Mesh網絡中基于效用轉發的路由恢復算法
2021-08-23 04:00:08康巧琴
計算機工程與設計 2021年8期
康巧琴,袁 丁,嚴 清,楊 霞
(四川師范大學 計算機科學學院,四川 成都 610101)
0 引 言
無線Mesh網絡(wireless mesh networks,WMNs)[1,2]是一種特殊的Ad Hoc網絡[3],由于節點頻繁移動,內存和能量等資源的有限,以及基于節點自身的原因,導致網絡拓撲結構不斷變化。因此,提供高質量高效率通信的路由協議是確保網絡正確運行的關鍵。
WMNs路由協議的研究集中于:一方面考慮網絡節點的移動性,選擇最優的備選隊列和下一跳轉發節點;另一方面當網絡中的節點進行數據交互之后,利用網絡編碼和機會路由以及兩者的結合使節點獲得更多數據轉發的可能性,減少不必要的開銷。在此過程中,WMNs中的節點在進行數據轉發時,形成了WMNs特有的store-carry-and-forward通信模式。如Epidemic路由協議[4,5],即傳染路由,該路由協議的傳遞率相對來說較高,并且傳輸時延也較小;缺點是其適應性較差,并且傳遞較多的副本會消耗更多的網絡資源。Prophet路由協議[6,7],利用節點之間的歷史相遇情況,計算每個節點傳輸數據的概率大小,選擇概率相對較大的節點作為下一跳轉發節點,減少了數據包的重傳次數,因此減少了資源的浪費,但并不適用于大部分網絡環境。而Spray-And-Wait路由算法[8,9]可以降低消息在網絡中的復制份數;但是若節點數限制在較小的移動范圍內,或者節點之間有較強的關聯性,那么該路由協議的性能會有所下降。王博等[10]提出基于效用轉發的自適應機會路由方案(簡稱URD),利用節點之間歷史交互信息,計算節點的效用值并選擇效用值較大的節點作為下一跳轉發節點。優點是提高了數據包的轉發效率,減少了資源的消耗,不足之處是較適用于理想狀態,而在實際的網絡環境中,由于節點不斷移動,以及節點自身資源的有限,很難保證節點之間鏈路一直連通,尤其是在數據傳輸率較高的鏈路中,當網絡的拓撲結構發生變化時,該算法的性能有所下降。本文提出了一種基于效用轉發的路由快速恢復算法(簡稱URM),在計算效用值[11-14]時,考慮影響效用值的各因素所占的權重不同這一特點,動態獲取權重值,從而使算法能更好適應真實的網絡環境。同時綜合網絡時延,節點的效用值和節點對之間的跳數,選擇最優的下一跳轉發節點,減少了時延值的增加和資源的浪費。
1 效用轉發模型
1.1 模型假設
通常意義上的WMNs模型很難用以往的G=(V,>E)的形式來表示,其中V是網絡中節點的集合,E為邊集。節點的高速移動性,導致網絡拓撲結構不斷變化,節點與節點之間邊的連接不夠穩定。隨著節點之間不斷進行數據交互,節點之間存在著某種特定且相對穩定的社會關系和極強的規律性,而找到這樣的關系,對于路由協議的研究很有幫助。為了便于形象的描述本文的研究過程和分析,將做出如下的假設:
(1)G=(V,>E)為網絡的拓撲圖,由N個節點構成,其中V為網絡中的節點集合,E為定義在節點之間邊的集合。
(2)節點u,v∈V,當節點u,v之間進行數據傳輸時,鏈路eu,v∈E是雙向的。在復雜的網絡拓撲圖中,由于網絡環境的不同,在不同的時刻,鏈路eu,v處于不穩定狀態,隨時可能不連通。
(3)網絡拓撲由多個節點組成,分為不同的簇塊,每個簇塊有各自的割點和割邊,刪除了割點或者割邊,網絡拓撲則分為若干個不同的小的簇塊。
(4)每個節點的緩存空間大小是一樣的,每個簇塊內節點分配的個數也一樣。
1.2 模型的定義
圖1至圖3是某時刻的部分網絡拓撲圖,由4個簇塊組成,其中節點3,5,9,B分別作為各簇塊的割點,邊3-B,3-5,5-9和B-9作為簇塊之間的割邊。此時節點S要與節點D取得通信,則需要經過多個簇塊,經過多個節點的轉發。那么在節點不斷移動的情況下,下一跳轉發節點的選擇至關重要。

圖1 t1時刻

圖2 t2時刻

圖3 t3時刻
顯然,節點S和D之間沒有直接的連通通道。為了選擇合適的轉發節點,首先節點S在其所在的簇塊中,會將數據分組轉發給節點3,再將數據發送給節點B或節點5,最后將數據轉發給節點9,選擇節點3,5,9和B的原因是這些節點作為簇塊的割點。但是當前存在兩個問題:
第一,由于網絡中的節點在不斷地移動,各個簇塊中節點的位置不一定一直保持在原本的簇塊中,很有可能移動到其它的簇塊。比如以下的情況:
第一種情況。如圖2所示,節點3在第一個簇塊中時,若其將數據發送給位于第二個簇塊中的節點B,此時節點3移動到第二個簇塊中。這種情況下,對于下一步數據的轉發沒有很大影響,節點B將數據轉發給節點9即可,再將數據直接轉發給同一個簇塊的節點D,本次數據的第一次傳輸完成,此過程體現了機會網絡中的“存儲—攜帶—轉發”機制[15],如圖4所示。

圖4 節點間數據包的收發流程
第二種情況。如圖3所示,假如節點B和節點9移動至第三個簇塊中,節點A移動至第四個簇塊中,此時第四個簇塊沒有割點,而節點B在第三個簇塊中。節點B若要將數據轉發給目的節點,則需要重新尋找轉發節點,那么找到合適的轉發節點成為重點。
第二,利用簇塊之間的割點作為轉發節點,除了可以在某種程度上提高數據的轉發效率之外。一方面因為割點頻繁轉發數據,容易導致網絡擁塞,數據分組的丟失以及傳輸次數的增加;另一方面由于割點自身資源有限,導致其失效也極有可能。
綜上,利用節點之間數據轉發的歷史信息,從多角度定義節點與節點之間的效用值,并且結合時延開銷以及節點之間跳數的計算,選擇備選隊列以及最佳下一跳轉發節點。給出以下定義請參見文獻[10]。
定義1節點中心度,表示為CE(m)。
定義2節點頻繁度,表示為FP(m,n)。
定義3節點親密度,表示為CP(m,n)。
定義4節點新近度,表示為RP(m,n)。
定義5節點關聯度,表示為AP(m,n)。
定義6節點相似度,表示為Sim(m,n)。
定義7節點移動連通度,表示為MC(m)。
1.3 效用值各權重的確定
基于節點之間數據交互的歷史數據,令當前時刻節點m到達目的節點d的總體效用值U(m,>d)[10]的具體計算公式如下
U(m,d)=αAP(m,d)+βSim(m,d)+γ(CE(m)+MC(m))
(1)
上述公式中的α、β和γ是權重因子,并且α+β+γ=1。由于網絡不斷變化,惡意交互行為的存在,以及網絡自身因素帶來較大的誤差率,所以在不同時刻效用值的各參數所占的權重不同。顯然,0≤U(m,>d)≤1。當節點與節點之間第一次通信時,由于各節點之間沒有數據交互的歷史信息,節點結合自身簇塊內的中心度計算各自的效用值,即α=β=0,γ=1;隨著節點之間不斷通信,增加關聯度的計算;一段時間過后,節點之間的通信有了一定的規律,節點的利用率也更大,形成更有效的通信數據,增加節點的相似度和移動連通度的計算。此外,考慮受到節點自身網絡資源以及網絡拓撲動態變化等因素的影響,設置無法正常工作的節點效用值為0。
為了體現效用值計算的主觀性,在確定3個權重系數時,由于中心度用于描述一個簇塊內節點之間的聯通程度,不能說明簇塊之間節點的聯通性;關聯度描述需要進行數據交互的節點之間的聯通程度,而并未說明沒有進行數據交互的節點之間的聯通程度,因此無法完整地體現網絡的穩定性能;移動連通度描述網絡動態變化的程度,增加或者減少的節點越多,說明節點轉發數據的可能性越大,但網絡的穩定性越不好;而相似度描述兩個節點之間通信的公有鄰居節點集,相似度越高,則說明節點進行下一次數據傳輸經過公有節點的概率越大。
綜上,相似度不僅描述了節點的社會屬性[16,17],而且能逐漸區分出節點之間相互合作性能的高低,以及節點之間通信鏈路穩定性能的高低,從而在效用值的計算中,相似度對效用值的貢獻相對較大。在不同的情況下,節點之間的接觸頻率和連接時間各不相同,節點會偏重不同的社會屬性度量和效用值。為了使計算的結果更加符合實際的網絡環境,考慮假設β=1/3,然后利用不同節點對中心度,移動連通度和關聯度的偏重程度來動態確定α和γ。具體計算過程如下
α=AP(m,d)*(1-β)/AP(m,d)+(CE(m)+MC(m))
(2)
γ=(CE(m)+MC(m))*(1-β)/AP(m,d)+ (CE(m)+MC(m))
(3)
2 URM路由算法
在WMNs網絡中,根據節點之間的歷史交互信息,實時收集節點的移動情況并且更新節點本地的數據信息,結合節點自身緩存中的數據,從而計算各節點的效用值和時延值。URM路由算法包括3個部分:節點本地緩存的更新,節點的效用值、時延值的計算以及數據分組的轉發。
第一個部分,節點本地緩存的更新。節點第一次通信,需要向所有鄰居節點廣播Hello數據包,在有效的TTL時間內,如果收到鄰居節點的Response包,那么說明該鄰居節點是有效的;同時在Response包中,包括鄰居節點的私有信息,當前節點就將鄰居節點的信息添加到自己的本地緩存中;若不是第一次通信,則當鄰居節點位置發生改變時,當前節點需要更新鄰居節點的位置信息。在下次轉發數據時,直接查找當前節點的本地緩存,減少不必要的時延開銷。因此在當前節點收到的數據包中,鄰居節點私有信息的獲取,將成為當前節點進行第一次的通信最主要的依據。
第二個部分,節點的效用值、時延值的計算。在數據包的轉發過程中,主要包括兩個部分,一是備選隊列的選擇,一是下一跳轉發節點的選擇。本文主要考慮3個方面:節點轉發數據的時延值,效用值以及跳數的計算。其中,時延值的計算包括節點在等待通信鏈路處于空閑狀態的時間,鏈路處于擁擠狀態的時間以及節點在進行通信時的預熱時間。在本地緩存中,節點會記錄當前節點與其它節點之間的跳數,如果兩個消息的跳數都小于或者大于閾值,則選擇跳數較小的節點作為轉發節點;若其中一個的跳數小于閾值,另一個的跳數大于閾值,則選擇跳數小于閾值的節點。
如算法1所示,在計算節點之間的效用值時,由于在不同時刻下節點的位置和通信情況不同,所以節點參數的取值是一個動態變量。利用本地緩存中的數據,動態計算參數的值,使之更符合實際情況。
算法1:UtilityComputing Algorithm
//計算節點m與鄰居節點d之間的效用值
(1)if 節點之間首次通信,節點m沒有與節點d的歷史交互信息
(2)//計算節點的中心度
(3)節點m利用其所在的簇塊中與其它節點的聯通程度計算節點的中心度CE(m)
(4)在周期時間T內,節點獲取當前簇塊內的歷史信息
(5)if 沒有與節點d相關的數據交互信息 then
(6){
(7) AP(m,>d)←0
(8) Sim(m,>d)←0
(9) MC(m,>d)←0
(10)}
(11)else 節點m有與節點d的歷史數據交互信息
(12){
(13) //(1)計算節點m和d之間的關聯度[10]
(14) 獲取節點m與節點d最近一次建立連接的時間,計算節點m和節點d的關聯度AP(m,>d)
(15) AP(m,>d)←FP(m,>d)+CP(m,>d)+RP(m,>d)
(16) //(2)計算節點m與d的移動連通度
(17) 獲取本地緩存中該周期時間T內,鄰居節點表的數據,計算節點m與節點d的移動連通度MC(m)
(18) //(3)計算節點m與d的相似度
(19) 獲取本地緩存中節點m與節點d的公有鄰居節點集,得出公有鄰居節點數,計算節點m與節點d的相似度Sim(m,>d)
(20) //(4)計算節點的效用值U(m,>d)
(21) if 節點m與節點d之間是第一次通信
(22) {
(23) U(m,>d)←CE(m)
(24) }
(25) else
(26) {
(27) 令β=1/3
(28) 利用上述計算的節點的關聯度,中心度和移動連通度,計算α和γ
(29)α←AP(m,d)*(1-β)/AP(m,d)+(CE(m)+MC(m))
(30)γ←(CE(m)+MC(m))*(1-β)/AP(m,d)+(CE(m)+MC(m))
(31) U(m,d)←αAP(m,d)+βSim(m,d)+γ(CE(m,d)+MC(m,d))
(32) end if
(33) }
(34) end if
(35) }
第三個部分,數據分組的轉發。首先利用節點之間的跳數和效用值來選擇備選隊列,再利用節點數據轉發的時延值、效用值和跳數選擇下一跳轉發節點。具體如算法2所示:
算法2:DataForwarding Algorithm
(1)獲取節點本地緩存的數據,包括節點在等待通信鏈路的時間,鏈路處于擁擠狀態的時間和節點間通信之前的預熱時間。
(2)計算節點總的時延值
總的時延值=等待通信鏈路的時間+鏈路處于擁擠狀態的時間+節點通信之前的預熱時間
(3)按照節點的跳數和效用值對鄰居節點進行排序
(4)比較節點的時延值、效用值和跳數的大小。
(5)在當前的鄰居節點的隊列中,綜合3個因素,選擇最優的節點作為下一跳轉發節點。
3 仿真實驗與分析
3.1 仿真環境的建立
本文使用ONE仿真(opportunistic network environment simulator)[18]模擬系統作為本次模擬的實驗平臺。ONE是芬蘭赫爾辛基大學用Java編寫的開源軟件,是一個機會網絡環境模擬器,現在最多的將其應用于時延容忍網絡模擬網絡的真實工作情況。
基于以上的實驗環境,做出平臺中的某些參數的假設,見表1。

表1 實驗平臺的參數設置
3.2 實驗參數
對于實驗中所用到的對比參數:節點的平均占用率、節點之間轉發數據的平均跳數、端到端的平均時延、節點預測數據包傳遞的可能性以及數據分組收發的成功率,進行如下的說明:
(1)平均緩存占用率(average node cache utilization):節點所利用的緩存大小與總的緩存空間之間的平均比值;
(2)數據轉發的平均跳數(average hot count):節點之間保持數據交互的平均跳數,跳數越少,說明當前節點所對應的鄰居節點作為下一跳的幾率更大,并且所花的時間越少;
(3)端到端的平均時延[10](average end-to-end delay):節點之間通信的平均時間;
(4)數據包轉發的平均可能性(average probability of packet forwarding):預測節點作為下一跳轉發節點傳輸數據的可能性;
(5)數據包收發的平均成功率(the transceiver success rate of data packets):發送的數據包的數量和接收到的數據包數量的比例。
3.3 仿真實驗結果分析
3.3.1 不同路由協議的對比
本文選擇隨機路徑移動模型(random waypoint movement modal,RWP)作為節點的移動方式,并進行對比分析:
(1)平均緩存占用率
由圖5可知,隨著仿真時間的增加,5種協議的節點緩存占用率都在不斷增加。比較而言,URD和URM協議的緩存占用率相對較低,并且URM的節點緩存占用率的增加相對趨于平穩。Epidemic和Spray-And-Wait協議相對較高,前者以洪泛的方式,只要有機會,就將數據轉發給鄰居節點,因此產生太多消息副本,占用了較大的存儲空間;而后者則是折半將數據發送給鄰居節點,緩存占用率相比Epidemic較低。Prophet、URD和URM協議都是利用了節點之間數據交互的歷史信息,緩存占用率相對較低。Prophet協議是以計算節點投遞數據的概率,選擇概率較高的節點發送數據;URD協議是計算節點的效用值,選擇效用值較大的節點發送數據;而URM協議綜合節點的效用值、時延和跳數,選擇最優的節點轉發數據,從而URM的緩存占用率最小。此外,在RWP移動模式下,節點隨機移動,每隔一定的時間,節點更新本地緩存中鄰居節點的信息,包括節點的效用值、時延值和跳數等,因此URM的節點緩存占用率增加趨于平穩。
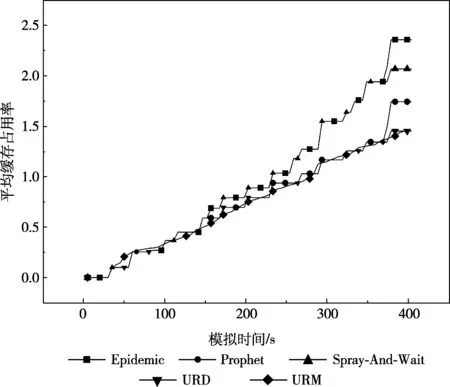
圖5 5種協議的緩存占用率
(2)數據傳輸的平均跳數、轉發的可能性、收發成功概率、端到端的平均時延
由圖6表示數據傳輸的平均跳數、轉發的可能性、收發成功概率、端到端的平均時延可知,對于平均跳數,URM和URD協議相比于其它協議較少,并且兩者相近。Epidemic采用洪泛機制,將數據轉發給所有節點,當一個節點獲得數據,依次轉發給下一個節點,因此跳數最高。而URM和URD協議的收斂性主要是基于鄰居節點的效用值,通過移動連通度和相似度可知網絡的聯通性能和節點之間合作性能的高低,從而在不受到局部性影響的RWP移動模型下,節點之間的跳數相對較低。Prophet和Spray-And-Wait協議居于中間。

圖6 平均跳數、轉發的可能性、成功概率、平均時延
對于數據傳輸的可能性和成功概率,由于節點隨機選擇移動方向、速度和目的地,導致節點相遇概率低,消息的傳輸總數較少,并且使得大多數消息在TTL生存時間內未到達目的地而被丟棄,因此傳輸的可能性和成功概率較低。而URD和URM在轉發數據包時,利用節點本地緩存的歷史數據計算節點的效用值,有效地預測了節點間相遇的可能性,因此稍高于其它3種協議。而URM利用動態獲取影響效用值的參數來計算效用值,更接近于真實的網絡,所以稍高于URD協議。
對于數據傳輸的平均時延,由于場景中節點比較密集,并且在RWP移動模型下,節點相遇的概率較低,因此對于多拷貝方式的Prophet、Epidemic和Spray-And-Wait來說,每次傳輸數據時,都需要通過更多次數據的拷貝,增加了時延開銷。而URD和URM協議基于歷史信息來預測節點之間相遇的可能性,以及計算移動連通度和相似度時,更容易看出網絡的聯通性和節點之間的相互協作性能的高低,因此在一定程度上大大減少了時延開銷。其中URM根據歷史信息動態計算效用值,使結果更貼近于實際,所以較低于URD協議。
3.3.2 網絡中節點的移動方式不同
本文利用4種不同的移動模型來進行模擬,分別是Random Walk(隨機移動模型)、Shortest Path Map Based Movement(基于地圖的最短路徑移動模型)、Map Based Movement(基于地圖的移動模型)、Car Movement(汽車移動模型)。為了更加說明算法的有效性,以下通過消息傳輸的平均時延和數據包收發的平均成功率來進行描述:
由圖7表示不同移動模型下基于URM算法,數據包收發的平均成功率和平均時延值,圖8表示不同移動模型下不同路由協議的平均時延值可知,基于不同的移動模型下,URM路由算法無論是在哪種移動模型下,與上述節點之間數據包收發的平均成功率的數據分析圖相比,可以看出URM的數據包收發的平均成功率都是較大的。說明在不同的網絡環境下,基于節點間通信的歷史數據,動態計算效用值,在一定程度上減小了誤差,URM協議對實際網絡環境的適應性,相對于其它幾種協議來說較好。基于不同的移動模型,對比于上述節點之間進行數據轉發的平均時延值的數據分析圖,可以看出URM路由算法的平均時延值較小。URM路由算法的時延主要是在節點之間進行數據轉發的過程中消耗的,而由于選擇同一節點作為下一跳轉發節點的概率更大,因此消耗的時間減少。此外,由于不需要獲取新的節點的數據信息,減少了獲取信息的時延值。因此總體上相較于其它路由協議,URM路由算法的時延值最小。
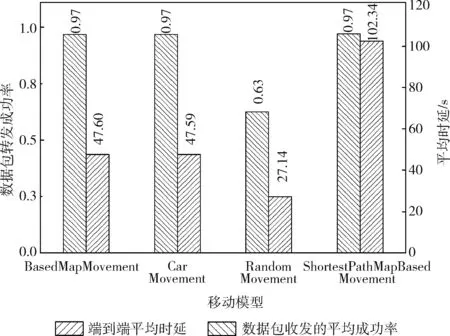
圖7 不同移動模型下基于URM算法,成功率和時延值

圖8 不同移動模型下不同路由協議的平均時延值
4 結束語
為了解決無線Mesh網絡由于節點的不斷移動,存在網絡拓撲結構動態變化、數據轉發時延增加、網絡資源浪費的問題,根據當前效用轉發的路由算法較適用于理想狀態的問題,提出基于效用轉發的路由快速恢復算法,利用節點間的歷史交互數據,動態獲取在不同網絡環境下,影響效用值的各因素所占權重值,從而使算法能更好適應真實的網絡環境。同時綜合網絡時延,節點效用值和節點間跳數,選擇最優的下一跳轉發節點,減少網絡中不必要的時延增加和資源浪費。ONE仿真結果表明,該算法能夠判斷網絡穩定性能的高低,提高數據包的轉發效率,減少網絡恢復的時延開銷,從而提升網絡的性能。在未來的工作中,將考慮通過結合網絡編碼和機會路由選擇更合適的轉發節點,進一步優化該協議的性能。
