遷移學(xué)習(xí)在自然語言處理中的應(yīng)用綜述
2021-09-04 07:27:12袁君
科教導(dǎo)刊·電子版 2021年21期
袁 君
(武漢學(xué)院 湖北·武漢 430212)
1 遷移學(xué)習(xí)簡介
Bozinovski等人最早明確提出在神經(jīng)網(wǎng)絡(luò)的訓(xùn)練過程中使用遷移學(xué)習(xí)的方法,并且給出了一個(gè)基于數(shù)學(xué)和幾何學(xué)的遷移學(xué)習(xí)模型。遷移學(xué)習(xí)作為一種機(jī)器學(xué)習(xí)的方法,就是把為任務(wù)A開發(fā)的模型作為原始模型,將其重新應(yīng)用在任務(wù)B中來開發(fā)出一套針對(duì)任務(wù)B的模型。其中任務(wù)A和任務(wù)B應(yīng)該具有一定的相關(guān)性或者相似性。其一般的過程如下圖1所示。

圖1:遷移學(xué)習(xí)的一般過程
因此在遷移學(xué)習(xí)中核心的問題是,如何找到目標(biāo)任務(wù)與源任務(wù)之間的相似性,并順利的實(shí)現(xiàn)知識(shí)/經(jīng)驗(yàn)的遷移。簡而言之,我們希望計(jì)算機(jī)可以利用遷移學(xué)習(xí)的方法像人一樣通過舉一反三的進(jìn)行學(xué)習(xí)。圖2給出了生活中常見的遷移學(xué)習(xí)的例子。

圖2:遷移學(xué)習(xí)的例子
2 遷移學(xué)習(xí)在自然語言處理中的應(yīng)用與分類
在過去幾年的時(shí)間里,以預(yù)訓(xùn)練語言模型為形式的遷移學(xué)習(xí)在自然語言處理中已經(jīng)無處不在,并在各種任務(wù)解決中發(fā)揮了實(shí)質(zhì)性的作用。然而,遷移學(xué)習(xí)在自然語言處理中的應(yīng)用并不是一個(gè)新進(jìn)出現(xiàn)的方法。我們以命名實(shí)體識(shí)別(NER)任務(wù)的進(jìn)展為例,如下圖3所示:

圖3:CoNLL-2003(英語)上的命名實(shí)體識(shí)別(NER)性能隨時(shí)間變化
縱觀其歷史,這項(xiàng)任務(wù)的大部分重大改進(jìn)都是由不同形式的遷移學(xué)習(xí)推動(dòng)的:從早期Ando等人提出的帶有輔助任務(wù)的自我監(jiān)督學(xué)習(xí)和Lin等人對(duì)短語及詞組的研究到近年來Peters等人的語言模型嵌入,以及包括近幾年P(guān)eters,Akbik,Baevski分別提出的預(yù)訓(xùn)練語言模型。
目前在自然語言處理中常見的遷移學(xué)習(xí)有不同的類型。這些可以根據(jù)以下三個(gè)維度進(jìn)行大致分類:
(1)源和目標(biāo)設(shè)置是否處理相同的任務(wù);
(2)源和目標(biāo)領(lǐng)域的性質(zhì);
(3)學(xué)習(xí)任務(wù)的順序。
這些任務(wù)的具體分類如下圖4所示,其中順序遷移學(xué)習(xí)是到目前為止取得最大進(jìn)展的方法。

圖4:遷移學(xué)習(xí)在自然語言處理中分類
3 順序遷移學(xué)習(xí)方法
順序遷移學(xué)習(xí)一般的做法是選擇合適的方法在大型的無標(biāo)簽文本語料庫上進(jìn)行預(yù)訓(xùn)練表征,然后用有標(biāo)簽的數(shù)據(jù)將這些表征遷移到有監(jiān)督的目標(biāo)任務(wù)中,如下圖5所示,其中預(yù)訓(xùn)練和適應(yīng)是該方法的核心步驟。
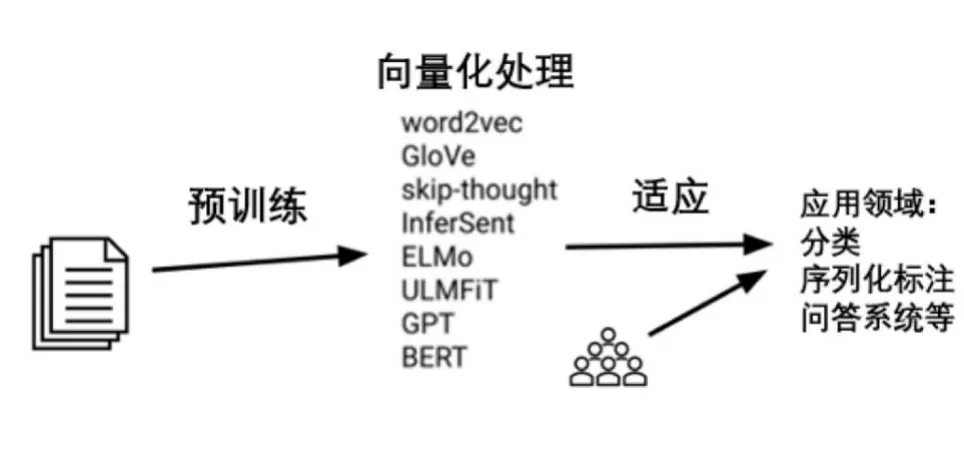
圖5:順序遷移學(xué)習(xí)過程
3.1 預(yù)訓(xùn)練
預(yù)訓(xùn)練語言模型所取得的成功是令人矚目的。語言建模成功的一個(gè)原因可能是即使對(duì)人類來說它也是一項(xiàng)非常困難的任務(wù)。為了有機(jī)會(huì)解決這個(gè)任務(wù),一個(gè)模型需要學(xué)習(xí)語法、語義以及關(guān)于世界的某些事實(shí)。給予足夠的數(shù)據(jù)、大量的參數(shù)和足夠的計(jì)算,一個(gè)模型可以做一個(gè)合理的工作。Zhang和Wang則驗(yàn)證了相較于其他預(yù)訓(xùn)練任務(wù),語言建模在翻譯或自動(dòng)編碼等方面取得了更好的效果。最近Hahn對(duì)人類語言的預(yù)測率失真(PRD)分析表明,人類語言以及語言建模具有無限的統(tǒng)計(jì)復(fù)雜性,但它可以在較低水平上得到很好的近似。這一觀察表明:(1)可以用相對(duì)較小的模型獲得良好的結(jié)果;(2)有很大的潛力來擴(kuò)大模型規(guī)模。對(duì)于這兩個(gè)含義,都有經(jīng)驗(yàn)性的證據(jù)。
一般來說,為了提高預(yù)訓(xùn)練的表現(xiàn),可以通過聯(lián)合增加模型參數(shù)的數(shù)量和預(yù)訓(xùn)練數(shù)據(jù)的數(shù)量來改善效果。隨著預(yù)訓(xùn)練數(shù)據(jù)量的增長,收益開始減少。然而,如下圖6所示的性能曲線,并不表明我們已經(jīng)達(dá)到了一個(gè)瓶頸。因此,可以期待看到在更多數(shù)據(jù)上訓(xùn)練的更大的模型。

圖6:使用不同數(shù)量的共同抓取數(shù)據(jù)進(jìn)行預(yù)訓(xùn)練的GLUE平均得分
預(yù)訓(xùn)練的一個(gè)主要應(yīng)用方向是跨語言的預(yù)訓(xùn)練,并可以使我們?yōu)槭澜缟?000種語言建立屬于它們自己的自然語言處理模型。許多關(guān)于跨語言學(xué)習(xí)的工作如Ruder都集中在訓(xùn)練不同語言的單獨(dú)的詞嵌入,并學(xué)習(xí)如何對(duì)齊它們。同樣地,Shuster提出可以學(xué)習(xí)對(duì)齊語境表征。Devlin,Artetxe則提出了另一種常見的方法是共享一個(gè)子詞詞表,并在多種語言上訓(xùn)練一個(gè)模型。雖然這很容易實(shí)現(xiàn),而且是一個(gè)強(qiáng)大的跨語言基線,但Heinzerling指出它會(huì)導(dǎo)致低資源語言的代表性不足。Pires和Wu分別提出的多語種的BERT模型則成為了備受關(guān)注的主題。盡管它具有強(qiáng)大的零點(diǎn)性能,但Eisenschlos專用的單語語言模型往往具有競爭力,同時(shí)效率更高。
3.2 適應(yīng)
為了使預(yù)訓(xùn)練的模型適應(yīng)目標(biāo)任務(wù),我們可以對(duì)架構(gòu)進(jìn)行修改和優(yōu)化方案。
3.2.1 架構(gòu)的修改
保持預(yù)訓(xùn)練模型的內(nèi)部結(jié)構(gòu)不變。這可以簡單到在預(yù)訓(xùn)練模型的基礎(chǔ)上增加一個(gè)或多個(gè)線性層,這通常是用BERT模型來做的。但我們也可以在預(yù)訓(xùn)練模型無法為目標(biāo)任務(wù)提供必要的交互時(shí),將模型的輸出作為一個(gè)單獨(dú)的模型的輸入,例如跨度表示或跨句子關(guān)系建模任務(wù)中。
修改預(yù)訓(xùn)練模型的內(nèi)部結(jié)構(gòu)。如Houlsby和Stickland分別嘗試使用預(yù)訓(xùn)練的模型來盡可能地初始化結(jié)構(gòu)不同的目標(biāo)任務(wù)模型。此外還可以應(yīng)用特定的任務(wù)修改,如增加跳過或殘留的連接或注意力。最后,修改目標(biāo)任務(wù)參數(shù)可以通過在預(yù)訓(xùn)練模型的各層之間添加瓶頸模塊(“適配器”)來減少需要微調(diào)的參數(shù)數(shù)量。
3.2.2 方案的優(yōu)化
在優(yōu)化模型方面,可以選擇應(yīng)該更新哪些權(quán)重以及如何和何時(shí)更新這些權(quán)重。
(1)對(duì)于預(yù)訓(xùn)練模型的權(quán)重,可以選擇調(diào)整或不調(diào)整兩種策略。
不改變預(yù)訓(xùn)練的權(quán)重。在實(shí)踐中,線性分類器是在預(yù)訓(xùn)練的表征之上訓(xùn)練的。Ruder等人發(fā)現(xiàn)要到達(dá)最優(yōu)性能不只需要利用頂層的表征,也需要學(xué)習(xí)各層表征的線性組合來實(shí)現(xiàn)的。另外,預(yù)訓(xùn)練的表征可以作為下游模型的特征使用。當(dāng)添加適配器時(shí),只有適配器層需要加以訓(xùn)練。
改變預(yù)訓(xùn)練的權(quán)重。預(yù)訓(xùn)練的權(quán)重被用作下游模型的參數(shù)的初始化。然后在適應(yīng)階段對(duì)整個(gè)預(yù)訓(xùn)練的結(jié)構(gòu)進(jìn)行訓(xùn)練。
(2)更新權(quán)重。
跟新權(quán)重的主要目的是避免覆蓋有用的預(yù)訓(xùn)練信息,并最大限度地實(shí)現(xiàn)正向轉(zhuǎn)移。McClosky曾提出災(zāi)難性遺忘的概念,即一個(gè)模型忘記了它最初訓(xùn)練的任務(wù)。同預(yù)訓(xùn)練模型相比,更新模型參數(shù)的指導(dǎo)原則是在時(shí)間上、強(qiáng)度上,從上到下逐步更新參數(shù)。
在時(shí)間上逐步更新。通常如果同時(shí)在所有的網(wǎng)絡(luò)層中利用不同的任務(wù)來進(jìn)行訓(xùn)練會(huì)導(dǎo)致性能的不穩(wěn)定和糟糕的解決方案。因此在早起深度神經(jīng)網(wǎng)絡(luò)的分層訓(xùn)練中Hinton和Bengio都分別嘗試了分別訓(xùn)練各神經(jīng)層去適應(yīng)新的任務(wù)和數(shù)據(jù)。最近Felbo,Howard和Chronopoulou各自提出的方法多以共同訓(xùn)練的層之間不同的組合方式為主;并在最后聯(lián)合訓(xùn)練所有參數(shù)。
強(qiáng)度逐漸增加。通常使用較低的學(xué)習(xí)率是為了避免覆蓋有用的信息。低學(xué)習(xí)率在低網(wǎng)絡(luò)層、訓(xùn)練早期和訓(xùn)練后期尤為重要。Howard提出可以使用鑒別性的微調(diào)是每一層的學(xué)習(xí)率適度衰減。為了在訓(xùn)練前期保持較低的學(xué)習(xí)率,可以使用三角學(xué)習(xí)率計(jì)劃。Liu最近提出,預(yù)熱可以減少訓(xùn)練早期的變異。
4 遷移學(xué)習(xí)在自然語言處理中的問題
預(yù)訓(xùn)練的語言模型在細(xì)粒度的語言任務(wù)(Liu)、層次化的句法推理(Kuncoro)和常識(shí)(Zeller)方面表現(xiàn)仍然很糟糕。它們?cè)谧匀徽Z言生成方面仍然表現(xiàn)較差,尤其是在保持語言的一貫性、關(guān)系和一致性方面。較大模型如果只利用少量數(shù)據(jù)進(jìn)行微調(diào)時(shí)會(huì)使其較難優(yōu)化,并且還會(huì)出現(xiàn)高變異的情況。目前預(yù)訓(xùn)練的語言模型也非常大,因此蒸餾和修剪是處理這個(gè)問題的較好選擇。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
文苑(2020年4期)2020-05-30 12:35:30
小學(xué)生作文(中高年級(jí)適用)(2018年3期)2018-04-18 01:24:47
華北電力大學(xué)學(xué)報(bào)(社會(huì)科學(xué)版)(2016年4期)2016-12-01 03:59:30
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
少兒科學(xué)周刊·少年版(2015年4期)2015-07-07 21:11:17
