基于時間特征的可疑資金交易識別研究
2021-09-09 07:36:28丁曉
現代計算機 2021年19期
關鍵詞:資金
丁曉
(中南財經政法大學信息與安全工程學院,武漢 430073)
0 引言
隨著經濟發展,洗錢犯罪活動也呈現擴大趨勢,如果不進行打擊,將會對國家和社會造成嚴重危害。金融機構、特定非金融機構及相關監管部門都有發現、打擊這類行為的迫切需求。但是相關數據具有體量大的特征,手工方法已經無法甄別,需要用計算機技術進行分析。
洗錢活動中,部分犯罪分子的資金轉移手法有一定規律性。交易時間作為資金交易數據中的一個基本特征,能反映該涉案人員的交易習慣、交易周期等。本文研究以資金交易的時間特征為研究對象,以聚類分析為輔助手段,進行可疑資金交易模式識別研究,并以“靶心模式”這種行為模式的識別為例,設計了詳細識別算法。這個算法是無監督學習算法,不需要先驗數據,簡化了算法的應用。這個算法也是辦案人員經驗、知識的固化,保證了算法的正確性,而且算法在實際案件偵查中取得了好的成績。
1 相關研究
在反洗錢領域,分析算法大體可以分為五大類:
(1)洗錢類型分析,是基于已經發現的案例進行檢測。Bhattacharyya等人使用支持向量機進行信用卡欺詐檢測[1];Luo X使用頻繁項模式算法檢測賬戶之間的可疑交易[2];Paula E等使用了深度學習方法[3]。
(2)鏈接關系分析,找出賬戶間的實質關系。Dreewski等人使用社交網絡分析法進行賬號間關系分析,每個賬戶作為圖的一個頂點,具備介數中心度、接近中心度、權威度等屬性,還借助社交網絡技術,試圖分析各個賬戶在洗錢犯罪中的角色[4];Colladon AF等人試圖從網絡中發現可疑交易[5]。Jin Y等人使用分層模型根據資金流動的方向對賬戶進行分層,簡化大規模網絡,還利用熵權法對各賬戶主體進行評價,分析各主體在洗錢網絡中的重要性[6]。
(3)行為模型。Demetis DS使用EM聚類算法,進行聚類,根據客戶的歷史數據建立概率密度函數,再據此判斷新數據是否可疑,但是它假設的用戶交易數據滿足高斯分布不一定成立[7]。
(4)風險評估。Larik和Haider改進了歐式自適應諧振理論,消除了基于距離聚類和基于密度聚類的弱點,計算出平衡集群,將正常行為模式和稍微偏離正常行為模式的數據劃分到同一個集群,且能通過AICAF索引將兩者區分開,當客戶數據差異較大時效果較好[8];Vikas J等人使用了基于位圖索引的決策樹算法評估風險因數,特別之處在于構造決策樹的方法,效率很高[9]。
(5)異常檢測。異常檢測是識別、發現每個賬戶不同尋常的交易。Raza等將貝葉斯網絡和聚類技術結合,先使用模糊C-means聚類算法對客戶交易數據進行劃分,接著在每個聚類上構造動態貝葉斯網絡,使用后驗概率分布進行預測[10];Andrew Elliott等人將交易數據構造為有向帶權圖,綜合使用了網絡比較分析、社區劃分、頻譜分析和統計方法,提取出140多個特征,接著將這些特征聚合,最后采用隨機森林進行正常、異常的劃分[11]。
和上述工作都不同,本文研究是對辦案人員經驗、知識總結、提煉后,以算法形式實現對人類知識的固定。
2 基于時間特征的可疑資金交易識別算法
2.1 可疑資金交易行為模式分析
通常來說,洗錢過程可以分為處置階段、培植階段、融合階段[12]。處置階段將非法取得的資金投入洗錢系統;培植階段通過多種、多賬戶、多層的金融交易來將非法取得的資金與其來源分離開來;融合階段將“合法化”后的資金集中起來使用。通過這三個階段來達到掩蓋資金的非法來源和真實所有權的洗錢目的。洗錢案件一般涉及的金額較大,涉案人員為了規避相關部門的自動審查,往往會采取拆分的方式對資金進行多次轉移,但交易數額均在報告閾值之內。即便如此,這些行為也會呈現出一定的行為特征。
洗錢活動中資金交易行為模式有很多,本文以一種“靶心模式”為例展開研究。賬戶所有人若在短時間內有一筆大額資金轉入,隨后又以多筆小額資金的形式進行轉出,這種“一進多出”的交易行為模式,本文將其稱作“靶心模式”。除此之外,資金轉入、轉出的時間間隔不長,具有快進快出的特點;作為中轉賬戶,操作人有收取手續費的行為,轉出總金額和轉入總金額的比例在一定范圍之內;這種轉賬工具賬戶具有突發性,每次資金轉移行為的前后時間段,往往沒有其他資金進出行為。在資金融合階段,存在類似的但是方向相反的行為模式。
本文以“靶心模式”為例進行探究,提出了一種基于時間特征的可疑資金交易識別算法,目的是識別出呈現“靶心模式”的可疑資金交易。
2.2 基本概念
定義1,交易資金序列。對于序列集X={(d,m,t)│d∈D,m∈R,t∈T},D={′轉入′,轉出′},R為實數集合,T為離散的交易時間集合,則稱序列集X為某賬戶的交易資金序列。令c=|X|,設p∈X,q∈X,若p≠q,則p(t)≠q(t)。
定義2,轉入交易資金序列。交易資金序列I,I?X,I={(d,m,t)│d=′ 轉入′,m∈R,t∈T},則稱交易資金序列為某賬戶的轉入交易資金序列。令m=|I|。
定義3,轉出交易資金序列。交易資金序列O,O?X,O={(d,m,t)│d=′ 轉出′,m∈R,t∈T},則稱交易資金序列為某賬戶的轉出交易資金序列。令n=|O|。
2.3 算法框架
“靶心模式”的突發性行為特點,導致了可以采用時間聚類的方法對交易資金序列進行自動劃分,然后再結合其他交易特征進行可疑交易的提取和識別。
如果突發性不明顯,可能會使得多次資金轉移數據混合在一起,導致行為特征不明顯,進而降低算法的準確性。
考慮到在“靶心模式”下,每次資金轉移行為的轉入和轉出存在時間上的先后關系,故不對整個交易資金序列進行時間聚類,而是分別對轉入交易資金序列和轉出交易資金序列進行聚類,這樣有利于降低突發性不明顯帶來的問題;然后根據時間特征,把每個轉出聚類簇和轉入聚類簇進行對應,匯集成一次資金轉移行為的交易簇;再針對交易簇數據進行“靶心模式”行為特征匹配,判斷該次資金轉移行為是否為可疑交易。
“靶心模式”的可疑交易資金的識別算法框架如圖1所示。
(1)對數據進行預處理,轉換為交易資金序列;
(2)將交易資金序列按照資金流動方向劃分為轉入交易資金序列和轉出交易資金序列;
(3)分別對轉入交易資金序列和轉出交易資金序列進行時間聚類,在適當排除噪聲、調整聚類方法的參數后,保證兩次聚類得到的簇數目一致;
(4)對每一個轉入交易資金序列的聚類簇Ca,在轉出交易資金序列的聚類簇中尋找一個聚類簇Cb,使得Cb簇中心的交易時間大于Ca簇中心的交易時間,且差值在預設區間內;將Ca、Cb合并為交易簇Ct;
(5)計算每個交易簇中轉出總金額和轉入總金額的比值,如果不在預設區間,則為不平衡賬戶,不符合“靶心模式”行為特征;
(6)計算每個交易簇中轉出總筆數與轉入總筆數的比值;如果不在預設區間,則視為不符合“靶心模式”行為特征;
(7)通過(5)和(6)檢測的交易簇數據,就是具備“靶心模式”行為特征的可疑交易數據。
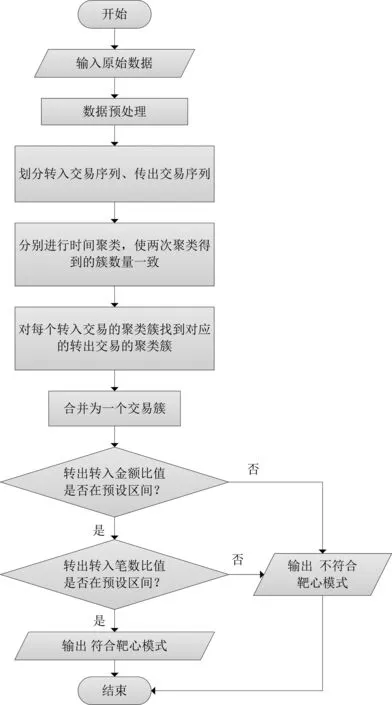
圖1 算法流程圖
2.4 聚類算法的選取
聚類方法可以按照算法思想分為四類:基于劃分、基于密度、基于層次、基于網格。常見的聚類算法有:K均值算法(K-means),基于密度的聚類算法(DBSCAN)、凝聚層次聚類,它們分別對應于基于劃分、基于密度、基于層級的聚類算法。
不同的聚類算法在不同的數據集上的表現存在差異,依據數據集的特點選擇合適的聚類算法是十分必要的。K-means作為聚類算法中使用最為廣泛的算法,其優點是理解簡單、容易實現、時間復雜度低,缺點是對噪聲和離群值敏感、不適用于結果是非凸形分布的數據、需要給定聚類簇數。DBSCAN的優點是無須預先給定聚類的簇數、可以識別任意形狀的數據、可以識別噪聲,缺點是不適用于密度不均勻的數據。層級聚類的優點是無須預先給定聚類的簇數,可以發現類的層次關系,缺點是計算復雜度高,容易聚成鏈狀。
在本文研究的“靶心模式”行為特征的交易資金序列,不存在層次關系;轉入交易資金序列的特點是交易筆數少,單筆交易金額大,交易時間分散;轉出交易資金序列的特點是交易筆數多,單筆交易金額相對轉入一般不大,交易時間密集且不一定均勻。考慮到轉入交易資金序列中的交易筆數少,即樣本點不多,噪聲對聚類的影響較大,故使用DBSCAN對轉入交易資金序列進行時間聚類。由于轉出交易資金序列中交易筆數多,即樣本點多,噪聲對整體聚類影響不明顯,且存在交易時間分布密度不均勻的情況,故使用K-means對轉出交易資金序列進行時間聚類。
2.5 算法設計
在識別具備“靶心模式”行為特征的可疑資金交易時,設X為某涉案賬戶A的交易資金序列,設集合中元素數量為c,故有X={x1,x2,…,xc-1,xc}。
(1)按照資金流動方向,交易資金序列X劃分為轉入交易資金序列I和轉出交易資金序列O,它們各自的交易筆數分別為m和n。則有轉入集合I={i1,i2,…,im-1,im},轉出集合O={o1,o2,…,on-1,on},c=m+n。
(2)抽取轉入交易資金序列I和轉出交易資金序列O的時間集合,轉入時間集合表示為TI={t1,t2,…,tm},轉出時間集合可以表示為TO={t1,t2,…,tn}。
(3)使用K-means算法對轉出時間集合TO進行聚類,k從2開始,多輪聚類,取使輪廓系數最大的k值為最終簇數量。
(4)使用DBSCAN算法對轉入時間集合TI進行聚類,調整DBSCAN算法中的的參數,包括鄰域距離eps和鄰域最小樣本個數MinPts,排除噪聲點后保證聚類得到的簇數量與上一步驟中的k值相同。如果無法得到k個簇,算法終止。
(5)將轉入時間集合的聚類結果按照聚類中心升序排序后,定義每個轉入時間簇為TI1,TI2,…,TIk,TI=TI1∪…∪TIk;同樣,將每個轉出時間簇定義為TO1,TO2,…,TOk,TO=TO1∪…∪TOk。
(6)對轉入時間簇TIi,找到晚于且最接近于其聚類中心的轉出時間簇TOj,且兩個聚類中心的時間差小于閾值γ;TIi∪TOj構成一個交易時間簇。在交易資金序列X中按照交易時間查找對應元素,形成對映的交易簇。
(7)給定閾值δ,計算每個交易簇中轉入總金額MI、轉出總金額MO,若MO/MI>δ,則認為該交易簇的交易行為不符合扣手續費的特征,不符合“靶心模式”。
(8)給定閾值σ,計算每個交易簇中轉入總筆數FI、轉出總筆數FO,若FO/FI>σ時,則認為該交易簇的交易行為模式符合“靶心模式”,該交易簇中全部交易為“靶心模式”下的可疑資金交易。
在交易資金序列的定義中,已經約束了某賬戶的每筆交易具有時間唯一性,保證了在步驟(6)中,能夠正確地從交易資金序列X中按照時間找到對應元素。
3 實驗設計及結果
3.1 數據準備
根據某可疑賬戶的數據,設計了具有相同行為特點的模擬數據。模擬數據的時間跨度從2017年4月到2017年12月,包含2358條交易數據,有129條轉入交易數據,2229條轉出交易數據,轉入資金總計約4470萬元,轉出資金總計約3870萬元。每個數據項包含交易時間、金額、交易方向和交易對手ID四項內容,其中交易時間為時間戳格式。
接著清洗數據。刪除小額交易數據,這往往是正常的消費數據;刪除交易對手是自己的數據,這是自己對倒行為,不是本文要分析的內容,排除后可以減少干擾。每個數據項保留交易時間、金額和交易方向三項內容,按照交易方向,將數據劃分為轉出交易資金序列和轉入交易資金序列。最終得到2316條數據。
將清洗后的交易數據進行按月時間-頻次可視化后,發現交易頻次比較高的集中在2017年5月和2017年7月兩個月份,2017年5月有數據260條,轉入4條,轉入金額238萬元,轉出256條,轉出金額295萬元,2017年7月有數據258條,轉入8條,轉入金額489萬元,轉出250條,轉出金額458萬元;其余月份頻次低,轉入、轉出間隔較遠,明顯不符合“靶心模式”的行為特征,所以選取2017年5月與2017年7月兩個月的交易數據進行分析。
3.2 實驗過程及分析
使用Python3,調用sklearn.cluster中的K-means方法對轉出交易資金序列的時間進行聚類,不斷調整參數,繪制輪廓系數隨k值變化的曲線,選取效果最佳的k值;調用sklearn.cluster中的DBSCAN方法對轉入交易資金序列的時間進行聚類,依據確定的k值,對DBSCAN進行調參。統計聚類結果中每個交易簇的各項指標,觀察指標是否符合閾值規定的區間。按照簇中心時間相近、方向對應原則,合并得到多個交易簇。對每一個交易簇進行“靶心模式”識別。
對2017年5月的轉出交易資金序列,根據交易時間,k的取值從1到50變化,依次進行K-means聚類;根據每次聚類得到的輪廓系數,畫出變化曲線,如圖2所示。當k=3時輪廓系數最大,為0.995,所以最終確定簇數量k為3。
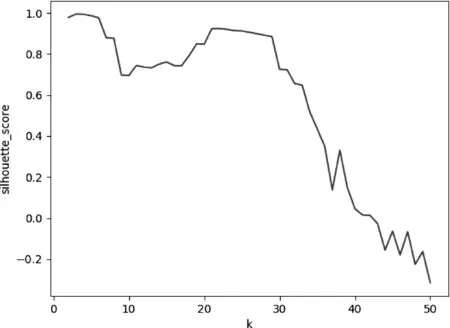
圖2 輪廓系數隨k值變化曲線
對轉入交易資金序列,根據交易時間使用DBSCAN進行聚類。計算[元素個數/k]=1,所以令參數MinPts=1;對交易時間排序后計算差分,得到差分序列,以各差分值為鄰域距離參數eps,逐次聚類,取聚類數量為3時的結果為最終結果。
根據聚類結果,將轉入交易資金序列劃分為3個子序列,每個子序列根據交易時間分別畫出箱線圖,如圖3(a)所示,橫坐標代表各聚類中心點的時間順序,縱坐標為交易時間。同樣根據聚類結果,將轉出交易資金序列劃分為3個子序列,每個子序列根據交易時間分別畫出箱線圖,如圖3(b)所示,橫坐標代表各聚類中心點的時間順序,縱坐標為交易時間。
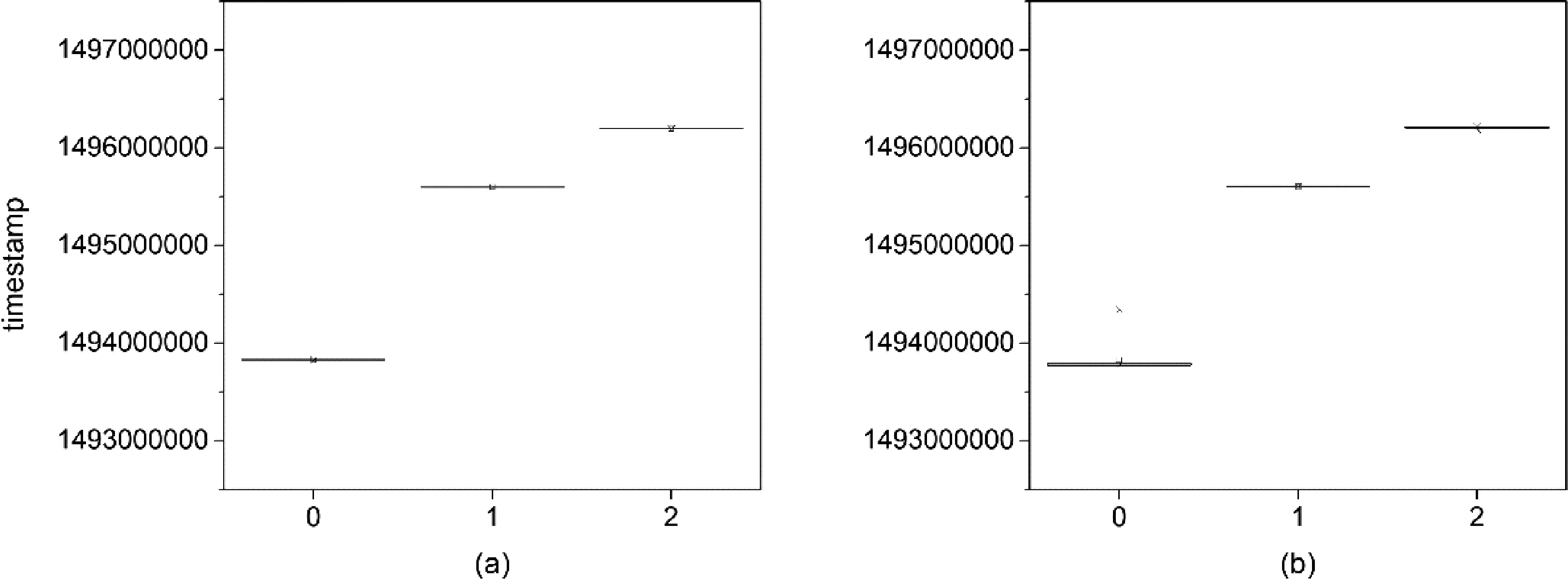
圖3 2017年5月交易數據分簇箱線圖
箱線圖可以反映出每個簇中交易時間的分布情況,具體體現在極大值、極小值、中位數和兩個四分位數上。當以上幾個值相當接近或完全重合時,箱型圖的形狀趨近于一條直線。可以看出,2017年5月發生的交易在基于時間特征進行聚類后,每個簇的交易時間十分緊密,每個箱型圖的形狀趨近于一條直線,且與其他的簇分布位置相隔一段距離,這也反映出聚類的輪廓系數很高。還可以看出,對轉入時間集合和轉出時間集合聚類后得到的簇分布位置非常一致。
同樣的方法,在對2017年7月交易資金序列進行計算后,轉出資金序列數據聚類數為2,轉入資金序列在聚類時候存在噪聲,所以多了一個噪聲簇。刪除噪聲簇后所畫箱線圖如圖4所示。
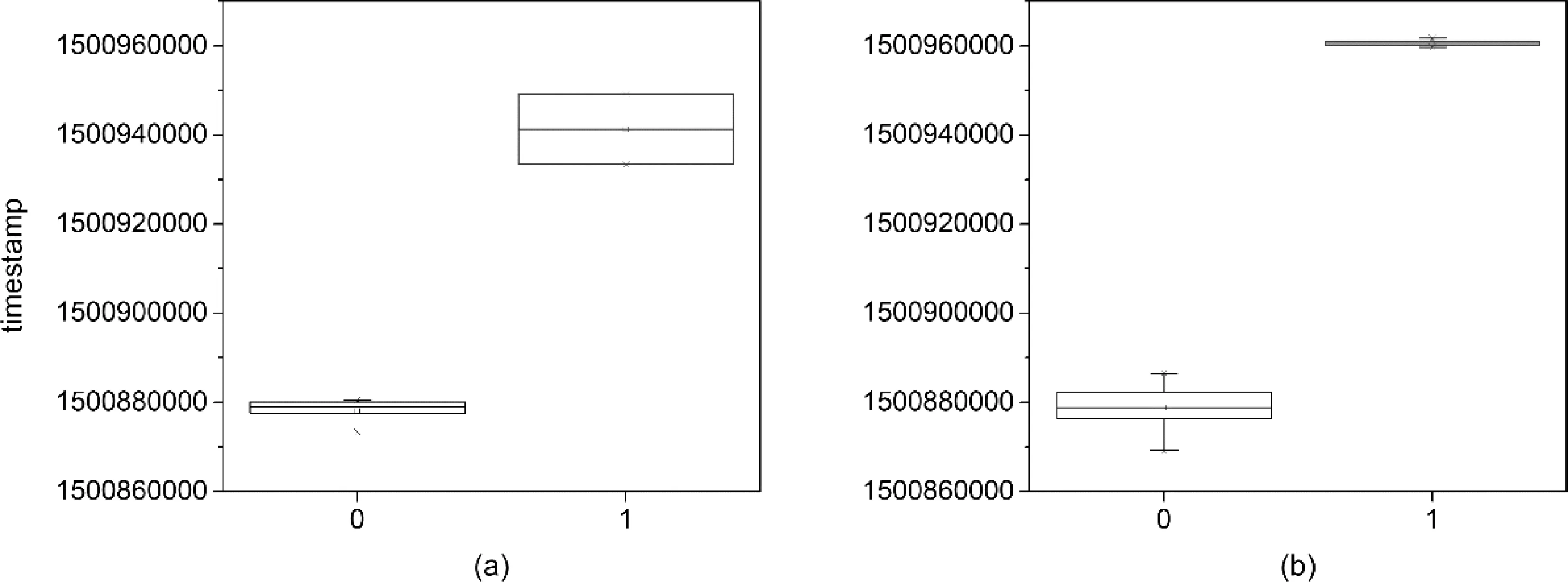
圖4 2017年7月交易交易數據分簇箱線圖
根據辦案干警經驗,取δ=1.05,σ=100,即“靶心模式”模式要求轉出總金額與轉入總金額相差在百分之五以內,每筆轉入要對應100筆以上的轉出。兩個月的交易數據,分別按聚類簇計算,結果如表1和表2所示。

表1 5月數據實驗結果

表2 7月數據實驗結果
表1中,0號交易簇,兩個比值都不在閾值之內,2號交易簇,雖然轉出總金額與轉入總金額基本平衡,但轉出交易筆數不符合“靶心模式”的特點,只有1號交易簇滿足設定的閾值,可以判定為“靶心模式”的可疑資金交易。
表2中,0號交易簇雖然轉入轉出總金額基本平衡,但是轉入轉出筆數不滿足“靶心模式”的特點。1號交易簇滿足設定的閾值,可以判定為“靶心模式”的可疑資金交易。
4 結語
本文算法實現了對可疑交易資金的識別,但是這些交易行為是否就一定是違法行為,單純從交易資金數據上是無法給出準確結論的。本文研究定位于先找出可疑的資金數據,進而提供偵查方向。本文算法已經在經濟犯罪案件偵查中得到應用,算法能夠在海量資金數據中找到可疑的賬戶和人員,為案件偵查提供了方向,辦案部門據此展開進一步偵查,已經偵破了多起案件。
猜你喜歡
股市動態分析(2020年21期)2020-11-06 07:24:07
股市動態分析(2020年20期)2020-10-26 02:22:07
股市動態分析(2020年19期)2020-09-26 09:35:37
股市動態分析(2020年18期)2020-09-12 14:30:15
股市動態分析(2020年17期)2020-09-02 07:16:26
股市動態分析(2020年16期)2020-08-17 07:24:32
股市動態分析(2020年15期)2020-08-12 09:09:31
股市動態分析(2020年14期)2020-08-12 09:09:12
股市動態分析(2020年13期)2020-08-12 05:25:53
股市動態分析(2020年12期)2020-08-12 05:25:33
