基于集成學習的海岸帶變化檢測方法研究
2021-08-11 08:31:16王娟趙吉祥單春芝高曉慧
海洋開發與管理 2021年7期
關鍵詞:特征
王娟,趙吉祥,單春芝,高曉慧
(1.國家海洋局北海環境監測中心 青島 266000;2.中國石油大學(華東)海洋與空間信息學院 青島 266000)
0 引言
海岸帶地區資源豐富,區位優勢明顯,人類生產生活和經濟活動相對密集,但該地域海陸相互作用復雜,生態環境脆弱。隨著經濟的快速發展,海岸帶地區的各類生產建設活動日益頻繁,對資源環境造成了巨大壓力[1]。隨著全國海岸帶監督管理的不斷加強,各省市分別出臺相應的海岸帶開發利用及保護等條例,海岸帶及海域使用監管空前嚴格。在我國自主研發的衛星組網不斷完善的背景下,高時空分辨率的海岸帶及海域使用動態變化監測已成為高效的監管手段[2]。現有的業務體系大多采用目視解譯方法,亟須開展相關的自動化變化監測來提高工作效率和準確度。
變化檢測能夠從不同時期的遙感影像中確定地表的變化,自遙感技術誕生以來一直是眾多學者研究的焦點問題之一。李德仁[3]對比分析了7種變化檢測常用的手段,指出自動變化檢測是未來發展的方向。國內外學者提出了大量的算法模型,從變化信息提取的角度主要分為閾值法、機器學習和深度學習3種方式。閾值法是指直接利用閾值分割差異影像從而提取變化信息,如魏立飛等[4]基于融合后的影像進行自適應閾值確定,提取變化信息。Chehata N等[5]利用均值漂移分割算法提取風暴后的受災信息。閾值法簡單易行,但是在復雜情況下難以用一個單一的閾值提取變化信息,精度受限。深度學習近年來迅速發展,從最初的圖像識別、文本分析擴展至各個領域,部分學者利用深度學習方式提取變化信息,如張鑫龍等[6]構建并訓練了高斯-伯努利深度限制玻爾茲曼機模型,以提取變化和未變化區域深層特征,進而完成變化檢測。杜博等[7]提出深度慢特征分析用于遙感圖像的變化檢測,在測試數據集上取得了較好的效果。深度學習需要大量的訓練樣本,同時一個模型的訓練需要大量的參數調節,在實際應用中較難實現。
綜合來看,以機器學習為代表的算法模型構建簡單,在小樣本狀態下能夠實現變化信息的自動提取,相對于傳統算法和深度學習方法仍有優勢。機器學習算法如支持向量機(Support Vector Machine,SVM)等將變化檢測問題轉變成分類問題,通過樣本訓練模型識別提取變化信息,如李亮等[8]采用貝葉斯最小錯誤理論提取變化;王志盼等[9]利用SVM進行高分辨率遙感影像的建筑物變化檢測。集成學習是機器學習的一種,通過構造多個學習器完成學習任務,能夠獲得比單一分類器更加優秀的性能,是機器學習近年來發展的熱點。本研究針對沿海試驗區,利用兩種集成學習方式:隨機森林(Random Forest)和極端梯度提升(XGBoost),進行變化檢測試驗,并與經典的變化檢測方法和傳統機器學習方式進行對比,驗證集成學習算法開展海岸帶地區變化檢測的優勢。
1 研究方法
1.1 數據及預處理
獲取2018年10月和12月的兩景GF-1衛星影像,覆蓋范圍為山東省蓬萊市某處在建港口,該處位于渤海黃海交界海域,臨近蓬萊閣風景區,與長島縣隔海相望。獲取的GF-1衛星影像相隔兩月,為融合后三波段(紅、綠、藍)真彩色影像,分辨率2 m,像元數量1 550×2 156,經過了初步大氣校正、地形校正和嚴格的圖像配準。
圖像在不同季節成像,由于外部原因造成的圖像間輻射差異和植被等地物自然變化帶來的季相差異將會給變化檢測造成嚴重干擾[10],本研究采用文獻[11]中的方法[11],選擇18個偽不變特征點(PIF)建立回歸模型對兩景影像進行相對輻射校正。經過檢驗,兩幅影像在3個波段上的相關性指數均大于90%,說明回歸模型擬合效果較好,校正后影像如圖1所示。

圖1 相對輻射校正后影像
1.2 特征提取
1.2.1 紋理特征
高分辨率遙感影像光譜數量較少,空間紋理信息豐富,根據相關學者研究,在變化檢測中加入紋理特征能夠提高變化檢測的精度[12]。灰度共生矩陣(GLCM)是一種基于統計的紋理特征描述方式,由Haralick等[13]在1973年提出。在灰度共生矩陣的基礎上,Haralick等人定義了14個紋理特征,根據Ulaby等[14]的研究,14個特征中只有4個不相關的特征:二階矩(Second Moment)、對比度(Contrast)、相關性(Correlation)和熵(Entropy)。
為進一步突出圖像紋理特征,除GLCM外,選用局部二值模型(LBP)進行進一步提取。LBP特征具有灰度不變性和旋轉不變性,可以作為灰度共生矩陣紋理特征的補充[15]。
本研究在0°、45°、90°和135°的方向上進行提取灰度共生矩陣的4個特征值:二階矩(Second Moment)、對比度(Contrast)、相關性(Correlation)和熵(Entropy),最后各自取4個方向上的平均值作為最終特征。由于圖像中部分地物尺度較小,選擇3×3窗口提取兩景影像的LBP紋理特征。
1.2.2 可見光波段差異植被指數(VDVI)
影像分別于10月和12月采集,植被覆蓋有明顯變化,因此選擇能夠突出綠色植被信息的特征進行提取。健康綠色植被在綠光和近紅外波段有較強反射作用,而在藍光和紅光波段有吸收作用,根據這一原理對植被識別主要依賴可見光-近紅外波段的組合變化,增強植被信息的同時使非植被信息最小化,如常見的歸一化植被指數NDVI、增強型植被指數EVI等[16]。
本實驗數據為融合完成的三波段真彩色影像,缺失紅外波段信息。因此選擇可見光波段差異植被指數VDVI進行提取,該指數利用綠色植被在不同波段的反射吸收特性,通過對波段的組合能夠增強植被信息,相關實驗證明VDVI指數對于綠色植被具有較好的提取效果[17]。計算如公式(1)所示。
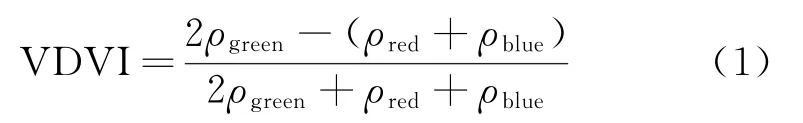
式中:ρgreen代表綠色波段反射率;ρred代表紅色波段反射率;ρblue代表藍色波段反射率。
1.2.3 形態學建筑物指數(MBI)
該地區正在建設中,建筑物發生變化可能性較大,因此選擇相關特征突出建筑物信息。形態學建筑物指數(MBI)由黃昕等[18]提出,通過基本的形態學重建,對影像進行粒度分析和不同方向上的特征計算,能夠有效描述建筑物的特征(如亮度、大小、對比度和方向性等)。
首先提取影像各個波段中灰度值最大的像元組成亮度圖像,有研究表明建筑物的反射能夠產生較大的灰度值,如式(2)所示。
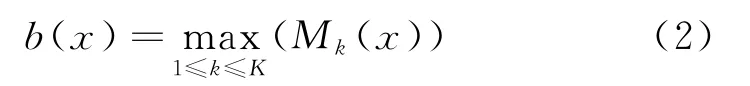
式中:Mk(x)為像素點x在波段k上的灰度值;b(x)為該像素點亮度。
在亮度圖像的基礎上利用形態學基本運算執行形態學重建,如式(3)所示。
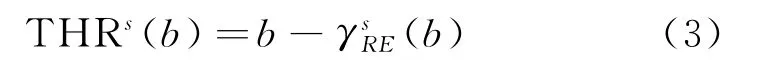
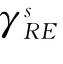
在不同方向求取運算結果后求平均,如式(4)所示。


由于高分辨率圖像中的建筑物顯示出不同大小、形狀、高度和面積的復雜空間模式,因此將多尺度THR建立在不同形態剖面上,能夠描述建筑的復雜空間特征,如形狀、大小等[19-20]。如式(5)所示。
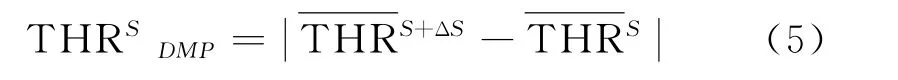
式中:Δs是移動步長。
在DMP中取平均得到MBI如式(6),即為形態學建筑物指數。

綜上,兩景影像分別提取特征如表1所示。
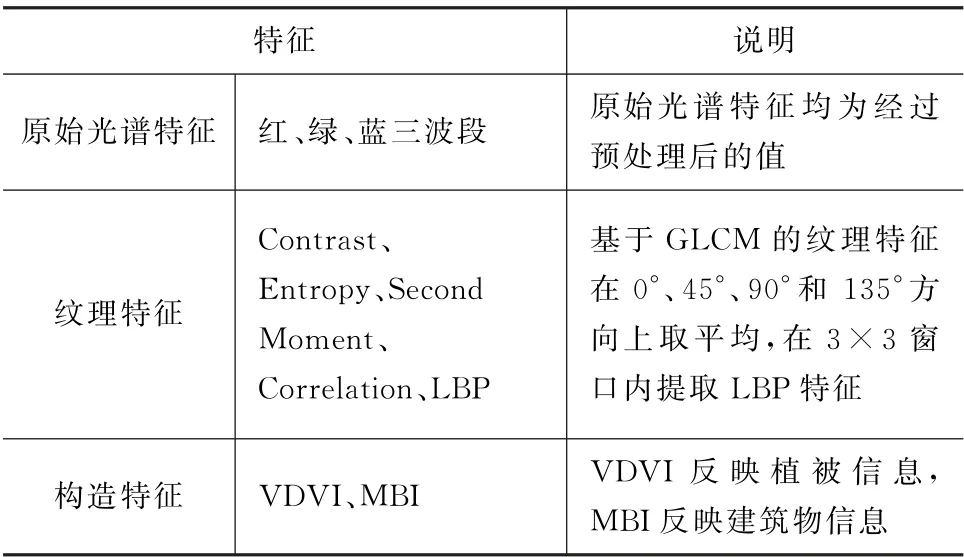
表1 特征提取
1.3 隨機森林(Random Forest)
隨機森林(Random Forest)是一種基于決策樹結構集成學習的方式,結合了Bagging算法(Bootstrap aggregating,引導聚集算法)和隨機子空間理論,集成眾多決策樹進行預測,通過各個決策樹的預測值進行平均或投票,得到最終的預測結果[21]。其是一個Bagging算法的擴展應用,在以決策樹為基礎進行集成的基礎上引入了隨機屬性,使最終集成的泛化性能得到加強。
隨機森林首先采用基于自展法(Bootstrap)重采樣,產生多個訓練集;由每個自助數據集生成一棵決策樹,由于采用了Bagging算法采樣的自助數據集僅包含部分原始訓練數據,將沒有被Bagging采用的數據稱為袋外(out-of-bag,OOB)數據,把OOB數據用生成的決策樹進行預測,對每個OOB數據的預測結果錯誤率進行統計,得到的平均錯誤率即為隨機森林的錯誤估計率[22-23]。而OOB誤差估計作為泛化誤差估計的一個組成部分,相關研究表明其可以取代測試集進行誤差估計。同時由于隨機森林抽取樣本的隨機性,OOB數據作為評估學習器誤差的指標,在選擇不同特征時有不同的準確率,因此可以進行特征重要性的排序。
隨機森林整體流程如圖2所示。
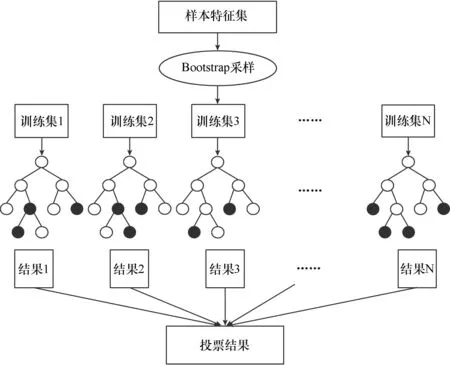
圖2 隨機森林流程
1.4 極端梯度提升(XGBoost)
極端梯度提升(eXtreme Gradient Boosting,XGBoost)[24]是梯度提升決策樹(Gradient Boosting Decision Tree,GBDT)的改進型算法,不同于Random Forests的Bagging集成學習,其采用Boosting集成學習方式,有多個具有關聯性的決策樹進行決策。XGBoost將損失函數進行泰勒多項式的二次展開,其目標函數相對于GBDT具有更高的準確定和更快地收斂速度[25]。XGBoost模型如公式(7)所示。

其目標函數如公式(8)所示。
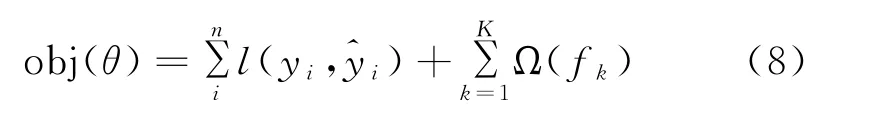
式中:n為樣本數;yi為樣本真實值;l為損失函數;Ω為抑制函數復雜度的正則化項。
采用boosting的方法進行優化,依次優化每一棵樹的模型,在保留原有模型的基礎上進行下一級的優化,如公式(9)所示。
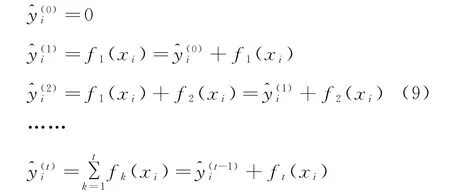
最終樹優化如公式(10)所示。
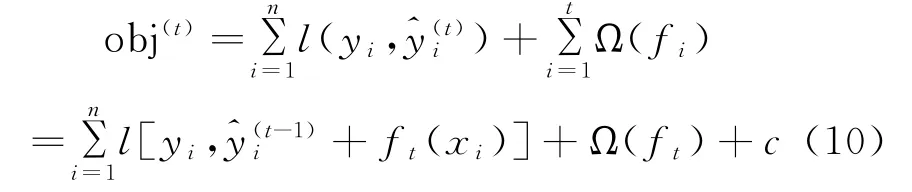
式中:c為前t-1棵樹的復雜度。
對函數進行泰勒二階展開,如式(11)所示。
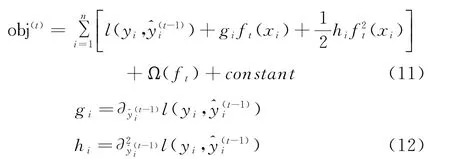
最終優化的損失函數如下:
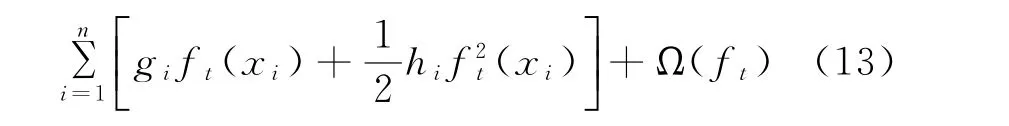
式中:gi為損失函數一階導數;hi為損失函數二階導數。
gi和hi是不依賴于損失函數的形式的,只要這個損失函數二次可微就可以了,后續在模型正則化的基礎上即可實現XGBoost的訓練。
XGBoost可以通過計算相關特征在每棵樹中的分裂次數賦以對應的權重,實現特征重要性的排序,如式(14)所示,特征j在整個模型中的重要性為特征在單棵樹中重要度的平均值衡量。
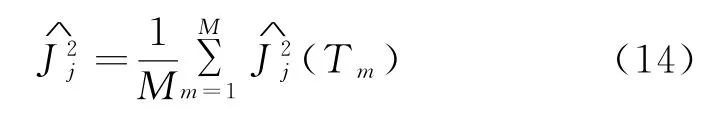
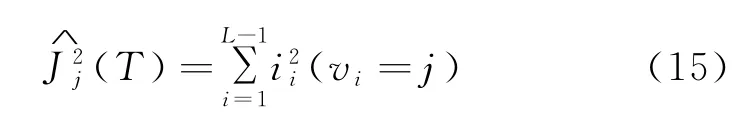
1.5 精度評價
采用準確率(ACC)、漏檢率(MA)和誤檢率(FA)3個指標進行變化檢測的精度評價,其中準確率表示正確檢測的像元(包括發生變化和未發生變化)占總像元的比例,漏檢率表示發生變化但是沒有檢測出的像元占發生變化總像元的比例,誤檢率表示實際沒有發生變化但是被錯誤檢測成變化像元占未發生變化總像元的比例。三者計算公式如下:
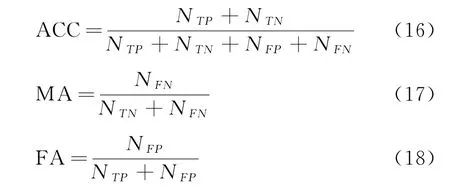
式中:NTP為正確檢測的變化像元數量;NFP為實際未變化但是檢測為變化的像元數量;NTN為正確檢測的未變化像元數量;NFN為實際變化但是檢測為未變化的像元數量。
2 實驗與結論
實驗主要由3部分構成:①對兩時相影像進行預處理并提取特征,除傳統的光譜特征和紋理特征之外,考慮到本實驗區域和實驗數據的特點,加入人為構造的VDVI和MBI指數,分別反映植被變化信息和建筑物的變化信息;②構建特征差異影像并選取樣本,選擇傳統的差值法對各特征構建差異影像,結合原始影像選擇變化和未變化的樣本,開展基于像素級別的變化檢測方法研究;③分別利用隨機森林(Random Forest)、極端梯度提升(XGBoost)兩種集成學習方式和傳統的機器學習SVM進行變化檢測試驗,與經典變化檢測方法(CVA和IRMAD)在精度和效率上進行對比分析。整體流程如圖3所示。
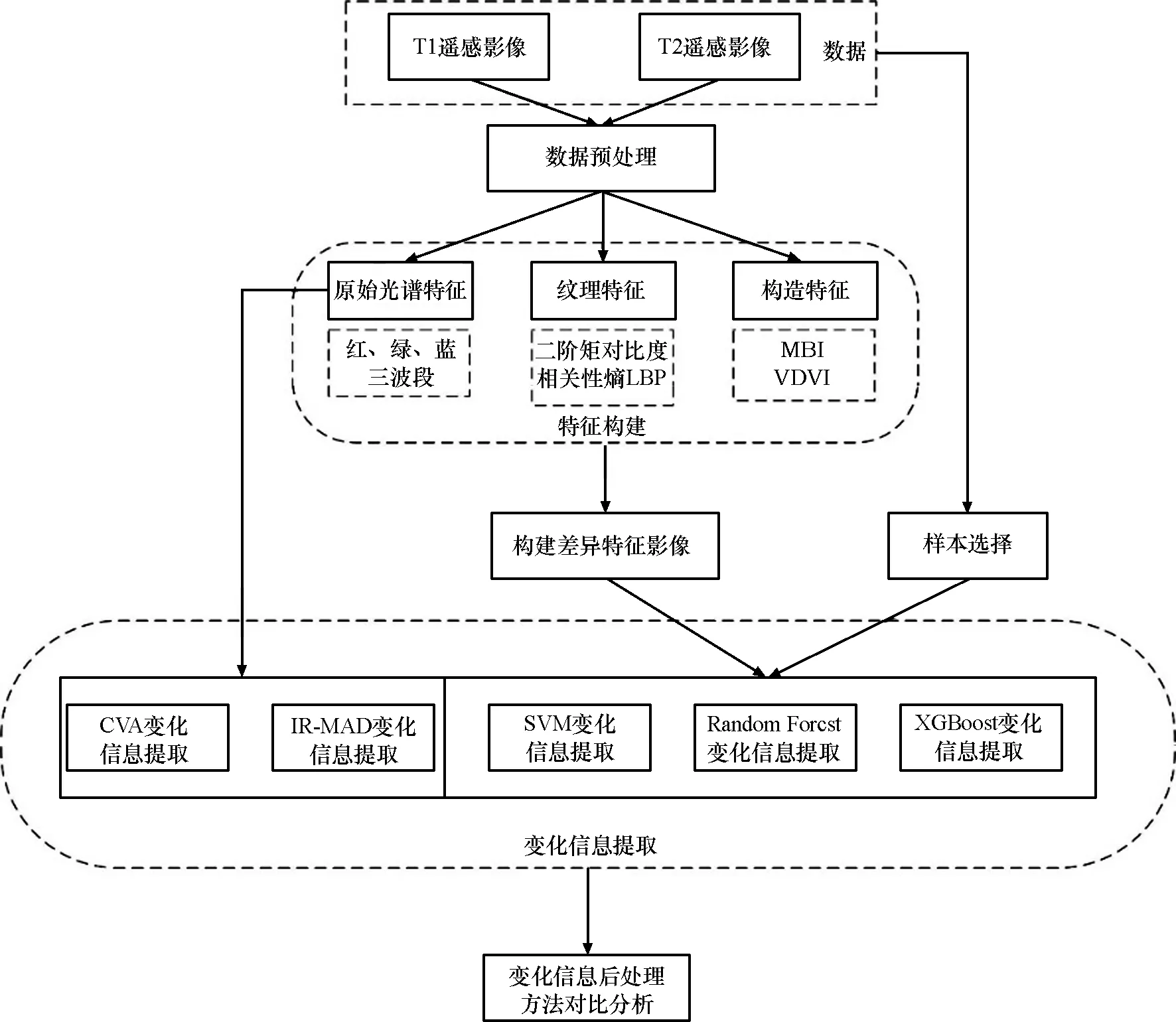
圖3 整體流程
分別采用Random Forest、XGBoost和SVM算法進行訓練,其中為評估隨機森林中決策樹的數量對最終變化檢測結果的影響,對[10,90]區間范圍內以5為動態變化步長進行實驗,計算30次OOB準確率的平均值進行可視化,如圖4所示,當決策樹個樹達到60時,隨機森林的OOB準確率達到98.6%,后續繼續增加決策樹個數,OOB準確率并不會提升,同時模型訓練效率會降低,因此在實驗中設置決策樹個數為60是合理的。
為驗證人工選取的VDVI和MBI特征在變化檢測中的作用,通過Random Forest和XGBoost進行特征的重要性排序,結果如圖5所示,特征差異對隨機樹森林模型的影響由大到小依次為:B3(藍光波段)、B1(紅光波段)、MBI、VDVI、Contrast、B2(綠光波段)、Entropy、Second Moment、LBP和Correlation。在XGB模型中,MBI特征重要性僅次于B3(藍光波段),VDVI特征重要程度較大部分紋理特征更高,因此人為構造的VDVI和MBI特征在該地區的變化檢測中有效。
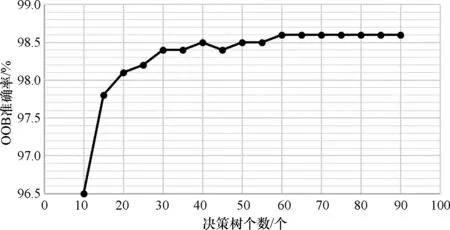
圖4 OOB準確率
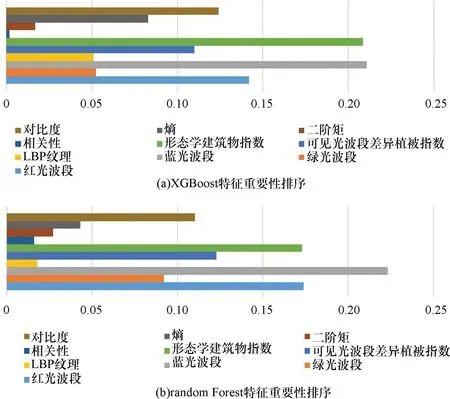
圖5 特征重要性
為后續進行算法的比較分析,利用XGBoost進行訓練時保持決策樹個數與隨機森林中決策樹個數一致。利用SVM進行訓練時,采用五折交叉檢驗的方式,確定最優化參數C=10,核函數選擇rbf。
傳統的變化檢測主要有變化矢量分析(CVA)、迭代加權多元檢測(IR-MAD)等方式,針對實驗區域,采用兩種傳統方式進行檢測。其中CVA變化檢測需要閾值分割,而閾值選取對最后的精度評定有重要影響,分別采用Otsu's、Tsai's和Kittler's自適應閾值分割算法進行圖像的二值化分割,避免人為主觀性。在IR-MAD中,變化閾值設置為0.001,迭代至42次時閾值變化小于設定值。
以人工提取的變化信息作為參考影像,對上述算法進行評價,結果如表2所示。
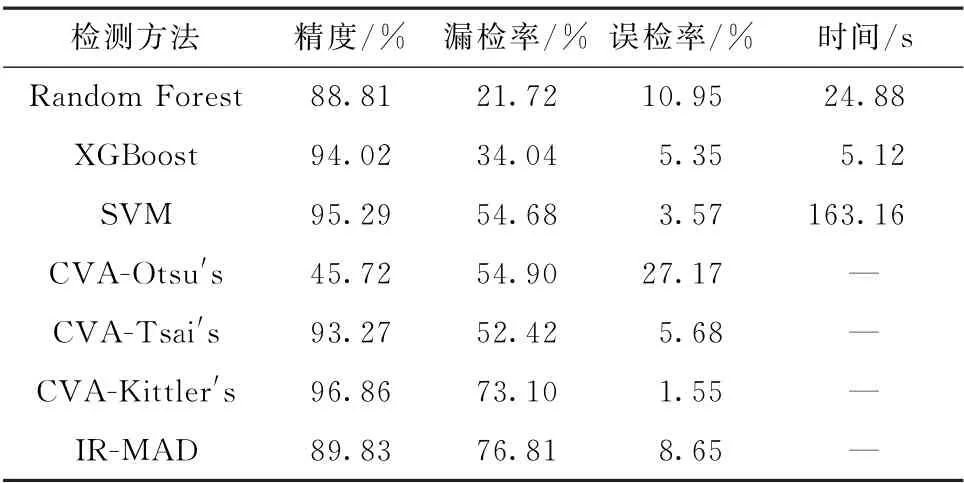
表2 變化檢測精度評價
通過上述幾種方法的對比可以得到:
(1)在傳統的變化檢測方法中,檢測質量嚴重依賴閾值的確定,如CVA變化檢測,通過不同的閾值確定方式得到的精度相差較大,基于Tasi's的閾值分割方式漏檢率明顯小于其他兩種閾值分割方式(Otsu's和Kittler's),誤檢率處于合理區間,因此在CVA-Tsai's變化檢測較其余方式(包括IRMAD)更具優勢。
(2)3種機器學習變化檢測對比CVA-Tsai's優勢明顯,Random Forest相對于CVA-Tsai's的52.42%的漏檢率明顯降低,同時誤檢率處于較合理的區間,其余兩種機器學習方式(XGBoost和SVM)在精度、漏檢率和誤檢率上明顯優于CVA-Tsai's。
(3)XGBoost變化檢測方法的精度、漏檢率、誤檢率和效率明顯優于Random Forest方式,相對于傳統的機器學習SVM方法,其漏檢率大幅下降近20%,誤檢率雖有上升,但其效率較SVM提升30余倍。綜合來看,XGBoost變化檢測方法相對于其他兩種機器學習方式優勢明顯。
需要指出的是以上方法都是基于像素級別的變化檢測,檢測結果中存在較多椒鹽噪聲,因此通過聚類和濾波等后處理消除噪聲。
3 結束語
本研究以沿海地區某處在建港口為實驗區,在變化復雜情況下進行了變化檢測實驗,利用原始光譜特征、紋理特征和人為構造的VDVI、MBI指數構建差異影像,分別使用兩種集成學習方式進行了變化檢測實驗,并與傳統的SVM方法和經典變化檢測方法進行了對比。
經實驗驗證,集成學習方式能夠實現自動化的變化信息提取,其效率遠遠超過傳統的SVM方法,并且漏檢率和誤檢率等指標優于經典的變化檢測方式,在實驗中,XGBoost相對于Random Forest算法實現了較好的效果,同時經實驗驗證,人為構造的兩種特征在進行變化信息提取時均起到比傳統特征更加重要的作用。
需要指出的是,目前實際變化檢測工作中依舊以人工判斷提取變化區域為主,本研究方法可作為輔助參考,提升作業效率;由于本研究方法屬于像素級別的變化檢測,變化檢測結果中存在大量椒鹽噪聲,后續在面向對象的基礎上實現準確、自動化的變化檢測是進一步研究的方向。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
