基于XGBoost和神經(jīng)網(wǎng)絡(luò)擬合預(yù)測模型的辛烷值損失的預(yù)測
2021-08-09 11:22:29朱怡欣
智能計算機與應(yīng)用 2021年3期
朱怡欣
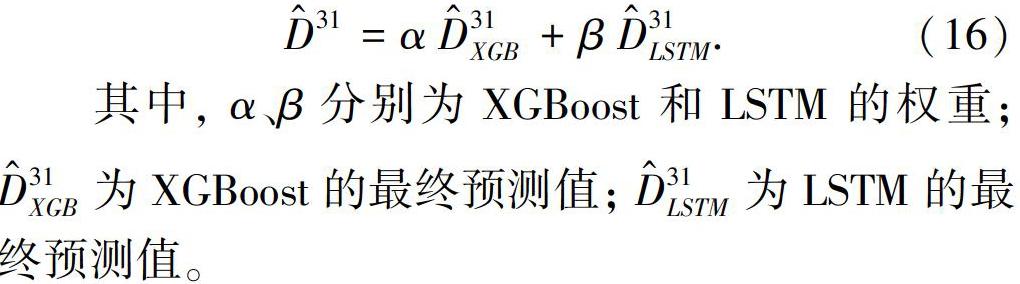
摘 要: 汽油清潔化重點是降低汽油中的硫、烯烴含量,同時盡量保持其辛烷值。降低辛烷值(RON)損失是國內(nèi)車用汽油質(zhì)量升級的主要目標(biāo)之一。本文針對某石化企業(yè)的催化裂化汽油精制脫硫裝置運行收集的數(shù)據(jù)進行處理,探求數(shù)據(jù)樣本中變量與變量本身、其他自變量及目標(biāo)變量等之間的相關(guān)性,對特征變量進行多階段降維,進而通過XGBoost和LSTM循環(huán)神經(jīng)網(wǎng)絡(luò)對汽油辛烷值損失進行建模,通過對預(yù)測結(jié)果的統(tǒng)計表明該方法在企業(yè)辛烷值損失預(yù)測中具有較好的表現(xiàn),為國內(nèi)車用汽油技術(shù)升級提供一定的指導(dǎo)作用。
關(guān)鍵詞: 辛烷值損失;XGBoost;LSTM
文章編號: 2095-2163(2021)03-0185-05 中圖分類號:TE621 文獻標(biāo)志碼:A
【Abstract】The focus of gasoline cleaning is to reduce the sulfur and olefin content in gasoline while maintaining its octane number as much as possible. Reducing the loss of octane number (RON) is one of the main goals of China's automotive gasoline quality upgrade. This paper deals with the data collected from the operation of the catalytic cracking gasoline refinery desulfurization unit of a petrochemical company, and explores the correlation between the variables in the data sample and the variables themselves, other independent variables and target variables, and performs multi-stage dimensionality reduction on the characteristic variables. Furthermore, the gasoline octane loss is modeled by XGBoost and LSTM recurrent neural network, and the statistics of the prediction results show that this method has a good performance in the prediction of enterprise octane loss, which provides a certain guidance for the upgrading of China's automotive gasoline technology.
【Key words】 octane loss; XGBoost; LSTM
0 引 言
汽油作為小型汽車的主要燃料,其燃燒產(chǎn)生的尾氣對環(huán)境造成了惡劣的影響。世界各國都制定非常嚴(yán)格的汽油標(biāo)準(zhǔn)。隨著國內(nèi)經(jīng)濟的迅速發(fā)展,汽車保有量在持續(xù)增長,汽油的需求量也在逐年加大。因此國內(nèi)大力發(fā)展了以催化裂化為核心的重油輕質(zhì)化工藝技術(shù),充分利用了原油中的重油資源,將重油轉(zhuǎn)化為汽油、柴油和低碳烯烴。超過70%的汽油是由催化裂化生產(chǎn)得到,因此成品汽油中95%以上的硫和烯烴來自催化裂化汽油。辛烷值是反映汽油燃燒性能的重要指標(biāo),辛烷值每降低1個單位,相當(dāng)于損失約150元/噸。以一個100萬噸/年催化裂化汽油精制裝置為例,若能降低RON損失0.5個單位,其經(jīng)濟效益將達到7 500萬元。
1 研究方法與基本假設(shè)
1.1 研究方法
首先,研究根據(jù)樣本針對不良數(shù)據(jù)進行預(yù)處理,篩選出無關(guān)緊要的操作變量,輔助找出主要變量,其次,對預(yù)處理數(shù)據(jù)進行多階段降維,利用了Embedded Feature Selection篩選出在建模過程中貢獻度比較高的變量(特征),作為最終建模變量。經(jīng)過多階段特征降維后,遴選出了30個變量作為影響最終結(jié)果的自變量,選出了產(chǎn)品性質(zhì)中的硫含量、辛烷值損失作為因變量,上述的32個變量用于對辛烷值損失的模型的建立和求解。在經(jīng)過325個訓(xùn)練樣本的訓(xùn)練后,根據(jù)XGBoost和神經(jīng)網(wǎng)絡(luò)兩個擬合預(yù)測模型不同的預(yù)測能力,使用加權(quán)打分的形式進行組合,對最終的辛烷值損失進行預(yù)測。
1.2 基本假設(shè)
假設(shè)各訓(xùn)練樣本之間相互獨立,不存在強耦合的關(guān)系。
假設(shè)各樣本內(nèi)容雖然與真實環(huán)境存在一定誤差,但不影響最終結(jié)果。
假設(shè)在預(yù)處理階段剔除的變量,對最終結(jié)果的預(yù)測不會產(chǎn)生方向性錯誤。
2 XGBoost和神經(jīng)網(wǎng)絡(luò)擬合預(yù)測模型
2.1 多階段特征降維
由于原始數(shù)據(jù)變量較多,工程技術(shù)應(yīng)用中經(jīng)常需要先降維,這有利于忽略次要因素,發(fā)現(xiàn)并分析影響模型的主要變量。所以,文中對預(yù)處理后的數(shù)據(jù)進行了多階段降維,充分考慮到了多方面因素進行變量的選擇。
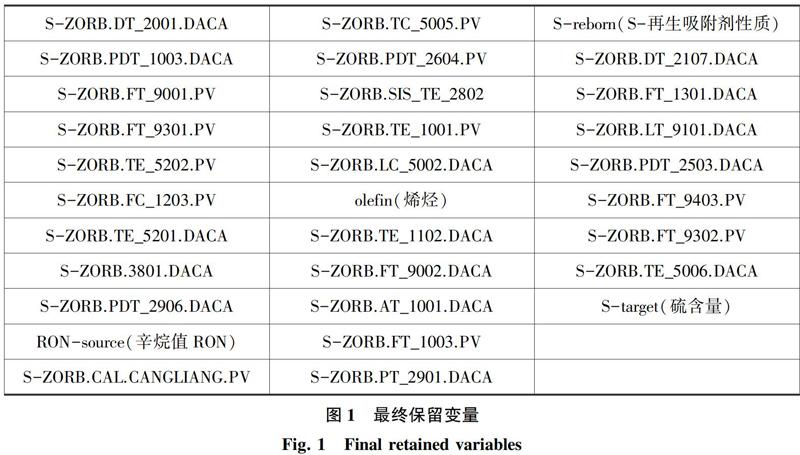
首先,是業(yè)務(wù)邏輯降維。根據(jù)業(yè)務(wù)邏輯可以知道辛烷值(RON)損失是原料辛烷值與產(chǎn)品辛烷值的差值,所以在給定原料辛烷值的情況下,就不再將產(chǎn)品辛烷值作為建模特征,否則會出現(xiàn)信息泄露問題。隨后,是標(biāo)準(zhǔn)化降維,利用樣本數(shù)據(jù)預(yù)處理結(jié)果,已經(jīng)刪除了一部分變量。然后,是自變量間相關(guān)性降維,考慮到各變量之間的相關(guān)性,進行變量的兩兩比較,刪除高度相關(guān)的變量,保留高度相關(guān)的其中一個變量即可,這樣有利于減少變量維度并且降低變量之間的耦合性。其次,是目標(biāo)變量與自變量間相關(guān)性降維,考慮到辛烷值RON損失作為因變量,其與剩余所有變量的相關(guān)性,故對辛烷值RON損失以及其余所有變量進行了兩兩相關(guān)性計算,有利于剔除與目標(biāo)變量無關(guān)的變量,最大限度地保留對目標(biāo)變量有意義的變量。接下來,是方差降維。考慮到變量自身的有效性,對變量進行了方差檢驗,剔除了方差小于0.1的變量,方差越小,表示該變量無法有效地去表征目標(biāo)變量,在后續(xù)建立模型中會產(chǎn)生較大的影響。最后,再利用Embedded Feature Selection篩選出在建模過程中貢獻度比較高的變量(特征),作為最終建模變量。最終保留變量如圖1所示。
2.2 多模型融合下的辛烷值損失預(yù)測模型
在預(yù)測模型中,需要指出的是,目標(biāo)變量是辛烷值損失值,而不是產(chǎn)品性質(zhì)中的辛烷值。從上述的相關(guān)性分析中,可以得到產(chǎn)品性質(zhì)中的辛烷值與原料性質(zhì)中的辛烷值具有高度相關(guān)性,如果利用產(chǎn)品性質(zhì)中的辛烷值作為目標(biāo)變量,對于結(jié)果而言會存在一定的作弊行為。
經(jīng)由多階段特征降維處理后得到30個主要變量,本次研究將其認(rèn)定影響最終結(jié)果的自變量,其中每個變量含有325個數(shù)據(jù)。進一步地,選取產(chǎn)品性質(zhì)中的辛烷值損失作為因變量,同樣含有325個數(shù)據(jù)。通過對這含有31個變量的325組數(shù)據(jù)構(gòu)建模型,對處于不同操作條件(30個主要變量的不同取值)下的辛烷值損失進行預(yù)測。
2.2.1 RMSE和MAE指標(biāo)介紹
RMSE函數(shù)一般用來檢測模型的預(yù)測值和真實值之間的偏差。RMSE值越大,表明預(yù)測效果越差。
平均絕對誤差(Mean Absolute Error,MAE),即誤差絕對值的平均值,可以準(zhǔn)確反映實際預(yù)測誤差的大小,其對應(yīng)數(shù)學(xué)公式可寫為:
MAE評估的是真實值和預(yù)測值的偏離程度,即預(yù)測誤差的實際大小。MAE值越小,說明模型質(zhì)量越好,預(yù)測越準(zhǔn)確。
2.2.2 辛烷值損失預(yù)測模型的建立-XGBoost
XGBoost(eXtreme Gradient Boosting)作為一種對多棵決策樹進行集成學(xué)習(xí)的算法,其中的決策樹之間具備一定的關(guān)聯(lián)關(guān)系,這和隨機森林有極大的不同。XGBoost 模型中,每棵決策樹都是對前面所有決策樹的預(yù)測結(jié)果之和與真實值的殘差,其算法過程如下:
(1)假設(shè)原始訓(xùn)練集含有的樣本數(shù)為N[1-2],隨機且有放回地從原始訓(xùn)練集中抽取n個訓(xùn)練樣本,并將其作為第一棵決策樹的訓(xùn)練集。
(2)設(shè)定每個訓(xùn)練樣本的特征數(shù)都為M,隨機從中抽取m個特征,并將其作為決策樹選擇最優(yōu)劃分特征的特征集合。
(3)利用這n個訓(xùn)練樣本和m個特征構(gòu)建第一棵決策樹,得到第一棵樹預(yù)測值。
(4)將第一棵決策樹的預(yù)測值與真實值之間的殘差作為第二棵樹的輸入值得到第二棵決策樹的預(yù)測值[2]。
(5)重復(fù)地將第一棵樹與第K-1棵樹之間的預(yù)測結(jié)果之和與真實值之間的殘差作為第K棵樹的輸入值[2],實驗循環(huán)至達到項目停止的條件,最終得到K棵決策樹,即XGBoost。
(6)利用XGBoost對測試集進行預(yù)測得到最終預(yù)測結(jié)果,即K棵決策樹的預(yù)測結(jié)果之和。
在XGBoost回歸模型中,樣本Di的最終預(yù)測值為各棵決策樹對該樣本的預(yù)測結(jié)果之和[2],如式(3)所示:
其中,T為第K棵決策樹的葉子節(jié)點總數(shù);wt為第K棵樹的第t個葉子節(jié)點的預(yù)測值[2];γ和δ分別表示對這兩部分的重視程度。
公式(8)表示在欠擬合和過擬合之間尋求平衡。其中,第一部分表示全部樣本的真實值以及預(yù)測值的殘差函數(shù),該值越小,欠擬合的概率越低;第二部分表示正則化懲罰項,該值越大,過擬合可能性就越大,因此將該部分盡可能縮小化,可以使最終模型更加簡單,具有更強的泛化能力。同時,XGBoost 中每個葉子節(jié)點的預(yù)測值是根據(jù)貪心策略,通過最優(yōu)化目標(biāo)函數(shù)求出。
2.2.3 辛烷值損失預(yù)測模型的建立-LSTM
循環(huán)神經(jīng)網(wǎng)絡(luò)RNN與傳統(tǒng)神經(jīng)網(wǎng)絡(luò)不同的是,RNN通過保存當(dāng)前隱藏層的信息,并通過隱藏層之間的連接將信息傳遞到下一時刻的隱藏層[1],賦予網(wǎng)絡(luò)“記憶”屬性,如圖3所示。但RNN網(wǎng)絡(luò)在反向傳播的情況下,對模型的線性關(guān)系參數(shù)具有長期依賴性[1],序列過長往往伴隨著梯度消失,網(wǎng)絡(luò)參數(shù)過大等條件將進一步導(dǎo)致梯度爆炸。
LSTM模型是RNN模型的一種衍生,是為了避免RNN存在的長期依賴性問題,LSTM網(wǎng)絡(luò)利用時間進行反向傳播訓(xùn)練,解決了梯度消失問題。LSTM的具體結(jié)構(gòu)如圖4所示。圖4中,ht-1是上一層的輸出,Ct-1是上一個LSTM結(jié)構(gòu)的數(shù)據(jù)信息,ht是該層的輸出,Ct是該LSTM結(jié)構(gòu)的數(shù)據(jù)信息。
LSTM基于細(xì)胞狀態(tài)和門控制對信息實現(xiàn)遺忘和更新,結(jié)構(gòu)中包括輸入門、輸出門和遺忘門,其對應(yīng)的方程式為:
其中,σ為激活函數(shù),U、W、b分別為模型信息的相關(guān)參數(shù)和偏倚[1]。
之前隱藏層的“記憶”的保留和遺忘是由遺忘門決定的。式(10)通過激活函數(shù)sigmoid,利用ht-1
和當(dāng)前的輸入xt得到輸出ft,輸出數(shù)值在[0,1]之間表示上一個LSTM 結(jié)構(gòu)保留信息的概率[1]。式(11)、式(12)利用sigmoid和tanh兩個激活函數(shù)實現(xiàn)了對新信息的選擇保留。式(13)表示為對LSTM 結(jié)構(gòu)保留的信息進行更新,即由ft與Ct-1 取Hadamard積,表示部分保留舊信息;it和Ct取Hadamard積,表示部分保留新信息,將兩者相加來更新LSTM 結(jié)構(gòu)保留的信息Ct。輸出門將式(15)中的tanh激活函數(shù)應(yīng)用于最新LSTM 結(jié)構(gòu)保留的信息,并利用式(14)得到的ot取Hadamard積控制最終的輸出ht。
在得到最終的訓(xùn)練樣本D后,結(jié)合主要變量的長期時間序列的特點,建立了的LSTM循環(huán)神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)如圖5所示[1]。
圖5中,除了當(dāng)前時刻的變量數(shù)據(jù),上一個LSTM結(jié)構(gòu)的隱藏層輸出和LSTM結(jié)構(gòu)所包含的信息一起作為當(dāng)前LSTM循環(huán)神經(jīng)網(wǎng)絡(luò)的輸入[1]。該結(jié)構(gòu)輸出結(jié)果不僅傳遞給下一個LSTM結(jié)構(gòu),還利用隨機失活模塊進一步無差別舍棄部分隱藏層節(jié)點,以此預(yù)防過擬合現(xiàn)象的出現(xiàn),同時也能避免LSTM循環(huán)神經(jīng)網(wǎng)絡(luò)因過度關(guān)注歷史信息而導(dǎo)致新信息輸入時一直出現(xiàn)不滿意結(jié)果的現(xiàn)象。XGBoost模型的參數(shù)設(shè)置見表1。XGBoost擬合對比如圖6所示,LSTM擬合對比如圖7所示。
2.3 XGBoost和LSTM的融合
由以上實驗結(jié)果對比可得,XGBoost的訓(xùn)練結(jié)果最好。但考慮到LSTM循環(huán)神經(jīng)網(wǎng)絡(luò)的構(gòu)建是基于時間序列的,考慮到了時間因素,最終值的預(yù)測是對相比于XGBoost進行了更深的挖掘而得,且LSTM的訓(xùn)練結(jié)果也很好。因此,本文采用基于XGBoost和LSTM的融合模型對辛烷值損失進行預(yù)測,即對XGBoost的預(yù)測值和LSTM的預(yù)測值進行加權(quán)求和,進而得到最終的預(yù)測值D^31,如式(16)所示:
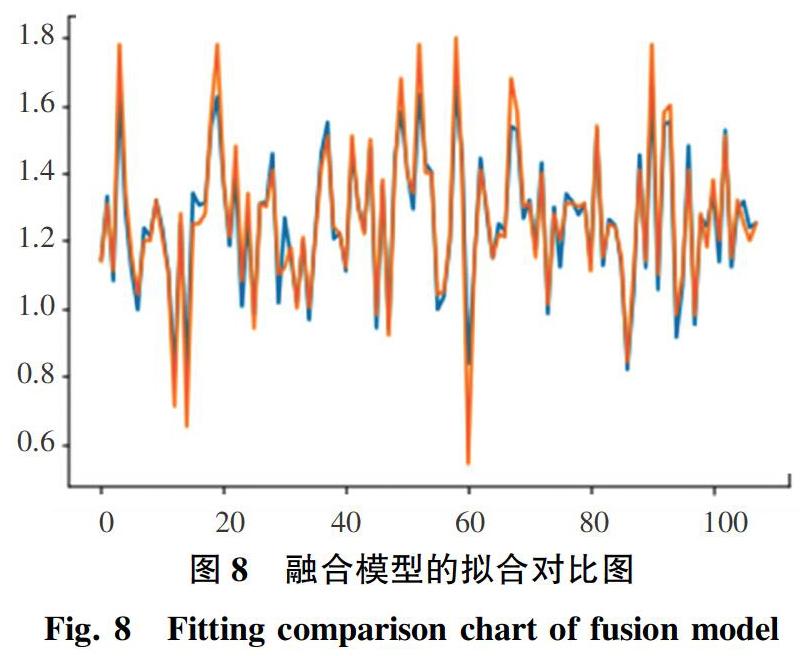
設(shè)定α=β=0.5,XGBoost的參數(shù)設(shè)置同表1,訓(xùn)練樣本與上文相同,融合模型的擬合對比如圖8所示。由圖8可以看出,融合模型的擬合效果并未有XGBoost模型的效果好,但考慮到訓(xùn)練樣本數(shù)據(jù)的數(shù)量并不多,可能存在過擬合問題,LSTM相較于XGBoost多考慮了時間相關(guān)性因素,進行了更深層次的數(shù)據(jù)挖掘。因此,當(dāng)前的融合模型雖然擬合效果不如XGBoost,但具有更強的魯棒性和適應(yīng)性,如果擁有更多的數(shù)據(jù)量,融合模型的表現(xiàn)會更好。
3 結(jié)束語
本文通過2種模型融合對石化企業(yè)的催化裂化汽油精制脫硫裝置辛烷值損失程度進行了預(yù)測,結(jié)果表明該模型在預(yù)測精準(zhǔn)度上有較好的表現(xiàn),能夠為有關(guān)部門對車用汽油質(zhì)量升級關(guān)鍵技術(shù)上提供可靠參考。
參考文獻
[1] ?王煒,劉宏偉,陳永杰,等. 基于LSTM循環(huán)神經(jīng)網(wǎng)絡(luò)的風(fēng)力發(fā)電預(yù)測[J]. 可再生能源,2020,38(9):1187-1191.
[2] 鄒玉瑩. 基于機器學(xué)習(xí)的票據(jù)轉(zhuǎn)貼現(xiàn)利率預(yù)測研究[D]. 南昌:江西財經(jīng)大學(xué),2020.
[3] ?楊軼男,任曄,毛安國,等. 影響催化裂化裝置汽油辛烷值變化的技術(shù)因素分析[J]. 煉油技術(shù)與工程,2019,49(6):32-35.
[4] 馬強,趙昌明. 降低S-Zorb裝置汽油辛烷值損失的優(yōu)化操作[J]. 當(dāng)代化工研究,2020(15):43-45.
[5] 劉寶,倪維起. S Zorb裝置汽油辛烷值損失影響因素分析[J]. 齊魯石油化工,2019,47(2):102-104,124.
[6] GERS F A, SCHMIDHUBER J, CUMMINS F. Learning to forget: Continual prediction with LSTM[J]. Neural Computation, 2000, 12(10):2451-2471.
[7] ?ZHANG Dahai, QIAN Liyang, MAO Baijin, et al. A data-driven design for fault detection of wind turbines using Random Forests and XGboost[J]. IEEE Access, 2018,6:21020-21031.
[8] 萬黎, 毛炳啟. Spearman秩相關(guān)系數(shù)的批量計算[J]. 環(huán)境保護科學(xué), 2008,34(5):53-55,72.
