邊緣設備上的葡萄園田間場景障礙檢測*
2021-09-23 14:19:48崔學智馮全王書志張建華
中國農機化學報 2021年9期
崔學智,馮全,王書志,張建華
(1. 甘肅農業大學機電工程學院,蘭州市,730070; 2. 西北民族大學機電工程學院,蘭州市,730030;3. 中國農業科學院農業信息研究所,北京市,100081)
0 引言
目前在農用無人駕駛方面,較為成熟的路徑規劃和避障方案是使用衛星導航[1]配合毫米波雷達[2],但這種方式對環境的感知水平較低,無法準確識別障礙物類型,只能在障礙物較少、信號良好的區域使用。相比于城市場景,農業田間場景障礙物體積相對較小,多數為柔性且位置固定(或移動緩慢)。探索快速、準確、經濟的田間障礙物檢測技術,可以推動無人駕駛農機發展,提升農業機械自動化和智能水平。
為解決田間障礙檢測問題,很多學者采用計算機視覺技術進行了探索[3-4],傳統方法處理速度快,但難以勝任復雜場景的高精度障礙檢測。近年來隨著深度學習技術興起,涌現出許多優秀的深度卷積神經網絡[5-8],它們在圖像識別方面取得了良好效果,將這些網絡作為主干網絡,研究者們設計了專用于目標檢測的網絡模型[9-11],其特征提取快,分類回歸更為準確,逐漸成為目標檢測的主流。一些學者開始在農業田間場景檢測方面使用深度學習方法。李云伍等[12]將丘陵山區田間場景障礙物分11類,構建了基于空洞卷積神經網絡的田間道路場景圖像語義分割模型,該模型包括前端模塊和上下文模塊,前端模塊為VGG-16融合空洞卷積的改進結構,上下文模塊為不同膨脹系數空洞卷積層的級聯,采用兩階段訓練方法進行訓練。劉慧等[13]針對果園環境復雜難以準確檢測出障礙物信息的問題,提出了一種改進SSD的深度學習目標檢測方法,使用輕量化網絡MobileNetV2作為SSD模型中的基礎網絡,以減少提取圖像特征過程中所花費的時間及運算量,輔助網絡層以反向殘差結構結合空洞卷積作為基礎結構對行人進行位置預測,在果園行人實時檢測上取得了較好效果。
普通目標檢測神經網絡可以實現高精度目標檢測,其缺點是運行消耗計算資源大,需要臺式服務器,但由于智能農機內空間有限,服務器在其上部署困難,且田間道路顛簸,會導致其工作可靠性降低。為解決以上問題,需使用輕量級神經網絡模型和堅固的邊緣設備。輕量級神經網絡模型雖然檢測精度相對一般,但消耗計算資源較少。邊緣設備雖然計算能力較弱,但體積較小,部署方便,在顛簸場景運行相對穩定,且價格較低。因此在邊緣設備上使用輕量級目標檢測模型實現實時障礙檢測功能對于實用的、廉價的無人駕駛農機具有重要意義。
本文選擇常用的邊緣設備NVIDIA JETSON TX2作為葡萄園田間場景障礙物快速檢測算法的硬件運行平臺,使用YOLOV3-TINY、YOLOV4-TINY、EfficientDet-D0、YOLO-FASTEST4種輕量級神經網絡在以葡萄園作為背景的自建田間場景數據集進行訓練,再將得到的4種網絡模型移植到TX2上,通過試驗比較這幾種目標檢測網絡的障礙檢測精度以及在TX2上的運行幀率、計算資源占用等項目,采用加權評分制對4種網絡在TX2上的綜合表現進行打分,優選出最適合移植到TX2上的目標檢測網絡。
1 4種輕量級目標檢測模型介紹
1.1EfficientDet-D0
EfficientDet[14]是Google Brain于2019年11月發布的目標檢測網絡。其多尺度特征融合網絡采用了加權雙向特征金字塔網絡(BIFPN)進行多尺度特征融合,通過自上而下以及自下而上的、跨尺度的對不同尺度的特征進行加權融合,BIFPN采用深度分離卷積進行特征融合,并在每次卷積后加入批量歸一化和激活,從而實現高效的聚合不同分辨率的特征。
本文所使用的EfficientDet-D0模型是EfficientDet所提供的預訓練模型中的輕量級模型,大小僅15.1 MB,非常適合遷移到邊緣設備上運行,其總體結構由EfficientNet-B0的3層64通道的BIFPN以及3層的類別預測/目標檢測層(CONV層)組成,其中EfficientNet-B0由1個輸出通道數為32、卷積核尺寸為3×3,步進為2的卷積層和16個MBConv運算塊組成。
EfficientDet采用的損失函數分為兩種,一種是分類損失函數,另一種是回歸損失函數。其中分類損失函數采用focal loss損失函數,用來控制正負樣本的權重以及控制容易分類和難分類樣本的權重;回歸損失函數采用SmoothL1 loss損失函數。
1.2YOLOV3-TINY
YOLOV3[15]系列是2018年最熱門的目標檢測網絡之一,而YOLOV3-TINY是YOLOV3的簡化版,其模型體積為33.7 MB。YOLOV3-TINY主干網絡在YOLOV3的基礎上進行了刪減,去掉了一些特征層,采用了7層2維卷積層輔以6層最大池化層網絡提取特征。多尺度特征融合方面,YOLOV3-TINY使用了FPN多尺度特征融合網絡,提升了對于細小目標的檢測能力。連接網絡方面,YOLOV3-TINY采用了13×13、26×26組成分辨率探測網絡。
1.3YOLOV4-TINY
YOLOV4系列目標檢測網絡是Bochkovskiy等[16]于2020年4月提出的目標檢測網絡系列,其中YOLOV4-TINY是YOLOV4的輕量級模型,其模型大小僅23.1 MB。YOLOV4-TINY為簡化運算,減少模型大小以及提高運行速度,僅使用FPN進行特征融合,并在損失函數中做了改進,使用了CIOU作為回歸損失函數。
在主干網絡方面,YOLOV4-TINY使用CSPDarknet53-TINY主干網絡,總體結構可以大致分為2個部分,主干網絡、多尺度特征融合網絡。主干網絡首先是通過2個特征提取層(包含2維卷積、批量歸一化、Leak ReLU激活)對圖片特征進行初步提取,然后3次使用CSP模塊加MAX POOLING層所組成的結構塊進行進一步特征提取。多尺度特征融合使用了若干卷積層和一組FPN,YOLOV4-TINY僅使用了兩個特征層(YOLO層)進行分類與回歸預測。
1.4YOLO-FASTEST
YOLO-FASTEST是2020年9月提出的超輕量級YOLO網絡模型。它在YOLOV4-TINY網絡模型的基礎上以降低檢測精度為代價,進一步減少其模型體積,其尺寸僅為1.3 MB,是目前最小的YOLO模型,方便移植到各類平臺,但是模型網絡結構較為復雜,共126層。
2 材料與方法
2.1 試驗平臺和試驗參數設置
2.1.1 訓練平臺及訓練參數
本試驗的訓練平臺其搭載了Intel?CORETMi5-8400六核處理器,基礎頻率2.80 GHz,最大睿頻4.00 GHz,GPU采用了NVIDIA RTX 2060 6 GB,基礎頻率1 210 MHz,最大頻率1 435 MHz,內存為Samsung DDR4@2 666 MHz 8 GB×2。軟件環境為Windows 10 1909 64 bit家庭版操作系統,GPU驅動程序版本為452.06、CUDA Toolkit 10.2。表1為4種網絡模型的實現方式。

表1 4種網絡模型的實現方式Tab. 1 Achievement method of four networks
其中,EfficientDet-D0、YOLOV3-TINY、YOLOV4-TINY的訓練參數一致:學習率0.001,迭代次數為2 000,采用批量訓練的方法,將訓練集以及測試集分為32個批次進行,既batch-size為32,將數據集設置為640×640的統一分辨率進行訓練和測試。
YOLO-FASTEST使用官方原版YOLOV4主程序,僅權重文件、配置文件不同,訓練參數設置:迭代次數18 000(2 000×類別數9),其余參數與其他3種網絡模型一致。
2.1.2 邊緣設備測試平臺
障礙檢查網絡訓練好后會被移植到邊緣設備上進行實際障礙檢測測試。本試驗中的邊緣設備平臺為NVIDIA公司的NVIDIA JETSON TX2(以下簡稱TX2)。其搭載了由HMP Dual Denver 2雙核處理器以及Quad ARM@A57四核處理器所組成的六核處理器,最高頻率2.00 GHz,GPU采用了NVIDIAPascal架構芯片NVIDIA Tegra X2,擁有256個CUDA計算核心,GPU最高頻率1 300 MHz,內存為LPDDR4 8 GB,該邊緣設備擁有板載CSI攝像頭。軟件環境Ubuntu18.04、python3編程語言、C編程語言、Pytorch深度學習框架、CUDA Toolkit 10.0、CUDNN 7.5.0。
2.2 試驗數據采集
田間場景圖像的采集是在甘肅省葡萄酒產業技術研發中心的葡萄園中完成,地點是甘肅省蘭州市安寧區甘肅農業大學校內。使用了搭載Intel REALSENSE D415攝像頭的上海一坤Bulldog無人車進行了葡萄園田間數據采集,對葡萄園內數條田埂周圍環境分時段(上午、中午、傍晚)、分天氣(晴天、陰天、雨天)、光照(無陰影、少量陰影遮蔽、大量陰影遮蔽、順光、逆光)、并以不同分辨率(640×480、1 280×780、1 920×1 080)進行了圖像、視頻采集。之后將視頻文件進行了圖像拆分,拆分幀率為10張/s,剔除冗余重復圖片,最終得到了無人車視角的4 400張田間場景圖片,包含9種障礙物,保證了數據集的豐富性。
2.3 試驗數據集制作
將采集到的上述4 400張圖片數據集使用labelme標注軟件對田間常見障礙進行標注,共分為9類:people(人)、fence(柵欄)、trellis(葡萄架)、stone(石塊)、root(根莖)、hole(坑洞)、dog(狗)、stair(臺階)、barrel(水桶)。考慮到數據集制作圖片隨機選取的原則、將所有圖片按拍攝時間分為10組,按照4∶1原則分別從這10組圖片中進行隨機選取,其中80%的圖片設置成訓練集、剩余20%為測試集。共得到訓練集3 520張,測試集880張。
2.4 障礙檢測精度評價指標
本文使用均值平均精度(mean Average Precision,mAP)來衡量網絡模型精度的好壞,其計算式
(1)
式中:N——類別數,在本試驗中為9;
AP——單個類別平均精度。
AP按照COCO競賽方式計算
(2)
其中Ri與Pi為P-R曲線上的取值點,i∈{0,0.01,0.02…0.99,1.00}共計101個值,COCO的AP計算方式會取多個交并比(Intersection Over Union,IOU)值進行計算,本試驗的AP僅取IOU=50%的結果。
以單個類別召回率為橫軸,單個類別識別精度為縱軸,即可繪制P-R曲線。P-R曲線的P為單個類別識別精度(Precision),其計算式
(3)
式中:TP——分類器認為是正樣本,并且符合實際情況;
FP——分類器認為是正樣本,但實際是負樣本。
P-R曲線的R為單個類別召回率(Recall),其計算式
(4)
式中:FN——分類器認為是負樣本,但是實際是正樣本。
2.5 邊緣設備上的視頻檢測性能評價
本試驗為TX2實時視頻的障礙檢測試驗,TX2開啟最大性能模式(MAXN模式),關閉所有無關終端窗口,確保每次測試僅開啟一種網絡模型檢測程序以及jetson-stats系統資源監測程序。
實時視頻檢測的目的是為了評價不同障礙檢測網絡模型在TX2上的運行性能,優選適合在TX2進行實時目標檢測的網絡模型。由于運行目標檢測模塊會占用不小的系統資源,可能會影響整個檢測系統的其他功能模塊運行(如距離檢測、避障等),所以除了檢測精度和幀率外,有必要結合各模型對硬件資源占用情況綜合分析其性能。本文采用打分制來評價網絡模型的綜合表現,其計算公式
(5)
式中:ST——總得分;
s1、s2、s3——mAP項得分、平均幀率項得分、資源占用得分;
w1、w2、w3——上述3項得分的加權系數,其和為1。
考察資源占用得分時從以下3個子項給出其分值:GPU使用情況、CPU使用情況以及RAM使用情況。
根據經驗,在田間場景障礙實時檢測中,檢測流暢性最為重要,障礙物檢測精度次之,硬件資源消耗情況再次之。因此本文根據重要程度對所有檢測項加權系數做出如下賦值:w1為0.4,w2為0.5,w3為0.1。
所有測試項目的評分以設置標準為最高得分(5分),每下降標準的20%,得分降低1分,測試項目評價標準如表2所示。
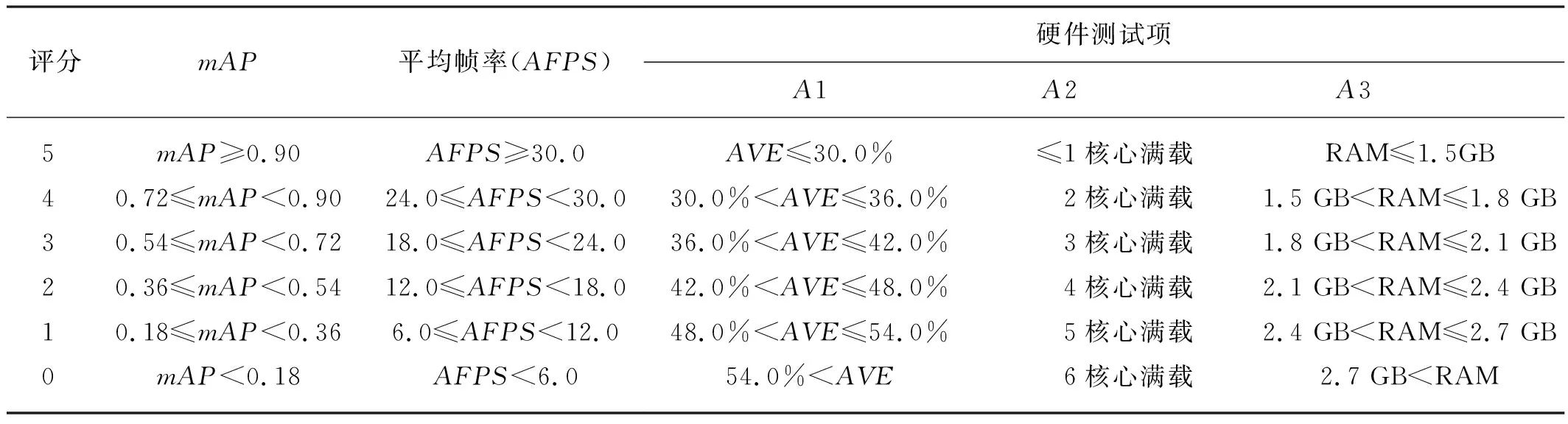
表2 測試項目評價標準Tab. 2 Rating criteria of test items
3 結果與分析
3.1 障礙檢測結果與分析
圖1(a)給出了EfficientDet-D0、YOLOV4-TINY和YOLOV3-TINY的訓練損失曲線,YOLO-FASTEST迭代次數與上述三種網絡相差較大,其訓練損失曲線如圖1(b)所示。EfficientDet-D0損失曲線收斂最為迅速,且最終損失值比其他兩種網絡模型小2.0左右。YOLOV4-TINY、YOLOV3-TINY總體誤差曲線十分相似,其曲線趨勢幾乎一致,YOLOV3-TINY曲線略優于YOLOV4-TINY,差距在0.2以內。對比圖1(a)與圖1(b)可以得知,YOLO-FASTEST總體損失曲線無論從曲線穩定性上還是最終值上都遜色于其他3種網絡。YOLO-FASTEST總體損失曲線波動較大,其最終損失值大于2.5。
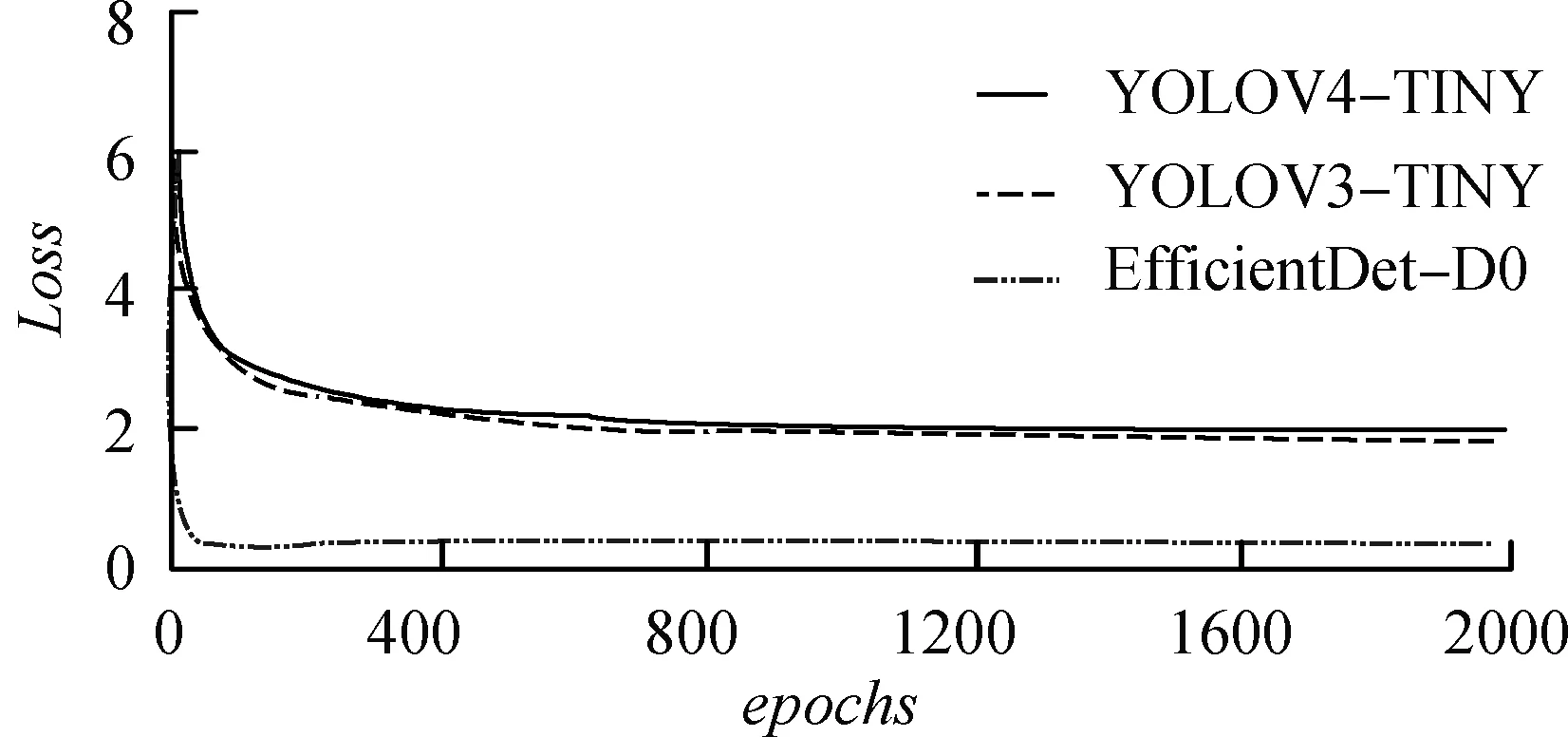
(a) EfficientDet-D0、YOLOV3-TINY、YOLOV4-TINY
圖2為4種網絡模型在測試集上的mAP以及各子類的AP。EfficientDet-D0、YOLOV4-TINY、YOLOV3-TINY和YOLO-FASTEST三種網絡模型的mAP分別為0.598、0.601、0.648和0.401,YOLOV3-TINY的mAP值最高。而YOLO-FASTEST網絡模型的mAP最低。
從圖2可以看出,在4種網絡模型對于各子類AP值測試中,EfficientDet-D0網絡模型在“hole(0.93)”“people(0.923)”“root(0.727)”“barrel(0.534)”“fence(0.742)”等五類障礙上的AP值測試處于第一位,對“stair(0.079)”類障礙的AP值測試處于第4位。YOLOV3-TINY網絡模型對于“trellis(0.597)”“stair(0.316)”“stone(0.627)”“dog(0.785)”四類障礙的AP值測試處于第1位,對于“fence(0.582)”類障礙的AP值測試處于第4位。
YOLOV4-TINY網絡模型對于“hole(0.818)”“people(0.809)”三類障礙的AP值測試處于第4位。YOLO-FASTEST對于“trellis(0.271)”“root(0.398)”“barrel(0.049)”“stone(0.224)”“dog(0.000 2)”五類障礙處于第4位。

圖2 4種網絡模型最終模型測試柱狀圖
在這4種網絡模型中,EfficientDet-D0網絡模型對于自建數據集內五類障礙檢測平均精度在4種網絡中最高,但對細小障礙的檢測平均精度可能較差;YOLOV3-TINY網絡模型對于自建數據集內的障礙檢測平均精度在4種網絡中處于第2位,其四類障礙檢測平均精度在4種網絡中最高,且沒有精度低(AP<0.1)的明顯短板;YOLOV4-TINY網絡對于自建數據集內障礙的平均檢測精度比較中庸,但其各子類的AP與最好模型的AP相差不大;YOLO-FASTEST網絡模型除了對于自建數據集內“hole”“people”“fence”的AP尚可外,其他類AP均較低。
總體而言,對于自建數據集內紋理清晰、畫質較好的兩類“hole”“people”而言,4種網絡模型平均檢測精度均在80%以上,處于較好水平。對于畫質模糊,背景復雜的“stair”類而言,4種網絡檢測平均精度均較差。對于其他類別障礙而言,4種網絡模型表現不一,各有優劣,但總體水平比較一般,如圖3所示。

(a) EfficientDet-D0 (b) YOLOV3-TINY
3.2 4種網絡模型在TX2上實時視頻檢測結果分析
表3為TX2上實時視頻檢測結果。根據表3的實時檢測結果以及圖2中給出的4種網絡模型的mAP值,采用2.5節的評分標準計算了各模型在TX2上的評分結果,如表4所示。從表4可以看出YOLO-FASTEST和EfficientDet-D0在資源占用項得分很高,特別是前者,因其模型尺寸最小,占用內容也最少。出乎意料的是,雖然YOLO-FASTEST是C語言編寫且模型很小,但其檢測速度只排在第3位,無法達到實時障礙檢測的效果,與原文試驗結果相差很大。究其原因,可能是TX2的GPU與原文試驗中的型號不同,在TX2的GPU和CPU上,其核心Darknet分組卷積沒有得到很好的支持(可能與NVIDIA的CUDNN有關),檢測效率低下,導致在TX2上的檢測速度很慢,其運行效率反而不如使用python編寫的YOLOV3-TINY和YOLOV4-TINY,僅略強于模型復雜度遠高于它的EfficientDet-D0。這說明模型尺寸小和高效編程語言并不能必然導致模型速度快,對于并行單元很多的深度檢測模型,各種支持庫和深度開發平臺與運行硬件的配合與優化可能更為重要。
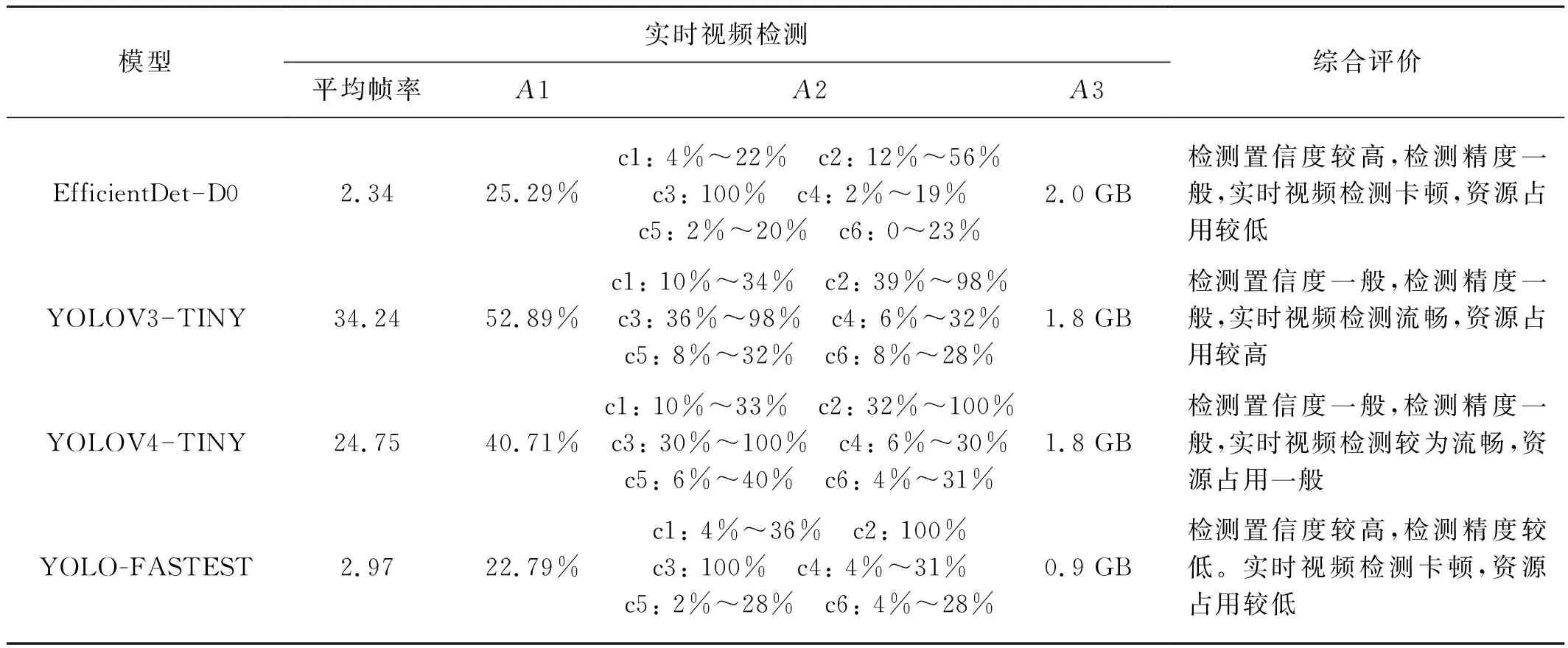
表3 TX2視頻實時檢測試驗結果Tab. 3 Experimental results of real-time video detection on TX2
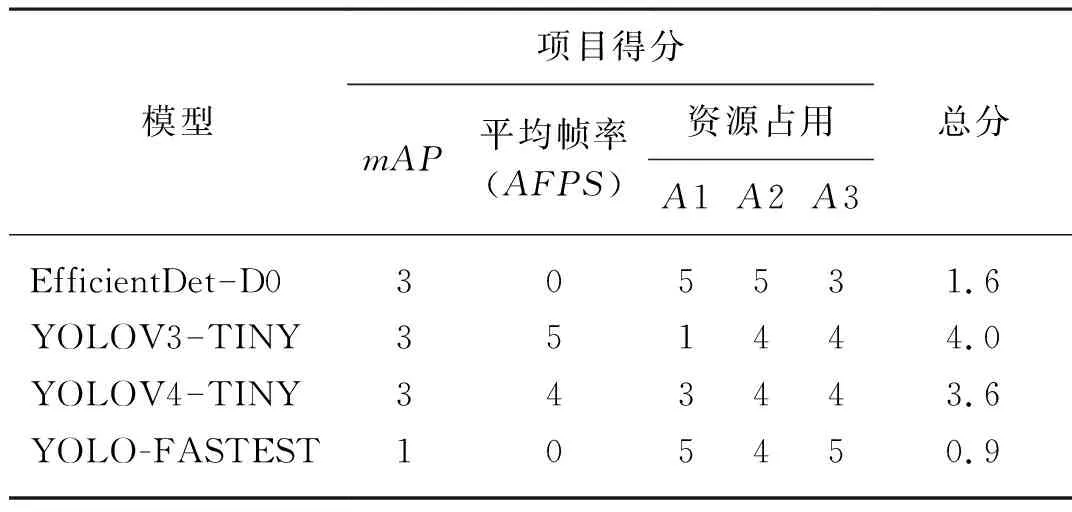
表4 4種網絡模型得分表Tab. 4 Score table of four network models
由表4可得,對于“平均幀率”檢測項,YOLOV3-TINY和YOLOV4-TINY排在前2位,可以實現實時檢測,且其mAP值均較高,雖然占用資源項得分較低,但憑借w1和w2的高權重,使其分別占得綜合評分的前2位。因此在TX2上進行單純性的障礙檢測時,可優先選擇YOLOV3-TINY。如果實際自動駕駛系統由多種模塊組成,當有多個深度學習任務同時需要申請GPU時,考慮到YOLOV3-TINY對GPU占用率最高,采用YOLOV4-TINY可能更有利于系統整體性能的提升。
3.3 4種網絡模型的對比
EfficientDet-D0的優點是對于9類障礙物中的5類障礙目標檢測精度相比而言最高,且其檢測置信度非常高,不易出現誤判,消耗系統計算資源較少,利于系統其他程序運行。缺點是其對細小障礙目標的檢測存在較為明顯的檢測精度短板,進而導致了總體檢測精度的下降,因其對于系統計算資源的調用不夠充分導致了實時檢測速度慢。EfficientDet-D0對本場景的適用性較差,更適合靜態圖片檢測。
YOLOV3-TINY的優點是對于9類障礙物的總體檢測精度最高,且沒有檢測短板,實時視頻檢測流暢。缺點是其檢測置信度一般,可能出現誤判且系統計算資源占用較高。YOLOV3-TINY對本場景的適用性相比之下最好,適合運行單障礙檢測任務的場合。
YOLOV4-TINY的優點是平衡性較好,可以在系統計算資源占用適中的情況下進行較為流暢的實時視頻檢測,且不存在精度上的明顯短板。缺點是檢測置信度一般,可能出現誤判。YOLOV4-TINY對本場景的適用性較好,適合多任務并行運行的場合。
YOLO-FASTEST的優點是檢測置信度較高,且系統計算資源占用相比而言最低;缺點是檢測精度差,存在短板,且因CUDA對于C語言程序支持性較差導致了系統資源調用不充分,致使實時視頻檢測卡頓。YOLO-FASTEST對本場景的適用性差,更適合靜態圖片檢測場景。
4 結論
為了實現在邊緣設備TX2上進行葡萄園田間場景目標檢測,本文使用4種目前較為熱門的輕量級目標檢測神經網絡模型在自建數據集上進行訓練,并移植到TX2上進行了試驗,得到以下結論。
1) YOLOV3-TINY作為一款2018年提出的輕量級網絡模型,在自建數據集上,其mAP值(64.8%)領先于EfficientDet-D0(59.8%)、YOLOV4-TINY(60.1%)、YOLO-FASTEST(40.1%),且各子類AP值并無明顯的非常低的短板(<10%)。
2) EfficientDet-D0與YOLO-FASTEST對于AP值較好的類別(>80%)目標檢測置信度比YOLOV3-TINY、YOLOV4-TINY高,且更穩定,YOLOV3-TINY、YOLOV4-TINY在AP值較好的類別目標檢測中存在置信度較低且波動明顯的問題。
3) 根據試驗結果,在TX2上,如無需同時運行多個GPU任務,YOLOV3-TINY得分最高,可以流暢的進行攝像頭視頻檢測,實時性較其他3種輕量級網絡模型更優,但是其實時視頻檢測耗費GPU資源較大。如需同時運行多個GPU任務,YOLOV4-TINY可以在消耗較少計算資源的情況下比較流暢的進行實時視頻檢測。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
