基于Stacking組合分類算法的新體制雷達(dá)型號識別技術(shù)
2021-07-21 07:46:04張生杰張譯方閆亞斌邱光輝
火控雷達(dá)技術(shù) 2021年2期
徐 晶 張生杰 張譯方 周 超 閆亞斌 邱光輝
(西南電子設(shè)備研究所 成都 610036)
0 引言
雷達(dá)輻射源型號識別是將偵測到敵方雷達(dá)發(fā)射的信號,在信號分選基礎(chǔ)上,分析工作參數(shù),實(shí)現(xiàn)雷達(dá)輻射源型號判識,完成準(zhǔn)確的威脅判斷和搭載平臺識別,為作戰(zhàn)指揮人員提供戰(zhàn)場態(tài)勢信息和戰(zhàn)術(shù)決策行動信息[1-2]。
隨著新體制、多功能雷達(dá)的廣泛運(yùn)用,戰(zhàn)場電磁環(huán)境呈現(xiàn)密集性和復(fù)雜性,雷達(dá)信號呈現(xiàn)頻率捷變快、參數(shù)變化多的特點(diǎn),傳統(tǒng)雷達(dá)信號處理在分選、關(guān)聯(lián)、識別各個(gè)環(huán)節(jié)面臨巨大挑戰(zhàn),難以有效處理新體制雷達(dá)信號[3]。其中,以相控陣?yán)走_(dá)型號的準(zhǔn)確識別問題尤為突出;另一方面,隨著神經(jīng)網(wǎng)絡(luò)等人工智能算法的引入,一定程度上解決了對復(fù)雜雷達(dá)信號的識別問題[4-6]。但由于戰(zhàn)場環(huán)境的非合作化,復(fù)雜體制雷達(dá)信號參數(shù)的可區(qū)分特征維度少、樣本數(shù)據(jù)存在錯(cuò)誤、缺失等特點(diǎn),要求所運(yùn)用的人工智能算法能夠同時(shí)具備對小樣本數(shù)據(jù)泛化能力和對錯(cuò)誤樣本數(shù)據(jù)容錯(cuò)能力的特點(diǎn)[7]。因此,運(yùn)用諸如隨機(jī)森林、SVM、CNN等目前較為成熟的單一人工智能算法無法取得最優(yōu)的識別效果。
為解決上述問題,本文提出一種基于Stacking組合分類方法的雷達(dá)輻射源型號識別技術(shù),通過構(gòu)造兩級疊加式架構(gòu),將卷積神經(jīng)網(wǎng)絡(luò)、支持向量機(jī)等機(jī)器學(xué)習(xí)算法組合,豐富識別手段,同時(shí)擴(kuò)展識別參數(shù)維度,結(jié)合特征規(guī)律和不同智能算法的特點(diǎn),針對性地將不同參數(shù)作為各個(gè)分類器的輸入特征向量,達(dá)到對特征參數(shù)的最佳運(yùn)用,形成對復(fù)雜體制雷達(dá)的準(zhǔn)確識別。
1 Stacking框架基本原理
Stacking框架是一種疊加式分類器[10],具有較強(qiáng)的可擴(kuò)展性,組合的層次可以從一層到多層向上延伸,該方法將組合問題看做歸納過程,利用前一級模型的輸出作為下一級的輸入,使得前一次的學(xué)習(xí)能充分用于后面的歸納過程,發(fā)現(xiàn)并糾正分類偏差[11],提高學(xué)習(xí)的精度。
Stacking框架通常采用的是兩級式框架結(jié)構(gòu),通過對多個(gè)分類器的輸出結(jié)果進(jìn)行融合,利用前一級分類器的輸出結(jié)果以及其他的特征作為下一級分類器的學(xué)習(xí)輸入特征,使得后一級的學(xué)習(xí)對前一級輸出結(jié)果進(jìn)行充分的歸納學(xué)習(xí),同時(shí)能及時(shí)發(fā)現(xiàn)識別誤差并糾正,從而獲得比單個(gè)獨(dú)立分類器更優(yōu)異的識別率[12]。兩級Stacking框架中第1級代表各個(gè)成員分類器,稱為基分類器,第2級代表更高一層的融合歸納分類器[13],稱為元分類器,決定Stacking泛化能力的關(guān)鍵是基分類器和元分類器的組合方式。
Stacking框架工作的過程分為訓(xùn)練和分類兩個(gè)階段,訓(xùn)練階段采用訓(xùn)練樣本數(shù)據(jù)來創(chuàng)建第1級和第2級分類器,分類階段使用生成的1、2級分類器來測試未知類別的數(shù)據(jù)類別[12]。
1.1 訓(xùn)練過程
首先利用訓(xùn)練數(shù)據(jù)對第1級分類器進(jìn)行訓(xùn)練,訓(xùn)練過程采用交叉驗(yàn)證的方式進(jìn)行[13],假設(shè)訓(xùn)練數(shù)據(jù)為
D={(x(n),y(n)),n=1,2,3,…,N}
其中:x(n)代表第n個(gè)訓(xùn)練樣本數(shù)據(jù),y(n)代表訓(xùn)練樣本標(biāo)簽,隨機(jī)將訓(xùn)練數(shù)據(jù)劃分為k個(gè)大小基本相等的子集D1,D1,…,Dk,分別定義Dk和D(-k)=D-Dk為K折交叉驗(yàn)證中的第k折測試集和訓(xùn)練集。給定S個(gè)分類學(xué)習(xí)算法作為第1級歸納算法,對訓(xùn)練集D(-k)用第s個(gè)算法歸納得到模型D(-k),s=1,…,S。
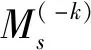
Dcv={(yn,z1n,…,zsn),n=1,…N}
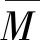
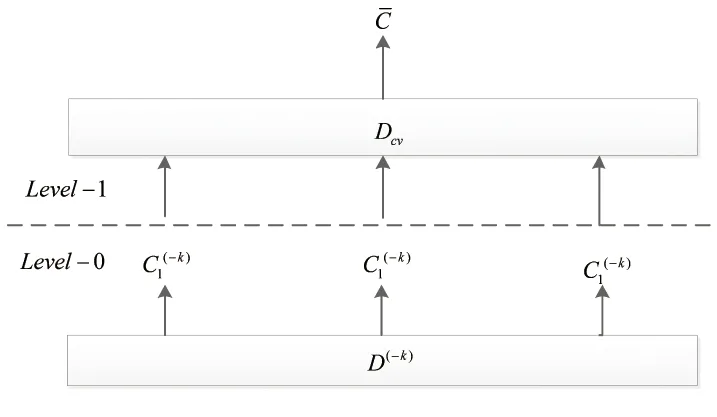
圖1 Stacking的泛化示意圖
基于Stacking的組合分類器方法系統(tǒng)架構(gòu)如圖2所示。
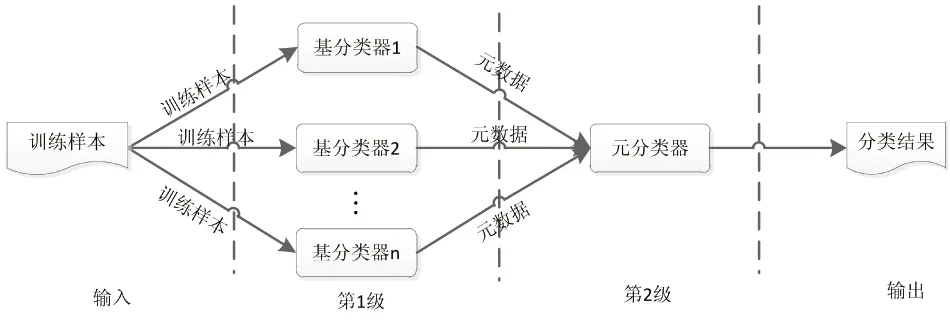
圖2 基于Stacking組合分類器系統(tǒng)架構(gòu)
1.2 分類過程
對于輸入的一個(gè)待分類樣本x,對它的分類過程分為如下兩步:
1)由第1級分類器對它進(jìn)行分類,得到預(yù)測結(jié)果;
2)將第1級分類器的預(yù)測結(jié)果看做是一個(gè)新的預(yù)測樣本,送入第2級分類器,由第2級分類器來預(yù)測類別[14]。
2 基于Stacking框架的識別技術(shù)
雷達(dá)輻射源型號識別的關(guān)鍵在于特征參數(shù)和分類器的選擇。分類器選擇主要面臨如下挑戰(zhàn):一是特征矢量比較復(fù)雜,維度較多,對分類器識別能力提出較高的要求;二是雷達(dá)輻射源識別作為偵收機(jī)信號處理的關(guān)鍵環(huán)節(jié),接收到的信號持續(xù)時(shí)間較短,分類器必須具備在小樣本條件下的快速、穩(wěn)定識別能力,識別準(zhǔn)確率必須滿足實(shí)戰(zhàn)化需要[15]。
2.1 總體思路
參照Stacking組合分類器系統(tǒng)架構(gòu),將傳統(tǒng)一級分類架構(gòu)擴(kuò)展到兩級,通過一個(gè)融合模型來融合若干個(gè)單模型的預(yù)測結(jié)果,這個(gè)單模型稱為1級模型,融合模型稱為2級模型,第1級分類器采用卷積神經(jīng)網(wǎng)絡(luò)(CNN),第2級分類器采用支持向量機(jī)(SVM),通過合理組織兩級分類器使得Stacking架構(gòu)具備更優(yōu)異的泛化能力。利用新體制雷達(dá)脈間常規(guī)特征參數(shù)、脈內(nèi)特征參數(shù),實(shí)現(xiàn)對雷達(dá)不同特征參數(shù)識別結(jié)果的融合。
2.2 分類器選擇
由于受電磁環(huán)境的影響,偵收到的輻射源信號數(shù)據(jù)受到嚴(yán)重干擾,無法準(zhǔn)確提取表征信號的有效特征,尤其是新體制雷達(dá)技術(shù)的快速發(fā)展使得現(xiàn)有技術(shù)無法靈活適應(yīng),因此需采用類似大腦皮層多級處理的層級編碼結(jié)構(gòu)智能化提取更抽象的深層特征。
神經(jīng)網(wǎng)絡(luò)分類器具有分析非線性模式數(shù)據(jù)、處理大數(shù)據(jù)的能力,處理分析數(shù)據(jù)速度較快,通過對數(shù)據(jù)特征的學(xué)習(xí)和記憶達(dá)到對未知類別數(shù)據(jù)的準(zhǔn)確識別[21]。卷積神經(jīng)網(wǎng)絡(luò)(CNN)作為一種典型的深度學(xué)習(xí)算法,目前廣泛應(yīng)用于圖像處理、語音識別等領(lǐng)域,取得了突破性的成果。深度學(xué)習(xí)模型從低層次特征提取更高層抽象特征屬性,實(shí)現(xiàn)了復(fù)雜的非線性函數(shù)逼近,較淺層模型泛化能力更強(qiáng),能刻畫數(shù)據(jù)更豐富的本質(zhì)信息[16]。卷積神經(jīng)網(wǎng)絡(luò)采用“局部感受區(qū)域”的策略,以減少網(wǎng)絡(luò)中的非重要參數(shù),同時(shí)采用權(quán)值共享和降采樣技術(shù),大幅減少了訓(xùn)練參數(shù)的數(shù)量,提高訓(xùn)練識別速度并有效防止網(wǎng)絡(luò)過擬合,以達(dá)到更好的學(xué)習(xí)和泛化效果,能取得較好的識別準(zhǔn)確率。根據(jù)目前的研究資料,雷達(dá)輻射源識別領(lǐng)域采用的均是人為設(shè)計(jì)的特征參數(shù),深度特征的學(xué)習(xí)尚未得到廣泛應(yīng)用,提取雷達(dá)輻射源信號深層表征特征是目前亟待解決的問題。
支持向量機(jī)(SVM)專門研究小樣本條件下機(jī)器學(xué)習(xí)規(guī)律,在處理高維數(shù)據(jù)時(shí),能有效解決“維度災(zāi)難”,具有很好的泛化能力[17-19]。支持向量機(jī)在解決小樣本、非線性及高維模式識別問題中表現(xiàn)出結(jié)構(gòu)簡單、全局最優(yōu)、泛化能力強(qiáng)等許多特有的優(yōu)勢[18],已在許多研究領(lǐng)域得到成功應(yīng)用。
雷達(dá)輻射源數(shù)據(jù)具有非合作、小樣本、碎片化等顯著特點(diǎn),因此輻射源分類識別是在小樣本條件下的非線性分類問題,對識別速度和識別準(zhǔn)確率均有較高的要求,為了提取雷達(dá)輻射源深層特征,實(shí)現(xiàn)多維度特征數(shù)據(jù)處理,本文采用卷積神經(jīng)網(wǎng)絡(luò)作為第1級分類器,為了解決小樣本條件的判識問題,增強(qiáng)識別模型的泛化能力,采用支持向量機(jī)作為第2級分類器,SVM卷積核采用徑向基函數(shù)(RBF)。
2.3 系統(tǒng)設(shè)計(jì)
本文采用Stacking框架與機(jī)器學(xué)習(xí)算法相結(jié)合的方式,系統(tǒng)結(jié)構(gòu)如圖3所示。主要分為訓(xùn)練過程和識別過程。
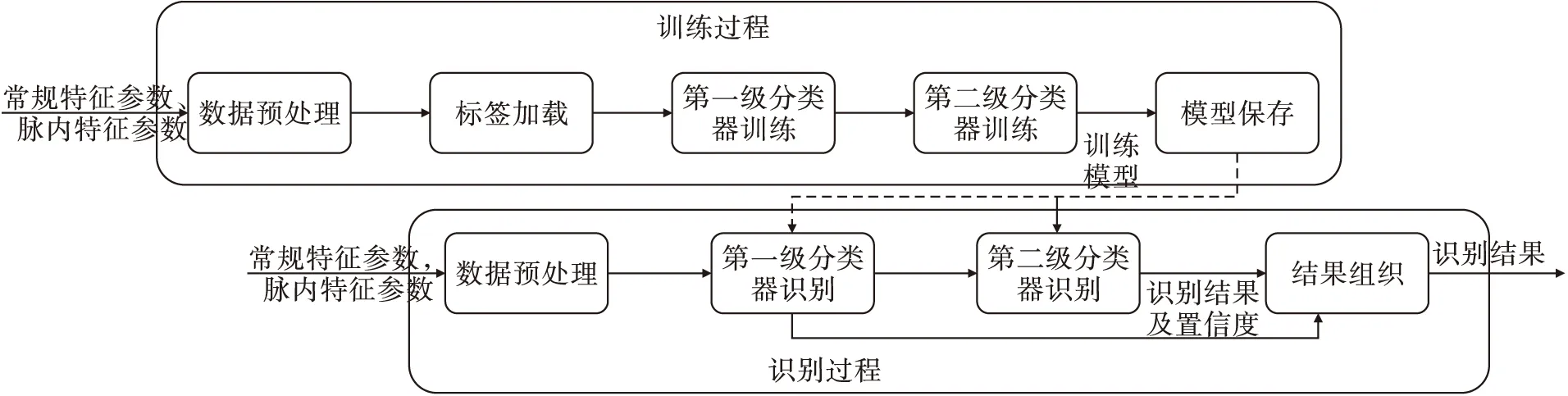
圖3 Stacking融合算法分類器實(shí)現(xiàn)
其中,訓(xùn)練過程為:
1)數(shù)據(jù)預(yù)處理
預(yù)處理步驟主要分為數(shù)據(jù)過濾、特征提取,具體為:
①數(shù)據(jù)過濾:為了濾除噪聲及背景信號影響,根據(jù)已知數(shù)據(jù)接收情況,按照頻段、參數(shù)范圍等規(guī)則進(jìn)行過濾;
②特征提取:根據(jù)信號分選算法、特征提取算法挖掘常規(guī)信號特征及脈間細(xì)微特征,根據(jù)脈內(nèi)特征提取算法分析脈內(nèi)調(diào)制特征參數(shù)。
2)標(biāo)簽加載
根據(jù)先驗(yàn)知識,對信號特征參數(shù)數(shù)據(jù)賦予對應(yīng)的標(biāo)簽(特征參數(shù)對應(yīng)的目標(biāo)ID)。
3)第1級分類器訓(xùn)練
傳統(tǒng)特征參數(shù)在雷達(dá)輻射源型號識別領(lǐng)域仍具有非常重要的作用,因此以傳統(tǒng)特征參數(shù)為主,脈間細(xì)微特征、脈內(nèi)特征為輔,訓(xùn)練識別分類器。為了提取雷達(dá)信號深層特征,第1級分類器采用卷積神經(jīng)網(wǎng)絡(luò)。利用傳統(tǒng)特征參數(shù)訓(xùn)練第1級分類器中第一個(gè)卷積神經(jīng)網(wǎng)絡(luò),利用傳統(tǒng)特征參數(shù)加脈間細(xì)微特征訓(xùn)練第1級分類器中的第二個(gè)卷積神經(jīng)網(wǎng)絡(luò),利用傳統(tǒng)特征參數(shù)加脈內(nèi)特征訓(xùn)練第1級分類器中的第三個(gè)卷積神經(jīng)網(wǎng)絡(luò)。
4)第2級分類器訓(xùn)練
第2級分類器采用支持向量機(jī)(SVM),將第1級分類器中三個(gè)卷積神經(jīng)網(wǎng)絡(luò)的輸出,結(jié)合脈內(nèi)特征,形成第1級分類器輸出的特征向量,標(biāo)簽與第1級分類器的標(biāo)簽相同,利用第1級分類器輸出的特征向量及標(biāo)簽訓(xùn)練第2級分類器。
第1級分類器和第2級分類器訓(xùn)練過程如圖4所示。
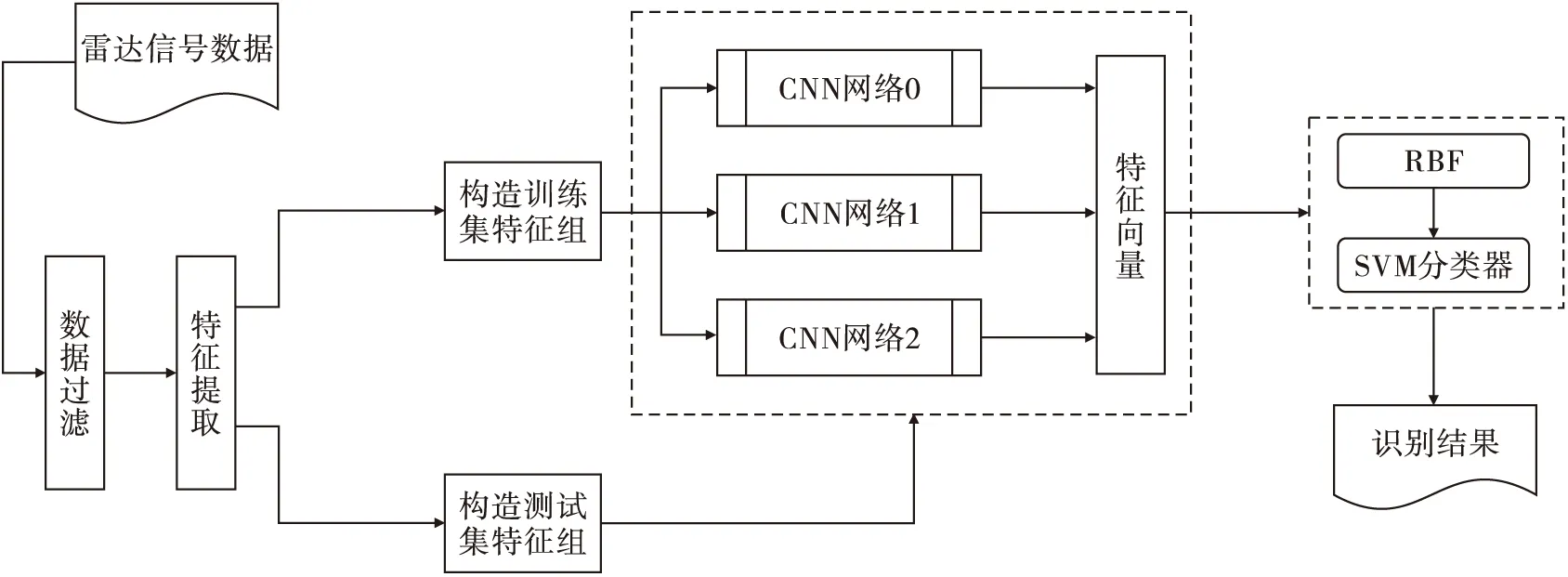
圖4 訓(xùn)練測試過程
5)模型保存
將第1級分類器中的三個(gè)卷積神經(jīng)網(wǎng)絡(luò)訓(xùn)練的模型加標(biāo)簽、第2級分類器訓(xùn)練的模型加標(biāo)簽及備注信息依次保存至模型文件中,在每個(gè)模型數(shù)據(jù)之前先保存模型標(biāo)識信息,用以標(biāo)識各個(gè)模型,模型保存方式如圖5所示。

圖5 模型保存方式
識別過程為:
1)數(shù)據(jù)預(yù)處理
識別的預(yù)處理方式與訓(xùn)練的預(yù)處理過程相同,即需要對原始數(shù)據(jù)進(jìn)行過濾、信號特征參數(shù)提取等操作。
2)分類識別
首先加載已訓(xùn)練的模型文件,根據(jù)模型標(biāo)識完成對應(yīng)分類器的初始化,根據(jù)數(shù)據(jù)預(yù)處理提取的信號特征參數(shù),采用Stacking架構(gòu)模型進(jìn)行識別。
3)結(jié)果輸出
采用第2級分類器的結(jié)果,作為最終的結(jié)果輸出。
3 仿真分析
運(yùn)用仿真方法生成6類新體制雷達(dá)目標(biāo)特征參數(shù),按照上述算法進(jìn)行驗(yàn)證分析。
不同分類器的識別結(jié)果混淆矩陣如圖6、圖7、圖8所示。采用識別準(zhǔn)確率、召回率、F1-Score指標(biāo)驗(yàn)證不同分類器的識別性能。驗(yàn)證結(jié)果如表1、表2、表3所示。

圖6 CNN識別結(jié)果歸一化混淆矩陣
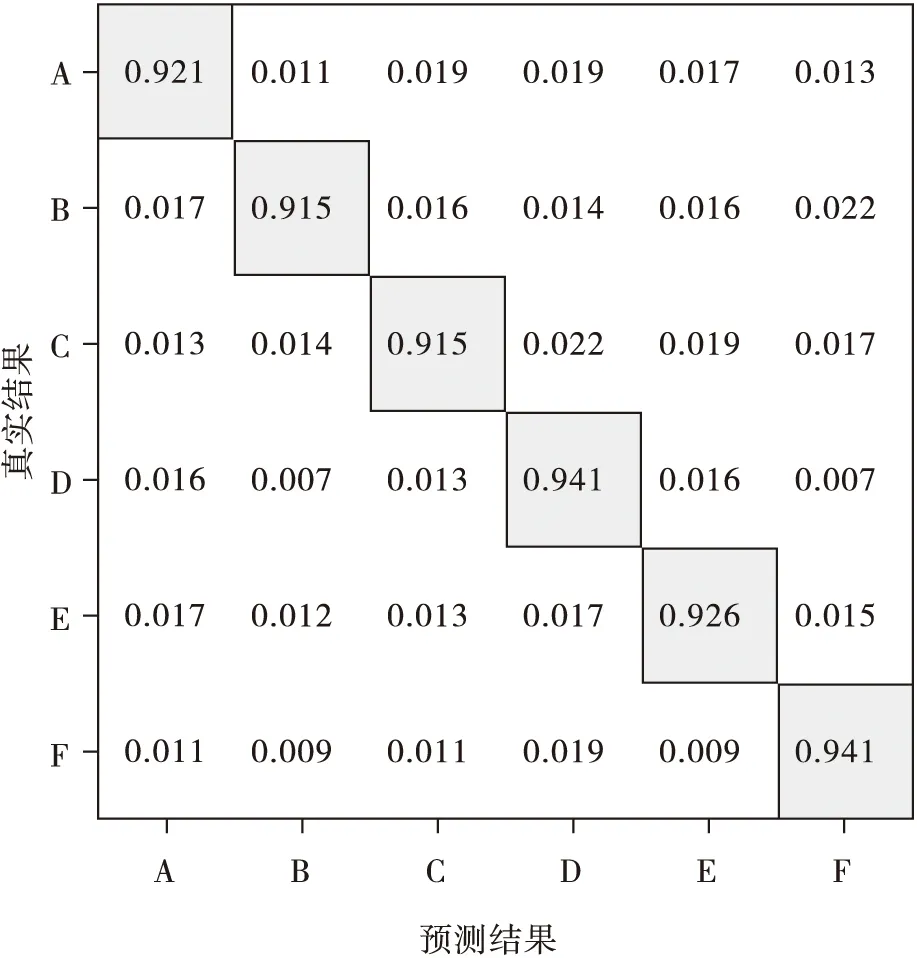
圖7 SVM識別結(jié)果歸一化混淆矩陣

圖8 Stacking識別結(jié)果歸一化混淆矩陣
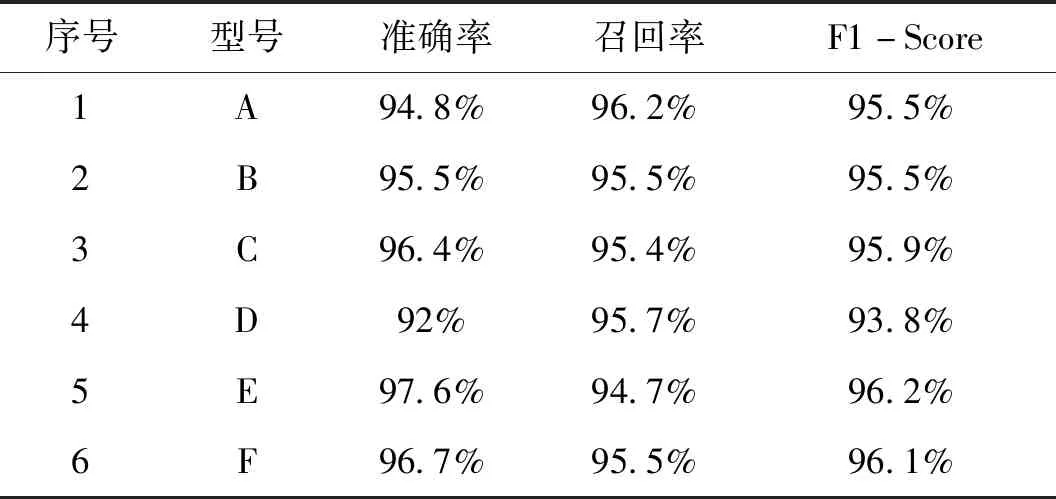
表1 CNN分類器識別結(jié)果
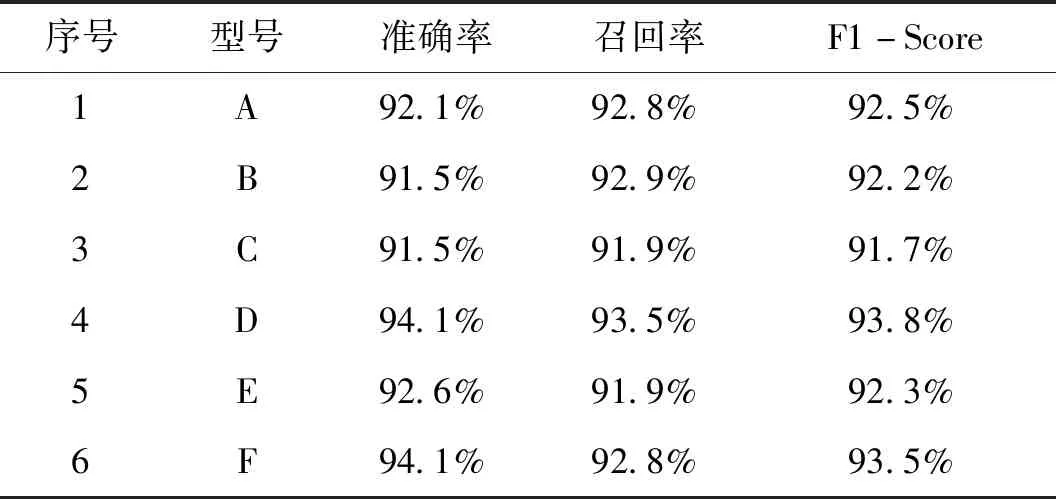
表2 SVM分類器識別結(jié)果
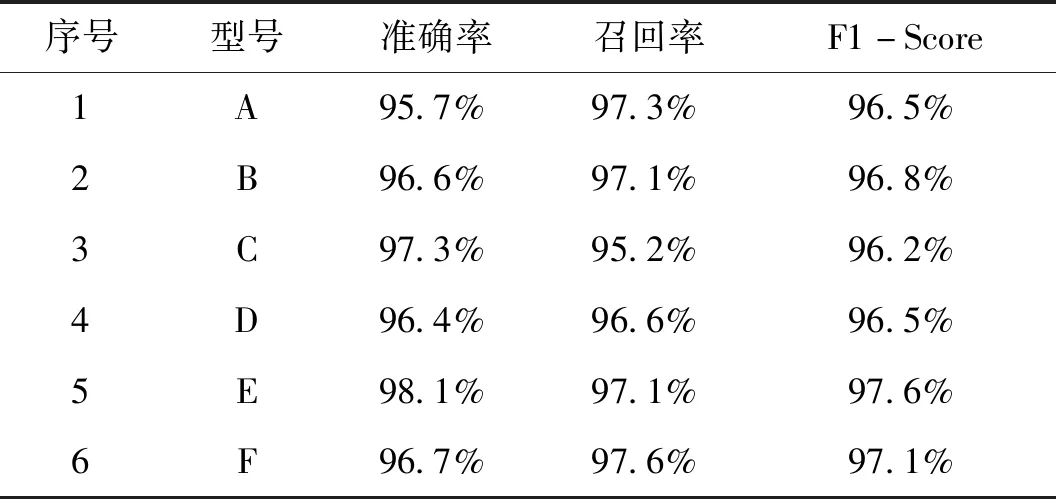
表3 Stacking分類器識別結(jié)果
從表1、表2、表3的驗(yàn)證結(jié)果可以看出,相對于單一分類器SVM、CNN,本文提出的Stacking組合分類算法能提高1%~2%的識別準(zhǔn)確度,因此,對于不同體制雷達(dá),不需要針對性地選擇最優(yōu)的基分類算法,而是利用組合分類算法去組合不同的基分類器,這種組合結(jié)果可以充分應(yīng)用不同特征參數(shù)對不同使用場景的分類貢獻(xiàn)率,結(jié)合不同信號特征參數(shù)取得最佳分類效果,具有較強(qiáng)的工程應(yīng)用價(jià)值。
4 結(jié)束語
本文從機(jī)器學(xué)習(xí)算法著手,以雷達(dá)信號特征參數(shù)為基礎(chǔ),將卷積神經(jīng)網(wǎng)絡(luò)、支持向量機(jī)應(yīng)用在新體制雷達(dá)型號識別領(lǐng)域,采用不同基分類器學(xué)習(xí)不同維度信號特征參數(shù),利用Stacking架構(gòu)組合不同分類器的識別結(jié)果,實(shí)現(xiàn)新體制雷達(dá)型號的準(zhǔn)確判識,相對于單一分類器,本文提出的識別技術(shù)能有效提升雷達(dá)輻射源識別率,具有較好的應(yīng)用前景。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
鴨綠江(2021年35期)2021-04-19 12:24:18
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
考試與評價(jià)·高一版(2020年6期)2020-11-02 02:45:24
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
中國生殖健康(2019年3期)2019-02-01 06:12:26
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
鑿巖機(jī)械氣動工具(2016年3期)2016-03-01 04:00:25
海軍航空大學(xué)學(xué)報(bào)(2015年3期)2015-11-11 17:20:00
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
