數據模型與物理模擬驅動的人工智能測井
2021-09-29 01:45:48程希宋新愛李國軍包德洲陳琪泉
測井技術 2021年3期
程希,宋新愛,李國軍,包德洲,陳琪泉
(1.西安石油大學地球科學與工程學院,陜西西安710065;2.西安石油大學院士專家工作站,陜西西安710065;3.中國石油集團測井有限公司技術中心,陜西西安710077)
0 引 言
近幾年,人工智能(Artificial Intelligence,AI)在科學、工程界掀起了巨大的浪潮。斯坦福大學的MARKUS等[1]和KARIANNE等[2]分別提出了數據模型驅動的地球科學知識發現思想。國際巖石物理學家與測井職業分析家學會的Xu等[3]提出了“數據驅動的巖石物理學”思想。2018年陸大衛在測井年會上指出測井已進入“智能測井”階段。程希等[4-5]提出“測井方法、儀器制造、測井作業、巖石物理以及測井綜合解釋”一體化和“新一代集成化測井系統”的思想及利用“數值模擬方法驅動的數據流過套管電阻率測井技術”,提高過套管地層電阻率校正的精度和速度。程希等[6]發表了人工智能測井發展現狀和趨勢的報告。匡立春等[7]展望了人工智能在石油勘探開發領域的應用前景。
中國石油大學(北京)、西南石油大學相繼建立了人工智能研究院,西安石油大學在2020年秋季開始招收第一屆人工智能專業本科生。中國石油長慶油田分公司探索在成熟區塊應用人工智能算法替代人完成儲層測井解釋和質量監測,并取得初步成效。中國石油勘探開發研究院成立了人工智能研究所,探索把AI算法應用于測井成像、裂縫識別等應用中。中國石油天然氣集團有限公司正在研發的勘探開發夢想云平臺,通過統一數據湖、統一技術平臺、通用應用推進油氣勘探開發的智能化[8-10]。李寧等[11]提出了人工智能技術在測井技術中的應用構想。
中國石油集團測井有限公司把智能絞車投入現場使用,該公司擁有包括巖石物理測試數據在內的超過30 TB的數據庫,為人工智能測井奠定數據基礎。斯倫貝謝公司2019年建立DELFI云平臺勘探開發認知環境,提出“通過DELFI認知E&P環境發揮機器學習和人工智能的力量”,將數字化更深入到智能油藏描述,推進油氣服務的智能化。貝克休斯公司建立了以測井解釋為核心,結合錄井、油井監測、地層測試的綜合大數據平臺,促進在石油和天然氣行業中應用人工智能技術。AI算法引起國外油田公司和服務公司研究人員在非常規油氣勘探與開發、測井數據處理以及巖石物理、測井模擬、測井解釋方面的興趣[12-16]。
本文分析測井大數據形成的基礎。從數據模型、物理模擬算法以及人工智能測井生態闡述人工智能測井的可行性,由大數據平臺、機器學習到深度學習、智能儀器等信息技術的發展,結合油田勘探開發的應用需求和人工智能的發展趨勢,得出人工智能測井發展必經的3個階段。
1 測井大數據基礎
測井數據的記錄和存儲由最初的點測井手繪、光電記錄筆、描圖曬圖、716格式的磁帶記錄,到目前的磁盤記錄,各種形式的解釋報告圖件,不同測井服務公司不同存儲格式的測井數據。模擬測井手描的裸眼井測井曲線藍圖、數字測井磁帶記錄裸眼井數據和過套管電阻率測井在內的生產測井數據,錄井數據,巖心、地層水分析數據,試井測試數據,隨鉆測井、錄井記錄數據,后校正和處理解釋的數據,這些形成了測井大數據的來源。
分布式永久性井下傳感器數據是測井大數據的另一個基礎。分布式溫度傳感器、離散分布式應變傳感器和分布式聲波傳感器等分布式井下傳感器數據,具有容量大、多樣性、迅速、準確和可視化的特點。目前,分布式井下傳感數據的傳輸、儲存、處理、存檔、檢索和解釋可在測井大數據庫中完成。新的傳感器技術已能夠將大容量、多尺度和高維巖石物理數據實時流式傳輸到數據庫中[3]。
測井數字曲線、陣列數據、測井圖像、文本和表格都是巖石物理測井數據的類型,可以用深度(連續或離散)或時間對應采集的數據。測井數據具有多尺度的特點,例如,巖心掃描數據具有微米到厘米尺度,電聲成像數據具有毫米到厘米尺度;探測深度也不同,例如,微電阻率、聲波時差、密度、中子和自然伽馬等測井探測深度在厘米尺度,側向類測井探測深度在1 m尺度內,感應類測井探測深度在2 m尺度內,過套管電阻率測井探測深度在1~10 m,井間聲波和電磁測井探測深度在幾百米到1 km內。由于測井歷史累積和成像測井的大規模應用,形成海量測井數據;以上數據既具有體積屬性,也具有多樣性、可變性、可視化和價值等大數據的特征。這些都是測井大數據的基礎,也是人工智能測井大數據基礎。
2 人工智能測井定義
正向反向傳播和隨機梯度下降算法的提出,極大地推動深度神經網絡的發展,為智能測井奠定技術基礎。Keith Holdday針對地球物理數據,提出了數據驅動的軟計算技術概念[17],將AI學習、計算神經學、模式識別、統計學、數據科學以及數據庫等應用技術交叉,實現數據清洗、分割、轉換以及建模,將建模成果應用于地球物理中。本文提出的人工智能測井(Artificial Intelligence Logging,AIL)可以從3方面理解:①能學習地球物理測井和相關知識;②能從不同格式的中大型測井數據中得出解釋結論;③能模仿人類的思維能力,從包括巖石物理模型、理論模擬結果、分析測試以及測井解釋結果等大數據分析中發現潛在因果規律,形成新知識和新解決方案,通過智能測井儀器解決勘探開發中新的問題。綜上所述,人工智能測井是測井專家和人工智能學家賦予機器綜合判斷、分析和學習能力,并使機器利用人工智能算法、計算機儲存與算力在測井大數據生態云中感知發現新知識并自我學習完善,形成人機相互學習協作解決勘探開發中復雜測井問題的方法技術。
3 人工智能測井技術及發展階段
人工智能測井技術是以硬件算力和測井大數據私有云為支撐,數據模型與物理模型為核心驅動,以測井應用層為落腳點,形成的人工智能測井生態有機體。
3.1 人工智能測井生態
人工智能測井生態由智能測井儀器完成測井數據的采集、預處理,在測井大數據綜合平臺上通過人工智能和物理模擬算法完成測井數據的學習、模型的應用、知識的發現和決策,由智能儀器完成現場實施。它由運行在測井大數據上的智能算法、用于數據采集與決策實施的智能儀器以及測井大數據的管理與應用層組成。人工智能測井的應用層由測井大數據管理與知識發現、人工智能算法與模型評價、智能儀器、測井數據處理與評價組成。
測井大數據管理包括數據的分割、計算、更新、補充、可視化、圖表化、標準化等;知識發現系統包括數據交會、校正、分析、總結等。測井大數據私有云的數據輸入/輸出接口與分布式存儲和處理系統的接口通過光交換機連接,提交給人工智能測井云系統用于分析的數據,優化模型輸入權重,從數據中提取特征的卷積或循環神經網絡逐漸修改給出的權重,在神經網絡的某些模型中優化學習。人工智能算法與模型評價系統中,包括監督學習、非監督學習(半監督學習)、強化學習算法,從知識提取角度,包括分類學習算法、回歸學習、聚類學習。模型包括預測模型和描述模型。預測模型包括決策樹、基因模型、線性回歸、隨機森林等;描述模型用相關算法、路徑分析、K平均、束算法等。模型評價方法包括混淆矩陣、接收數據特征曲線、得分、訓練與驗證等。此外,大數據、云計算以及物聯網技術的發展,使測井方法、測井儀器設計與制造、巖石物理、測井數據采集、測井解釋、錄井、地質、地震、鉆井以及永久監測傳感器數據通過物聯網連接,通過邊緣計算上傳到大數據系統的云端,進行大數據分析與學習、資源調配與決策。智能儀器則包括儀器的中樞、外部傳感接口、中低級運動操作系統、內外硬件組成。本質上,人工智能測井的發展是由大數據AI學習和物理模擬算法為內核驅動而發展的,以分類、回歸和預測為特征的各類AI學習算法的發展為這些測井大數據的價值挖掘、特性發現和趨勢預測提供了技術手段。
3.2 硬件算力與測井私有云
人工智能測井的硬件算力通常由邏輯處理器、運行存儲器、網絡服務器組成。邏輯處理器通常由中央處理器CPU(Central Processing Unit,CPU)、圖像處理器(Graphic Processing Unit,GPU)、復雜門陣列或專用測井功能芯片構成,其中,CPU為人工智能測井的中央處理器,GPU為圖像處理單元,用于優化測井大數據的處理,以利于機器學習算法的應用;運行存儲器用于臨時計算或使用存儲短期記憶數據,通常由大量的動態存儲記憶器組成;網絡服務器用于測井井場和處理中心的網絡交換機、路由器和其他用于鏈接服務器的設備,以連接測井云服務器和各種巖石物理測試、測井儀器、探測器、傳感器等邊緣設備。
具有圖像渲染的GPU尤為關鍵,目前最新的Titan RTX GPU數據通道傳輸率達1 Gbit/s,并且可以并行處理AI任務。深度學習所設計的模型,可以由數十億個軟件神經元和數萬億個連接并行訓練,這種學習模型需要新的計算機平臺來高效運行。相比于基于CPU的學習平臺,GPU在深度學習訓練數據時,在速度和能源效率方面更具優勢,這是因為神經網絡由大量相同的神經元創建,本質上是高度平行的。在私有云環境中通過訓練平臺應用AIL學習算法實現數據訓練、測試及建模。
測井大數據私有云至少配置1個主節點、2個從節點,實現對稱管理與分布式測井大數據存儲。其算力配置:至強48核處理器,256 GB內存,10個SDD磁盤,總存儲數據量10 TB(可擴容),數據交換速度10 GBit/s;訓練平臺配置:i9處理器(8核16線程),64 GB內存,AI學習模塊(TensorFlow、PyTorch、Caffe、Keras、CUDA),8 GB顯存的獨立顯卡。通過電腦、智能手機、衛星、智能儀器終端上傳數據后獲取問題處理結果,測井大數據私有云學習訓練平臺與應用關系見圖1。

圖1 測井大數據私有云學習訓練平臺與應用關系圖
3.3 算法
在復雜的井況和地層情況下,計算機快速建模可以發揮最大的作用。對地層電聲特性和地層結構進行建模,通過正演迭代得到地層真實的電、聲、核特性參數或對測井數據進行校正。多物理場模擬可用于全面表征或預測測井響應特性與測井儀器設計,各種電、聲測井模擬方法的特點見表1。在研發中,存在尚不了解地層聲、電、核響應特性和測井模擬過程的情況,將物理算法模型與AI學習技術集成,有效地改善模型的精度和速度。AI學習可以揭示未知的基本行為,使測井模擬速度更快、地層參數反演更精確、動態變化更具有解釋性和預測性。

表1 測井模擬方法特點
AI學習算法通過已有的測井數據構建分類、回歸或預測模型,實現巖性或儲層分類、含油氣變化的未來預測,這與蒙特卡洛算法使用隨機數輸入到專家構建的模型預測概率類似。AI學習最適合基于觀察已知結果對新數據進行快速、自動預測。實際應用中,AI學習可以很方便地測試和優化仿真模型。深度學習是機器學習的一個分支,主要用來進行回歸、聚類和預測,具有人工智能的特點,能模仿人腦的數據處理和決策功能,能夠從未知數據或未標記的數據中學習知識,并不需要監督學習的神經網絡,也稱為深度神經學習或深度神經網絡。對深度學習而言,卷積神經網絡在處理復雜數據時,使用卷積濾波器,神經元代表特定內核,在后傳播過程中降低了節點數,形成卷積序列以利于提取特征值。具有隱含層的循環神經網絡能模擬數據流,通過長短記憶法處理未知數據的過程事件,通過不同算法共享系數降低了需要學習的參數數量。AI分類學習算法特點與測井適用性見表2。
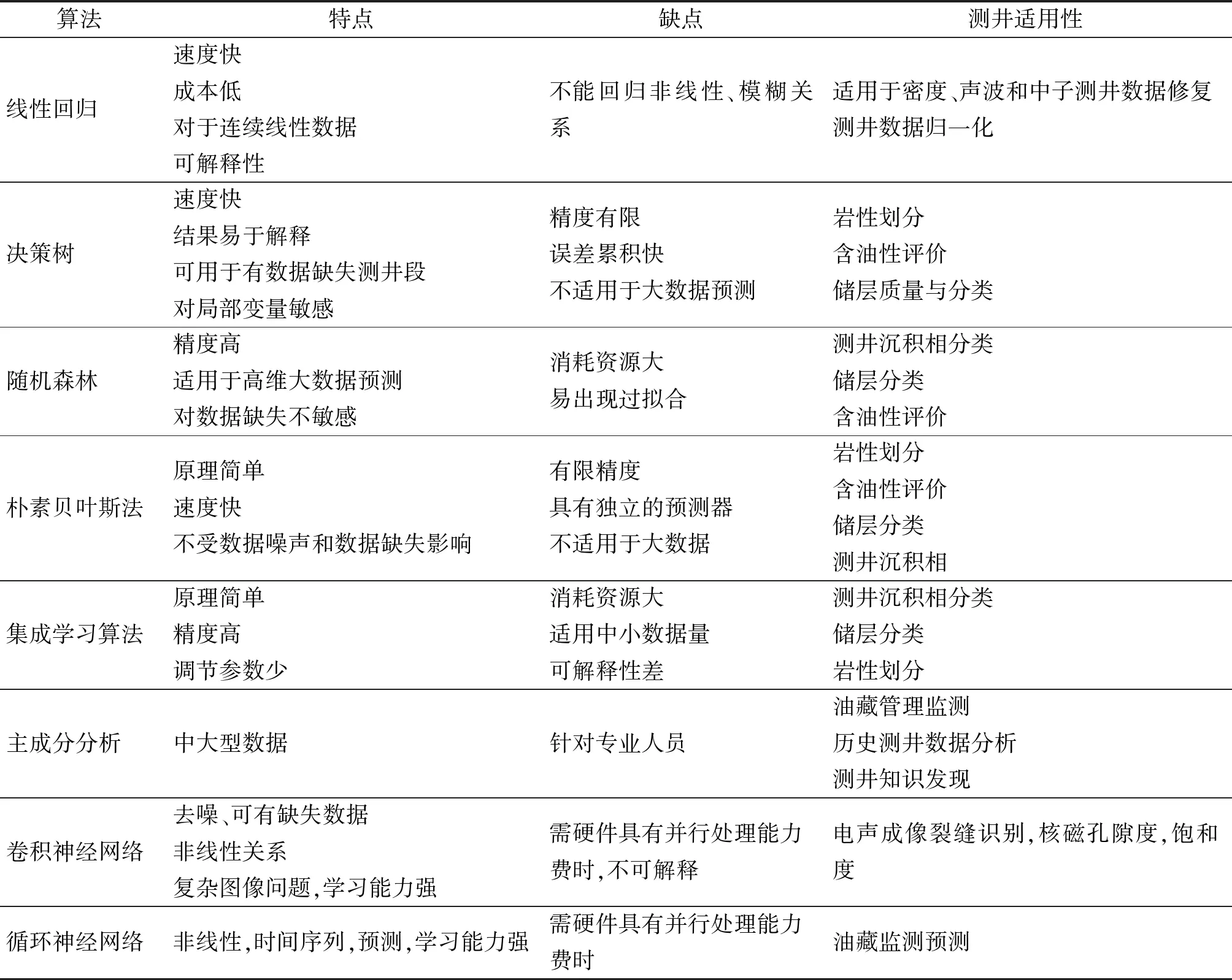
表2 AI分類學習算法特點與測井適用性
AI學習使系統能夠從已有大量數據中自動學習并從經驗中進行改進,無需人工干預。其過程始于觀察學習數據,根據實例形成模式,進行預測,做出更好的決策,處理流程見圖2。測井解釋中,分類算法主要用于測井巖性識別。分類樹、回歸樹AI學習算法具有統一的函數,利用交叉驗證可以測試新樹在新數據上的準確率或精度,估計生成樹的預測精度,更好地了解樹對新數據的預測準確性。集成學習方法將許多弱學習的結果融合到高質量的整體預測器中,根據需求探索求取預測精度最好的方法。評價學習質量的方法,可以在獨立的測試集上評估整體,也可以通過交叉驗證來評估整體。例如,循環神經網絡長短相記憶法(LSTM)主要用于模型復雜的空間物理模擬及時間序列變化趨勢預測。LSTM模型在時間序列或空間序列數據學習上比循環神經網絡(RNN)具有更好的表現,它在輸入長短向量序列數據時,加入了循環神經網絡,對數據進行優化處理。該方法最常使用梯度下降的反向傳播學習算法,先隨機初始化權重,再使用梯度下降法調整權重使誤差最小化,學習過程包括連續多次前進和后退。在前向傳遞中,通過多個隱藏的非線性層將輸入向輸出轉換,并最終將計算出的輸出與相應輸入的實際輸出進行比較、優化。在后向傳遞中,相對于網絡參數誤差的導數用于在反向傳播中調整權重,以使輸出的誤差最小。根據誤差要求,該過程可持續多次,直到模型預測滿足改進要求為止。機器學習通常由監督式學習、無人監督式學習和強化學習組成。強化學習涉及智能儀器應如何在井孔環境下采取行動,最大限度地提高累積獎勵的概念。智能儀器通過強化學習從測井專家和現場獲取經驗,以提高數據獲取、測井資料處理應用和現場決策的準確度。
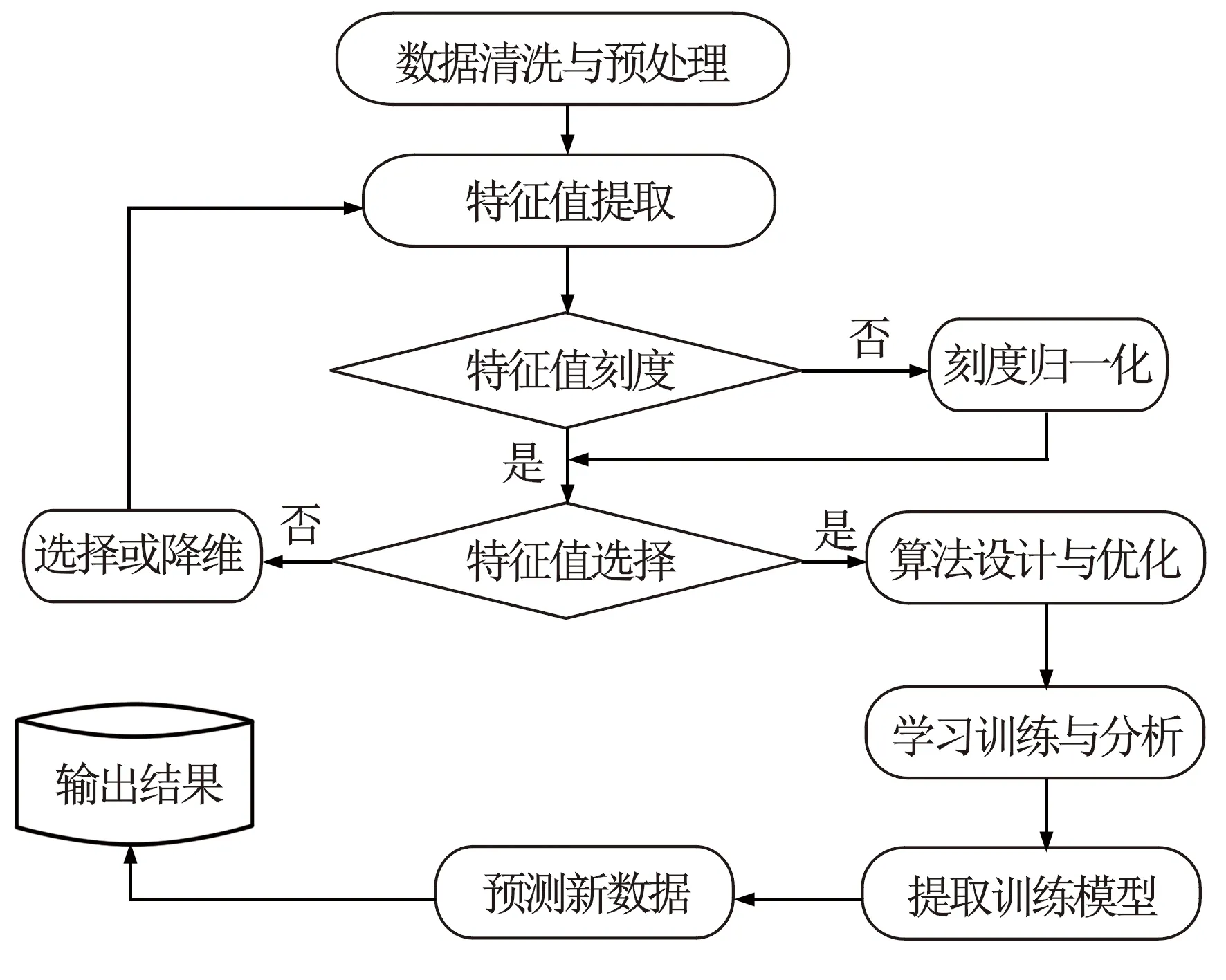
圖2 AI學習數據分析流程
3.4 平臺語言
目前Python語言的數據處理能力和豐富的學習庫,使其具有良好的多樣性和擴展性,這種設計架構有利于開展測井大數據管理、測井模擬仿真與測井數據處理、機器學習、深度學習、人工智能。同樣具有強大數據統計分析函數和AI學習功能包的R語言也正引起廣泛關注。總之,Python語言以其獨有的全球支持、免費開源、兼容性好、移植性強、可混合編程、簡單易學和具有強大的機器學習、深度學習模塊的優點,正受到越來越多工程師和研究人員的青睞。
3.5 測井大數據管理
目前測井大數據管理系統有2種:①Hadoop大數據平臺,其內核是基于Java建立的可擴展系統,通常由分布式文件管理系統(HDFS)、YARN、Apache Hives和Map Reduce組成,能在不受時間、地域限制的數十臺計算機上進行分布式數據存儲。HDFS數據結構可以提供高吞吐量的數據訪問,適用于具有大數據集的應用程序,可實現對文件系統數據的流式訪問。YARN模塊為分布式數據存儲和處理測井大數據平臺提供資源和進程管理。Map Reduce作業,將數據組織到分布式文件系統的表中,并在集群上運行處理,它的映射步驟是1個主節點接受輸入并將其劃分為較小的子問題,然后將其分配給工作程序節點,映射步驟完成后,主節點將獲取所有子問題的答案,并將其組合以輸出結果。這是測井大數據存儲、處理和輸出的基本原理。②以在Hadoop大數據平臺基礎上建立的Spark系統為代表的測井大數據存儲與處理系統,提供分布式任務分配、結構數據和非結構數據調度和基本數據輸入、輸出功能;Spark使用稱為彈性分布式數據集的特殊基礎數據結構,把存儲在不同機器上的數據形成邏輯數據集,從而形成內存式處理數據,免受磁盤數據傳輸率的影響。
3.6 人工智能測井發展階段
人工智能測井隨著信息技術和油氣勘探開發對測井技術的要求而發展。由于實際地層的復雜性,為滿足現場需求和測井儀器研發,地層模型設計越來越復雜,模擬網格形狀和網格數越來越多,現有的計算資源難以滿足現場需求。隨著勘探的深入,非常規油氣正引起石油公司的關注,傳統的儲層模型難以滿足復雜的非常規油氣儲層的建模和評價需求,以人工智能為內核的智能測井技術更適合解決這種非常規資源評價及開發。從現場需求角度,人工智能測井的應用可以貫穿油氣勘探和開發全階段。
成熟區塊有成熟的解釋模型,需要機器學習等智能算法從老井解釋結果或巖石物理測試結果中學習獲取參數,實現測井解釋智能化,即人工智能測井發展的第一階段:針對單口或多口井數據的AI學習和建模驅動助力測井專家的人工智能測井初級階段。由于面對的是小中型數據,人工智能測井的應用包括測井數據質量控制與標準化、地層對比、巖性識別、力學評價、缺失數據修復、區域測井曲線的深度匹配等工作。
隨著井況和安全環保的要求提高,評價地層變得越來越復雜,需要具有蛇結構的爬行臂,在井孔環境下能夠受系統導航自主移動測井儀器以適應井下狀況,自適應探測器和功率組合,即人工智能測井發展的第二階段:自主測井儀器具有學習建模和預測評價的人工智能測井中級階段。由于測井數據和其他油氣工業數據量的增加及算力提升,以數據和物理模擬驅動的人工智能測井將智能獲取地層真參數,對相同沉積環境巖心的巖石物理參數預測。
具有數字孿生的智能機器在測井大數據生態云中實現儀器探測參數調整、地層電聲核真測井值獲取、測井知識與規律的發現、人機交互學習、科學決策實施、深度強化學習完善和提高AIL的能力。進入人工智能測井發展的第三階段:人工智能測井高級階段。隨著智能儀器的發展,人工智能生態云的發展和完善,能夠實現隨鉆測井虛擬仿真導向、油藏智能描述、動態監測與壽命預測、虛擬測井儀器與地層真參數提取。
4 結 論
(1)以測井大數據平臺支撐、數據模型和物理模擬為核心的人工智能測井生態云的建立,標志著人工智能測井時代的來臨。
(2)人工智能測井將打破儀器制造、方法研究、巖石物理實驗、測井數據采集和測井解釋的界限,以數據為紐帶貫穿整個測井過程。
(3)信息技術的發展和油氣勘探開發的需求,促使人工智能測井的發展必將經歷作為測井專家助手為特征的AIL初級階段;自主移動儀器和建立在測井大數據基礎上的數據模型與物理模擬結合驅動的復雜模型建立為特征的AIL中級階段;以智能儀器和知識發現、深度強化學習完成智能測井體自我完善和提高為特征的AIL高級階段。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
西安航空學院學報(2022年2期)2022-07-04 07:45:42
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商界(2019年12期)2019-01-03 06:59:05
IT經理世界(2018年20期)2018-10-24 02:38:24
小康(2017年16期)2017-06-07 09:00:59
光學精密工程(2016年6期)2016-11-07 09:07:19
南風窗(2016年19期)2016-09-21 16:51:29
南風窗(2016年19期)2016-09-21 04:56:22
