基于XLNet的情感分析模型
2021-07-19 09:58:18梁淑蓉謝曉蘭陳基漓
科學技術與工程 2021年17期
梁淑蓉,謝曉蘭,2*,陳基漓,2,許 可
(1.桂林理工大學信息科學與工程學院, 桂林 514004;2.廣西嵌入式技術與智能系統重點實驗室, 桂林 514004)
隨著互聯網時代發展起來的各種消費、娛樂和工作平臺,不僅給人們帶來便利生活,也給意見反饋和信息交流提供媒介,人們更愿意通過網絡平臺反饋自己對事物的喜好程度。情感分析是對主觀文本的情感傾向性分析,可獲取人們對事物的情感傾向,也給決策者規劃提供參考。
情感分析的發展主要經過3個階段:基于情感詞典方法階段、基于機器學習方法階段和基于深度學習方法階段[1]。情感詞典是最早用于情感分析的手段,但人工構建的情感詞典存在情感詞不完整、在不同的語境情況下無法識別情感傾向以及不能及時收錄新詞等問題。第二階段在機器學習的基礎上,根據文本特征的提取進行情感分類,相較于情感詞典的方法能減少人工標注的勞動力,但分類器的優劣取決于特征提取的效果,導致其泛化程度不高。而深度學習的方法通過對人的神經系統的模擬來構建網絡模型,比上述兩者都更具優勢。近年來,隨著計算機生產力的提高,云計算技術、大數據等技術以及先進技術的不斷發展,使得深度學習方法被廣泛應用于自然語言處理(natural language processing,NLP)領域,主要體現在三種主流預訓練模型手段:
第一種是神經網絡語言模型Word Embedding(詞嵌入),先通過無監督學習語料得到的詞向量,再應用于下游任務,Word2Vec模型和GloVe模型都是Word Embedding的代表,但該方法未考慮上下文語義。對此,文獻[2]在Word2Vec基礎上引入BILSTM以及文獻[3]在GloVe基礎上引入LSTM,用來獲取文本的上下文信息,將提取到的詞向量輸入分類器進行情感分析,但分類器效果會依賴于特征提取能力的優劣,泛化能力不高。
第二種手段是采用RNN及其擴展方法,例如LSTM、GRU和Seq2Seq等,由于考慮了上下文語義,能很好地應對NLP中機器翻譯[4]、閱讀理解[5]和情感分析[6]等相關問題,但缺點是需要大量標注數據和監督學習。文獻[7]提出一種GRU和膠囊特征融合的情感分析模型,相對基于CNN方法的模型,準確率得到了提高。文獻[8]將BILSTM和CNN相結合,該解決方案使用遷移學習為情感分類的特定任務嵌入微調語言模型,從而能夠捕獲上下文語義。文獻[9]基于CNN和Bi-GRU網絡模型,引入情感積分來更好提取影響句子情感極性的特征,再加入注意力層使得模型相對比其他相關模型獲得更高的準確率。上述改進方式都是希望引入新機制的優勢優化模型性能,但未從本質上解決模型缺陷。
第三種手段基于無監督學習,并充分考慮上下文語義,是目前公認最有效的模型訓練手段。以此衍生的模型有ELMo[10]、OpenAI GPT[11]、Bert[12]和XLNet[13]。ELMo的本質是多層雙向的LSTM,但ELMo通過無監督學習語料得到上下文相關的特征不能適應特定任務。OpenAI GPT則是對ELMo的改進,采用Transformer替代ELMo的LSTM部分,同時針對不同任務進行Fine-Tuning,但在編碼時不能看到后文的語義。2018年Google提出的Bert模型基于Encoder-Decoder架構和雙向Transformer編碼,同時采用masked語言模型和上下文語句預測機制,BERT的出現開啟了NLP新時代,在情感分析領域也取得不錯成果,但也仍存在一定的缺陷,如模型上下游任務不一致而導致泛化能力低,每個預測詞之間相互獨立,以及生成任務能力不高。次年,谷歌大腦提出了XLNet模型,采用自回歸語言模型,引入置換語言模型解決AR模型不能雙向建模的缺陷,也增加了factorization order和Two-stream attention機制,一定程度上解決了BERT的缺陷,在許多公認的數據集任務中表現也十分優異。
當前,基于BERT和XLNet兩種模型的優化方法在情感分析上的應用成為研究人員關注的焦點,針對BERT的改進,文獻[14]基于BERT模型結合BILSTM分析微博評論的情感傾向,提出的方法F1值有較高結果,但由于BERT參數過大,訓練難度大的問題,使用的是發布訓練好的模型。針對以往模型不能解決長文本存在的冗余和噪聲的問題,文獻[15]在文本篩選網絡中采用LSTM和注意力機制相結合方式,來篩選粗粒度相關內容。再與細粒度內容組合并輸入BERT模型中,該方法一定程度提升了方面級情感分析任務性能。文獻[16]基于BERT模型,引入BILSTM層和CRF層來擴展原模型,可以根據上下文來判斷那些情感傾向不明顯文本的情感傾向。文獻[17]針對BERT模型不能提供上下文信息的問題,結合GBCN方法構建新模型,采用GBCN門控制機制,根據上下文感知嵌入的方法,優化BERT提取出的詞向量特征。文獻[18]在BERT的基礎上增加BILSTM和注意力機制構成的情感分析模型,相比以往模型,準確率和召回率都得到較好的結果。可以觀察到,大多數情況對BERT的改進是在模型的基礎上,增加一些神經網絡處理層,最后再進行微調的過程。目前針對XLNet的優化研究處于初步探索階段,但從文獻[19]可發現,基于Transformer-XL結構的XLNet模型應用于情感分析領域,其效果優于以往技術,并且訓練模型所需數據減少了120倍。文獻[20]提出一種基于XLNet和膠囊網絡的模型,該方法通過提取文本序列的局部和空間層次關系,產生的局部特征表示經過softmax再進入下游任務,其性能優于BERT模型。文獻[21]基于XLNet提出了一種CAW-XLnet-BiGRU-CRF網絡框架,該框架引入XLNet模型來挖掘句子內部隱藏的信息,相比其他中文命名實體識別框架獲得了較好的F1值。文獻[22]針對抽取式數據集(如QuAD)類型的機器閱讀理解任務,采用XLNet語言模型代替傳統Glo Ve來生成詞向量,實驗表明在基于XLNet模型訓練的詞向量的基礎上建立網層來進行SQuAD任務,比以往大多數模型取得更好的F1值。文獻[23]針對股票評論提出了基于混合神經網絡股票情感分析模型,利用XLNet語言模型做多義詞表示工作,提出的模型能兼備短文本語義和語序信息提取、捕獲雙向語義特征以及關鍵特征加權的能力。可以觀察出,采用XLNet預訓練模型學習到的詞向量比以往模型獲得更多的上下文語義信息,將XLNet預訓練模型的潛力充分挖掘成為研究人員目前的新工作。
因此,基于前人研究成果及優化策略,現提出XLNet-LSTM-Att情感分析優化模型,該模型通過XLNet預訓練模型獲取包含上下文語義信息的特征向量,利用LSTM進一步提取上下文相關特征,引入注意力機制分配權重突出特征的重要程度,再判別情感傾向性。本文模型通過在XLNet的基礎上,添加新的網絡層來獲取更為豐富的語義信息,進而提高情感分析模型預測的準確性,優化模型性能。
1 XLNet-LSTM-Att模型
目前的自然語言處理領域大多遵循兩階段模型規則,第一階段是上游任務預訓練語言模型階段,第二階段是下游任務的調優階段。XLNet-LSTM-Att模型預訓練屬于上游任務,該模型由3層結構組成,分別為XLNet層、LSTM層和Attention層,如圖1所示。
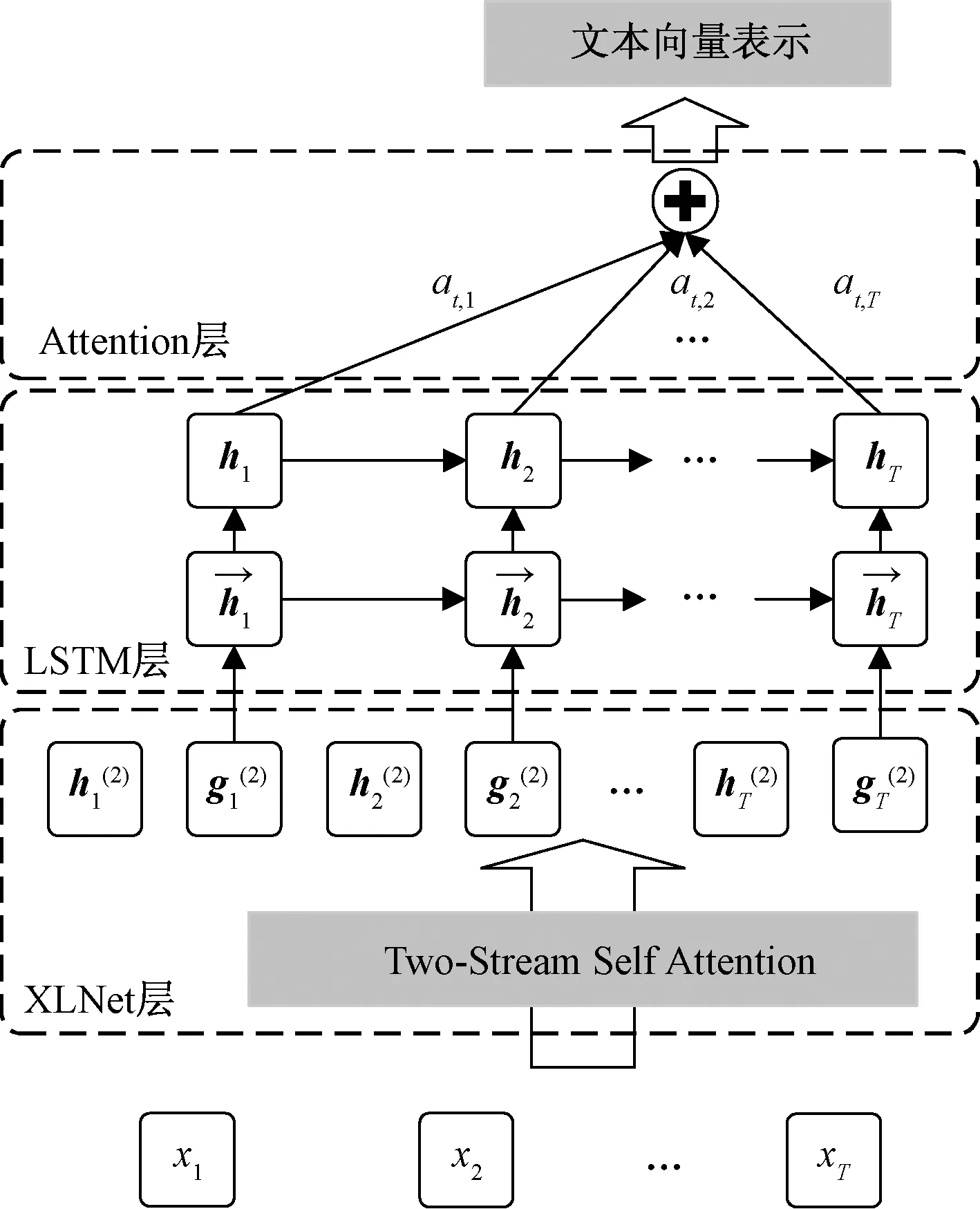
圖1 XLNet-LSTM-Att模型架構圖
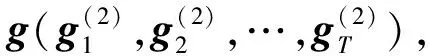
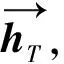
Attention層:Attention層是為了給特征向量賦予不同權值。對于從LSTM層進一步篩選出來的特征向量h(h1,h2,…,hT),通過Attention機制對保留的特征根據不同的影響程度a(at,1,at,2,…,at,T)而賦予不同權重,提高模型對重要特征的注意力。最后通過softmax激活函計算文本對應類別的向量表示,最終將向量表示執行下游情感分析任務。
1.1 XLNet層
XLNet是谷歌大腦提出的一種新的NLP預訓練模型,該模型在20個任務上超越了BERT的性能,并且在18個任務上取得了最佳效果[12]。可以預估XLNet模型未來在NLP領域的發展將會有更好的表現。
1.1.1 自回歸語言模型
XLNet基于對下游任務更友好的自回歸語言模型。自回歸語言模型具有計算高效性、建模的概率密度明確的優點。假設給長度為T的文本定序列x(x1,x2,…,xT),自回歸語言模型的目標函數由式(1)來表示。
(1)
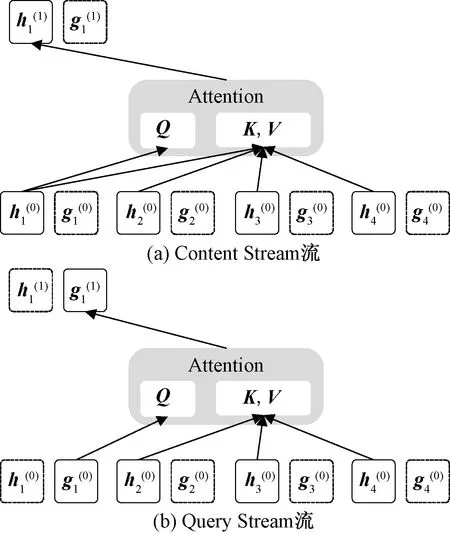
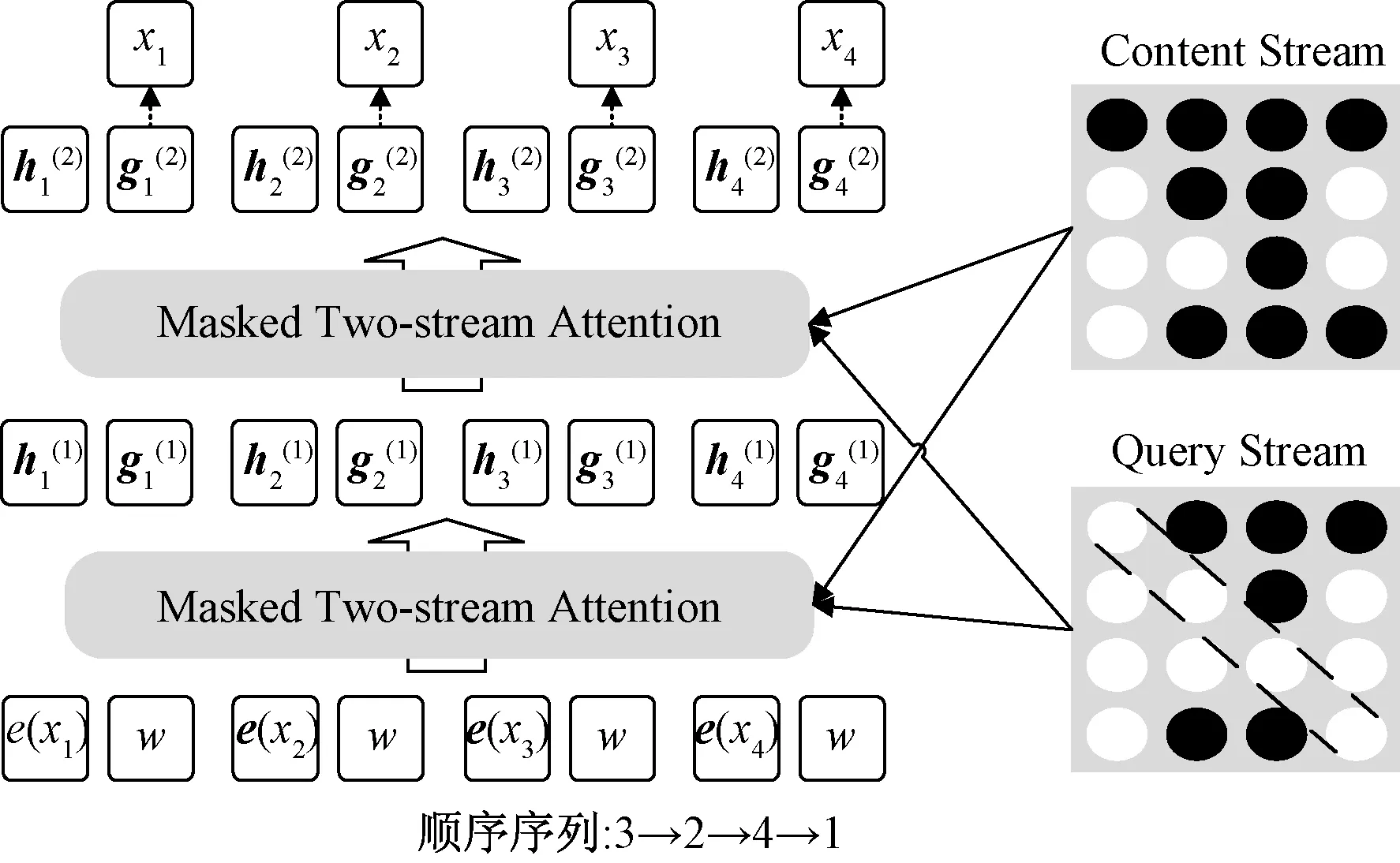
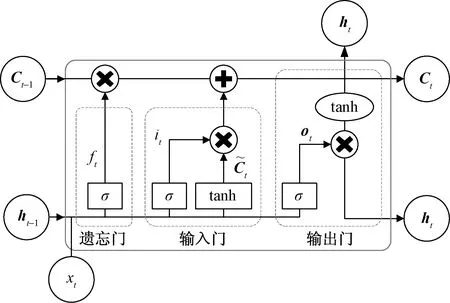
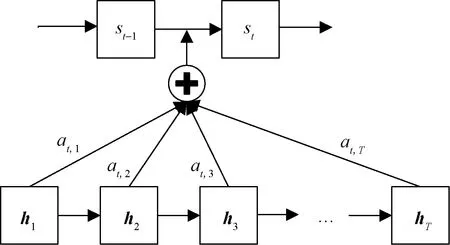
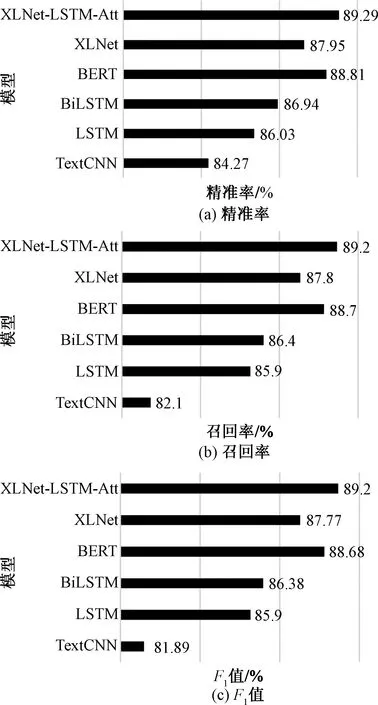
通過式(1)可知,自回歸語言模型根據上文內容來預測下一個詞,模型不能看到下文信息。假設需預測詞為xt,x 1.1.2 Permutation Language Modeling XLNet采用了一種新型的語言建模任務PLM,通過隨機排列語序來預測某個位置可能出現的詞。PLM需要兩個步驟來實現。 第一步:對全排列采樣。首先,PLM模型需對序列順序進行factorization order(全排列),以獲得不同的語序結構,假設給定序列x(x1,x2,…,xT),其語序的排列方式為1→2→3→4,對序列順序全排列得到3→2→4→1、2→4→3→1、1→4→2→3等順序。根據序列因式分解產生的不同順序來預測x3的舉例如圖2所示。 圖2 根據序列因式分解產生的不同順序預測x3 對于順序3→2→4→1的情況,因x3排在首位,則只能利用其隱藏狀態men進行預測;對于順序2→4→3→1的情況,可根據x2和x4的信息來預測x3的內容,也就達到了預測過程中獲取上下文信息的目的。 對于上述全排序的方法,對給定長度T的序列x,有T!種排序結果,當序列長度過大時會導致算法的復雜度過高,并且也會出現預測詞位于首位的情況,顯然對模型的訓練無益。因此,XLNet通過式(2)對序列全排序進行采樣優化,去除不合適的序列。 (2) 式(2)中:ZT為長度為T的序列全排列的集合;z為從ZT里采樣的序列;zt為序列z中t位置上的值;Εz~ZT為對采樣結果求期望來減小其復雜度。 第二步:Attention掩碼機制。Attention掩碼機制的原理是在Transformer的內部,把不需要的部分mask,不讓其在預測過程中發揮作用,但從模型外部來看,序列順序與輸入時保持一致。 順序序列3→2→4→1的掩碼矩陣由圖3所示,序列真實順序沒有改變,通過mask的操作達到類似隨機排序的效果。在掩碼矩陣中,其陰影部分為預測時能參考的信息,當預測x3時,由于其在首位無參考信息,因此掩碼矩陣第三行無陰影;當預測x2時,可根據x3內容預測,因此掩碼矩陣第二行的位置3有陰影,以此類推。 圖3 順序3→2→4→1掩碼矩陣 PLM既解決了AR語言模型不能獲取上下文語義的問題,又解決了BERT模型中mask之間相互獨立的問題。 1.1.3 雙流自注意機制 雙流自注意(two-stream self attention)機制可解決PLM模型中,全排序序列語序隨機打亂使得模型退化為詞袋模型的問題。雙流(two-stream)分為Content Stream和Query Stream。傳統的AR語言模型對于長度為T的序列x目標函數為 (3) 式(3)中:z為從長度為T的序列x全排列隨機采樣序列;zt為采樣序列t位置上的序號;x為預測詞;e(x)為x的embedding;內容隱狀態hθ(xz 由于PLM會將序列順序打亂,需要“顯式”的加入預測詞在原序列中的位置信息zt,式(3)更新為 (4) 式(4)中:g(xz (5) 式(5)中:m為網絡層的層數,通常在第0層將查詢隱狀態g(0)初始化為一個變量w,內容隱狀態h(0)初始化為詞的embedding,即e(x),根據上一層計算下一層數據,Q、K和V分別為query、key和value,是通過對輸入數據不同權值線性變換所得矩陣。 雙流自注意機制希望在預測xt時,只獲取xt的位置信息,對于其他詞,既要提供位置信息,又要提供內容信息。圖4是順序序列3→2→4→1預測x1時在Content Stream流和Query stream流的工作原理。 圖4 雙流模型 當預測x1時,模型能獲得x2、x3和x4的信息,其中,在圖4(a)所示的Content Stream流中,預測x1既編碼了上下文的信息(位置信息和內容信息),還編碼了預測詞本身信息;在圖4(b)的Query stream流中,預測x1編碼了其上下文信息,且只編碼了預測詞本身的位置信息。 圖5 雙流自注意機制實現原理圖 XLNet預訓練模型更夠充分學習到上下文語義信息,XLNet-LSTM-Att模型在該層將輸入文本序列轉化為可被機器識別的詞向量表達。 LSTM是一種特殊的循環神經網絡模型,該網絡模型以RNN為基礎,加入了遺忘單元和記憶單元來解決梯度消失和梯度爆炸的問題。LSTM由遺忘門、輸入門和輸出門3個門結構構成。LSTM架構如圖6所示。 ht-1為上一個單元輸出;ht為當前單元輸出;xt為當前輸入;σ為sigmod激活函數;ft為遺忘門輸出;it與的乘積為輸入門輸出;ot為輸出門輸出 各個門控單元計算公式如下。 (1)遺忘門決定上一時刻單元狀態中保留什么信息到當前時刻Ct。 ft=σ(Wf[ht-1,xt]+bf) (6) (2)輸入門決定當前時刻網絡的輸入xt有多少信息輸入到單元狀態Ct。 it=σ(Wi[ht-1,xt]+bi) (7) (8) (9) (3)輸出門控制單元狀態Ct輸出多少信息ht。 ot=σ(Wo[ht-1,xt]+bo) (10) ht=ottanh(Ct) (11) LSTM的實現首先經過遺忘門,確定模型丟棄上一個單元狀態中的某些信息,根據ht-1和xt輸出一個0~1之間的數值,決定是否舍棄該信息。然后通過輸入門來確定有多少信息被添加到單元狀態,其中sigmoid層決定信息更新,tanh層創建一個備選的更新信息,從而更新單元狀態。最后輸出門確定單元狀態的輸出信息,sigmoid層決定輸出部分,再經tanh處理得到值與sigmoid門的輸出相乘,得到最終輸出內容。 LSTM通過特殊的門結構可以解決學習能力喪失的問題,避免了當預測信息與相關信息距離較大導致的信息丟失。XLNet-LSTM-Att模型在該層對XLNet層輸出的序列進行深度學習,從而對特征向量做進一步特征提取。 Attention機制通過對輸入序列x中每個詞的重要程度賦予不同權重,使得模型能夠獲得更好的語義信息,提升模型效率。采用的注意力機原理實現公式為 eij=a(si-1,hj) (12) (13) (14) 式中:i為時刻;j為序列中的第j個元素;si為i時刻的隱狀態;eij為一個對齊模型,用來計算i時刻受第j個元素的影響程度;hj為第j個元素的隱向量;αij為i時刻受第j個元素受關注的程度;Tx為序列的長度;ci為經權重化后輸出的向量。Attention機制架構如圖7所示。 圖7 Attention機制架構 對情感分析來說,句子中的每個詞對于其情感傾向的影響是不同的,為了擴大關鍵部分的影響力,需要找到并突出其關鍵部分,因此在LSTM層上引入Attention機制來提取文本中對于情感傾向重要的部分,采用傳統的Attention機制Soft Attention來接收LSTM層的輸出作為輸入,根據不同特征向量的重要程度不同,對其賦予權重,最后經過softmax歸一化處理得到加權的向量表示,至此上游任務完成。 XLNet-LSTM-Att模型以keras架構實現,通過Anaconda平臺采用Python語言進行仿真驗證。采用譚松波采集的酒店評論語料ChnSentiCorp-6000進行仿真實驗,該語料是一個正負類各3 000篇的平衡語料,實驗將數據集劃分訓練集和測試集規模如表1所示,取數據集前5 000條數據作為訓練集,其余為測試集。語料示例如表2所示,其中標簽0為負面評價,標簽1為正面評價。 表1 數據集基本信息 表2 語料示例 仿真實驗將XLNet+LSTM+ATT模型與TextCnn、LSTM、BiLSTM、BERT、XLNet 5種常見的情感分析模型作對比試驗,其中各模型參數設置如表3所示。 表3 模型參數設置情況 仿真實驗效果由精準率P、召回率R、F1值和AUC 4個評價指標來評判,AUC即接受者操作特性曲線(receiver operating characteristic curve, ROC)下對應的面積,通過預測概率計算,AUC值越大則分類器效果越好。精準率、召回率、F1值計算公式為 (15) (16) (17) 式中:TP為把正類評價判斷為正類評價的數量;FP為把負類評價錯判為正類評價的數量;FN為把正類評價錯判為負類評價的數量。 圖8為XLNet-LSTM-Att模型與5種其他模型進行比較的結果,分別從精準率P、召回率R和F1值評價模型優劣。 圖8 6種模型測試結果 在對比實驗中,提出的XLNet-LSTM-Att優化模型其精準率、召回率、F1值均優于其他模型,其中,模型與BERT模型比較,精準率提高0.48%,與XLNet模型比較,精準率提高1.34%。 表4給出的是不同預訓練模型的AUC值,目前常應用于情感分析的模型在AUC值上均取得不錯水平,且由于BERT和XLNet能真正識別上下文語義,其AUC值比以往模型更高,其中,提出的XLNet-LSTM-Att模型AUC值略微提高,也表明了所提出模型具有良好的性能和泛化能力。 表4 6種模型AUC值 情感分析愈來愈成為政府和企業輿論把控的手段,通過對現有的預訓練手段進行分析,基于XLNet預訓練模型能提取上下文語義優勢,提出在該模型上增加LSTM層和Attention機制的優化模型XLNet-LSTM-Att,該模型首先利用XLNet獲取包含上下文語義的特征向量,再利用LSTM網絡層進一步提取上下文相關特征,最后引入Attention機制對提取出的特征分配權重,對文本進行情感傾向性分析,經過對比實驗仿真,提出的模型在精確率等評價指標均有一定程度的提升。下一步工作中,對情感細粒度劃分是今后的研究重點。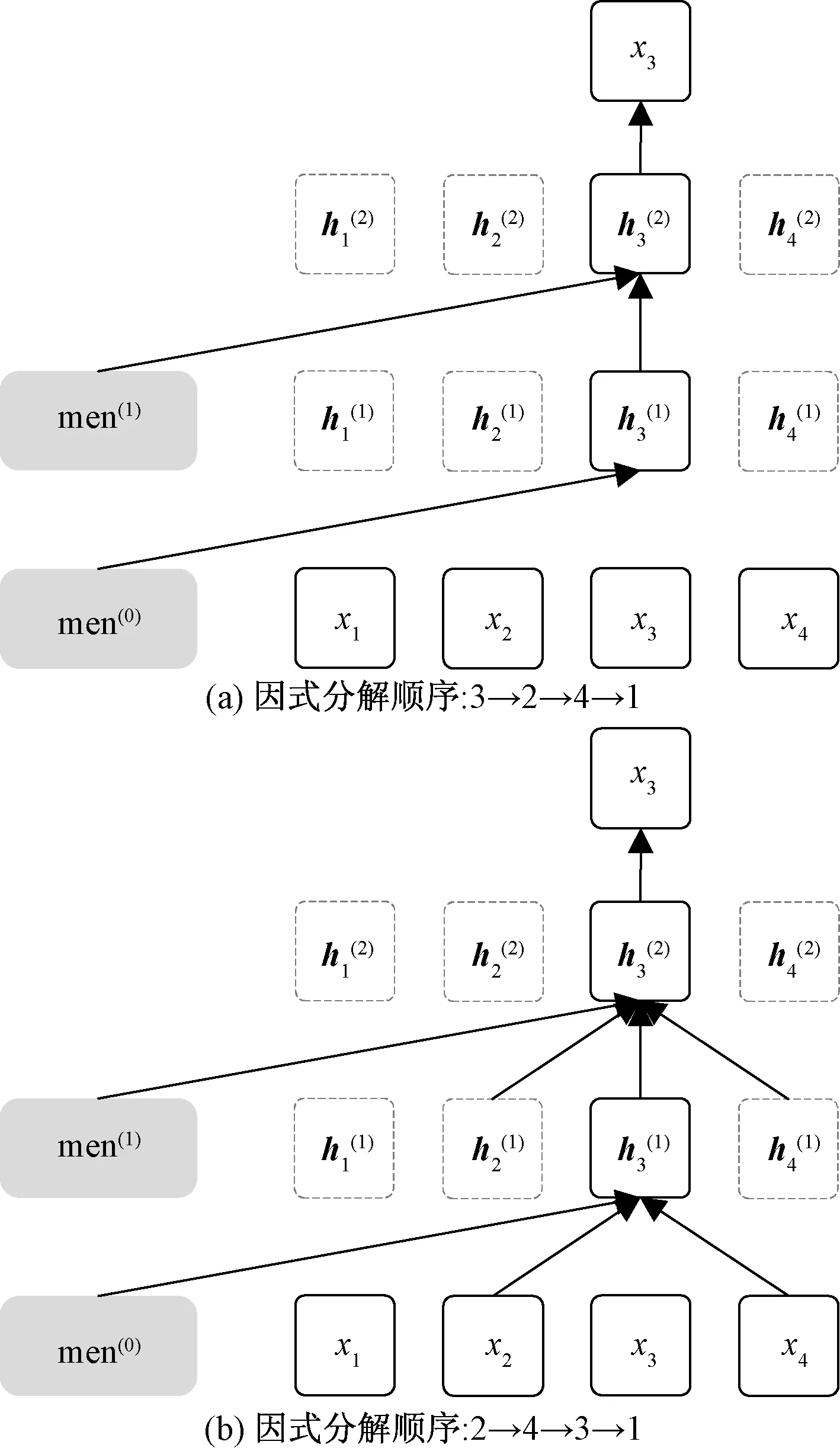

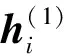
1.2 LSTM層
1.3 Attention層
2 仿真實驗分析
2.1 數據集信息


2.2 相關參數設置
2.3 評價指標
2.4 結果分析

3 結論
猜你喜歡
中國生殖健康(2020年5期)2021-01-18 02:59:48開放教育研究(2020年2期)2020-03-31 01:54:14北極光(2019年12期)2020-01-18 06:22:10小太陽畫報(2019年10期)2019-11-04 02:57:59文苑(2018年21期)2018-11-09 01:23:06中國生殖健康(2018年5期)2018-11-06 07:15:40現代語文(2016年21期)2016-05-25 13:13:44中國衛生(2015年9期)2015-11-10 03:11:12大連民族大學學報(2015年2期)2015-02-27 08:28:11中國衛生(2014年3期)2014-11-12 13:18:12
