基于尖τ型DS證據理論的機載LiDAR地物分類方法
2021-07-26 01:15:04馬澤亮楊風暴
激光與紅外 2021年7期
馬澤亮,楊風暴
(中北大學信息與通信工程學院,山西 太原 030051)
1 引 言
機載激光掃描與測距系統(Light Detection And Ranging,LiDAR)作為一種新興主動式遙感技術,具有空間分辨率高、獲取三維信息迅速等獨特優勢,廣泛應用于森林樹種分類[1],地物類別檢測[2-3],三維城市建模[4-5]和自然災害救援[6],而上述應用得以實現的必要保證是構造一種滿足高精度要求,具有實時性的LiDAR數據地物分類算法。
現有的LiDAR數據地物分類方法主要是機器學習、深度學習和以證據推理為代表的多特征智能組合方法。機器學習和深度學習方法能夠在大規模數據集訓練的基礎上,半自動或者全自動的識別地物。Hoang M N[7]等人運用支持向量機方法(SVM)實現了森林植被區域單株樹木的提取;何曼蕓[8]等人運用隨機森林算法(RF)實現了城市地區建筑物點的提取;趙中陽[9]等人提出了一種基于多尺度特征和Point Net的深度神經網絡模型,實現了復雜場景下LiDAR點云的自動分類。DS證據理論[10]作為處理不確定性問題的基本方法,通過構建信任分配函數描述不同分類特征與地物類別間的不確定關系,利用決策規則進行證據的合成,可以很好地處理不同特征數據間的復雜關系并且該過程不需要大量訓練樣本,能夠大大提高算法運行效率,可以廣泛應用于多種地物分類場景。馮裴裴[11]等結合模糊分布中的正態分布提出一種基于正態DS證據理論的LiDAR數據地物分類方法,將不同特征數據下的地物類別分布設為正態信任分配函數; Yang F B[12]等人基于DS證據理論,構造了一種線性信任分配函數,并利用分層組合框架對城市地物進行分類;上述方法解決了模糊點的分類問題,但其信任分配函數難以準確描述分類特征數據與地物類別間的不確定關系,算法分類精度不太高。
綜上所述,本文基于基本DS證據理論,改進上述方法中的信任分配函數,構造了一種基于尖τ型信任分配函數的快速地物分類方法,在有效提高算法運行效率的同時提升了算法分類精度,可廣泛應用于多種地物分類場景。
2 理論基礎
2.1 LiDAR數據特征
本文用到的源數據包括機載LiDAR首次回波(FE),末次回波(LE),強度特征(IN),可見光圖像(RGB),近紅外圖像(NIR)。根據源數據特征和地物特性得到兩組衍生數據特征:首末次回波高程差(HD)、歸一化差異植被指數(NDVI)。
首末次回波高程差(Height Difference,HD)可由公式(1)得到,激光雷達對樹木有穿透特性,能夠在樹冠、樹干與地面形成多次回波,而對于不可穿透地物,比如建筑物、道路、草地,HD沒有能力將其區分,該衍生特征可以用來表征樹木點的高度信息。
HD=FE-LE
(1)
歸一化植被差異指數(Normalized Difference Vegetation Index,NDVI)通過測量近紅外(植被強烈反射)和紅光(植被吸收)之間的差異來量化植被。該衍生特征利用植物葉綠素對紅光的吸收特性來進行植物的識別,獲取公式如式(2)所示:
(2)
NDVI值總是在-1~+1之間,與植被分布密度成線性關系,如果接近+1,則是密集的綠葉。NDVI值的大小與地物覆蓋種類關系如(3)所示:
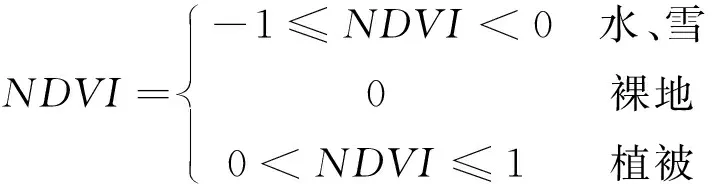
(3)
本文采用首次回波(FE)、強度(IN)、首末次回波高程差(HD)、歸一化植被差異指數(NDVI)四種特征來對包含建筑物、草地、樹木、道路四類復雜地物場景進行分類。
2.2 DS證據理論
DS證據理論作為一種不確定性的推理方法,在解決地物分類問題時,其作用在于利用不同特征的輸入數據,將待識別地物區分為符合實際地物的不同地物類別,其集合Θ稱為識別框架。識別框架Θ的所有子集組成的一個集合稱為Θ的冪集,記作2Θ,來自不同數據源的特征數據可以為一個或者多個命題提供支持度,這種支持度可以通過基本信任分配函數獲得。
基本信任分配函數m(A)是一個從集合2Θ到[0,1]的映射,A表示識別框架Θ的任意子集(命題),記作A∈2Θ,基本信任分配函數m(A)滿足0≤m(A)≤1,m(φ)=0,∑A∈2Θm(A)=1,其中φ為空集,且識別框架中的集合A只要滿足m(A)>0,則稱A為焦元。m(A)可利用函數根據傳感器得到的數據計算獲得,比如BPA函數。BPA函數可以根據傳感器檢測得到的數據構造而來。
基本信任分配函數是對一個命題的不確定性度量的基礎,在地物分類應用中,由于不同特征數據來源不同,會得到兩個或者多個不同的基本信任分配函數,此時為描述命題的不確定性,必須將兩個或多個基本信任分配函數進行正交和運算來合成,上述方法即為D-S合成規則。若已知P個數據源,每個數據源i有基本信任分配函數mi(Bj),且有0≤i≤P,Bj∈2Θ。對于命題A可以由D-S合成規則對多個數據源的基本信任分配函數進行合成:
(4)
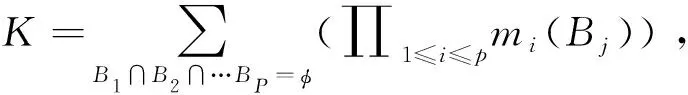
(5)
其中,焦元A,Bj∈2Θ,|Bj|是集合Bj的元素個數。
3 本文方法
3.1 尖τ型信任分配函數
信任分配函數的定義是DS證據理論的基礎。本文基于基本DS證據理論的基礎,引入模糊集理論,提出了一種新的信任分配函數——尖τ型信任分配函數,表示分類特征和地物類別間的不確定關系。該函數基于不同特征下地物點灰度值與所屬地物類別可能性程度呈尖τ型分布的假設。利用直方圖統計不同特征數據下不同地物類別的灰度值范圍,由此確定不同特征對應信任分配函數的閾值。函數定義為:
(6)
(7)
(8)
式中,PAi(x)表示當數據源i輸入為x時,圖像某個像素點屬于A類的可能性;PBi(x)表示當數據源i輸入為x時,圖像某個像素點屬于B類的可能性;引入模糊類別A∪B用來表示A類與B類之間的模糊類,集合A∪B中的元素不能完全確定屬于A類還是B類。當輸入x小于閾值h12時,PAi(x)和PA∪Bi(x)可以由式(6)和式(8)求出,此時屬于B類的可能性PBi(x)為0。同理,當輸入x大于閾值h12時,PBi(x)和PA∪Bi(x)可以由式(7)和式(8)求出,此時屬于A類的可能性PAi(x)為0。
尖τ型信任分配函數的曲線由圖1給出。地物類別間的辨識度描述的是分類特征不同取值時屬于某類地物的可能性程度[13]。考慮到不同數據源獲取信息的不確定性,本文中選取P1=0.02,P2=0.98來表示實際情況中不確定程度的下限和上限。與基本DS信任分配函數相比,尖τ型信任分配函數的優勢在于:
(1)對地物特性進行直方圖統計可得,尖τ型分布更符合實際地物類別的分布。
(2)模糊類別A∪B,將無法準確分類的地物點歸為模糊類別更符合實際情況,能有效提高分類精度。
(3)軟閾值使得DS理論在處理不確定性問題時發揮更好的優勢。
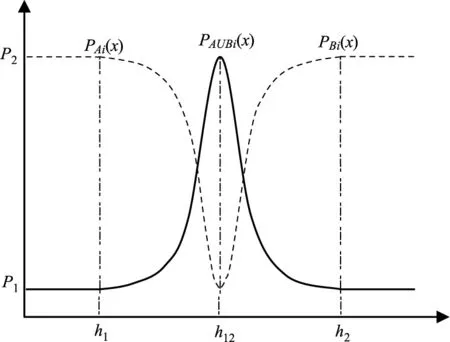
圖1 尖τ型信任分配函數曲線
3.2 圓形區域均值濾波
均值濾波是一種線性空間濾波,可以均等地對鄰域中的每個像素點進行處理。本文在使用尖τ型信任分配函數對地物場景進行分類時引入模板半徑為3的圓形區域均值濾波,用于消除部分存在于某一類地物場景中表示其他類地物的孤立像素點,比如草地中存在的裸地點會被錯分為道路類地物,應用圓形區域均值濾波可以有效減少錯分率,提高分類精度。
4 實驗與分析
本文實驗采用兩組LiDAR數據集,由TopoSys Falcon II系統拍攝,均經過預處理,空間分辨率為0.5 m。數據集1和數據集2尺寸分別為300×300像素和220×300像素。
4.1 實驗設計
為說明本文方法應用于LiDAR數據地物分類時的有效性,使用基本DS證據理論方法和正態分布DS證據理論方法處理實驗數據集,并將其實驗結果與本文方法應用于同一數據集的實驗結果作對比。圖2為實驗所使用的數據集1,圖3為實驗數據集2。

圖2 LiDAR數據集1

圖3 LiDAR數據集2
本文提出的尖τ型DS方法與基本DS方法相比,實驗結果更接近人工解譯真實值。在使用信任分配函數對像素點進行分類時,某個區域內可能會存在代表其他地物類別的孤立像素點。實際地物分類中,樹木區域出現的混淆主要是激光無法穿透茂密樹冠區域導致與建筑物區域產生的混淆;草地區域的混淆主要是由于草地區域有部分裸地點的存在,本文在采用尖τ型模糊DS證據理論分類過程中,引入模糊類別能夠對上述混淆點進行所屬地物類別的可能性分配,同時采用均值濾波算法對數據中的噪聲點進行處理,可以有效提高分類精度。
4.2 實驗結果與分析
數據集1實驗結果如圖4所示。圖4(d)為人工解譯真實值圖像,由人工對比可見光圖像逐個像素分類得到,作為標準用來評判分類結果的準確性和有效性。

圖4 實驗結果圖
表1為本文方法應用于數據集1時的混淆矩陣,根據相關計算公式可得,Kappa系數為85.93 %,表明本文分類算法結果與實際地物具有比較高的一致性,因此該分類模型能夠滿足實際要求。
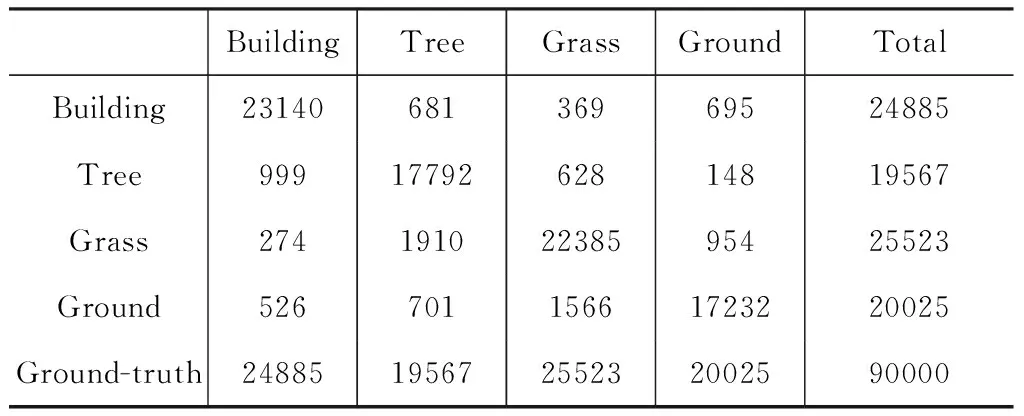
表1 數據集1混淆矩陣
表2為數據集1利用基本DS證據理論和本文方法的分類精度對比,表中S-DS為基本DS證據理論方法,F-DS+F為正態分布DS證據理論采用均值濾波方法。分析數據可得本文方法能夠在有效提高建筑物、草地類分類精度的同時,顯著提高了樹木類的分類精度,平均分類精度由85.41 %提升到89.50 %,提高4.09 %。
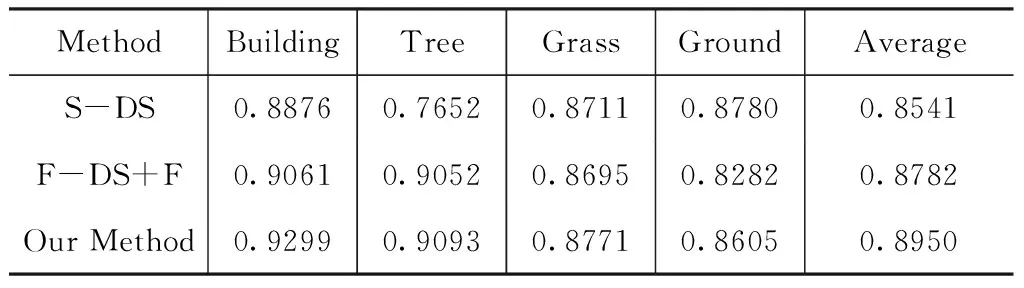
表2 數據集1分類結果精度(%)
表3為本文方法與參考文獻[14]中不同方法應用在同一數據集的算法復雜度對比,通過算法運行時間相比,參考文獻[14]中算法運行時間最快的為ICM-MRF方法,運行時間為21.65 s,而本文方法僅為0.28 s,時間縮短了98.70 %,有效提高了算法效率,因此本文方法能夠有效應用于實時性要求較高的場景中。

表3 幾種算法運行時間對比
圖5為本文方法應用于數據集的2實驗結果圖。圖5(d)為人工解譯真實值圖像,對比結果圖發現本文方法分類結果最接近實際地物類型場景。

圖5 實驗結果圖
表4、表5、表6分別為本文方法應用于數據集2的混淆矩陣、實驗結果精度表和算法運行時間對比。數據集2平均分類精度由82.38 %提高到88.64 %,提高了6.26 %;算法運行時間僅為0.26s,與參考文獻[14]中運行速度最快算法相比運行時間縮短了98.02 %,Kappa系數為84.80 %,表明本文分類算法結果與實際地物具有較高的一致性,并且算法有比較好的魯棒性。
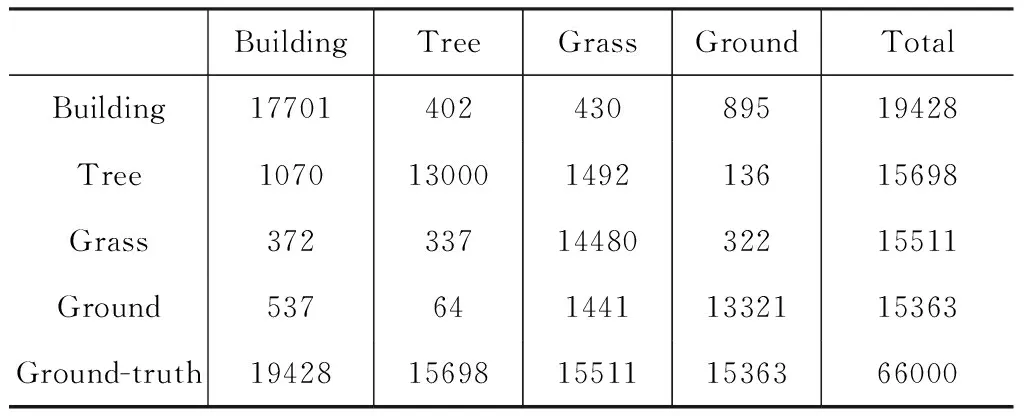
表4 數據集2混淆矩陣
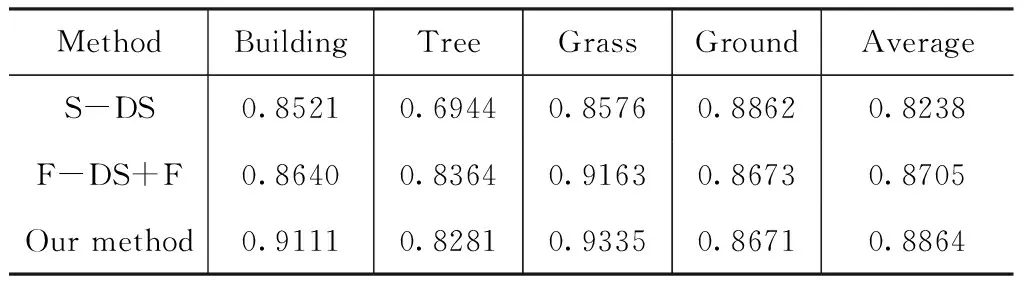
表5 數據集2分類結果精度(%)

表6 幾種算法運行時間對比
5 結論與展望
本文提出一種基于尖τ型信任分配函數的快速地物分類方法,并且在兩組數據集上驗證本文方法的有效性。結論如下:(1)構造了一種新的信任分配函數,有效協調四種分類特征的分布合成方法;(2)解決了現有算法在復雜地物分類場景中實時性較低的問題。基于現有工作基礎,下一步研究需構造各分類特征的可能性分布及其合成規則,構建基于可能性分布合成推理的LiDAR數據地物分類模型。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
鐵道通信信號(2020年9期)2020-02-06 09:15:22
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
數學大王·趣味邏輯(2019年5期)2019-06-13 20:27:43
當代陜西(2019年10期)2019-06-03 10:12:04
小學科學(學生版)(2019年5期)2019-05-21 01:00:18
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
經濟技術協作信息(2018年30期)2018-11-22 06:20:24
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
