基于貝葉斯模型平均法構(gòu)建杉木林分蓄積量生長模型
2021-07-11 03:33:38魯樂樂張雄清張建國段愛國
林業(yè)科學(xué)研究 2021年3期
關(guān)鍵詞:模型
王 震,魯樂樂,張雄清*,張建國,姜 麗,段愛國
(1. 中國林業(yè)科學(xué)研究院林業(yè)研究所,國家林業(yè)和草原局林木培育重點實驗室,北京 100091;2. 南京林業(yè)大學(xué)南方現(xiàn)代林業(yè)協(xié)同創(chuàng)新中心,江蘇 南京 210037)
林分蓄積量是反映森林資源質(zhì)量與森林經(jīng)營水平的重要依據(jù),也是反映森林生產(chǎn)力的一個重要指標[1]。分析林分蓄積量與林分變量、氣候因子的關(guān)系,對于評價森林生產(chǎn)力有重要的參考價值。氣候變化對林分蓄積量影響的研究已經(jīng)做了不少。如:Di Filippo等[2]發(fā)現(xiàn)夏季以及前一年夏秋的干旱指數(shù)導(dǎo)致土耳其櫟(Quercus cerrisL.)的蓄積生長量減少。Patrick等[3]利用森林資源連續(xù)清查中的無梗花櫟(Quercus petraeaLibelb)和樟子松(Pinus sylvestrisvar.mongolicaLitv.)樣地數(shù)據(jù),探討了環(huán)境氣候、林分直徑和林分密度對林分生長的影響,研究發(fā)現(xiàn)12月至次年7月的降水對每年的林分生長十分重要。林分變量因子,包括林分密度、立地條件、林齡、林分結(jié)構(gòu)等,也能對森林生長變化產(chǎn)生一定的影響。汪瑋和孟偉[4]以湖南省杉木(Cunninghamia lanceolata(Lamb.) Hook.)人工林為研究對象,基于7類立地因子數(shù)據(jù),建立了湖南省杉木人工林林分蓄積量估測模型,提高了模型精度。氣候因子和林分變量因子均對森林生長變化產(chǎn)生影響。而不同的影響因子對森林生長的影響又不同[5-7]。Toledo等[8]認為氣候因子是玻利維亞熱帶森林生長的主要驅(qū)動因子,其次是土壤和人為的經(jīng)營干擾。Zhang等[9]利用加拿大西部地區(qū)半個世紀的森林調(diào)查資料分析森林生長變化的驅(qū)動因子,得到結(jié)果為林木競爭因子是該地區(qū)森林生長變化的主要驅(qū)動因子,其次是氣候因子。之后,Pricea等[10]對該結(jié)論提出了疑問,并認為氣候變化才是加拿大西部地區(qū)森林生長變化的主要驅(qū)動因子。何理深和張超[11]采用因子分析法對13個影響因子進行組合(其中包括林分因子、溫度因子、水分因子、密度因子與光照因子),構(gòu)建了云南松(Pinus yunnanensisFranch.)林分蓄積量回歸模型,發(fā)現(xiàn)蓄積量隨林分因子的變動最為顯著,且對溫度因子和光照因子不敏感。
對于諸多的影響因子,選擇合適的變量并分析其對林分蓄積量變化的影響很有必要。目前,用的比較多的方法是逐步回歸(SR)。逐步回歸根據(jù)變量的統(tǒng)計顯著與否最終確定該變量是否保留在模型中。而在用該方法分析時,僅根據(jù)P值選擇,存在一定的局限性,有可能還會選出冗余的變量[12]。此外,在建立模型時,一般是人為指定包含某些變量的某個模型為最優(yōu)模型。而實際上事先并不知道包含哪些變量的模型為最優(yōu)模型,即模型本身的不確定性[13-14]。當建立回歸模型時,模型本身的不確定性可能很大,若忽略模型本身的不確定性而僅以單一特定模型的結(jié)果進行推斷,一方面會低估模型的不確定性,導(dǎo)致模型的適用范圍變窄,另一方面會更趨向于拒絕無效假設(shè)產(chǎn)生誤導(dǎo)性判斷[15-16]。
貝葉斯模型平均法(Bayesian model averaging,BMA)是變量選擇和構(gòu)建不確定性模型的另一種方法[17]。與傳統(tǒng)方法不同,它并非僅得出一個“最佳”模型,而是考慮模型空間內(nèi)所有可能變量的組合模型,用各模型的后驗概率加權(quán)平均得到一個模型,然后根據(jù)各自變量估計值的后驗概率分析該自變量的重要性[18-19]。近些年,BMA方法在林業(yè)上也有應(yīng)用,如:直徑分布模型[20]、生物量模型[17]、林分斷面積模型[21-22]和枯損率模型[23]。但是,總體上對BMA模型的研究還不夠。本研究以福建邵武28年的杉木人工林密度試驗林為研究對象,分別利用貝葉斯模型平均法和逐步回歸法分析杉木林分蓄積量與林分變量、氣候因子之間的關(guān)系,比較不同影響因子的重要性,構(gòu)建杉木林分蓄積量生長模型。
1 研究區(qū)概況與數(shù)據(jù)整理
1.1 研究區(qū)概況
研究區(qū)位于福建省邵武市衛(wèi)閩林場,地處武夷山北段中山山脈東南側(cè)山區(qū),為杉木的中心產(chǎn)區(qū)。地貌主要為低山、高丘,海拔250~700 m,坡度25°~35°。氣候?qū)賮啛釒Ъ撅L(fēng)氣候,年平均氣溫17.7℃,極端低溫-7.9℃,全年日照時數(shù)1 740.7 h。年降水量1 768 mm,年平均相對濕度82%。土壤以發(fā)育在花崗巖等母質(zhì)上的紅壤為主,土層比較厚,腐殖質(zhì)含量豐富。林下灌木有木荷(Schima superbaGardn.et Champ.)、中華杜英(Elaeocarpus chinensis(Gardn. et Chanp.) Hook. f. ex Benth.)、絲栗栲(Castanopsis fargesiiFranch.)和胡頹子(Elaeagnus pungensThunb.)等,林下草本植物有狗脊(Woodwardia japonica(L. F.) Sm.)、芒萁(Dicranopteris dichotoma(Thunb.) Berhn.)、中華里白(Hicriopteris chinensis(Ros.) Ching)、半邊旗(Pteris semipinnataL.Sp.)、華南毛蕨(Cyclosorus parasiticus(L.) Farwell.)等。
1.2 數(shù)據(jù)整理
本研究數(shù)據(jù)來源于15塊杉木密度實驗林固定樣地,樣地大小為20 m × 30 m。1980年使用裸根苗造林,采用隨機區(qū)組造林試驗,設(shè)置5種造林密度,包括A:2 m × 3 m,B:2 m × 1.5 m,C:2 m ×1 m,D:1 m × 1.5 m,E:1 m × 1 m,每種密度重復(fù)3次。5種密度由小到大依次選取測量的株數(shù)為100株,200株,300株,400株,600株,并對其進行標號和每木檢尺,測量胸徑和樹高。造林后1984—1990年每年測量1次,1992—2010年每2年測量1次,每次調(diào)查均在當年樹木生長停止后的冬季或下一年開始生長前進行。其中1986年測量樣地內(nèi)所有樹的樹高,之后開始每個樣地隨機抽取50株并測量樹高。在測量樹高的時候采用5點取樣法在每個樣地的上、下部各取2株,中部取1株,共5株最高木作為林分優(yōu)勢木,以求林分優(yōu)勢木平均高。利用部頒杉木一元材積表經(jīng)驗公式計算出杉木單木材積:
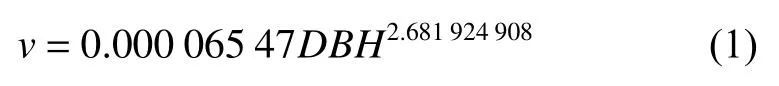
分別將樣地中單木材積相加,得到樣地林分蓄積量M(m3·hm-2)。樣地林分因子統(tǒng)計量見表1。
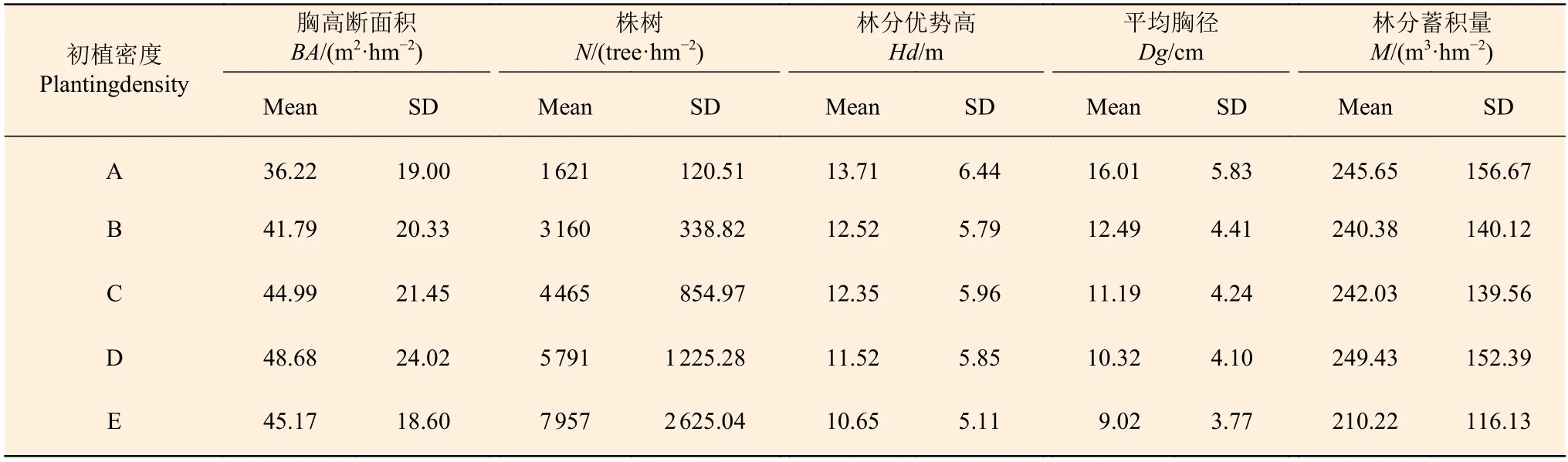
表1 樣地林分因子統(tǒng)計值Table 1 Summary statistics of stand variables of Chinese fir plantations
本研究所利用的氣候數(shù)據(jù)由ClimateAP軟件獲得[24]。該軟件通過研究區(qū)的經(jīng)緯度和海拔信息插值計算得到氣候變量因子。氣候變量包括年均氣溫(MAT),年均降水量(AP),最冷月的平均溫度(MCMT),年均濕熱指數(shù)(AHM),低于0℃天數(shù)(DD0),夏季平均最高溫度(SMMT),冬季平均最低溫度(WMMT),最熱月的平均溫度(MWMT)和春季平均氣溫(SMT)。1984—2010年的氣候因子統(tǒng)計見表2。
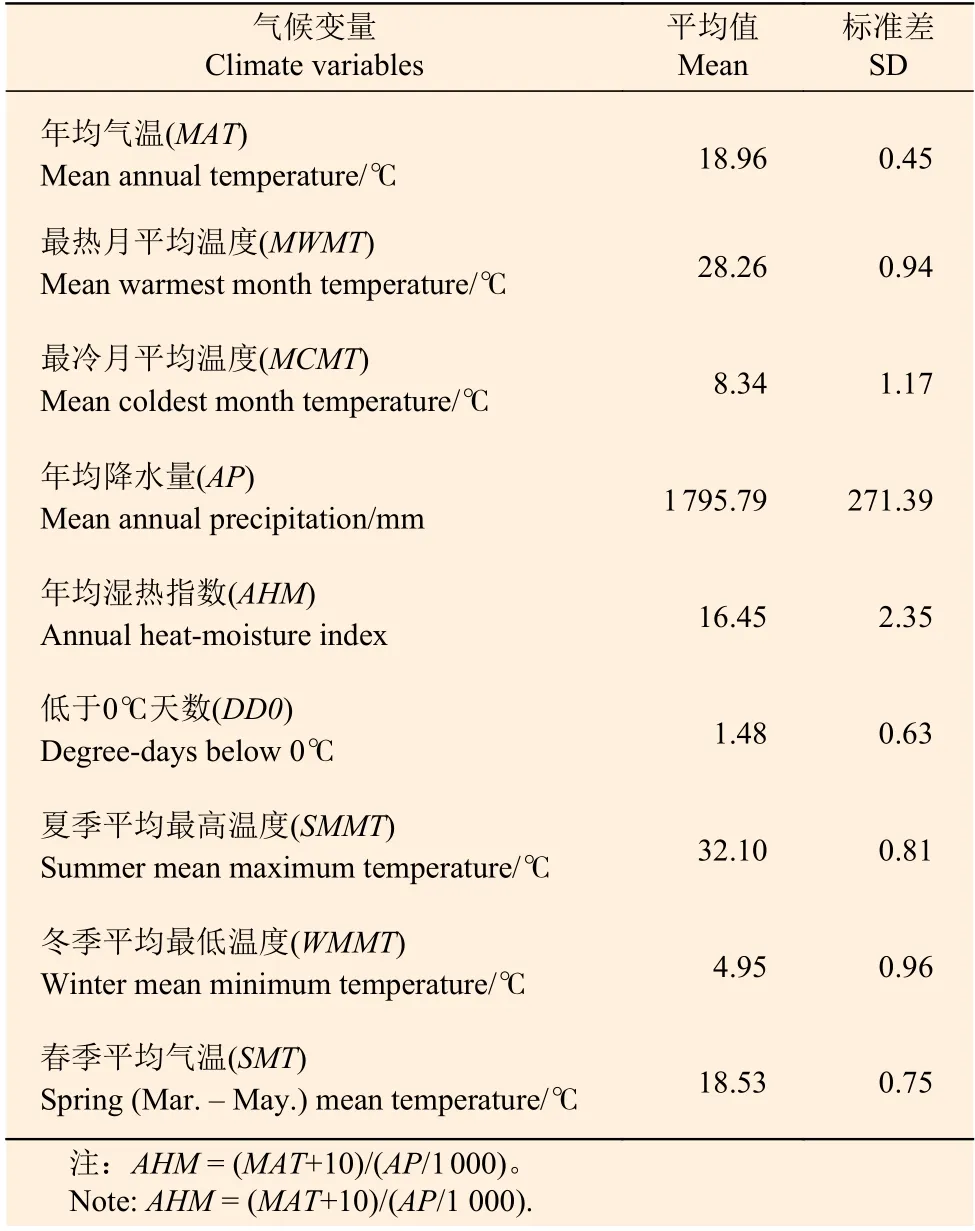
表2 氣候因子統(tǒng)計值Table 2 Summary statistics of climate variables
2 研究方法
用于建模的自變量包括林分變量因子和氣候因子。林分變量因子包括造林密度(PD)、林齡(A)、每公頃胸高斷面積(BA)、每公頃株樹(N),優(yōu)勢木平均高(Hd),林分平方平均胸徑(Dg);氣候因子包括MAT,AP,MCMT,AHM,DD0,SMMT,WMMT,MWMT,SMT。
2.1 林分蓄積量模型
本研究構(gòu)建林分蓄積量模型采用的多元回歸模型形式如下:
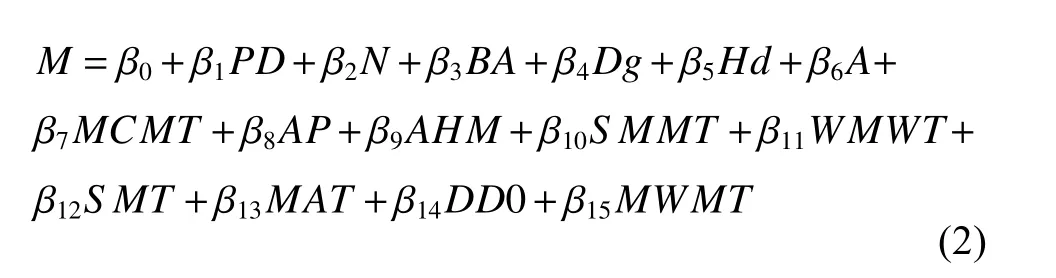
式中:M為林分蓄積量,β0—β15為模型參數(shù)。
2.2 BMA原理
假設(shè)y是研究的林分蓄積量,Z是調(diào)查所得的數(shù)據(jù)(包括氣候因子和林分變量因子),f={f1,···,fk}(k=1,···,n)代表所有可能的模型組成的模型空間。則y的后驗分布為:
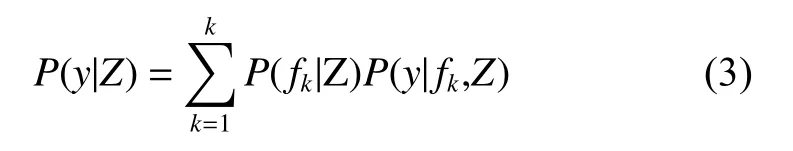
式中:P(y|fk,Z)是在給定調(diào)查數(shù)據(jù)Z和模型fk的條件下y的后驗分布,P(fk|Z)是在給定數(shù)據(jù)Z的情況下fk為最優(yōu)模型的概率。從方程(3)可知,y的后驗分布實際上是以后驗概率P(fk|Z)為權(quán)重,對所有模型的后驗分布進行加權(quán)的一個平均值。貝葉斯平均模型法涉及了模型空間中所有模型的計算。模型空間中所有模型的數(shù)量很大,若自變量個數(shù)為6個,那么即使在不考慮交互作用的情況下模型數(shù)量可達64個。從貝葉斯的觀點看BMA的假設(shè)檢驗,其對應(yīng)的備擇假設(shè)H1為:Xk為杉木林分蓄積量變化的影響因子的后驗概率有多大,即βk不等于0的后驗概率有多大?BMA法以所有包含變量Xk的杉木林分蓄積量模型的后驗概率的和作為βk不等于0的后驗概率的估計:
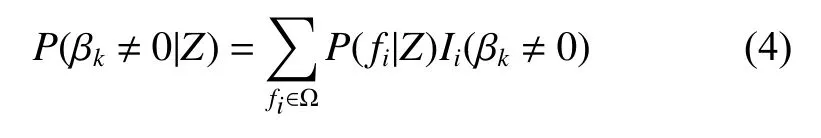
其中Ii為0/1指示變量,當βk在模型fi中,Ii=1,反之為0。Ω為模型空間。一般認為P(βk≠0|Z) <0.5表示沒有證據(jù)表明Xk是杉木林分蓄積量變化的影響因子;0.5 ≤P(βk≠0|Z) < 0.75表示有弱的證據(jù)表明Xk是杉木林分蓄積量變化的影響因子;0.75 ≤P(βk≠0|Z) < 0.95表示有強的證據(jù)表明Xk是杉木林分蓄積量變化的影響因子;P(βk≠0|Z) ≥0.95表示有很強的證據(jù)表明Xk是杉木林分蓄積量變化的影響因子[25]。若Xk是杉木林分蓄積量變化的影響因子,則變量因子Xk的點估計的后驗均值為:
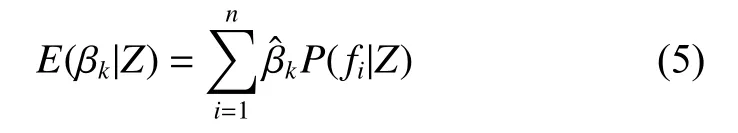
2.3 模型評價
本研究采用R2和平均相對誤差(MD)作為模型預(yù)測的評價指標。一般來說,R2越大,MD絕對值越小,模型表現(xiàn)更好。
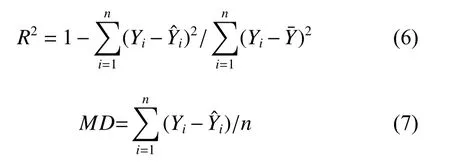
本研究隨機抽取總數(shù)據(jù)的60%作為模擬數(shù)據(jù),剩余40%作為預(yù)測數(shù)據(jù)。分別利用BMA與逐步回歸法構(gòu)建林分蓄積量模型。BMA通過貝葉斯自適應(yīng)抽樣包(BAS)實現(xiàn)[26],逐步回歸通過step函數(shù)實現(xiàn)。所有的計算均在R軟件中完成。在貝葉斯模型方法計算中,利用Zellner-Siow柯西先驗分布[27]作為參數(shù)的先驗分布。
3 結(jié)果與分析
3.1 兩種方法確定的最佳模型的比較
逐步回歸法擬合的林分蓄積量模型與BMA后驗概率最大的模型相似(表3)。但是BMA模型考慮了所有可能的變量組合,即考慮了林分蓄積量模型的不確定性(圖1)。根據(jù)表3和圖1即可發(fā)現(xiàn),林分蓄積量模型并非只是一個簡單的模型,而是由多種模型組合。
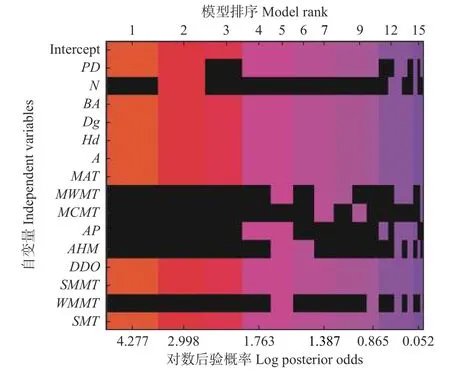
圖1 BMA法預(yù)測林分蓄積量模型的模型空間Fig.1 The model space of forest volume model determined by BMA method

表3 兩種方法選擇的林分蓄積量模型和BMA模型的后驗概率Table 3 Model selection and its posterior probability (Post prob) of forest volume model using BMA and stepwise regression model
其次,在模型評價上,兩種方法結(jié)果比較相近。這兩種方法的R2相似(R2=0.99),BMA的MD為-0.55,逐步回歸法的MD為0.55。此外,根據(jù)圖2也可發(fā)現(xiàn),根據(jù)BMA方法預(yù)測的杉木林分蓄積量殘差波動比較平穩(wěn),沒有明顯的異方差。
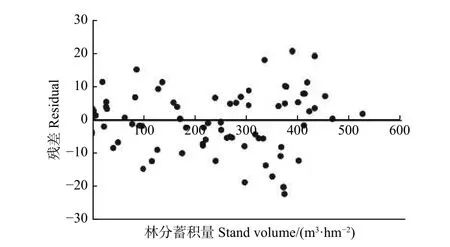
圖2 基于BMA模型預(yù)測的林分蓄積量殘差Fig.2 Residuals of stand volume against observed volume output from BMA model
3.2 變量選擇的比較
BMA方法有強的證據(jù)表明杉木林分蓄積量生長與PD負相關(guān)(后驗概率P=0.81 < 0.95),有很強的證據(jù)表明與BA,Dg,Hd,A,DD0,SMMT和SMT正相關(guān),與年均氣溫負相關(guān)(后驗概率P>0.95,表4)。而在逐步回歸法中,杉木林分蓄積量生長除了與上面一些變量相關(guān)顯著相關(guān)外,還與N、AP、AHM和WMMT顯著正相關(guān),與MWMT顯著負相關(guān)(表4)。
4 討論
4.1 BMA與SR模型的比較
在本研究中,分別用BMA模型法與逐步回歸法分析杉木林分蓄積量與林分變量因子和氣候因子的關(guān)系。逐步回歸方法根據(jù)自變量的P值判斷顯著與否。然而,在變量選擇之后使用P值可能會產(chǎn)生極大的誤導(dǎo)。如:當樣本量比較大時,P值可能明顯地拒絕擬合效果比較好的模型,而當樣本量比較小時,擬合效果比較差,模型結(jié)果不可靠[28]。此外,有研究表明逐步回歸法忽略了模型的不確定性[16,29]。而實際上事先并不知道包含哪些變量的模型為最佳模型,即模型本身的不確定性[14]。
BMA方法不同,它并非僅得出一個“最佳”的模型,而是考慮所有可能的單項模型以及各個模型的后驗概率,用模型的后驗概率加權(quán)平均得到一個貝葉斯平均模型,然后根據(jù)模型中的變量估計值不等于0的后驗概率進行變量重要性的排序[18]。BMA不僅給出了最大后驗概率模型,同時給出篩選的模型的后驗概率,從后驗概率的大小評價各模型的優(yōu)劣,從而有效解決了林分蓄積量模型的不確定性[19]。
林分蓄積量模型中,逐步回歸法所得到的模型并不在BMA法所確定的前5個后驗概率高的模型中(表3)。這表明林分蓄積量模型存在不確定性,且逐步回歸方法忽略了這一點。此外,逐步回歸模型中更易選擇冗余變量。在本研究中,逐步回歸法多選擇了N、MCMT、AP、AHM和WMMT。很明顯,本研究區(qū)福建邵武氣候溫暖濕潤,雨量充沛。故年均降水量AP和干旱指數(shù)AHM對于杉木林分生長并不存在顯著的影響關(guān)系。而且該區(qū)域的最低溫因子包括最冷月平均溫MCMT和冬季平均最低溫WMMT也很難對杉木林分生長起到重要的作用。此外,在逐步回歸方法中多選的變量N很明顯與BA相關(guān)。Genell等[30]通過模擬數(shù)據(jù)表明,BMA不選擇冗余變量的概率高于逐步回歸方法,并且選擇真實預(yù)測因子的概率與逐步回歸法相似。
一般來說模型變量越多,模型精度越高。而Madigan和Raftery[31]證明了BMA模型的精度絕對不會低于逐步回歸模型所確定的單一模型。這在本研究中也得到了證實:兩種方法的R2值相近。這或許是由于在大樣本中,兩種模型性能相當,而對于小樣本,貝葉斯方法的性能優(yōu)于傳統(tǒng)方法[32-33]。Wang等[34]將層次貝葉斯方法與非線性混合效應(yīng)模型進行比較,以估計地上樹生物量,并表明這兩種方法在匯集數(shù)據(jù)時表現(xiàn)相似,而對于小樣本,貝葉斯模型方法要好得多。
4.2 影響杉木林分蓄積量變化的因子
林分變量因子中,蓄積量隨著林分平方平均胸徑,年齡,每公頃斷面積和優(yōu)勢高的增加而增加。這與何理深和張超[11]的結(jié)果一致:平均年齡、平均胸徑和平均樹高對云南松蓄積量生長有促進作用。汪瑋和孟偉[4]也認為杉木林分蓄積量與平均胸徑和平均樹高是正相關(guān)關(guān)系,但他們認為與平均林齡無關(guān)。王少杰等[35]在用基礎(chǔ)模型預(yù)估林分蓄積量時,得出優(yōu)勢木平均高和林分斷面積促進蓄積量增長的結(jié)論,與本研究結(jié)果一致。我們發(fā)現(xiàn)初植密度越大,蓄積量越小,這和以前的研究不同[4,36],林分蓄積量由林分密度和單株材積的乘積取得,兩者互為消長,因此林分蓄積量取決于哪個因子的作用更強[37]。密度較低時,初植密度處于支配地位,林分蓄積與密度是正相關(guān)關(guān)系,當密度達到一定程度時,蓄積量不再隨初植密度的增加而變化,保持在一定水平[38]。本研究結(jié)果可能是由于初植密度越大,競爭越大,自然稀疏越多,保留株數(shù)急劇減少,因此林分蓄積量隨之變小。劉新亮等[39]發(fā)現(xiàn)樟樹林蓄積量隨著初植密度的增大,呈現(xiàn)出先增大后減小的規(guī)律,在1 111株·hm-2時,蓄積量最大。在高密度時,杉木個體對養(yǎng)分、光照等資源競爭激烈,樹木發(fā)育受到明顯抑制[40]。
氣候因子中,夏季平均最高溫、春季平均溫和低于0℃天數(shù)都對林分蓄積量有促進作用。年均氣溫和最熱月平均溫與林分蓄積量是負相關(guān)關(guān)系。一般來說溫度和降雨會促進杉木的生長。夏季溫度高,杉木人工林的生長季將會有所延長,那么其生長量也會增加[41],最終會使得林分蓄積量增加。春季平均溫的升高,使杉木得到迅速生長,其蓄積量相應(yīng)得到增加。研究發(fā)現(xiàn)紅松(Pinus koraiensisSieb. et Zucc.)生長和年平均溫是負相關(guān)關(guān)系,因為氣溫的上升增強了呼吸作用,消耗了積累的有機物質(zhì),影響了下一年樹木的早材生長[42]。在本研究中,由于研究區(qū)屬于溫暖濕潤,雨量充沛的氣候區(qū)域,而杉木喜歡濕潤的環(huán)境,因此降水量和干旱指數(shù)對杉木林分蓄積量的增長并不起顯著作用。
5 結(jié)論
本研究采用逐步回歸方法和貝葉斯模型平均法分析杉木人工林林分蓄積量與林分變量因子和氣候因子的關(guān)系。研究發(fā)現(xiàn)逐步回歸法所確定的模型并不在BMA選出的后驗概率較高的前5個模型中。從后驗概率的角度說明,逐步回歸模型精度比BMA模型精度低。其次,逐步回歸法僅給出一個所謂的最優(yōu)模型,而貝葉斯模型平均法根據(jù)不同模型的后驗概率考慮所有可能模型的組合,表現(xiàn)出模型的不確定性。同時,逐步回歸法相對于BMA方法更易選擇冗余變量,冗余變量有N、MCMT、AP、AHM和WMMT。此外,這兩種方法所表現(xiàn)出的模型預(yù)測精度相當。杉木林分蓄積量隨著每公頃胸高斷面積、平方平均胸徑、優(yōu)勢高、年齡、夏季平均最高溫、春季平均溫和低于0℃天數(shù)的增加而增加。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(2021年2期)2021-07-19 08:35:14
新世紀智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
