Spectre X RF在大規模RFIC設計中的應用
2021-08-29 07:00:16郭錫韌
電子技術應用 2021年8期
郭錫韌 ,曾 義
(1.深圳市中興微電子技術有限公司,廣東 深圳 518055;2.上海楷登電子科技有限公司,上海 200120)
0 引言
隨著模擬電路復雜性增大以及工藝尺寸不斷減小,寄生規模不斷增大。模擬下變頻電路是通信鏈路中的接收機模塊的重要電路模塊,其中包含的射頻前端電路,在設計過程中,代入后仿寄生參數后,還需要進行多次RF 仿真。仿真速度對設計影響較大,另一方面,受限于服務器性能限制,無法滿足部分大規模小尺寸模擬射頻電路內存需求。
Spectre X RF 仿真器是Cadence 于2020 年推出的新一代仿真器,能提升仿真速度、優化內存,能有效解決目前射頻前端RF 仿真中仿真速度過慢、服務器性能需求過高的問題。
在應用Spectre X RF 之前,需對其進行評估,本文在三個主流工藝下,在模擬下變頻模塊中,對比Spectre APS RF 和Spectre X RF的精度、內存和速度。
1 模擬下變頻電路
模擬下變頻電路是通信系統中接收機模塊中的重要模塊,如圖1 所示,本文中使用的模擬下變頻電路包括射頻前端以及后端中頻模塊,主要包括混頻器、放大器、濾波器等結構。

圖1 模擬下變頻模塊結構圖
LO 信號為方波信號,在hb 仿真過程中,為了得到符合設計需求的精度,通常需要設置比較大的諧波數,導致速度過慢、內存需求過大。
隨著電路性能需求的提升,模擬下變頻電路規模不斷增大,仿真器的精度和性能需求也隨之提升。
OIP3(Output third Intercept Point)為射頻電路系統中衡量線性度的重要指標。常規射頻系統仿真中,得到OIP3有兩種方法:hb+hbac,小信號輸入,hbac 使用Rapid IP3模式;hb,LO 信號與雙音信號交調。
本文利用OIP3 進行精度分析,在不同工藝中分別使用了兩種常用仿真形式中的一種。
2 Spectre X RF
Spectre X RF 仿真器是Cadence 于2020 年推出的新一代仿真器,目的是解決使用Spectre APS 對大寄生射頻電路仿真中內存過高、速度慢的問題。理論上與Spectre APS RF 精度相當,速度提高2~3 倍,內存減小。
Spectre X RF的使用模式與Spectre X 一致,對比Spectre APS的使用模式,Spectre X RF/X 更為簡單,圖2 為其不同模式的簡要說明。對于一般的模擬射頻電路,Cadence推薦使用Cx/Ax/Mx。本文使用了Cx、Ax、Mx 三種模式,APS RF 相應的模式為Conservatice/Moderate 和+postlayout=hpa/upa。

圖2 Spectre X RF 使用模式說明
3 仿真結果
本文對比了TSMC 28 nm、SMIC 14 nm、TSMC 7 nm三種工藝中的Spectre X RF 與Spectre APS RF的速度、內存以及實際需求中性能參數的仿真精度。三種工藝中均使用接收機射頻前端,即模擬下變頻電路。
3.1 TSMC 28 nm
TSMC 28 nm工藝環境中,仿真使用的電路規模為1.971M N,103k bsim 4,5.616M C,2.573M R。Spectre APS RF 與Spectre X RF 均使用了16 線程。
對TSMC 28 nm工藝的模擬下變頻電路做了hb+hbac仿真,hb 仿真中,為滿足精度需求,LO 信號的諧波數與過采樣因子分別設為15 與2,hbac 使用Rapid IP3 模式。APS+Conservative+UPA 仿真結果如圖3 所示。

圖3 TSMC 28 nm hbac Rapid IP3 仿真結果
TSMC 28 nm工藝中,Spectre APS RF 與Spectre X RF 仿真性能對比如表1 所示,其中,Spectre APS RF 使用Conservative、Moderate 兩種精度,內存優化選擇UPA(Ultra Precision Analog)與HPA(High Precision Analog);Spectre X RF使用CX、AX、MX 三種模式。精度為OIP3 相對于Conservative+UPA OIP3 偏差值。

表1 TSMC 28 nm工藝仿真對比
從表中可看出,在TSMC 28 nm工藝中,Spectre X RF 對內存優化不太明顯,僅在UPA 內存優化模式中,內存相對較大,運行時間相對較長。具體內存優化與運行時間優化如表5 所示。
以APS RF Conservative+UPA 作為標準,精度最低為Spectre X RF+MX,為98.87%,在射頻電路系統中,為可接受的誤差值。
以APS RF Conservative+UPA 運行時間為基準,Spectre X RF 整體提速約7 倍,以常用的Convervative+HPA 為基準,整體提速約2 倍多。
3.2 SMIC 14 nm
SMIC 14 nm工藝環境中,仿真使用的電路規模為0.388M N,82k bsimcmg,0.639 M C,1.03 M R。Spectre APS RF 與Spectre X RF 均使用了16 線程。
此工藝中使用了hb LO 信號與雙音信號交調方式仿真OIP3,輸入信號為頻率相差1 MHz的雙音信號,LO信號的諧波數與過采樣因子為15 與2,雙音信號的諧波數與過采樣因子均為5 與1,各模式的時域輸出波形如圖4 所示。

圖4 SMIC 14 nm 時域輸出波形對比
各模式的頻域輸出波形如圖5 所示。

圖5 SMIC 14 nm 頻域輸出波形對比
SMIC 14 nm工藝中,Spectre APS RF 與Spectre X RF仿真性能對比如表2 所示,各仿真器使用模式與TSMC 28 nm 一致。

表2 SMIC 14 nm工藝仿真對比
在SMIC 14 nm工藝中,Spectre X RF 內存優化不太理想,運行時間有一定的優化,但未達到理論預期。
以Conservative+UPA 作為標準,精度最低為Spectre X RF+MX,為98.40%,在射頻電路系統中,為可接受的誤差值。
Cadence 研發已經在對該電路進行調查研究。
3.3 TSMC 7 nm
TSMC 7 nm工藝環境中,仿真使用的電路規模為994k N,33k bsource_rhim,50k tmibsimcmg,1.4M C,3.761M R。Spectre APS RF 與Spectre X RF 均使用了16 線程。
此工藝中使用了hb LO 信號與雙音信號交調方式仿真OIP3,輸入信號為頻率相差1 MHz的雙音信號,LO信號的諧波數與過采樣因子為15 與2。
在仿真前的內存預估過程中,Spectre APS RF 預計使用內存如表3 所示。仿真使用服務器僅有1.4 TB 內存,無法滿足內存使用需求。

表3 TSMC 7 nm Spectre APS RF 內存預估
Spectre APS RF 中打開lowmems開關,Conservative+HPA 內存減小至1.2 TB。
Spectre X RF的內存預估在服務器性能范圍內,最終使用Spectre X RF 與Spectre APS RF 對電路進行了仿真。圖6 與圖7 分別為TSMC 7 nm工藝中各仿真模式輸出端時域與頻域的波形對比。TSMC 7 nm工藝仿真對比如表4 所示。

圖6 TSMC 7 nm 時域輸出波形對比

圖7 TSMC 7 nm 頻域輸出波形對比
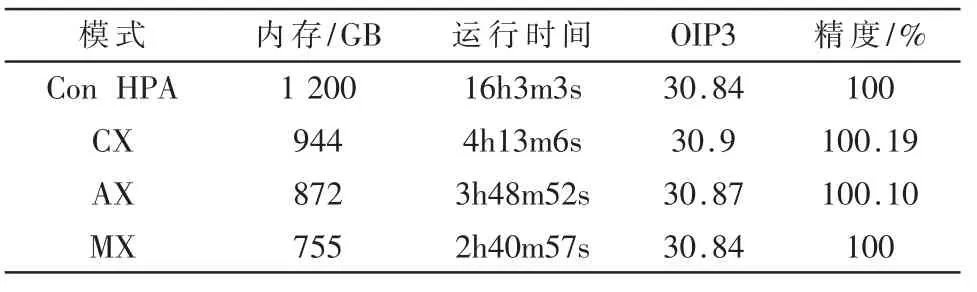
表4 TSMC 7 nm工藝仿真對比
TSMC 7 nm工藝環境中,Spectre X RF 內存優化、運行時間優化均高于預期,對比于降低內存的APS+Conservative+HPA OIP3 精度保持很好,且提速約4 倍,符合實際項目需求。如果Spectre X RF 也打開lowmem options,運行時間和內存使用應當還能進一步降低。
具體內存優化與運行時間優化如表5 所示。
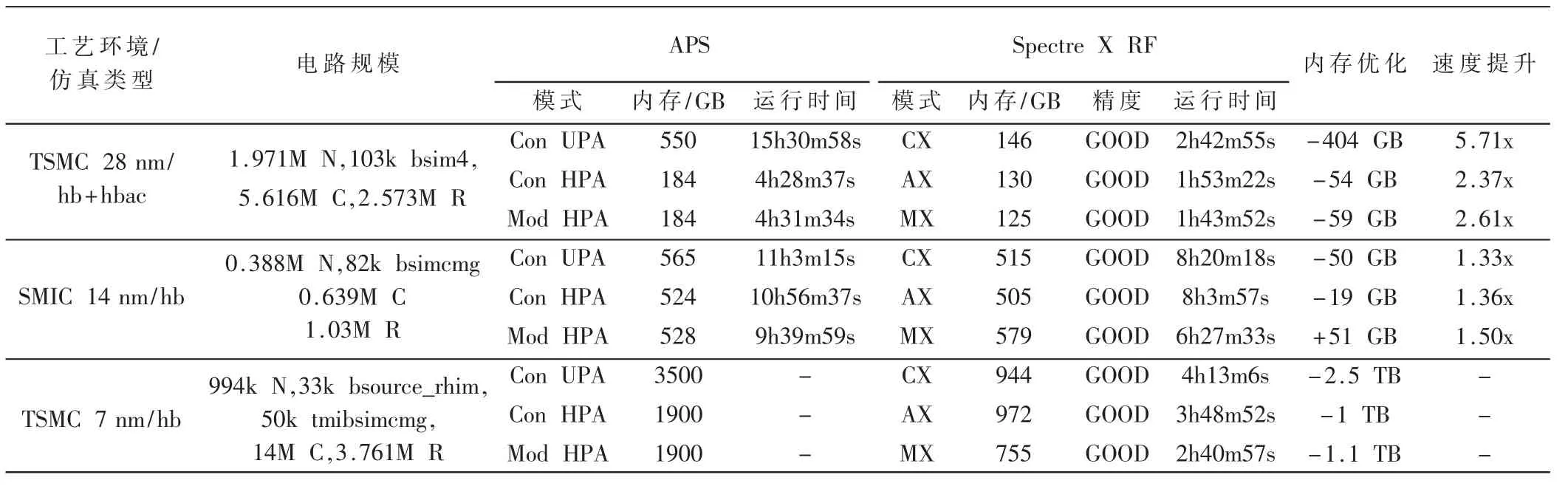
表5 各工藝仿真對比總結
4 結論
Spectre X RF 作為Cadence 推出的新一代RF 仿真器,默認使用方式相比于APS RF,更為簡單,從而使得電路工程師能更多的聚焦于電路設計。
應用于本文的模擬下變頻電路的仿真中,在TSMC 28 nm、SMIC 14 nm、TSMC 7 nm工藝環境中,內存與運行時間均有一定的優化。在小工藝TSMC 7 nm工藝中,內存與運行時間優化遠超預期。
Spectre X RF 還存在改進空間。另外,Spectre X RF支持的distributed HB 分析對大內存需求的multi-tone HB 仿真幫助很大,但因為時間以及其他原因,本文沒有進行太多的調查研究。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
山東冶金(2019年6期)2020-01-06 07:45:54
世界農藥(2019年2期)2019-07-13 05:55:12
電子制作(2018年11期)2018-08-04 03:25:42
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
