基于R語言的社交網絡數據信息挖掘
2021-09-18 02:57:48孫澤龍
電子測試 2021年16期
孫澤龍
(西安職業(yè)技術學院,陜西西安,710077)
1 R 語言的特點
R 語言是數據分析并進行可視化展示實現的實用工具,數據科學的不斷發(fā)展,使得我們需要把數據映射成為方便查看的圖形、圖像或微視頻等,用戶對數據的交互更為方便,容易從中理解和讀取數據。R 語言擁有靈活性和多樣性的特點,使用它可以根據用戶的不同需求,通過R 語言工具本身提供的大量R 函數,可以完成相對應的圖形圖標繪制,依據函數的幫助信息,對于特殊圖形要求的還可以自己編寫程序,繪制符合個性化要求的圖形。
生活中全國春運客流數據,氣象云圖數據、用戶搜索生成搜索網絡數據,微博用戶相互關注和傳播的數據,電子商務購物網站等都可以稱得上是大數據產生的源頭聚集地,數據爆發(fā)式增長和社會化趨勢是大數據產生的本質原因。爆發(fā)式增長是現在實時數據、非結構化數據、機器數據產生的迅速是以前無法想象的。摩爾定律中全球每18 個月產生的數據量是之前有計算機歷史以來數據的總和,現在更新后需要的時間更短了。用戶的行為和關系產生大量的碎片化信息被互聯網所記錄。大數據體量之大使得現有數據庫技術無法承載,視頻、音頻等存儲遇到問題,實時生成數據之快傳統數據庫和網絡架構無法滿足,數據產生的價值密度低,需要挖掘展現其中的價值。
2 社交網絡的特點
互聯網上擁有用戶實時生成的海量數據,這些數據往往具有碎片化,當然也存在著N 度好友理論,說的是你的好友的好友依次往下不超過六個的好友可以覆蓋你所在區(qū)域或更廣的所有人,由于社交網絡工具的便捷,使得生成的這些數據記錄著上網用戶的情緒和智慧,這些龐大的群體用戶蘊含著社交網絡的價值。比如利用社交網絡挖掘價值,可以進行預測天氣的變化,通過各個地區(qū)很熱的人數來進行監(jiān)測,在微博網絡上選取一些關鍵詞種子描述很”熱”的詞需要關注的,在一定語境下的熱才指天氣熱,選取相應數據并進行文本集合算法的規(guī)則處理,當然關于’熱’的方言相關詞和綜合語境都要提取文本處理相關語境,根據語法結構判斷真正的天氣熱。經過這些處理后再統計出各個地區(qū)很熱的人數,然后得到”熱”的數據,加上日期后可以根據時間的推移看出不同地區(qū)天氣的變化情況。預測選用的方法會對結果產生影響。
社交網路也存在著問題和挑戰(zhàn),有時同一個句子不同語境所表達的意思會不一樣,這就涉及到機器對自然語言規(guī)則的處理,不同場景中情感分析中詞匯本題庫的積累,微博或論壇數據中涉及大都是稀疏文本或表情符號信息提取、垃圾信息地處理等面臨一定的問題,抽樣數據中不是所有的信息都有用,有用的數據是否抽取全面和抽樣方法的合理性都可能影響最后的處理結果。
3 數據信息挖掘
把從數據源文本中抽取出的特征詞,進一步量化的過程來進行表示文本信息。將它們從一個無結構的原始文本轉化為結構化的計算機可以識別處理的信息,即對文本進行科學的抽象,建立它的數學模型,用以描述和代替文本。文本挖掘是從大量文本數據中提取前所未知的、有用的、可理解的、可操作的知識的過程。文本挖掘包含了學術或技術報告、新聞、網頁、用戶手冊等都是文本挖掘的數據來源,文本挖掘的主要任務是包含對詞或短語的關鍵字提取;對詞條的關系建立對應文本的主要概念,進行概念提取;從多角度出發(fā)進行分析,實現可視化的顯示或導航;文本挖掘與數據挖掘有著緊密的聯系,主要區(qū)別如表1 所示。
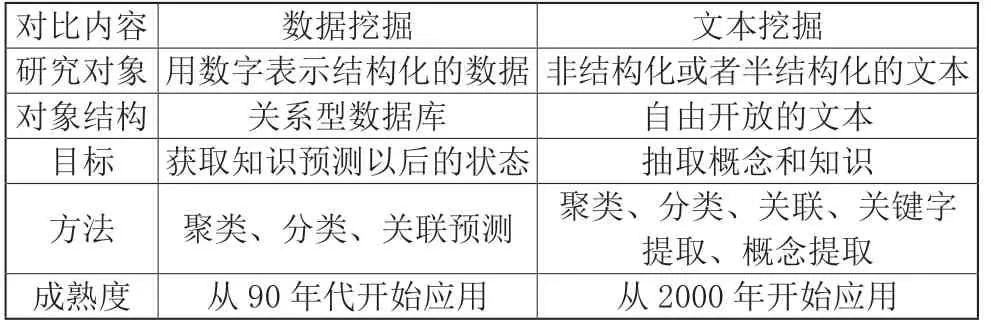
表1 對比數據挖掘與文本挖掘
使計算機能夠通過對這種模型的計算和操作來實現對文本的識別。短語提取是提取文本集中所有相關的短語。概念提取是對這些短語之間的關系,建立一個該文本集中的主要概念。可視化顯示和導航是從多個視角出發(fā)進行分析。本文數據來源是一個班級群里,近一個月時間里群里消息文本資料,班級群里面應該有老師,學生,學生里面有學生的班干部等,通過對此數據進行挖掘分析,從下圖2 所示,來找出群內高頻詞匯,分析群里面近期關注的熱點信息等。

圖1 高頻詞挖掘圖
4 數據分析應用
聊天時間統計后發(fā)現,群里早上10 點前基本很少有人聊天,11 點后聊天數量逐步上升,一天時間段中晚上9-11點聊天是最為活躍的。從下圖2 所示時間分布圖中,可以看出群聊里在一天中聊天的活躍度分布情況。這樣就可以看出,如果需要討論或者通知相關事宜,就可以適當選擇合適的時間進行,比如早上方便通知消息或發(fā)布文件資料等信息,這樣重要信息就不會被吞沒,而討論適合在晚間進行。
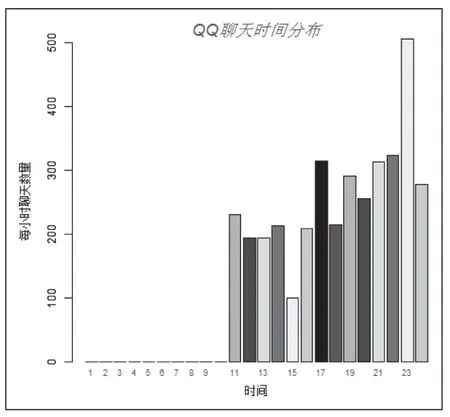
圖2 聊天時間分布圖
5 結語
隨著大數據與云計算的發(fā)展,網絡上的信息內容和文本類型將變得日趨豐富。本文在對文本內容分析為研究目的和文本挖掘模型的基礎上對高頻詞、時間分布兩個參數為研究對象進行了分析。從高頻詞和時間分布的圖表中,我們可以判斷出來群信息最近談論的最熱的話題等。以上分析的數據只是建立在現有的數據之上的,統計數據只能統計出大概的事情發(fā)展趨勢,可能會有許多的誤差,所以還需進一步完善和優(yōu)化進而做出更準確的判斷。今后教學實踐將繼續(xù)以數據挖掘案例為載體,“新工科”建設為指導,設計更多基于有數據挖掘價值的應用案例,提升教育教學水平和激發(fā)學生學習興趣。
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
電力與能源(2017年6期)2017-05-14 06:19:37
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
小學教學參考(2015年20期)2016-01-15 08:44:38
信息通信技術(2015年6期)2015-12-26 01:16:46
創(chuàng)業(yè)家(2015年5期)2015-02-27 07:53:25
