基于分層極限學習機的鋰離子電池剩余使用壽命預測?
2021-07-19 01:21:10史永勝洪元濤丁恩松施夢琢
電子器件 2021年3期
關鍵詞:模型
史永勝,洪元濤,丁恩松,施夢琢,歐 陽
(1.陜西科技大學電氣與控制工程學院,陜西 西安 710021;2.江蘇潤寅石墨烯科技有限公司,江蘇 揚州 225600)
鋰離子電池的剩余使用壽命(Remaining Useful Life,RUL)在電池管理系統中的重要性正在逐漸凸顯出來。當前對于鋰離子電池RUL 的預測方法越來越多,總體分為兩類:基于模型的方法和數據驅動的方法。基于模型法的主流模型有電化學模型、等效電路模型和數學模型等。Liu 等人[1]基于容量衰減的電化學模型,提出了一種改進的鋰離子電池退化模型。然后利用粒子濾波跟蹤模型參數和狀態的變化實現對RUL 的預測。等效電路模型利用電子元件組成的電路網絡來等效電池的電氣特性,已被廣泛用于電池狀態的估計[2]。Guha 等人[3]基于分數階等效電路模型(FOECM)得到鋰離子電池的電化學阻抗譜(EIS),然后將EIS 代入粒子濾波框架中的回歸模型預測出電池的RUL。這類方法依賴準確而復雜的電池容量退化模型,增加了建模難度和計算復雜度[4]。另一類利用大數據預測電池RUL 的方法并不需要電池內部詳細的老化機理,因此這類方法在研究預測問題上逐漸受到關注[5]。基于數據驅動的方法通常使用監測數據來擬合變量退化模型,并通過將變量外推到故障閾值來計算RUL。韋海燕等[6]通過將電池的容量數據作為新陳代謝灰色粒子濾波(MGM-PF)算法的輸入來進行電池RUL 的預測。龐曉瓊等[7]提出了一種結合主成分分析(PCA)特征融合與非線性自回歸(NARX)神經網絡的鋰離子電池RUL 間接預測框架,并結合實驗數據驗證了該框架的較強適用性。
上述方法在對電池RUL 預測時,主要利用已經循環老化后的電池特征數據結合失效閾值來判斷電池是否達到壽命終止(end of life,EOL),其本質只是對于電池當前剩余使用容量的一個估算,并沒有實現真正意義上的RUL 提前預測。而且大部分文獻的電池數據集相對較小,因此基于這些數據的預測結果并不具有代表性。
針對以上問題,本文提出了基于分層極限學習機的鋰離子電池剩余使用壽命預測模型。首先在數據集的選取方面,采用了豐田研究所的超大數據集,保證了基于大數據下的預測結果的泛化性能。其次針對大數據的數據處理方法,選擇了基于ELM 的稀疏自動編碼器進行降維和特征提取工作,縮減了大數據處理的時間并提高了預測算法的效率。最后把稀疏自動編碼器與原始ELM 相結合形成分層極限學習機H-ELM,通過對電池容量退化前期的少量循環數據進行訓練,最終實現對電池RUL 的提前準確預測。
1 分層極限學習機H-ELM 的建立
1.1 極限學習機ELM 算法
假設具有L個隱層節點的單隱含層前饋神經網絡(SLFN)可以用下式表示:
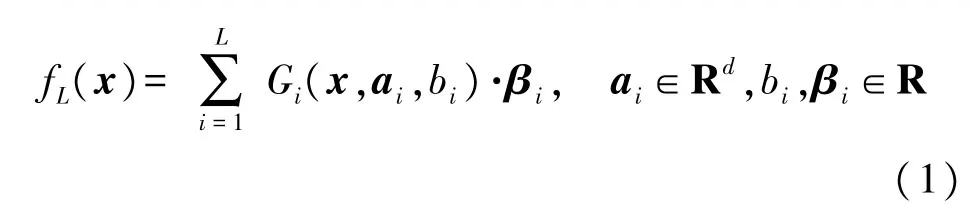
式中:Gi(?)表示第i個隱層節點的激活函數,ai是將輸入層連接到第i個隱含層的輸入權重向量,bi是第i個隱含層的偏置權重,βi是輸出權重向量。對于具有激活函數g的隱層節點,Gi定義如下:
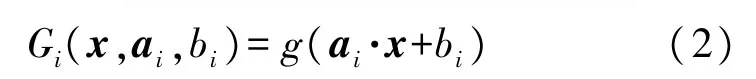
文獻[8]證明,即使隱層節點的參數被隨機初始化,SLFN 也可以逼近任意緊湊子集X∈Rd上的任何連續目標函數。因此可以使用隨機初始化的隱層節點構建ELM。給定訓練集{(xi,ti)|xi∈Rd,ti∈Rm,i=1,…,N},其中xi是訓練數據向量,ti表示每個樣本的目標,L表示隱藏的節點數。從學習的角度來看,與傳統的學習算法不同,ELM 理論旨在達到最小的訓練誤差,但也要達到最小的輸出權重范數
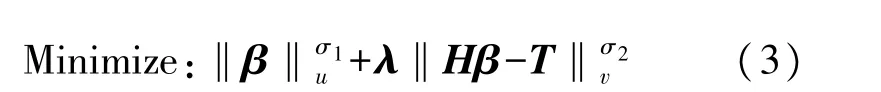
式中:σ1>0,σ2>0,u,v=0,(1/2),1,2,…,+∞,λ是用戶指定的參數,為了在最小訓練誤差和最小輸出權重之間提供折中,H表示隱含層的輸出矩陣
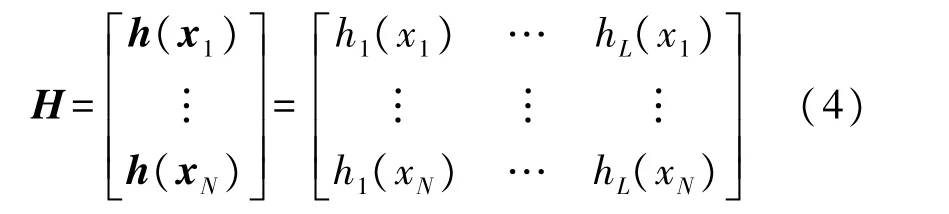
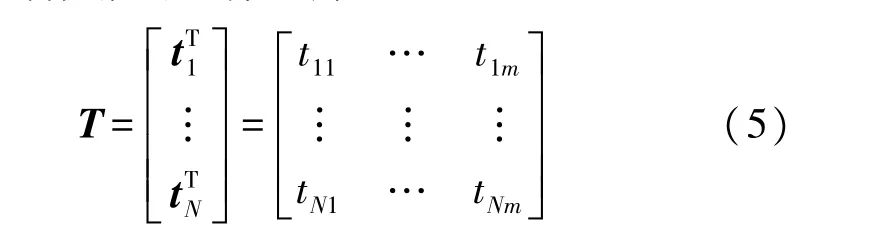
T表示訓練數據的目標矩陣
ELM 訓練算法可以總結如下。
(1)隨機初始化隱層節點的輸入權重ai和偏置bi,i=1,…,L。
(2)計算隱含層輸出矩陣H。
(3)獲得輸出權重向量

式中:H?是矩陣H的Moore-Penrose 廣義逆。
由嶺回歸理論可知,當求解輸出權重β時,可以在HTH或HHT的對角線上填入正值(1/λ)。這樣所得的解決方案等效于σ1=σ2=u=v=2 的ELM優化解決方案,它更穩定并且具有更好的泛化性能。也就是說,為了提高ELM 的穩定性,我們可以使
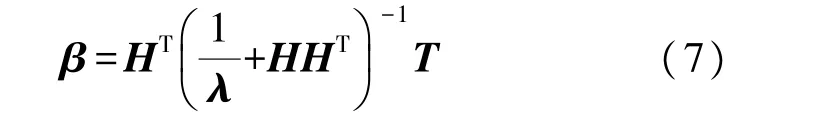
ELM 的對應輸出函數為
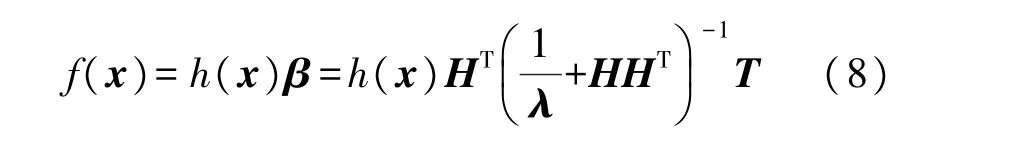
或者我們可以使

ELM 的對應輸出函數為
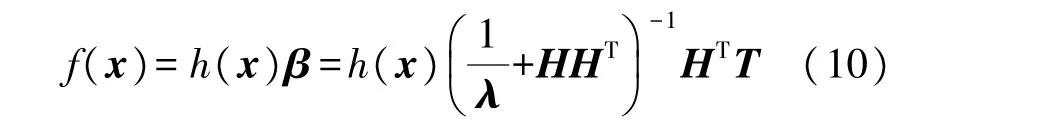
1.2 ELM 稀疏自動編碼器
自動編碼器通過將誤差趨于零使編碼后的輸出來近似原始輸入。使用隨機映射輸出作為潛在表示,可以很容易地構建基于ELM 的自動編碼器[9]。由于ELM 自動編碼器提取的特征往往比較密集,可能存在冗余,在這種情況下最好使用更稀疏的解決方案。
本文利用ELM 的普遍逼近能力進行自動編碼器的設計,并在自動編碼器優化的基礎上加入稀疏約束,因此將其稱為ELM 稀疏自動編碼器。ELM稀疏自動編碼器的數學表達式是
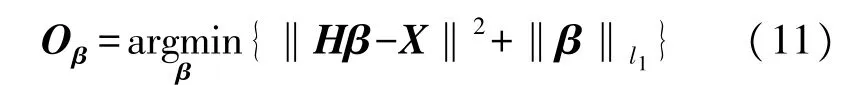
式中:X是輸入矩陣,H是隱層輸出矩陣,β是隱含層權重。隨機映射不僅有助于提高訓練時間,而且有助于提高學習精度。
為了清晰地描述l1正則化的優化算法,我們將對象函數重寫為
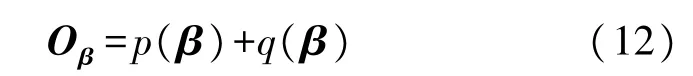
式中:p(β)=‖Hβ-X‖2,并且q(β)=‖β‖l1是訓練模式的l1懲罰項。
采用快速迭代收縮閾值算法(FISTA)來解決優化問題。FISTA 最小化了一個復雜度為O(1/j2)的光滑凸函數,其中j表示迭代次數。通過迭代計算,使用所得的β作為稀疏自動編碼器的權重,由于采用自動編碼器作為所提出的H-ELM 的結構,因此可以通過逐層比較來生成更高級別的特征表示。
1.3 H-ELM 框架
所提出的H-ELM 以多層方式構建,與傳統的深度學習框架[10]的貪婪分層訓練不同,H-ELM 訓練體系在結構上分為兩個獨立的階段:無監督的分層特征表示和有監督的特征訓練。在無監督階段,每一個隱含層的輸出都能用下式計算:

式中:Hi是第i層的輸出(i∈[1,K]),Hi-1是第(i-1)層的輸出,g(?)表示隱含層的激活函數,并且β代表輸出權重。隨著層數的增加,產生的特性變得更加緊湊。一旦前一隱含層的特征被提取出來,當前隱含層的權值或參數就會固定,不需要進行微調。
在H-ELM 中經過K層的無監督訓練后,輸出結果HK可以看作是從輸入數據中提取的高級特征。把這些高級特征進行隨機擾動以便提高模型的普遍逼近能力,然后輸入到原始ELM 模型中去,最終得到H-ELM 網絡的輸出結果。
2 基于H-ELM 的RUL 預測模型
2.1 電池的循環數據
本文使用的電池循環數據來自麻省理工學院、斯坦福大學和豐田研究所(Toyota Research Institute,TRI)合作完成的大型數據集[11]。整個數據集包括124 塊商用磷酸鐵鋰(LFP)/石墨電池,這些鋰離子電池全部是由A123 Systems 公司生產的,其型號為APR18650M1A。電池的標稱容量為1.1 Ah,標稱電壓為3.3 V。在30 ℃的恒溫室中,將這些電池放入具有48 個通道的Arbin LBT 電池測試系統中進行充放電循環。
此數據集中的所有電池都使用一步或兩步快速充電策略進行充電,一共設計了72 種不同的充電策略。每種充電策略的格式為C1(Q1)-C2,其中C1和C2分別是第一步和第二步恒流充電倍率,C1,C2∈[3.6C,6C],Q1是電流切換時的荷電狀態SOC,Q1∈[0,80%]。每個電池循環到剩余可用最大容量為0.88 Ah 時實驗停止,具體的充放電循環8 步總結如下:
(1)以充電倍率C1恒流充電至電池SOC 達到Q1;
(2)以充電倍率C2恒流充電至電池SOC 達到80%;
(3)靜置一段時間;
(4)以1 C 倍率恒流充電至上截止電壓3.6 V;
(5)以3.6 V 恒壓充電至截止電流;
(6)以放電倍率4 C 恒流放電至下截止電壓2.0 V;
(7)以2.0 V 恒壓放電至截止電流;
(8)靜置一段時間。
電池的內阻測量是在電池充電至SOC 達到80%時,通過平均10 個±3.6 C 的紅外脈沖測量內阻。數據集分為三個批次,三批實驗的時間跨度長達近一年之久,每個批次的不同點見表1。

表1 三批實驗數據的差異
通過改變充電條件,生成了一個包含約96 700個周期的數據集,其數據容量大小共計7.7GB。該數據集獲得了大范圍的循環壽命,從150 個周期到2 300 個周期不等,平均循環壽命為806 次,標準偏差為377 次。
2.2 H-ELM 的輸入輸出參數
為了得到較好的預測結果,依照文獻[11]中的內容,在選取H-ELM 模型的輸入參數時需要考慮輸入參數與電池循環壽命之間的相關性,盡量選擇具有高相關系數的參數,下面分別討論不同參數與循環壽命之間的相關性。如圖1 所示,繪制出124 個電池在前1 000 次循環中的容量衰減曲線。
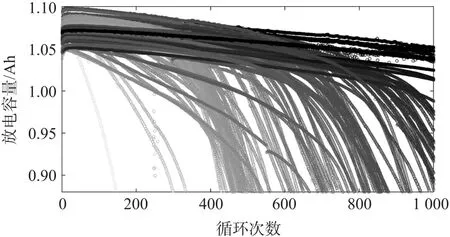
圖1 LFP/石墨電池前1 000 次循環的放電容量
在圖1 中每條曲線的灰度深淺都是由電池的循環壽命決定的,即循環壽命越長對應的放電容量曲線顏色越深,循環壽命越短曲線顏色越淺。容量衰減曲線的交叉表明了初始容量與循環壽命之間的相關性較弱。針對圖中前100 次循環的放電容量曲線可以發現到第100 次循環時循環壽命還沒有一個明顯的區分。計算出第100 次循環與第2 次循環時放電容量的比率,并把對應區間的電池數量進行統計,然后作出如圖2 所示的柱形圖。
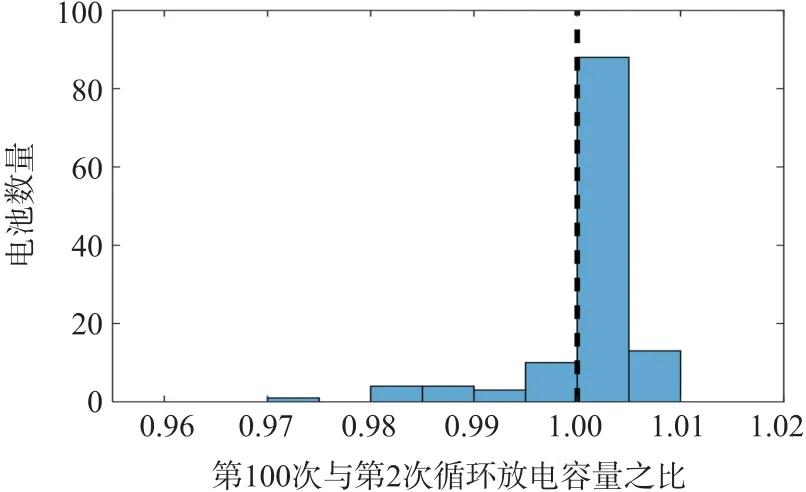
圖2 第100 次與第2 次循環放電容量之比的直方圖
如圖2 所示虛線表示比率為1.00,而且大部分電池都在比率為1 附近,因此可以看出第100 次循環的放電容量相比第2 次并沒有多大變化。大多數電池在第100 次循環時的容量略高,容量的微小增加是由于存儲在負極區域的電荷超過了正極[12-13]。本文繼續將每個電池在第2、100 次循環時的放電容量以及第95 次~100 次循環的放電容量曲線的斜率作為自變量,循環壽命的對數作為因變量,分別作出如圖3 所示的3 幅圖用來探究彼此之間的關系。
通過圖3 可以發現,在第2 次循環(相關系數為-0.061)和第100 次循環(相關系數為0.27),以及在第100 次循環附近(相關系數為0.47),循環壽命的對數和容量衰減之間存在微弱的相關性。這些微弱的相關性是可以預料到的,因為在這些早期循環中,容量退化是可以忽略的。
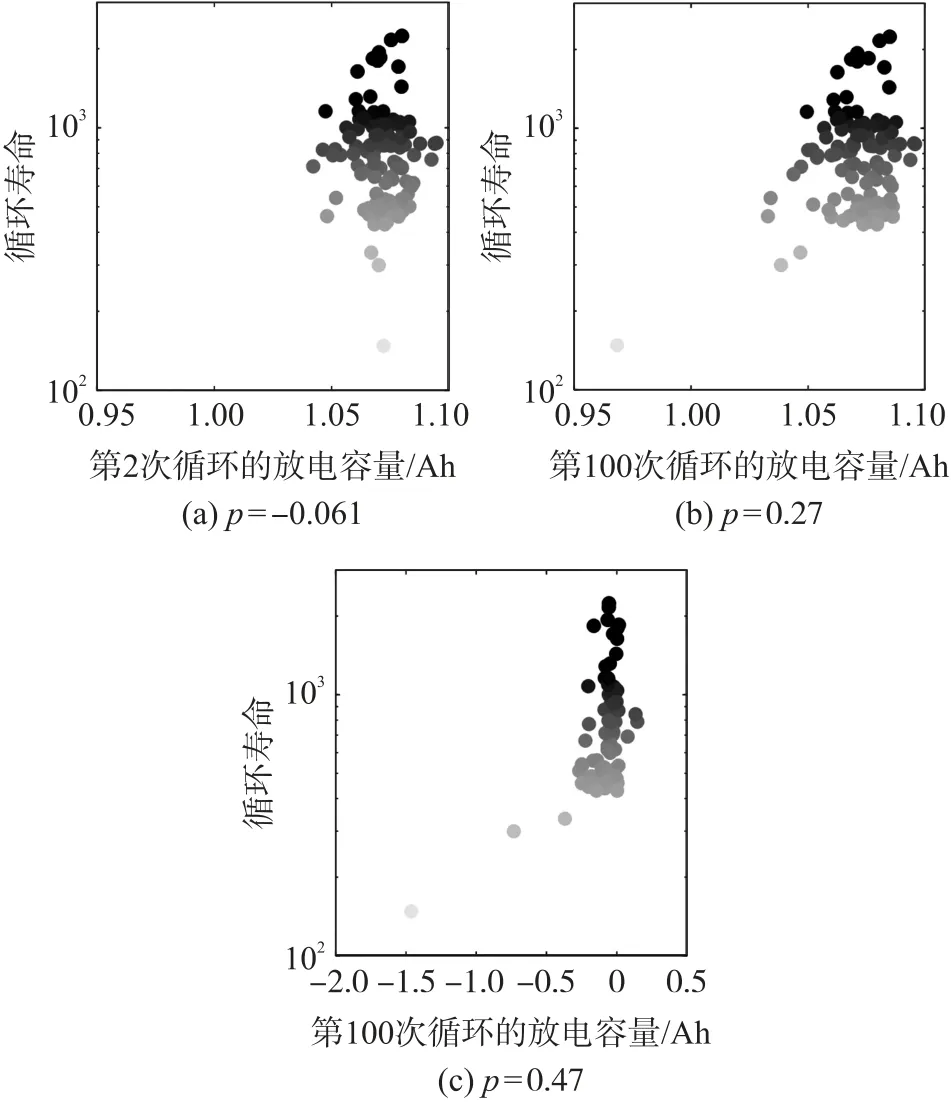
圖3 不同循環時放電容量與循環壽命的相關性
由于基于容量衰減曲線的預測能力有限,為了得到更加全面詳細的電池特征參數,本文選取了更多相關性高的輸入參數變量。包括ΔQ100-10(V)的對數方差[14-15],放電過程特征信息,充電時間,電池溫度和內阻等一共9 個循環特征,并將它們作為H-ELM 模型的輸入參數。下面對這9 個參數分別進行介紹。
(1)第100 次循環與第10 次循環放電容量之差的最小值
如圖4 所示是電池的第100 和第10 次循環的放電容量曲線,對于124 個電池,第100 次循環和第10 次循環之間的放電容量曲線差值是電壓的函數ΔQ100-10(V),計算如下。
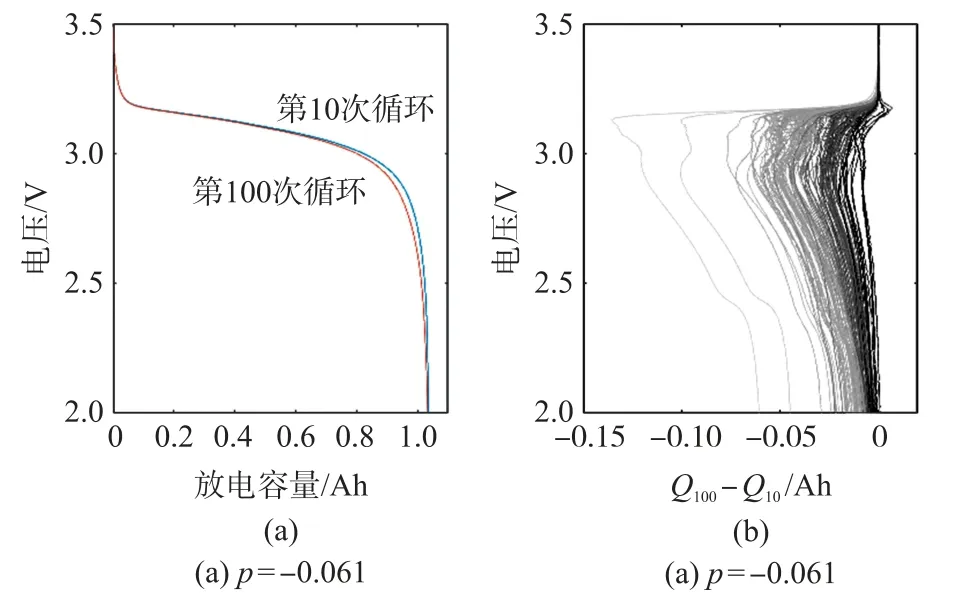
圖4 循環容量之差
(2)第100 次循環與第10 次循環放電容量之差的方差
如圖5 所示在對數坐標軸上繪制出循環壽命和ΔQ100-10(V)方差的函數,相關系數為-0.93,可見在循環壽命和基于ΔQ100-10(V)的方差之間出現了明確的趨勢,計算如下。
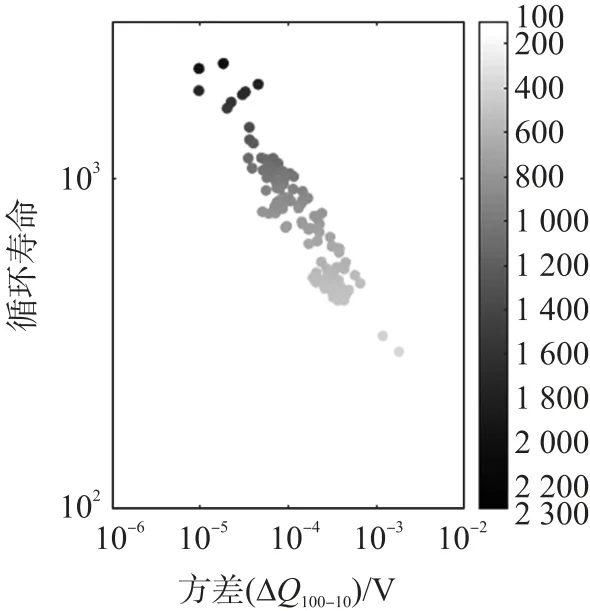
圖5 基于前100 次循環電壓容量曲線的高性能特征
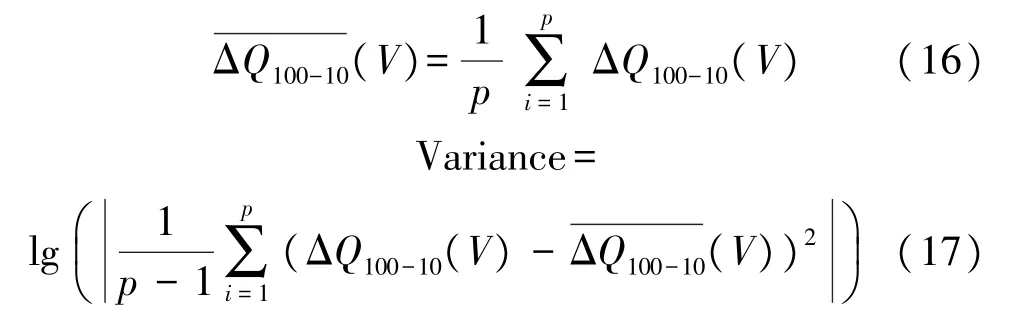
式中:p是電壓區間2.0 到3.5 V 之間的等分數,這里取p=1000。
(3)第2 次到第100 次循環容量衰減曲線的線性擬合的斜率
(4)第2 次到第100 次循環容量衰減曲線的線性擬合的截距
(5)第2 次循環的放電容量
(6)前5 次循環的平均充電時間
(7)第2 次到第100 次循環溫度隨時間的積分
(8)第2 次到第100 次循環電池內阻的最小值
(9)第100 次和第2 次循環電池內阻的差值
在確定了9 個輸入參數后,將每個電池的循環壽命作為H-ELM 預測模型的最終輸出。
2.3 H-ELM 預測模型的結構
在選擇好模型的輸入輸出變量之后,本文給出了預測模型的結構框圖如圖6 所示。
從圖6 可以看出,輸入變量先經過H-ELM 的前一層即基于ELM 的多層稀疏自動編碼器,目的是對輸入數據進行降維處理并且提取最有價值的特征。然后把新生成的特征再加載到后一層的原始ELM中,利用ELM 的快速學習能力等優勢,最終輸出鋰離子電池的剩余使用壽命。

圖6 基于H-ELM 的電池RUL 預測模型
3 預測實驗與結果分析
本文的預測算法和結果圖均在MATLAB2019a中實現。數據集一共包括124 個電池,隨機選取103 個電池的前100 個周期的實驗數據作為訓練集,剩余21 個電池數據用作測試集。在經過103 個電池數據的訓練之后,H-ELM 模型對于測試集的預測結果以及誤差分別如圖7 和圖8 所示。
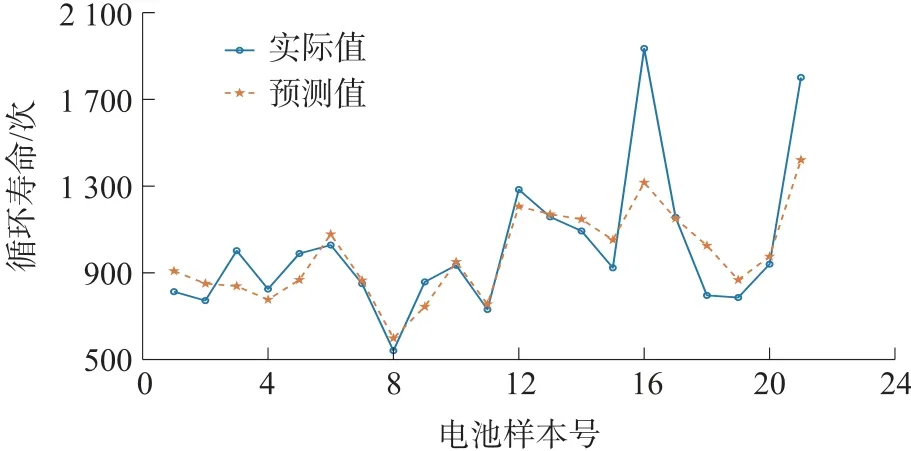
圖7 測試集電池循環壽命預測結果圖
根據圖7 可以看出H-ELM 對于測試集電池循環壽命的預測取得了較好的效果,其中大部分電池都實現了較高精度的預測,循環壽命的預測值和實際值之間相差較小。圖8 展示了測試集每個電池循環壽命預測值的相對誤差,在21 個電池當中有17個電池即80%的電池相對誤差都小于15%,進一步證實了H-ELM 對于電池循環壽命預測的有效性。由于目前利用電池前期循環數據去預測壽命的研究還相對較少,因此本文選取了均方根誤差RMSE 和平均絕對百分比誤差MAPE 兩項評價指標,將HELM 的預測結果與文獻[7]中線性模型的結果進行比較分析,具體結果如表2 所示。

表2 兩種方法的比較
通過表2 可以明顯地看出H-ELM 預測模型兩項指標均優于文獻[7]的方法,并且其均方根誤差占據較大優勢。值得注意的是,盡管本文提出的HELM 預測模型在MAPE 方面性能有所提升,但是只降低了0.56%。為了驗證H-ELM 預測模型的泛化性能和穩定性,本文隨機挑選出測試集中的第5 號電池(循環壽命為989 次)繼續利用H-ELM 進行了100 次預測實驗,并將每次的預測結果進行統計,最終繪制出如圖9 所示的預測結果分布直方圖。
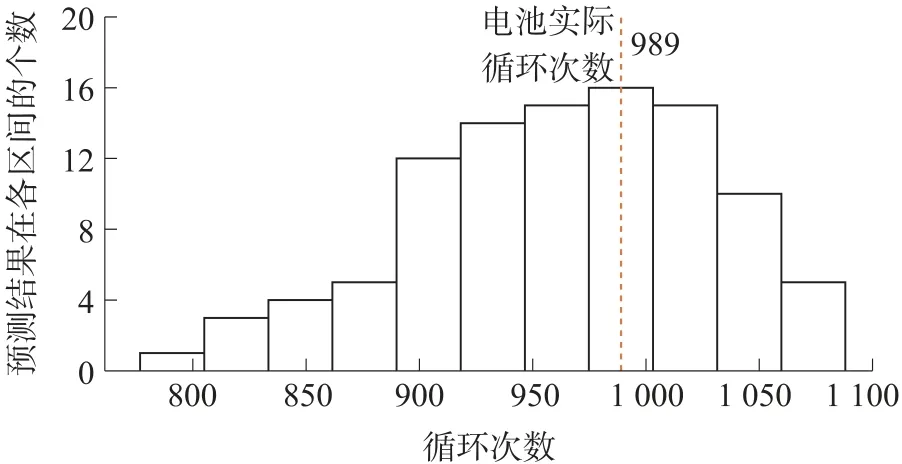
圖9 測試集中第5 個電池的預測結果直方圖
在圖9 中,對測試集中的5 號電池循環數據應用H-ELM 模型進行了100 次預測實驗,預測的循環次數結果中最小值為776 次,最大值為1 088 次。從圖中可以看出,將整個預測結果平均劃分為11 個小區間,每個區間長度大概為28,在包含電池實際循環次數989 次的區間[975,1 003]中有16 次預測結果落在其中。也就是說,有16%的預測結果都在絕對誤差小于28/2 即14 次的誤差范圍內,同理有16%的預測結果的相對誤差都小于14/989 即1.4%。進一步地擴大誤差范圍可以得到如表3 所示的統計結果。
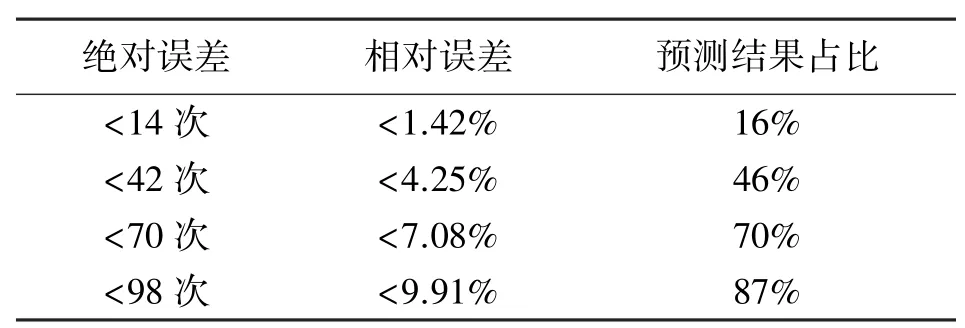
表3 誤差范圍對應預測結果占比
對這100 次預測實驗的結果進行概率分布統計,得到如圖10 所示的概率分布曲線圖。
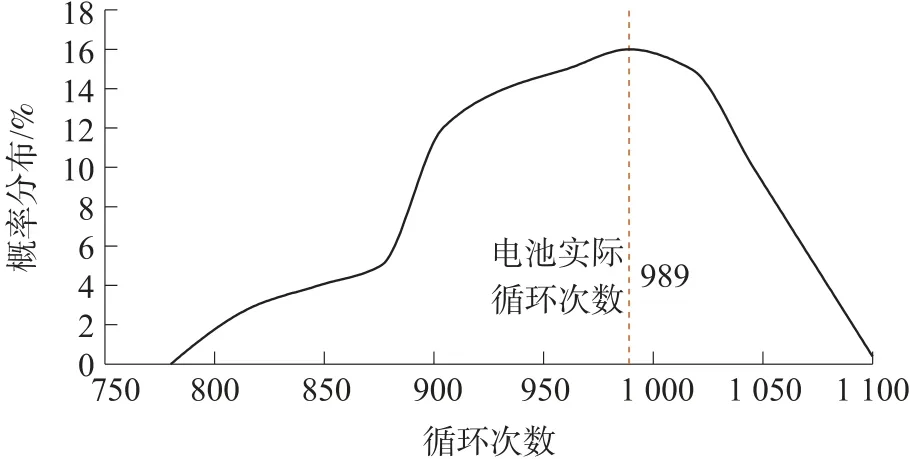
圖10 第5 號電池預測結果的概率分布圖
如圖10 所示,概率分布曲線的峰值在電池的實際循環次數989 處,并且大概率部分都集中在989附近,由此可以看出H-ELM 模型的預測結果比較穩定,泛化性能較好,可以很好地應用于實際。
4 結論
本文在對124 個電池的大量數據的處理基礎之上,應用了更加高級的H-ELM 算法,通過構建HELM 預測模型實現對鋰離子電池循環壽命的提前精準預測,主要有以下兩點結論:
(1)基于H-ELM 算法的預測模型可以對輸入數據進行降維和特征重組優化,在面向大數據應用方面,提高了數據處理的效率。
(2)根據電池前期的少量循環數據就可以準確地提前預測出其循環壽命,預測結果的MAPE 只有10.14%,并且在針對同一電池的多次實驗中表現出較好的穩定性,這將為電池的出廠檢測和新電池的研發測試節省大量時間。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
