一種高效的不確定圖上k步可達查詢處理算法
2021-07-27 04:59:16周軍鋒
新一代信息技術 2021年5期
關鍵詞:方法
仲 悅,杜 明,周軍鋒
(東華大學,上海 201620)
0 引言
k步可達查詢用于研究在給定的數據圖上,起始點u是否能在路徑長度不大于k的前提下到達目標頂點v。該研究有著廣泛的用途[1-3],例如在人際關系網絡圖[4]中,查詢兩個人能否通過 k個中間好友構成熟人關系;道路網絡[5]中,用以查詢用戶是否可以從一個起點經過k條道路到達目的地等。
目前已有的 k步可達查詢研究都是基于確定圖[6-10],然而不確定圖[11]在實際生活中隨處可見,此時兩個實體之間的聯系的強弱程度表現為邊上的概率權值。例如,在道路網絡中時常會出現擁堵的情況,而擁堵的嚴重程度可以用概率來刻畫,從而導致本來可達的路徑暫時性不可達;以及路由網絡中,傳感器測量誤差導致兩個路由之間的信號不穩定也會產生不確定的邊。當給定一個不確定圖,k步可達查詢不但要求兩點間可達,而且還要求出可達的概率。最樸素的方法是枚舉所有的可能世界及其出現概率,接著計算每一個可能世界上u到v的可達情況,將結果相加。而每一個可能世界由于邊的出現情況不同,無法用預先處理的索引對不同的可能世界進行查詢。一個n條邊的不確定圖有2n個可能世界,呈指數級。因此,即使該方法能得到最精確的結果,當數據圖達到比較大的規模后,這種枚舉法顯然無法進行,不具有擴展性。
針對上述問題,本文提出一種兩階段查詢方法,用于加速不確定圖上k步可達查詢的處理。其基本思想是:對可達和不可達的查詢基于不同索引分別處理。對不可達查詢,提出基于頂點覆蓋的高效索引來快速檢測是否k步不可達。對可達查詢,構建位向量索引提前存儲可能世界來加速判斷。其總體思想是根據大數定律用抽樣近似法進行計算,再用較小的內存提前存儲抽樣結果。實驗結果驗證了本文提出的索引和查詢方法 kRP的高效性。
1 問題定義及相關工作
1.1 問題定義
給定一個有向無環不確定圖G=(V,E,P),其中V是圖中所有頂點的集合,E是圖中邊的集合,(u,v)表示從頂點u出發到頂點v有一條邊,在有向圖中(u,v)和(v,u)是兩條不同的邊,P是所有邊上概率的集合,且P={pi|0<pi≤1,pi為第i條邊上的概率權值}。
以下介紹不確定圖、可能世界等相關定義及問題的定義。
定義 1 不確定圖在圖中,邊上有權值,權值范圍在(0,1)區間內,且權值表達的含義為該邊出現的概率,將這樣的圖表示為G=(V,E,P),如圖1。
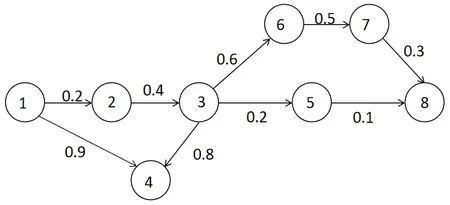
圖1 不確定圖GFig. 1 Uncertain graph G
定義2 可能世界對于不確定圖G=(V,E,P),若一個確定圖 G′=(V′,E′)滿足:(1)V′?V;(2)E′?E,則G′為G的一個可能世界。當V′=V且E′=E的時候,G′稱為 G的完全圖。圖2是圖1的兩個可能世界。

圖2 不確定圖G的兩個可能世界Fig.2 Possible Worlds of Uncertain Graph G
定義3 k步可達在一個確定圖上,給定頂點u和頂點v,存在一條從u到v的路徑且路徑上的邊數不大于k,則稱u到v在k步以內可達,結果為TRUE或FALSE。
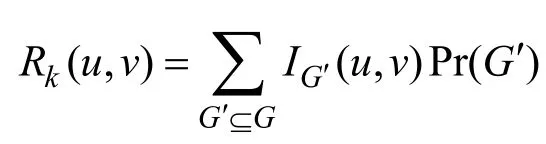
問題定義 給定一個不確定圖G、頂點u和頂點v,以及步數約束k,求u到v在k步以內可達的概率值。
1.2 相關算法
1.2.1 確定圖上k步索引
確定圖上的 k步可達研究目前已經有不少算法,文獻[7]提出了一種在頂點覆蓋集上建立路徑信息的索引。基本思想是隨機選取一條邊,將邊兩端的頂點都加入到覆蓋集C中,刪除這兩個頂點的所有出邊和入邊,再重新隨機選取一條邊,重復以上操作直到圖中沒有剩余的邊,然后在覆蓋集上建立k步以內的路徑傳遞閉包。
由于索引是在覆蓋集的基礎上構建的,因此查詢可以分為三種情況,分別是(1)u和v都是覆蓋集C中的頂點,此時只要查詢索引中u到v是否 k步可達就能直接得出結果;(2)起始點 u是覆蓋集C中的頂點而目標頂點v不在覆蓋集內,這種情況下把問題轉換為是否存在一個頂點w,且w是v的入結點,滿足u到w的距離不大于k-1(u不在覆蓋集中且 v在覆蓋集中的情況類似,不再贅述);(3)u、v都不在覆蓋集里,此時查詢能否存在w1和w2,且w1是u的出結點,w2是v的入結點,滿足w1到w2的距離不大于k-2。
這種索引方法存在規模大、效率低兩個問題,覆蓋集的大小直接影響了索引的大小和性能,然而對于覆蓋集的選取過于隨機性,導致生成的索引每次都不同。并且,該方法沒有考慮邊的不確定性,只能運用在確定圖上。
1.2.2 MC抽樣法
在不確定圖中進行蒙特卡洛(Monte Carlo)抽樣[12-13]是求解可達性問題的一種基本方法,主要思想如下:從起始點u出發BFS遍歷進行不同可能世界的抽樣,只有當邊(u,w)存在時,才把頂點w加入BFS的運算隊列中。在隊列為空前,如果找到了目標頂點v,則該可能世界中兩者可達,繼續下一次的圖抽樣和可達判斷。最終的結果為
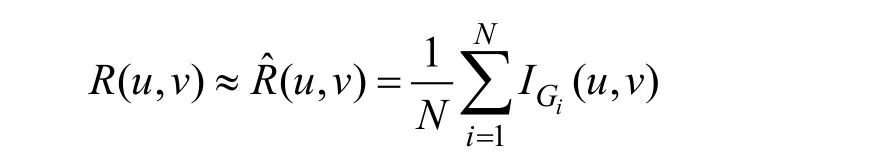
1.2.3 其他方法
YILDIRIM在文獻[1]中提出GRAIL算法進行可達性查詢,首先用不同遍歷方式生成d個區間標簽加速不可達判斷,對于使用標簽會產生誤判的查詢對,提出使用特例列表進行記錄,減少查詢時的遍歷操作。
文獻[2]提出的 BFSI-B將查詢分為可達和不可達進行處理,先構建深度優先生成樹,再基于樹利用區間標簽判斷可達性,如果滿足區間包含要求,則計算兩頂點在樹中的層數差是否不大于k,從而得出k步可達查詢結果。
Yano等人在文獻[9]中提出 PLL算法,該方法為每個頂點 u建立inLabel和outLabel兩組標簽,分別用來記錄能到達u的頂點和距離以及從u出發可達的頂點和距離。當查詢時只需要求起始點的 outLabel與目標頂點的 inLabel中的交集頂點,通過判斷兩段距離相加之和與k的大小關系進行判斷。
2 兩階段求解算法
對于給定兩點u和v的k步可達查詢,基本方法是從u出發,進行N次抽樣,統計這些可能世界中既滿足可達又滿足k步的樣本個數,除以N值得到結果。這種方法存在大量冗余計算。例如,在圖3給定的有向無環不確定圖中求頂點v0到頂點v1的3步可達概率,按照以上方法,需要從頂點 v0出發對邊依次進行抽樣。然而從頂點v0出發,無論怎么抽樣都不可能到達頂點v1。事實上,在這種無法k步可達的情況下直接抽樣毫無意義。對于該問題,本文提出結點覆蓋索引快速判斷不可達情況,從而能夠避免抽樣的昂貴代價。另外,對于可能到達的情況,本文提出高效的索引來加速查詢處理。下面分別進行介紹。

圖3 有向無環不確定圖Fig.3 Directed Acyclic Uncertain Graph G
2.1 頂點覆蓋索引
本文首先在不確定圖對應的完全圖上構建頂點覆蓋集,接著基于覆蓋集中的頂點構建k步索引,用來判斷給定查詢是否能在確定圖上k步可達。只有在確定圖上k步可達的前提下,才需要計算它的可達概率,否則無需進行抽樣操作。和k-reach算法構造覆蓋集的方法不同:k-reach是通過隨機選邊的方式來構造覆蓋集,然后計算覆蓋集中兩兩頂點之間的最短路徑。
本文在構建索引時選用的邊并非隨機抽取,而是優先選擇度較大的頂點加入到覆蓋集。因為隨機取邊的操作不僅會導致每次生成的頂點覆蓋集和索引都不一樣,索引效果也無法保證。
例如,用 k-reach算法對圖 3中不確定圖 G的完全圖進行頂點覆蓋計算的可能情況如下。假設第一次隨機取邊結果為 v1->v2,將頂點 v1和頂點v2加入結點覆蓋集C,刪除頂點v1和頂點v2的所有鄰邊,即邊 v1->v4、v0->v2、v2->v3和v2->v4。第二次隨機取邊 v4->v7,相應的將頂點v4和頂點v7加入覆蓋集C,并刪除鄰邊v4->v6。若第三次和第四次隨機取到的邊分別為 v6->v8和v5->v9,那么此次求解覆蓋集的過程如表1所示。可以看到最終求得的覆蓋集C仍有8個頂點,對圖的壓縮效果較差。

表1 求解覆蓋集過程Tab.1 The progress of computing vertex cover
但是如果按照大度頂點進行求解的話,能獲得更小的頂點覆蓋集,生成的索引在查詢時也更高效,具體操作如下。首先選取度最大的頂點,即頂點 v2,刪除 v2的鄰邊。然后選取當前度最大的頂點 v4,刪除 v4的鄰邊。第三步選擇剩余圖中度最大的v8,最后選擇頂點v5。可見,用這四個頂點就能構成原圖的頂點覆蓋集,比隨機選邊的方式減少了一半的頂點規模。

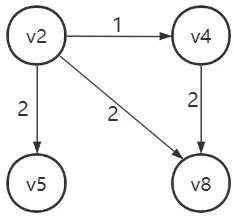
圖4 完全圖的kR+索引Fig.4 The kR+ index
關于索引構建的具體代碼設計如下。
算法1kR+(完全圖G=(V,E))
輸入:完全圖G=(V,E)
輸出:基于頂點覆蓋集VC的索引kR+
算法1用來構建完全圖上的索引,加速判斷k步不可達的情況。第 1~7行按照上述大度頂點的方法構建頂點覆蓋集,第1行初始化頂點覆蓋集VC為空集,第2行判斷是否有剩余邊,|E|表示邊數,第 3行選擇當前度最大的頂點賦給 u,在第4行加入覆蓋集VC,第5~6行刪除u的所有鄰邊并將鄰接點的度都減去一。第8~11行基于頂點覆蓋集構造k步索引,對于頂點u和頂點v,若u能在k步以內到達v,則給邊(u,v)賦予權值,表示路徑步數,否則不建立邊。最后生成kR+索引。
查詢時,如查詢頂點v1到頂點v5是否3步可達,由于v1不在覆蓋集內而v5在覆蓋集內,則問題轉換為查詢頂點v1的出結點到頂點v5是否2步可達。頂點v1的出結點為v2和v4,由kR+索引查詢可知v2到v5在2步內可達,因此得出結論v1到v5可以3步到達。
2.2 基于路徑的提前抽樣
本文采用文獻[14]中提出的離線抽樣思想,把N個可能世界提前進行抽樣并且以位向量[15]的索引形式存放在邊上。邊存在時記為 1,不存在記為0,第i個值表示在第i個可能世界上該邊的存在與否,每一條邊都有一個N大小的位向量,如[01100]可以看作5個抽樣圖中某一條邊的出現情況,該邊在第二、第三個可能世界上存在。由于該索引只需要0和1兩種值,因此可以采用C++中STL容器bitset或者二進制int的存儲方式,從而節省索引所占內存,時間復雜度為O(K|E| ),其中N是抽樣個數,|E|是邊數。
求解不確定圖上兩點間 k步可達概率的一個重要前提是它們之間能夠可達,而這一點可以用完全圖上的頂點覆蓋索引進行判斷。倘若在完全圖上無法滿足k步可達,那么在任何一個可能世界中都不存在符合要求的路徑,此時查詢結果為0.如果完全圖的查詢結果為TRUE,再通過路徑枚舉剪枝可能世界中的邊,縮小查詢范圍。
例如,在圖3上求v2->v8在3步內可達概率,有 v2->v3->v8 和 v2->v4->v6->v8 兩條路徑。此時看 v2->v3和 v3->v8這兩條邊的第 1位,只有兩者都為 1的時候這條路徑才完整存在并且滿足 3步可達,此時不再需要驗證 v2->v4->v6->v8 路徑,只有在前一條路徑不符合要求時才進行第二條路徑的查詢。
本文提出枚舉路徑的時候可以采用 kDFS的方式,求解的如果是k步可達問題,則用一個大小為k+1的棧,把起始點壓入棧中,如果存在未被訪問過的鄰居頂點就依次入棧。與DFS不同的是該棧有固定大小,如果棧滿時還未到達目標頂點,則需先彈出棧頂元素后再入棧其余頂點,直到棧空。kDFS的過程中若遇到了目標頂點,就把棧中所有元素記錄下來,作為一條可能路徑,該方法的時間復雜度為O(|Gk(u) |),即從源頂點 u 出發k步內可以到達的頂點個數。
2.3 查詢算法
算法2給出了在不確定圖G上查詢兩點間k步可達概率的kRP方法,設計代碼如下。
算法2 kRP(u,v,k,N)
輸入:起始點u,目標頂點v,步數k,抽樣個數N
輸出:u到v在k步內可達的概率

第一行中success用來計數可能世界里k步可達的數量。第2行是在生成的頂點覆蓋索引上進行查詢,若u不在覆蓋集內,則轉換為u的出結點與v的k-1步查詢,v不在覆蓋集內的情況不再贅述。如果該步驟判斷結果為 TRUE,則用固定大小的棧執行深度優先遍歷kDFS枚舉u到v的k步路徑。第5~9行,在預先存儲的N個可能世界中進行查詢,當路徑存在且查詢結果為TRUE時,給計數器 success的值增加1。第10行用可達的抽樣圖個數除以總的個數N,即可得到概率結果。
3 實驗分析
3.1 實驗環境
本文實驗所使用的硬件平臺是Intel Core i7,主頻為2.60 GHz的CPU,RAM內存為8 GB,操作系統為 Windows10 64位系統。代碼用 C++實現,使用基礎BFS抽樣法進行比較。查詢的距離k取值為3,抽樣個數N為1000個,查詢對數100對,其中3步內可達的頂點對數和不可達的頂點對數各占一半。
3.2 數據集
本文使用8個數據集對實驗進行驗證,Amaze和 Kegg都是與生物基因相關的網絡圖;Human和 Pubmed描述的是蛋白質網絡;Nasa是 XML文檔的數據集;Yago用來描述語義庫中的關系結構;Arxiv來自文獻[16];Web-Google是 Google網頁相關的數據集,具體信息見表 2,|V|表示頂點數,|E|表示邊數。邊上的概率權值用隨機數生成,取值為(0,1)的左開右閉區間。查詢集用完全圖隨機生成 100對查詢對,3步可達與不可達的比例為1∶1。
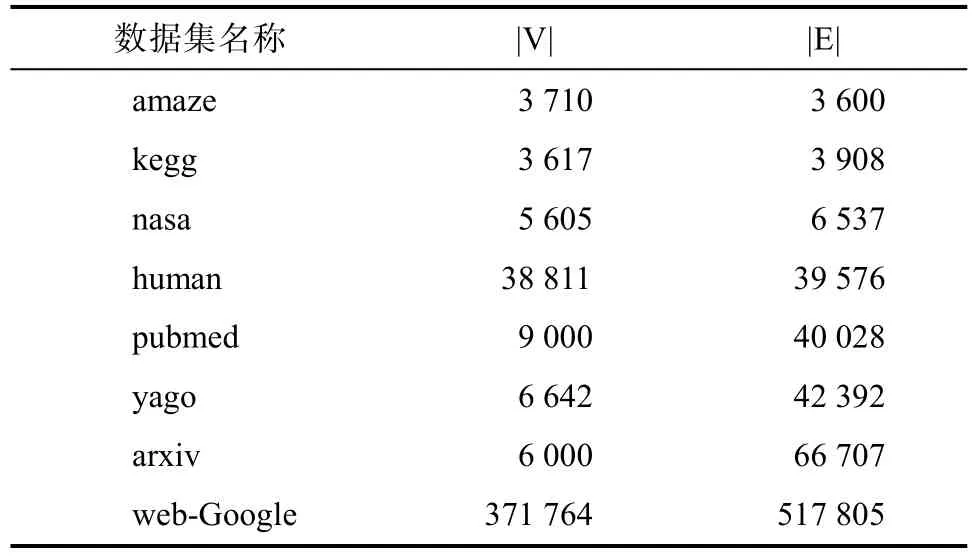
表2 數據集Tab.2 Dataset
3.3 性能比較分析
3.3.1 索引大小
表 3展示了在不同數據集上構造的索引大小,單位均為MB。其中,kR+是本文提出的用頂點覆蓋集構造的k步路徑索引,bitEdge是提前抽樣N個可能世界后存儲在邊上的索引,此處N值是1000,total表示兩個索引相加后的大小。可以看出索引所占的內存都較小,即使是在幾十萬頂點的圖上,也僅要117.553 MB。

表3 索引大小/MBTab.3 Inde x Size/MB
3.3.2 索引構建時間
如表4所示,列出了構造對應索引所需的時間。在構造bitEdge位向量索引時耗時較長,因為該步驟相當于對每一條邊都預先抽樣了N次,優點是在后續的查詢時,不論查詢對是多少,都無需再進行額外的抽樣,且在查詢時可以直接得出結果。基于頂點覆蓋構造的 kR+索引不僅消耗時間少,還能加快處理不可達查詢。
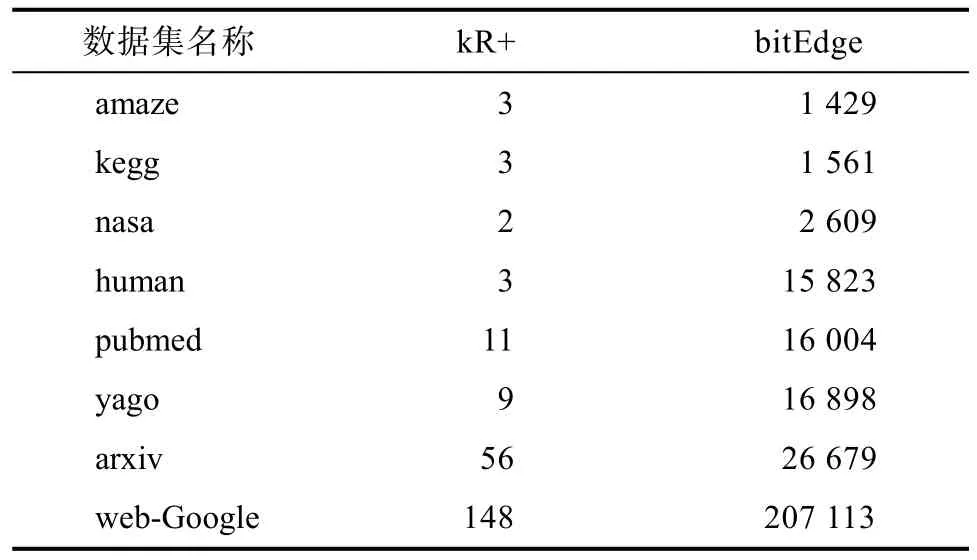
表4 索引構建時間/msTab.4 Index Building Time/ms
3.3.3 查詢時間
由于樸素抽樣法中,對于每一組查詢對,都需要從起始點開始向外BFS尋找目標頂點,且找到后還需要判斷兩個頂點之間的最短距離是否滿足 k步可達,消耗了極大的時間。如果u不可達v或者可達步數超過k時,更是浪費了N次的BFS遍歷。
而本文提出的kRP算法先判斷了查詢是否滿足可達和k步兩個條件,又枚舉出路徑縮小了需要查詢的邊數,剪枝了不在路徑上的邊,查詢的時候通過讀取位向量就可以直接得出結果。當一條邊在多次查詢中用到的時候,也不需要進行重復抽樣,極大地縮短了查詢時間。查詢100對頂點對的時間結果如表5所示,可見樸素的抽樣法耗費了大量時間在冗余遍歷上,只有在數據集nasa上,使用本文所提方法的構建索引時間超出了樸素方法的時間,原因是該數據集的出度較小。而其余7個數據集中,構建索引的時間都遠遠小于直接抽樣所耗費的時間,實驗結果驗證了本文所提出的kRP算法的有效性。

表5 查詢時間/msTab.5 Query Time/ms
4 結論
本文分析了不確定圖上的 k步可達近似算法,即樸素抽樣的BFS方法,并針對該方法中直接抽樣過于耗時的問題,提出將查詢分為兩種情況進行不同的處理。首先基于完全圖的頂點覆蓋集構建了k步可達索引,其中在求解覆蓋集時按照頂點度從大到小的順序選擇頂點加入覆蓋集,從而縮小覆蓋集的規模。用索引判斷出無法k步可達的頂點對,直接得出可達概率為 0,對這些查詢不再進行后續抽樣計算。對于可以k步可達的查詢,本文提出基于路徑來減少抽樣時的邊數,再用位向量的索引方式提前存儲抽樣圖例。實驗結果驗證了本文所提方法的高效性。
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
