差分可辨性隱私參數的迭代分配方法*
2021-09-14 07:36:22任旭杰劉建偉
密碼學報 2021年4期
任旭杰, 尚 濤, 劉建偉
北京航空航天大學 網絡空間安全學院, 北京100083
1 引言
隨著大數據和云計算時代的到來, 各種數據挖掘算法得到了飛速發展. 例如聚類算法, 通過幾輪迭代將一個數據集劃分為多個簇, 同一簇中的數據相似性較高, 不同簇之間相似性較低, 以此實現對數據的無標簽分類, 可以對數據隱含未知信息進行挖掘, 對大數據的潛在價值有重要作用. 但在聚類為數據帶來應用前景的同時, 也出現了一些敏感信息的隱私泄露問題. 近些年, 對隱私保護的研究已成為學術界的熱門方向.
2006 年, Dwork[1]提出差分隱私的概念, 具有嚴格的數學理論基礎, 不依賴攻擊者的背景知識, 把對敏感數據的保護程度參數化為一個隱私預算值?; 2005 年, Blum 等人[2]在SuLQ 平臺上設計實現了一種差分隱私k-means 算法, 在計算聚類中心的過程中, 在求和函數和計數函數的查詢結果中加入少量噪聲來保證隱私, 但是該算法并未給出設置隱私預算?的方式. 2006 年, Aggarwal 等人[3]提出先對原始數據集進行聚類操作, 用簇中心替換所有記錄連同簇特征一起發布實現隱私保護的方法, 但這種處理方式使大多數數據遭到破壞, 降低了數據可用性. 2007 年, Nissim[4]提出PK-means 算法, 給出了如何計算誤差下界和函數敏感度的方法, 使最終聚類模型滿足差分隱私的要求. 2011 年, Dwork[5]分析了k-means 算法中敏感度的詳細計算方法, 并給出了隱私預算?的設置方式. 2013 年, 李楊等人[6]提出IDPk-means算法, 該算法經過一個對初始中心點的處理, 解決了經過差分隱私加噪后的初始中心點偏離過大導致聚類結果不可用的問題. 2016 年, 鄭劍等[7]提出了一種針對線性回歸的分析的差分隱私算法Diff-LR, 將線性回歸模型的目標函數分解, 并將隱私預算分配為兩部分對子函數進行擾動, 降低了算法的敏感度, 提升了模型精度. 2018 年, 楊庚等[8]提出一種面向差分隱私的隱私預算分配和數據發布方法, 利用泊松機制實現了差分隱私預算在數據發布中的應用, 可以達到隱私預算無窮分配的目的. 2019 年, 尚濤等[9]提出了一種等差隱私預算分配方法, 相比等比隱私預算分配, 該方法在保證了模型可用性的同時提升了精度, 但等差分配的方式不能實現隱私預算的任意分配, 只能應用于迭代次數固定或已知的模型訓練中.
2012 年, Lee 和Clifton[10]認為差分隱私不關注攻擊者背景知識, 只關注個體對數據庫輸出影響, 這不符合隱私相關的法律定義, 因此提出差分可辨性的概念, 它提供與差分隱私相當的隱私保護能力, 旨在限制個體被重新識別的概率, 隱私參數的設置也為從業者提供了一個簡單的參數化方法. 2014 年, 歐洋伶[11]提出新的隱私保護算法Margin-Jump, 為非交互型數據列聯表提供ρ-差分可辨性隱私保護. 通過隨機替換數據集的敏感屬性值, 以ρ-差分可辨性作為隱私保護模型. 目前, 對基于差分可辨性的聚類算法研究仍有較大空白.
2020 年, Shang 等人[12]研究了差分可辨性的指數機制應用于非數值型數據, 并通過數學證明得出差分可辨性的組合性質, 基于組合性質在聚類算法的迭代過程中添加噪聲, 在MapReduce 框架上進行聚類,最終得到滿足ρ-差分可辨性的聚類模型. 但是, 文獻[12] 的方法中添加噪聲的方式基于差分可辨性與差分隱私的映射關系, 即將差分隱私的隱私參數設置為ρ的函數, 并沿用了每輪隱私預算為上一輪一半的分配方式, 這并未很好地利用差分可辨性的性質, 本質上仍是差分隱私噪聲. 因此, 本文提出基于差分可辨性組合性質推出的隱私參數分配方法, 可以滿足隱私參數在迭代輪數固定情況下的平均分配和迭代輪數不固定時的任意分配, 并且最終得到的模型仍滿足ρ-差分可辨性的要求.
本文結構如下. 第2 節介紹了差分可辨性的相關定義及組合性質. 第3 節給出了差分可辨性參數分配方法在聚類中的應用. 第4 節是實驗分析, 驗證本文方法的可行性. 最后, 第5 節總結全文, 并討論未來可能的研究方向.
2 相關知識
Lee 和Clifon[10]認為,?-差分隱私的定義存在一定缺陷: 隱私預算?是評估安全性的指標, 它旨在限制鄰近數據集輸出結果的差異, 很難將其直接與個體可識別的概念聯系在一起. 它不符合人們對于隱私安全的理解和相關法律對隱私的定義. 因此, Lee 和Clifton 提出ρ-差分可辨性的概念,ρ-差分可辨性也可提供強大的隱私保證, 其隱私參數ρ限制的是重新識別某個個體屬于原始數據集的概率, 這與人們對隱私保護的法律意義相符.ρ-差分可辨性假設攻擊者擁有背景知識L=
定義1 (ρ-差分可辨性) 給定一個查詢函數f, 隨機機制M是滿足ρ-差分可辨性的, 當且僅當?D′=D ?vi, 且vi ∈U ?D′, 有
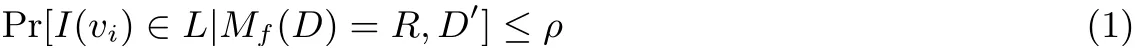

則Δf為查詢函數f的全局敏感度.
給定查詢函數f的敏感度, 可借助拉普拉斯機制實現ρ-差分可辨性.

文獻[12] 證明了差分可辨性和差分隱私具有類似的組合性質, 借助這些組合性質, 可以在聚類算法中實現差分可辨性.

推論2 (并行組合性) 假設有n個機制M1,M2,··· ,Mn, 機制Mi(i ∈[1,n]) 提供ρi-差分可辨性,Di是輸入數據集D中互不相交的子集, 機制序列Mi(Di) 提供(minρi)- 差分可辨性.

并行組合性說明了,如果有n個隨機機制M1,M2,··· ,Mn,他們均滿足差分可辨性,其中機制Mi(i ∈[1,n]) 提供ρi-差分可辨性. 對一個數據集D進行劃分后得到n個互不相交的子集D1,D2,··· ,Dn, 機制Mi對某一子集Di作用, 最終得到的模型序列(M1(D1),M2(D2),···Mn(Dn)) 滿足(minρi)- 差分可辨性.
3 差分可辨性隱私參數分配方法

3.1 迭代輪數不固定時的隱私參數分配

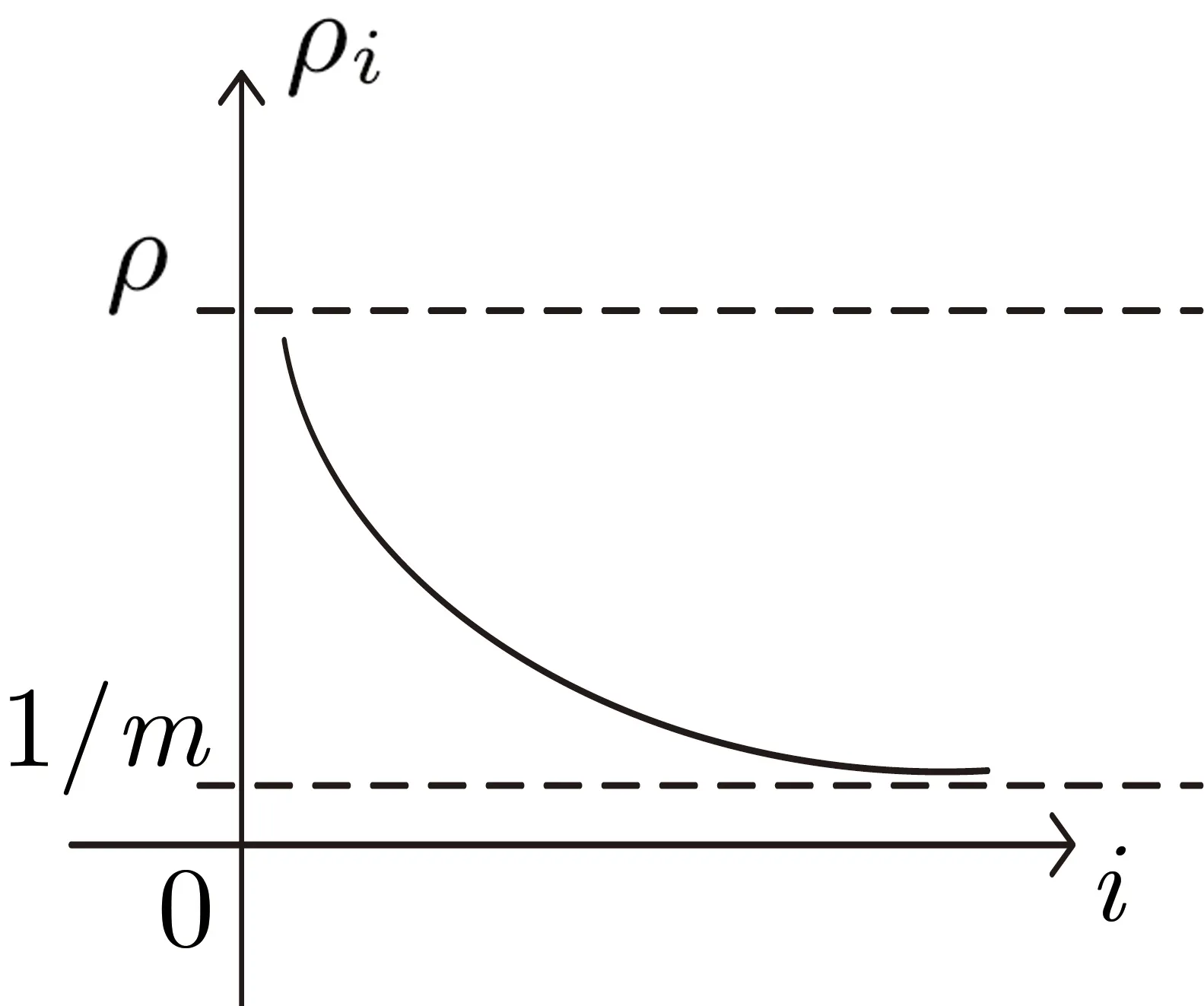
圖1 DI 參數變化趨勢Figure 1 Variation trend of parameter DI

指數部分收斂于1, 所以整個式子收斂于ρ.
該分配方法適用于任意輪數的迭代分配中, 隨著迭代輪數越多, 最終模型滿足的隱私保護能力越接近預設的ρ, 因此這是一種能夠實現隱私參數無窮分配的方法. 但是迭代輪數較少時, 可能會浪費較多的隱私參數預算.
3.2 迭代輪數固定時的隱私參數分配
對于迭代輪數固定的聚類算法, 假設迭代輪數為N, 是一個固定值; 希望模型滿足的隱私參數為ρ, 根據推論1 的序列組合性, 取每輪分配的隱私參數相等, 可得每輪迭代滿足的隱私參數為


3.3 差分可辨性k-means 算法
為驗證本方法的可行性, 本節給出結合差分可辨性的k-means 算法, 具體算法如下. 輸入:d維空間[0,1]d的n個數據點p1,p2,··· ,pn, 分類個數k, 差分可辨性隱私參數ρ, 迭代輪數閾值N(可選);
輸出:k個聚類中心點c1,c2,··· ,ck.

上述過程第5) 到7) 步循環執行, 直到簇的劃分不再變化, 或迭代次數達到某一閾值停止.
根據差分可辨性的序列組合性, 每輪迭代運算滿足差分可辨性, 那么迭代完成后的整體模型仍滿足差分可辨性. 對于加入隱私保護的聚類算法, 由于隱私參數ρ在迭代過程中的遞減, 添加的拉普拉斯噪聲會逐漸增大, 導致聚類中心點偏移較大, 從而使迭代進入死循環或使最終的聚類結果喪失可用性. 文獻[1] 中提出的差分隱私預算分配方法也有類似的特性. 解決辦法是對迭代輪數設置一個較小的閾值, 才能保證較好的可用性.
4 實驗分析
采用大數據集和小數據集兩組數據集進行聚類測試. 小數據集是來自KEEL 的banana 數據集, 通過兩種屬性將5300 組數據劃分為兩個類別, 用于生成可視化的聚類結果查看分類的性能. 大數據集實驗所用數據集來自UCI 機器學習庫中的magic gamma telescope, 共19 020 條數據, 11 個特征, 用于對第3 節中的隱私參數分配方法進行驗證實驗, 同時與表1 中提到的方法進行性能對比. 實驗環境為Windows 7 64 bit 操作系統, 開發語言為Python 3.7. 評價聚類性能好壞的指標為F-measure.F-measure 由常用于評價數據挖掘結果的指標準確率P(Precision) 和召回率R(Recall) 組成, 其計算值可用于評價聚類結果的效用. 準確率P和召回率R是主要參數,F-measure 大小與算法聚類結果和準確聚類結果的相似性成正比,F-measure 越大, 表明兩個聚類結果的相似性越高, 最大值為1.F-measure 可通過下列公式計算.
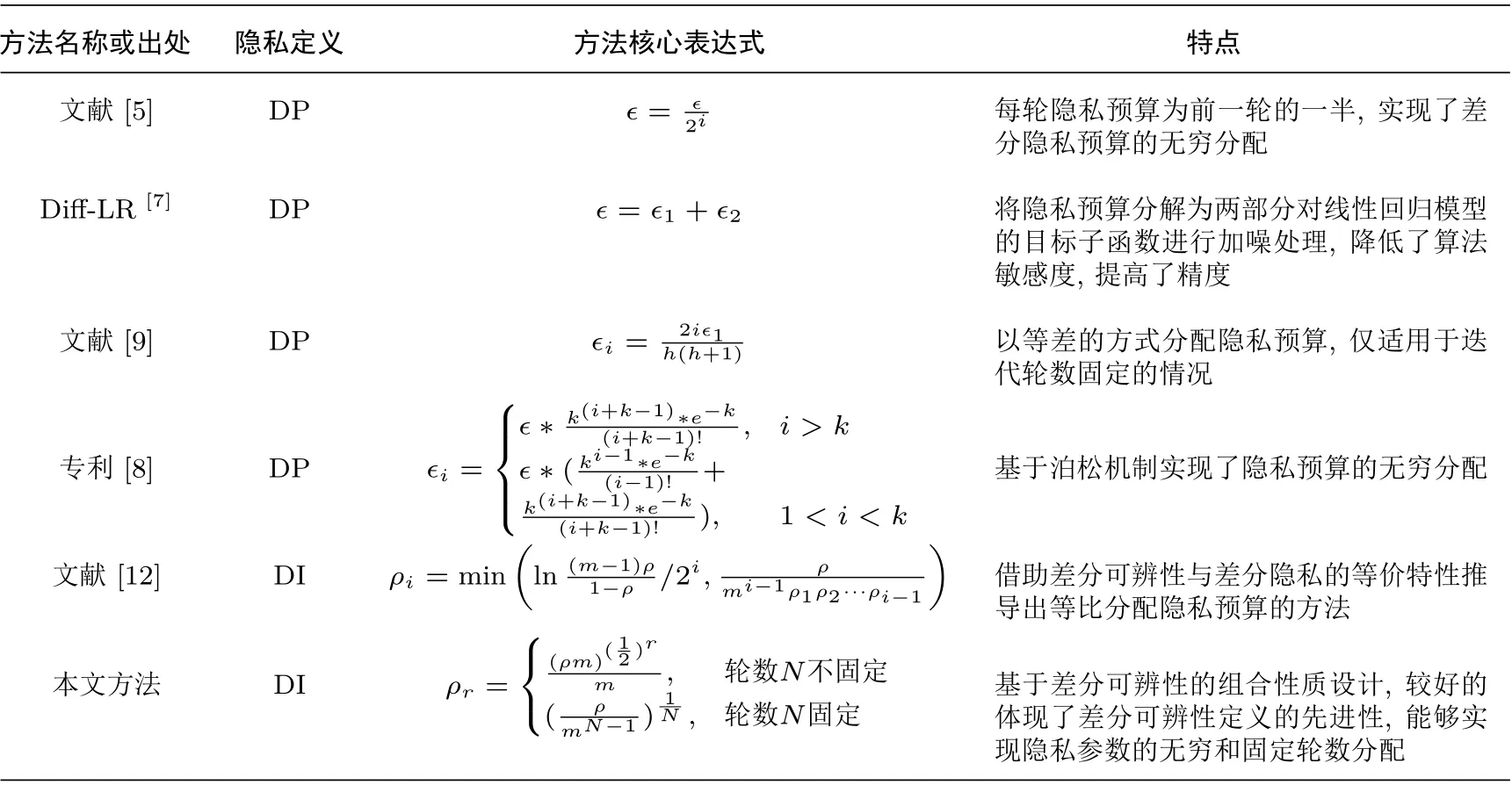
表1 不同隱私參數分配方法Table 1 Different privacy parameter allocation methods
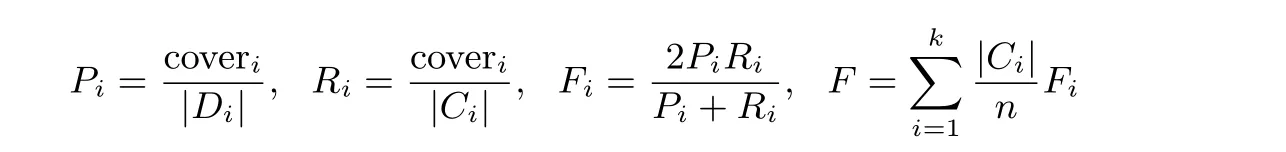
Pi和Ri(1≤k) 是第i個聚類的準確率和召回率, 聚類個數為k.Ci和Di分別表示數據集C和D的第i個聚類,|Ci| 和|Di| 為聚類Ci和Di中數據記錄數目, coveri是聚類Ci和Di中相同數據記錄數目, 計算各個聚類的F-measure 值Fi, 由各個聚類的Fi值加權平均得到指標F.
4.1 對小數據集的聚類實驗
4.1.1 未進行加噪處理的k-means 聚類
實驗設置k=2. 首先進行不加噪聲處理的k-means 聚類, 結果如圖2 所示.
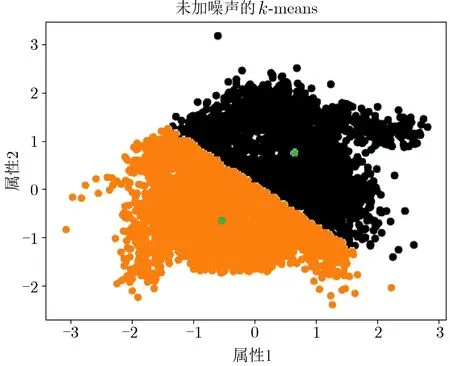
圖2 未經加噪處理的k-means 聚類結果Figure 2 k-means cluster without noise
通過兩種不同的顏色區分兩種不同類別(某種顏色并不代表特定的類, 僅作類的區分使用). 兩個聚類中標出的點為聚類迭代過程最終產生的類中心點. 實驗最終聚類模型的F-measure 值計算為48%.
4.1.2 差分隱私k-means 聚類實驗結果
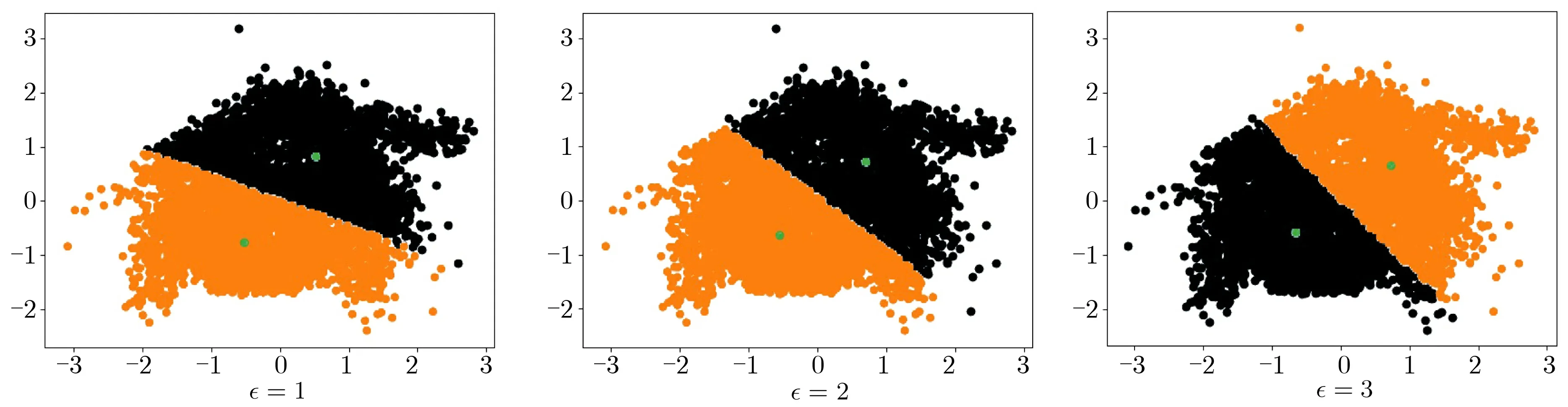
圖3 差分隱私k-means 聚類結果Figure 3 k-means cluster with noise DP
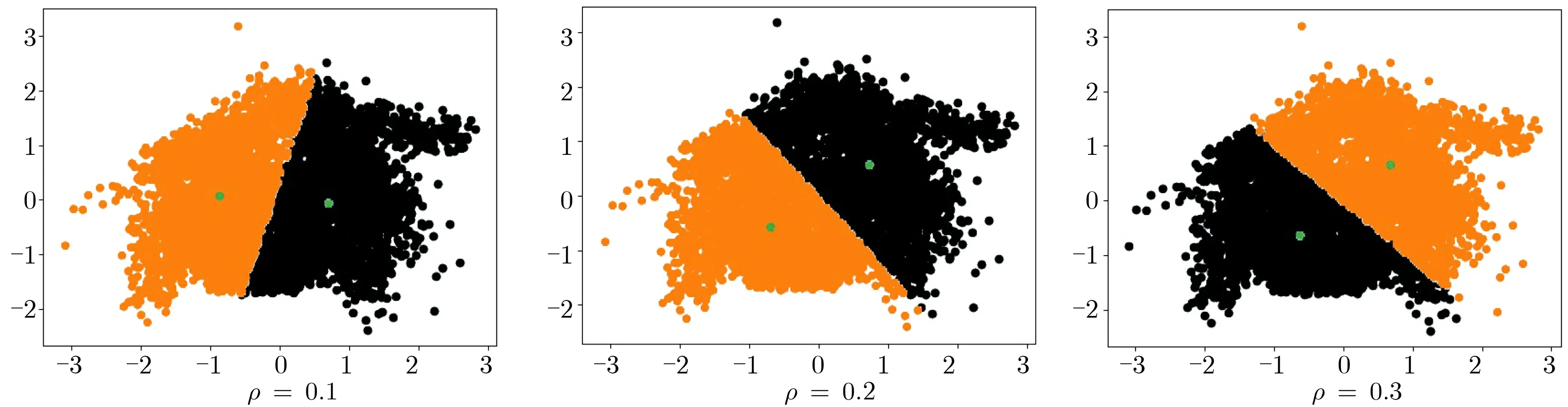
圖4 差分可辨性k-means 聚類結果Figure 4 k-means cluster with noise DI
根據第3 節中給出的隱私參數分配方法, 以ρ= 0.1 為例, 每輪隱私參數ρi= 0.003 16,0.000 56,0.000 24,0.000 15,0.000 12. 根據推論1, 最終模型滿足0.080 58-差分可辨性, 顯然也滿足0.1-差分可辨性,但因迭代輪數較少而產生了隱私參數預算的浪費.
實驗結果表明, 隱私參數ρ越小, 模型失真程度越高, 這與理論期待的情況吻合. 當設置合適的ρ值時, 聚類模型仍滿足一定的可用性.
4.2 對大數據集進行k-means 聚類實驗
數據集較小時, 對聚類過程中的參數進行處理可能無法很好體現出對聚類結果的影響, 因此本節對較大的數據集進行聚類測試. 使用表1 中列出的幾種隱私參數分配方法, 對數據集進行k-means 聚類, 設置k=11, 此后分別添加差分隱私噪聲和差分可辨性噪聲并計算F-measure. 實驗結果如圖5 和圖6 所示.
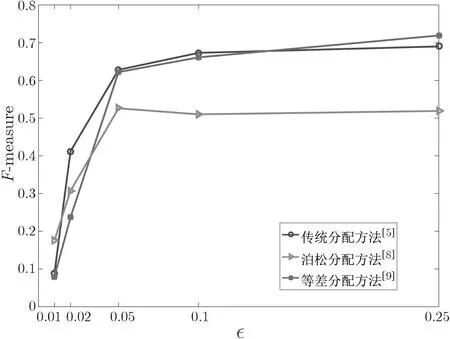
圖5 大數據集差分隱私k-means 聚類結果Figure 5 k-means cluster of big dataset with noise DP
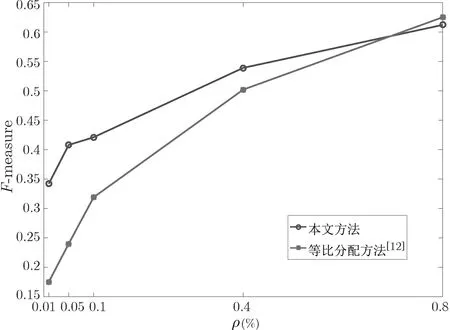
圖6 大數據集差分可辨性k-means 聚類結果Figure 6 k-means cluster of big dataset with noise DI
實驗結果顯示, 隨著隱私參數的增大, 差分隱私和差分可辨性方法表現出類似的性質,F-measure 值都出現了上升, 這與理論設想情況吻合. 差分可辨性方案分類表現最佳的對應F-measure 約為0.6, 略低于差分隱私方案的0.7, 一定程度上保持聚類的可用性.
如圖6 所示, 在與文獻[12] 的方法對比中, 使用本文方法進行的k-means 聚類性能明顯較高.
4.3 迭代輪數對模型性能的影響
由于隱私參數在迭代過程中的逐輪遞減, 迭代的同時添加的噪聲也將逐步增大. 因此若不對迭代輪數進行限制, 到迭代后期對模型添加的噪聲將非常大, 從而對聚類性能產生影響. 本小節將通過設置不同k-means 模型構建的迭代輪數, 觀察模型性能變化, 討論迭代輪數對模型性能的影響. 在本節實驗中, 設置差分可辨性隱私參數ρ=0.8, 實驗結果如圖7 所示.
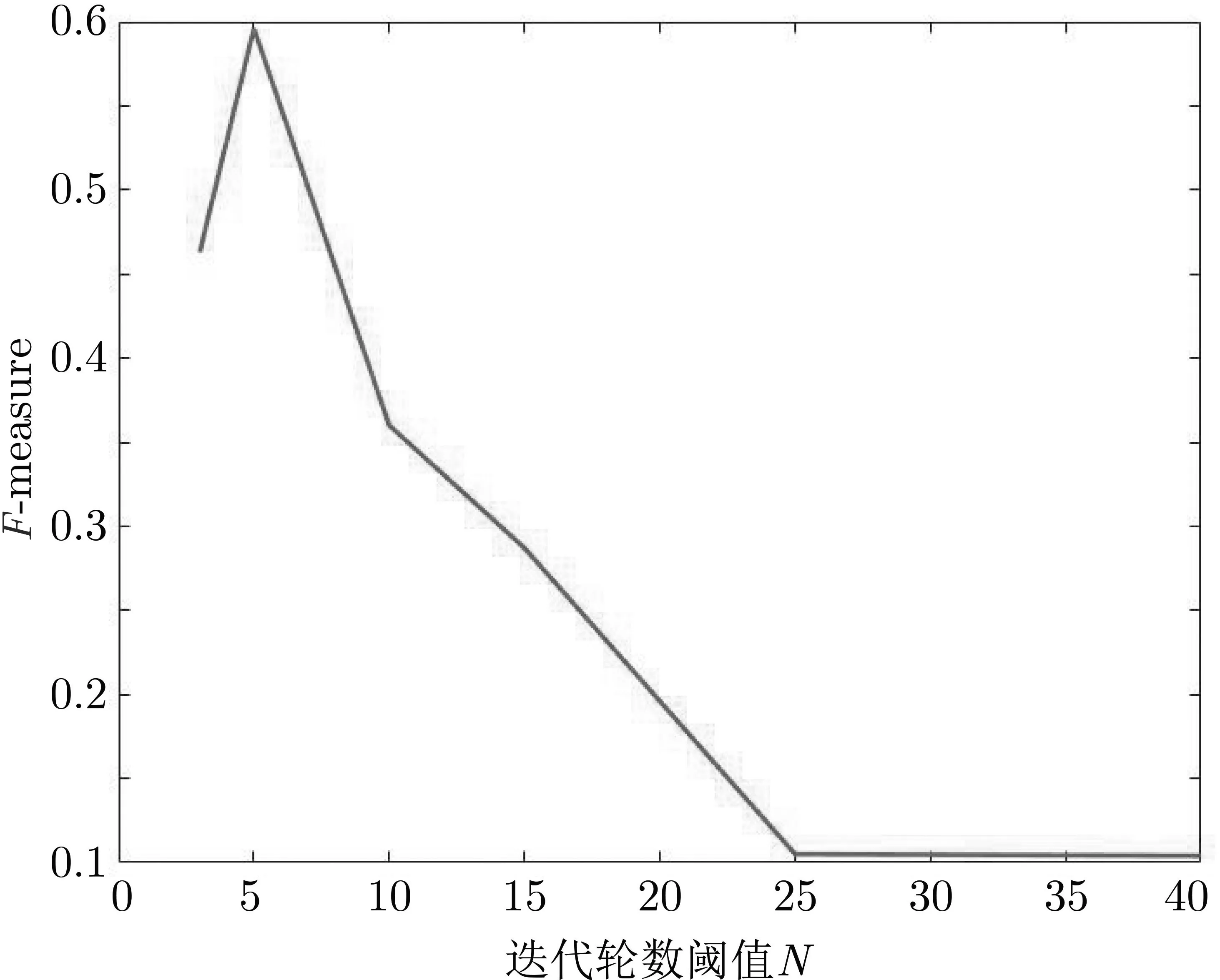
圖7 迭代閾值對模型性能的影響Figure 7 Effect of iteration round threshold on model performance
根據實驗結果, 當迭代輪數設置一個較小的閾值(5 輪左右) 時, 聚類性能可以得到保證,F-measure值在0.6 附近. 當迭代輪數增多到15 之后,F-measure 值下降到0.3 以下, 模型基本喪失可用性.
5 總結
本文針對傳統的大數據聚類迭代算法, 基于組合性質提出了一種差分可辨性隱私參數的迭代分配方法, 滿足了迭代輪數不固定情形下隱私參數的無窮分配, 也滿足了輪數固定時隱私參數的平均分配, 且最終迭代生成的模型滿足差分可辨性, 較好地體現了差分可辨性定義的先進性. 實驗結果表明, 差分可辨性隱私參數分配方法適用于k-means 聚類算法, 通過與差分隱私k-means 模型的對比, 可以看出本方法處理后的聚類模型也具有較好的分類效果.
差分可辨性能提供與差分隱私等價的隱私保護能力, 它在隱私保護應用上同樣有很大價值. 相較于已有長足發展的差分隱私保護理論, 差分可辨性的研究目前仍有較大的空白和廣泛的前景.
目前對隱私參數ρ,m的選取大多依靠人為分析或實驗來決定, 下一步仍需繼續研究具有科學性的方法, 針對不同維度、不同規模的數據集制定合理的隱私參數. 除了聚類中的迭代加噪, 針對數據發布和其他機器學習等數據挖掘方法均有借助差分可辨性參數化隱私保護的研究前景, 可以探索差分可辨性的更多應用.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
鐵道通信信號(2020年9期)2020-02-06 09:15:22
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
數學大王·趣味邏輯(2019年5期)2019-06-13 20:27:43
小學科學(學生版)(2019年5期)2019-05-21 01:00:18
經濟技術協作信息(2018年30期)2018-11-22 06:20:24
意林原創版(2016年10期)2016-11-25 10:28:30
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
