云平臺容災技術研究與實現
2021-07-26 01:19:32陳劉忠展亞南張旭東
網絡安全技術與應用 2021年5期
◆陳劉忠 展亞南 張旭東
(1.電科云(北京)有限責任公司南京分公司 江蘇 21000;2.中國電子科技集團公司第二十八研究所 江蘇 21000)
云計算是一種按需分配的IT 資源供給方式,可以滿足對IT 資源的“拿來就能用”,“想要就能有”的需求。企業上云,是一個近年來比較熱門的話題。云計算中的虛擬化技術帶來“彈性、靈活、安全、低成本”特性,使“上云是常態,不上云是例外”成為共識。但是上云意味著數據會集中保存在公共數據中心,數據中心安全影響到云上所有應用數據的安全,因此數據中心容災技術成為云解決方案需要考慮的問題。本文研究并實現了以openstack+ceph 云解決方案的容災技術。
1 容災系統衡量指標
容災系統是指在距離相隔較遠的不同地方,建立兩套或多套作用功能相同的系統,這幾套系統之間可以相互進行數據轉移和功能業務的切換。當一方系統因某些意外故障停止工作的時候,另外一套系統可以完全恢復數據或將工作接管起來,使得該系統可以繼續正常工作。
按照SHARE 78 的國際標準,容災系統被分為7 層,為各容災等級的評定標準。衡量容災系統質量的指標主要有兩個,分別是RTO和RPO。
RTO(Recovery Time Objective):系統恢復時間,這一指標主要關注的是應用的恢復時間,關注業務系統所能容忍的停止服務的最長時間,代表業務系統從故障到恢復正常的時間。
RPO(Recovery Point Objective):丟失的數據量,這一指標主要關注的是災難發生后數據的丟失量。RPO 用以反映容災系統恢復數據完整性,代表業務系統所能容忍的數據丟失量。
2 Ceph 數據異步復制原理
Ceph 塊存儲是實時備份實現原理,是異步復制數據到備份數據中心存儲,是一個Tier5 級別的容災方案。本容災模塊數據備份分為兩個階段:啟動階段和實時復制階段。
啟動階段:第一次加入時對整個塊的數據做一次全量的快照,之后將快照同步到備端數據中心后創建一個鏡像基礎塊設備,原理圖如圖1所示。
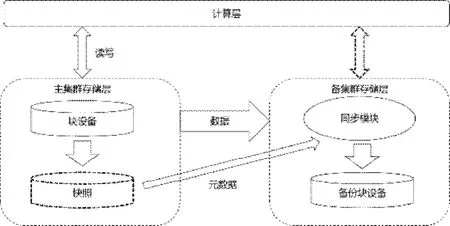
圖1 啟動階段數據同步原理圖
實時同步階段:實時同步階段中,數據同步模塊會從主集群的日志中讀取數據,在備集群增量回放數據,實現主集群存儲層和備集群存儲層的實時數據一致性能。實時同步階段原理如圖2所示。
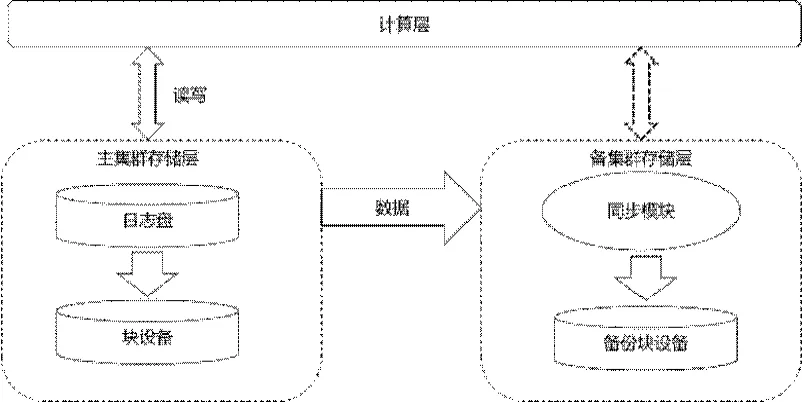
圖2 實時同步階段數據同步原理圖
計算層數據寫入時先將數據封裝成一個事務順序寫入日志盤,日志盤落盤后再寫入設備盤,這樣就可以保證主備集群數據的一致性。同時,同步模塊可以實時從日志盤中順序回放事務,寫入備集群塊設備。這樣的架構設計主備集群存儲層數據保證了弱一致性,解決了主備集群數據強一致性導致的數據主集群io 延遲問題。但是由于需要先寫日志盤,導致主集群io 延遲增加主要是寫日志盤的時間,可以使用更高性能的存儲介質存放日志以減小對延遲的影響。
3 云容災架構設計
同步模塊包括數據同步模塊和元數據同步模塊兩個部分。數據同步模塊實時同步存儲層塊設備數據;元數據同步模塊同步計算層虛擬機、云硬盤和鏡像的元數據。為在容災切換時能夠快速恢復虛擬機,需在備數據中心創建一個占位虛擬機實現容災切換虛擬機秒級恢復。
計算層容災主要包括虛擬機、云硬盤、鏡像和網絡,分別對應OpenStack 中的nova、cinder、glance、neutron 模塊。容災架構設計如圖3所示。
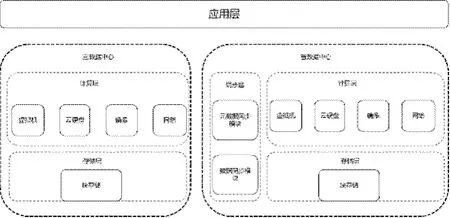
圖3 容災架構設計圖
4 云容災流程設計
容災流程包含創建容災組、加入容災資源、容災切換、停止數據同步、移除容災資源、清理容災組六種關鍵流程。
(1)加入容災資源:災備資源是用戶需要進行災備的虛機和云盤的統稱,相互關聯的資源需要添加到同一個容災組中進行統一管理和容災備份。為了在備端快速進行災難恢復,備端需要創建相同的資源(占位資源)和主端資源進行一一映射。
容災資源加入容災組之后會自動收集主端虛機的port、子網、網絡、安全組、flavor、啟動方式、云盤信息。根據這些信息在備端恢復出來相應的資源,加入容災資源流程如圖4所示。
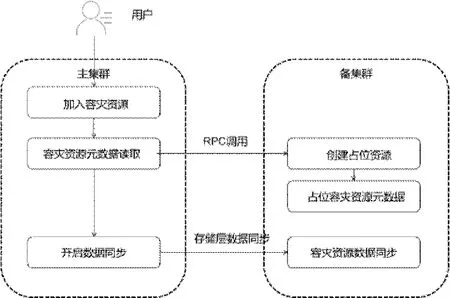
圖4 加入容災資源流程圖
用戶將相關聯的資源加入容災組中,容災服務讀取容災資源的所有元數據信息通過RPC 調用在備集群創建占位資源,之后開啟存儲層數據同步,實時在往備集群同步存儲層數據。
(2)容災切換:當主數據中心由于故障或者其他原因導致無法提供服務時,需要進行災備切換,把備端強制升級為主端,并利用備份的數據來恢復服務;同時當主端恢復后,需要繼續和備端進行數據同步,把備端的數據同步到主端,保持主備端數據的一致性。容災切換流程如圖5所示。

圖5 容災切換流程圖
●主集群宕機切換流程:當主集群故障宕機不能提供服務時,需要在備集群進行災備處理,將備集群備服虛擬機升級為主提供服務。當然為了虛擬機的ip 地址、mac 地址一致,主備集群采用大二層打通的方式,在備份升級為主的同時進行ip 地址指定,保證備集群虛擬機計算、存儲、網絡等所有信息與主集群保持一致對外提供服務。
●主集群恢復切換流程:主數據中心故障恢復正常,需要在主端再次進行災備處理,把備集群資源數據同步到主集群。需要將主集群虛擬機先降級為備,從備集群同步數據到主集群保證主備集群數據一致后,再進行容災切換將主集群虛擬機恢復對外提供服務,備集群再次降級為備。
(3)停止數據同步:因為業務部分虛擬機不需要再繼續容災,或者為了節省容災網絡和備集群存儲空間暫停同步。這時需要支持停止數據同步功能,停止容災功能是以容災組為單位進行,并且停止容災之后會清理該容災組在備集群的數據存儲資源。停止容災的流程包括存儲層數據同步停止和備集群存儲層數據清理兩個步驟。
(4)刪除容災資源:如果某些資源不再需要,可以刪除資源。但是如果資源已經在災備組中,則必須從主端發起移除資源。之后容災服務會先檢查狀態,然后清理主備映射關系,后刪除主機群資源。備集群資源由用戶決定是否刪除。刪除容災資源流程如圖6所示。
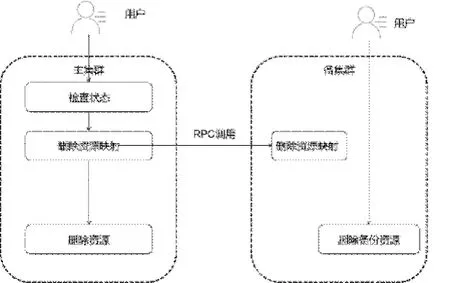
圖6 容災切換流程圖
(5)刪除災備組:當用戶不再需要對某個災備組中的資源進行災備時,可以在中止數據同步之后刪除災備組。如果災備組正在開啟同步或者正在切換,在這種中間狀態下,也不允許刪除災備組。在主集群檢查狀態后刪除資源映射和容災組映射,同時在備集群也刪除它們。之后刪除主集群災備組,備集群災備組由用戶決定是否刪除。
刪除災備組的流程圖如圖8所示。
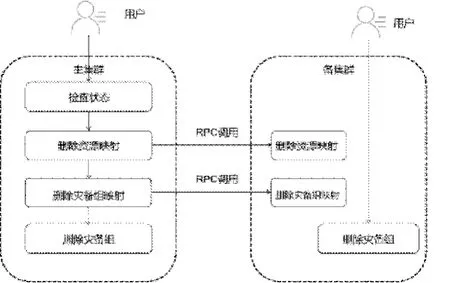
圖7 刪除災備組的流程圖
5 總結
本文主要介紹了Openstack+ceph 云平臺Tier5 級備份容災的原理、架構設計和流程設計,并且本文介紹的方案已經在生產環境中經過驗證,為今后云平臺容災設計提供參考。
猜你喜歡
江蘇安全生產(2023年1期)2023-02-08 05:58:38
工業設計(2022年8期)2022-09-09 07:43:20
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
家庭影院技術(2017年9期)2017-09-26 03:41:45
