一種馬田系統的無線傳感器網絡數據異常檢測方法
2021-07-27 04:59:24張星亮
新一代信息技術 2021年5期
關鍵詞:特征
張星亮
(河北地質大學 信息工程學院,河北 石家莊 050031)
0 引言
無線傳感器網絡(Wireless Sensor Network,WSN)是由具備通信能力和計算能力的傳感器節點組成的自組網絡。由于節點低成本且部署靈活等特點,現已廣泛用于農業環境監測、地質數據采集、軍事偵察等眾多相關領域。無線傳感器網絡往往部署在無人管理的或者惡劣的環境中,可能會受到其他信號的干擾、自身電量限制和環境異常變化而導致數據出現異常,進而使得無法進行后面的數據計算和分析。因此在部署無線傳感器網絡時需要將對數據的異常檢測考慮在內。
近些年來,一些專家和學者對無線傳感器網絡中的異常數據檢測做了很多突出貢獻。Bilal[1]等人提出了一種基于 K-medoid定制聚類技術的混合異常檢測方法,該方法適用于無線環境下包括誤向和黑洞攻擊的混合異常檢測。Mahmood[2]等人一種基于局部時間序列的無線傳感器網絡數據噪聲與異常檢測方法,采用自適應貝葉斯網絡作為分類算法,能夠對每個傳感器節點的異常值進行局部預測和識別。Murad[3]等人提出了一種基于單類主成分分類器(OCPCC)的WSN分布式異常檢測模型,該模型利用了封閉鄰域中感測數據之間的空間相關性來對異常進行檢測。鄭文添[4]針對WSN的異常數據檢測,以PCA算法為基礎結合馬氏距離提出改進型分布式主成分異常數據檢測方案,能夠提高了網絡中異常數據的檢測性能并同時降低網絡中的通信資源開銷。鄧麗[5]等人提出一種融合數據流時空特征和多分類模型的異常檢測算法,算法首先基于 Markov鏈提取傳感器數據流的時空特征,然后將時空特征作為多分類卷積神經網絡模型的輸入特征,對數據流進行異常檢測及異常類型識別。
馬田系統是一種用于多變量數據的判別預測方法,并且馬氏系統的應用十分廣泛。Ning Wang[6]等人提出了一種基于改進 MTS的設備狀態特征識別與選擇模型,研究了模型的兩個方面,即原始馬氏空間的構造和閾值的確定。Wenhe Chen[7]等人利用馬田系統通過六個維度:收入、教育、健康、生活、資產和住房,能夠準確識別貧困戶和非貧困戶。
彭宅銘[8]將馬田系統應用在對滾動軸承的狀態監測中,根據時域、頻域和自適應白噪聲來分析軸承故障發展趨勢。彭宅銘[9]利用航空發動機的健康狀態進行評估,為航空發動機的狀態分析提供了一種新方法。王海燕[10]和吳敬之[11]分別將馬田系統應用到航空客運服務的評價和工業運行質量的評價,拓展了馬田系統的應用。
本文將利用馬田系統來對無線傳感器網絡中所采集數據進行異常檢測。
1 馬田系統
馬田系統是由日本統計學家田口玄一博士提出的一種用于多變量數據的判別預測方法。馬田系統是由馬氏距離和田口方法組成。馬氏距離不僅僅是一種距離的度量,而且還可以用來表示數據之間的協方差距離。它是把屬性之間的相互聯系考慮在內,并且是與數據的測量單位無關。馬氏距離是用來區分異常數據和正常數據,將區分之后的正常樣本的馬氏空間上通過田口方法的正交表和信噪比來對主要的特征變量進行篩選,達到優化特征測量表,進而為后面的計算降低復雜度。將優化之后的馬氏空間對異常數據和正常數據進行閾值劃分,當再遇到未知的樣本數據時,可以直接利用已經計算好的閾值,直接進行分類和預測。利用馬田系統將異常數據劃分出來之后,對于異常數據將不再信任,本文將利用第四章方法對不信任的異常值進行補值。
本文將具體的實施步驟可以分為4步:構建馬氏空間、馬氏空間的驗證、馬氏空間的優化、分類和診斷。
1.1 構建馬氏空間
馬氏空間就是由馬氏距離構建的矩陣,馬氏空間對馬氏系統的有效性和可靠性有著極其重要的影響,這也是構建馬田系統最首要的步驟。首先需要選出進行構建空間的正常樣本并確定特征量,先將選定的特征變量進行計算平均值和標準差,并以此來對數據進行標準化。將標準化的正常樣本的馬氏距離構成馬氏空間。
馬氏距離是由印度統計學家馬哈拉諾比斯提出的,是用來表示協方差的距離,一種來表示未知特征集合相似度的度量方式。馬氏距離相對于歐氏距離來說,馬氏距離不僅對變量之間的相關性極其敏感,而且還能消除變量之間的相互干擾;而歐氏距離只是單純的計算變量之間的距離值,無法對變量之間的相關性和變量之間是否存在相互干擾做出判斷。
馬氏距離通過被測樣品與馬氏總體之間的距離,來體現樣本之間的相似程度。本文中使用施密特正交法對馬氏距離進行計算,所以這里只對施密特正交法進行介紹。對于逆矩陣法的馬氏距離求解的具體步驟如下:
(1)假設多元系統中有p個變量,并設為vj,其中j= 1 ,2,3,… ,p,通過p個變量來進行界定正常數據的樣本空間。
(2)在系統的p個變量下,進行收集容量為n的樣本數據,數據vij是第j個變量中第i次的測量值,其中i= 1 ,2,3,… ,n。
(3)將測量的樣本數據進行標準化,
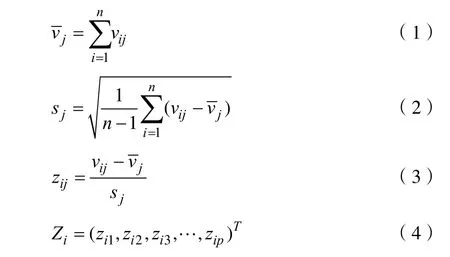
其中Zi表示正常樣品中第i個標準化的數據,其中i= 1 ,2,3,… ,n。
通過相關系數矩陣可以得到馬氏距離,但是相關矩陣可能存在多重共線問題,進而影響模型的穩健性。為了避免多重共線問題,可以利用施密特正交法來進行馬氏距離的計算。先是通過對p個變量進行標準化為:
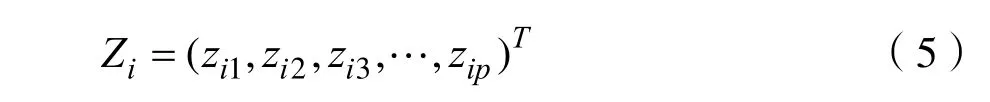
其中i= 1 ,2,3,… ,n。將標準化的向量組進行施密特正交化。
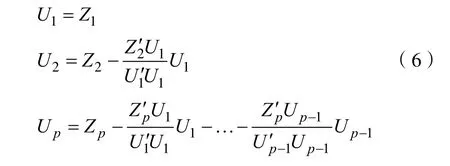
進而得到的馬氏距離為:
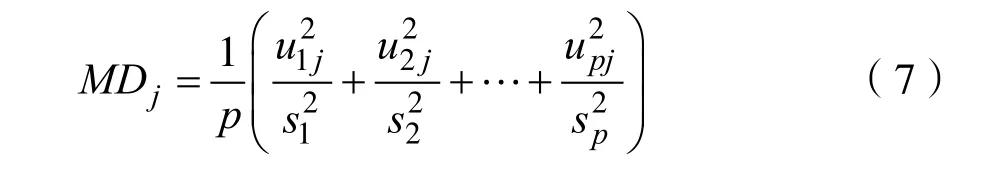
1.2 馬氏空間的驗證
由于馬氏空間是通過正常樣本進行構建的,所以馬氏空間的有效性還需要檢驗,若該馬氏空間能夠將異常數據和正常數據進行區分,那證明該馬氏空間是有效的,否則需要重新構建馬氏空間。在進行馬氏空間驗證時,需要計算異常數據的馬氏距離的均值,并以此與正常數據的馬氏距離均值進行比較,如果大于正常數據的馬氏距離均值,那說明由第一步構建的馬氏空間是有效的。其中在計算異常數據的馬氏距離時,用到的樣本均值和標準差均是采用正常樣本的。
本文中的異常數據的馬氏空間也是利用正常數據的均值和標準差將數據標準化,利用施密特正交化構建的異常數據的馬氏空間。如果正常數據的馬氏空間遠遠小于異常數據的馬氏空間,則說明由正常數據構建的馬氏空間有效,否則需要重新選擇樣本數據來重新構建馬氏空間。
1.3 馬氏空間的優化
在選定的所有原始變量中,并不是所有的變量都對異常檢測有貢獻,所以在構建馬氏空間之后要對馬氏空間進行優化,這樣不僅能對數據降維,也能為后面的計算降低復雜度。本文使用正交表和信噪比來對馬氏空間進行優化。
1.3.1 正交表
正交表是帶有規則的設計表格,而在馬田系統中則是根據初始變量的不同來選擇相對應的正交表。在正交表中,每一行對應著每一組實驗,“1”是選擇該變量,“2”是不選擇該變量,這樣將會對變量進行選擇,將被選擇的變量來組成馬氏空間。
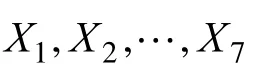
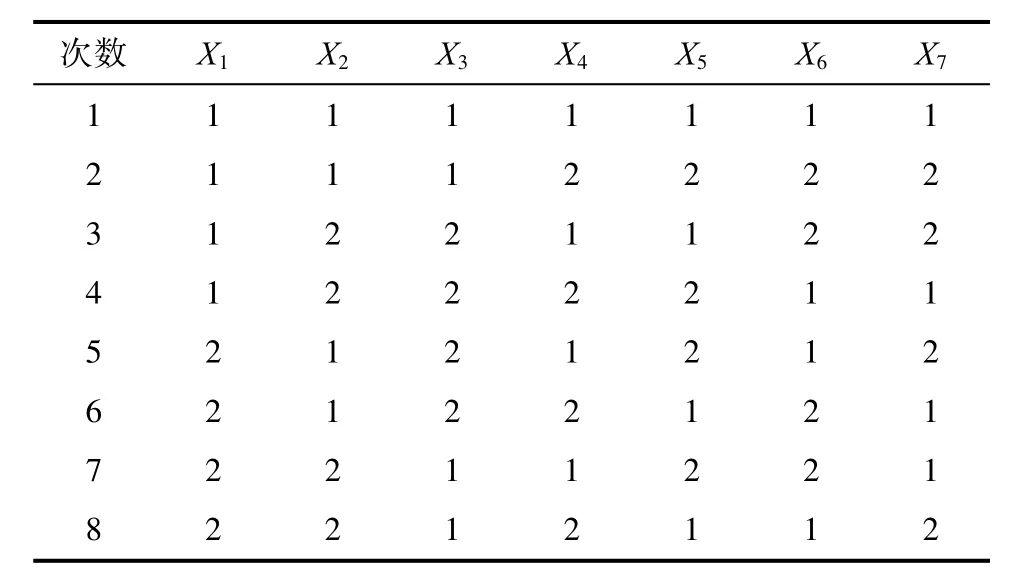
表1 L8(27)的正交表Tab.1 The orthogonal table of L8(27)
在表中第一次試驗對應的變量選擇為1、1、1、1、1、1、1,即每個特征變量的水平為“1”,由此可得組成馬氏空間的特征變量為X1、X2、X3、X4、X5、X6、X7。而表中的第二次試驗的變量選擇為 1、1、1、2、2、2、2,前三個的特征變量都為“1”,后四個的特征變量都為“2”,由此組成的馬氏空間的變量為X1、X2、X3。將使用選擇的特征變量來計算正常樣品和異常樣品的馬氏距離。
1.3.2 信噪比
信噪比(Signal Noise Ratio,SNR)通常是用在通信行業中,用于對電子設備或電子系統的通信的評價。在通信行業中,信噪比是接收到的信號功率和噪聲功率的比值;而在馬田系統中是通過信噪比來使馬氏距離的偏離程度放大,進而能夠選擇對異常檢測貢獻較大的特征變量。本文采用正交表和信噪比來篩選特征變量。
信噪比不僅能評價篩選之后的特征變量的可靠性和穩健性,還能對篩選的特征變量組的功效性進行評價。當對異常數據進行評價時,在不了解異常數據的情況下,相對于正常數據,希望異常數據的偏離程度越大越有利于數據的辨識,本文采用望大特性信噪比來進行計算。假設異常樣本的數目為n,采用施密特正交法計算得到的馬氏距離為MD1,MD2,… ,MDn,則正交表進行的第i次實驗的望大特性信噪比為:
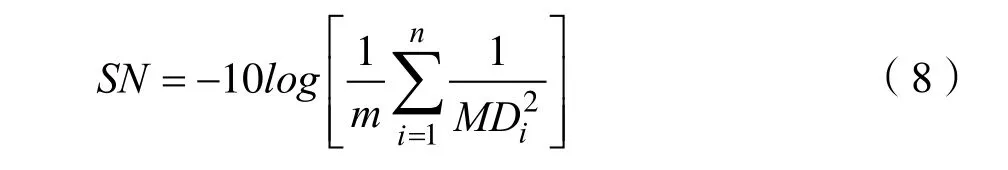
在引入信噪比之后,需要對特征變量進行部分剔除和保留,因此引入信息增益差ΔSN:

1.4 分類和診斷
將篩選過后的特征變量重新計算正常數據和異常數據的馬氏距離和馬氏空間,并與原始馬氏空間進行對比,驗證優化后的馬氏空間的是否改善。利用優化后的馬氏空間和閾值λ來對未知的樣本進行分類和識別。對于未知樣本的分類和識別,本文采用f極大值方法來確定閾值。
在馬田系統的應用及實踐中,閾值的確定對異常數據的判斷有著極其重要的意義,閾值的好壞直接影響著系統的好壞以及對數據的判斷結果。馬田系統的閾值確定一直都備受關注,田口玄一博士利用二次損失函數(Quality Loss Function,QLF)對閾值進行計算,二次損失函數是憑借專業人員的判斷和損失數據來對閾值進行判斷,這樣得到的閾值會有很大的主觀性。本文采用f極大值法來確定閾值。
設T為閾值,通過施密特正交法計算的正常樣本的馬氏距離MDi,i= 1 ,2,…,n,而異常樣本的馬氏距離為MDi,i=n+ 1 ,n+ 2,…,n+m。

其中i= 1 ,2,… ,n。
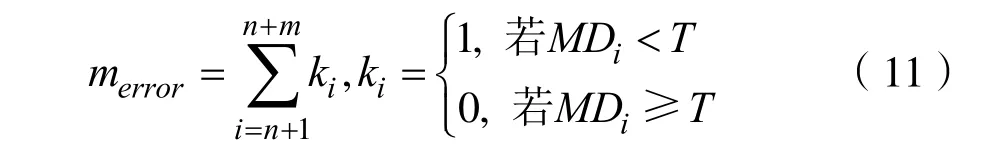
其中i=n+ 1 ,n+ 2,… ,n+m。
則正常樣本進行分類的正確率為:
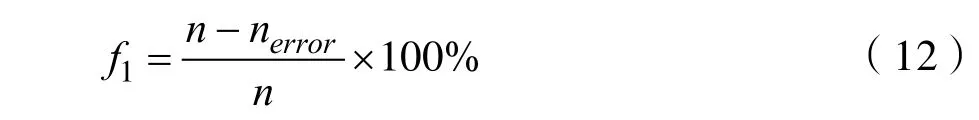
異常樣本進行分類的正確率為:

設極大值f=f1×f2,f值最大時求得T值為馬田系統的閾值。具體算法表示
在閾值確定之后,對于未知的樣本數據,可以利用本文提到逆矩陣法、施密特正交法、伴隨矩陣法構建相對應的馬氏空間,并通過計算好的閾值與馬氏距離相比較,進而能夠對異常數據進行判定和識別。
2 實驗分析
2.1 數據來源
本文使用python進行實驗,并對真實數據集上進行本文實驗,測試所用的數據集是由部署在英特爾-伯克利實驗室的54個傳感器節點在36天內產生的采集數據。這些采集數據分別是對溫度、濕度、光照強度和節點電壓每隔30 s進行一次采樣所得的采集值。本文選取節點19在2004年3月8日所采集的數據,每隔15分鐘進行一次數據選取。
2.2 實驗分析
本文將以時間序列為依據,采用隨時間的變化的傳感器的數據為馬氏系統的特征向量,特征向量將由溫度、濕度、光照強度、電壓組成。表2將要進行異常數據監測的特征變量。
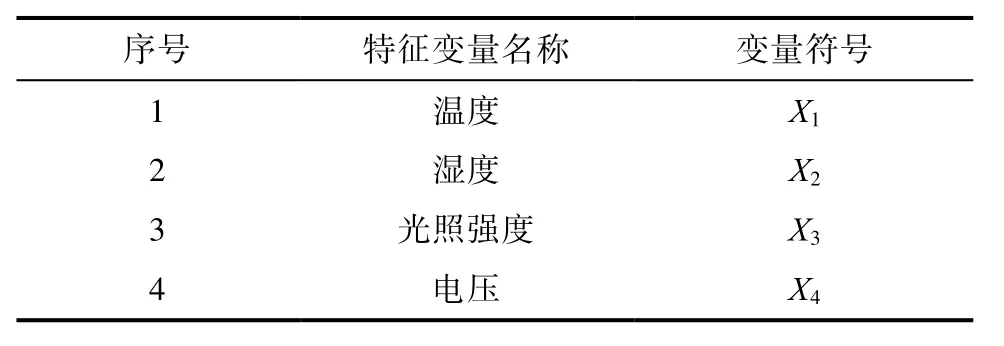
表2 農業數據的特征變量Tab.2 Characteristic variables of agricultural data
利用施密特正交法對特征變量計算正常樣本的馬氏距離,如表3所示。
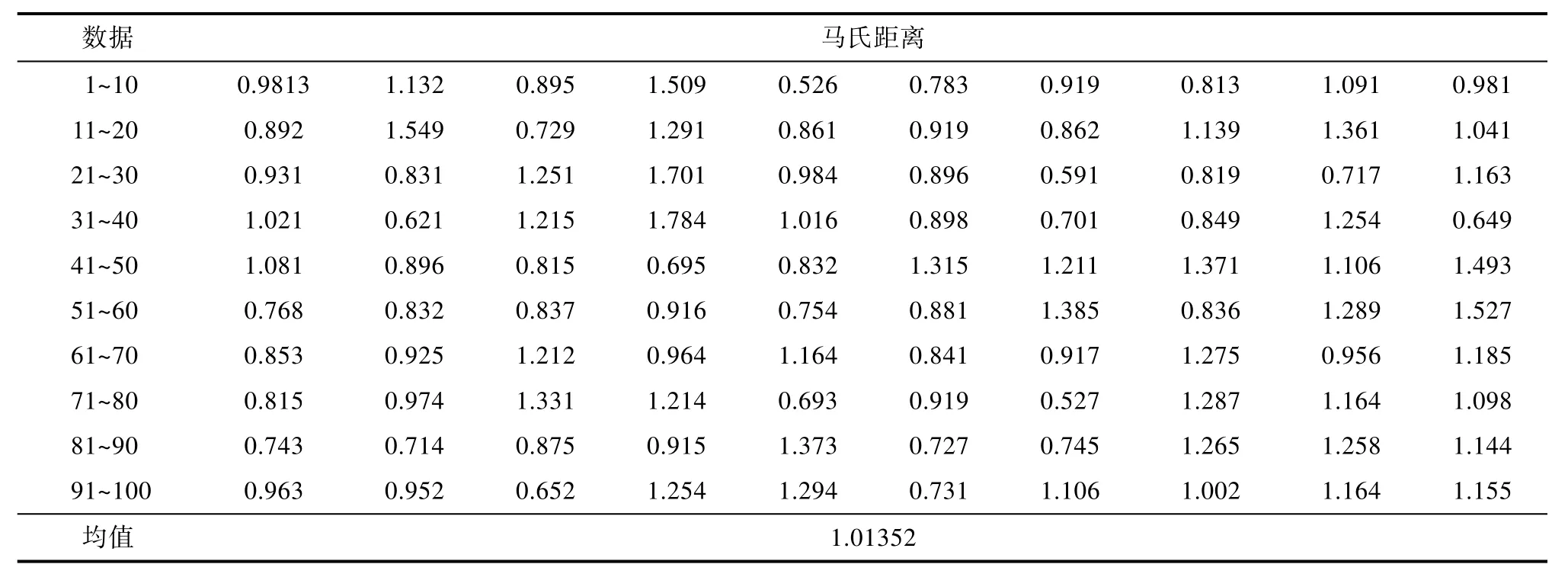
表3 正常樣本的馬氏距離表Tab.3 Mahalanobis distance table of normal samples
通過表 3正常數據的馬氏距離可以看出,馬氏距離的均值 1.01352≈1,但可以看出選取的正常樣本數據是有效的,但是單從正常數據的馬氏距離是不能看出該特征變量的數據是否有效,還要與異常數據的馬氏距離進行比較,通過觀察異常樣本的馬氏距離的偏離程度來確定選取的數據是否有效。
異常數據是正常數據之外的數據,在本文中將模擬異常數據,使用python隨機產生30個異常數據進行試驗。本文將模擬采集數據錯誤、終端節點掉電、節點被攻擊、發送數據超時等多種情況的發生,盡可能的使異常數據還原到真正的異常情況發生。異常數據的馬氏距離如表4所示。

表4 異常樣本的馬氏距離表Tab.4 Mahalanobis distance table of abnormal samples
由表 2中數據可以得知,異常數據的馬氏距離的均值為 8.0142,并且與正常樣本的馬氏距離存在明顯的差異,異常樣本的馬氏距離是遠遠大于正常樣本的馬氏距離,由此創建的馬氏空間是有效的。若是異常樣本的馬氏距離與正常樣本的馬氏距離存在的數據差異較小的話,則需要重新選擇數據來重新構建空間。
2.3 馬田系統的優化
在系統中并不是數據的特征量越多就代表數據越詳細,就能較全面的展現系統中的變化。有些特征量能直觀的反應農業數據的變化,有利于提高識別數據中存在的異常值,但是有些數據是不能直觀的展現數據變化的,因此需要將這些不能直觀展現數據變化的冗余數據給去除掉。在本文中則使用正交表和信噪比進行冗余數據的篩選,篩選出對判別異常數據有用的特征變量,從而能夠達到降維的目的。
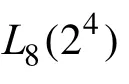
其中“1”表示選擇該特征變量進行計算信噪比,“2”則相反,即不選擇該變量進行計算信噪比。每一行都對應所選取的特征變量來構建馬氏空間,即每行對應著一個馬氏空間,由表中可知總共為8組實驗方案。在選定每行的特征變量之后,再進行計算選定之后異常條件下的馬氏距離,最后再計算馬氏距離所相應的信噪比。
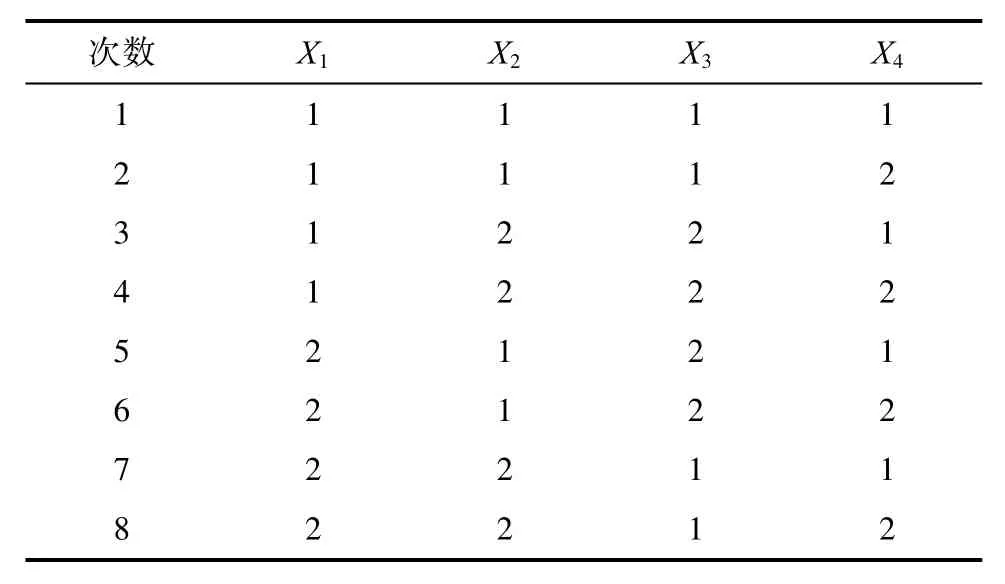
表5 L8 (24)的正交表及變量選擇Tab.5 The orthogonal table of L 8 (24)and variable selection
在選定各組特征變量后,通過對各組的被選中的異常情況下數據進行標準化和施密特正交化,進而得到馬氏距離而構成的子馬氏空間。30組異常條件下的特征變量在表4重新構建的馬氏空間下所對應的馬氏距離的均值,如表6所示。

表6 8 次實驗所對應的馬氏距離的均值及信噪比Tab.6 Mean value and SNR of Mahalanobis distance corresponding to eight experiments
在計算正交表所重構的馬氏距離和馬氏距離所對應的信噪比之后,還需要與重構馬氏空間后剩下的部分特征變量所形成的信噪比進行對比,進而形成信息增益,如表7所示。
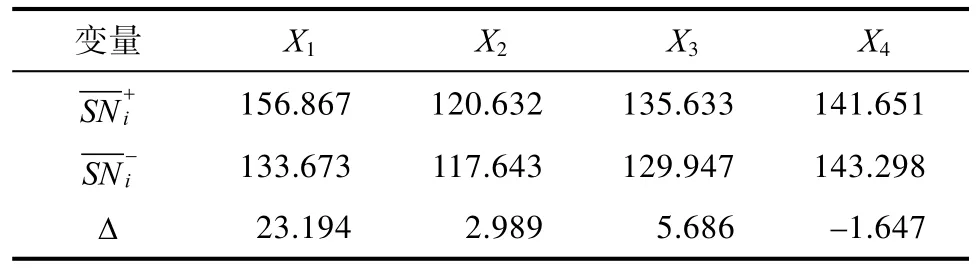
表7 信息增益表Tab.7 Infor mation gain table
2.4 分析與診斷
在多元系統變量中,決策閾值對判別的有效性有著重要的作用。傳統的馬田系統使用質量損失函數方法確定決策閾值,但是真實情況下質量損失是專業人員根據平常的經驗和積累規定的,所以質量損失函數在確定閾值的過程中會存在主觀性,由此方法得到的閾值準確度不高。采用f極大值方法來確定閾值,為了使是實驗結果準確本文采用窮舉法來確定閾值,雖然消耗的時間長點,但是整體具有較高的準確性。具體的算法描述如算法1所示。
算法1f極大值計算閾值偽代碼表示
Algorithm.1 Pseudo code representation of f-max calculation threshold
f極大值計算閾值偽代碼表示
輸入:正常樣本的馬氏距離、異常樣本的馬氏距離。
輸出:判斷正常樣本馬氏距離的閾值T。
MD_Nor_Data、MD_Abnor_Data分別是正常數據和異常數據所對應的馬氏距離。
Step.1whilej< max(MD_Nor_Data)/*使用最大馬氏距離來當作循環的終止點*/
Step.2forindextolen(MD_Nor_Data)
Step.3 統計正常數據的馬氏距離中大于j的個數
Step.4forindextolen(MD_Abnor_Data)
Step.5 統計異常數據的馬氏距離中小于等于j的個數
Step.6 記錄正常數據馬氏距離的正確率f1
Step.7 記錄異常數據馬氏距離的正確率f2
Step.8fi←f1 *f2
Step.9 最大的fi就是馬田系統的閾值T
Step.10endwhile
通過上文的正常樣本馬氏距離和優化后的異常樣本的馬氏距離,利用f最大值方法,以0.0001為精度進行遍歷,得到的最佳閾值點的馬氏距離為3.742。通過農業物聯網節點所采集的數據進行分類計算,在異常情況下進行診斷的準確率為80.13%。雖然會消耗一點時間,但是得到的正常樣本的正確分類率是比較高的。
3 結論
針對數據樣本中存在的異常數據,本文提出使用馬田系統進行異常檢測,利用施密特正交法分別計算正常數據和異常數據的馬氏距離。大量的數據樣本經過正交表和信噪比降維后,能夠大大減少計算量,之后使用f極大值方法計算出閾值。通過英特爾-伯克利實驗室采集的真實數據進行異常檢測實驗,并能夠對異常數據進行有效的識別。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
