DNA信息存儲:生命系統與信息系統的橋梁
2021-07-21 09:30:40韓明哲陳為剛宋理富李炳志元英進
合成生物學 2021年3期
關鍵詞:信息
韓明哲,陳為剛,宋理富,李炳志,元英進
(1天津大學,合成生物學前沿科學中心,系統生物工程教育部重點實驗室,天津 300072;2天津大學化工學院,天津 300072;3天津大學微電子學院,天津 300072)

信息存儲是文明傳承的基礎。人類是地球上最具智慧的生命體,從結繩記事開始,生命體外的數據存儲就成為了人類思想的延續,記錄了燦爛文明。造紙與印刷術的發明,使得人類能夠存儲的數據量在幾百年內獲得了大約5個數量級的提升[1];在計算機時代,尤其是近年來隨著信息技術的快速發展,人類生活的方方面面都逐漸實現數字化轉變,人類產生的數據爆發式增長。基于磁、光及集成電路的現代數據存儲介質歷經發展,存儲體積密度已經可達到1010~1012bit/cm3[2]。與之相比,DNA存儲具有更高密度存儲潛力,如大腸桿菌染色體DNA的存儲體積密度據估算達約1019bit/cm3[3]。近年來,隨著合成生物學的快速發展,以高通量DNA合成技術[4]和人工合成染色體的工作為代表[5-6],標志著人類對DNA的設計[7]、合成[8]、編輯[9]和讀取[10]能力已經進入到一個嶄新的時代。在此背景下,利用合成DNA進行高密度信息存儲成為一個非常有前景的研究方向[11],得到了相關領域研究者、信息技術企業與生物科技企業的廣泛關注。2020年11月,微軟、西部數據等傳統信息技術企業與Twist Bioscience、Illumina等新興生物技術公司一道,共同宣布成立了第一個DNA數據存儲聯盟,將制定全面的行業路線圖,為經濟高效的商業檔案存儲奠定基礎[12]。
1 DNA存儲數字信息
利用人工合成的脫氧核糖核酸(DNA)存儲數字信息,簡稱DNA信息存儲[13]。DNA用作信息存儲載體,具有存儲高密度、不受電磁干擾、長期高可靠和維護低成本等優勢[13-16]。DNA作為天然的信息載體,以“A/T/C/G”數字信號的表示形式,存儲了億萬年來無數生物的遺傳信息,依托中心法則造就生命繁衍、進化演化及生物多樣性。人類產生的海量信息,記錄在各類數字存儲介質,保存并得以延續,支撐了文明的傳承與繁榮。利用DNA存儲數字信息連通了生物系統與信息系統,發展了多種應用模式,成為近年重要的研究熱點。
利用DNA存儲數字信息的原理和技術流程如圖1所示。其原理是:數字化信息在二進制碼流、四進制堿基序列和實際DNA片段之間的轉化與流動[3,13-14]。目前,基于此原理的技術流程主要包含兩個方面:①信息寫入,首先對文本、圖片或視頻等信息的二進制碼流進行編碼,得到A/T/C/G組成的堿基序列,隨后利用DNA合成技術將信息寫入對應的DNA片段,并對其進行多模式保存[17-18];②信息讀取,首先對制造的數據DNA片段進行測序,隨后進行識別、組裝、糾錯與解碼等,將存儲在DNA介質中的數據還原為原始數字化信息,得到原始文本、圖片、聲音和視頻等。
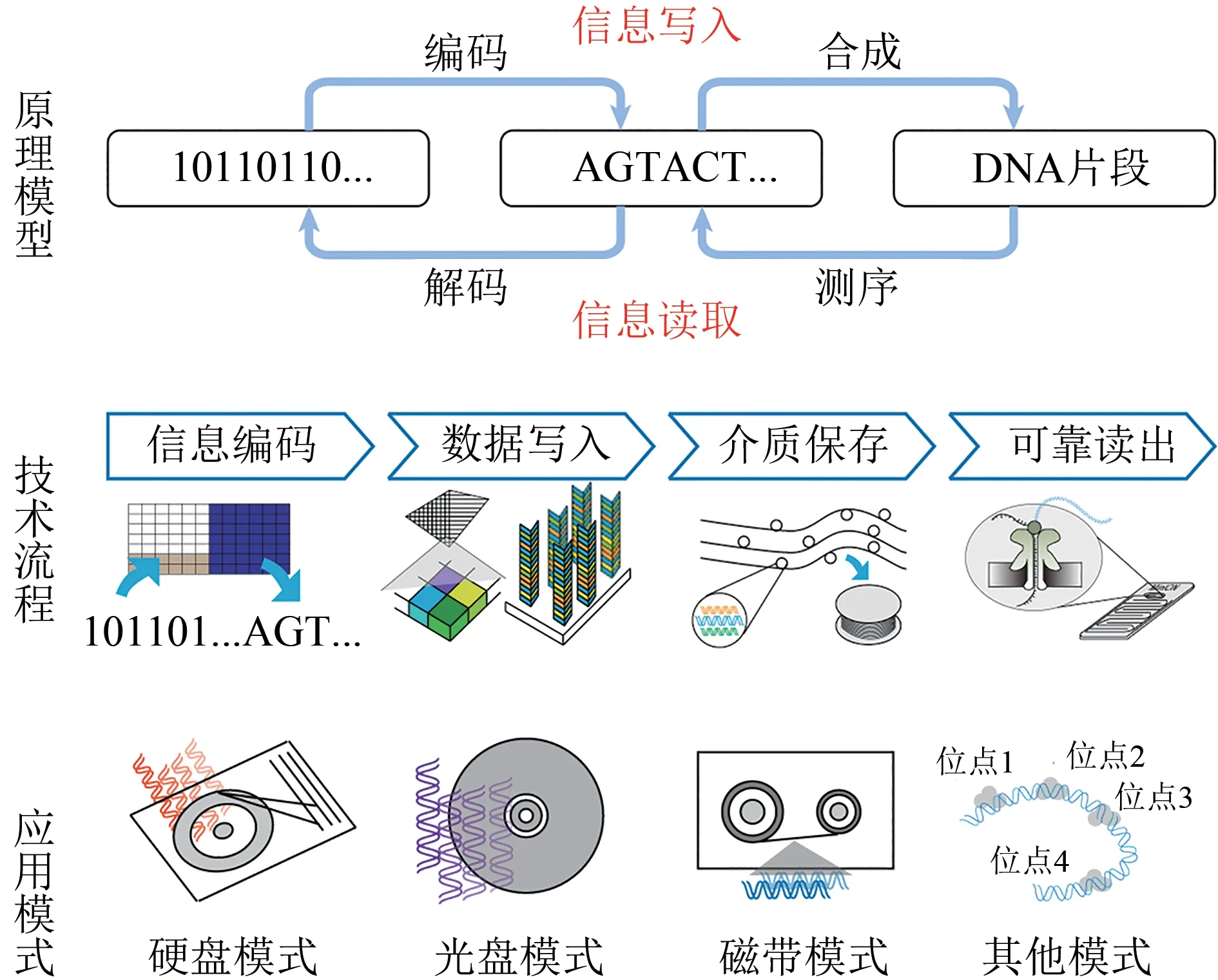
圖1 DNA存儲的原理模型、技術流程和應用模式Fig.1 The basic principle,technical work flow and storage modes of DNA information storage
2 DNA信息存儲的若干模式
依據DNA片段讀寫技術的特點,類似傳統數據存儲,也可劃分為“硬盤”“光盤”“磁帶”等應用模式。“DNA硬盤”具有高通量讀寫特征,面向海量數據的高密度存儲;“DNA光盤”具有低成本快速復制特征,支持單寫多讀,面向數據的海量分發;“DNA磁帶”具有體內串行刻寫特征,面向數據或狀態的順時間記錄。以下將對各個存儲模式的特點和相關研究進展進行詳細介紹。
2.1 “DNA硬盤”模式
2012年哈佛大學George Church等在《科學》雜志發表研究成果[19],成功存儲和讀取了5.27 Mb包含文字、圖像和JavaScript程序的數字化信息,出錯率僅為百萬分之二。隨后在Johns Hopkins Magazine上首次提出“DNA硬盤”(DNA hard drive)[20]。該模式依托高通量DNA芯片合成技術和高通量二代測序技術來寫入和讀出數據。與傳統的硬盤類似,具有面向海量數據的高密度存儲潛質。由此衍生的類似研究,可歸納為“DNA硬盤”。
“DNA硬盤”的數據端到端可靠性遠不及傳統硬盤,需要解決DNA作為載體的數據可靠性問題[21]。目前商業硬盤的讀寫錯誤率低至10-15以下,而高通量合成寡核苷酸的錯誤率一般在1/2000到1/200[22-23],二代測序的錯誤率在1/1000到1/100[24]。為了解決這些錯誤對信息可靠性的影響,多個信息領域的信息編碼方法被引入到了“DNA硬盤”框架。歐洲分子生物學實驗室的Goldman教授[25]通過添加四倍冗余和簡單的校驗機制實現了數據的可靠恢復,但是由于四倍冗余的設計,該方法實現的邏輯密度(bit/nt)和成本控制都不理想。蘇黎世聯邦理工大學Grass團隊[26]引入了里德-所羅門(RS)糾刪碼,解決了寡核苷酸鏈池中部分片段丟失以及片段內堿基替代錯誤,在保證數據可靠恢復的同時使數據部分的邏輯密度超過了1 bit/nt。Erlich等[27]引入了噴泉碼,更好地適配海量片段化的存儲模式,將數據部分的邏輯密度進一步提升到1.57 bit/nt。另一思路,Anavy等[28]和Choi等[29]分別使用了簡并堿基來拓展DNA的多進制表示方法,將“硬盤”模式下的邏輯密度推升到了2 bit/nt以上,但是此方法也面臨需要更高測序覆蓋度(覆蓋度>150×)的問題。除此之外,在未來引入非天然堿基拓展存儲單元,可進一步提升邏輯密度[30]。總而言之,在確保數據可靠性的前提下,逼近數據承載能力的極限是DNA信息存儲發展的趨勢[31]。
值得關注的是,“DNA硬盤”中合成與測序會引入堿基的插入和缺失錯誤(insertion/deletion,簡稱Indel),這有別于傳統存儲介質,處理較為困難[3]。針對該問題,Press等[32]提出了基于哈希編碼和貪婪窮舉解碼的編碼方案,該方案能夠在單分子拷貝的情況下糾正插入和缺失錯誤,但是需要較高的冗余度來實現糾錯,且解碼復雜度較高。Sabary等[33]提出了幾種動態的DNA重構算法,可直接用于較高錯誤率下的DNA序列重建。天津大學Song等[34]設計了一個基于德布萊英圖(de Bruijn Graph)的DNA序列高魯棒重建算法,如圖2所示,可以從包含大量插入缺失和替代錯誤的多序列快速重建無錯誤的DNA片段序列。該方法可以從低質量的PCR產物(序列長度完全錯誤)中可靠地讀取數據,實現高魯棒讀取。
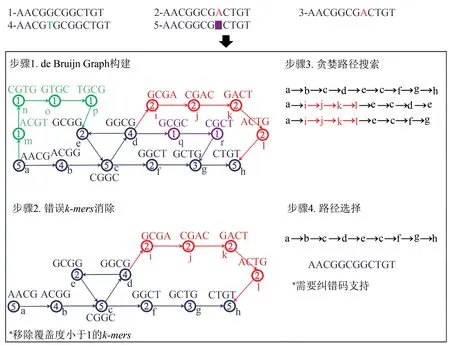
圖2 基于de Bruijn圖論的DNA序列重建算法[34]Fig.2 Algorithm of de Bruijn graph-based reconstruction of DNA strands[34]
為降低“DNA硬盤”寫入成本,提高寫入速度,2019年,Lee等[35]采用非阻斷型的末端脫氧核酸轉移酶(TdT)合成DNA,實現了一種專用于信息存儲的DNA酶法合成技術。2020年,Lee等[36]進一步利用圖案化紫外光快速解離Co2+激活TdT,成功編碼了110位的數據信息,初步驗證了在陣列表面實現大規模DNA并行合成的可行性。
為解決“DNA硬盤”多輪PCR造成的偏好性累積和部分DNA片段丟失的問題,Lin等[37]通過對原始文庫修飾并引入RNA逆轉錄過程,構建了始終以原始文庫為模板的擴增方法,在一定程度上降低了多次訪問對原始文庫的影響。Choi等[38]將原始文庫固定在具有二維碼編號的微盤上,實現了對文庫的原位(in situ)擴增,經過20輪擴增未發現產物片段分布的明顯變化,顯著降低了擴增帶來的偏好性,同時還通過二維碼實現了數據庫管理。天津大學Gao等[39]將原始文庫固定在磁珠上,通過等溫鏈置換擴增技術,實現了對文庫低偏好性、穩定重復的擴增。
“DNA硬盤”的應用模式已實現了一定規模的存儲驗證[40-47]。2018年,華盛頓大學和微軟公司的研究團隊實現了200 MB的數據存儲和部分數據文件的隨機訪問[40],并于2019年開發了原型設備,實現了“HELLO”的自動讀寫[41],同時還設計了DNA保存和訪問的微流控平臺[42];2019年,美國Catalog公司[43]利用獨創的DNA寫入技術,存儲了16 GB的維基百科數據,是目前最大規模的“DNA硬盤”。在國內,天津大學陳為剛等[44]采用LDPC碼與RS碼的乘積碼保證可靠性,采用27萬條的寡核苷酸池存儲超過3 MB數據,存儲了兩段有歷史價值的音視頻片段以及13 000多漢字,實現了低樣本濃度、低測序覆蓋度的可靠讀出(圖3)。深圳華大生命科學研究院Ping等[45]設計的“陰-陽”編碼策略可調整均聚物長度或GC含量等以滿足不同用戶需求,實現了2.02 MB數據的存儲。
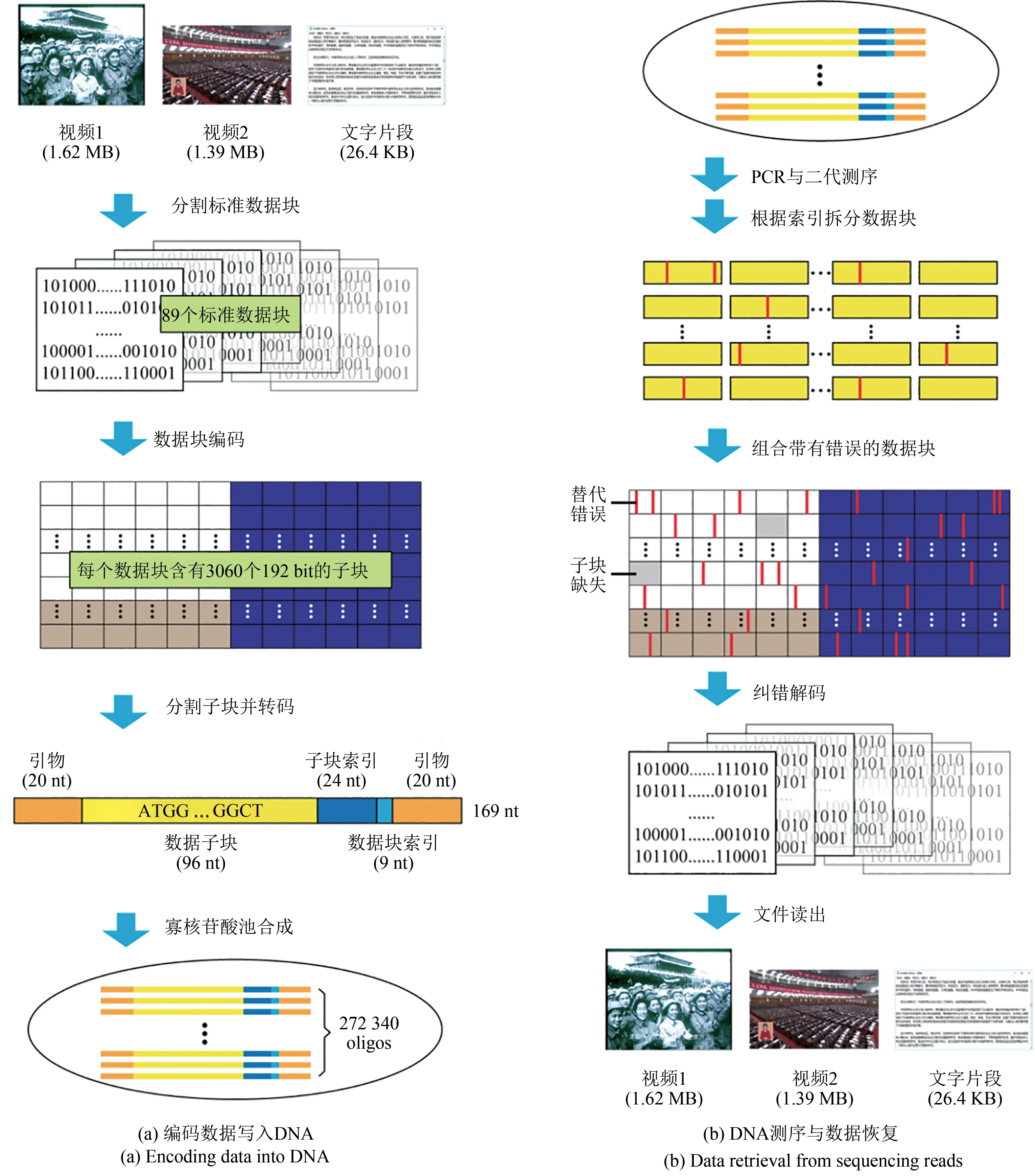
圖3 “DNA硬盤”模式示意圖[44]Fig.3 Schematic diagram of"DNA hard drive"[44]
2.2 “DNA光盤”模式
與“DNA硬盤”的體外存儲方式不同,一種生命體內的DNA信息存儲模式也被提出,其特征類似光盤,本文歸納為“DNA光盤”[48]。該模式的主要特征是采用較長DNA片段,通過細胞體內組裝完成寫入、借助細胞自身的快速低成本的DNA復制能力,快速且均一拷貝數據。雖然“CD母版”的制作成本較高,即合成與組裝成本較高,但是其類似CD的低成本大量拷貝,使得“母版”成本得以分攤。受益于常用模式生物較低的突變率[49-50],“DNA光盤”亦可高保真拷貝,支持數據長期傳代復制[51]。利用小型納米孔測序器件,有望實現數據快速讀出,便攜式“DNA光驅”呼之欲出。值得注意的是,納米孔測序錯誤率高達10%,并且包含難以處理的插入與缺失錯誤[52]。因此如何保證數據在納米孔測序下的可靠讀出,是一個值得研究的方向。
“DNA光盤”開始于早期細胞體內存儲數字信息的概念驗證,探索單個細胞內存儲的數據量是個有價值的問題。概念驗證多使用質粒在大腸桿菌內存儲數據,編碼的DNA長度通常不超過1 kbp[53-59]。2010年,Venter等[60]在化學合成蕈狀支原體時,第一次在原核生物基因組中嵌入了超過4 kbp的編碼DNA存儲外部信息。本文作者[48]從頭設計合成了一條254 886 bp的存儲專用染色體,其中數據編碼部分占95.27%,將單菌內數據存儲DNA數量提升到了百kbp級,存儲了37.8 KB圖片、視頻以及文字,利用疊加編碼方案,有效克服三代測序的高錯誤率問題,實現了數據的可靠恢復。這項工作突破性地將單菌內數據存儲DNA數量提升到百kbp級,初步打通了單細胞數據存儲容量這個限制“DNA光盤”模式存儲通量提升的關鍵因素(圖4)。
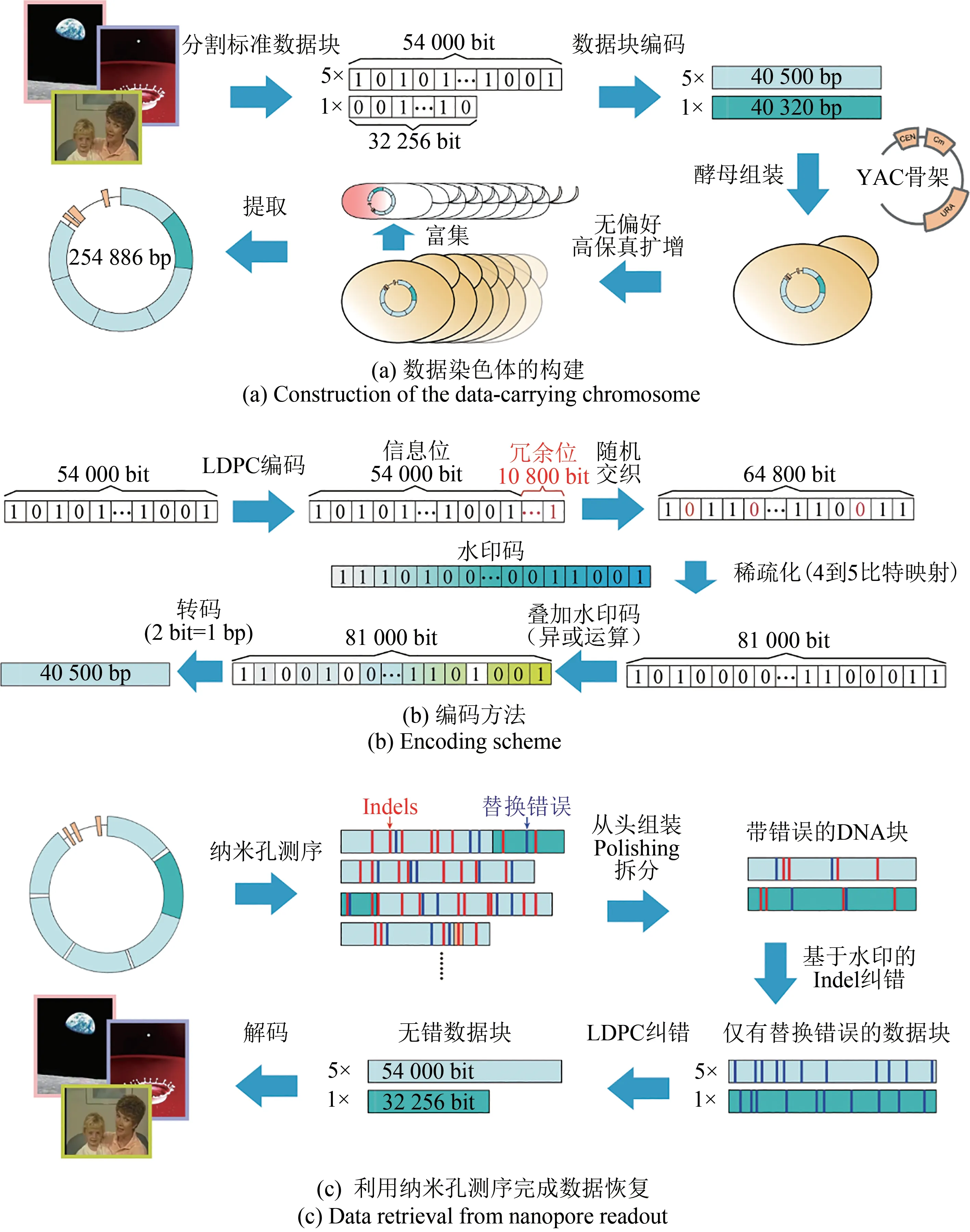
圖4 “DNA光盤”模式示意圖[48]Fig.4 Schematic diagram of"DNA CD"[48]
“DNA光盤”模式除了提高單細胞數據容量外,增加并行通量也是提升數據存儲容量的關鍵。Shipman等[61]通過CRISPR/CAS1-CAS2系統捕捉DNA小片段整合進大腸桿菌群體的CRISPR序列中,分別編碼了494字節的21色圖片和2.6 KB的動畫短片。天津大學Hao等[62]構建了攜帶不同短信息片段質粒的大腸桿菌分布式混菌存儲系統,在維持低成本的同時實現較大的體內存儲通量,將445 KB的數字文件存儲在11 520個115 bp的合成DNA中。
2.3 “DNA磁帶”及其他模式
運用動態基因組工程(dynamic genome engineering)[63]在生命體內“書寫”DNA來記錄信息的新模式,一定程度上類似磁帶,本文稱之為“DNA磁帶”。“書寫”包括對特定DNA靶向插入、刪除、倒位和單堿基突變等操作,類似于在磁帶上磁化刻錄以記錄信息[64]。目前已經驗證的模型中,“書寫”過程的開啟信號可以是對抗生素或病毒的暴露、營養底物的改變和對光及特定誘導劑的響應等[65-69]。起初“DNA磁帶”主要記錄細胞內的特定事件或狀態,Harries Wang團隊[70]首次構建了基于電刺激的“人-胞”輸入接口,利用電壓控制胞內的氧化還原對狀態,從而誘導CRISPR/Cas1-Cas2系統在特定位點插入不同的DNA序列,實現信息寫入。這使得未來半導體-生物接口的發展成為了可能。進一步,得益于基因線路設計的發展,生物“邏輯門”可與“DNA磁帶”相結合,為生物細胞計算提供記錄。然而,“DNA磁帶”依然存在邏輯密度低、數據響應延遲和精準性較低等問題。此外,目前通常是基于菌群進行記錄,通過加標簽(barcode)對不同菌群進行區分[70],隨機訪問的難度較大。
與“DNA磁帶”模式類似,為避免人工合成DNA產生的高昂成本,美國UIUC的Tabatabaei等[71]模仿古老的打孔卡存儲方式,以天然的DNA分子鏈(例如基因組DNA、克隆或PCR擴增產物)為“卡紙”,以特定的酶為“打孔機”,建立了一種“打孔卡”DNA存儲方法。該方法通過在DNA磷酸骨架上預設位置“打孔”來表示二進制數據中的“0”和“1”,從而避免了昂貴的DNA合成。與之相似,以天然M13噬菌體單鏈DNA為骨架,Chen等[72-73]在骨架上間隔插入帶有生物素標記的支鏈DNA用以記錄信息,并通過納米孔測序檢測是否帶有標記物來讀取數據的“0”和“1”。然而,這種基于天然DNA分子鏈的存儲技術沒有發揮DNA存儲密度大的優勢。
除此之外,華盛頓大學和微軟公司的研究團隊[74]也嘗試了對組裝后的寡核苷酸池進行納米孔測序。上海交通大學Zhang等[75]利用DNA折紙技術實現信息的加解密,這種基于結構的信息表示和加密方法,為保證重要信息的安全性提供了新的方案。
3 挑戰與展望
當前DNA信息存儲的主要挑戰為單位信息存儲成本高,信息讀寫速度慢,無法高效對接現有信息系統。因此,DNA信息存儲當前發展的重點是進一步降低成本,提高讀寫速度,實現與現有信息系統的融合。
3.1 更低成本的信息寫入
目前,寡核苷酸池的商業合成價格大約為0.002美元/base,折合0.001美元/bit(約8.6×106美元/GB)[23,76],寫入成本較高,是硬盤的108倍[77],如圖5所示。美國情報高級研究計劃局(IARPA)分子信息存儲技術(MIST)項目的目標是到2023年DNA信息寫入成本將降低至10-10美元/bit(約0.86美元/GB)[78]。
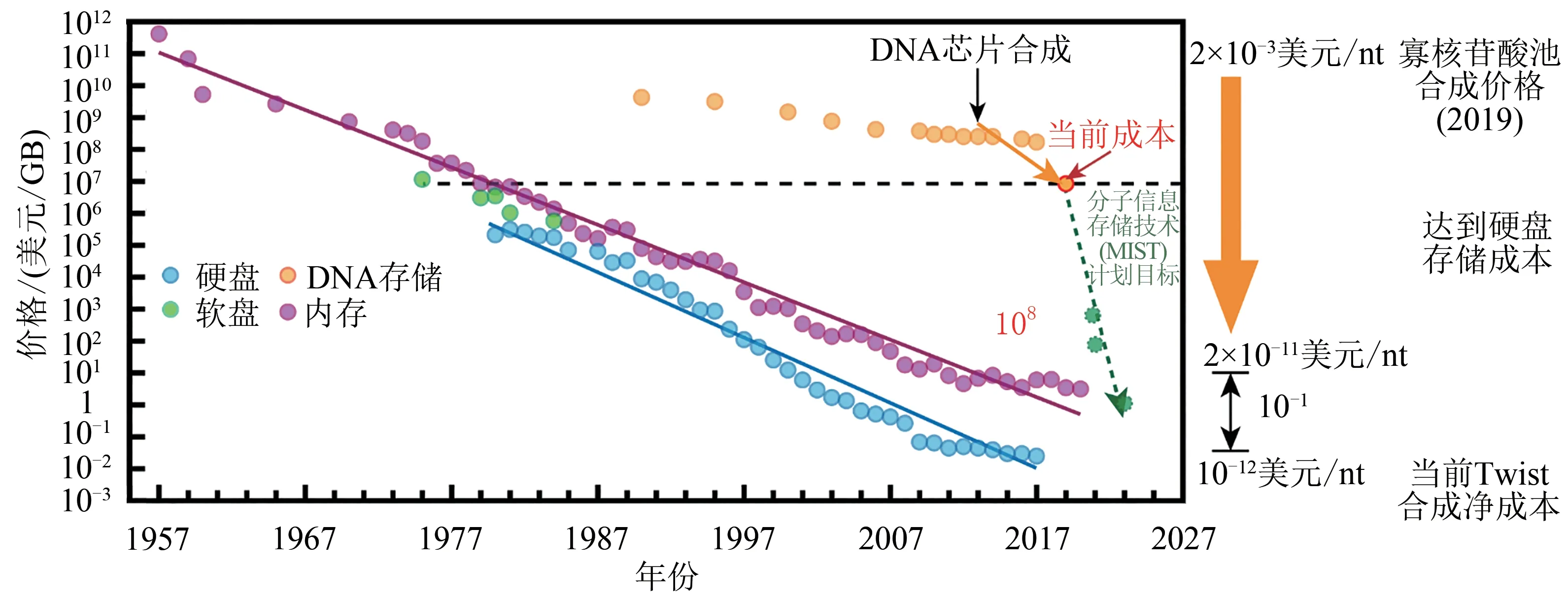
圖5 DNA信息存儲成本比較與預測Fig.5 Comparison and forecast of cost by DNA information storage
DNA信息存儲成本在未來有很大下降的潛力。首先,Twist Bioscience的首席技術官在2016年聲稱其合成成本已經低于10-12美元/base[79]。但是,運行維護、合成芯片、試劑耗材、質量控制以及人工等其他成本造成了現有DNA信息寫入成本較高的現狀。可以從優化合成反應、改良芯片結構、替換廉價耗材、優化試劑分配量等多方面著手,有望大幅降低合成成本。其次,傳統上DNA合成主要用于生命科學研究,其技術指標與DNA信息存儲的需求不匹配。面向DNA信息存儲的合成,可容忍合成步驟產生的更多錯誤,降低精度與純度要求,減少質量控制成本,在保證數據準確性而不是序列準確性的基礎上提升合成的長度和通量,從而有望大幅降低合成成本[80]。再者,由于信息存儲領域市場規模巨大,隨著半導體器件、微納加工在DNA信息存儲領域的應用,該領域的巨大投入將對DNA合成技術產生重大影響,DNA合成技術與裝備快速迭代升級,合成通量快速提升,成本有望快速下降。
3.2 更快速的數據讀取
DNA信息存儲的讀取依賴測序技術,與磁、光、電等存儲相比,讀取速度較慢,如圖6所示。進一步提升讀取速度,是DNA信息存儲發展的一個需求。DNA的測序技術與現有電、磁存儲技術的串行讀取不同,具有高并行讀取特點,以Illumina為代表的二代測序技術可以同時讀取0.04億~11億個位點[81]。然而,每輪測序反應和信號采集時間長達2.2~19 min[82],所有反應所耗時間約占運行時間的90%。通過高通量(也即空間并行度)彌補反應時間較慢的缺陷,讀取速度可達5~500 KB/s[81](最大數據產出/最長運行時間),但是需測序完全結束后才能獲取原始數據。三代納米孔測序已經做到便攜化和低延遲數據生成,單通道測序速度約為450 bp/s(約112 B/s)[83],基 于MinION測序芯片(最多支持512通道同時讀取)的最高讀取速度約為56 KB/s(不包含電信號到堿基轉換時間)。而現有電、磁存儲技術通常每秒可讀取幾十到幾百兆字節數據。基于二代測序的數據讀取受化學反應限制,較難突破性地降低反應時間,可以通過進一步增大通量滿足未來大規模冷數據讀取需求;基于三代納米孔測序的數據讀取,依然有較大潛力提升單孔讀取速度,如固相納米孔的發展有望在保證分辨率的前提下繼續提升讀取速度1~3個數量級[84],甚至在未來超越現有存儲的讀取速度。此外,提高并行化讀取的集成程度,構建一體化、自動化的讀取專用設備也面臨很大挑戰,需要機械、生化、信息、控制等的多學科協同解決。

圖6 DNA信息存儲讀取速度對比Fig.6 Comparison of reading rate for DNA information storage
3.3 DNA信息存儲與現代存儲系統的融合
依據DNA合成與讀取的技術發展現狀和特點,DNA信息存儲有望率先在冷數據存儲方面獲得應用[85]。圖7為DNA信息存儲在開放系統互聯(OSI)、模型中的映射關系以及存儲系統分等級架構。DNA作為新介質,融入現代存儲系統的過程,也是信息存儲系統不斷演化完善的過程。
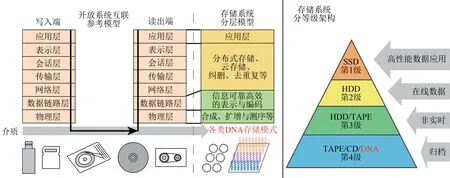
圖7 DNA信息存儲與現代存儲系統的融合Fig.7 Fusion of DNA information storage and information storage system
在物理層,造成DNA數據存儲不可靠的因素主要包括:合成、擴增以及測序處理過程的非理想,體現在堿基的插入、缺失、替代(IDS)錯誤以及DNA分子或片段丟失等[86];按照信息理論研究范式,一旦建立了準確的堿基錯誤模型,就可以設計匹配的信息編碼方法與數據恢復方法[31],設計有效的數據鏈路層。但是,由于DNA信息存儲信道的一些新特點,例如包含Indel錯誤、信道容量尚無法準確計算[87],值得深入研究[13,32,88]。中間各層是DNA信息存儲融入現代存儲系統的橋梁。傳統數據存儲領域的關鍵技術,需要結合DNA介質與DNA存儲的新特點進行優化設計。例如,目前糾刪碼已經在基于寡核苷酸池的信息存儲模式得到了很好的應用[27,40]。同時,糾刪碼也廣泛應用于存儲系統的中間各層,如何協調設計是一個非常有價值的問題。在應用層,提供的用戶服務需要與DNA存儲特點相適配[89]。例如,數據檢索、聚類分析、數據挖掘、特征識別等,需要方便地讀取數據,而現階段DNA信息存儲將大塊數據封裝于無法實時讀取的DNA介質。因此,探索結合DNA信息存儲特點的“存算一體化”的處理引擎,設計跨層的直達DNA介質的機制就顯得極為重要。
存儲系統的分等級架構是存儲系統充分發揮作用的基礎,DNA作為新的存儲介質,短期內其技術特性與大容量冷數據歸檔存儲最為匹配。據預測,歸檔的冷數據比例高達60%[90],冷數據的DNA存儲展現出了巨大的發展潛力,有望平穩融入現代數據存儲體系。
值得一提的是,DNA信息存儲也可能給傳統信息系統帶來安全方面的隱患。研究者可將計算機病毒信息存儲于DNA,通過DNA測序以及處理過程,訪問并進入非合作方的計算機系統,造成信息安全風險[91-92]。而DNA分子極小的物理尺度、特定條件下穩定的物理性質和無金屬特征的非電/磁存儲,為隱蔽數據傳遞提供了新途徑。將攜帶信息的DNA封裝為可打印材料,存儲到常見的生活物品中并隱蔽傳遞[26,93],可能造成敏感數據泄露。
3.4 總結
近年來,DNA信息存儲的基本原理、技術流程和應用模式引起了研究者的廣泛關注。DNA信息存儲連接了生命系統與信息系統,推動相關研究與應用的發展。以“DNA硬盤”為主的體外存儲與電子信息系統耦合更多,拓展了現有基于磁、光、電的電子信息存儲系統;以“DNA光盤”和“DNA磁帶”為主的體內存儲與生命信息系統耦合度比較大,提供了細胞內的信息存儲器或記錄器,為未來細胞計算或細胞通信的發展提供了更廣闊的空間。DNA信息存儲是一個新興的、多學科深度交叉融合的研究方向。進一步推動其走向實用化,仍面臨很多挑戰。為應對挑戰,美歐的相關企業、大學與研究機構已經組成了DNA數據存儲聯盟,通過廣泛合作共同制定全面的行業路線圖,以推動DNA信息存儲的產業化發展。據高德納咨詢公司預測,到2024年,將有30%的數字業務進行DNA存儲試驗[94],以應對指數級增長的數據存儲需求。面對未來的存儲需求,國內也亟需布局和發展DNA信息存儲研究與應用。本文從合成生物學與信息科學交叉融合的視角,對近年來DNA信息存儲的研究進行了綜述與展望,希望能吸引更多研究者在該交叉框架下提出有價值的研究問題,推動DNA信息存儲的發展與應用。
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
大眾創業(2009年10期)2009-10-08 04:52:00
數字社區&智能家居(2009年7期)2009-09-29 08:16:48
數字社區&智能家居(2009年11期)2009-06-25 04:30:34
數字社區&智能家居(2009年3期)2009-04-21 03:09:04
數字社區&智能家居(2009年2期)2009-03-27 04:33:44
數字社區&智能家居(2009年12期)2009-02-03 07:50:48
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
