一種視覺SLAM單目半稠密建圖方法的實現
2021-07-11 19:13:02尚任
智能計算機與應用 2021年1期
尚任
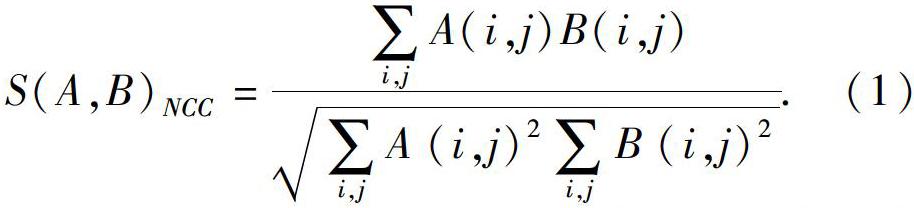

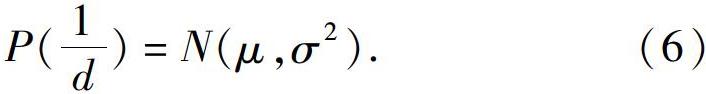
摘?要:SLAM即同時定位與地圖構建,一直是機器人和計算機視覺的研究熱點。尤其是視覺SLAM技術,21世紀以來在理論和實踐上均取得了明顯的突破,已逐步邁向市場應用。建圖作為SLAM的兩大目標之一,可以滿足更多的應用需求。本文在給定相機軌跡的情況下,提出一種視覺SLAM單目半稠密建圖方法,利用極線搜索和塊匹配技術,加入圖像變換和逆深度高斯深度濾波器處理,以期避免單目稠密建圖嚴重依賴紋理、計算量大的缺點,提高單目半稠密建圖的準確性和魯棒性。經測試顯示,改進的單目半稠密建圖方法在檢測梯度變化明顯像素點上更加準確,深度估計的平均誤差和平方誤差分別減少了9%和47%,是一種可行有效的視覺SLAM單目半稠密建圖解決方案。
關鍵詞: 視覺SLAM;建圖;單目;極限搜索;塊匹配;逆深度
文章編號: 2095-2163(2021)01-0089-05 中圖分類號:TP391 文獻標志碼:A
【Abstract】Simultaneous Localization and Mapping(SLAM) is the hot spot of Robots and Computer Vision. Visual SLAM had made a breakthrough since 21st century and applied to the market. Mapping is one of the targets of SLAM. Given location and poses of the monocular camera, the paper proposes a Visual SLAM semi-dense mapping method. Using searching on the epipolar line and block-matching, image transformation and inverse depth filter have been used in order to avoid depending on textures and large amounts of calculation. In this way, the accuracy and robustness of semi-dense mapping has been improved. From the testing result, the improved visual SLAM semi-dense mapping method on monocular camera has a better performance on gradient detecting of pixels. The average error and square error on depth estimation decrease about 9% and 47%. It is a feasible and effective solution to rebuild semi-dense mapping on monocular camera.
【Key words】visual SLAM; mapping; monocular; extreme search; block match; inverse depth
0 引?言
同時定位與地圖構建(Simultaneous Localization and Mapping,SLAM),于1986年提出[1],是指搭載特定傳感器的主體,在沒有環境先驗知識的情況下,在運動中估計自身軌跡,并同時建立環境的模型[2]。在視覺SLAM中,特定傳感器以視覺傳感器(即相機)為主體,研究者則需要根據連續拍攝的多幅圖像,推斷相機的運動以及周圍的環境。
定位與建圖是SLAM的兩大目標。在視覺SLAM中,建圖與定位同樣重要,建圖還具有很多其他的應用需求。對于單目相機的地圖構建,國內外已涌現了不少的研究成果,提供了很多優秀的開源SLAM方案。PTAM[3]的問世是視覺SLAM發展過程中的重要事件,首次提出并實現了跟蹤與建圖過程的并行化。ORB-SLAM[4]是繼PTAM之后業內著名的視覺SLAM系統,代表著主流特征點SLAM的一個高峰。ORB-SLAM能夠支持單目、雙目、RGB-D三種模式,有著良好的泛用性,但只能用于構建稀疏地圖,在建圖方面顯得過于重量級。LSD-SLAM[5-6]標志著單目直接法在SLAM中的成功應用,其核心貢獻是將直接法應用到了半稠密單目地圖重建中。還有很多單目SLAM開源系統(如SVO[7]、DSO[8]等等)。此外,羅鴻城[9]、謝瑒[10]、張劍華等人[11]、Vogiztzis等人[12]均對單目建圖進行了探索。
本文旨在提出一種單目半稠密建圖的方法,研究中在圖像間仿射變換預處理后,利用塊匹配的方法進行極線搜索[13],并將像素點的逆深度進行高斯融合,采用高斯分布的逆深度濾波器的方式估計像素點的深度,具有良好的準確性和魯棒性。
1 SLAM系統介紹
研究時通常使用便攜式的傳感器來完成SLAM,在未知環境中進行實時建模[14]。視覺SLAM主要是指如何用相機解決定位和建圖問題。按照工作方式的不同,相機可以分為單目(Monocular)、雙目(Stereo)和深度(RGB-D)三大類。此外,視覺SLAM中還可使用全景相機[15]、Event相機[16]等不同種類,但迄至目前還未成為主流,僅會將其應用在部分場景中。
在典型的視覺SLAM框架中,主要分為前端視覺里程計(Visual Odometry)、后端優化(Optimization)、回環檢測(Loop Closure Detection)和建圖(Mapping)四個模塊。對此擬做闡釋分述如下。
(1)視覺里程計。根據相鄰圖像的信息估計出粗略的相機運動以及局部地圖,處理的結果將作為后端優化的初始值。視覺里程計的算法主要分為兩大類:特征點法和直接法。基于特征點法的前端,直到現在也被公認為視覺里程計的主流方法。其中,特征點法穩定性強,對光照和動態物體不敏感,是目前比較成熟的解決方案。但特征點法中,關鍵點的提取與描述子的計算非常耗時,忽略了除特征點以外的所有信息,而且在特征缺失區域效果并不理想。直接法根據像素的亮度信息估計相機的運動,克服了特征點法的不足,但由于灰度不變假設,對光照、環境等外界條件敏感,穩定性相對較差。
(2)后端優化。負責優化整個問題,將視覺里程計估計的相機位姿以及回環檢測的信息進行優化,返回優化后的結果,得到全局一致的軌跡和地圖。后端優化部分主要有2種處理方法:批量(Batch)處理的非線性優化方法和漸進(Incremental)處理的濾波器方法。目前,視覺SLAM的主流是非線性優化方法。以非線性優化為主的后端考慮當前狀態與之前所有狀態的關系,在同等計算量的情況下,能夠取得更好的精度和魯棒性[17],但往往計算量過大,不適用于計算能力有限的平臺。以擴展卡爾曼濾波為代表的濾波器方法,僅關注當前時刻和前一時刻的情況,雖然精度和魯棒性上不如非線性優化,但是在計算資源受限,或待估計量較簡單的場合,濾波器方法仍不失為一種有效的方式。
(3)回環檢測。判斷傳感器是否經過先前位置,將檢測到的回環信息提供給后端進行處理。目前,回環檢測用得最多的方法是基于外觀的方法,即僅根據2幅圖像的相似性確定回環檢測關系。較為經典的是詞袋模型,該模型是一個非監督學習的過程。但是深度學習方法由于在學習與無監督聚類上的優異表現,其在性能方面則有望勝過目前的主流方法。
(4)建圖模塊。根據估計的軌跡,建立與需求對應的地圖。建圖是SLAM的兩大目標之一。根據使用像素的數量,構建的地圖分為3種:稀疏地圖、稠密地圖和半稠密地圖。總地來說,稀疏地圖只建模感興趣的部分,稠密地圖將建模所有看到過的部分,半稠密地圖所建模的像素數量介于稀疏地圖和稠密地圖之間。地圖的用途可以歸納為5點[14],分別是:定位、導航、避障、重建和交互。其中,定位需要用到稀疏地圖,而導航、避障、重建則要用到稠密地圖。
2 半稠密直接法
對于單目建圖,特征點法和直接法均可以重建稀疏地圖,而半稠密地圖和稠密地圖由于沒有描述子,只能采用直接法重建。構建稀疏地圖只能滿足定位需求,應用有限,構建稠密地圖雖然可以滿足地圖導航、避障和重建的應用需求,但對物體紋理有強烈的依賴性。故本文采用單目半稠密建圖的折中方式。建圖需要估計或者獲取空間點的位置和深度。根據空間點深度的來源,可以把直接法分成3類:
(1)稀疏直接法,即空間點來自于稀疏關鍵點,不必計算描述子,速度最快,但只能計算稀疏的重構。
(2)半稠密直接法,即空間點來自部分像素,考慮到像素梯度為零的像素點對計算運動增量沒有任何貢獻,只使用帶有梯度的像素點,能夠重構一個半稠密結構。
(3)稠密直接法,即空間點來自于所有像素,需要計算所有像素,多數不能在現有CPU上實時計算,需要GPU加速。而且由于使用了梯度不明顯的像素點,重構稠密地圖的效果難以保證[14]。
本文采用半稠密直接法作為單目半稠密重建的重要環節,既保證了單目相機建圖實時性的要求,又保證了建圖結果的準確性。
3 圖像匹配
本文沿用了直接法的思想,利用極限搜索和塊匹配技術確定一幅圖像中某像素出現在其他圖像里的位置。當能夠確定某個像素在各個圖像中的位置,就可以像特征點法那樣,利用三角測量法確定對應的深度。研究內容詳見如下。
3.1 對極幾何與極線搜索
單目SLAM僅已知二維像素坐標。對于稀疏地圖的構建,可以利用特征匹配得到若干對配對好的匹配點,從而通過這些二維像素點的對應關系,恢復出在兩幀之間相機的運動。該問題可用對極幾何解決。
而對于半稠密地圖和稠密地圖的構建,需要對每個或大部分像素點做匹配,這種情況下,沒有描述子的存在,第一幅圖像上的像素點只能在極線上搜索,以找到其在第二幅圖像上比較相似的點。即沿著第二幅圖像中的極線,逐個比較每個像素與第一幅圖像像素點的相似程度。這種通過比較像素亮度來確定圖像間匹配,從而估計相機運動的做法,與視覺里程計中的直接法思想相同。
3.2 塊匹配
為避免直接法中單個像素沒有區分度且灰度值不變假設過強的弊端,一種有效的方法是以圖像塊為計算單位,而不是單個像素點。研究時,可在第一幅圖像待匹配像素點p1周圍取一個大小為n×n的小塊,假設在不同圖像間整個小塊灰度值不變,比較相同大小像素塊的亮度相對于比較單個像素的亮度要穩定可靠得多。對于單目相機的半稠密地圖和稠密地圖的構建,可在極線上取很多大小相等的像素塊進行比較,使極線搜索的結果有更好的準確性和魯棒性。
計算像素塊之間差異的方法有若干種,其中將每個像素塊均值去掉的處理方法更為可靠。常見的計算方法有SAD、SSD、NCC等[18],去均值后,稱為去均值的SAD、去均值的SSD、去均值的NCC等等。研究中,不妨將p1周圍的去均值像素塊記為Ai,i=1,…,n,把極線上的n個去均值像素塊記為Bi,i=1,…,n。去均值的NCC(即去均值的歸一化互相關)計算公式為:
本文采用去均值的NCC來計算極線上像素塊的相似性度量,在極限搜索中將得到一個沿著極線的NCC分布。由于圖像的非凸性質,在搜索距離較長的情況下,NCC分布通常會得到一個非凸函數,即這個分布存在很多峰值[12]。這種情況下,可使用概率分布來描述像素塊的深度值,而不是用某個單一數值來描述深度。
3.3 圖像變換
在塊匹配中,研究假設像素塊在相機運動時保持不變。這個假設在相機平移時能夠保持成立,但在相機發生明顯旋轉時就有可能不成立。特別地,當相機繞著光心旋轉較大角度,會出現相關性直接變成負數的情況,即使都是同一個像素塊。在這種情況下,在塊匹配前,做一次圖像變換,把2幀圖像間的運動考慮進來,是一種常見有效的預處理方式。
仿射變換的矩陣形式如下:
現以第一幅圖像為參考幀,推導參考幀與當前幀之間的仿射變換。根據相機模型,第一幀圖像上的一個像素PR與真實的三維點世界坐標PW有以下關系:
其中,dR表示像素PR距離相機成像平面的深度。
類似地,對于當前幀,PC為真實三維點世界坐標PW的投影為:
2幀圖像之間的像素關系為:
當PR與dR已知時,可以計算出PC的投影位置。再給PR的2個分量各加一個增量du、dv,就可以求得PC的增量duc、dvc。這樣就可以算出局部范圍內參考幀和當前幀一個線性的坐標變換,構成仿射變換。經過仿射變換后的塊匹配,以期得到對旋轉更好的魯棒性。
4 深度估計
4.1 三角測量
研究已通過極線搜索和仿射變換后的塊匹配技術得到了半稠密或稠密深度估計中某個像素在各個圖中的位置,這樣就可以利用三角測量(Triangulation)方法確定其深度。三角測量最早由高斯提出,是指通過不同位置對同一路標點進行觀察,從觀察到的位置推斷路標點的距離。在視覺SLAM中,主要用三角化來估計像素點的距離(即深度)。由于噪聲的存在,通常求得深度的最小二乘解。
4.2 高斯分布的逆深度濾波器
對像素點的深度估計,有濾波器方法或非線性優化兩種求解思路。由于前端已經占用一定的計算量,建圖方面通常采用計算量相對較少的濾波器方法。
對深度的分布假設有若干種方法,可假設深度值服從高斯分布,也可假設深度值服從均勻-高斯混合分布[7,12]。
但是深度的高斯分布并不準確,因為近處的點不會小于相機焦距,而且在一些室外場景中,會存在距離很遠的點,這個分布并不和高斯分布一樣是對稱形狀。在仿真中,研究發現假設深度的倒數(即逆深度)為高斯分布是比較有效的。逆深度在實際應用中也具有更好的數值穩定性,從而成為一種通用的技巧。本文采用的就是高斯分布的逆深度濾波器方法。這里,假設某個像素點的逆深度1d服從高斯分布,對應數學公式可寫為:
新觀測的信息更新原來像素點的深度分布,融合后的逆深度分布仍然是高斯分布。采用逆深度的方差更新方式描述深度的不確定性。在實際工程中,當深度不確定性小于一定閾值時,即可認為深度數據已收斂。
5 建圖
本次研究主要著重于改進單目半稠密建圖的方法,故選用給定相機軌跡的數據進行討論,根據一段視頻系列估計某幅圖像的深度。研究時選用了REMODE[13,19]數據集和EuRoC數據集。
5.1 數據集介紹
REMODE數據集提供了一架無人機采集的單目俯視圖像,共200張,同時提供了每張圖像的真實位姿。EuRoC數據集是雙目和IMU數據集,包含2個場景:蘇黎世聯邦理工學院的一個廠房和一個普通房間。本文僅用雙目中的一個相機的廠房場景數據和對應的圖像真實位姿數據,共200張。
5.2 建圖測試結果分析
建圖測試結果驗證分為對照組和改進組。其中,對照組采用未優化的單目半稠密建圖方法(極限搜索+塊匹配+高斯分布的深度濾波器),改進組采用改進的單目半稠密建圖方法(極限搜索+圖像變換+塊匹配+高斯分布的逆深度濾波器)。
對照組方法和改進組方法在REMODE和EuRoC數據集中表現如圖1所示, 數據集測試結果分析見表1。
可以看出,改進的方法有更好的準確性和魯棒性。具體來說,在檢測梯度變化明顯的像素點上,對于相對簡單的REMODE數據集室內普通房間場景,對照組和改進組兩種方法效果大致相同,深度的平均誤差和平方誤差相差無幾,但在EuRoC數據集復雜工廠室內場景中,改進的方法顯然要更加準確,深度圖效果更為突出,平均誤差減少了9%,平方誤差減少了47%。在用時上,由于改進的半稠密建圖方法對圖像中每個像素做了仿射變換,使改進組方法用時多于對照組方法。
6 結束語
在視覺SLAM中,相比于RGB-D建圖,單目建圖的計算量大,結果也并不可靠。但是單目視覺SLAM的應用能夠適用于復雜室外環境,而且性價比高,是頗具學術價值的研究方向。在今后的研究工作中,將致力于提出完整的單目SLAM系統,以期得到更加準確有效的定位及建圖解決方案。
參考文獻
[1]BARFOOT T. State estimation for robotics-A matrix lie group approach[M]. Cambridge: Cambridge University Press, 2016.
[2]DAVISON A J, REID I D, MOLTON N D, et al. MonoSLAM: Real-time single camera SLAM[J]. IEEE transactions on pattern analysis and machine intelligence, 2007, 29(6):1052-1067.
[3]KLEIN G, MURRAY D. Parallel tracking and mapping for small AR workspaces[C]// ISMAR 2007 6th IEEE and ACM International Symposium on mixed and Augmented Reality. Nara, Japan:IEEE, 2007: 225-234.
[4]MUR-ARTAL R, MONTIEL J, TARDOS J D. Orb-slam: A versatile and accurate monocular slam system[J]. arXiv preprint arXiv: 1502.00956, 2015.
[5]ENGEL J, SCHOEPS T, CREMERS D. Lsd-slam: Large-scale direct monocular SLAM[M]//FLEET D, PAJDLA T, SCHIELE B, et al. Computer Vision-ECCV 2014. Lecture Notes in Computer Science. Cham:Springer, 2014:834-849.
[6]ENGEL J, STURM J, CREMERS D. Semi-dense visual odometry for a monocular camera[C]//Proceedings of the IEEE International Conference on Computer Vision. Washington, DC, USA:IEEE, 2013:1449-1456.
[7]FORSTER C, PIZZOLI M, SCARAMUZZA D. Svo: Fast semi-direct monocular visual odometry[C]//2014 IEEE International Conference on Robotics and Automation(ICRA). Hong Kong:IEEE, 2014:15-22.
[8]ENGEL J, KOLTUN V, CREMERS D. Direct sparse odometry[J]. arXiv preprint arXiv: 1607. 02565, 2016.
[9]羅鴻城. 基于卷積神經網絡的實時單目稠密建圖方法研究[D]. 武漢:華中科技大學,2019.
[10]謝瑒. 無人機自主導航的單目視覺SLAM技術研究[D]. 南京:南京航空航天大學,2019.
[11]張劍華,王燕燕,王曾媛,等. 單目同時定位與建圖中的地圖恢復融合技術[J].中國圖象圖形學報,2018,23(3):372-383.
[12]VOGIZTZIS G, HERNNDEZ C. Video-based, real-time multi-view stereo[J]. Image and Vision Computing, 2011, 29(7): 434-441.
[13]PIZZOIL M, FORSTER C, SCARAMUZZA D. Remode: Probabilistic, monocular dense reconstruction in real time[C]//2014 IEEE International Conference on Robotics and Automation(ICRA). Hong Kong:IEEE, 2014:2609-2616.
[14]高翔, 張濤, 劉毅,等. 視覺SLAM十四講, 從理論到實踐[M]. 2版. 北京:電子工業出版社, 2019.
[15]PRETTO A, MENEGATTI E, PAGELLO E. Omnidirectional dense large-scale mapping and navigation based on meaningful triangulation[C]//2011 IEEE International Conference on Robotics and Automation(ICRA 2011). Shanghai, China:IEEE,2011: 3289-3296.
[16]RUECKAUER B, DELBRUCK T. Evaluation of event-based algorithms for optical flow with ground-truth from inertial measurement sensor[J]. Frotiers in neuroscience, 2016,10(137):1-17.
[17]STRASDAT H, MONTIEL J M, DAVISON A J. Visual slam: Why filter?[J]. Image and Vision Computing, 2012,30(2):65-77.
[18]HIRSCHMULLER H, SCHARSTEIN D. Evaluation of cost functions for stereo matching[C]//2007 IEEE Conference on Computer Vision and Pattern Recognition. Minneapolis:IEEE, 2007:1-8.
[19]HANDA A, NEWCOMBE R A, ANGELI A, et al. Real-time camera tracking: When is high frame-rate best?[M]//FITZGIBBON A, LAZEBNIK S, PERONA P, et al. Computer Vision-ECCV 2012. Lecture Notes in Computer Science. Berlin/Heidelberg:Springer, 2012:222-235.
