孤立森林算法研究及并行化實現
2021-07-06 02:14:40王誠,狄萱
計算機技術與發展 2021年6期
關鍵詞:檢測
王 誠,狄 萱
(南京郵電大學 通信與信息工程學院,江蘇 南京 210003)
0 引 言
異常檢測是近年來數據挖掘中熱門的研究課題之一,被廣泛應用于醫保欺詐[1]、網絡入侵[2]、醫療診斷[3]等領域。隨著物聯網、云計算等技術的不斷發展,數據量日漸增長,傳統單機版異常檢測算法難以對大規模數據進行高效檢測。因此,針對大規模數據設計相應算法,具有重要的應用價值。近年來,已有的異常檢測算法分為三類,分別是基于統計[4]、密度[5]和聚類[6]的算法。Liu等[7-8]提出的孤立森林算法,通過計算測試數據在已構建的孤立森林模型下的平均路徑長度代入公式求其異常值,該算法大大減少了計算時間,適用于高維數據。Liao等[9]提出一種基于信息熵的改進孤立森林算法,該算法通過計算數據集中各個特征下的信息熵,優先選擇信息熵小的特征作為切割特征,并且改進了路徑長度的計算公式,對噪聲特征具有較強的抵抗性。Yang等[10]提出了一種基于孤立的嵌入式無監督特征選擇(IBFS)算法,該算法通過計算孤立森林在訓練過程中每個特征的得分,選出表現優異的特征集合進行異常檢測,提高了異常檢測精度。Yong等[11]根據Hadoop平臺業調度機制和孤立森林算法的思想,將孤立森林算法的模型構建和異常預測兩個過程進行了并行化設計,但其運算過程中需要多個MapReduce操作完成并行運算,多次讀寫硬盤,耗費大量時間。
孤立森林算法異常檢測不需要計算距離和密度,避免了大量的計算,因此能夠更好地支持高維數據的異常檢測,同時孤立森林的每棵孤立二叉樹的構建過程都是獨立的,能夠利用分布式平臺對孤立森林算法進行并行化設計。孤立森林算法存在一些不足之處:
(1)在深入研究孤立森林算法過程中發現,孤立森林算法在計算測試樣本的異常值時,計算的是測試樣本在孤立森林的平均路徑長度,而孤立森林算法的核心思想是:在一棵孤立二叉樹中,若某個葉子節點的路徑長度短,則認為該節點是異常點。當某棵孤立二叉樹沒有相對短的路徑的葉子節點時,則說明其難以區分異常點。
(2)Yong等[11]指出,孤立森林算法異常檢測的精度與孤立二叉樹的數量有關,隨著數據量的增多,所需構建孤立二叉樹的數量也相應增多,從而導致耗費大量內存和時間,影響算法效率。
針對第一點不足,對孤立森林中每棵孤立二叉樹的路徑長度的標準差進行歸一化加權,計算異常值。若標準差大,則說明該棵孤立二叉樹中各葉子節點間的路徑長度差異大,具有較好的異常檢測能力,應賦予較高的權值,否則賦予較低的權值。通過加權計算測試樣本在孤立森林的異常值,以提高異常檢測的精確度。針對第二點不足,利用Spark平臺實現改進算法的并行化。Spark平臺是基于內存設計的,避免了Hadoop平臺MapReduce操作需要頻繁讀寫磁盤,能夠加快整體的異常檢測速度。
1 相關工作
1.1 孤立森林算法
孤立森林是由多棵孤立二叉樹組成的,孤立二叉樹的構建過程是算法的核心,孤立二叉樹的構建過程如下:
(1)從數據集D中隨機選擇m個樣本點作為生成本棵孤立二叉樹的樣本集Ds。
(2)從樣本集Ds中隨機選擇一個特征f和一個切割值p。若節點N包含的所有樣本在特征f下的最大值和最小值分別為f_max和f_min,則有p∈[f_min,f_max]。
(3)若樣本的特征f的值小于切割值p,則將該樣本分到節點N的左孩子;否則,分到右孩子。
(4)重復(2)、(3)兩步,分別對節點N的左右孩子節點進行切分,生成孤立二叉樹。當孩子節點中有多條相同的數據或只有一條數據或孤立二叉樹已達到設置的最大高度時,停止生成孤立二叉樹。
(5)孤立森林最終由用戶指定數目的孤立二叉樹組成。根據樣本點d在每棵孤立二叉樹中的路徑長度h(d),利用公式(1)計算d的異常值,從而評價其異常情況。
(1)
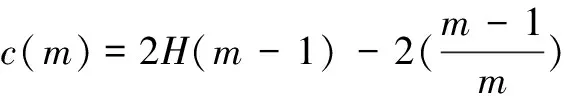
1.2 Spark大數據計算框架
Spark[12-13]是加州大學伯克利分校的AMP實驗室開發的一款基于內存的并行分布式計算框架。相較于Hadoop框架中的分布式計算模塊MapReduce需要頻繁讀寫磁盤I/O操作,Spark框架基于內存的設計,將每一輪的輸出結果都緩存在內存中,避免了從HDFS中讀取數據,更適合需要多次迭代的算法。Spark的運行架構模型如圖1所示,其基本運行流程是:

圖1 Spark運行架構模型
(1)Spark在驅動節點Driver端運行main()方法并創建SparkContext以構建Spark Application的運行環境,創建完成后的SparkContext向資源管理器Cluster Manager申請所需要的CPU、內存等資源并申請運行多個執行節點Executor,Cluster Manager分配并啟動各個Executor。
(2)SparkContext構建有向無環圖DAG以反映彈性分布式數據集RDD之間的依賴關系,并將其分解成任務集TaskSet發送給有向無環圖調度器TaskScheduler。
(3)各Executor向SparkContext申請Task,TaskScheduler將Task分發給各個Executor,同時SparkContext將打好的程序Jar包發送給各個Executor,各Executor執行結束后將結果收集給Driver端[14],最終釋放資源。
2 改進孤立森林算法的并行化實現
2.1 加權孤立森林的構建算法
如公式(1)所示,孤立森林在計算測試樣本異常值時,計算的是測試樣本在孤立森林的平均路徑長度,忽略了各孤立二叉樹的異常檢測能力的差異性,即每個葉子節點的路徑都很長的孤立二叉樹難以區分異常點,而具有短路徑的葉子節點的孤立二叉樹能夠更好地區分異常點。如圖2和圖3所示,圖2的孤立二叉樹比圖3的孤立二叉樹具有更強的區分異常點的能力。因此該文通過計算每棵孤立二叉樹的路徑長度標準差對具有更強區分異常點能力的樹進行加權,同時減小區分異常點能力較差的樹的權值。
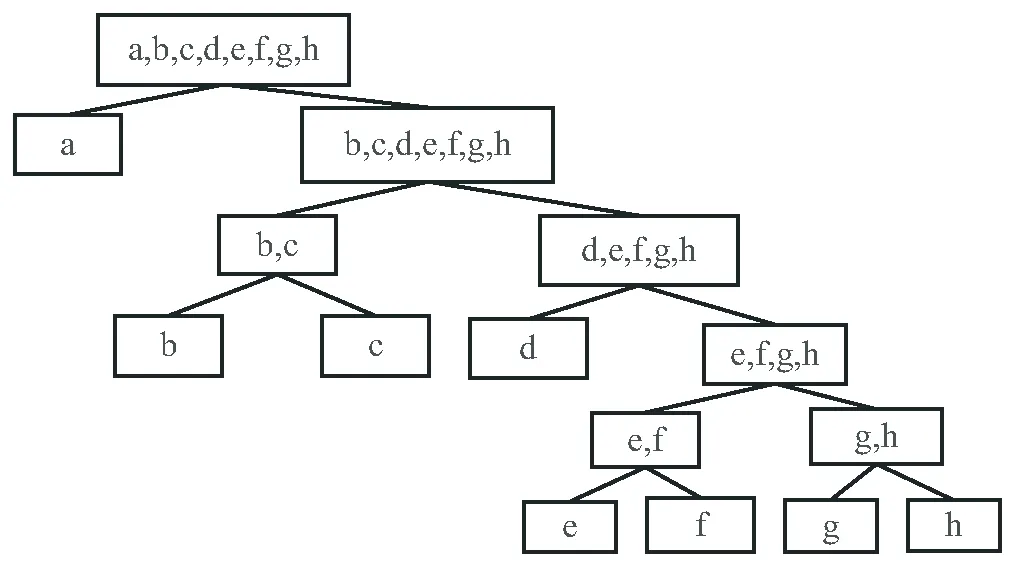
圖2 區分異常能力強的孤立二叉樹
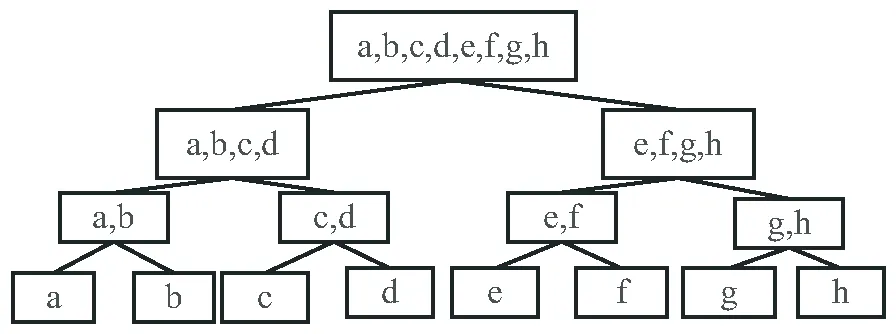
圖3 區分異常能力差的孤立二叉樹
若一棵孤立二叉樹的葉子節點集合為Node={node1,node2,…,noden},葉子節點的路徑長度集合為Hnode={h1,h2,…,hn},則該棵樹的路徑長度標準差σ的計算公式為:
(2)
其中,n為葉子節點的總個數,μ為該棵樹所有葉子節點路徑長度的均值。
若孤立森林中所有孤立二叉樹的路徑長度標準差集合為σ={σ1,σ2,…,σn},其中最大值為σmax,最小值為σmin,對路徑長度標準差集合進行歸一化,公式為:
(3)
若數據集D中每個樣本點d在每棵孤立二叉樹中的路徑長度為集合Hd={h1,h2,…,hn},孤立二叉樹的權重集W={w1,w2,…,wn},則樣本點d的異常值計算公式為:
(4)
具體算法實現如下:
算法1:加權孤立森林的構建算法。

輸出:孤立森林,權重集W。
(1)對數據集D進行隨機采樣,抽取m個數據放入集合Ds中。
(2)調用孤立二叉樹生成算法,并傳入相關參數,生成單棵孤立二叉樹。
(3)利用公式(2)計算當前生成的孤立二叉樹的路徑長度標準差。
(4)重復1、2兩步,直到生成n棵孤立二叉樹及路徑長度標準差集合。
(5)利用公式(3)對路徑長度標準差集合進行歸一化,生成權重集W。
(6)返回由n棵孤立二叉樹組成的孤立森林及權重集W。
算法2:樣本點異常值計算流程。
輸入:數據集D,權重集W;
輸出:數據集D的異常值集N。
(1)計算數據集D中每個樣本點在每棵孤立二叉樹中的路徑長度集合Hd。
(2)利用公式(4),加權計算每個樣本點的異常值,并合為異常值集N。
(3)返回數據集D的異常值集N。
2.2 改進孤立森林算法的并行化設計
該文利用Spark平臺實現改進孤立森林算法的并行化。主要步驟包括:數據抽樣、模型構建和異常預測。整體框架如圖4所示。
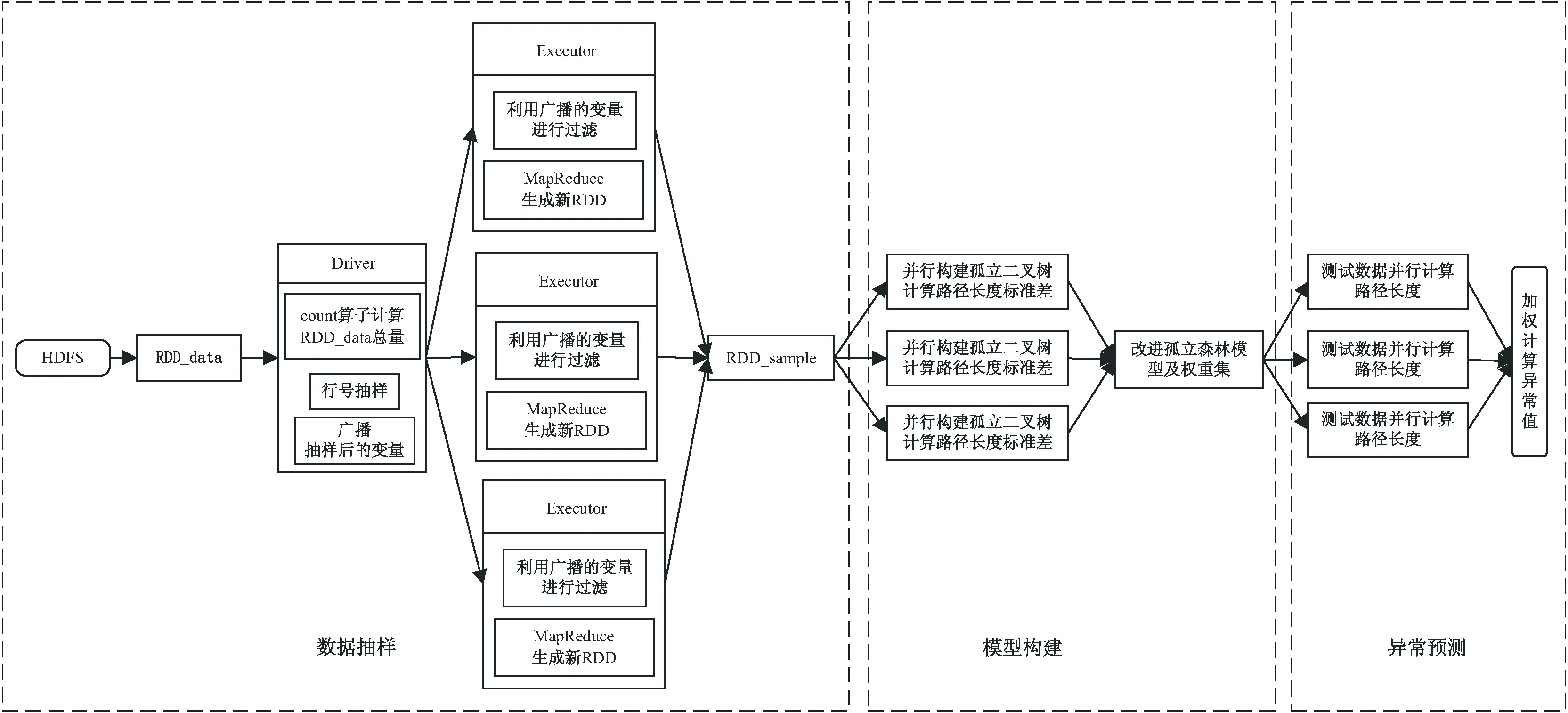
圖4 改進孤立森林算法并行化框架
(1)數據抽樣。
單機版的孤立森林算法需要對原始數據集進行隨機抽樣,利用抽樣后的數據集生成孤立二叉樹。而Spark平臺數據存儲核心RDD是分布式數據集,如果直接對各個分區的數據進行定量隨機抽樣,不能保證抽樣后得到的數據集是全局隨機的。雖然Spark提供了sample抽樣算子,但會導致非確定性大小的采樣樣本集。因此,該文設計從HDFS中讀取數據文件,轉化成RDD記為RDD_data,在Driver端首先利用count算子計算RDD_data數據總量,創建RandomData-Generator類,根據RDD_data數據總量、孤立二叉樹數量、隨機采樣樣本數量,隨機生成包含行號索引值的二維數組,并將其映射為(rowId(行號),treeIdArray(該行數據對應的孤立二叉樹ID集合))的格式,最后將該形式的變量廣播到各個Executor端,以減少Shuffle成本。利用zipWithIndex算子,為RDD_data添加全局索引號,在各個Executor端利用廣播來的變量中的行號對RDD_data數據內容篩選過濾,并通過flatMap、reduceByKey算子生成(treeId(孤立二叉樹ID),ContentArray(構建此ID孤立二叉樹所需的數據集))格式的數據集:RDD_sample。
(2)模型構建。
將RDD_sample數據集map到各個Executor端進行孤立二叉樹的并行同步構建并計算各個孤立二叉樹的路徑長度標準差,數據格式分別為:(treeId(孤立二叉樹ID),tree(孤立二叉樹))、(treeId(孤立二叉樹ID),stdPath(路徑長度標準差))。利用collect算子將多棵孤立二叉樹及各自的路徑長度標準差收集到Driver端,并將多棵樹的路徑長度標準差合并歸一化成一個數據格式為(treeId(孤立二叉樹ID),weight(權重))的權重集。最后將構建好的模型及權重集分別存入RDD_model和RDD_weight中。
(3)異常預測。
將構建好的模型RDD_model廣播給各個Executor,測試數據集并行遍歷每一棵孤立二叉樹,得到每一個測試數據樣本在模型下的路徑長度集合,集合中元素的數據格式為(treeId(孤立二叉樹ID),pathLength(路徑長度)),利用權重集RDD_weight對每一個測試數據樣本的路徑長度集合進行加權計算,得到每一個測試數據樣本的異常值,從而評價其異常情況。
3 實驗設計與結果分析
3.1 實驗數據集
實驗數據集選取自威斯康星州數據集Breastw、UCI數據集Shuttle和KDD CUP 99數據集Http[15],數據集的具體信息如表1所示。

表1 數據集具體信息
3.2 異常檢測精確度
該文使用表1中的三個數據集對三種算法進行實驗對比分析。其中,三個算法的參數均為:孤立二叉樹數量n=100,隨機采樣樣本數量m=256,樹的高度限制l=8。采用ROC曲線下的面積AUC指標來評價算法異常檢測精確度。AUC值的范圍為[0,1],其值越接近1則說明算法的檢測效果越好。具體的實驗結果如表2所示。

表2 三種算法的AUC值
從表2中可以看出,對于Breastw、Shuttle和Http三個數據集,改進孤立森林算法相對于原始孤立森林算法的AUC值分別提高了2.22%、2.51%、1.65%,這是因為改進孤立森林算法改進了異常值計算公式,為高異常檢測能力的孤立二叉樹賦予更高的權值,從而讓異常點更為突出。并行化改進孤立森林算法與改進孤立森林算法的AUC值沒有明顯差異,因此并行化改進孤立森林算法在異常檢測精度上能與改進孤立森林算法保持一致。同時,改進孤立森林算法由于需要計算路徑長度標準差并歸一化為權重集,相對于原始孤立森林算法增加了些許時間開銷,但在小規模數據集上可以忽略不計。并行化改進孤立森林算法相較于單機的改進孤立森林算法耗費了更多的時間,這是由于數據規模小時,集群初始化、任務調度及節點間的數據通信時間遠大于算法本身的運算時間。
3.3 并行性能實驗
實驗環境是基于Spark平臺的計算集群,該集群共有4個節點,每個節點的CPU核數為1核,內存為2 G,硬盤為30 G,Java版本為1.8.0,Scala版本為2.11.0,Hadoop版本為2.7.6,Spark版本為2.4.0。實驗數據集是由Breastw數據集構造的行數為100萬行、300萬行、500萬行、800萬行的大規模數據集。分別對這四個大規模數據集進行對比實驗,其中自變量為孤立二叉樹數目,分別為100棵、200棵、300棵、400棵、500棵。同時計算當孤立二叉樹數量為100時,改進孤立森林算法在Spark集群下的加速比,評價其并行性能。實驗結果如圖5~圖6所示。
從圖5中可以看出,在不同數據規模下,隨著孤立二叉樹數目的不斷增加,單機和并行化的孤立森林算法的運行時間都呈線性增加,單機算法的增幅更陡峭,并行算法的增幅平緩。當數據量達到800萬行、孤立二叉樹數目為500棵時,單機運行時間是并行化后的運行時間的4.34倍。從圖6中可以看出并行化改進孤立森林算法總體上有很好的加速比。隨著數據量的不斷增大,加速比隨著節點數的增加而明顯增大,當數據量達到800萬行、節點數為4時,加速比提升到了2.88。因此,并行化改進孤立森林算法能夠更高效地處理需要構建大量孤立二叉樹的大規模數據集。

圖5 不同規模數據集下運行時間對比
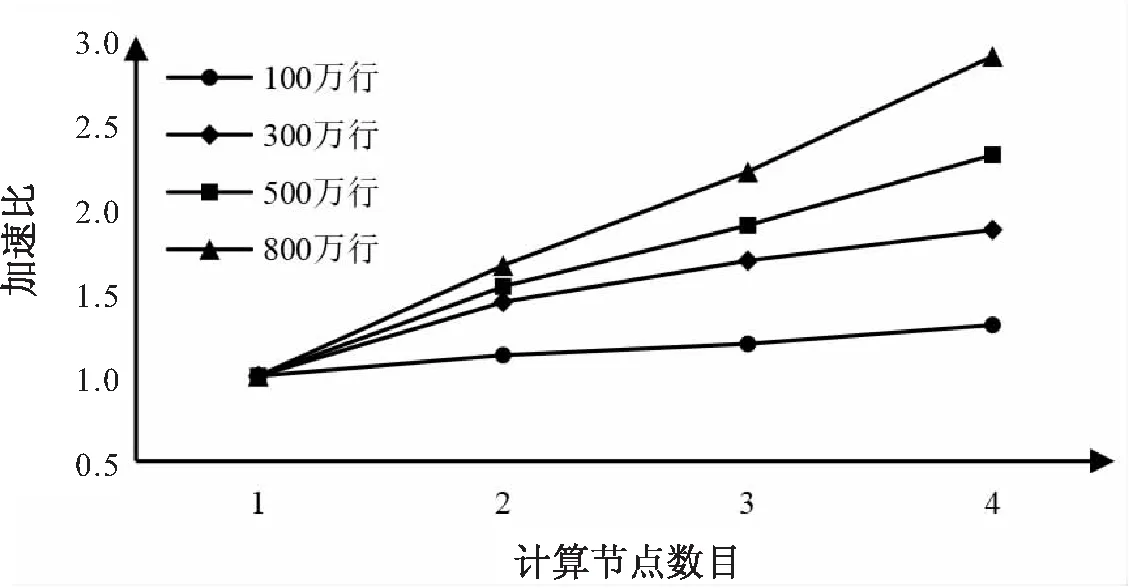
圖6 100棵孤立二叉樹下的加速比
4 結束語
該文針對孤立森林算法在計算測試樣本的異常值時,忽略了孤立二叉樹間檢測異常能力差異性以及大規模數據下構建大量孤立二叉樹需要耗費大量內存時間這兩點不足進行改進,加權計算測試樣本在孤立森林中的異常值并基于Spark平臺設計實現并行化改進孤立森林算法。通過多個對比實驗結果表明,并行化改進孤立森林算法能夠加快大規模數據集下的異常檢測速度,同時提高了異常檢測精度。下一步將把該算法與實際應用場景相結合,檢驗其實際應用價值。
猜你喜歡
中國設備工程(2022年12期)2022-07-11 04:33:00
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:36
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:34
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:50
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:48
