法[23~24]引入到目標跟蹤領域。該算法是采用蒙特卡洛方法來近似狀態空間模型,即利用有限的粒子近似的運動狀態空間。雖然該算法對于運動狀態變化較慢的目標能夠較好的應對,但是對于運動狀態變化迅速的目標定位問題存在很大的滯后性。
基于上述理論,本文從特征信息提取、運動模型構建、外觀模型更新三個方面著手來提高視頻運動目標的跟蹤精度。為了減少計算量同時還能提取出圖片中價值容量大的信息,提出了梯度稀疏矩陣來提取圖片的顏色特征信息,該方式利用一定閾值來精分各像素處的梯度幅值,然后將大于閾值處的九鄰域內的零矩陣置一來獲得梯度稀疏矩陣。然后針對復雜環境下存在大量的背景雜波問題和目標運動狀態多變問題,本文采用改進煙花算法對目標運動位置進行更精確的預測,該算法不同于傳統煙花算法采用固定的爆炸半徑參量,而是在此基礎上考慮了目標運動多變的情況,將目標的運動速率量加入到煙花爆炸半徑參數中,進而使得煙花的爆炸半徑能夠隨著目標的運動速度變化情況動態的進行調整,同時為了防止煙花多樣性問題造成的煙花種群收斂于與目標具有相似外觀的雜波信息處,該算法利用煙花的置信度方差特征來調節煙花的變異概率,進而將煙花的多樣性控制在合理范圍內,提高位置的預測精度。為了應對目標形變問題,本文提出了動態更新機制,該方式是利用相鄰幀間目標的置信度變化率來調整更新樣本的數目,然后利用在線極限學習機算法來增量學習相應數目的樣本信息。為了驗證該跟蹤技術的可行性,本文將該跟蹤器在公共數據集OTB上進行測試,通過實驗表明本文算法不僅兼顧跟蹤的實時性而且擁有較高的跟蹤精度。
2 算法實現
2.1 特征提取
為了使得提取到的圖片特征信息保留了顏色的空間特征,同時還能夠降低數據的計算維度,本文提出了一種利用梯度稀疏矩陣的方式提取顏色信息。其實現原理為:通過將梯度突變處(梯度幅值大于設定閾值的矩陣位置)九鄰域內的零矩陣置1的方式來生成梯度稀疏矩陣,然后利用邊緣稀疏矩陣來提取圖片的特征信息,得到顏色梯度矩陣。具體的實現步驟如下所示。
1)計算稀疏梯度矩陣
首先,對圖片進行伽馬校正,解決光線分布不均的問題,同時提取H通道的顏色矩陣。
然后,計算每個像素的水平和垂直梯度值,進而得到每個像素的梯度幅值,具體的計算公式如式(1)、(2)、(3)所示:
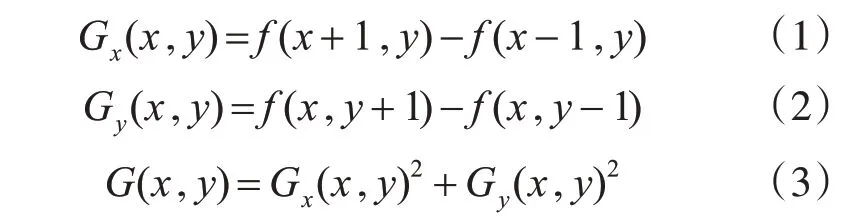
上式中Gx(x,y),Gy(x,y)表示顏色矩陣(x,y)處的水平和垂直方向的梯度值,f(x-1,y),f(x+1,y),f(x,y-1)f(x,y+1)表 示 圖 片(x-1,y),(x+1,y),(x,y-1),(x,y+1)處的像素值,G(x,y)表示像素(x,y)處的梯度幅值。
之后利用每個像素的梯度幅值來判斷圖片中物體的邊緣輪廓分布,將邊緣輪廓處九鄰域內數值置1,進而得到梯度稀疏矩陣,具體的實現公式見式(4):
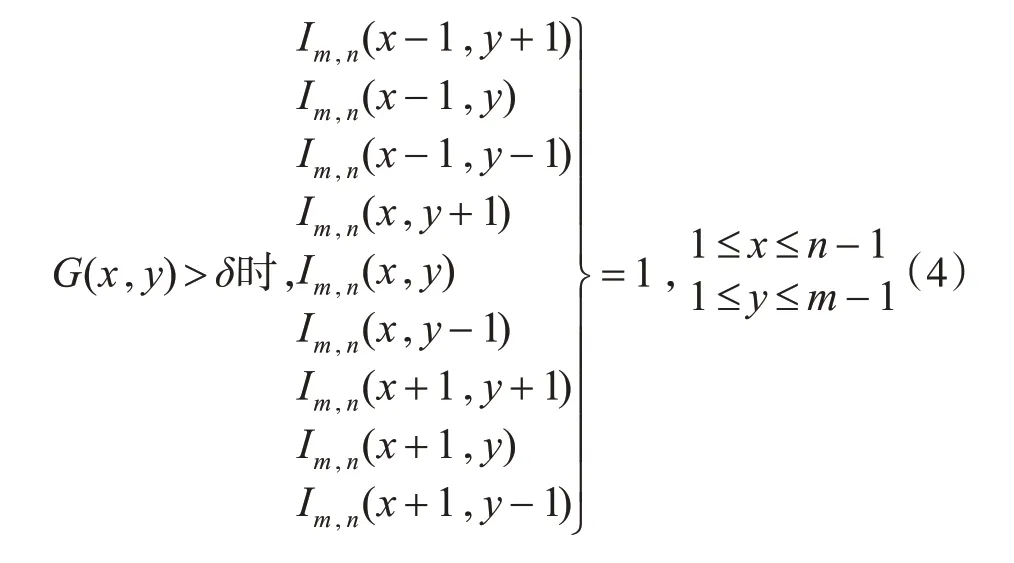
上式中Im,n為m行n列的零矩陣,該矩陣的維數與顏色矩陣相同,δ表示精分梯度幅值的閾值。上式通過將梯度幅值大于閾值δ處像素的9領域內零矩陣數值置1來獲得梯度稀疏矩陣。
2)提取特征信息
計算得到梯度稀疏矩陣后,利用稀疏矩得到兼具邊緣輪廓信息的顏色梯度矩陣,如下式所示:
當:
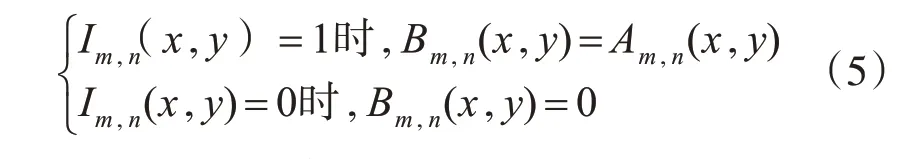
A表示在圖片提取到的基于HSV空間的H通道的顏色矩陣,B表示利用梯度稀疏矩陣提取的顏色梯度矩陣。為了使得提取的圖片信息對小范圍光線變化和微小形變具有一定魯棒性,本文學習借鑒了提取HOG特征的處理方式,將圖片矩陣進行局部區域標準化。
首先將顏色梯度矩陣劃分為若干個不重疊的4*4像素的cell,提取每個cell的顏色梯度向量;然后將局部cell放入block中依據對比度大小進行歸一化,此處的block大小為2×2個cell,block與block之間有重疊,且block的移動步長為8個像素,標準化后得到每個block的顏色梯度向量;最后為了得到整個矩陣的顏色梯度向量,將一個個block向量連接起來。
2.2 外觀模型的建立
1)極端學習機構建初始幀外觀模型
通過前面的處理已獲得正負樣本的特征向量[Xp1,Xp2,…,Xpn,XN1,XN2,…,XNk]T及其 對應 的觀測值[YP1,YP2,…,YPn,YN1,YN2,…,YNk],根據極限學習機的訓練公式可以計算得到輸出權重矩陣β,具體表示如式(6)、(7)、(8)所示:

其中:
其中:
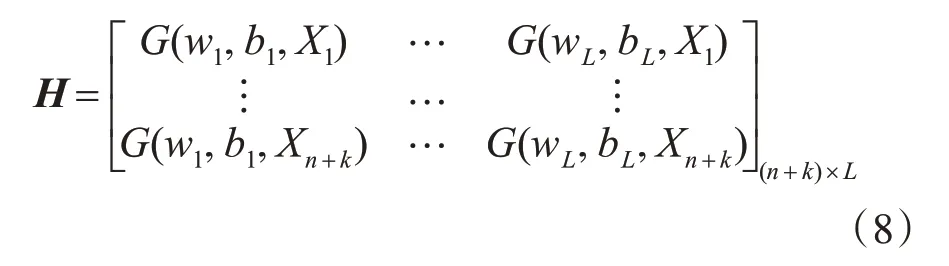
其中wi,bi表示輸入層和隱層之間的權重向量和偏置向量,它是隨機生成的。G(.)表示激活函數,H表示隱層的輸出矩陣,H?為H的廣義轉置。
2)動態在線極限學習機更新分類器
動態在線極限學習機包括兩個部分:動態更新機制和在線極限學習機。動態更新機制用于確定更新目標外觀模型的正樣本的數目,通過這種方式不僅能夠滿足外觀模型中納入更多目標的實時信息,同時還能免得造成由更新不足或納入太多錯誤信息引起的分類精度降低的情況。在確定更新樣本的數目后,利用在線極限學習機對這些樣本進行增量學習,完成對分類器的更新。
在第t幀中用來更新外觀模型的正樣本數目Ntp(其中包含10個靜態樣本,該樣本是從初始幀隨機抽取的10個正樣本),隨著目標的置信度值的改變而動態調整,具體表現為:
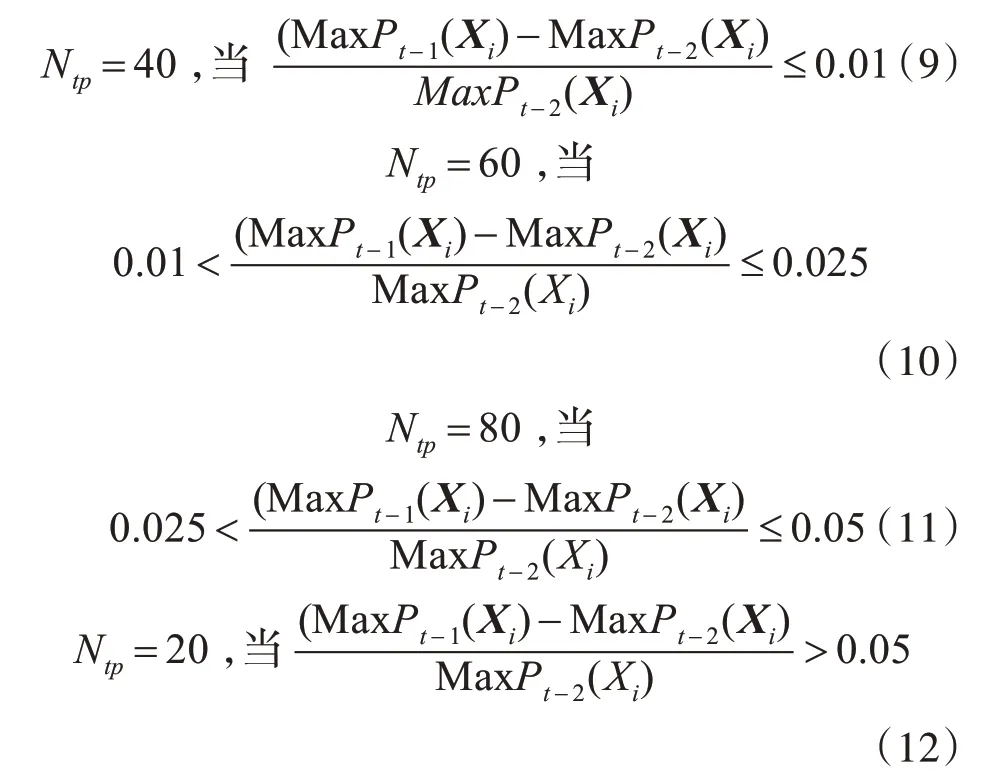
MaxPt(Xi)代表在第t幀候選目標圖像塊中最大的置信度值,其反映的是第t幀外觀模型對目標外觀的模擬能力。目標的置信度值變化率越大說明目標外觀模型的更新不能適應目標的外觀變化,因此需增加正樣本的數目,使得分類器的更新速度和目標的外觀變化持平。并且通過試驗得到相鄰兩幀的目標函數差值比率小于0.05時,目標的外觀變化與相鄰兩幀目標的函數差值比率呈正相關。而當其差值比率大于0.05,目標跟蹤失敗的概率較大,因此為防止在外觀模型中引入太多錯誤信息,需要將正樣本的采集數目減少為20。
提取到目標的正負樣本后,利用2.1節所述方法來獲得每個樣本的顏色梯度向量[Xp1,Xp2,…,XNtp,XN1,XN2,…,XNk]T及各訓練樣本所對應的期望值矩陣,根據在線極限學習機的更新原理可以得到其更新后的輸出權重矩陣如下:
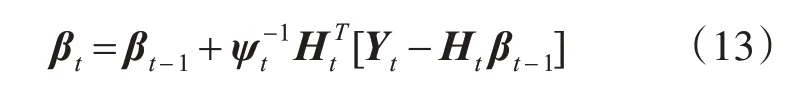
其中:
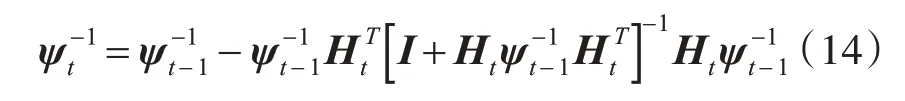
這里增量學習樣本的隱層輸出矩陣Ht通過公式(15)計算得到。
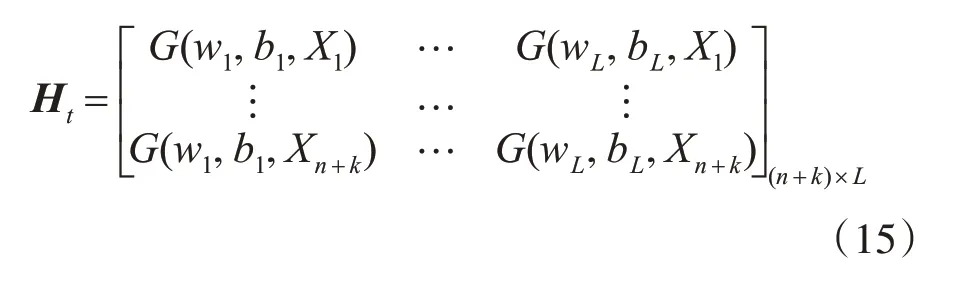
2.3 目標位置預測
對運動狀態多變的運動物體的搜索定位不僅需要有較高的收斂能力,同時還要兼顧全局的搜索能力,使得當物體保持有規律的狀態運動時,能夠收斂于一定區域內,降低匹配識別的壓力,而當物體發生突變時,能夠擴大搜索范圍來搜尋目標的位置,基于此本文利用煙花爆炸算法[25]的可控的爆炸搜索模式來預測目標的位置。為了使得該搜索定位方式能夠較好的解決目標跟蹤問題,本文對煙花算法的爆炸算子和變異策略進行改進,具體措施如下。
1)爆炸算子
由于傳統的煙花算法的爆炸半徑參數為固定不變的常量,其不能較好地應對運動目標狀態突變的情況,因此需要加入目標的運動速率參數來調整每幀中爆炸半徑大小。同時傳統煙花算法的爆炸算子的計算方式不太適應跟蹤問題的解決,本文采用粒子濾波算法的權值思想將適應度值的差值差異化運算改成權值比例運算,其具體的實現方式如下。
爆炸半徑:煙花的爆炸半徑由目標運動速率以及煙花置信度值權重共同決定。其計算方式如式(16)所示:
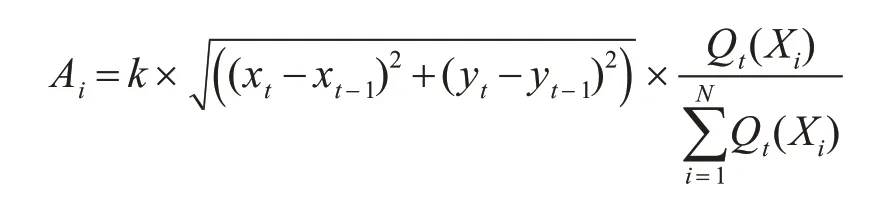
其中:
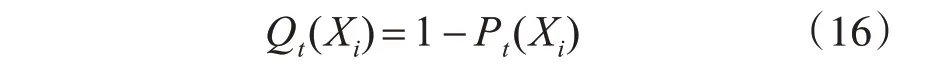
其中Ai為第i個煙花的爆炸半徑,為目標運動速率,其中(xt,yt),(xt-1,yt-1)為相鄰兩幀間目標的中心坐標,k為調整半徑大小的常量參數。Pt(Xi)為第t幀第i個煙花的置信度值。
爆炸火花數:煙花的爆炸火花數與該煙花的適應度值在煙花種群中所占權重成正比。其計算方式如式(17)所示:
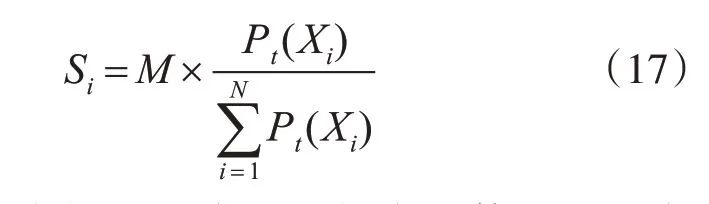
其中Si為第i個煙花生成預測煙火的數目,M為調整預測煙火數目大小的常量參數,Pt(Xi)為第t幀第i個煙花的置信度值。
2)煙花選擇策略
根據目標運動的連續性,相鄰幀之間的目標的位移較小。因此為了提高搜索精度,我們應該預留50%*Q個置信度較優的煙火作為預留煙火,以保證目標附近擁有足夠的煙花火種。其余的50%*Q個預留煙火通過輪盤賭法來在煙花種群里獲得,來增加煙花多樣性,防止目標狀態突然改變或目標運動過快,導致漏搜現象。
3)煙花變異策略
為了增加煙花的多樣性,跳出持續跟蹤錯誤物體的死循環,本文應用變異策略來解決該現象。其通過判斷候選目標置信度值的方差值來確定每個煙火變異的概率,方差值越小說明候選樣本間的區分度較小,煙花的多樣性不足,因此需要提高煙火多樣性,因此給于較大的概率來生成變異火花;反之亦然。具體表現為
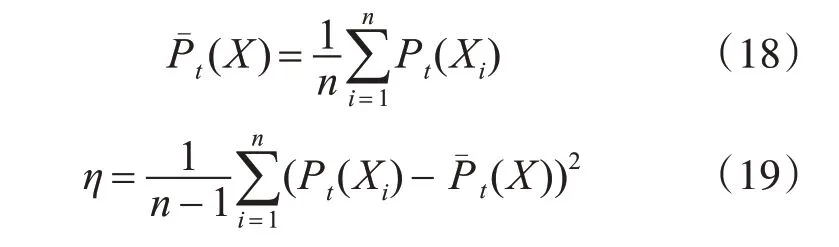
當:
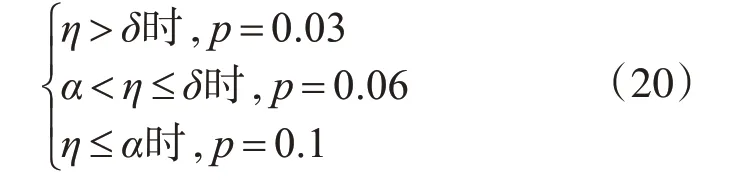
獲得變異的概率后,選定要變異的煙火進行變異操作,具體實現見下式:
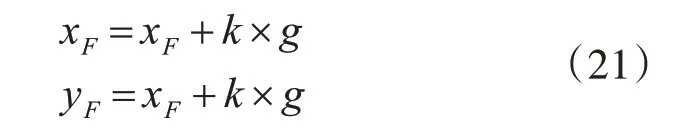
式(21)中xF,yF表示煙火矩形框的中心坐標,k表示常量參數,g表示高斯噪聲,g~N(1,1)表示g服從均值為1,方差為1的高斯分布。
4)搜索框的尺度調整
為了提高的匹配精度,搜索矩形框的尺度應隨著目標的大小的變化進行調整。其調整方式為
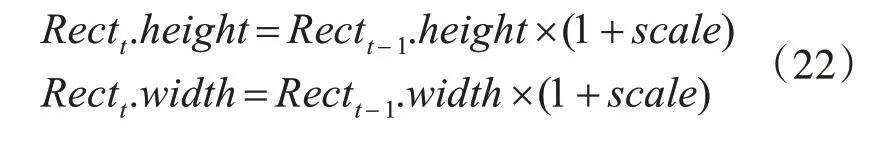
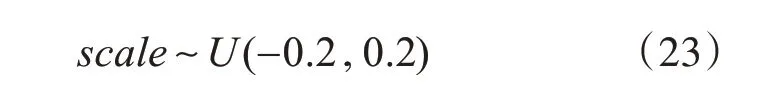
式(23)中Rectt.h eight,Rectt.width表示第t幀第i個煙火的跟蹤矩形框的高度和寬度,scale表示尺度調節參數,scale服從-0.2~0.2的均勻分布。
2.4 OSELM-FWA整個跟蹤流程綜述
算法:OSELM-FWA跟蹤算法
輸入:帶有初始狀態s0的視頻圖像f0,f1,...,fn

3.按照2.2節所述,計算ELM網絡輸出層的初始輸出權重形成初始ELM分類器。
4.初始化M個位置圖像塊為煙花種群。
for每幀fi,i=2,3...n
1.獲取M個位置的候選樣本并根據2.1節所示提取特征。
2.根據公式Y=Hβ和置信度計算公式計算出每個候選樣本的置信度值Pt(Xi)。
3.對每個候選樣本按置信度值進行排序,置信度值最大的即為目標。
4.根據2.3節所述方法來更新煙花種群。
5.根據式(16)、(17)計算爆炸半徑和爆炸火花數目,通過爆炸搜索獲得個位置,并獲得其對應位置的候選目標樣本。
6.在目標周圍采集正負樣本來更新外觀模型,具體更新方式如2.2小節介紹。
輸出:標識出視頻中要跟蹤的目標。
3 實驗結果與分析
本部分首先展示本文算法與其他8個較優算法的跟蹤效果圖,隨后利用評價方法來評估本文算法和其他算法的跟蹤精度,并展示這9個算法的跟蹤精度圖。進行對比試驗的8個算法包括CT算法、TLD算法、IVT算法、DFT算法、ASLA算法、L1APG算法、ORIA算法、MTT算法。
試驗是在引入OpenCV2.4.9庫文件的Visual C++2010上進行編程實現的,電腦硬件配置為Intel(R)3.4GHz CPU,4 GB RAM,Win7×86系統,本文的跟蹤結果測試是在OTB數據集上進行。
單個視頻試驗很難全面地說明算法的有效性,因此本文為了評估算法能否應對視頻目標跟蹤中的常見關鍵性難題,如背景雜波問題、運動模糊問題、部分遮擋問題、姿態變化問題等,我們對8個包含不同場景的視頻進行跟蹤試驗。本文次實驗的視頻資源和數據資源都來自于OTB標準數據集。表1展示的是本文所用視頻信息的基本資料和存在的跟蹤試驗關鍵難題。下述8個視頻包含視頻目標跟蹤中的常見關鍵難題,因此通過跟蹤處理該視頻圖像能夠全面評估算法的有效性。
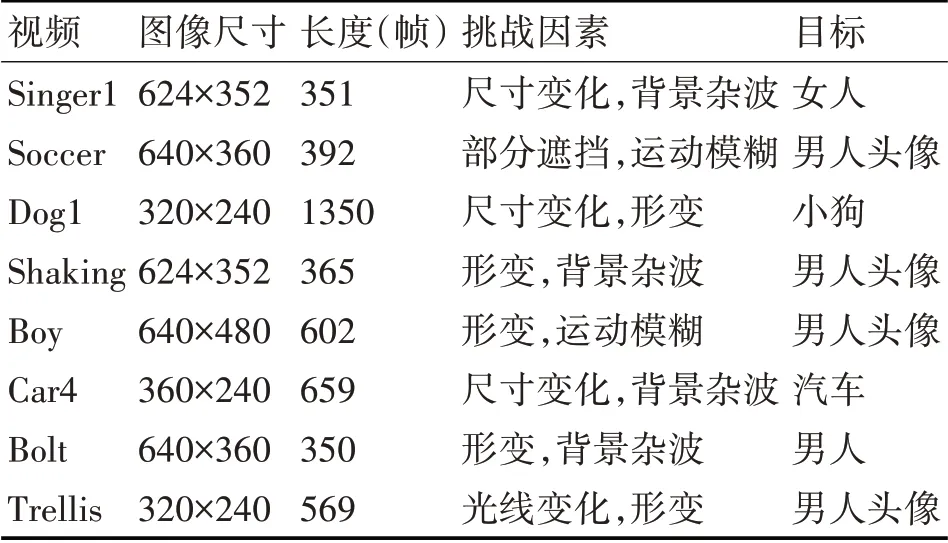
表1 視頻屬性表格
3.1 跟蹤參數確定
參數設定也是影響算法實現目標跟蹤關鍵因素,因此下面給出通過實驗得到的合理參數:各視頻第一幀目標的初始位置是來自于數據集OTB中的初始狀態數據,初始分類器建立需要搜集250個正樣本、280個負樣形成訓練數據集,并且初始幀還需初始化100個位置的圖像塊為煙火集,后續幀中我們每幀保留的預留煙火數目為20。在搜索定位中爆炸半徑的計算用到的參數A=150,爆炸火花數目計算參數M=150。并且確定煙火變異概率時所用到的閾值δ=0.008,α=0.003,為了兼顧跟蹤精度和跟蹤效率,本章神經節點的個數取L=150。在提取特征時,我們將候選目標樣本調整為32×32像素的圖像,每個cell大小為4×4,其中2×2個cell組成一個block。
3.2 跟蹤結果
圖1顯示的是各算法對singer1、Soccer、Dog1、Shaking、Boy、Car4、Bolt、Trellis這8個視頻的部分跟蹤效果圖。其中ASLA算法的跟蹤效果圖,通過singer1、Shaking、Trellis三個視頻跟蹤表現顯示ASLA算法在處理光線變化問題時在有著明顯的優勢。通過Soccer視頻的第155幀的跟蹤結果顯示該算法在處理背景雜波和部分遮擋時不能精確的跟蹤目標,并且該算法在跟蹤Bolt和Boy視頻中的目標時,其在后面的視頻幀中出現完全跟丟目標的現象,說明該算法在應對快速運動和大的形變問題時,存在較大的缺陷。圖中ORIA算法的跟蹤結果,通過其對視頻Singer1、Dog1的跟蹤結果顯示,該算法能夠應對單存的光線變化和尺度變化問題,當出現目標的大尺度形變和快速運動問題時,其就會出現偏移目標的現象,如Bolt和Boy視頻的跟蹤結果截圖顯示。盡管CT和TLD應用了一些在線更新機制去學習目標的外觀,但是在遇到較大的姿態變化(Bolt)問題或者遮擋問題(e.g Soccer)時,依然存在跟丟現象。IVT算法通過對Singer1、Dog1、Boy、Car4和Trellis視頻的跟蹤效果顯示,其能夠從始至終精確的定位目標,說明該算法能夠處理尺度變化、較小形變、快速運動及光線變化問題,但是當存在如視頻Soccer較大面積的部分遮擋和雜波問題和大尺度的形變問題(e.g Bolt、Shaking)就出現丟失目標的現象。DFT算法能夠很好地定位快速運動的(e.g Boy)目標及存在較小光線變化場景下的運動物體,然而在處理尺度變化(e.g Singer 1)、大區域的遮擋(e.g Soccer)、較大形變(e.g Bolt)問題時表現較差。MTT算法在跟蹤視頻Shaking時能夠穩定的跟蹤目標,而對于形變較大(e.g Bolt)和移動過快(Bolt)的運動目標,存在魯棒性差的特點。L1APG算法能夠對視頻Tellis、Singer1和Dog1自始至終進行定位跟蹤,對于其他的視頻就會存在很大的偏移現象。
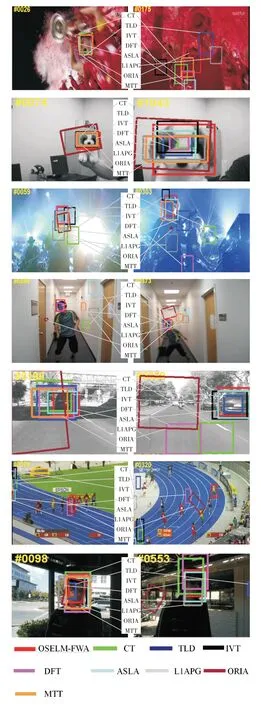
圖1 基于8個視頻的跟蹤效果圖
通過比較能夠看出本文算法相較與其他8個算法在應對光線變化、姿態變化、部分遮擋、移動模糊等關鍵難題時有著明顯的優勢,本文算法表現良好的原因主要歸因于以下三方面:1)從特征提取方面,本文算法的特征提取方式是采用梯度稀疏矩陣來提取圖片信息,使提取的特征信息不僅包含顏色信息而且還兼顧圖片的輪廓分布特點;因此,該特征能夠顯著的表達圖片的信息,并且在提取特征時,我們采用分區域提取,能夠一定程度上解決區域光線變化、較小變形等問題。2)從分類器構建與更新方面,本文采用動態更新策略來更新分類器,使得分類器不僅能夠隨著目標外觀變化進行實時更新,而且還能防止在外觀模型分類器模型里引入太多非目標信息,基于此構建的分類器才能較好的分類出目標和背景信息。3)在運動模型構建方面,采用改進煙花算法進行搜索定位。該運動模型在搜索定位時,考慮了運動狀態的變化情況利用運動速率量來調整爆炸半徑參數,進而能夠保證煙花種群能夠較好地收斂于目標所在區域,并且本文還通過預測煙火置信度的方差值來調節預測煙火的變異的概率,來保持煙花的多樣性,避免出現漏搜現象。
3.3 跟蹤效果評估
為了更好地評價各算法的跟蹤質量,本文采用了重疊率(VOR)來對跟蹤結果進行評價,該方法能夠很好的評估跟蹤的整體性能。式(24)為顯示的是重疊率計算公式:
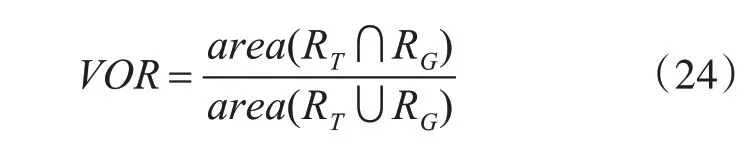
這里的RT代表跟蹤結果矩形框,RG指相應的標準標定框。當VOR大于指定的閾值時,表示本幀跟蹤成功。假定有跟蹤視頻,其視頻幀數用length表示,并且定義該視頻第t幀的跟蹤VOR值用Q(t)表示,設定成功率為S(τ),τ為重疊率閾值,則該視頻的成功率計算公式如下:
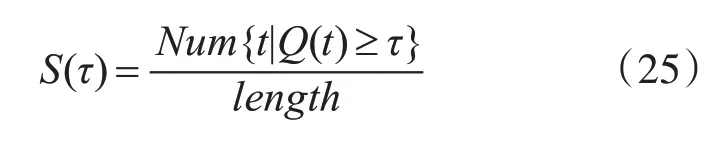
單獨的重疊率來評價跟蹤結果不能全面反映各算法表現,因此下面我們用中心偏差值來評價各算法跟蹤精度。該方法是通過判斷跟蹤結果矩形框的中心坐標與標準標定框的中心坐標之間的距離,其計算公式如式(26)所示:
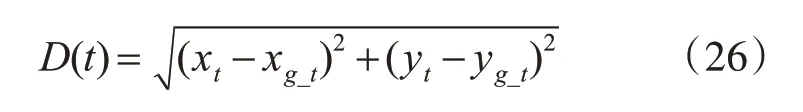
上式中D(t)表示第t幀跟蹤結果矩形框中心坐標與標準標定矩形框的中心坐標之間的距離,xt,yt表示該幀跟蹤框中心坐標的橫縱坐標,xg_t,yg_t表示標準標定框的中心坐標的橫縱坐標。當D(t)小于指定閾值時表示本幀跟蹤成功。則其計算公式如式(27)所示:
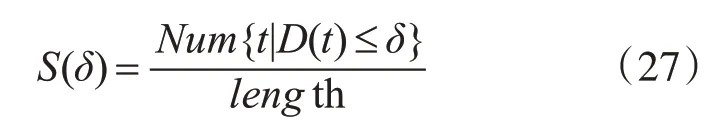
本文根據上述評價方法來生成各算法的跟蹤成功率對比圖和跟蹤精度對比圖,如下圖所示。左圖Success plots of OPE為跟蹤的成功率評價圖,圖中橫軸表示重疊率閾值,縱軸對應該重疊率閾值的成功率值;右圖Precision plots of OPE為跟蹤精度評價圖,圖中橫軸表示中心偏差閾值,縱軸對應該閾值的成功率值。圖2是我們繪制出的8個視頻的總的成功率圖和精度圖,本文算法OSELM_FWA用紅色曲線表示,可以看出本文算法無論是采用重疊率的評價方式還是中心偏差的評價方式,其綜合跟蹤精度表現良好。圖3~圖9為該評價方法基于單個跟蹤難題的跟蹤效果評價圖,從圖中能夠看出本文跟蹤算法在應對背景雜波、平面內外旋轉、光線變化、部分遮擋、快速運動和運動模糊問題時其跟蹤成功率在一定范圍內(評價指標在設定的閾值范圍內)趨近于1,相較于幾種傳統算法有一定優勢。
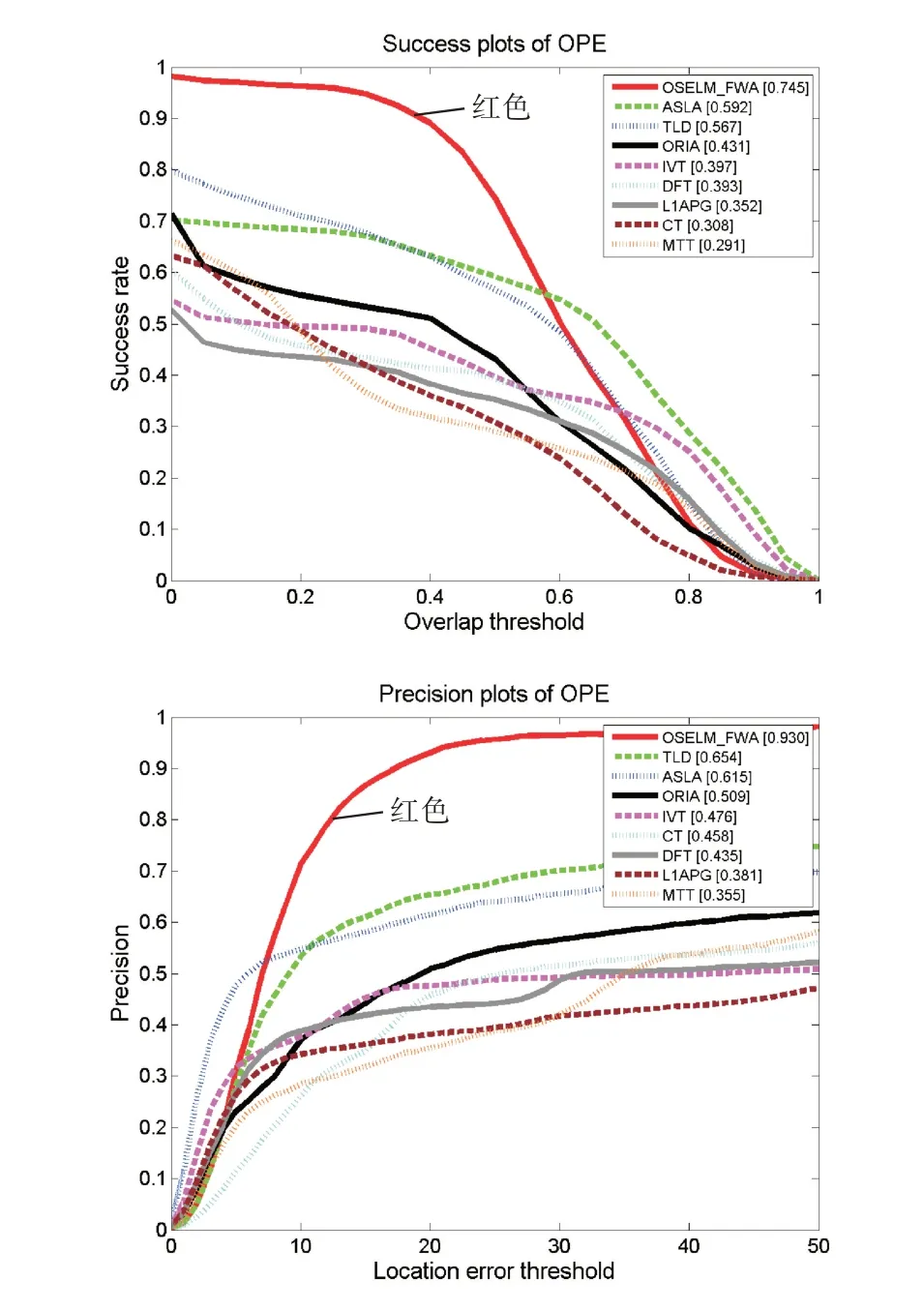
圖2 總體成功率圖和精度圖
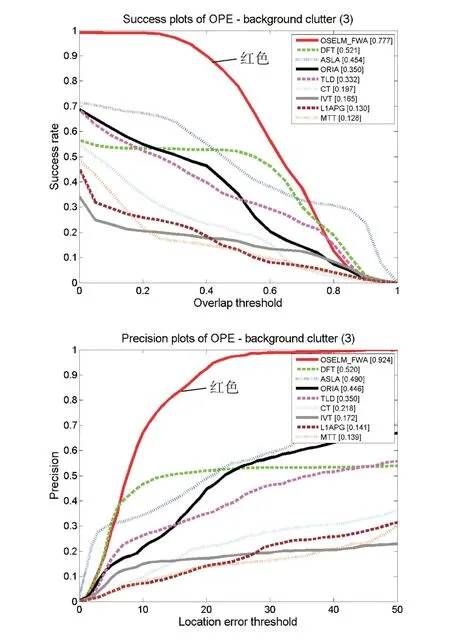
圖3 基于背景雜波單項問題跟蹤效果評價圖
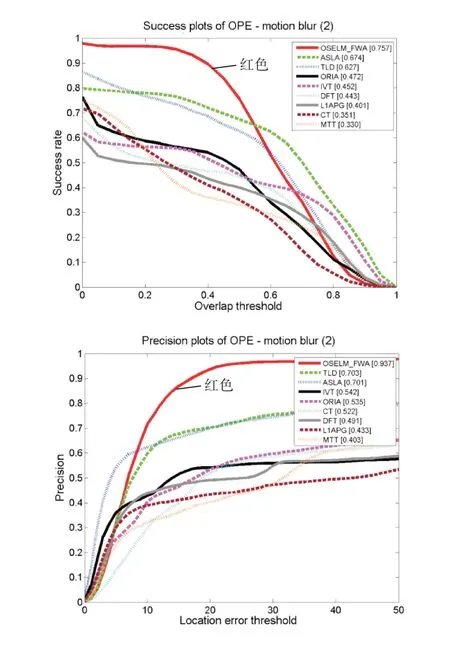
圖9 基于運動模糊單項問題跟蹤效果評價圖
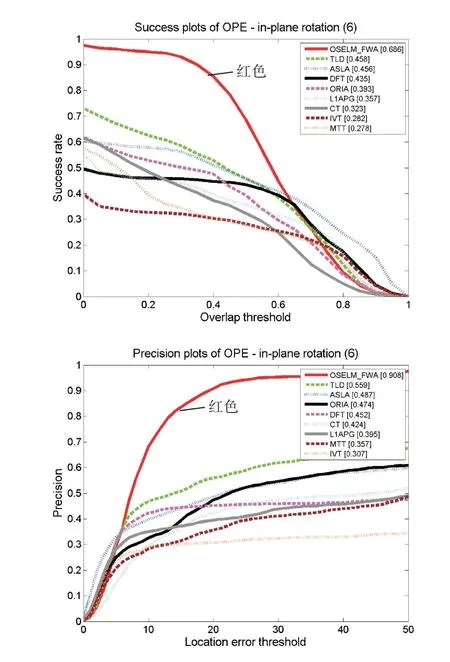
圖4 基于平面內旋轉單項問題跟蹤效果評價圖
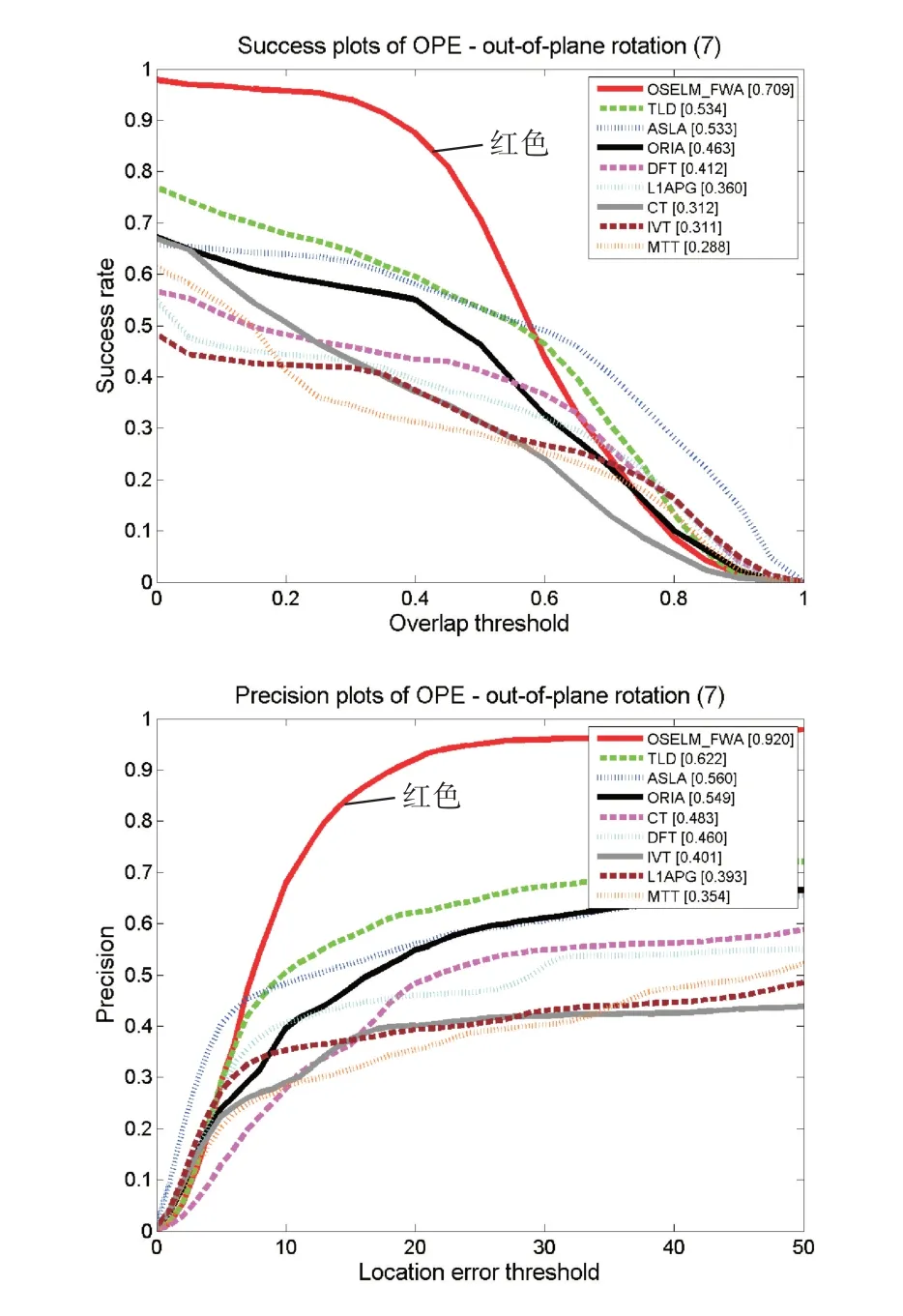
圖5 基于平面外旋轉單項問題跟蹤效果評價圖
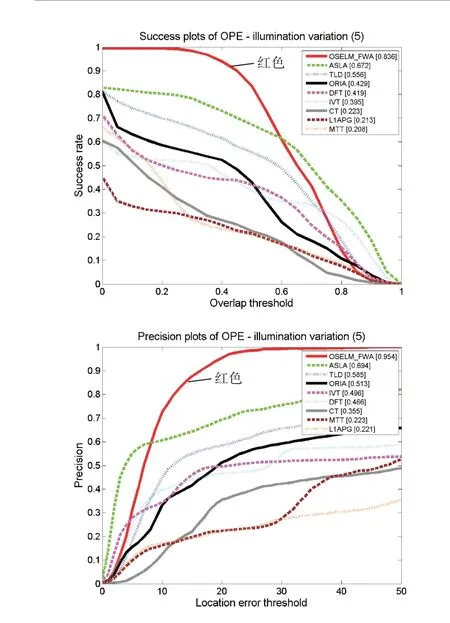
圖6 基于光線變化單項問題跟蹤效果評價圖
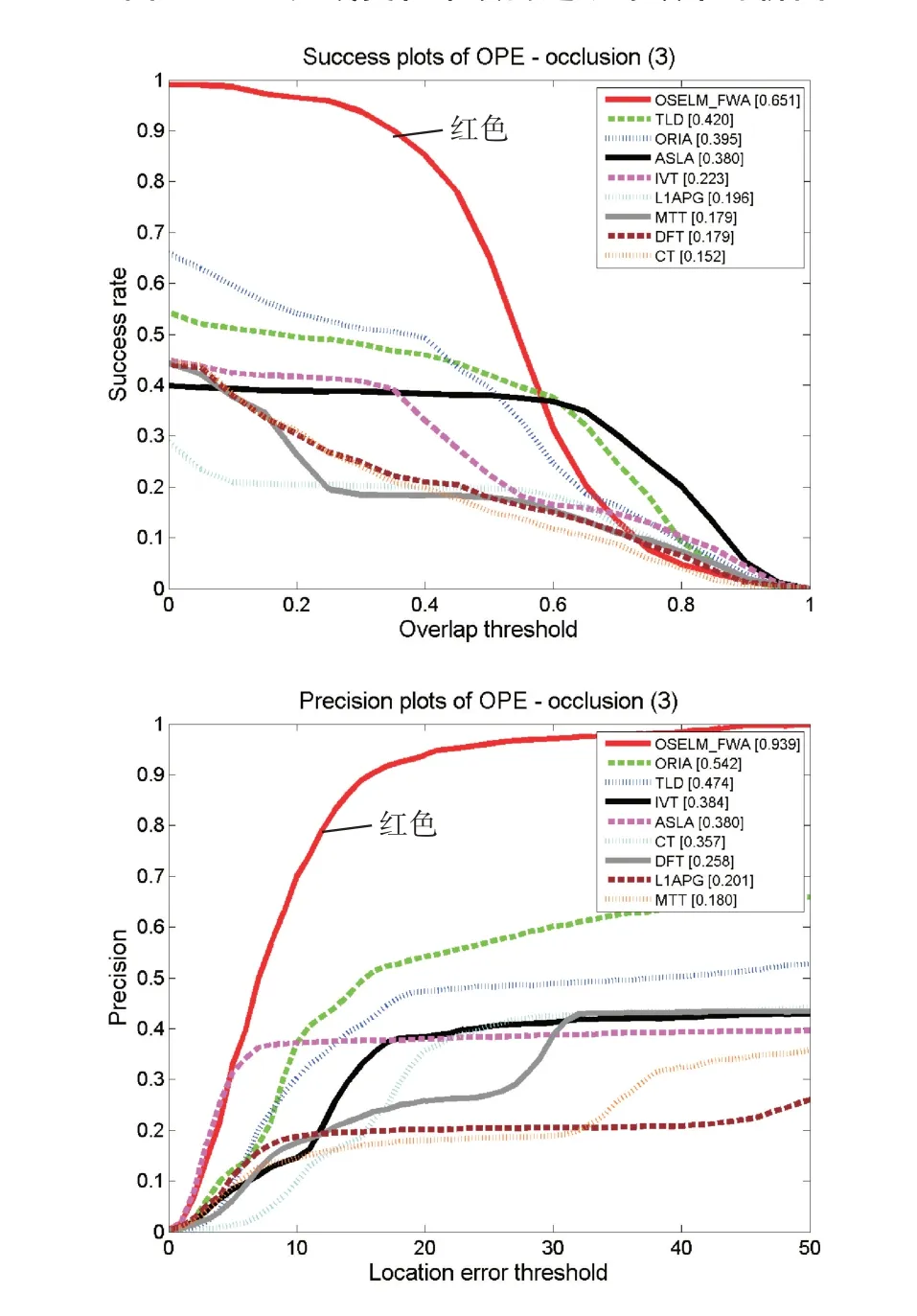
圖7 基于部分遮擋單項問題的跟蹤效果評價圖
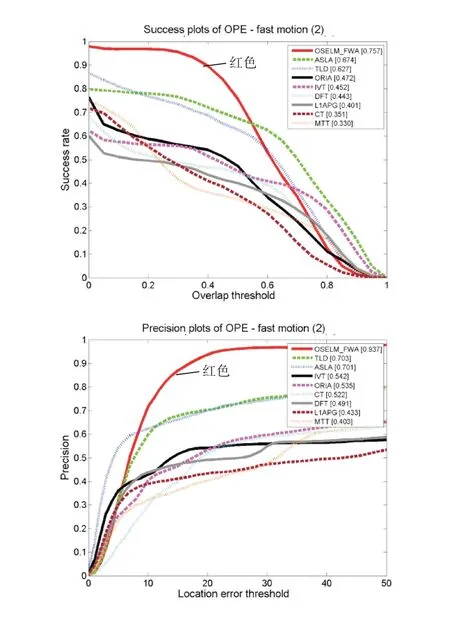
圖8 基于快速運動單項問題跟蹤效果評價圖
3.4 跟蹤速度分析
跟蹤精度和跟蹤效率是驗證跟蹤算法可行的兩個關鍵因素,前面圖表已經詳細說明算法的跟蹤效果和精度,下面需要說明本文算法的跟蹤效率。表2展示各算法的處理幀率,其中本文算法OSELM-FWA的幀率為22,其跟蹤效率不如CT算法的幀率36和IVT算法的幀率26,但是優于多數的對比算法的效率。因此,本文算法的處理效率還是在可接受的范圍。

表2 算法跟蹤速度對比表平均FPS幀/s
4 結語
為了解決復雜背景下的視頻目標跟蹤問題,本文提出一種融合極限學習機算法和改進煙花算法的混合式目標跟蹤技術。在特征提取方面,該算法利用梯度稀疏矩陣來獲得圖片特征,并應用分區域的信息提取方式來提取完整的圖片信息。在分類構建與更新方面,初始幀利用極限學習機來構建初始分類器,后續幀中利用動態在線極端學習機來動態更新分類器。在運動模型方面,利用改進煙花算法的爆炸搜索方式來生成獲選目標圖像塊。實驗表明,本文算法相較于其他跟蹤算法不僅擁有較高的跟蹤精度,而且還能兼顧跟蹤效率。
