三維熒光光譜技術結合線性支持向量算法在水體有機污染監測中的應用
2021-09-14 09:33:30謝繼征郭宏達孫小平王志剛
光譜學與光譜分析 2021年9期
戴 源,謝繼征,袁 靜,沈 薇,郭宏達,孫小平,王志剛
1. 江蘇省揚州環境監測中心, 江蘇 揚州 225100 2. 揚州大學環境科學與工程學院, 江蘇 揚州 225009
引 言
隨著城市化進程的日益加快, 城市及周邊地表水的污染源不斷增加, 水質不斷惡化, 對生態系統和人類健康構成威脅[1]。 城市及周邊地表水中的有機污染物主要來自陸地生活源、 地表徑流、 工業、 服務業、 養殖業和水生生物源污染, 以蛋白質、 氨基酸、 腐殖酸、 脂肪等有機污染物為主。 環境監測技術通過化學需氧量(CODCr)、 高錳酸鹽指數(CODMn)、 氨氮(NH3-N)、 總磷(TP)、 總氮(TN)和五日生化需氧量(BOD5)等指標表征水體有機污染, 其中CODCr, CODMn和BOD5通常用于表示水體中有機污染物總量; NH3-N, TN和TP的含量升高會導致水體富營養化, 破壞生物多樣性并產生臭味。
城市及周邊地表水一直以來都是環境監測工作的重點, 但傳統監測手段存在監測周期長、 采樣缺乏代表性、 水樣前處理復雜、 分析難度高等困難, 往往造成監測數據時空分布不足, 監測數據滯后等問題, 因此開發連續、 高效、 低耗的水質原位監測技術具有重要意義[2]。 近年來, 水體熒光光譜技術常被用來快速反演水體中TP, TN, NH3-N, BOD5和COD等指標[3-5], 避免了化學試劑的使用和復雜的水樣前處理過程。 三維熒光光譜技術可以在較寬的激發和發射波長范圍內獲取水體有機物豐富的光譜信息, 具有快速、 可靠、 實用的優點, 近年來被廣泛應用于化學分析和環境監測領域。 Yang等[6]使用激發發射矩陣三維熒光平行因子法(EEM-PARAFAC)對污水處理廠水樣進行分析, 得到類蛋白等有機污染物的熒光特征峰位置, 利用多元線性回歸算法(multiple linear regression, MLR)針對COD等有機污染指標建立預測模型, 實現對水處理效果的快速評價。 陳方等[7]使用平行因子算法(PARAFAC)分析苯酚等有機污染因子的三維熒光光譜, 提出針對清潔水和污水的二分類支持向量機(SVM)模型。 但是, 現有研究大多針對模擬配制水樣或單一類型的少量水質樣本, 依賴已有的光譜特征經驗選擇算法, 從三維熒光光譜中提取若干點狀光譜信息用于水質評價。 由于地表水中有機污染物種類繁多, 各種物質的熒光峰位置和波段范圍不同, 且存在熒光峰重疊現象, 因此這種僅選擇少數光譜點的計算方法局限性強、 泛化性能較差。
支持向量回歸算法(support vector regress,SVR)是一種被廣泛應用于機器學習和數據挖掘領域的算法模型。 常規的SVR算法通過不同的核函數來構造非線性模型用以解決復雜的分類和回歸問題, 但是當樣本量較大或特征維度較高時, SVM算法存在消耗資源多、 訓練時間長等問題。 LIBLINEAR是一個針對線性分類場景而設計的工具包, 支持線性SVM和線性邏輯回歸等模型, 可以對高維度大樣本數據進行快速建模。 該工具包采用熱啟動(warm-start)技術實現高效的參數尋優過程, 并結合交叉驗證方法得到最優懲罰參數C和不敏感度ε, 具有建模速度快、 計算精度高等特點。
本文對揚州市域內多種類型地表水進行了長期的三維熒光光譜采集和水質分析, 形成了具有多樣性和代表性的水質樣本集合, 首次將LIBLINEAR技術應用于三維熒光光譜水質監測, 充分利用豐富的三維熒光光譜信息, 將水體三維熒光光譜的全波段數據作為算法的輸入, 快速建立了CODCr, CODMn, NH3-N, TN, BOD5和TP等6項水質指標的預測模型, 并且通過水質指標的預測結果進一步判斷水體有機污染指標相關的水質等級, 實現對城市及周邊地表水水質指標和水質等級的快速原位監測。
1 實驗部分
1.1 樣品采集
從2016年1月至2019年8月, 每月對揚州市域內122個地表水監測斷面進行水樣采集, 使用直立采樣器采集水面下50 cm深處的水體5 L, 靜置30 min后取上層清液, 按照水質采樣規范平行分裝在棕色玻璃瓶中, 并于4 ℃保存。 采樣現場同時測量水體的溫度(T)、 溶解氧(DO)含量和pH值。
水質監測斷面共122個, 涉及長江和淮河兩大流域, 覆蓋了揚州市域內大部分的主要河流和湖泊, 分布如圖1所示。 城市建成區內設有87個監測斷面, 囊括了55條城市河流和4個小型湖泊, 其余35個監測斷面分布在市域城郊及農村區域。 根據2016年—2019年揚州市水環境監測數據, 監測斷面水質等級包含Ⅱ類~劣Ⅴ類, 此外還存在少量輕度和重度黑臭斷面。 樣本的采集時間涵蓋了多個季節和枯豐水期, 涉及水溫、 水位、 水流和周邊生態系統等多種環境因素變化對水質的影響, 由此形成一個覆蓋區域廣、 時間跨度長、 水質變化多的樣本集合。
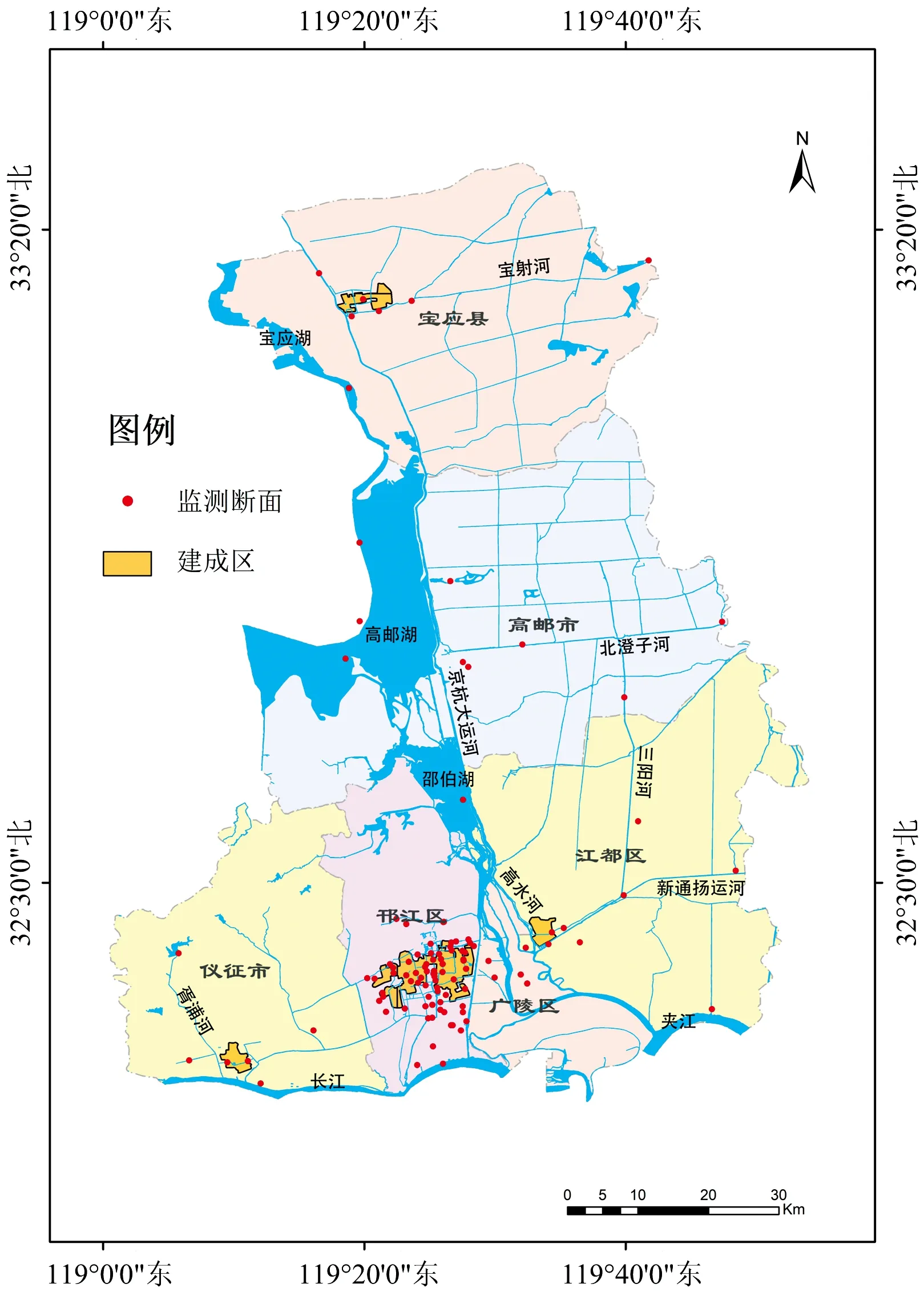
圖1 水質監測斷面分布Fig.1 Distribution of water quality monitoring sections
1.2 化學分析
為保證化學分析與光譜分析的樣品一致, 將樣品搖勻并靜置30 min后取上層清液進行檢測, 檢測方法參照相關國標和行業標準, 使用儀器和具體分析方法見表1。 其中pH值、 DO和T在采樣時現場測定, 所有樣品在采樣1周內完成分析測試, 測試結果見表2。 每項指標的測試結果中, 最大值與最小值差異大, 樣本包括不同污染程度的多種水體。 此外, 本實驗涉及的樣本數量大、 水質指標多, 為建立水質指標預測模型提供有利條件。
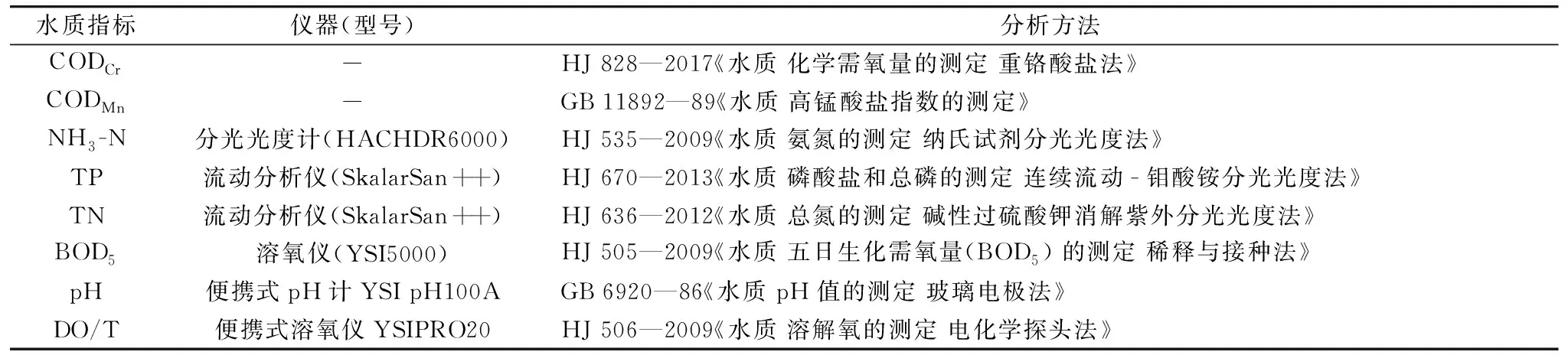
表1 儀器及分析方法Table 1 Instruments and analysis methods
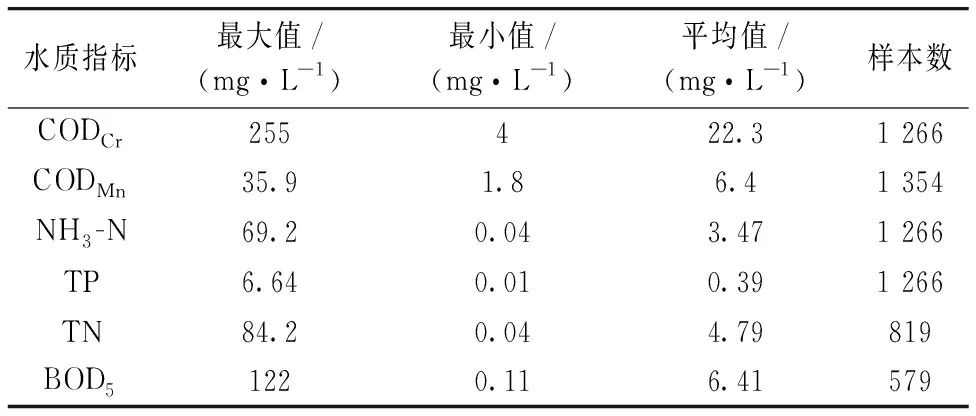
表2 化學分析結果Table 2 Results of chemical analysis
1.3 三維熒光光譜測量
采用中國科學院安徽光學精密機械研究所改造的日立 F4600型熒光分光光度計測量水樣三維熒光光譜, 該儀器在保留原有光路設計的基礎上添加自動進樣和清洗裝置, 在底部加裝避震裝置, 可實現在水質自動站或監測車中的連續快速原位監測。
每次對空白樣品(Milli-Q超純水)進行掃描后再進行水樣測量。 三維熒光光譜測量前, 先將水樣搖勻后靜置至室溫。 若水樣的熒光強度超出儀器測量范圍, 須用超純水稀釋。 樣品光譜平行測試的相對精度偏差應小于2%[4], 同批水樣的光譜分析與化學分析時間間隔不超過24 h。 光譜測量參數設置如下: 激發波長Ex為220~400 nm, 采樣間隔5 nm; 發射波長Em為260~520 nm, 采樣間隔1 nm; 狹縫寬度為10 nm, 掃描速度為12 000 nm·min-1。
1.4 模型建立
本文采用MATLAB2019(Mathworks,Natick,MA,USA)軟件構建水質指標預測模型。 訓練集與測試集樣本的劃分采用隨機抽樣法, 抽取20%的樣本作為測試集, 用于評價模型的泛化能力和預測效果, 剩余樣本作為訓練集用于建立預測模型。
1.4.1 數據預處理
使用Delaunay三角形內插值法對原始光譜中包含的瑞利散射和拉曼散射進行修正。 為消除實驗環境變化和光譜儀光源波動的影響, 從樣品光譜中扣除空白樣品光譜, 并用空白樣品在Ex=348 nm和Em=397 nm處的拉曼峰強度值對去散射處理后的樣品光譜強度值進行拉曼歸一化處理[8]。
1.4.2 線性支持向量回歸模型(LIBLINEAR)
本文將每個激發-發射波長對應的熒光強度作為水質指標的潛在預測因子, 為降低數據冗余度、 提高模型收斂度, 將預處理后的三維熒光光譜去除激發波長大于發射波長的光譜區域, 結合T, DO和pH值形成7601維向量。 將該向量作為算法的輸入, 以各水質指標的化學分析結果作為算法目標值, 使用LIBLINEAR工具包建立L2正則L2誤差支持向量回歸模型(L2-regularized L2-loss support vector regression), 通過調整權重向量ω, 使L2正則項與L2誤差項之和最小。

1.4.3 模型評價標準

1.4.4 水質分類標準及方法
表3是根據GB3838—2002《地表水環境質量標準》和《城市黑臭水體整治工作指南》中的標準限值制定的水質分類標準, 基于該標準使用模型預測結果對有機污染指標相關的水質等級進行判斷。 針對不同的水質判斷需求, 本文設計了如表4所示的4種水質分級方法。 方法的分級數量越多, 對水質狀況的區分越細致。 其中“劣Ⅴ類”在本文中定義為超過Ⅴ類標準限值但尚未達到輕度黑臭的水體。
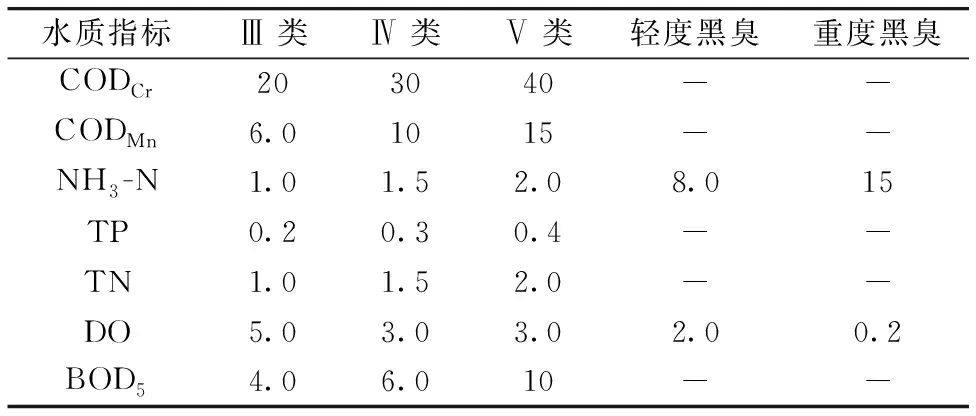
表3 水質分類標準限值Table 3 Water quality classification standard limits (mg·L-1)
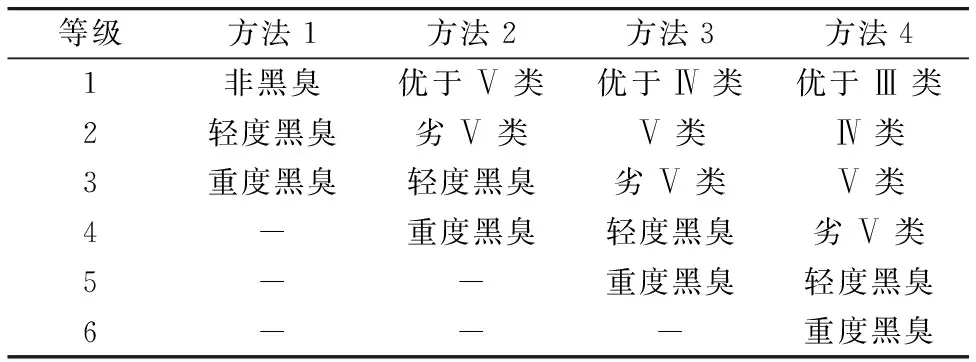
表4 四種水質分級方法Table 4 Four water quality classification methods
2 結果與討論
2.1 水質指標模型及預測結果
圖2為水質預測模型中三維熒光光譜權重的分布圖, 如圖2所示, 各模型權重較大的三維熒光光譜位置主要分布在7個熒光區域, 熒光區域的范圍和對應組分信息如表5所示, 可知A—F均為水體中常見溶解性有機污染物的特征熒光區域, 其中A與水體中的分子量較大的類腐殖酸相關; B區域內的熒光峰常出現在城市廢水光譜中, 被認為是與微生物相關的類腐殖質物質(可溶性微生物副產物)[8]; C對應類富里酸的熒光特征峰, 其來源為陸源前驅染物[9]; D為游離態類色氨酸的熒光峰, 其光譜值與水體中微生物細胞數量緊密相關, 可以表征水生態系統的微生物活性[9]; E和F為酪氨酸等芳香族蛋白質的特征光譜范圍, 主要來自生活源有機污染[10]; G被定義為類色氨酸的特征光譜區域, 其光譜強度同采樣斷面與污染源排口之間的距離和水體中污染物的新鮮程度有關[9]。

表5 熒光區域范圍及組分Table 5 Fluorescence regions and components
由圖2可知, 6項水質指標預測模型中正權重均主要分布于6個熒光區域內(A—F), 而負權重主要集中在G區域中, 說明6項水質指標預測值均與色氨酸、 酪氨酸、 類腐殖酸、 類富里酸和類蛋白等有機污染物的熒光強度成正比, 與G區域的熒光值成反比。 此外, 各預測模型的權重分布略有不同, 其中CODCr模型正權重的覆蓋范圍大于CODMn, 說明有更多的有機物熒光信號會對CODCr的預測結果產生正影響; D, E和F所代表的蛋白質和氨基酸熒光區域在NH3-N和TN模型中具有較大的正權重, 并且TN模型具有更大的正權重范圍; TP的正權重分布較為集中在類腐殖酸特征范圍內; BOD5的正權重集中在D區域內, 說明BOD5的預測值與色氨酸光譜強度具有較高相關性, 這與Henderson等的研究結論一致[11]。 由此可知, 基于全波段的預測模型與以往的固定點式光譜模型相比, 該模型能夠針對不同的水質指標對每一個光譜位置設置相應的權重, 并且模型權重分布符合水質指標與有機污染物的邏輯關系, 可以更加充分地利用水體三維熒光光譜信息建立光譜與有機污染物之間的定量關系。
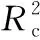
表6 模型預測結果Table 6 Prediction results of models
圖3為使用Matlab2019軟件進行的模型預測值與化學分析值的相關性分析。 從圖3可知, CODCr, CODMn, NH3-N, TN, BOD5和TP六項水質指標的預測值和實際測量值之間的相關系數R分別為0.95, 0.92, 0.92, 0.91, 0.94和0.90, 并且通過了p=0.05的顯著性水平檢驗, 說明LIBZINEARSVM模型預測的各水質指標結果與國標及行業標準分析結果具有較高的擬合度, 證明了三維熒光光譜技術用于監測水質污染狀況的可行性, 本方法可為城市及周邊地表水的快速、 原位、 高效監測提供解決方案。

圖3 模型預測值與化學分析值的相關性Fig.3 Correlation between predicted value and chemical analysis results
2.2 水質分類結果
為了驗證水質分類的預測效果, 使用LIBLINEAR模型對100個未知水樣進行水質指標預測, 并用預測結果按照表3中的標準判斷其水質類別。 分類預測效果通過準確率A和F1分數兩個指標評價。 其中A代表正確判斷的樣本數和總樣本數的比值;F1分數是查準率P和查全率Re的調和平均數, 可以綜合評價分類效果。 計算公式如式(4)
其中,TP為真正例樣本數,TN為真反例樣本數,FP為假正例樣本數,FN為假反例樣本數。
圖4為表4中4種分級方法的水質分類結果。 如圖4所示, 方法1, 2, 3和4的水質分類準確率分別為86%, 74%, 67%和60%, F1分數分別0.93, 0.88, 0.84和0.77, 隨著分級的細化, 水質分類準確率和F1分數有所下降, 說明水質指標預測結果對清潔水體的細化分類稍有不足, 但對較重污染水體的水質分級具有較高的正確率和識別精度。 總之, 本方法可以快速判斷水質等級, 并同步顯示超標污染物及其濃度值, 實現對地表水水質的高效監測和精準評價。

圖4 水質分類結果Fig.4 Water quality classification results
3 結 論
對揚州市域內122個地表水監測斷面的三維熒光光譜信息和水質狀況進行了長期積累形成了覆蓋范圍廣、 時間跨度長、 水質變化多的樣本集合, 基于全波段光譜數據使用LIBLINEAR算法建立了針對CODCr, CODMn, NH3-N, TN, BOD5和TP 六項水質指標的預測模型, 模型的權重分布與多種溶解性有機物的熒光特征區域重合, 說明該模型可以綜合地反應地表水中的有機污染程度。 模型預測結果具有較高的決定系數和較低的均方根誤差, 測試集的預測結果與實際測量值之間的相關系數達到0.90以上。 此外, 使用水質指標的預測結果對水體的水質等級進行判斷, 其中對黑臭水體判斷正確率達86%, 對Ⅲ類~重度黑臭水體的分類準確率達60%, 表明該技術的水質指標預測結果與現行的國標及行業標準方法分析結果一致性較高, 可以用于在廣域時空尺度中對流域水體的整體水質狀況進行全面判識, 是一種快速、 原位、 高效的城市及周邊地表水水質監測技術。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
環境(2023年5期)2023-06-30 01:20:01
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
當代水產(2019年1期)2019-05-16 02:42:04
當代水產(2019年3期)2019-05-14 05:42:48
電子制作(2018年14期)2018-08-21 01:38:16
光學精密工程(2016年6期)2016-11-07 09:07:19
水利規劃與設計(2016年7期)2016-02-28 15:06:27
核科學與工程(2015年4期)2015-09-26 11:59:03
