Arrow在分布式查詢引擎中的應用與研究
2021-09-09 07:36:24張世同
現代計算機 2021年19期
關鍵詞:引擎
張世同
(北京云至科技有限公司南京分公司,數據服務產品研發部,南京 211801)
0 引言
近年來,大數據技術領域列式存儲成為主流,現代CPU技術借助流水線技術、SIMD(Single Instruction Multiple Data)指令、向量計算,大幅提升處理性能。內存越來越廉價,借助內存提升性能成為可能。數據來源復雜,數據格式多樣化,出現了復雜、嵌套數據格式。用戶對數據處理效率的要求日益迫切。
以Presto、Drill、Impala、Kylin為代表的查詢引擎采用MPP技術,使用SQL的方式,對底層異構的大數據存儲進行訪問。未來查詢引擎向數據發現、數據治理、自助服務的方向發展,即讓業務人員在無IT人員的參與下,可以順利工作,從繁雜的原始數據中,發現數據、聚合數據、形成高質量的數據、發布數據服務。這時,查詢引擎的查詢、更新性能就變得尤為重要。
本文介紹了一種基于MPP和Arrow內存列存儲的數據查詢引擎ADE(Agile Data Engine)的設計和實現,ADE有效提升了查詢引擎本身的性能和跨系統數據通訊效率,再結合預計算和SQL重寫技術能夠滿足OLAP場景下常規查詢和即席查詢(1)常規查詢在系統設計時是已知的,可以事先通過建立索引、分區等技術來優化。而即席(ad-hoc)查詢是用戶在使用時臨時產生的,系統無法預先優化這些查詢,所以即席查詢也是一個重要指標的需求。
1 研究現狀
1.1 分布式查詢引擎的現狀
分布式查詢引擎的興起,起源于Google的Dremel,隨后Cloudera開源了大數據查詢分析引擎Impala,Facebook開源了Presto,Hortonworks開源了Stringer,Apache基于Hadoop原生SQL的HAWQ[9],國內的Kylin、Druid等。Apache基金會的頂級項目Drill是業界比較接受的Dremel的開源實現。文獻[5]將這些分布式查詢引擎分為基于預計算思想的計算引擎和實時計算引擎兩類。
基于預計算思想的計算引擎,通過提前的聚合存儲操作,通過SQL重寫技術把一個計算任務轉換成查詢操作,本質上減少計算量,如Kylin[15]。該類查詢引擎的缺點:①立方體的構建具有維度爆炸問題,無論對計算能力還是存儲能力都提出了挑戰。②由于數據查詢分析分布具有聚集性,所以,立方體中的大量club從來沒有使用過,浪費了計算資源和存儲資源。所以對該類查詢引擎的研究,主要是立方體物化策略的研究[5]。
實時計算引擎,每次查詢都需要對數據進行聚合計算,所以實時性并不是很高不能達到實時的標準[5]。對該類引擎的研究,主要集中在優化執行計劃和存儲,如位圖索引、列式存儲[1,3]、查詢計劃優化[2,6]等。查詢計劃優化研究,目前有基于規則、成本、運行時的查詢計劃優化以及基于算法的查詢優化等。
1.2 內存列式存儲的現狀
目前內存數據庫已經成熟,常見的內存數據庫有SAP-HANA[18]、Ignite、Geode等。SAP-HANA支持行存儲和列存儲,而Ignite和Geode都是以Key-Value格式存儲。它們在分布式內存網絡方面,都已經有了成熟的實現和應用。
在大數據MPP計算領域,列存儲也已經普遍,如文件列存儲格式Parquet、Avro等;內存列存儲格式如SAP-HANA、Spark、Drill等都在應用。但是目前內存列存儲格式還由各軟件自行定義和進行內存管理,沒有統一的格式標準和讀寫接口,這就意味著跨系統數據傳輸時,避免不了數據序列化反序列化操作。
紐約大學的Pilaf[16]和微軟研究院的FaRM[17]采用RDMA(Remote Direct Memory Access)技術,實現內部節點之間的數據通訊和整個分布式系統對外共享內存讀寫接口,較少序列化反序列化,極大提高效率。
Arrow內存列存儲就是為了解決當前內存列存儲無標準的問題,它為內存列存儲格式和數據讀寫接口提供了標準,并已經實現了C++、Go、Java、Python、R、Ruby和Rust等多種編程語言,可以有效提升查詢引擎的效率又可以實現跨系統數據傳輸,而無需進行數據序列化反序列化。
2 Arrow技術基礎
Arrow是跨語言、跨平臺的內存列式存儲格式。具備傳統列式存儲的優勢,同時具有內存數據快速訪問、復雜格式、內存網格化的優勢。Arrow具備以下特征:①充分利用現代高性能CPU的SIMD指令,支持向量計算。②利用內存緩存區, 線性緊湊定義數據結構,提高Cache命中率和CPU讀取數據效率。③統一內存格式,避免或減少異構系統之間序列化反序列化。④利用共享內存或者直接內存訪問,實現zero-copy。⑤支持復雜數據Schema和動態Schema。⑥易于采用內存網格化技術,實現分布式內存計算,大幅提高性能。
2.1 Arrow內存布局
Arrow內存結構支持基本類型(固定長度)、可變長度二進制、固定長度List、可變長度List、結構體類型、稀疏聯合類型、Null類型、字典類型等。這些指的是物理存儲類型,所有邏輯數據類型,均使用這些物理存儲類型設計。邏輯類型為整型、長整型、日期類型、字符串類型等。

圖1 Int32的向量內存布局
Int32向量的內存布局如圖1所示,元數據記錄向量長度、空值個數,理論最多可以存儲231-1元素。Bitmap位圖,記錄非空值索引,例如示例中有效bitmap為1字節,字節長度對齊為64字節(2)64字節對齊,取決于IntelCPU AVX-512指令集特點,對512位64字節提供更高的性能。。
is_valid[j]->bitmap[j/8]&(1<<(j%8))
(1)
判斷位置j是否為有效值is_valid為公式(1):內存緩沖區是一段連續的內存區,按照64字節長度對齊。對于空值,不分配字節值。

圖2 字符串向量內存布局
字符串類型的向量內存布局使用可變長度List
slot_position=offsets[j]
(2)
slot_length=offsets[j+1]-offsets[j]
(3)
有些屬性列是關聯字典,重復存儲造成空間浪費、影響檢索性能。可以設計成字典類型、通過Int32索引引用字典值。
2.2 Arrow內存模型
Arrow 基于NettyJEMalloc實現了內存分配器Allocator,它基于數據塊分配器內存。整個內存結構呈樹型結構,如圖3所示。
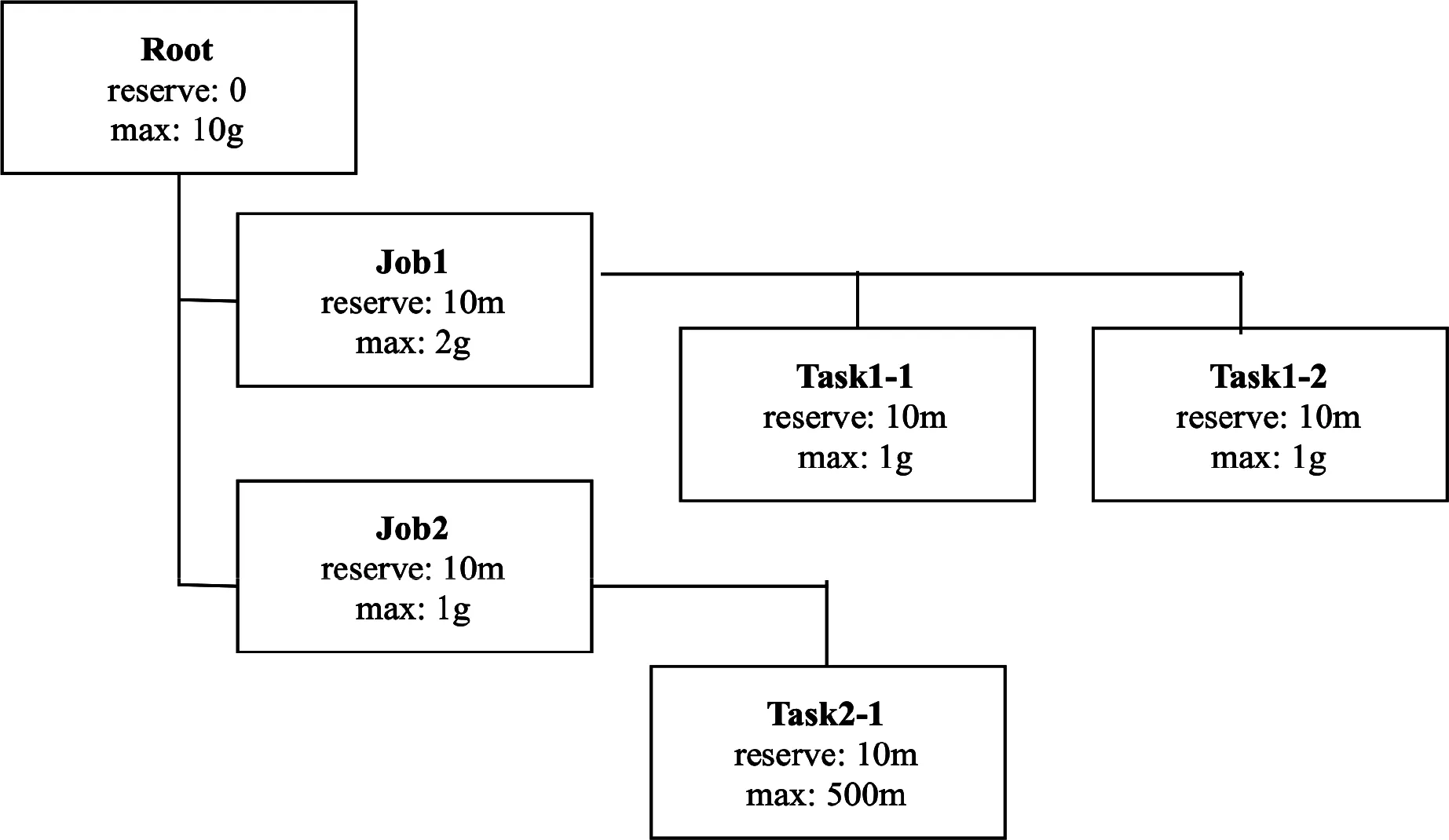
圖3 內存分配器(Allocator)的樹型結構
樹型結構的內存分配器(Allocators),有利于分功能分配、管理、檢測、回收部分內存區。每個內存分配器有預留容量(可用于計算)和最大容量。預留容量不會被數據占用,這意味著整個生命周期中都是被計算分配的。Arrow向量數組使用Off-heap堆外內存。手工管理和釋放內存區,不依賴于GC。內存負載管理,檢測內存溢出風險、檢測內存分配器的使用情況,決定是否寫入部分數據到磁盤。每個查詢計劃Operator都創建了一個Allocator,它還可以創建自己的子Allocator,用于對該Operator內的每個數據分片進行處理。
2.3 Arrow數據傳輸格式
Arrow 以Batch的方式,封裝數據及其模式進而進行數據傳輸。即用Batch的方式把一定數量的數據記錄(包括所有屬性列)及其Schema封裝在Record Batch中。有Dictionary Batch和Record Batch兩種形式。數據傳輸的Message邏輯結構如圖4。

圖4 數據傳輸Message邏輯結構
數據模式(Schema)定義了數據的邏輯結構,屬性邏輯類型,指定了屬性的字典類型編碼。字典類型Batch,把字典屬性進行編碼存儲,記錄中僅存儲字典編碼。記錄類型Batch分屬性向量存儲實際數據。
以記錄類型Batch為例,其數據分為:數據頭、各屬性的bitmap區、offsets區、數據區。其中數據頭記錄該batch的類型(Dictionary batch、Record batch、Schema),各屬性向量的長度和空值個數,各屬性向量的內存地址。一個屬性向量占用連續的物理內存,整個Batch在網絡傳輸時,連續字節傳輸。一個Batch中可以存儲 1-64K條數據記錄。
3 ADE架構設計與關鍵技術
ADE包含Coordinator、Executor兩個角色,兩者通過zookeeper協調。Zookeeper記錄了Coordinator和Executor的節點名稱、IP、內存、CPU等信息。Coordinator負責接收用戶端SQL請求、解析SQL語法樹、生成Logic Plan、獲取并存儲數據表的元數據、分配Executor節點、執行每個分區數據的Logic Plan,并匯總SQL結果返回給客戶端。Executor負責執行在每個分區數據的Logic Plan,發送結果數據給Coordinator。Coordinator和Executor之間通過gRPC進行并行通信。
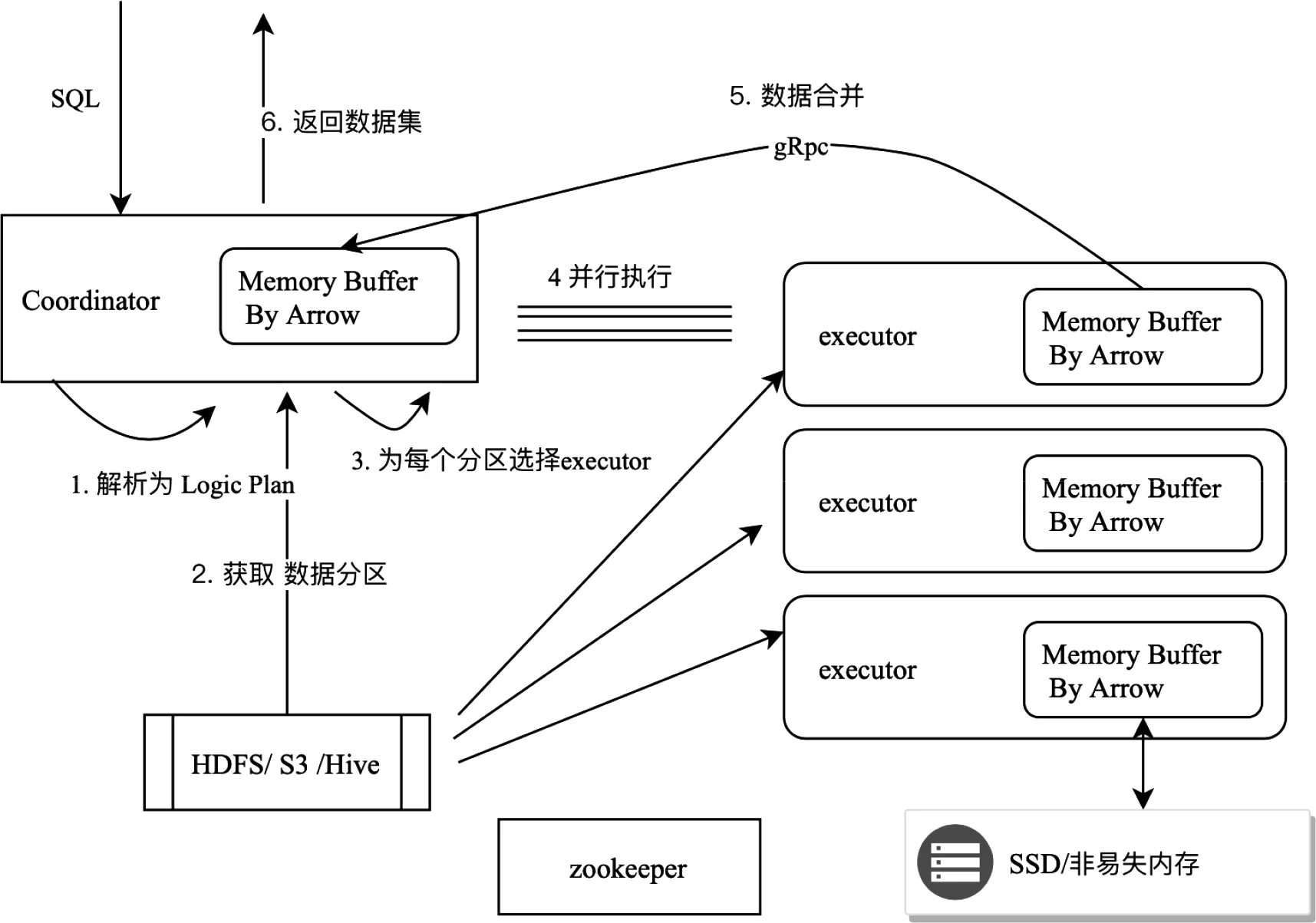
圖5 查詢引擎ADE的架構設計
3.1 面向向量的執行計劃
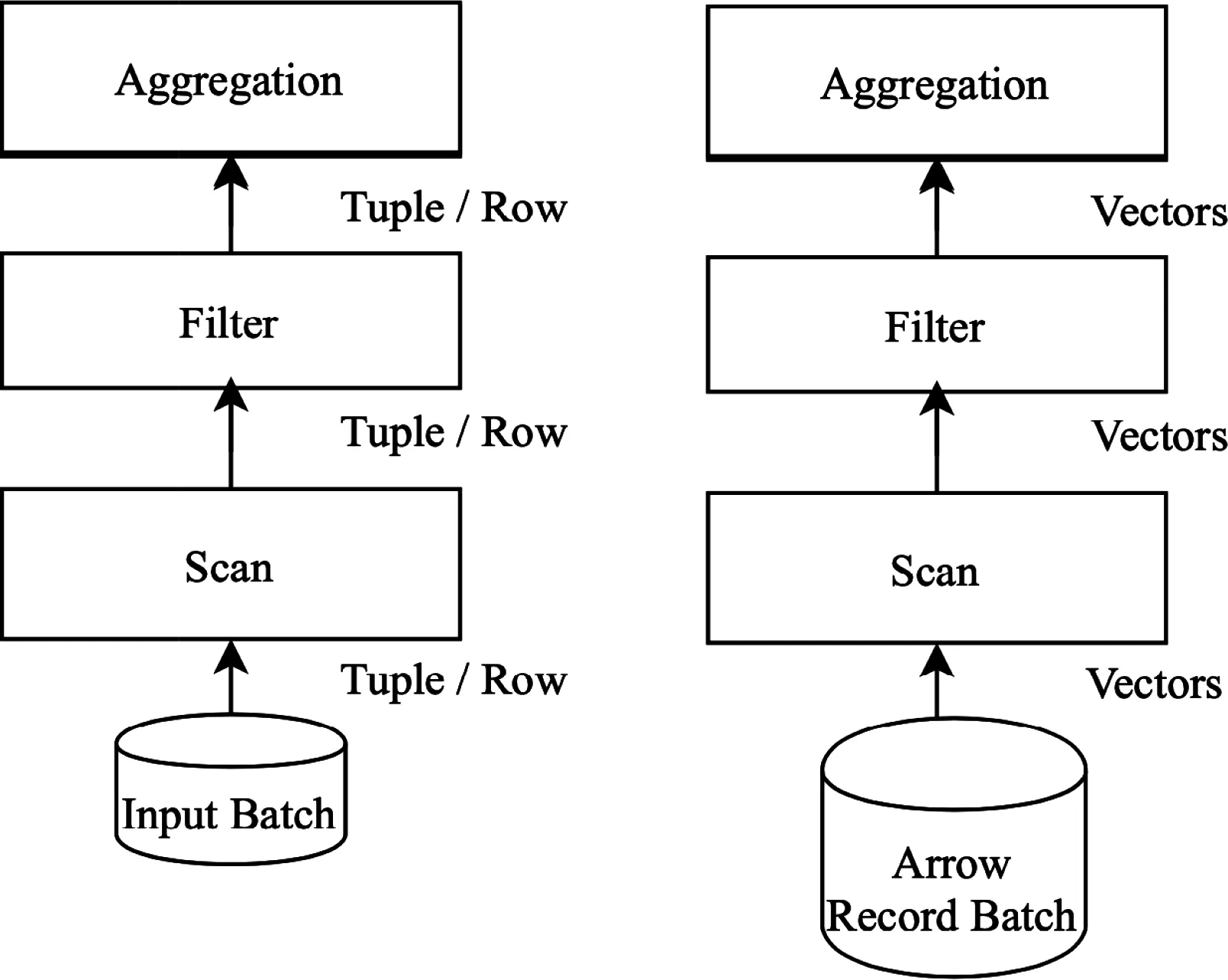
圖6 向量在執行計劃Operator之間傳輸
傳統的基于行存儲的查詢引擎,在查詢計劃節點之間傳遞的是行或者Tuple對象。通過調用next方法,逐行的處理數據。在大數據環境下,函數調用上下文切換的時間消耗,不可忽略。而且在OLAP中的聚合運算,往往只需要部分列,Tuple中卻包含了所有的列數據。相反,列存儲以向量的方式計算和傳遞數據,向量數據以Record Batch 的格式,在Operator之間傳輸。向量運算和傳遞,充分利用了SIMD指令,快速實現FILTER, COUNT, SUM, MIN 。OLAP典型的計算是復雜Join、數據聚合和數據掃描。以如下SQL為例詳細介紹ADE查詢引擎的工作方式:
SELECT avg(wholesale_cost), avg(list_price) FROM store_sales
Operator的Allocator之間有父子關系,同查詢計劃的父子關系。父Operator能夠訪問子Operator的Allocator的數據。Scan算子選擇四個字段,掃描數據封裝在Record Batch中。Filter算子掃描store_sk向量,過濾出store_sk=7的行,記錄在Filter Vector向量中。Filter Vector的格式為4個字節的向量數組,結構為(batch_index,row_index)。其中1-2字節標識Batch的Index,3-4字節標識在該Batch中的位置。如(3,68)。Aggregation算子,通過構建Hash Table來計算Avg平均值。分為兩個步驟:
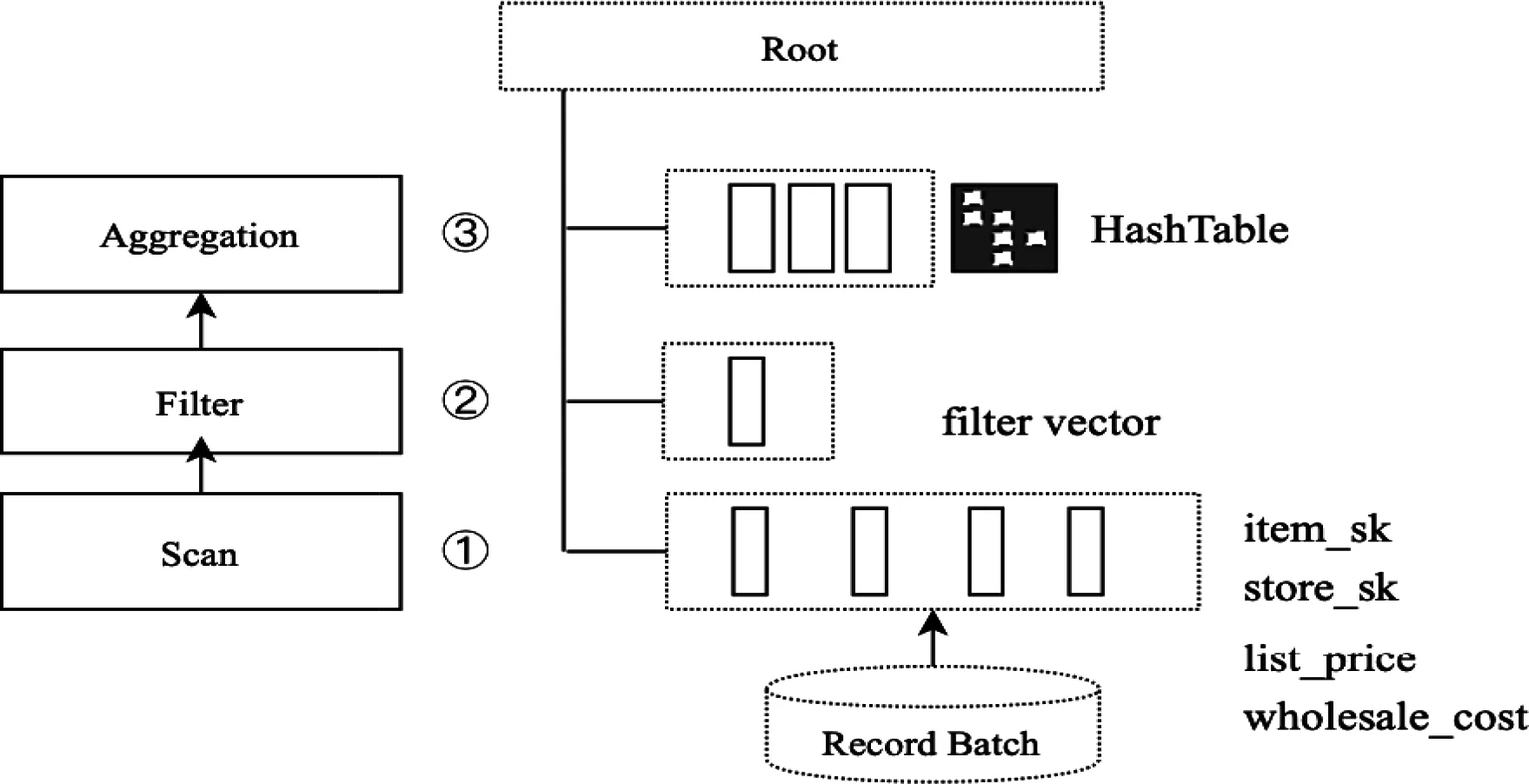
圖7 面向內存向量的過濾與聚合運算
掃描Record Batch中Group By字段(item_sk),Avg字段(list_price、wholesale_cost)使用SIMD指令掃描,Item Vector構建新的Record Batch。
對上述Record Batch掃描字段(item_sk)進行轉置成行式數據,對所有Keys字段計算Hash值并構建Hash Vector,進而構建Hash Table,在Hash Table中進行Aggregation運算。Hash Table是常用來進行Hash Aggregation/Hash join的數據結構。
3.2 過濾和排序實現
在執行過濾和排序操作時,使用一個索引向量,來標識符合條件的數據行或者使用索引向量順序標識向量值的順序。因為一個batch設計為最多64K條記錄。所以用Int16整數表示。Batch之內,使用2字節的整型0,12,17表示行索引號。標識多個Batch數據,使用4字節的,區間索引。0-12表示第一個batch的第12行記錄。
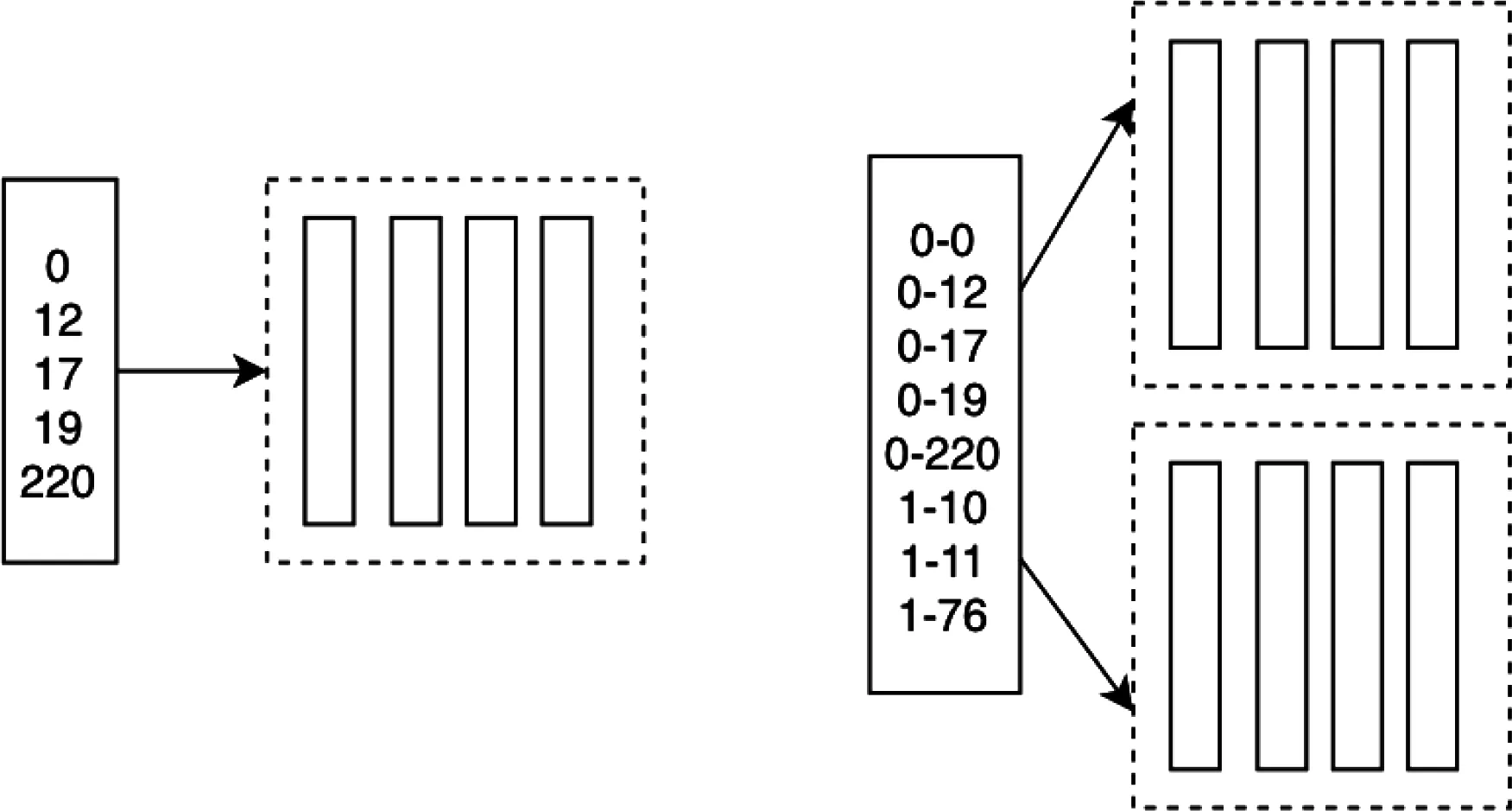
圖8 FilterVector實現過濾和排序
執行過濾操作時,一次Scan就能過濾出符合條件的記錄,不需要改變原始數據得結構,只需要構建一個索引向量。輸出查詢結果時,只需要根據這個FilterVector和字段映射選擇某些字段向量匹配索引輸出即可。
執行排序操作時,使用選擇排序算法或者冒泡排序算法,依次把最大到最小值的索引放在FilterVector中。輸出查詢結果時,只需要根據這個FilterVector和字段映射選擇某些字段向量匹配索引輸出即可。
3.3 Hash關聯與Hash 聚合運算
在實踐中發現,列式存儲格式,不利于進行HashJoin、HashAggregation運算。因為列式存儲對HashTable的插入、查找是低效的。因此,需要在計算之前先轉置成行的格式。首先,把GroupBy字段進行轉置成行數據,然后構建Hash Table。如圖9所示。
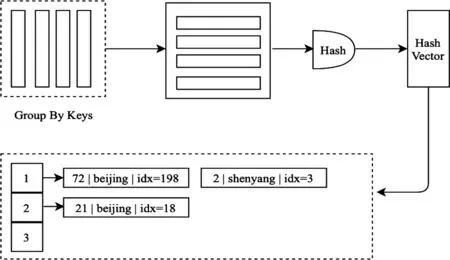
圖9 數據轉置和構建Hash Table
3.4 節點數據遷移優化
節點之間Shuffle數據仍然是按照Record Batch封裝,每個Record Batch都開啟一個線程進行數據傳輸,而Record Batch過濾后可能僅有很少的數據,這無疑就增加了上下文交換、任務調度、線程資源開銷。為此本文中使用多路復用技術、在發送端重新組裝Record Batch。

圖10 多路復用節點間數據傳輸
如圖10所示,N個RecordBatch最終分配到K個Buckets進行數據傳輸,K即集群節點數。Filter Vector后的數據,首選對Key進行Hash,生成Bucket Id,為此,每個RecordBatch生成Bucket Vector。然后,所有遍歷Record Batch,根據Bucket Vector把數據分配到對應的Bucket,并根據記錄數等參數,每個Bucket數據都封裝成多個Record Batch。為每個Bucket啟動一個線程,進行數據傳輸。優化前節點間數據交換次數為(K-1)* N,優化后為(K-1)* K。
3.5 動態估算Batch Size
Arrow以Batch的方式存儲和傳輸數據,在內存的數據,往往要比在磁盤上大,因為在磁盤上可以壓縮,而在內存中一般不壓縮,因為要支持隨機讀取等操作。Batch是處理數據得最小執行單元。適當的Batch Size有利于集中計算,提高Operator之間數據傳輸效率,減少上下文交換,減少計算任務調度次數,提升整體效率。Batch Size過大可能會造成Operation之間數據傳輸異常。Batch Size過小會增多上下文交換、增加線程數量、增大數據處理時內存overhead消耗。除此之外,批次大小還要考慮數據表的寬度、字段數量、平均字節數等因素。
ADE實現了根據表寬、字段數自動調整Batch Size。一般情況下Batch size在127-4095之間。計算公式為:
(4)
其中:bi為第i個字段的固定字節長度,h為行固定開銷一般為128字節,C為字段數量。W為表寬的調整因子,當C大于100是為1,當C小于100是為2。使用公式(6)把batchsize計算結果調整到127-4095的范圍內。
W=2ifC≤100
1ifC>100
(5)
batchsize=min(max(pre_batchsize, 127), 4095)
(6)
3.6 RPC數據傳輸協議
Batch的字段內部是連續的內存存儲,字段之間的內存區是不連續的。在RPC 傳輸時,修改傳輸協議頭,一次性連續傳輸所有字段的數據。并且增加RPC連接失敗回調處理方法,發生傳輸異常時進行重試,而不是簡單的異常斷開連接。
3.7 數據壓縮和優化
使用字典類型進行數據編碼和查詢優化。例如可以將全國省市字典加載,數據中使用Int32類型表示。原來重復每行記錄需要存儲的省市名稱,現在只需要用一個有限長度的字典向量即可。這樣,可以減少數據存儲量,壓縮數據。同時,把可變長度字段變為固定長度Int32類型,提高計算過濾、分組統計效率。如圖11所示。
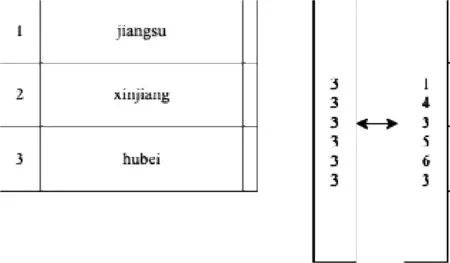
圖11 字典類型向量壓縮
3.8 并行查詢接口
ADE作為其他大數據組件(如Spark)的數據源,則JDBC訪問方式會成為瓶頸。因此該平臺設計了并行查詢接口,如上圖MPP并行計算引擎Spark,如圖12所示。ADE和Spark之間,使用Arrow Flight RPC傳輸數據,詳細過程分為三個階段:①發送SQL語句,ADE開始運行SQL,并生成運行基本數據,包括數據分片、執行節點、各節點的RPC的Endpoint。②客戶端向ADE發送doGet命令,請求發送數據,同時建立一個監聽器,監聽ADE發回的數據。ADE建立數據發送通道,不停地把數據集push到客戶端。③ADE發送數據完畢,發送complete指令。或者客戶端主動cancel 數據獲取動作。如圖12所示。
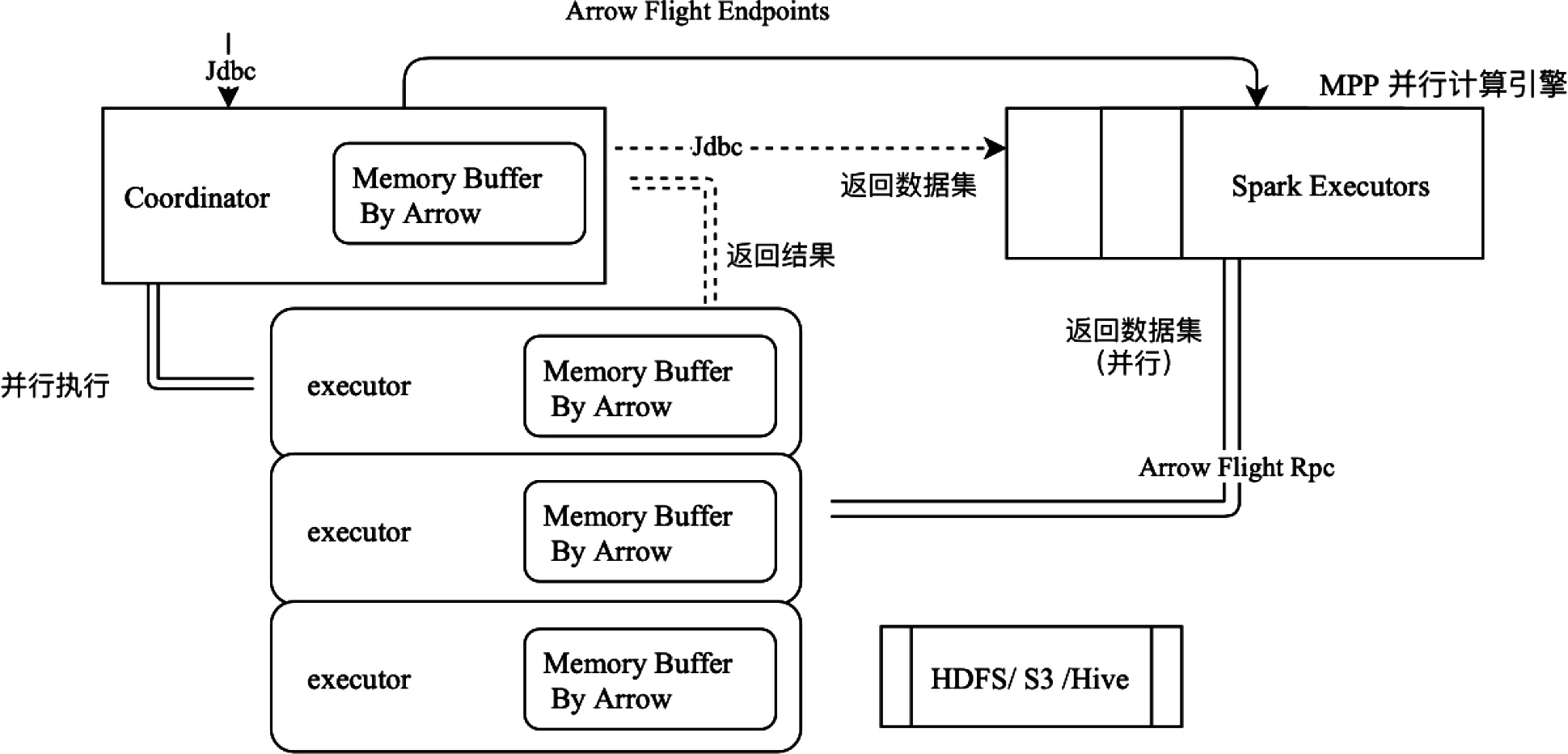
圖12 并行查詢接口架構
3.9 實驗效果分析
該項目采用TPC-DS測試工具集,與Hive on Spark、Apache Drill進行對比驗證。Hive on Spark配置為Executor四臺(8 Cores、10G內存、500G磁盤);Driver一臺(8 Cores、32G內存、500G磁盤)。Drill配置為四臺(8 Cores、4堆內存、8G堆外內存、500G磁盤)。ADE配置為Coordinator一臺(8 Cores、32G內存、500G磁盤),Executor四臺(8 Cores、4堆內存、8G堆外內存、500G磁盤)。
TPC-DS測試工具集生成1GB的數據量,并對數據根據時間分區。使用5線程數據負載測試,每個線程均按照隨機順序運行TPC-DS的84個SQL查詢語句(3)TPC-DS有標準的99條SQL語句,該文去除了15個函數不兼容的SQL語句。總體耗時對比結果如表1所示。
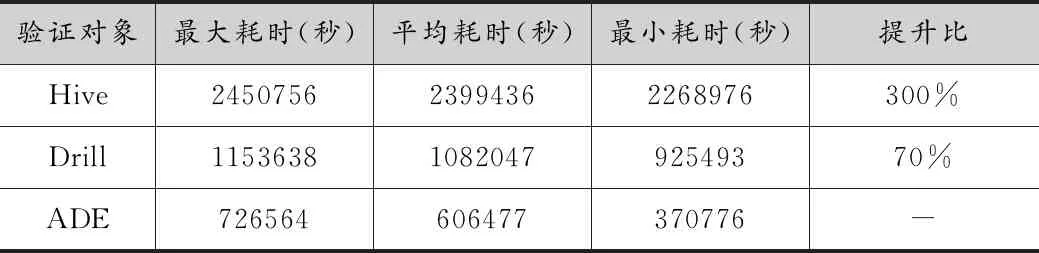
表1 TPC-DS測試數據對比
采集壓測過程中84條SQL的耗時數據,分別把ADE與Hive、Drill對比,如圖13所示。可見,在大多數SQL語句中,ADE性能大幅提高,比較Hive提升了近300%;比較Drill提升了近70%。在壓測過程中,觀察CPU負載情況,如圖14所示。可見,在SQL并行運行過程中,Hive的CPU負載較大波動,CPU利用率低;Drill的CPU負載相對比較平穩,CPU利用率高;ADE的CPU負載最為平穩,CPU利用率最高。
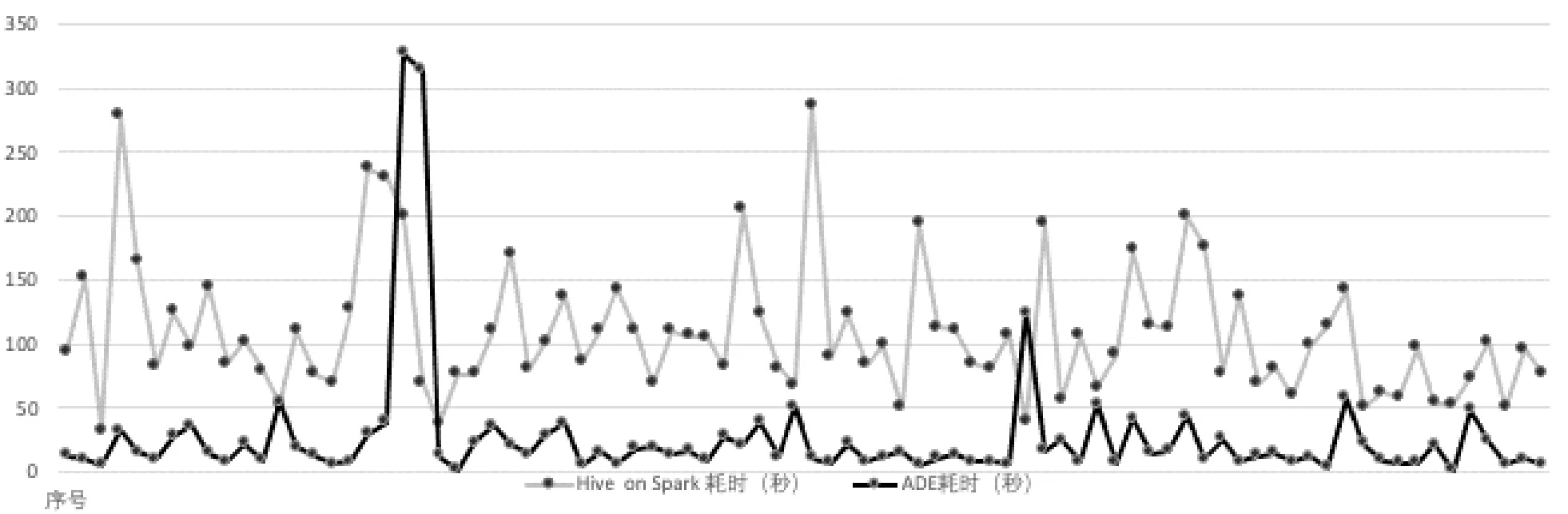
(a) Hive on Spark 與 ADE SQL耗時對比
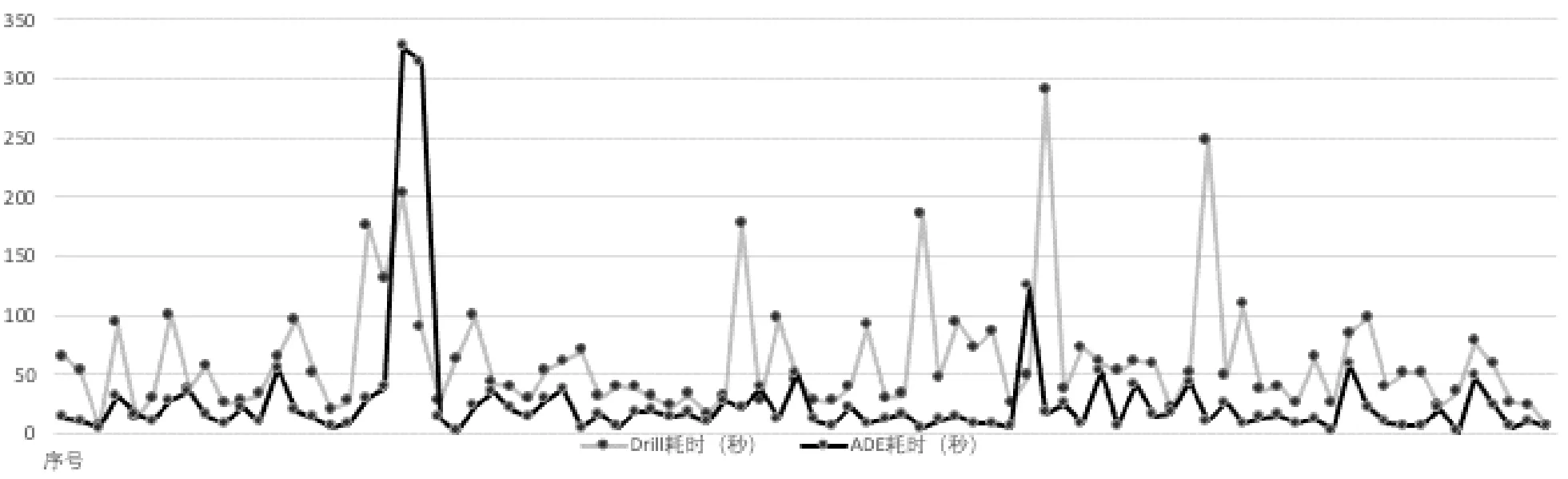
(b) Apache Drill 與 ADE SQL耗時對比

(a) Hive on Spark的CPU利用率
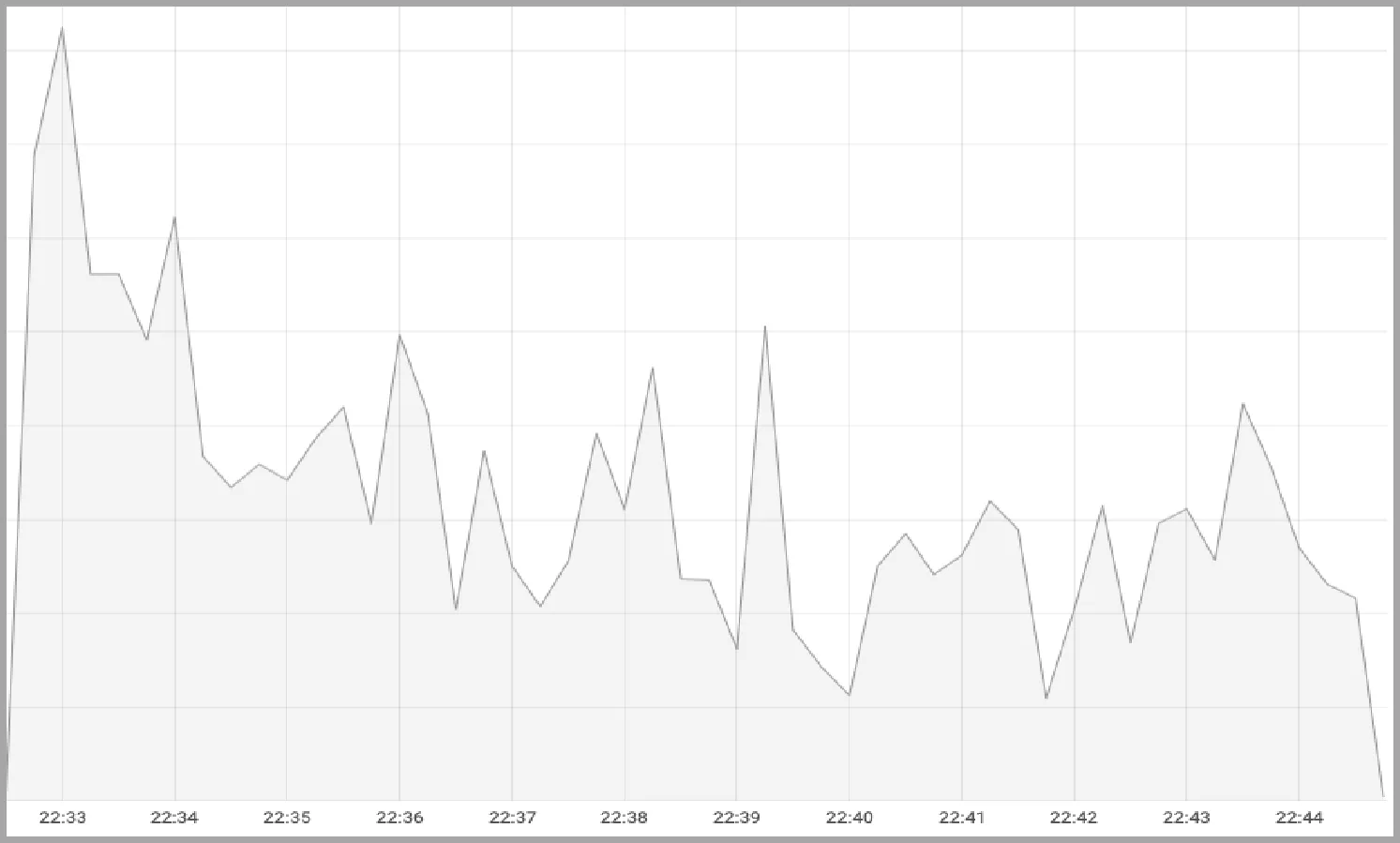
(b) Apache Drill的CPU利用率

(c) ADE的CPU利用率
4 結語
本文介紹了一種基于Arrow技術設計和實現的一種內存列存儲查詢引擎ADE,詳細介紹了SQL查詢中向量計算、內存使用的方法,并描述了其中的關鍵技術及優化策略,包括:過濾排序、節點數據Shuffle、Hash聚合運算、Hash Join、Batch Size估算、并行查詢接口等。經與Hive on Spark、Apache Drill的驗證對比說明ADE在面向OLAP場景的數據源聯合查詢中有效提高了查詢性能。
進一步的展望,可以著重在SQL的兼容性和預計算技術兩個方面。ADE的SQL兼容性應符合ANSI SQL-99標準,并支持大多數的函數運算。ADE結合預計算和SQL重寫技術,進一步提高常規查詢的性能。
猜你喜歡
江蘇安全生產(2023年10期)2023-11-14 12:12:58
江蘇安全生產(2022年8期)2022-11-01 09:14:48
房地產導刊(2020年12期)2021-01-14 09:25:04
消費導刊(2018年8期)2018-05-25 13:19:23
知識經濟·中國直銷(2018年3期)2018-04-12 06:43:21
商周刊(2017年22期)2017-11-09 05:08:31
中國水產(2017年2期)2017-02-25 07:56:29
中國衛生(2015年4期)2015-11-08 11:16:18
河南電力(2015年5期)2015-06-08 06:01:46
皖西學院學報(2015年5期)2015-02-28 17:52:46
