基于卷積神經網絡的人群計數算法研究
2021-08-02 03:35:24向飛宇張秀偉
計算機技術與發展 2021年7期
向飛宇,張秀偉
(西北工業大學 計算機學院,陜西 西安 710129)
0 引 言
人群計數通過對圖像中人像特征的檢測來獲取人群數量與密度信息,對于道路監控圖像的人群計數可以快速地獲取實時的人群狀態信息,在分析商圈人流密度、預防疫情期間人群聚集以及踩踏事故等方面有重要意義。
傳統的人群計數方法主要有兩大類:基于目標檢測的Haar小波檢測法[1]、梯度方向直方圖檢測法[2]等嘗試在對圖像進行處理之后檢測到圖像中每一個獨立的人形或者移動的興趣點,從而同時獲得人群計數與每個人的位置信息,但是在面對高遮擋和高密度的場景下效果不佳;另一類方法基于對目標軌跡信息的跟蹤[3],通過對連續圖像或者監控視頻圖像的對比分析判斷出正在移動的人像,此類方法包括貝葉斯聚類方法[4]和KLT跟蹤器方法[5]等,在高遮擋場景效果很好,但是計算耗時較長,算法的實時性能不好,同時對于圖像的連續性有一定的要求,不適用于單張靜態圖像的人群計數。
近年的研究主要圍繞卷積神經網絡(convolution neural network,CNN)來展開,自2012年AlexNet[6]在ImageNet挑戰賽上獲得冠軍后,CNN被廣泛應用于圖像識別領域當中,陸續出現了ZFNet[7]、VGGNet[8]、GoogLeNet[9]、ResNet[10]等更加深層次也更加有效的卷積神經網絡。CNN的主要算法原理是將輸入圖像與不同大小的卷積核進行卷積,從而提取出不同大小的圖像特征信息,相比于普通的神經網絡模型將輸入數據轉化為一位向量的處理方式,CNN使用卷積進行特征提取能夠有效地獲得像素之間的空間關系,因此在圖像識別領域當中取得了極佳的效果。
具體到人群計數領域,由于CNN的經典網絡架構會使用全連接層將像素一維化為用于分類的固定長度的特征向量,無法在獲得人群計數的同時獲得人群密度圖像,因此全卷積神經網絡(fully convolutional network,FCN)[11]被提出用于人群計數。FCN將傳統CNN網絡結構中的全連接層改為反卷積結構,使得輸出由特定長度的特征向量變成與原始輸入圖像相同的特征圖像,同時解除了輸入圖像的尺寸限制。FCN對于人群計數的適用性使其成為最新網絡架構的基礎。為了解決人群計數算法中特征提取的空間信息相對粗略以及缺乏對不同通道間信息的處理能力問題,文中提出了一種具有注意力模型的全卷積神經網絡,通過對通道數據與空間數據的注意力模型來獲取更加細化的特征圖像。實驗證明融合了注意力模型與全卷積神經網絡的人群計數方法在多個數據集上的表現優于之前的方法。
1 人群計數網絡架構綜述
圖1為文中人群計數網絡架構示意圖,主要包括全卷積神經網絡以及注意力模型兩大部分,其中VGG-16卷積神經網絡骨干,擴展卷積層與后續的上采樣層構成一個全卷積神經網絡。為獲取更高的精確度與更多的特征信息,在擴張卷積層之后增加了空間注意力模型(spatial-wise attention model,SAM)[12]與通道注意力模型(channel-wise attention model,SAM)[13],最終輸入的人群圖像通過上采樣層被轉化為分辨率大小相同的人群密度特征圖像。
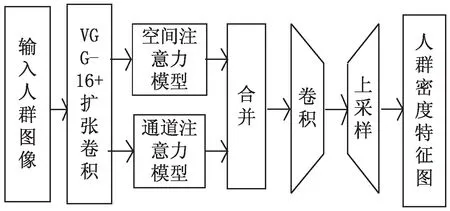
圖1 人群計數網絡架構
2 全卷積神經網絡
全卷積神經網絡FCN是在傳統卷積網絡CNN的基礎上,將最后的全連接層替換為反卷積層,從而將接受的輸入圖像尺寸從固定的尺寸擴展到任意尺寸,同時不再輸出不具有空間上下文關系的特征向量,而是輸出與原始圖像相同尺寸的包含空間特征信息的特征圖。基于這些特點,全卷積神經網絡被廣泛應用于圖像處理領域,尤其是適用于需要在獲得人群密度計數的同時獲得人群密度圖像的人群計數領域。標準的全卷積神經網絡一般包括三個部分:卷積層、池化層和上采樣層。
2.1 卷積層
卷積層是用于提取圖像特征的經典結構,每一層包含多個具有權重和偏置的卷積單元,可以在前向傳播的過程中提取輸入圖像的特征信息轉化為特征映射,在反向傳播中學習每個卷積單元的相關參數。圖2為文中網絡使用的卷積層示意圖,由VGG-16卷積神經網絡的前10個卷積層以及使用擴張卷積[14]的6個卷積層組成,圖中[k3,3-s1-c64-d2-R]表示卷積核為3×3,步長為1,輸出為64通道,擴張間隔為2,使用RELU為激活函數的卷積層。使用VGG-16預訓練網絡可以有效地減少訓練用時,同時保留很高的精確度。在整個網絡架構當中沒有使用全連接層,因此輸入圖像可以是任意尺寸的人群密度圖像,從而使得整個網絡適用于更多的應用場景。由于VGG-16卷積層會導致特征圖像變小,使得最終經過上采樣的密度圖分辨率降低,為了在不降低分辨率的情況下獲得高精度的特征密度圖,使用了擴張卷積層在VGG-16骨架之后對512通道的輸出進行擴張,最終生成64通道的特征圖像。
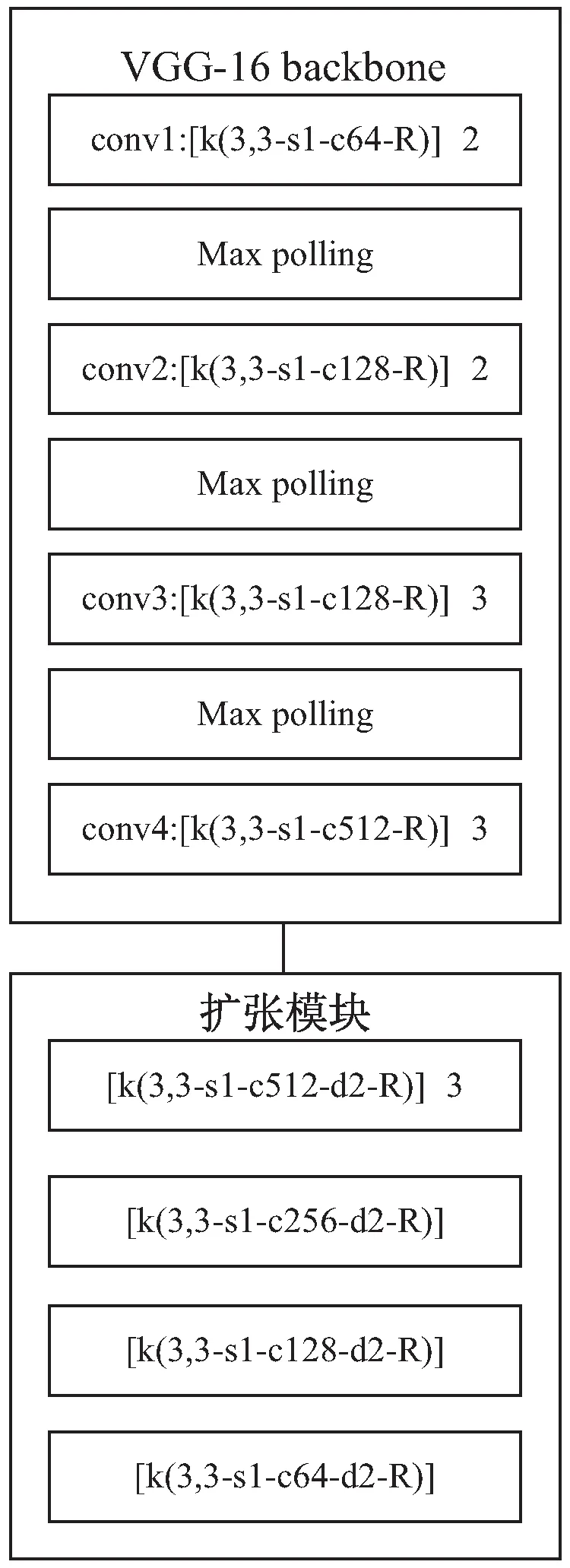
圖2 卷積層示意圖
2.2 池化層
池化層又稱下采樣層,指的是將同一通道的每個2×2非重疊區域經過處理輸出為一個數據作為下一層的輸入,用于降低網絡中參數的數量并且降低對訓練數據過擬合的風險。常用的池化層包括最大池化和平均池化,最大池化使用2×2區域的最大值作為輸出,能夠降低卷積層的參數誤差從而保留更多的紋理信息,平均池化使用2×2區域的平均值作為輸出,減少鄰域大小受限導致的估計值方差增大,更多地保留圖像的背景信息。在VGG-16卷積神經網絡架構中,前10個卷積層內增加了三個最大池化層。
2.3 上采樣層
上采樣層也稱為反卷積層或者轉置卷積層,是將輸入數據插入到更大的填充圖像當中,再進行卷積,以獲得與輸入圖像相同尺寸或者更大尺寸的輸出圖像的操作。在文中網絡中,輸入圖像經過卷積層和注意力模型的特征提取后得到的較小分辨率的圖像,由1×1的卷積核將通道數降至1后,經過8個上采樣層恢復到與輸入圖像分辨率大小相同的特征密度圖像[15],相當于直接輸出了與輸入圖像分辨率大小相同的人群密度特征圖。
3 注意力模型
自卷積神經網絡被應用于圖像識別領域以來,針對這一深度學習網絡架構有著多次的改進與創新。人群計數在圖像識別領域之中屬于目標檢測的范疇,即對于有著多個目標的輸入圖片,要檢測出所有目標的位置及其對應的類別。傳統的卷積神經網絡在面對目標檢測問題的時候主要是使用窮舉法或者滑窗法[16]來窮舉目標可能出現的所有區域,然后針對這些區域進行檢測、訓練和預測,這一過程有以下幾個缺點:
(1)使用窮舉法與設計大量不同尺寸的滑窗都需要占用大量的內存;
(2)大量非目標的區域被用于訓練和預測,訓練和計算的效率都比較低;
(3)對于選定的目標區域的訓練放棄了區域周圍的空間信息,弱化了區域與整體圖像之間的空間聯系。
為了解決上述的缺點,選擇性搜索算法[17]被提出用于產生潛在物體候選框(region of interest,ROI),基于這一思想產生了著名的目標檢測網絡架構R-CNN[18]。該算法通過對顏色相似度、紋理相似度、尺寸相似度、填充相似度等特征的加權來計算兩個區域之間的相似度,依次將相鄰區域中相似度最高的區域進行合并,從而獲得潛在物體候選框。然而,選擇性搜索算法雖然解決了內存占用以及非目標區域的問題,最終被輸入進CNN的輸入數據還是目標附近的一部分像素,不包括目標區域與整個圖像之間的上下文信息,在訓練和分析過程中放棄了區域與整體圖像之間的空間聯系。在人群計數領域,原始圖像當中人群的密度分布往往是有一定規律的,例如在一張道路監控圖像當中高密度的人群會集中在圖像兩側的人行道區域,而一張地鐵車廂人群圖像當中高密度人群會聚集在圖像中部,這樣的特征使得在人群計數領域,目標區域與原始圖像之間的空間關系是非常有價值的學習特征,而使用選擇性搜索算法就會損失對這一重要特征的研究與訓練,從而影響最終的預測效果。為獲取人群特征與原始圖像之間的空間關系,文中使用了注意力模型。
注意力模型起源于人對物體的辨識過程:人觀察一幅圖片的時候并非直接觀察整個圖片的所有信息,而是對圖片的某一部分進行聚焦,例如看到一張風景圖的時候人的視線會分別聚焦到遠方的山,近處的水等不同的目標區域。從計算機視覺的角度,就是在識別一張圖片的時候對于每個不同的像素區域有著不同的權重。對于重要的區域例如目標區域的周圍,較大的權重使得關鍵區域對于最后的特征圖像影響力較大;對于非重要的區域例如背景區域,較小的權重使得這些區域對最后的特征圖像影響較小甚至沒有影響。而這些權重可以通過神經網絡進行訓練學習,從而使得神經網絡獲得類似于人的注意力效果。針對人群計數對于圖像空間特征與通道特征的需求,主要使用兩種不同的注意力模型:空間注意力模型(spatial-wise attention model,SAM)和通道注意力模型(channel-wise attention model,CAM)。
3.1 空間注意力模型
圖3為空間注意力模型的架構示意圖,對于前置的CNN骨干輸出的大小為C×H×W的輸出圖像,在與三個1×1的卷積核進行卷積以減少參數和跨通道整合后,分別重整為三個不同大小的輸出:S1與S3大小為C×HW,S2大小為HW×C,在對S1和S2進行矩陣乘法和softmax歸一化運算后,獲得一張大小為HW×HW的空間注意力圖像。為了使得最后輸出的特征圖像同時包含原有的圖像特征信息和由注意力模型提取的大范圍上下文空間信息,同時為了使最終輸出與輸入的大小尺寸相同,將上一步獲得的HW×HW的圖像與重整后的S3進行矩陣乘法,獲得大小尺寸為C×H×W的空間注意力圖像,再與最初的骨干輸出進行帶參數的加權和,并通過1×1的卷積核來學習這一參數。整個過程用公式表達為:
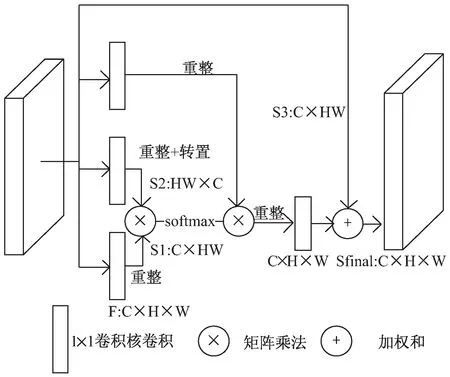
圖3 空間注意力模型示意圖
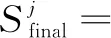
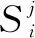
3.2 通道注意力模型
空間注意力模型提取的是單通道上大范圍的上下文信息,關注于人群在原始圖像上的空間分布特征。除了空間分布特征以外,對于高密度的人群計數原始圖像,目標區域和背景區域往往擁有較為相似的紋理特征,這使得背景區域的空間特征容易對目標特征產生額外的影響,使用通道注意力模型可以有效增加目標特征的權重,使得最終結果受到背景區域的影響減少。
通道注意力模型與空間注意模型整體上架構類似,如圖4所示。最初的特征圖僅與一個1×1的卷積核進行卷積降維后,同樣重整為三個不同大小的輸出:C1與C3大小為C×HW,C2大小為HW×C,在對C1和C2進行矩陣乘法和softmax歸一化運算后,獲得一張大小為C×C的通道注意力圖像。將上一步獲得的C×C的圖像與重整后的C3進行矩陣乘法,獲得大小尺寸為C×H×W的通道注意力圖像,最后與空間注意力模型一樣與初始圖像進行加權和。用公式表達為:
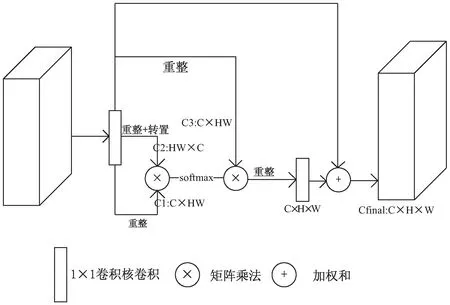
圖4 通道注意力模型示意圖
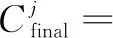
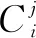
4 模型訓練及測試結果
4.1 實驗環境及相關參數
實驗采用的處理器為英特爾i5-9600KF,運行內存為8 GB,使用GPU加速,GPU為RTX2070super,顯存為8 G,開發環境為pycharm;訓練數據被預處理為576×768的大小,整個網絡的初始學習率為10-5,并在每個批次學習完成后下降為之前的0.995倍;每個批次包括4張圖像,使用Adam算法進行優化,在進行250次迭代之后進行測試。
4.2 損失函數
在人群計數中,常用的損失函數包括平均絕對值誤差(mean absolute error,MAE)和均方誤差(mean squared error,MSE),分別定義為:
4.3 實驗結果
為了測試網絡的性能,在ShanghaiTech數據集[19]和NWPU-Crowd數據集上進行了模型的訓練與測試。ShanghaiTech數據集是上海科技大學在2016年國際計算機視覺與模式識別會議(IEEE conference on computer vision and pattern recognition,CVPR)的會議論文中發表的人群計數數據集,包括兩個部分─Part A和Part B,共包含1 198張圖像。Part A的平均分辨率為589×868,平均人群計數數量為501,Part B的平均分辨率為768×1 024,平均人群計數數量為123。NWPU-Crowd數據集是西北工業大學于2020年發表的大型人群計數圖像數據庫,包括5 109張圖像,平均分辨率為2 191×3 209,平均人群計數數量為418。表1給出了相關算法在ShanghaiTech數據集上的表現,除在Part A的MSE上表現不如CP-CNN,其余項均有一定提升。表2給出了相關算法在NWPU-Crowd數據集上的表現,文中方法在MAE與MSE上均表現最佳,較之前算法有可觀的提升。

表1 ShanghaiTech數據集上的表現
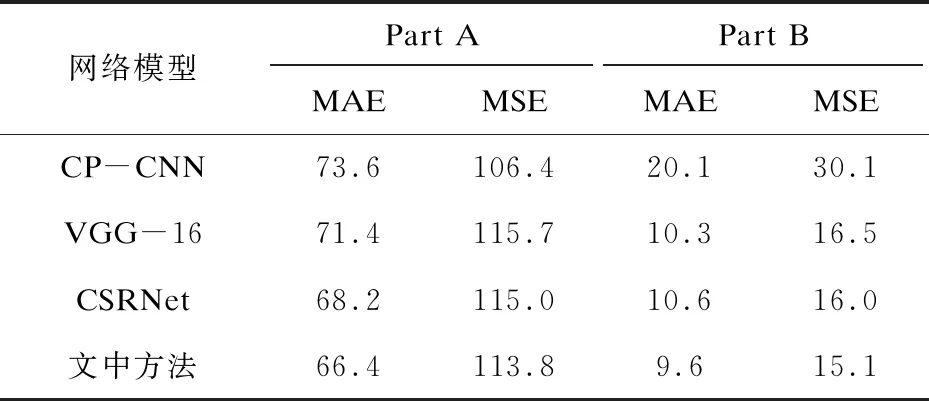
續表1
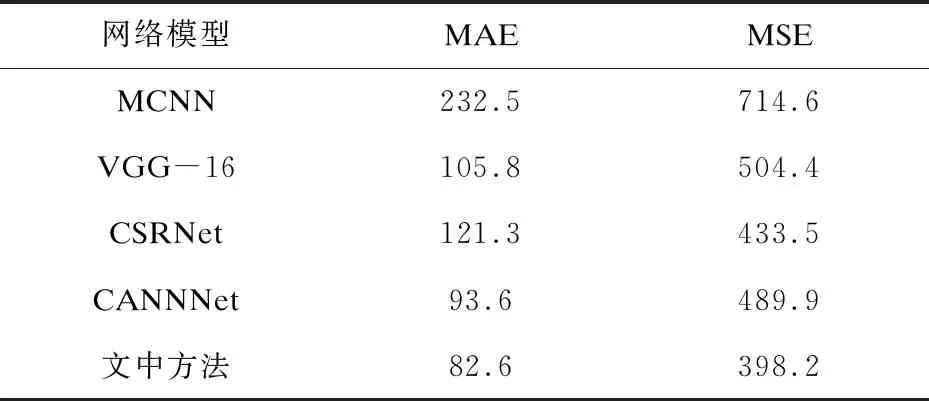
表2 NWPU-Crowd數據集上的表現
5 結束語
基于卷積神經網絡的人群計數系統在傳統卷積神經網絡的基礎上融入注意力模型與全卷積神經網絡架構,在保留卷積神經網絡對圖像特征提取的基礎上,增加了對于圖像整體空間信息和通道信息的編碼與學習,實現了對人群圖像的準確計數與人群密度圖生成,相較于之前的算法在準確度上有可觀的提升。在未來的研究中,可以嘗試對神經網絡進行輕量化,在盡可能保證準確率的基礎上將人群計數擴展到移動端和小型設備上,實現從圖像獲取到計數識別的一體化。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
