基于融合句法特征的翻譯方法研究
2021-08-20 10:28:58劉晶
電子設計工程 2021年16期
劉晶
(陜西鐵路工程職業技術學院,陜西渭南 714000)
機器翻譯以高性能的計算機作為運算核心來實現不同自然語言之間的轉換,在人工智能與機器學習領域中占據了較大的比重[1]。目前較為常見的機器翻譯應用場景為一些互聯網公司(百度、谷歌、有道等)提供的在線翻譯服務,這些服務均可實現多種語言間的相互粗糙翻譯。雖然這些翻譯結果與翻譯從業人員的翻譯結果相比仍有差距,但在翻譯質量要求較低的場景下,仍有較為廣泛的使用價值。
到目前為止,機器翻譯技術已經發展了幾十年。雖然不斷推出了各種算法模型,但機器翻譯準確程度仍較低,無法替代專業譯員。其中,最突出的問題為單詞較多、句型結構復雜的長句、從句翻譯效果較差[2]。在英語中,長句的結構成分較為復雜,除了主要的句子結構外還有各種修飾詞、連接詞等。此外,長句還可能會包含有一個以上的從句。從句之間的關系也有嵌套、并列及平行等組成方式,所以句法分析是長句翻譯的必要前提[3]。因此,對長句和難句進行句法分析預處理是提高長句翻譯質量的有效解決方式之一。
文中針對英漢機器翻譯的長句翻譯質量較差的問題,對長句進行算法訓練與處理,將其分離成易翻譯的短句進行組合翻譯,進而提高機器翻譯的質量。
1 英漢句法翻譯方法
基于句法分析的機器翻譯方法在機器語言翻譯領域占據著重要地位,句法分析主要是對整個句子序列的成分結構進行分析。而機器會與句法庫中的句式結構進行比較,進而對長句的句法進行判斷后再進行翻譯。機器翻譯的最終目標是將源語言翻譯成為高質量的譯文,雖然對句子進行句法分析不是機器翻譯的最終目的,但是句法分析卻影響著機器翻譯的質量。因此,句法特征分析也是諸多專家與學者極為關注的一項技術,近幾年提出了眾多關于句法分析的理論方法[4-6]。
目前,句法分析翻譯方法大體可以分為兩類:基于語言模板的翻譯方法與基于統計學的翻譯方法。
基于語言模板的翻譯方法是最早關于語法翻譯的技術方法,語言模板是指句子的表面特征,比如:根據句子的單詞數量、句子標點的位置、句子所擁有的特征詞匯等進行模板匹配,并在語料庫中進行準確度匹配進而實現句子的翻譯。基于語言模板翻譯方法的優點是在句子模板特征較強時翻譯最為準確,其不足之處是句子模板特征較弱時翻譯不準確甚至無法進行翻譯。
為了對基于語言模板的翻譯方法進行改進,各地學者均進行了深入的研究[7-11],逐漸演變成為基于統計學的翻譯方法。該方法可以使用機器學習的方法,對句子的弱特征進行大量的數據挖掘與特征學習,例如對長句的連詞特征、句式特征及標點使用特征進行學習,這可以彌補模板匹配翻譯方法中對句子特征匹配不全的缺陷。但基于統計學的方法也有自身的局限性,例如雖然在長句中可以通過挖掘句中逗號、連詞、特殊句式之間的聯系等處理方法解決基于規則方法的語言現象覆蓋度不足的問題。但若句子本身標點符號或連接詞數量較少,則基于統計學翻譯方法的準確率也會下降。
因此,文中結合基于語言模板的翻譯方法與基于統計學的翻譯方法,提出了融合句法特征的機器翻譯方法。
2 基于融合句法特征的翻譯方法
2.1 句法特征模型建立
句法特征方法也稱為依存句法分析或從屬關系文法,其關注的對象是長句中各個單詞之間的聯系。在英文語法中,句子成分關系常見的有主謂關系、動賓關系、并列關系等。而在一個句子中,動詞一般被看作是句子中的核心詞,該句中的其他詞與核心詞均有直接或間接的關系[12]。
而對一個句子進行句法特征分析,分析過程通常使用一個有向圖進行表示,如圖1 所示。句子中的單詞為一個個單獨的節點,核心詞與依存詞的句法關系使用有向的箭頭進行標示,在箭頭的上方對其關系進行說明。

圖1 句法特征有向圖模型
而在文中所提出的句法特征模型中,其是按照單元進行存儲,下面將建立句法特征單元模型。該模型直接將單詞之間的句法關系存儲到相應的句法單元中,單元構建規則如下:
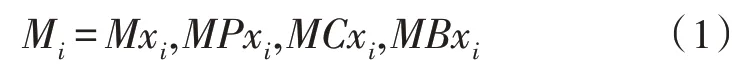
式(1)中,Mi表示句子中第i個單詞的存儲句法單元,MPxi、MCxi、MBxi表示句子中第i個父節點單詞、子節點單詞及相鄰節點單詞的位置。
雖然句法特征模型可以對句子成分進行判斷,構建的翻譯模型也可達到較優的正確率。但由于模型本身的局限性,該模型不能夠較優地學習句子的弱特征。因此仍需要在句法特征的基礎上加入統計學的模型,以強化長句中各個單詞的詞義聯系,從而進一步生成正確的結果。
2.2 基于條件隨機場的統計學模型
在對長句進行切割的過程中,并不是任意長句均可被切分成為適當的短句。只有當切分出來的句子擁有獨立的句法特征結構,才會認為對長句的切分是有意義的。因此,文中引入了條件隨機場模型對長句中的詞匯與逗號進行有意義的切分。在條件隨機場的模型中,所有語料應適當的被其訓練,進而判斷語料集中的句子分割是否具有合理性。
條件隨機場的從屬分類為無向圖模型,該模型具有最大熵與隱性馬爾科夫鏈的特征,該統計學模型在自然語言處理領域中的應用較為廣泛。其可將條件隨機場定義為一個條件概率事件,用X代表觀測序列集條件,用Y代表標記序列集條件,則條件隨機場模型可以用條件概率P(Y|X)表示。下面根據統計數學模型對條件隨機場進行定義[13-14]。
條件隨機場的數學定義為:假設某無向圖為T(V,E),其中V為各項頂點的集合,E為各邊的集合。假設Y={Yv|v∈V},即頂點集合中的每一項單獨元素均會有一變量Yv。設X為可滿足Yv的條件,則變量Yv可以滿足下式:

其中,u、v表示包含在圖T中的兩個頂點,則(X,Y)為一個條件隨機場。該隨機場的示意圖如圖2所示。

圖2 隨機場的示意圖
而目前條件隨機場模型的實現工具有多種,文中使用CRF 工具實現句子的標注及切分。
2.3 融合模型建立
由上文可知,基于句法特征的模型無法對句子的弱特征進行學習。因此,文中結合基于語言模板的翻譯方法與基于統計學的翻譯方法,建立基于融合句法特征的翻譯模型。該模型可強化長句中各個單詞的詞義聯系,進一步提升長句切割后的翻譯質量。兩種簡單模型的結合方式使用并列執行的方式,即基于句法特征對句子進行分析;基于條件隨機場對句子進行分析,進而得到兩種長句切分方式。然后對這兩種方式進行融合,融合方法包括合并、去重等。最終,在翻譯引擎中進行翻譯。模型的處理流程圖如圖3 所示。

圖3 融合模型執行過程
圖3 中,在使用融合句法特征模型進行句子切分前,首先要對條件隨機場模型進行訓練。模型訓練過程如下:
1)選取語料集合并進行預處理,對語料中的句子進行前處理,包括重復句子的去除、句子特殊符號的去除等;
2)對語料集合中的句子進行特征提取,此時使用句法特征濾波器對句子進行成分分析與依存有向圖的建立,隨即完成對句子特征進行提取;
3)將句子特征輸入至條件隨機場模型中進行訓練即可。
在模型訓練完畢后,預處理模塊中條件隨機場的訓練結果,會輸入至分割過程中的條件隨機場解碼器中進行解碼。同時與使用句法特征處理的句子進行比較處理,完成合并、去重等操作,最終將處理好的句子送入翻譯模型進行翻譯。
2.4 模型訓練過程
文中模型訓練腳本語言使用Python 編寫,作為一種面向對象的編程語言,Python 以其簡單、高效的特點被廣泛應用于機器翻譯與腳本語言中。相對于Java 或C++等語言而言,Python 效率更高,可以與其他語言編寫的模塊相結合。同時擁有豐富的第三方功能庫,能夠適應于多種編程需求。訓練腳本的代碼執行過程,如圖4 所示。

圖4 代碼執行過程
圖4中,第一行命令為依賴項的安裝,包括Python版本的設置、模型的路徑設置及訓練模型的版本設置等。第二行命令為執行Fenge.py 腳本,該腳本的輸入為語料集合,輸出為長句切割后的準確率與召回率,同時將切割完畢的句子輸出到下一條命令中。第3 條命令為執行Test.py 腳本,該腳本執行翻譯引擎,對句子進行翻譯,同時使用典型的翻譯評價標準(BLEU 與NIST 分數)對句子的翻譯質量進行評估。
文中訓練腳本使用到的硬件設備列表,如表1所示。

表1 模型訓練環境
3 實驗仿真與結果分析
3.1 模型預訓練
由上文可知,在檢驗模型翻譯質量前,首先要對條件隨機場模型進行訓練。在自然語言處理領域,國際計算語言學協會年會(ACL)是該領域的國際頂級會議,而每年ACL 會議在官方網站會發布用于機器翻譯的訓練集。文中選擇ACL2019 發布的新聞類型長句“News Crawl:articles from 2017”英語訓練集作為訓練語料集。為了更優地訓練條件隨機場模型,在語料集中仍要繼續進行抽取。使用文中模型的目的是提高長句翻譯質量,因此語句抽取規則為單詞數量大于或等于15,每句逗號數量大于或等于1。則文中訓練語料集,如表2 所示。

表2 訓練集信息
3.2 模型訓練結果
文中實驗需要解決如下兩個問題:
1)對長句進行切分處理后,使用模型還原切分前的長句,以驗證模型切分的準確性;
2)對長句處理完成后,使用文中建立的模型訓練,然后再對句子進行翻譯,觀察長句翻譯質量是否有提高。
因此,文中首先驗證長句,再進行合理切分,最終從上文提及的語料集中抽取了3 000 個長句進行訓練。實驗步驟如下:
1)使用句法分析工具對語料集中的長句進行句子特征提取;
2)刪除長句中的逗號后,使用文中模型對句子、逗號進行重新添加,進而對比插入位置的準確率。表3 為切分合理性實驗結果。

表3 句子切分實驗結果
由表3 實驗結果可以看出,使用條件隨機場方法與使用融合句法方法對句子進行切分的準確率是大致相同的。但融合句法特征方法的召回率更高,這充分證明了融合句法特征方法對句子切分的合理性。
下面進行翻譯準確度實驗,對長句處理后,使用文中建立的模型訓練,再對句子進行翻譯,觀察長句翻譯質量是否有提高。實驗使用Moses 作為翻譯引擎[15],Moses 翻譯引擎在使用前基于100 萬個英語平行語料進行訓練。翻譯質量使用BLEU 與NIST[16]譯文評價指標進行打分。BLEU 標準是用來評價機器翻譯結果與人工翻譯結果的相近程度,該標準使用便捷,比較接近人類的評分;NIST 標準是美國國標局建立的機器翻譯自動評價體系。BLEU 與NIST 譯文評價標準現已成為國際通用譯文評價系統,因此文中使用BLEU 與NIST 對模型翻譯質量進行評估。實驗測試結果如表4 所示。

表4 翻譯準確度試驗結果
實驗結果表明,文中提出的融合句法特征的翻譯方法對翻譯質量有大幅度的提升,BLEU 分數較單一地使用基于句法特征的模型與基于條件隨機場模型更高,同時NIST 分數也有所提高。因此,文中提出基于融合句法特征的翻譯方法對長句翻譯質量有一定程度的提升。
4 結束語
文中針對英漢機器翻譯的長句翻譯質量較差的問題,提出了融合句法特征的機器翻譯方法。對長句進行算法訓練與處理,將其分離為易翻譯的短句進行組合翻譯。在實驗測試中,對經過模型訓練的句子進行翻譯。實驗結果表明,句子的BLEU 與NIST 值均有不同程度的提高,因此文中提出的模型對機器翻譯的翻譯質量有一定程度的提升。
猜你喜歡
中華詩詞(2021年3期)2021-12-31 08:07:22
大連民族大學學報(2021年2期)2021-07-16 05:41:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中華詩詞(2018年3期)2018-08-01 06:40:40
中華詩詞(2018年11期)2018-03-26 06:41:32
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
