子域適應無監督軸承故障診斷
2021-08-11 11:56:26吳靜然劉建華
振動與沖擊 2021年15期
吳靜然,劉建華,崔 冉
(1.中國礦業大學 信息與控制工程學院,江蘇 徐州 221008;2.中國礦業大學 徐海學院,江蘇 徐州 221008)
滾動軸承作為旋轉機械設備減少各部件間摩擦的重要組成部分,廣泛應用于現代機械設備中。然而在惡劣環境下工作,滾動軸承易遭受磨損,故障率較高。準確識別軸承的故障,判斷故障類型,可以有效指導維修工作,提高維修效率,提高機械設備的可靠性和安全性,減少經濟損失,保護工作人員的人身安全[1-2]。
隨著智能制造技術的快速發展,基于滾動軸承振動信號分析的方法成為研究熱門。傳統的方法主要通過頻譜分析、時頻域變換分析進行特征提取,利用K近鄰、人工神經網絡、支持向量機、隨機森林構建分類器進行故障診斷識別[3-5]。特征提取過程依賴于專家知識和人工經驗,通過頻譜分析或從振動信號中提取統計特征,無法從原始的振動信號中挖掘出有效的故障特征,獲得的診斷模型結構簡單,無法應用于大容量高維數據。當工況發生變化后,診斷準確率降低。
鑒于深度學習能夠從輸入的數據中自動學習特征,基于卷積神經網絡(convolutional neural network, CNN)的端到端故障軸承診斷方法[6-7]被廣泛應用。然而大多數研究要求訓練樣本和測試樣本具有相同特征空間、概率分布和大量的可用標簽。考慮到實際工況改變時,收集的故障數據分布會隨之改變,大部分數據沒有標簽;同時由于設備故障很難發生,很難收集足夠的信息來反映完整的健康狀態。利用現有大量標記數據進行無標簽變工況下的軸承故障診斷變得非常重要。
無監督領域適應(unsupervised domain adaptation, UDA)作為遷移學習的分支,能夠探索領域不變特征,彌合領域間分布差異。鑒于UDA在圖像處理領域的廣泛應用,UDA也被廣泛應用于跨領域故障診斷。文獻[8]以深度學習為主要結構,通過最小化多核最大均值差異,減少卷積網絡的多層特征分布差異,提取域不變特征,實現滾動軸承故障診斷。文獻[9]采用對抗域自適應學習策略,提出了一種機器故障診斷網絡,該網絡學習通用的域不變特征,有助于增強特征表示的魯棒性,提高訓練模型的泛化能力。文獻[10]提出一種跨設備故障診斷模型,采用卷積神經網絡提取數據特征,使用最大均值差異和域對抗減少源域和目標域全局分布。雖然上述方法取得了較好的效果,但是僅僅試圖進行全局對齊,未考慮源域和目標域間的關系,可能會丟失每個類別的細粒度信息。如圖1(a)所示,全局域適應后,生成的源域和目標域空間的特征基本一致,但是子域間數據過分接近,分類正確率低[11]。
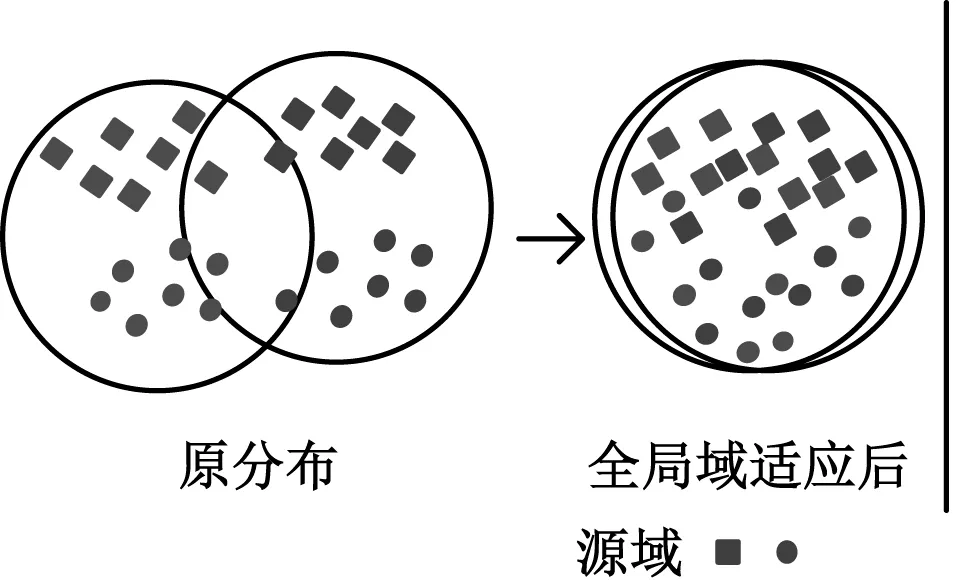
(a)全局域適應
為了解決上述問題,本文提出了一維卷積子域適應網絡(subdomain adaptation networks,SDAN)進行準確的無監督故障診斷。該網絡包括特征提取器和健康狀態分類器,特征提取器用于處理原始故障數據,進而獲得故障診斷分類特征。引入局部最大平均偏差(local maximum mean discrepancy, LMMD)[11]來度量源域和目標域數據嵌入相關子域的差異,調整相關子域同一類別下的分布,捕獲每個類別的細粒度信息,實現子域對齊。經過子域適應后,局部分布近似相同,全局分布也近似相同,如圖1(b)所示。使用江南大學JNU軸承故障數據集進行該方法的有效性驗證,與現有5種領域自適應算法進行對比,SDAN網絡具有更好的診斷性能,結果表明該方法在滾動軸承故障診斷上的可行性和有效性。
1 無監督網絡自適應
1.1 無監督遷移學習

1.2 卷積神經網絡
鑒于CNN在圖像處理、計算機視覺等領域的成功應用,CNN也被廣泛應用于振動信號分析的故障診斷領域。典型的CNN包含有卷積層、池化層和全連接層[12]。
卷積層(Conv):用于提取復雜的高維輸入特征,由多個卷積內核(過濾器)組成, 當每個核在輸入映射上滑動時,權值保持不變,通過將輸入信號與卷積核進行卷積運算獲得特征圖。卷積操作完成后,使用激活函數實現非線性映射,在本研究中,采用了直線單元(ReLU)函數[13]。卷積層數學模型可表示為:
δ(x)=max(0,x)
(1)

池化層(Pool):每個卷積層后面會連接一個池化層,通過池化內核對得到的特征圖進行下采樣,實現數據降維和進一步特征提取。本文采用最大池化函數,返回池化核區域最大值。
全連接層(FC):用于分類和識別故障類別。本文采用softmax函數將全連接層輸出映射到(0,1)區間,實現故障識別分類[14]。softmax公式可表示為:
(2)
式中:C為數據集類別個數;φi為全連接層的第i類的輸出值;αi為φi經過softmax運算后第i類的概率。
1.3 最大均值差異
最大均值差異(maximum mean discrepancy, MMD)是用來衡量兩個分布差異的指標[15]。給定兩個數據集Xs、Xt,利用核函數進行內積形式的希爾伯特空間的非線性映射,MMD表示式如式(3)所示。
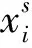
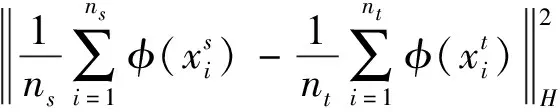
(3)
2 子域適應軸承故障網絡
本節介紹網絡結構和損失函數,用于實現無監督軸承故障類別診斷。
2.1 網絡結構
SDAN網絡主要包含有特征提取器、健康狀況分類器2部分。為了簡化復雜的網絡調參過程,本文特征提取器的網絡結構和參數與文獻[16]基本網絡結構保持一致。后續可結合實際應用,優化網絡結構和參數,更好地提取軸承故障數據的特征,提高分類正確率。本文SDAN網絡結構和參數如表2所示。Conv(x,y)為一維卷積運算,表示x個卷積核,卷積核的大小為y。網絡均采用最大池化操作,窗口大小為2,步長為2。FC(n)表示全連接層,包含有n個神經元輸出。隨機丟棄(Dropout)[17]為0.5,用于提高網絡的泛化能力。分類器只包含一個全連接層,其神經元的數目與數據集類別的個數相同。
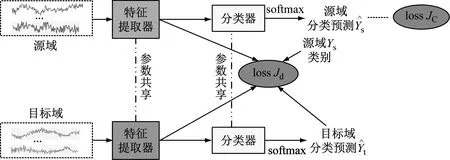
圖2 SDAN網絡結構

表1 SDAN網絡結構
2.2 局部最大平均誤差LMMD
MMD被廣泛應用于測量源域和目標域分布差異,但是主要關注全局分布對齊,卻忽略源域和目標域同一類別子域間關系。由于同一類別有更強的相關性,通過對齊具有相同標簽的樣本的相關子域可以匹配全局分布和類別局部分布。借鑒文獻[11],本文引入LMMD用于對齊同一類別相關子域的分布,公式可表示為:
(4)
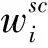
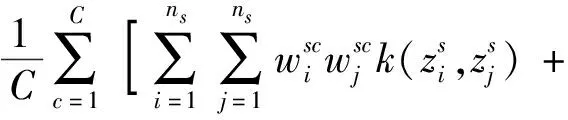
(5)
2.3 優化目標
該網絡通過深度特征表示學習和局部最大平均誤差學習來提取域可轉移的特征表示。訓練過程中有2個優化目標。
(1)最小化源域數據集上軸承故障類別分類器的損失函數Jc,引導分類器輸出正確預測標簽。
(2)最小化源和目標域數據集間的LMMD距離Jd。
其中Jc的表達式可表示為:
(6)
式中:Ga為特征提取器輸出;Gc為源域分類器預測輸出;Jy為交叉熵損失函數。
則總的損失函數J如下所示,其中α為平衡超參數。
J=Jc+αJd
(7)
3 實驗
對江南大學(Jiang Nan University, JNU)軸承故障數據集[18]進行了對比實驗,用以驗證所提出模型的有效性。
3.1 江南大學JNU軸承數據集
該數據集為江南大學采集的軸承故障數據集,采樣頻率為50 kHz,包含有正常狀態、內圈故障、外圈故障和滾動體故障四種健康狀況。根據軸承故障位置不同,將故障數據分為4類,如表2所示。

表2 JNU軸承故障數據集說明
實驗過程中使用加速度計在600、800和1 000 r/min三種不同轉速下采集振動信號。不同轉速被認為為不同任務,分別將轉速為600、800和1 000 r/min的數據定義為任務A、B、C。例如A->B表示源域為轉速為600 r/min的振動數據,目標域為轉速為800 r/min的振動數據。
實驗采用重疊采樣的方式,每間隔200個點采樣1 024個點,即每個樣本有1 024個數據點。每個故障類別500個樣本。其中100%的源域樣本和50%的目標域樣本作為訓練集,目標域剩余的50%的樣本作為測試集。
3.2 對比基準及實驗參數
為了驗證本文方法的有效性,本文選擇5個受歡迎的領域自適應學習方法,DCORAL[19]、JAN[20]、DDC[15]、DANN[21]、CDAN[22]進行對比實驗。JAN、DDC等方法均采用高斯核函數進行損失函數計算。以上所有的方法均采用與本文相同的CNN基本網絡框架進行數據特征提取,便于更合理的測試模型性能。

3.3 JNU軸承故障數據集變工況診斷結果
為了評估模型的性能,將本方法與其他5種常用算法進行比較,診斷的平均結果及對比如表3、圖3所示。其中DCORAL自適應方法效果最差,識別正確率平均值為72.61%,準確率波動較大,標準差更大。其中DDC、DANN兩種方法考慮對齊全局分布,方法識別正確率平均值分別為94.24%和93.64%,正確率明顯高于DCORAL。而JAN和CDAN方法考慮特征表示和標簽分類輸出特征進行特征對齊,識別正確率分別為94.26%和92.88%。本文提出的方法平均準確率為95.86%,都具有相對較小的標準差和較好的魯棒性,明顯優于其他5種方法,表明本文方法可以通過對齊子域分布,捕獲各類別細粒度信息,學習更多可轉移的表示,驗證了模型的有效性。
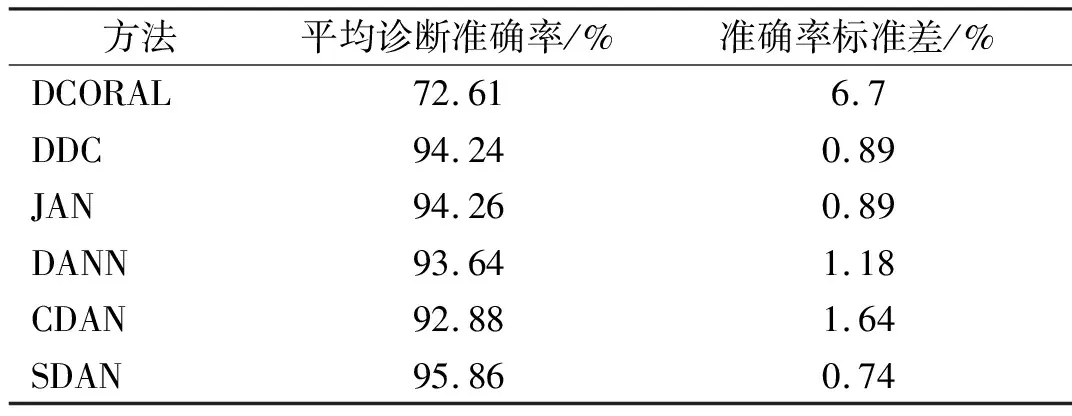
表3 實驗平均診斷結果

圖3 JNU軸承故障數據集不同方法故障識別正確率對比
為了更直觀地分析本文方法的優點,隨機選擇遷移任務B->A,采用t分布隨機鄰居嵌入(t-distributed stochastic neighbor embedding,t-SNE)算法[23]對目標域數據特征表示進行可視化,不同方法的特征表示如圖4所示。圖例中包含源域和目標域的4類故障類型,s代表源域,t代表目標域,如s-NA指的是源域的正常數據。由圖可知,通過深度遷移學習,各網絡學習到源域和目標域特征全局對齊較好。但是由4(a)可知DCORAL網絡學習存在嚴重的類別間的重疊問題,部分點很難分類,正確率偏低。由4(b)可知,DDC網絡重疊問題相較DCORAL改善明顯,但是各類別特征對齊較差。由4(d)可知,DANN雖然全局分布對齊效果良好,但是外圈故障類別特征相對分散,子域對齊效果一般。由4(c)、4(e)可知,雖兩種方法考慮不同域之間特征和輸出標簽的聯合分布差異進行軸承故障診斷,子域對齊效果卻差強人意。由4(f)可知,本文SDAN不僅可以很好的對齊全局分布,同時可以有效的對齊同類別子域的分布,各類別間具有明確的邊界,便于更好地識別目標域的故障類。
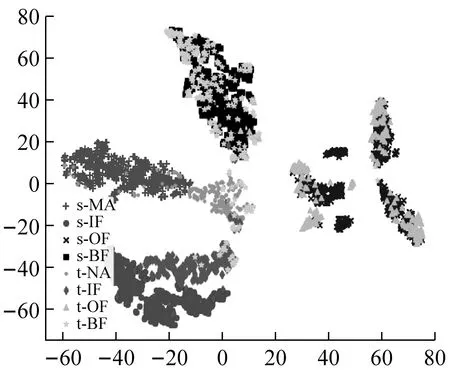
(a)DCORAL
本文同時計算了6種方法在遷移任務B->A的混淆矩陣,詳細地分析每個類別的分類精度,分類結果如圖5所示。由圖可知,本文方法僅有35個錯誤樣本,識別正確率為96.5%,明顯高于其他5種方法,說明了該方法的優越性。
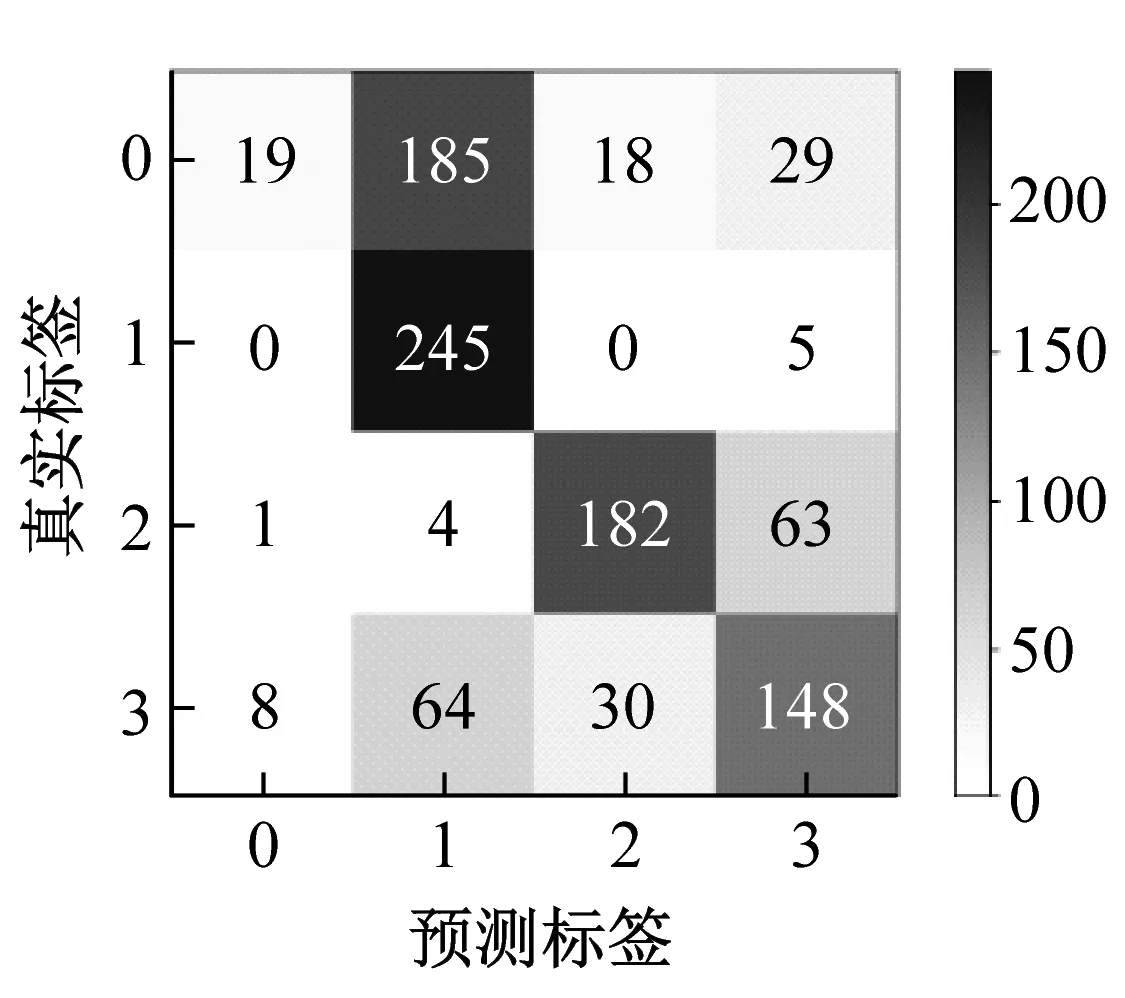
(a)DCORAL
4 結 論
為了提高軸承故障診斷在變工況情況下的分類精度,提出了一種子域適應無監督軸承故障診斷網絡SDAN。該網絡引入局部最大平均誤差LMMD,彌補了現有方法僅僅試圖進行全局對齊,未考慮源域和目標域間的關系,可能會丟失每個類別的細粒度信息的缺陷。在江南大學JNU軸承故障數據集,選取5種目前流行的領域自適應故障診斷方法進行對比實驗,驗證了該方法的有效性。
結果表明:本文提出的端到端無監督軸承故障診斷SDAN網絡,僅需在損失函數中引入局部最大平均偏差LMMD,不僅可以很好的對齊全局分布,同時可以有效的對齊同類別子域的分布。本文方法在變工況且數據無標簽的情況下,診斷正確率優于現有5種流行的領域自適應故障診斷方法,t分布隨機鄰居嵌入算法顯示該方法可以有效的對齊源域和目標域,驗證了該方法良好的可行性和有效性。
猜你喜歡
汽車維修與保養(2019年7期)2020-01-06 03:30:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
汽車維護與修理(2016年10期)2016-07-10 08:17:41
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維護與修理(2015年2期)2015-02-28 12:15:39
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
機械與電子(2014年1期)2014-02-28 02:07:31
