基于混合采樣和集成學習的軟件缺陷預測
2021-07-26 01:19:30楊昊天顧乾暉王嘉璐施愷杰徐力晨
網絡安全技術與應用 2021年5期
◆楊昊天 顧乾暉 王嘉璐 施愷杰 徐力晨
(南昌工程學院信息工程學院 江西 330096)
軟件缺陷檢測是軟件工程的重要課題[1]。一些常見的機器學習方法,如支持向量機、決策樹、KNN、邏輯回歸、樸素貝葉斯等都能夠用來建立分類模型[2]。但是,對于軟件缺陷檢測問題,經典的學習方法效果并不理想。由于傳統分類器的訓練過程普遍遵循誤差最小化原則,當訓練數據不平衡時,分類面向多數類偏倚,因此最終的模型對少數類的分類性能較差,在嚴重情況下,模型甚至完全無效。類別不平衡指的是訓練數據中不同類別樣本的數量差異很大,其中某些類別的樣本數目要遠小于其他類別樣本的數目[3]。這種情形廣泛存在于現實應用中。不平衡的數據降低了少數類樣本的分類正確性[4]。
不平衡學習算法目標可以簡單描述為在不嚴重降低多數類準確性的情況下獲得一個能夠為少數類提供高準確率的分類器[5]。類別不平衡學習一直是機器學習與數據挖掘領域的研究熱點與難點之一。目前,已有許多類別不平衡學習技術被提出,大致可以分為數據層處理技術、內置技術,混合技術。為了有效提升軟件缺陷預測精度,本文提出了一種將SMOTE_Tomek 采樣和集成學習算法XGBoost[3]相結合的分類預測模型。該模型先利用組合采樣方法SMOTE_Tomek 使失衡的數據平衡,同時濾除噪音樣本,然后再使用集成學習算法XGBoost 進行訓練得到分類模型。為了評估提出的分類模型的有效性,我們利用十個NASA 軟件缺陷數據集進行了廣泛的比較實驗。實驗結果驗證了本文提出的模型解決軟件缺陷預測問題的優越性。
1 XGBoost 集成學習
XGBoost 是一種基于決策樹并使用梯度提升框架的集成學習算法。
本文利用XGBoost 集成學習算法在平衡后的數據集上進行訓練。設每個數據集中有n 個樣本和m 個特征,記為:D={(xi,yi)}(|D|=n,xi∈Rm,yi∈R)。其中yi為實際缺陷標簽。根據XGBoost 算法中決策樹函數fk(x),預測缺陷標簽,其中k 為迭代次數。由損失函數和懲罰項Ω(fk)建立目標函數。損失函數衡量目標值yi與預測值之間的誤差,懲罰項用以避免過擬合,則目標函數可表示為
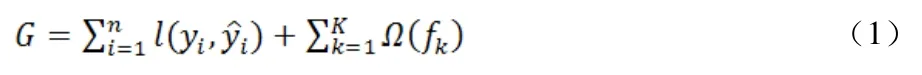

其中γ為決策樹的復雜度,λ為懲罰因子,T 為決策樹的葉子節點數目,ω為數據分到決策樹中葉子節點的所在層數。將上式進行泰勒展開,則算法的第k 次的目標函數可近似表示為

在模型訓練階段,每次迭代選擇最優的fk(x),使得式(3)最小化。
2 結合SMOTE_Tomek 的XGBoost 軟件缺陷預測
采樣技術主要包括欠采樣和過采樣。常見的欠采樣方法主要有:隨機欠采樣、Tomek Links、NearMiss-1、NearMiss-2、NearMiss-3 等。下面以NASA 數據集中的PC3 樣本為例。圖1 展示了PC3 原始數據樣本的分布情況。

圖1 PC3 原始數據樣本
SMOTE 采樣方法在平衡數據的同時,造成了分類面的過度偏倚,因此提出了組合采樣技術SMOTE_Tomek。該方法可以很好地改善SMOTE 過采樣中的噪聲和邊界問題。該方法包含兩步:首先利用SMOTE 采樣對不平衡數據進行過采樣處理,然后再通過Tomek Links采樣對新生成的樣本中存在的噪聲進行刪除。圖2 展示了采用SMOTE_Tomek 采樣方法后的新數據樣本分布。

圖2 SMOTE_Tomek 采樣
3 實驗結果與分析
3.1 數據集與評估指標
本文實驗使用了十個美國國家航空航天局(NASA)的軟件缺陷數據集。這些數據集是公開并被廣泛使用于軟件缺陷預測的數據集。每個數據集對應NASA 某個軟件子系統,其特征包括代碼行數、遞歸最大深度等。
軟件缺陷預測是一個分類問題,分類問題中我們評估實驗效果可以通過混淆矩陣來計算,由混淆矩陣計算出精確率、召回率、準確率和F1 值。其中,F1 值表示的是精確率和召回率的調和平均值,它的值越大,模型的分類性能越好。
3.2 分類性能比較與分析
本文實驗的采樣階段分別比較了多種常用的欠采樣和過采樣。主要包括:隨機過采樣[6]、ADASYN、SMOTE,以及本文使用的SMOTE_Tomek 采樣方法等。為了驗證文中所提出的組合模型的性能,使用了不同的組合分類模型與之對比。表1 使用不同的采樣模型和XGBoost 分類模型相結合,隨機連續進行20 次實驗,計算出各個組合預測模型在十個NASA 數據庫中的準確率。

圖3 八種采樣方法分別與XGBoost 分類器相組合的F1 值比較

圖4 九種分類器分別與SOMTE_Tomek 采樣相組合的F1 值比較
在NASA 數據集上,使用過采樣與XGBoost 的組合預測模型結果普遍優于欠采樣與XGBoost 的組合模型。其中SMOTE_Tomek 與XGBoost 的組合模型有最優的準確率。但是,對于不平衡數據的分類,準確率往往不是理想的比較指標。因此,我們進一步對各個組合模型的F1 值進行比較。在十個NASA 數據集的預測結果中,過采樣方法比欠采樣方法有更好的F1 值。由各個采樣方法在每個數據集的F1 值計算得到各個采樣方法的F1 均值,如表1所示。表1 的實驗結果表明,對于NASA 軟件缺陷數據集,SMOTE_Tomek 采樣方法與XGBoost 相組合的分類模型獲得最優的F1 值,即有最好的分類性能。為了進一步驗證SMOTE_Tomek 采樣與XGBoost 組合的分類模型的優越性,我們進一步比較了SMOTE_Tomek 采樣算法與其他主流分類器相組合的分類模型,實驗結果如表2所示。

表1 10 個NASA 數據庫上的F1 均值

表2 10 個NASA 數據庫上的F1 均值
4 結束語
本文提出了一種SMOTE_Tomek 組合采樣方法和XGBoost 集成學習相結合的分類模型。我們在十個NASA 數據集上的仿真實驗結果表明:該組合模型在軟件缺陷預測上有著非常出色的表現,獲得了最好的平均準確率和平均F1 值。實驗結果證明了本文提出的分類模型能夠很好地處理軟件缺陷預測問題。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
