情感子句預測與原因子句提取方法
2021-08-23 04:12:32陸丁天張志遠
計算機工程與設計 2021年8期
陸丁天,張志遠
(中國民航大學 計算機科學與技術學院,天津 300300)
0 引 言
近年來,文本情感分析引起學術界與工業界的研究興趣,對帶有各種情感色彩的評論文本進行情感分析具有很大的研究和應用價值[1]。
Zhang Y等[2]認為文本情感分析建模面臨的主要挑戰是如何捕捉文本的局部語義信息、情感依賴信息以及情感表達關鍵部分;于是提出CCLA模型,提取這3類信息特征并融合得到完整的句子特征進行情感分析。卷積神經網絡(CNN)更加關注局部特征,對文本情感分析的準確率有一定影響[3,4]。RNN能提取文本上下文語義信息,但其存在梯度爆炸和梯度消失問題,故常用LSTM來代替RNN進行文本情感分析任務[5-8]。然而LSTM是一個有偏模型,其更多注重句子末尾的詞,當關鍵詞不在句子末尾時,LSTM就無法很好捕獲句子語義信息來進行文本分類任務,于是又常用雙向的LSTM來代替單向的LSTM進行文本情感分析任務[9]。Bahdanau等[10]對Encoder-Decoder神經機器翻譯方式的改進引出了注意力機制。注意力機制是用來表示文本句子中的詞與輸出結果之間的相關性,表示句子中每個詞與句子相對應標簽之間的重要程度[11,12]。注意力機制與深度學習模型的結合大大提高了文本情感分析的效果[13]。
然而,知道情感傾向還需知道其產生的原因,因此目前相關研究重點正從日趨成熟的文本情感分析向挖掘文本情感的產生原因深入,即文本情感原因發現[14]。情感原因發現與抽取最早是由Lee等[15]提出。此后Gao K等[16]提出了基于規則的詞水平原因提取模型。基于詞水平的情感原因提取任務的語料庫構建需要大量復雜的標注,使得語料庫規模很小,無法為機器學習提供足夠信息。為此Gui等[17]使用新浪都市新聞建立了一個帶標注且以子句作為原因提取基本單元的語料庫,并提出了一種基于事件驅動的多核SVM情感原因提取方法。即使訓練集有限,仍然可以提取足夠的特征進行分析。Li X等[18]認為情感子句與原因子句之間有相互作用的關系,于是提出了一種基于多注意力的神經網絡模型(MANN)來捕捉情感分句與候選分句之間的相互關系。
傳統的情感原因提取需要預先標注情感標簽,該方式增加了人工成本,限制了情感原因提取任務在現實中的使用。為此Xia R等[19]提出情感-原因對提取方法Inter-EC,所提方法分兩步,先通過兩個子任務分別進行情感提取和原因提取,最后得到一個情感子句集合和原因子句集合;然后通過笛卡爾積將情感子句集和原因子句集構造成對,再訓練一個過濾器將沒有包含因果關系的情感-原因對剔除。此方法為情感原因提取任務的研究提供了一種思路。然而Inter-EC模型存在兩個問題:①在情感子句提取時,句子特征不完整,使得情感子句提取效果不夠好;②在原因提取時,情感和原因之間的聯系體現的不夠充分,使得原因提取效果不夠好。為此本文在Inter-EC模型的基礎上提出了一種基于注意力的情感子句預測與原因子句提取模型(emotion prediction & cause extraction model,EPCEM),實驗結果表明該模型具有不錯的效果。
1 方法描述
1.1 任務定義
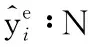
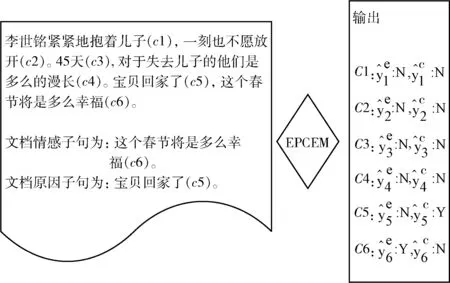
圖1 情感子句預測與原因子句提取任務示例
1.2 模型描述
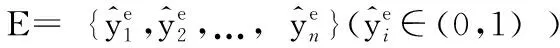

圖2 EPCEM模型
1.2.1 情感子句預測部分
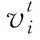
(1)
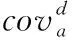
(2)
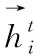
(3)
(4)

為獲得情感表達的關鍵部分,將Bi-LSTM的輸出作為注意力層的輸入。注意力機制的定義如下
(5)
(6)
(7)
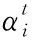
(8)
(9)
(10)
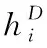
(11)
1.2.2 原因子句提取部分
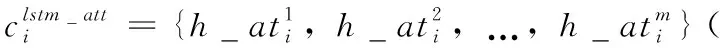
情感與原因之間是有聯系的,找到與情感信息相關聯的上下文語義信息是確定原因的先決條件,為找到與情感信息相關的原因信息,引入一種情感導向的注意力機制,該機制能夠對通過帶有注意力的詞水平Bi-LSTM獲得的句子特征進行加權表示,以獲得與情感相關的句子特征。情感引導的注意力機制的使用定義如下
(12)
(13)
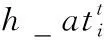
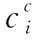
(14)
(15)
(16)
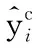
(17)
模型的損失函數由兩部分的交叉熵損失組成
LP=λLe+(1-λ)Lc
(18)
其中,Le為情感子句預測部分的交叉熵損失,Lc為原因子句提取部分的交叉熵損失,λ為權衡參數。
2 實 驗
2.1 數據集
本文使用情感原因分析ECPE數據集[19],數據集一共有1945篇文檔,每篇文檔由多個分句構成。數據統計信息見表1。模型訓練集大小與測試集大小的比例為9∶1。

表1 ECPE數據集統計信息
2.2 模型參數設置
使用word2vec預訓練好的微博語料庫詞向量,詞向量維度為300維。對于未登錄詞,采用均勻分布U(-0.01,0.01)來隨機初始化詞向量。CNN窗口大小為3和4,每個窗口過濾器數量為100。Bi-LSTM的隱藏層單元個數為100。模型訓練時,Adam優化算法的初始學習率為0.005,Batch大小為32,dropout為0.8,L2正則化的權重設置為10-5。
2.3 評價指標
評價指標實驗結果評估采用精確率p(Precision)、召回率r(Recall)和f1值來進行評估。定義如下
(19)
(20)
(21)
其中,correct_causes為原因子句預測標簽與真實標簽一致且為Y的數量;proposed_causes為原因子句預測標簽為Y的數量;annotated_causes為真實標簽為Y的原因子句數量。情感子句預測部分的評價指標與原因子句提取的評價指標相似。
2.4 實驗結果分析
2.4.1 不同詞向量表示
為了評估不同詞向量表示對模型的影響,使用不同的向量表示對模型進行評估。Rand200d:詞向量隨機初始化為200維;w2v200:通過Word2vec預訓練好的微博語料庫詞向量200維;Rand300d:詞向量隨機初始化為300維;w2v300:通過Word2vec預訓練好的微博語料庫詞向量300維。
不同詞向量表示對模型的影響見表2,在情感子句預測上,用預訓練好的微博語料庫詞向量得到的f1比隨機初始化方式得到的f1值高了近10%,其中300維的預訓練詞向量比200維的預訓練詞向量效果更好;在原因子句提取上,預訓練得到的f1值比隨機初始化得到的f1更是高出了10%。從而驗證,詞向量用隨機初始化的方式得到的結果較差;預訓練詞向量對句子特征表示是有效的,預訓練的詞向量能提高情感子句預測與原因子句提取的效果。
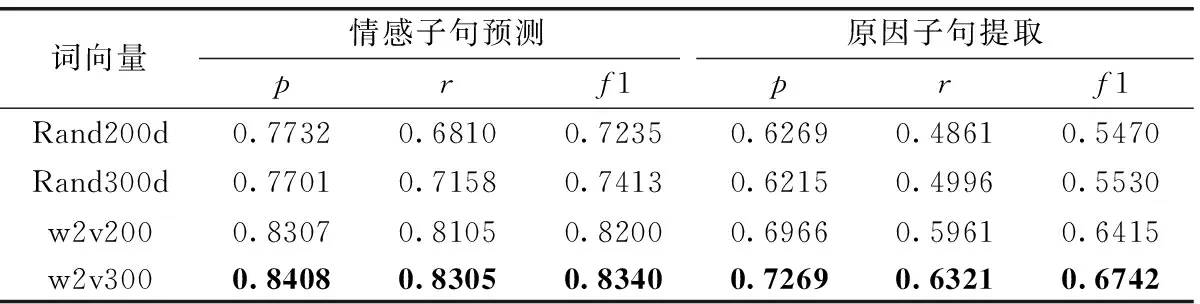
表2 不同詞向量表示對模型的影響
2.4.2 CNN窗口大小對模型的影響
目前大部分情感分類模型僅僅使用Bi-LSTM加上注意力來提取句子的上下文語義依賴信息和與情感相關的關鍵部分來進行情感分析。然而在進行情感分析時,一個完整的句子特征要包含局部語義信息、上下文語義依賴信息以及情感表達的關鍵部分。為驗證結論,在情感子句預測部分,模型提取句子特征時,進行了融入局部語義信息和不融入局部語義信息的實驗。實驗結果見表3,從表3中可以看出,在進行句子特征提取時,融入局部語義信息使句子特征更完整,能提高情感子句預測的效果,并且CNN窗口大小為{3,4}(注:表示窗口大小分別為3和4兩個過濾器)時,情感子句預測效果最好。
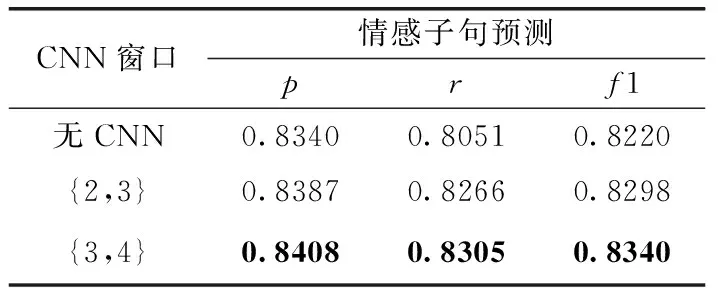
表3 CNN對情感子句預測的影響
2.4.3 情感子句預測標簽對原因子句提取的影響

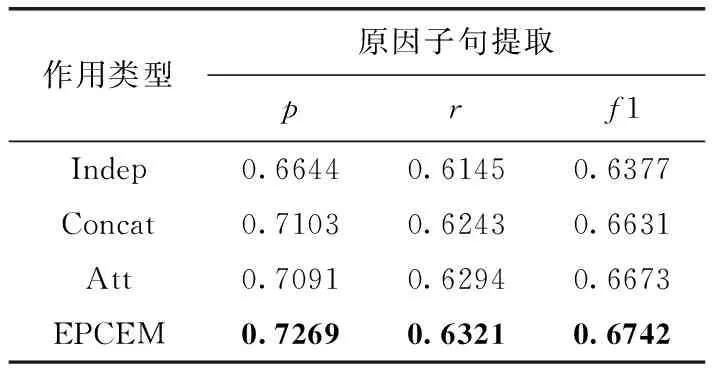
表4 消融實驗對原因提取的影響
從表4可以看出忽略情感與原因之間的關系,情感子句預測與原因子句獨立進行時,原因子句提取效果最差。在考慮情感與原因之間的關系后,通過Concat方式與Att方式將情感與原因聯系起來提高了原因子句提取的效果。通過Concat與Att結合的方式(即EPCEM)進一步增強了情感與原因之間的聯系,從而提高原因子句提取的效果。因此驗證了在進行原因子句提取時,考慮情感與原因的關系,將情感特征融入句子特征去進行原因子句提取能進一步提高原因提取的效果這一結論。
2.4.4 相同任務定義下的模型對比
相同任務定義是指在未給定文檔情感標簽的情況下,找出文檔情感子句,并提取相應的原因子句。目前在此任務定義下的模型僅為文獻[19]的Inter-EC模型。本文模型與Inter-EC模型對比結果見表5。從表中可以看出,在情感子句預測上,本文模型的f1值比Inter-EC模型的f1值高出了1.1%,這是因為本文模型在進行情感子句預測時考慮了局部語義信息,使得句子特征更完整,從而提高了情感子句預測的效果。在原因子句提取效果上,本文模型得到的f1值比Inter-EC模型得到的高出了2.35%,原因在于本文模型使用了情感導向注意力,使得情感與原因更相關,從而提高了原因子句提取的效果。

表5 相同任務定義的模型對比
2.4.5 與傳統的原因提取任務模型對比
傳統的情感原因提取任務ECE(emotion cause extraction)是指在標注好情感信息后,提取引起情感信息的潛在原因,需要在測試集中對文本情感信息進行標注。而本文的情感原因提取任務是預測情感信息,并提取引起情感信息的原因。對比結果見表6,其中:
RB:手工定義語義規則方法[15]。
CB:基于常識定義的方法[17]。
RB+CB+ML:RB與CB結合并通過機器學習SVM分類訓練。
SVM:使用1-grams、2-grams和3-grams作為特征通過SVM分類器進行分類[17]。
CNN:使用CNN提取候選子句和已確定的情感子句的特征進行情感原因提取[18]。
MANN:基于多注意力的上下文情感原因分析神經網絡模型[18]。
從表6可以看出,即使在測試集中沒有對文檔進行情感信息標注,所取得結果仍然優于大部分傳統模型,僅次于MANN模型,這是由于MANN模型是預先標注好情感標簽的原因提取,而本文模型是預測情感標簽后再去提取原因,預測情感標簽的效果會影響到原因提取的效果。
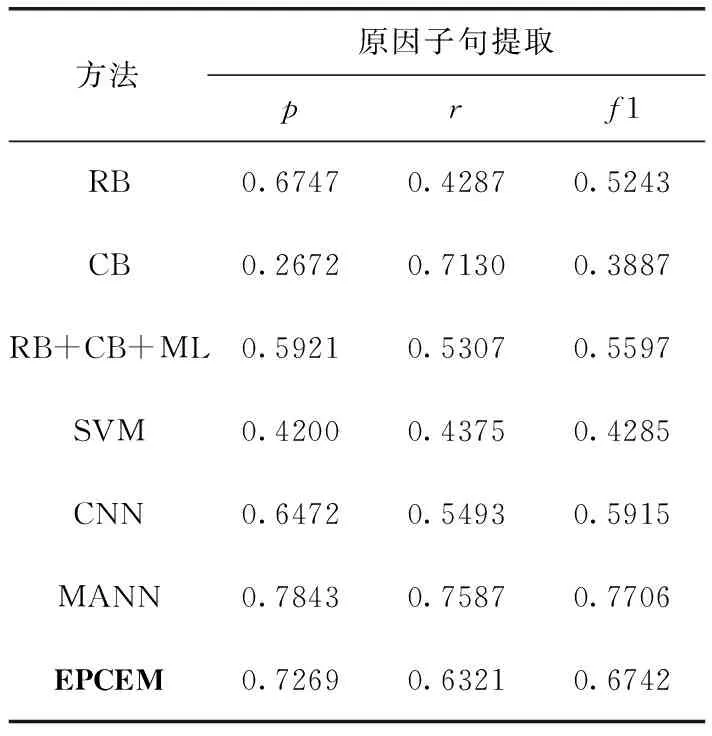
表6 與傳統情感原因提取任務方法比較
3 結束語
本文提出了一種基于注意力的情感子句預測與原因子句提取方法,與傳統的情感原因提取方法的不同之處在于該方法不需要預先對文本進行情感標注,在未給定情感標簽的情況下,在預測文本情感的同時匹配其對應的原因。該方法節約了人工標注的成本,擴大了情感原因提取任務在現實中的應用范圍。
實驗結果表明,在預測情感子句時,一個完整的句子特征需要包括局部語義信息、上下文語義依賴信息以及情感表達的關鍵部分。在進行原因子句提取時,融入預測的情感信息能更好提高原因子句提取的準確率,且通過注意力的方式的融合使原因子句提取的準確率有更進一步的提高。
猜你喜歡
中國生殖健康(2020年5期)2021-01-18 02:59:48
開放教育研究(2020年2期)2020-03-31 01:54:14
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
